Abstract
It has been a common practice in social psychology to publish only significant results. As a result, success rates in the published literature do not provide empirical evidence for the existence of a phenomenon. A recent meta-analysis suggested that ego-depletion is a much weaker effect than the published literature suggests and a registered replication study failed to find any evidence for it. This article presents the results of a replicability analysis of the ego-depletion literature. Out of 165 articles with 429 studies (total N = 33,927), 128 (78%) showed evidence of bias and low replicability (Replicability-Index < 50%). Closer inspection of the top 10 articles with the strongest evidence against the null-hypothesis revealed some questionable statistical analyses, and only a few articles presented replicable results. The results of this meta-analysis show that most published findings are not replicable and that the existing literature provides no credible evidence for ego-depletion. The discussion focuses on the need for a change in research practices and suggests a new direction for research on ego-depletion that can produce conclusive results.
INTRODUCTION
In 1998, Roy F. Baumeister and colleagues published a groundbreaking article titled “Ego Depletion: Is the Active Self a Limited Resource?” The article stimulated research on the newly minted construct of ego-depletion. At present, more than 150 articles and over 400 studies with more than 30,000 participants have contributed to the literature on ego-depletion. In 2010, a meta-analysis of nearly 100 articles, 200 studies, and 10,000 participants concluded that ego-depletion is a real phenomenon with a moderate to strong effect size of six tenth of a standard deviation (Hagger et al., 2010).
In 2011, Roy F. Baumeister and John Tierney published a popular book on ego-depletion titled “Will-Power,” and Roy F. Baumeister became to be known as the leading expert on self-regulation, will-power (The Atlantic, 2012).
Everything looked as if ego-depletion research has a bright future, but five years later the future of ego-depletion research looks gloomy and even prominent ego-depletion researchers wonder whether ego-depletion even exists (Slate, “Everything is Crumbling”, 2016).
An influential psychological theory, borne out in hundreds of experiments, may have just been debunked. How can so many scientists have been so wrong?
What Happened?
It has been known for 60 years that scientific journals tend to publish only successful studies (Sterling, 1959). That is, when Roy F. Baumeister reported his first ego-depletion study and found that resisting the temptation to eat chocolate cookies led to a decrease in persistence on a difficult task by 17 minutes, the results were published as a groundbreaking discovery. However, when studies do not produce the predicted outcome, they are not published. This bias is known as publication bias. Every researcher knows about publication bias, but the practice is so widespread that it is not considered a serious problem. Surely, researches would not conduct more failed studies than successful studies and only report the successful ones. Yes, omitting a few studies with weaker effects leads to an inflation of the effect size, but the successful studies still show the general trend.
The publication of one controversial article in the same journal that published the first ego-depletion article challenged this indifferent attitude towards publication bias. In a shocking article, Bem (2011) presented 9 successful studies demonstrating that extraverted students at Cornell University were seemingly able to foresee random events in the future. In Study 1, they seemed to be able to predict where a computer would present an erotic picture even before the computer randomly determined the location of the picture. Although the article presented 9 successful studies and 1 marginally successful study, researchers were not convinced that extrasensory perception is a real phenomenon. Rather, they wondered how credible the evidence in other article is if it is possible to get 9 significant results for a phenomenon that few researchers believed to be real. As Sterling (1959) pointed out, a 100% success rate does not provide evidence for a phenomenon if only successful studies are reported. In this case, the success rate is by definition 100% no matter whether an effect is real or not.
In the same year, Simmons et al. (2011) showed how researchers can increase the chances to get significant results without a real effect by using a number of statistical practices that seem harmless, but in combination can increase the chance of a false discovery by more than 1000% (from 5% to 60%). The use of these questionable research practices has been compared to the use of doping in sports (John et al., 2012). Researchers who use QRPs are able to produce many successful studies, but the results of these studies cannot be replicated when other researchers replicate the reported studies without QRPs. Skeptics wondered whether many discoveries in psychology are as incredible as Bem’s discovery of extrasensory perception; groundbreaking, spectacular, and false. Is ego-depletion a real effect or is it an artificial product of publication bias and questionable research practices?
Does Ego-Depletion Depend on Blood Glucose?
The core assumption of ego-depletion theory is that working on an effortful task requires energy and that performance decreases as energy levels decrease. If this theory is correct, it should be possible to find a physiological correlate of this energy. Ten years after the inception of ego-depletion theory, Baumeister and colleagues claimed to have found the biological basis of ego-depletion in an article called “Self-control relies on glucose as a limited energy source.” (Gailliot et al., 2007). The article had a huge impact on ego-depletion researchers and it became a common practice to measure blood-glucose levels.
Unfortunately, Baumeister and colleagues had not consulted with physiological psychologists when they developed the idea that brain processes depend on blood-glucose levels. To maintain vital functions, the human body ensures that the brain is relatively independent of peripheral processes. A large literature in physiological psychology suggested that inhibiting the impulse to eat delicious chocolate cookies would not lead to a measurable drop in blood glucose levels (Kurzban, 2011).
Let’s look at the numbers. A well-known statistic is that the brain, while only 2% of body weight, consumes 20% of the body’s energy. That sounds like the brain consumes a lot of calories, but if we assume a 2,400 calorie/day diet – only to make the division really easy – that’s 100 calories per hour on average, 20 of which, then, are being used by the brain. Every three minutes, then, the brain – which includes memory systems, the visual system, working memory, then emotion systems, and so on – consumes one (1) calorie. One. Yes, the brain is a greedy organ, but it’s important to keep its greediness in perspective.
But, maybe experts on physiology were just wrong and Baumeister and colleagues made another groundbreaking discovery. After all, they presented 9 successful studies that appeared to support the glucose theory of will-power, but 9 successful studies alone provide no evidence because it is not clear how these successful studies were produced.
To answer this question, Schimmack (2012) developed a statistical test that provides information about the credibility of a set of successful studies. Experimental researchers try to hold many factors that can influence the results constant (all studies are done in the same laboratory, glucose is measured the same way, etc.). However, there are always factors that the experimenter cannot control. These random factors make it difficult to predict the exact outcome of a study even if everything goes well and the theory is right. To minimize the influence of these random factors, researchers need large samples, but social psychologists often use small samples where random factors can have a large influence on results. As a result, conducting a study is a gamble and some studies will fail even if the theory is correct. Moreover, the probability of failure increases with the number of attempts. You may get away with playing Russian roulette once, but you cannot play forever. Thus, eventually failed studies are expected and a 100% success rate is a sign that failed studies were simply not reported. Schimmack (2012) was able to use the reported statistics in Gailliot et al. (2007) to demonstrate that it was very likely that the 100% success rate was only achieved by hiding failed studies or with the help of questionable research practices.
Baumeister was a reviewer of Schimmack’s manuscript and confirmed the finding that a success rate of 9 out of 9 studies was not credible.
“My paper with Gailliot et al. (2007) is used as an illustration here. Of course, I am quite familiar with the process and history of that one. We initially submitted it with more studies, some of which had weaker results. The editor said to delete those. He wanted the paper shorter so as not to use up a lot of journal space with mediocre results. It worked: the resulting paper is shorter and stronger. Does that count as magic? The studies deleted at the editor’s request are not the only story. I am pretty sure there were other studies that did not work. Let us suppose that our hypotheses were correct and that our research was impeccable. Then several of our studies would have failed, simply given the realities of low power and random fluctuations. Is anyone surprised that those studies were not included in the draft we submitted for publication? If we had included them, certainly the editor and reviewers would have criticized them and formed a more negative impression of the paper. Let us suppose that they still thought the work deserved publication (after all, as I said, we are assuming here that the research was impeccable and the hypotheses correct). Do you think the editor would have wanted to include those studies in the published version?”
To summarize, Baumeister defends the practice of hiding failed studies with the argument that this practice is acceptable if the theory is correct. But we do not know whether the theory is correct without looking at unbiased evidence. Thus, his line of reasoning does not justify the practice of selectively reporting successful results, which provides biased evidence for the theory. If we could know whether a theory is correct without data, we would not need empirical tests of the theory. In conclusion, Baumeister’s response shows a fundamental misunderstanding of the role of empirical data in science. Empirical results are not mere illustrations of what could happen if a theory were correct. Empirical data are supposed to provide objective evidence that a theory needs to explain.
Since my article has been published, there have been several failures to replicate Gailliot et al.’s findings and recent theoretical articles on ego-depletion no longer assume that blood-glucose as the source of ego-depletion.
“Upon closer inspection notable limitations have emerged. Chief among these is the failure to replicate evidence that cognitive exertion actually lowers blood glucose levels.” (Inzlicht, Schmeichel, & Macrae, 2014, p 18).
Thus, the 9 successful studies that were selected by Baumeister et al. (1998) did not illustrate an empirical fact, they created false evidence for a physiological correlate of ego-depletion that could not be replicated. Precious research resources were wasted on a line of research that could have been avoided by consulting with experts on human physiology and by honestly examining the successful and failed studies that led to the Baumeister et al. (1998) article.
Even Baumeister agrees that the original evidence was false and that glucose is not the biological correlate of ego-depletion.
In retrospect, even the initial evidence might have gotten a boost in significance from a fortuitous control condition. Hence at present it seems unlikely that ego depletion’s effects are caused by a shortage of glucose in the bloodstream” (Baumeister, 2014, p 315).
Baumeister fails to mention that the initial evidence also got a boost from selection bias.
In sum, the glucose theory of ego-depletion was based on selective reporting of studies that provided misleading support for the theory and the theory lacks credible empirical support. The failure of the glucose theory raises questions about the basic ego-depletion effect. If researchers in this field used selective reporting and questionable research practices, the evidence for the basic effect is also likely to be biased and the effect may be difficult to replicate.
If 200 studies show ego-depletion effects, it must be real?
Psychologists have not ignored publication bias altogether. The main solution to the problem is to conduct meta-analyses. A meta-analysis combines information from several small studies to examine whether an effect is real. The problem for meta-analysis is that publication bias also influences the results of a meta-analysis. If only successful studies are published, a meta-analysis of published studies will show evidence for an effect no matter whether the effect actually exists or not. For example, the top journal for meta-analysis, Psychological Bulletin, has published meta-analyses that provide evidence for extransensory perception (Bem & Honorton, 1994).
To address this problem, meta-analysts have developed a number of statistical tools to detect publication bias. The most prominent method is Eggert’s regression of effect size estimates on sampling error. A positive correlation can reveal publication bias because studies with larger sampling errors (small samples) require larger effect sizes to achieve statistical significance. To produce these large effect sizes when the actual effect does not exist or is smaller, researchers need to hide more studies or use more questionable research practices. As a result, these results are particularly difficult to replicate.
Although the use of these statistical methods is state of the art, the original ego-depletion meta-analysis that showed moderate to large effects did not examine the presence of publication bias (Hagger et al., 2010). This omission was corrected in a meta-analysis by Carter and McCollough (2014).
Upon reading Hagger et al. (2010), we realized that their efforts to estimate and account for the possible influence of publication bias and other small-study effects had been less than ideal, given the methods available at the time of its publication (Carter & McCollough, 2014).
The authors then used Eggert regression to examine publication bias. Moreover, they used a new method that was not available at the time of Hagger et al.’s (2010) meta-analysis to estimate the effect size of ego-depletion after correcting for the inflation caused by publication bias.
Not surprisingly, the regression analysis showed clear evidence of publication bias. More stunning were the results of the effect size estimate after correcting for publication bias. The bias-corrected effect size estimate was d = .25 with a 95% confidence interval ranging from d = .18 to d = .32. Thus, even the upper limit of the confidence interval is about 50% less than the effect size estimate in the original meta-analysis without correction for publication bias. This suggests that publication bias inflated the effect size estimate by 100% or more. Interestingly, a similar result was obtained in the reproducibility project, where a team of psychologists replicated 100 original studies and found that published effect sizes were over 100% larger than effect sizes in the replication project (OSC, 2015).
An effect size of d = .2 is considered small. This does not mean that the effect has no practical importance, but it raises questions about the replicability of ego-depletion results. To obtain replicable results, researchers should plan studies so that they have an 80% chance to get significant results despite the unpredictable influence of random error. For small effects, this implies that studies require large samples. For the standard ego-depletion paradigm with an experimental group and a control group and an effect size of d = .2, a sample size of 788 participants is needed to achieve 80% power. However, the largest sample size in an ego-depletion study was only 501 participants. A sample size of 388 participants is needed to achieve significance without an inflated effect size (50% power) and most studies fall short of this requirement in sample size. Thus, most published ego-depletion results are unlikely to replicate and future ego-depletion studies are likely to produce non-significant results.
In conclusion, even 100 studies with 100% successful results do not provide convincing evidence that ego-depletion exists and which experimental procedures can be used to replicate the basic effect.
Replicability without Publication Bias
In response to concerns about replicability, the American Psychological Society created a new format for publications. A team of researchers can propose a replication project. The research proposal is peer-reviewed like a grant application. When the project is approved, researchers conduct the studies and publish the results independent of the outcome of the project. If it is successful, the results confirm that earlier findings that were reported with publication bias are replicable, although probably with a smaller effect size. If the studies fail, the results suggest that the effect may not exist or that the effect size is very small.
In the fall of 2014 Hagger and Chatzisarantis announced a replication project of an ego-depletion study.
The third RRR will do so using the paradigm developed and published by Sripada, Kessler, and Jonides (2014), which is similar to that used in the original depletion experiments (Baumeister et al., 1998; Muraven et al., 1998), using only computerized versions of tasks to minimize variability across laboratories. By using preregistered replications across multiple laboratories, this RRR will allow for a precise, objective estimate of the size of the ego depletion effect.
In the end, 23 laboratories participated and the combined sample size of all studies was N = 2141. This sample size affords an 80% probability to obtain a significant result (p < .05, two-tailed) with an effect size of d = .12, which is below the lower limit of the confidence interval of the bias-corrected meta-analysis. Nevertheless, the study failed to produce a statistically significant result, d = .04 with a 95%CI ranging from d = -.07 to d = .14. Thus, the results are inconsistent with a small effect size of d = .20 and suggest that ego-depletion may not even exist at all.
Ego-depletion researchers have responded to this result differently. Michael Inzlicht, winner of a theoretical innovation prize for his work on ego-depletion, wrote:
The results of a massive replication effort, involving 24 labs (or 23, depending on how you count) and over 2,000 participants, indicates that short bouts of effortful control had no discernable effects on low-level inhibitory control. This seems to contradict two decades of research on the concept of ego depletion and the resource model of self-control. Like I said: science is brutal.
In contrast, Roy F. Baumeister questioned the outcome of this research project that provided the most comprehensive and scientific test of ego-depletion. In a response with co-author Kathleen D. Vohs titled “A misguided effort with elusive implications,” Baumeister tries to explain why ego depletion is a real effect, despite the lack of unbiased evidence for it.
The first line of defense is to question the validity of the paradigm that was used for the replication project. The only problem is that this paradigm seemed reasonable to the editors who approved the project, researchers who participated in the project and who expected a positive result, and to Baumeister himself when he was consulted during the planning of the replication project. In his response, Baumeister reverses his opinion about the paradigm.
In retrospect, the decision to use new, mostly untested procedures for a large replication project was foolish.
He further claims that he proposed several well-tested procedures, but that these procedures were rejected by the replication team for technical reasons.
Baumeister nominated several procedures that have been used in successful studies of ego depletion for years. But none of Baumeister’s suggestions were allowable due to the RRR restrictions that it must be done with only computerized tasks that were culturally and linguistically neutral.
Baumeister and Vohs then claim that the manipulation did not lead to ego-depletion and that it is not surprising that an unsuccessful manipulation does not produce an effect.
Signs indicate the RRR was plagued by manipulation failure — and therefore did not test ego depletion.
They then assure readers that ego-depletion is real because they have demonstrated the effect repeatedly using various experimental tasks.
For two decades we have conducted studies of ego depletion carefully and honestly, following the field’s best practices, and we find the effect over and over (as have many others in fields as far-ranging as finance to health to sports, both in the lab and large-scale field studies). There is too much evidence to dismiss based on the RRR, which after all is ultimately a single study — especially if the manipulation failed to create ego depletion.
This last statement is, however, misleading if not outright deceptive. As noted earlier, Baumeister admitted to the practice of not publishing disconfirming evidence. He and I disagree whether the selective publication of successful studies is honest or dishonest. He wrote:
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication)
So, when Baumeister and Vohs assure readers that they conducted ego-depletion research carefully and honestly, they are not saying that they reported all studies that they conducted in their labs. The successful studies published in articles are not representative of the studies conducted in their labs.
In a response to Baumeister and Vohs, the lead authors of the replication project pointed out that ego-depletion does not exist unless proponents of ego-depletion theory can specify experimental procedures that reliably produce the predicted effect.
The onus is on researchers to develop a clear set of paradigms that reliably evoke depletion in large samples with high power (Hagger & Chatzisarantis, 2016)
In an open email letter, I asked Baumeister and Vohs to name paradigms that could replicate a published ego-depletion effect. They were not able or willing to name a single paradigm. Roy Bameister’s response was “In view of your reputation as untrustworthy, dishonest, and otherwise obnoxious, i prefer not to cooperate or collaborate with you.”
I did not request to collaborate with him. I merely asked which paradigm would be able to produce ego-depletion effects in an open and transparent replication study, given his criticism of the most rigorous replication study that he initially approved.
If an expert who invented a theory and published numerous successful studies cannot name a paradigm that will work, it suggests that he does not know which studies may work because for each published successful study there are unpublished, unsuccessful studies that used the same procedure, and it is not obvious which study would actually replicate in an honest and transparent replication project.
A New Meta-Analysis of Ego-Depletion Studies: Are there replicable effects?
Since I published the incredibility index (Schimmack, 2012) and demonstrated bias in research on glucose and ego-depletion, I have developed new and more powerful ways to reveal selection bias and questionable research practices. I applied these methods to the large literature on ego-depletion to examine whether there are some credible ego-depletion effects and a paradigm that produces replicable effects.
The first method uses powergraphs (Schimmack, 2015) to examine selection bias and the replicability of a set of studies. To create a powergrpah, original research results are converted into absolute z-score. A z-score shows how much evidence a study result provides against the null-hypothesis that there is no effect. Unlike effect size measures, z-scores also contain information about the sample size (sampling error). I therefore distinguish between meta-analysis of effect sizes and meta-analysis of evidence. Effect size meta-analysis aims to determine the typical, average size of an effect. Meta-analyses of evidence examine how strong the evidence for an effect (i.e., against the null-hypothesis of no effect) is.
The distribution of absolute z-scores provides important information about selection bias, questionable research practices, and replicability. Selection bias is revealed if the distribution of z-scores shows a steep drop on the left side of the criterion for statistical significance (this is analogous to the empty space below the line for significance in a funnel plot). Questionable research practices are revealed if z-scores cluster in the area just above the significance criterion. Replicabilty is estimated by fitting a weighted composite of several non-central distributions that simulate studies with different non-centrality parameters and sampling error.
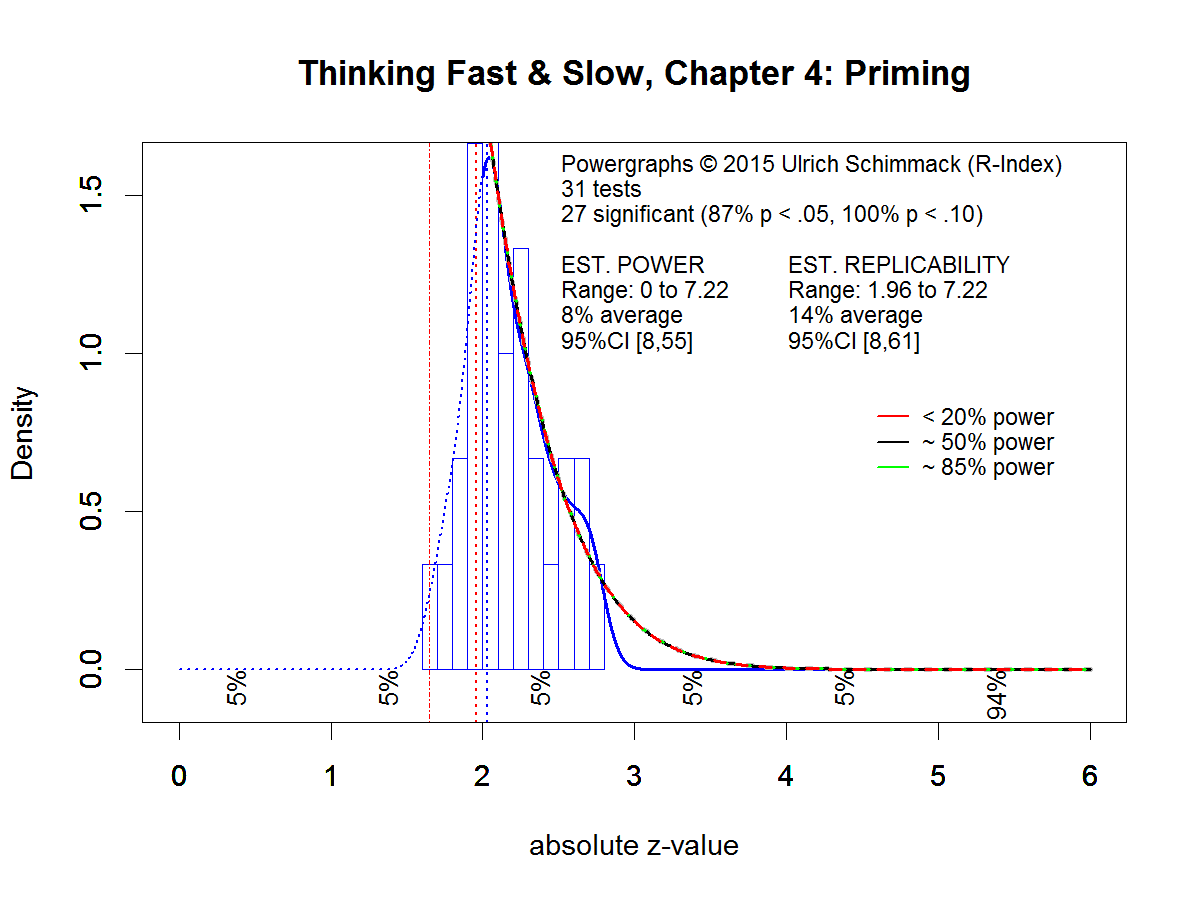
A literature search retrieved 165 articles that reported 429 studies. For each study, the most important statistical test was converted first into a two-tailed p-value and then into a z-score. A single test statistic was used to ensure that all z-scores are statistically independent.

The results show clear evidence of selection bias (Figure 1). Although there are some results below the significance criterion (z = 1.96, p < .05, two-tailed), most of these results are above z = 1.65, which corresponds to p < .10 (two-tailed) or p < .05 (one-tailed). These results are typically reported as marginally significant and used as evidence for an effect. There are hardly any results that fail to confirm a prediction based on ego-depletion theory. Using z = 1.65 as criterion, the success rate is 96%, which is common for the reported success rate in psychological journals (Sterling, 1959; Sterling et al., 1995; OSC, 2015). The steep cliff in the powergraph shows that this success rate is due to selection bias because random error would have produced a more gradual decline with many more non-significant results.
The next observation is the tall bar just above the significance criterion with z-scores between 2 and 2.2. This result is most likely due to questionable research practices that lead to just significant results such as optional stopping or selective dropping of outliers.
Another steep drop is observed at z-scores of 2.6. This drop is likely due to the use of further questionable research practices such as dropping of experimental conditions, use of multiple dependent variables, or simply running multiple studies and selecting only significant results.
A rather large proportion of z-scores are in the questionable range from z = 1.96 to 2.60. These results are unlikely to replicate. Although some studies may have reported honest results, there are too many questionable results and it is impossible to say which results are trustworthy and which results are not. It is like getting information from a group of people where 60% are liars and 40% tell the truth. Even though 40% are telling the truth, the information is useless without knowing who is telling the truth and who is lying.
The best bet to find replicable ego-depletion results is to focus on the largest z-scores as replicability increases with the strength of evidence (OSC, 2015). The power estimation method uses the distribution of z-scores greater than 2.6 to estimate the average power of these studies. The estimated power is 47% with a 95% confidence interval ranging from 32% to 63%. This result suggests that some ego-depletion studies have produced replicable results. In the next section, I examine which studies this may be.
In sum, a state-of-the art meta-analysis of evidence for an effect in the ego-depletion literature shows clear evidence for selection bias and the use of questionable research practices. Many published results are essentially useless because the evidence is not credible. However, the results also show that some studies produced replicable effects, which is consistent with Carter and McCollough’s finding that the average effect size is likely to be above zero.
What Ego-Depletion Studies Are Most Likely to Replicate?
Powergraphs are useful for large sets of heterogeneous studies. However, they are not useful to examine the replicability of a single study or small sets of studies, such as a set of studies in a multiple-study article. For this purpose, I developed two additional tools that detect bias in published results. .
The Test of Insufficient Variance (TIVA) requires a minimum of two independent studies. As z-scores follow a normal distribution (the normal distribution of random error), the variance of z-scores should be 1. However, if non-significant results are omitted from reported results, the variance shrinks. TIVA uses the standard comparison of variances to compute the probability that an observed variance of z-scores is an unbiased sample drawn from a normal distribution. TIVA has been shown to reveal selection bias in Bem’s (2011) article and it is a more powerful test than the incredibility index (Schimmack, 2012).
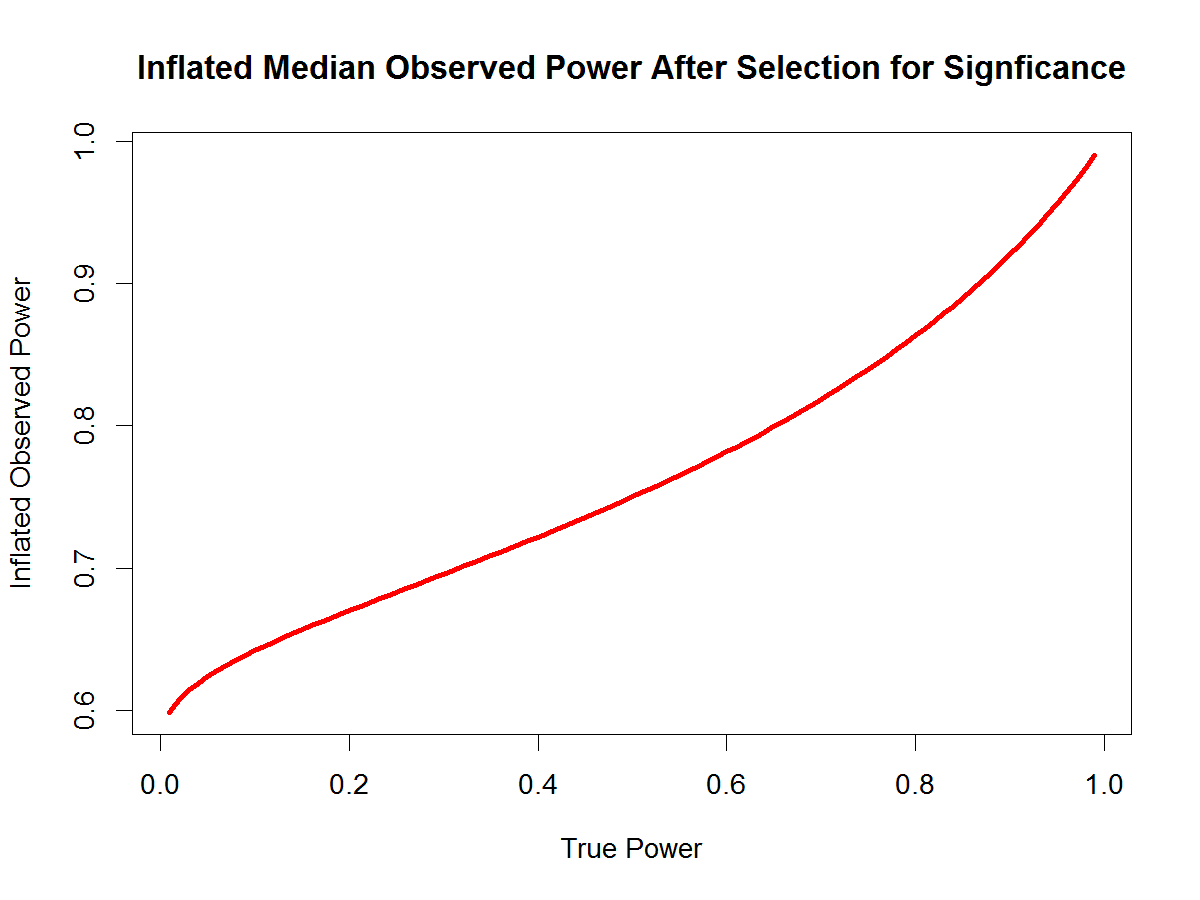
The R-Index is based on the Incredibilty Index in that it compares the success rate (percentage of significant results) with the observed statistical power of a test. However, the R-Index does not test the probability of the success rate. Rather, it uses the observed power to predict replicability of an exact replication study. The R-Index has two components. The first component is the median observed power of a set of studies. In the limit, median observed power approaches the average power of an unbiased set of exact replication studies. However, when selection bias is present, median observed power is biased and provides an inflated estimate of true power. The R-Index measures the extent of selection bias by means of the difference between success rate and median observed power. If median observed power is 75% and the success rate is 100%, the inflation rate is 25% (100 – 75 = 25). The inflation rate is subtracted from median observed power to correct for the inflation. The resulting replication index is not directly an estimate of power, except for the special case when power is 50% and the success rate is 100% When power is 50% and the success rate is 100%, median observed power increases to 75%. In this case, the inflation correction of 25% returns the actual power of 50%.
I emphasize this special case because 50% power is also a critical point at which point a rational bet would change from betting against replication (Replicability < 50%) to betting on a successful replication (Replicability > 50%). Thus, an R-Index of 50% suggests that a study or a set of studies produced a replicable result. With success rates close to 100%, this criterion implies that median observed power is 75%, which corresponds to a z-score of 2.63. Incidentally, a z-score of 2.6 also separated questionable results from more credible results in the powergraph analysis above.
It may seem problematic to use the R-Index even for a single study because observed power of a single study is strongly influenced by random factors and observed power is by definition above 50% for a significant result. However, The R-Index provides a correction for selection bias and a significant result implies a 100% success rate. Of course, it could also be an honestly reported result, but if the study was published in a field with evidence of selection bias, the R-Index provides a reasonable correction for publication bias. To achieve an R-Index above 50%, observed power has to be greater than 75%.
This criterion has been validated with social psychology studies in the reproducibilty project, where the R-Index predicted replication success with over 90% accuracy. This criterion also correctly predicted that the ego-depletion replication project would produce fewer than 50% successful replications, which it did, because the R-Index for the original study was way below 50% (F(1,90) = 4.64, p = .034, z = 2.12, OP = .56, R-Index = .12). If this information had been available during the planning of the RRR, researchers might have opted for a paradigm with a higher chance of a successful replication.
To identify paradigms with higher replicability, I computed the R-Index and TIVA (for articles with more than one study) for all 165 articles in the meta-analysis. For TIVA I used p < .10 as criterion for bias and for the R-Index I used .50 as the criterion. 37 articles (22%) passed this test. This implies that 128 (78%) showed signs of statistical bias and/or low replicability. Below I discuss the Top 10 articles with the highest R-Index to identify paradigms that may produce a reliable ego-depletion effect.
1. Robert D. Dvorak and Jeffrey S. Simons (PSPB, 2009) [ID = 142, R-Index > .99]
This article reported a single study with an unusually large sample size for ego-depletion studies. 180 participants were randomly assigned to a standard ego-depletion manipulation. In the control condition, participants watched an amusing video. In the depletion condition, participants watched the same video, but they were instructed to suppress all feelings and expressions. The dependent variable was persistence on a set of solvable and unsolvable anagrams. The t-value in this study suggests strong evidence for an ego-depletion effect, t(178) = 5.91. The large sample size contributes to this, but the effect size is also large, d = .88.
Interestingly, this study is an exact replication of Study 3 in the seminal ego-depletion article by Baumeister et al. (1998), which obtained a significant effect with just 30 participants and a strong effect size of d = .77, t(28) = 2.12.
The same effect was also reported in a study with 132 smokers (Heckman, Ditre, & Brandon, 2012). Smokers who were not allowed to smoke persisted longer on a figure tracing task when they could watch an emotional video normally than when they had to suppress emotional responses, t(64) = 3.15, d = .78. The depletion effect was weaker when smokers were allowed to smoke between the video and the figure tracing task. The interaction effect was significant, F(1, 128) = 7.18.
In sum, a set of studies suggests that emotion suppression influences persistence on a subsequent task. The existing evidence suggests that this is a rather strong effect that can be replicated across laboratories.
2. Megan Oaten, Kipling D. William, Andrew Jones, & Lisa Zadro (J Soc Clinical Psy, 2008) [ID = 118, R-Index > .99]
This article reports two studies that manipulated social exclusion (ostracism) under the assumption that social exclusion is ego-depleting. The dependent variable was consumption of an unhealthy food in Study 1 and drinking a healthy, but unpleasant drink in Study 2. Both studies showed extremely strong effects of ego-depletion (Study 1: d = 2.69, t(71) = 11.48; Study 2: d = 1.48, t(72) = 6.37.
One concern about these unusually strong effects is the transformation of the dependent variable. The authors report that they first ranked the data and then assigned z-scores corresponding to the estimated cumulative proportion. This is an unusual procedure and it is difficult to say whether this procedure inadvertently inflated the effect size of ego-depletion.
Interestingly, one other article used social exclusion as an ego-depletion manipulation (Baumeister et al., 2005). This article reported six studies and TIVA showed evidence of selection bias, Var(z) = 0.15, p = .02. Thus, the reported effect sizes in this article are likely to be inflated. The first two studies used consumption of an unpleasant tasting drink and eating cookies, respectively, as dependent variables. The reported effect sizes were weaker than in the article by Oaten et al. (d = 1.00, d = .90).
In conclusion, there is some evidence that participants avoid displeasure and seek pleasure after social rejection. A replication study with a sufficient sample size may replicate this result with a weaker effect size. However, even if this effect exists it is not clear that the effect is mediated by ego-depletion.
3. Kathleen D. Vohs & Ronald J. Farber (Journal of Consumer Research) [ID = 29, R-Index > .99]
This article examined the effect of several ego-depletion manipulations on purchasing behavior. Study 1 found a weaker effect, t(33) = 2.83, than Studies 2 and 3, t(63) = 5.26, t(33) = 5.52, respectively. One possible explanation is that the latter studies used actual purchasing behavior. Study 2 used the White Bear paradigm and Study 2 used amplification of emotion expressions as ego-depletion manipulations. Although statistically robust, purchasing behavior does not seem to be the best indicator of ego-depletion. Thus, replication efforts may focus on other dependent variables that measure ego-depletion more directly.
4. Kathleen D. Vohs, Roy F. Baumeister, & Brandon J. Schmeichel (JESP, 2012/2013) [ID = 49, R-Index = .96]
This article was first published in 2012, but the results for Study 1 were misreported and a corrected version was published in 2013. The article presents two studies with a 2 x 3 between-subject design. Study 1 had n = 13 participants per cell and Study 2 had n = 35 participants per cell. Both studies showed an interaction between ego-depletion manipulations and manipulations of self-control beliefs. The dependent variables in both studies were the Cognitive Estimation Test and a delay of gratification task. Results were similar for both dependent measures. I focus on the CET because it provides a more direct test of ego-depletion; that is, the draining of resources.
In the condition with limited-will-power beliefs of Study 1, the standard ego-depletion effect that compares depleted participants to a control condition was a decreased by about 6 points from about 30 to 24 points (no exact means or standard deviations, or t-values for this contrast are provided). The unlimited will-power condition shows a smaller decrease by 2 points (31 vs. 29). Study 2 replicates this pattern. In the limited-will-power condition, CET scores decreased again by 6 points from 32 to 26 and in the unlimited-will-power condition CET scores decreased by about 2 points from about 31 to 29 points. This interaction effect would again suggest that the standard depletion effect can be reduced by manipulating participants’ beliefs.
One interesting aspect of the study was the demonstration that ego-depletion effects increase with the number of ego-depleting tasks. Performance on the CET decreased further when participants completed 4 vs. 2 or 3 vs. 1 depleting task. Thus, given the uncertainty about the existence of ego-depletion, it would make sense to start with a strong manipulation that compares a control condition with a condition with multiple ego-depleting tasks.
One concern about this article is the use of the CET as a measure of ego-depletion. The task was used in only one other study by Schmeichel, Vohs, and Baumeister (2003) with a small sample of N = 37 participants. The authors reported a just significant effect on the CET, t(35) = 2.18. However, Vohs et al. (2013) increased the number of items from 8 to 20, which makes the measure more reliable and sensitive to experimental manipulations.
Another limitation of this study is that there was no control condition without manipulation of beliefs. It is possible that the depletion effect in this study was amplified by the limited-will-power manipulation. Thus, a simple replication of this study would not provide clear evidence for ego-depletion. However, it would be interesting to do a replication study that examines the effect of ego-depletion on the CET without manipulation of beliefs.
In sum, this study could provide the basis for a successful demonstration of ego-depletion by comparing effects on the CET for a control condition versus a condition with multiple ego-depletion tasks.
5. Veronika Job, Carol S. Dweck, and Gregory M. Walton (Psy Science, 2010) [ID = 191, R-Index = 94]
The article by Job et al. (2010) is noteworthy for several reasons. First, the article presented three close replications of the same effect with high t-values, ts = 3.88, 8.47, 2.62. Based on these results, one would expect that other researchers can replicate the results. Second, the effect is an interaction between a depletion manipulation and a subtle manipulation of theories about the effect of working on an effortful task. Hidden among other questionnaires, participants received either items that suggested depletion (“After a strenuous mental activity your energy is depleted and you must rest to get it refueled again” or items that suggested energy is unlimited (“Your mental stamina fuels itself; even after strenuous mental exertion you can continue doing more of it”). The pattern of the interaction effect showed that only participants who received the depletion items showed the depletion effect. Participants who received the unlimited energy items showed no significant difference in Stroop performance. Taken at face value, this finding would challenge depletion theory, which assumes that depletion is an involuntary response to exerting effort.
However, the study also raises questions because the authors used an unconventional statistical method to analyze their data. Data were analyzed with a multi-level model that modeled errors as a function of factors that vary within participants over time and factors that vary between participants, including the experimental manipulations. In an email exchange, the lead author confirmed that the model did not include random factors for between-subject variance. A statistician assured the lead author that this was acceptable. However, a simple computation of the standard deviation around mean accuracy levels would show that this variance is not zero. Thus, the model artificially inflated the evidence for an effect by treating between-subject variance as within-subject variance. In a betwee-subject analysis, the small differences in error rates (about 5 percentage points) are unlikely to be significant.
In sum, it is doubtful that a replication study would replicate the interaction between depletion manipulations and the implicit theory manipulation reported in Job et al. (2010) in an appropriate between-subject analysis. Even if this result would replicate, it would not support the theory that ego-depletion is a limited resource that is depleted after a short effortful task because the effect can be undone with a simple manipulations of beliefs in unlimited energy.
6. Roland Imhoff, Alexander F. Schmidt, & Friederike Gerstenberg (Journal of Personality, 2014) [ID = 146, R-Index = .90]
Study 1 reports results a standard ego-depletion paradigm with a relatively larger sample (N = 123). The ego-depletion manipulation was a Stroop task with 180 trials. The dependent variable was consumption of chocolates (M&M). The study reported a large effect, d = .72, and strong evidence for an ego-depletion effect, t(127) = 4.07. The strong evidence is in part justified by the large sample size, but the standardized effect size seems a bit large for a difference of 2g in consumption, whereas the standard deviation of consumption appears a bit small (3g). A similar study with M&M consumption as dependent variable found a 2g difference in the opposite direction with a much larger standard deviation of 16g and no significant effect, t(48) = -0.44.
The second study produced results in line with other ego-depletion studies and did not contribute to the high R-Index of the article, t(101) = 2.59. The third study was a correlational study with examined correlates of a trait measure of ego-depletion. Even if this correlation is replicable, it does not support the fundamental assumption of ego-depletion theory of situational effects of effort on subsequent effort. In sum, it is unlikely that Study 1 is replicable and that strong results are due to misreported standard deviations.
7. Hugo J.E.M. Alberts, Carolien Martijn, & Nanne K. de Vries (JESP, 2011) [ID = 56, R-Index = .86]
This article reports the results of a single study that crossed an ego-depletion manipulation with a self-awareness priming manipulation (2 x 2 with n = 20 per cell). The dependent variable was persistence in a hand-grip task. Like many other handgrip studies, this study assessed handgrip persistence before and after the manipulation, which increases the statistical power to detect depletion effects.
The study found weak evidence for an ego-depletion effect, but relatively strong evidence for an interaction effect, F(1,71) = 13.00. The conditions without priming showed a weak ego depletion effect (6s difference, d = .25). The strong interaction effect was due to the priming conditions, where depleted participants showed an increase in persistence by 10s and participants in the control condition showed a decrease in performance by 15s. Even if this is a replicable finding, it does not support the ego-depletion effect. The weak evidence for ego depletion with the handgrip task is consistent with a meta-analysis of handgrip studies (Schimmack, 2015).
In short, although this study produced an R-Index above .50, closer inspection of the results shows no strong evidence for ego-depletion.
8. James M. Tyler (Human Communications Research, 2008) [ID = 131, R-Index = .82]
This article reports three studies that show depletion effects after sharing intimate information with strangers. In the depletion condition, participants were asked to answer 10 private questions in a staged video session that suggested several other people were listening. This manipulation had strong effects on persistence in an anagram task (Study 1, d = 1.6, F(2,45) = 16.73) and the hand-grip task (Study 2: d = 1.35, F(2,40) = 11.09). Study 3 reversed tasks and showed that the crossing-E task influenced identification of complex non-verbal cues, but not simple non-verbal cues, F(1,24) = 13.44. The effect of the depletion manipulation on complex cues was very large, d = 1.93. Study 4 crossed the social manipulation of depletion from Studies 1 and 2 with the White Bear suppression manipulation and used identification of non-verbal cues as the dependent variable. The study showed strong evidence for an interaction effect, F(1,52) = 19.41. The pattern of this interaction is surprising, because the White Bear suppression task showed no significant effect after not sharing intimate details, t(28) = 1.27, d = .46. In contrast, the crossing-E task had produced a very strong effect in Study 3, d = 1.93. The interaction was driven by a strong effect of the White Bear manipulation after sharing intimate details, t(28) = 4.62, d = 1.69.
Even though the statistical results suggest that these results are highly replicable, the small sample sizes and very large effect sizes raise some concerns about replicability. The large effects cannot be attributed to the ego-depletion tasks or measures that have been used in many other studies that produced much weaker effect. Thus, the only theoretical explanation for these large effect sizes would be that ego depletion has particularly strong effects on social processes. Even if these effects could be replicated, it is not clear that ego-depletion is the mediating mechanism. Especially the complex manipulation in the first two studies allow for multiple causal pathways. It may also be difficult to recreate this manipulation and a failure to replicate the results could be attribute to problems with reproducibility. Thus, a replication of this study is unlikely to advance understanding of ego-depletion without first establishing that ego-depletion exists.
9. Brandon J. Schmeichel, Heath A. Demaree, Jennifer L. Robinson, & Jie Pu (Social Cognition, 2006) [ID = 52, R-Index = .80]
This article reported one study with an emotion regulation task. Participants in the depletion condition were instructed to exaggerated emotional responses to a disgusting film clip. The study used two task to measure ego-depletion. One task required generation of words; the other task required generation of figures. The article reports strong evidence in an ANOVA with both dependent variables, F(1,46) = 11.99. Separate analyses of the means show a stronger effect for the figural task, d = .98, than for the verbal task, d = .50.
The main concern with this study is that the fluency measures were never used in any other study. If a replication study fails, one could argue that the task is not a valid measure of ego-depletion. However, the study shows the advantage of using multiple measures to increase statistical power (Schimmack, 2012).
10. Mark Muraven, Marylene Gagne, and Heather Rosman (JESP, 2008) [ID = 15, R-Index = .78]
Study 1 reports the results of a 2 x 2 design with N = 30 participants (~ 7.5 participants per condition). It crossed an ego-depletion manipulation (resist eating chocolate cookies vs. radishes) with a self-affirmation manipulation. The dependent variable was the number of errors in a vigilance task (respond to a 4 after a 6). The results section shows some inconsistencies. The 2 x 2 ANOVA shows strong evidence for an interaction, F(1,28) = 10.60, but the planned contrast that matches the pattern of means, shows a just significant effect, F(1,28) = 5.18. Neither of these statistics is consistent with the reported means and standard deviations, where the depleted not affirmed group has twice the number of errors (M = 12.25, SD = 1.63) than the depleted group with affirmation (M = 5.40, SD = 1.34). These results would imply a standardized effect size of d = 4.59.
Study 2 did not manipulate ego-depletion and reported a more reasonable, but also less impressive result for the self-affirmation manipulation, F(2,63) = 4.67.
Study 3 crossed an ego-depletion manipulation with a pressure manipulation. The ego-depletion task was a computerized ego-depletion task where participants in the depletion condition had to type a paragraph without copying the letter E or spaces. This is more difficult than just copying a paragraph. The pressure manipulation were constant reminders to avoid making errors and to be as fast as possible. The sample size was N = 96 (n = 24 per cell). The dependent variable was the vigilance task from Study 1. The evidence for a depletion effect was strong, F(1, 92) = 10.72 (z = 3.17). However, the effect was qualified by the pressure manipulation, F(1,92) = 6.72. There was a strong depletion effect in the pressure condition, d = .78, t(46) = 2.63, but there was no evidence for a depletion effect in the no-pressure condition, d = -.23, t(46) = 0.78.
The standard deviations in Study 3 that used the same dependent variable were considerable wider than the standard deviations in Study 1, which explains the larger standardized effect sizes in Study 1. With the standard deviations of Study 3, Study 1 would not have
DISCUSSION AND FUTURE DIRECTIONS
The original ego-depletion article published in 1998 has spawned a large literature with over 150 articles, more than 400 studies, and a total number of over 30,000 participants. There have been numerous theoretical articles and meta-analyses of this literature. Unfortunately, the empirical results reported in this literature are not credible because there is strong evidence that reported results are biased. The bias makes it difficult to predict which effects are replicable. The main conclusion that can be drawn from this shaky mountain of evidence is that ego-depletion researchers have to change the way they conduct and report their findings.
Importantly, this conclusion is in stark disagreement with Baumeister’s recommendations. In a forthcoming article, he suggests that “the field has done very well with the methods and standards it has developed over recent decades,” (p. 2), and he proposes that “we should continue with business as usual” (p. 1).
Baumeister then explicitly defends the practice of selectively publishing studies that produced significant results without reporting failures to demonstrate the effect in conceptually similar studies.
Critics of the practice of running a series of small studies seem to think researchers are simply conducting multiple tests of the same hypothesis, and so they argue that it would be better to conduct one large test. Perhaps they have a point: One big study could be arguably better than a series of small ones. But they also miss the crucial point that the series of small studies is typically designed to elaborate the idea in different directions, such as by identifying boundary conditions, mediators, moderators, and extensions. The typical Study 4 is not simply another test of the same hypothesis as in Studies 1–3. Rather, each one is different. And yes, I suspect the published report may leave out a few other studies that failed. Again, though, those studies’ purpose was not primarily to provide yet another test of the same hypothesis. Instead, they sought to test another variation, such as a different manipulation, or a different possible boundary condition, or a different mediator. Indeed, often the idea that motivated Study 1 has changed so much by the time Study 5 is run that it is scarcely recognizable. (p. 2)
Baumeister overlooks that a program of research that tests novel hypothesis with new experimental procedures in small samples is most likely to produce a non-significant result. When these results are not reported, only reporting significant results does not mean that these studies successfully demonstrated an effect or elucidated moderating factors. The result of this program of research is a complicated pattern of results that is shaped by random error, selection bias, and weak true effects that are difficult to replicate (Figure 1).
Baumeister makes the logical mistake to assume that the type-I error rate is reset when a study is not a direct replication and that the type-I error only increases for exact replications. For example, it is obvious that we should not believe that eating green jelly beans decreases the risk of cancer, if 1 out of 20 studies with green jelly beans produced a significant result. With a 5% error rate, we would expect one significant result in 20 attempts by chance alone. Importantly, this does not change if green jelly beans showed an effect, but red, orange, purple, blue, ….. jelly beans did not show an effect. With each study, the risk of a false positive result increases and if 1 out of 20 studies produced a significant result, the success rate is not higher than one would expect by chance alone. It is therefore important to report all results and to report only the one green-jelly bean study with a significant result distorts the scientific evidence.
Baumeister overlooks the multiple comparison problem when he claims that “a series of small studies can build and refine a hypothesis much more thoroughly than a single large study”
As the meta-analysis, a series of over 400 small studies with selection bias tells us very little about ego-depletion and it remains unclear under which conditions the effect can be reliably demonstrated. To his credit, Baumeister is humble enough to acknowledge that his sanguine view of social psychological research is biased.
In my humble and biased view, social psychology has actually done quite well. (p. 2)
Baumeister remembers fondly the days when he learned how to conduct social psychological experiments. “When I was in graduate school in the 1970s, n=10 was the norm, and people who went to n=20 were suspected of relying on flimsy effects and wasting precious research participants.” A simple power analysis with these sample sizes shows that a study with n = 10 per cell (N = 20) has a sensitivity to detect effect sizes of d = 1.32 with 80% probability. Even the biased effect size estimate for ego-depletion studies was only half of this effect size. Thus, a sample size of n = 10 is ridiculously low. What about a sample size of n = 20? It still requires an effect size of d = .91 to have an 80% chance to produce a significant result. Maybe Roy Baumeister might think that it is sufficient to aim for 50% success rate and to drop the other 50%. An effect size of d = .64 gives researchers a 50% chance to get a significant result with N = 40. But the meta-analysis shows that the bias-correct effect size is less than this. So, even n = 20 is not sufficient to demonstrate ego-depletion effects. Does this mean the effects are too flimsy to study?
Inadvertently, Baumeister seems to dismiss ego-depletion effects as irrelevant, if it would require large sample sizes to demonstrate ego-depletion.
Large samples increase statistical power. Therefore, if social psychology changes to insist on large samples, many weak effects will be significant that would have failed with the traditional and smaller samples. Some of these will be important effects that only became apparent with larger samples because of the constraints on experiments. Other findings will however make a host of weak effects significant, so more minor and trivial effects will enter into the body of knowledge.
If ego-depletion effects are not really strong, but only inflated by selection bias, and the real effects are much weaker, they may be minor and trivial effects that have little practical significance for the understanding of self-control in real life.
Baumeister then comes to the most controversial claim of his article that has produced a vehement response on social media. He claims that a special skill called flair is needed to produce significant results with small samples.
Getting a significant result with n = 10 often required having an intuitive flair for how to set up the most conducive situation and produce a highly impactful procedure.
The need for flair also explains why some researchers fail to replicate original studies by researchers with flair.
But in that process, we have created a career niche for bad experimenters. This is an underappreciated fact about the current push for publishing failed replications. I submit that some experimenters are incompetent. In the past their careers would have stalled and failed. But today, a broadly incompetent experimenter can amass a series of impressive publications simply by failing to replicate other work and thereby publishing a series of papers that will achieve little beyond undermining our field’s ability to claim that it has accomplished anything.
Baumeister even noticed individual differences in flair among his graduate and post-doctoral students. The measure of flair was whether students were able to present significant results to him.
Having mentored several dozen budding researchers as graduate students and postdocs, I have seen ample evidence that people’s ability to achieve success in social psychology varies. My laboratory has been working on self-regulation and ego depletion for a couple decades. Most of my advisees have been able to produce such effects, though not always on the first try. A few of them have not been able to replicate the basic effect after several tries. These failures are not evenly distributed across the group. Rather, some people simply seem to lack whatever skills and talents are needed. Their failures do not mean that the theory is wrong.
The first author of the glucose paper was a victim of a doctoral advisor who believed that one could demonstrate a correlation between blood glucose levels and behavior with samples of 20 or less participants. He found a way to produce these results in a way that produced statistical evidence of bias, but this effort was wasted on a false theory and a program of research that could not produce evidence for or against the theory because sample sizes were too small to show the effect even if the theory were correct. Furthermore, it is not clear how many graduate students left Baumeister’s lab thinking that they were failures because they lacked research skills when they only applied the scientific method correctly?
Baumeister does not elaborate further what distinguishes researchers with flair from those without flair. To better understand flair, I examined the seminal ego-depletion study. In this study, 67 participants were assigned to three conditions (n = 22 per cell). The study was advertised as a study on taste perception. Experimenters baked chocolate cookies in a laboratory room and the room smelled of freshly baked chocolate cookies. Participants were seated at a table with a bowl of freshly baked cookies and a bowl with red and white radishes. Participants were instructed to taste either radishes or chocolate cookies. They were then told that they had to wait at least 15 minutes to allow the sensory memory of the food to fade. During this time, they were asked to work on an unrelated task. The task was a figure tracing puzzle with two unsolvable puzzles. Participants were told that they can take as much time and as many trials as you want and that they will not be judged on the number of trials or the time they take, and that they will be judged on whether or not they finish the task. However, if they wished to stop without finishing, they could ring a bell to notify the experimenter. The time spent on this task was used as the dependent variable. The study showed a strong effect of the manipulation. Participants who had to taste radishes rang the bell 10 minutes earlier than participants who got to taste the chocolate cookies, t(44) = 6.03, d = 1.80, and 12 minutes earlier than participants in a control condition without the tasting part of the experiment, t(44) = 6.88, d = 2.04. The ego-depletion effect in this study is gigantic. Thus, flair might be important to create conditions that can produce strong effects, but once a researcher with flair has created such an experiment, others should be able to replicate it. It doesn’t take flair to bake chocolate cookies, put a plate of radishes on a table, and to instruct participants how a figure tracing task works and to ring a bell when they no longer want to work on the task. In fact, Baumeister et al. (1998) proudly reported that even high school students were able to replicate the study in a science project.
As this article went to press, we were notified that this experiment had been independently replicated by Timothy J. Howe, of Cole Junior High School in East Greenwich, Rhode Island, for his science fair project. His results conformed almost exactly to ours, with the exception that mean persistence in the chocolate condition was slightly (but not significantly) higher than in the control condition. These converging results strengthen confidence in the present findings.
If ego-depletion effects can be replicated in a school project, it undermines the idea that successful results require special skills. Moreover, the meta-analysis shows that flair is little more than selective publishing of significant results, a conclusion that is confirmed by Baumeister’s response to my bias analyses. “you may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication).
In conclusion, future researchers interested in self-regulation have a choice. They can believe in ego-depletion and ignore the statistical evidence of selection bias, failed replications, and admissions of suppressed evidence, and conduct further studies with existing paradigms and sample sizes and see what they get. Alternatively, they may go to the other extreme and dismiss the entirely literature.
“If all the field’s prior work is misleading, underpowered, or even fraudulent, there is no need to pay attention to it.” (Baumeister, p. 4).
This meta-analysis offers a third possibility by trying to find replicable results that can provide the basis for the planning of future studies that provide better tests of ego-depletion theory. I do not suggest to directly replicate any past study. Rather, I think future research should aim for a strong demonstration of ego-depletion. To achieve this goal, future studies should maximize statistical power in four ways.
First, use a strong experimental manipulation by comparing a control condition with a combination of multiple ego-depletion paradigms to maximize the standardized effect size.
Second, the study should use multiple, reliable, and valid measures of ego-depletion to minimize the influence of random and systematic measurement error in the dependent variable.
Third, the study should use a within-subject design or at least a pre-post design to control for individual differences in performance on the ego-depletion tasks to further reduce error variance.
Fourth, the study should have a sufficient sample size to make a non-significant result theoretically important. I suggest planning for a standard error of .10 standard deviations. As a result, any effect size greater than d = .20 will be significant, and a non-significant result if consistent with the null-hypothesis that the effect size is less than d = .20.
The next replicability report will show which path ego-depletion researcher have taken. Even if they follow Baumeister’s suggestion to continue with business as usual, they can no longer claim that they were unaware of the consequences of going down this path.
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
More blogs on replicability.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}