Richard D. Morey, Rink Hoekstra, Jeffrey N. Rouder, Michael D. Lee, and
Eric-Jan Wagenmakers (2016), henceforce psycho-Baysians, have a clear goal. They want psychologists to change the way they analyze their data.
Although this goal motivates the flood of method articles by this group, the most direct attack on other statistical approaches is made in the article “The fallacy of placing confidence in confidence intervals.” In this article, the authors claim that everybody, including textbook writers in statistics, misunderstood Neyman’s classic article on interval estimation. What are the prior odds that after 80 years, a group of psychologists discover a fundamental flaw in the interpretation of confidence intervals (H1) versus a few psychologists are either unable or unwilling to understand Neyman’s article?
Underlying this quest for change in statistical practices lies the ultimate attribution error that Fisher’s p-values or Neyman-Pearsons significance testing with or without confidence intervals are responsible for the replication crisis in psychology (Wagenmakers et al., 2011).
This is an error because numerous articles have argued and demonstrated that questionable research practices undermine the credibility of the psychological literature. The unprincipled use of p-values (undisclosed multiple testing), also called p-hacking, means that many statistically significant results have inflated error rates and the long-run probabilities of false positives are not 5%, as stated in each article, but could be 100% (Rosenthal, 1979; Sterling, 1959; Simmons, Nelson, & Simonsohn, 2011).
You will not find a single article by Psycho-Bayesians that will acknowledge the contribution of unprincipled use of p-values to the replication crisis. The reason is that they want to use the replication crisis as a vehicle to sell Bayesian statistics.
It is hard to believe that classic statistics are fundamentally flawed and misunderstood because they are used in industry to produce SmartPhones and other technology that requires tight error control in mass production of technology. Nevertheless, this article claims that everybody misunderstood Neyman’s seminal article on confidence intervals.
The authors claim that Neyman wanted us to compute confidence intervals only before we collect data, but warned readers that confidence intervals provide no useful information after the data are collected.
Post-data assessments of probability have never been an advertised feature of CI theory. Neyman, for instance, said “Consider now the case when a sample…is already drawn and the [confidence interval] given…Can we say that in this particular case the probability of the true value of [the parameter] falling between [the limits] is equal to [X%]? The answer is obviously in the negative”
This is utter nonsense. Of course, Neyman was asking us to interpret confidence intervals after we collected data because we need a sample to compute confidence interval. It is hard to believe that this could have passed peer-review in a statistics journal and it is not clear who was qualified to review this paper for Psychonomic Bullshit Review.
The way the psycho-statisticians use Neyman’s quote is unscientific because they omit the context and the following statements. In fact, Neyman was arguing against Bayesian attempts of estimate probabilities that can be applied to a single event.
It is important to notice that for this conclusion to be true, it is not necessary that the problem of estimation should be the same in all the cases. For instance, during a period of time the statistician may deal with a thousand problems of estimation and in each the parameter M to be estimated and the probability law of the X’s may be different. As far as in each case the functions L and U are properly calculated and correspond to the same value of alpha, his steps (a), (b), and (c), though different in details of sampling and arithmetic, will have this in common—the probability of their resulting in a correct statement will be the same, alpha. Hence the frequency of actually correct statements will approach alpha. It will be noticed that in the above description the probability statements refer to the problems of estimation with which the statistician will be concerned in the future. In fact, I have repeatedly stated that the frequency of correct results tend to alpha.*
Consider now the case when a sample, S, is already drawn and the calculations have given, say, L = 1 and U = 2. Can we say that in this particular case the probability of the true value of M falling between 1 and 2 is equal to alpha? The answer is obviously in the negative.
The parameter M is an unknown constant and no probability statement concerning its value may be made, that is except for the hypothetical and trivial ones P{1 < M < 2}) = 1 if 1 < M < 2) or 0 if either M < 1 or 2 < M) , which we have decided not to consider.
The full quote makes it clear that Neyman is considering the problem of quantifying the probability that a population parameter is in a specific interval and dismisses it as trivial because it doesn’t solve the estimation problem. We don’t even need observe data and compute a confidence interval. The statement that a specific unknown number is between two other numbers (1 and 2) or not is either TRUE (P = 1) or FALSE (P = 0). To imply that this trivial observation leads to the conclusion that we cannot make post-data inferences based on confidence intervals is ridiculous.
Neyman continues.
The theoretical statistician [constructing a confidence interval] may be compared with the organizer of a game of chance in which the gambler has a certain range of possibilities to choose from while, whatever he actually chooses, the probability of his winning and thus the probability of the bank losing has permanently the same value, 1 – alpha. The choice of the gambler on what to bet, which is beyond the control of the bank, corresponds to the uncontrolled possibilities of M having this or that value. The case in which the bank wins the game corresponds to the correct statement of the actual value of M. In both cases the frequency of “ successes ” in a long series of future “ games ” is approximately known. On the other hand, if the owner of the bank, say, in the case of roulette, knows that in a particular game the ball has stopped at the sector No. 1, this information does not help him in any way to guess how the gamblers have betted. Similarly, once the boundaries of the interval are drawn and the values of L and U determined, the calculus of probability adopted here is helpless to provide answer to the question of what is the true value of M.
What Neyman was saying is that population parameters are unknowable and remain unknown even after researchers compute a confidence interval. Moreover, the construction of a confidence interval doesn’t allow us to quantify the probability that an unknown value is within the constructed interval. This probability remains unspecified. Nevertheless, we can use the property of the long-run success rate of the method to place confidence in the belief that the unknown parameter is within the interval. This is common sense. If we place bets in roulette or other random events, we rely on long-run frequencies of winnings to calculate our odds of winning in a specific game.
It is absurd to suggest that Neyman himself argued that confidence intervals provide no useful information after data are collected because the computation of a confidence interval requires a sample of data. That is, while the width of a confidence interval can be determined a priori before data collection (e.g. in precision planning and power calculations), the actual confidence interval can only be computed based on actual data because the sample statistic determines the location of the confidence interval.
Readers of this blog may face a dilemma. Why should they place confidence in another psycho-statistician? The probability that I am right is 1, if I am right and 0 if I am wrong, but this doesn’t help readers to adjust their beliefs in confidence intervals.
The good news is that they can use prior information. Neyman is widely regarded as one of the most influential figures in statistics. His methods are taught in hundreds of text books, and statistical software programs compute confidence intervals. Major advances in statistics have been new ways to compute confidence intervals for complex statistical problems (e.g., confidence intervals for standardized coefficients in structural equation models; MPLUS; Muthen & Muthen). What are the a priori chances that generations of statisticians misinterpreted Neyman and committed the fallacy of interpreting confidence intervals after data are obtained?
However, if readers need more evidence of psycho-statisticians deceptive practices, it is important to point out that they omitted Neyman’s criticism of their favored approach, namely Bayesian estimation.
The fallacy article gives the impression that Neyman’s (1936) approach to estimation is outdated and should be replaced with more modern, superior approaches like Bayesian credibility intervals. For example, they cite Jeffrey’s (1961) theory of probability, which gives the impression that Jeffrey’s work followed Neyman’s work. However, an accurate representation of Neyman’s work reveals that Jeffrey’s work preceded Neyman’s work and that Neyman discussed some of the problems with Jeffrey’s approach in great detail. Neyman’s critical article was even “communicated” by Jeffreys (these were different times where scientists had open conflict with honor and integrity and actually engaged in scientific debates).

Given that Jeffrey’s approach was published just one year before Neyman’s (1936) article, Neyman’s article probably also offers the first thorough assessment of Jeffrey’s approach. Neyman first gives a thorough account of Jeffrey’s approach (those were the days).

Neyman then offers his critique of Jeffrey’s approach.
It is known that, as far as we work with the conception of probability as adopted in
this paper, the above theoretically perfect solution may be applied in practice only
in quite exceptional cases, and this for two reasons.
Importantly, he does not challenge the theory. He only points out that the theory is not practical because it requires knowledge that is often not available. That is, to estimate the probability that an unknown parameter is within a specific interval, we need to make prior assumptions about unknown parameters. This is the problem that has plagued subjective Bayesians approaches.
Neyman then discusses Jeffrey’s approach to solving this problem. I am not claiming that I am a statistical expert to decide whether Neyman or Jeffrey’s are right. Even statisticians have been unable to resolve these issues and I believe the consensus is that Bayesian credibility intervals and Neyman’s confidence intervals are both mathematically viable approaches to interval estimation with different strengths and weaknesses.

I am only trying to point out to unassuming readers of the fallacy article that both approaches are as old as statistics and that the presentation of the issue in this article is biased and violates my personal, and probably idealistic, standards of scientific integrity. Using a selective quote by Neyman to dismiss confidence intervals and then to omit Neyman’s critic of Bayesian credibility intervals is deceptive and shows an unwillingness or inability to engage in open scientific examination of scientific arguments for and against different estimation methods.
It is sad and ironic that Wagenmakers’ efforts to convert psychologists into Bayesian statisticians is similar to Bem’s (2011) attempt to convert psychologists into believers in parapsychology; or at least in parapsychology as a respectable science. While Bem fudged data to show false empirical evidence, Wagenmakers is misrepresenting the way classic statistics works and ignoring the key problem of Bayesian statistics, namely that Bayesian inferences are contingent on prior assumptions that can be gamed to show what a researcher wants to show. Wagenmaker used this flexibility in Bayesian statistics to suggest that Bem (2011) presented weak evidence for extra-sensory perception. However, a rebuttle by Bem showed that Bayesian statistics also showed support for extra-sensory perception with different and more reasonable priors. Thus, Wagenmakers et al. (2011) were simply wrong to suggest that Bayesian methods would have prevented Bem from providing strong evidence for an incredible phenomenon.
The problem with Bem’s article is not the way he “analyzed” the data. The problem is that Bem violated basic principles of science that are required to draw valid statistical inferences from data. It would be a miracle if Bayesian methods that assume unbiased data could correct for data falsification. The problem with Bem’s data has been revealed using statistical tools for the detection of bias (Francis, 2012; Schimmack, 2012, 2015, 2118). There has been no rebuttal from Bem and he admits to the use of practices that invalidate the published p-values. So, the problem is not the use of p-values, confidence intervals, or Bayesian statistics. The problem is abuse of statistical methods. There are few cases of abuse of Bayesian methods simply because they are used rarely. However, Bayesian statistics can be gamed without data fudging by specifying convenient priors and failing to inform readers about the effect of priors on results (Gronau et al., 2017).
In conclusion, it is not a fallacy to interpret confidence intervals as a method for interval estimation of unknown parameter estimates. It would be a fallacy to cite Morey et al.’s article as a valid criticism of confidence intervals. This does not mean that Bayesian credibility intervals are bad or could not be better than confidence intervals. It only means that this article is so blatantly biased and dogmatic that it does not add to the understanding of Neyman’s or Jeffrey’s approach to interval estimation.
P.S. More discussion of the article can be found on Gelman’s blog.
Andrew Gelman himself comments:
My current favorite (hypothetical) example is an epidemiology study of some small effect where the point estimate of the odds ratio is 3.0 with a 95% conf interval of [1.1, 8.2]. As a 95% confidence interval, this is fine (assuming the underlying assumptions regarding sampling, causal identification, etc. are valid). But if you slap on a flat prior you get a Bayes 95% posterior interval of [1.1, 8.2] which will not in general make sense, because real-world odds ratios are much more likely to be near 1.1 than to be near 8.2. In a practical sense, the uniform prior is causing big problems by introducing the possibility of these high values that are not realistic.
I have to admit some Schadenfreude when I see one Bayesian attacking another Bayesian for the use of an ill-informed prior. While Bayesians are still fighting over the right priors, practical researchers may be better off to use statistical methods that do not require priors, like, hm, confidence intervals?
P.P.S. Science requires trust. At some point, we cannot check all assumptions. I trust Neyman, Cohen, and Muthen and Muthen’s confidence intervals in MPLUS.











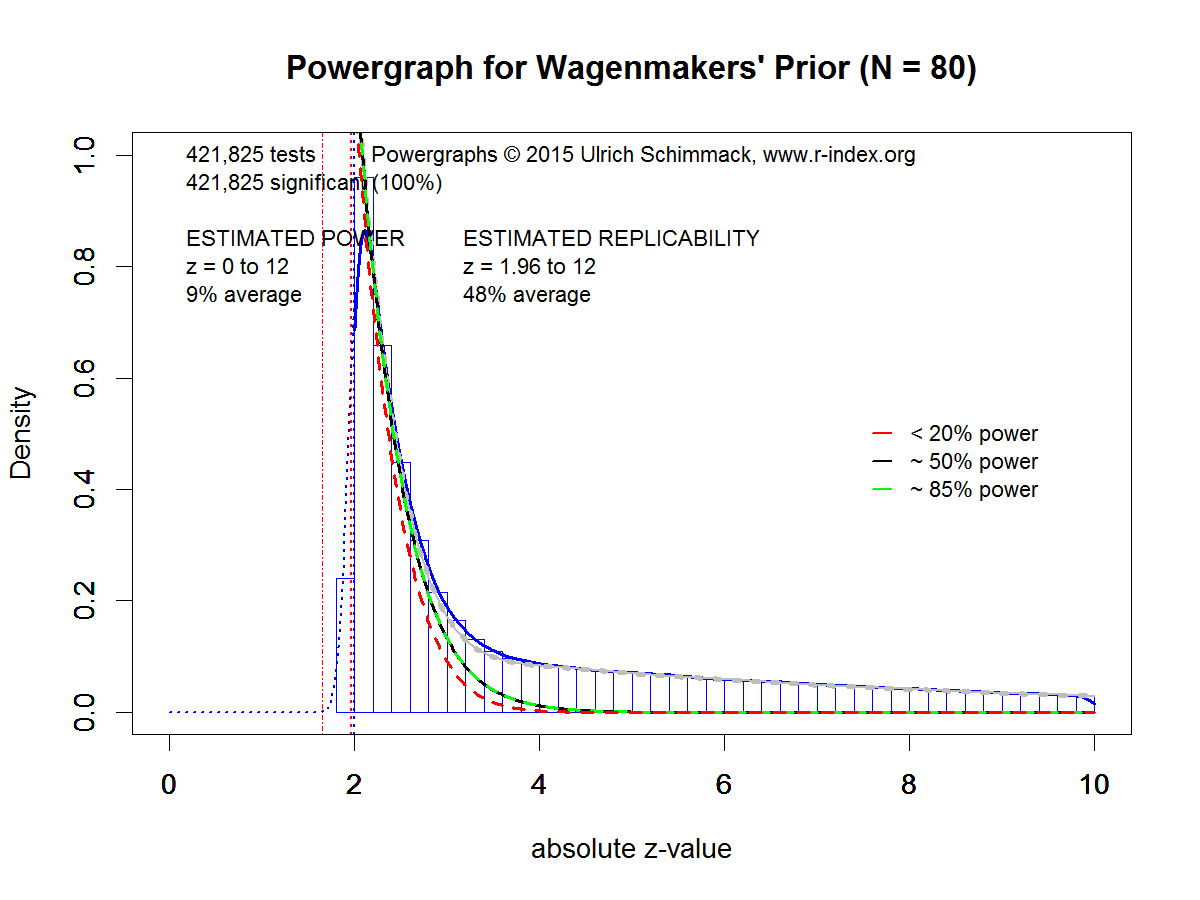


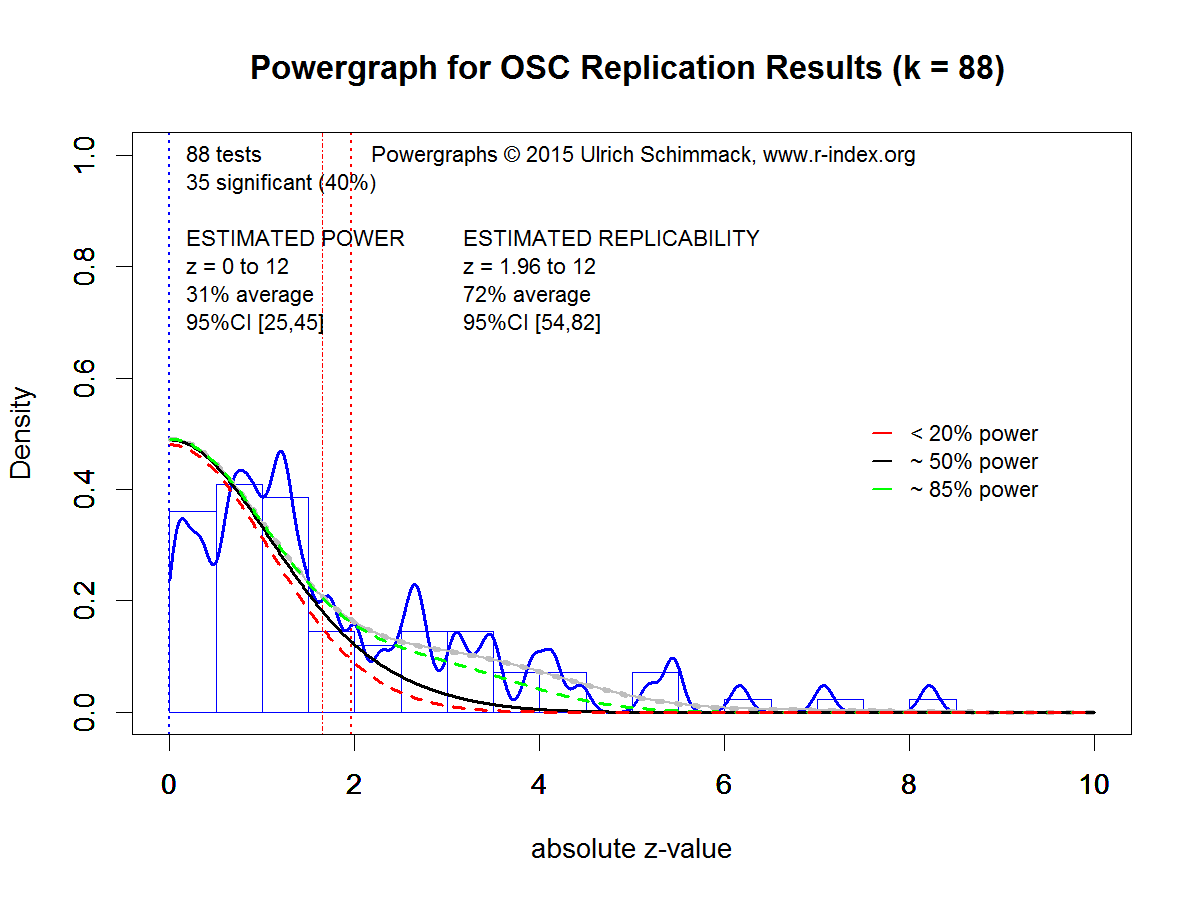 Figure 4 shows the powergraph for the 88 studies. As there is no publication bias, estimates of power and replicability are based on non-significant and significant results. Although the sample size is smaller, the estimate of power has a reasonably narrow confidence interval because the estimate includes non-significant results. Estimated power is only 31%. The 95% confidence interval includes the actual success rate of 40%, which shows that there is no evidence of publication bias.
Figure 4 shows the powergraph for the 88 studies. As there is no publication bias, estimates of power and replicability are based on non-significant and significant results. Although the sample size is smaller, the estimate of power has a reasonably narrow confidence interval because the estimate includes non-significant results. Estimated power is only 31%. The 95% confidence interval includes the actual success rate of 40%, which shows that there is no evidence of publication bias.