The scientific method is well-equipped to demonstrate regularities in nature as well as human behaviors. It works by repeating a scientific procedure (experiment or natural observation) many times. In the absence of a regular pattern, the empirical data will follow a random pattern. When a systematic pattern exists, the data will deviate from the pattern predicted by randomness. The deviation of an observed empirical result from a predicted random pattern is often quantified as a probability (p-value). The p-value itself is based on the ratio of the observed deviation from zero (effect size) and the amount of random error. As the signal-to-noise ratio increases, it becomes increasingly unlikely that the observed effect is simply a random event. As a result, it becomes more likely that an effect is present. The amount of noise in a set of observations can be reduced by repeating the scientific procedure many times. As the number of observations increases, noise decreases. For strong effects (large deviations from randomness), a relative small number of observations can be sufficient to produce extremely low p-values. However, for small effects it may require rather large samples to obtain a high signal-to-noise ratio that produces a very small p-value. This makes it difficult to test the null-hypothesis that there is no effect. The reason is that it is always possible to find an effect size that is so small that the noise in a study is too large to determine whether a small effect is present or whether there is really no effect at all; that is, the effect size is exactly zero (1 / infinity).
The problem that it is impossible to demonstrate scientifically that an effect is absent may explain why the scientific method has been unable to resolve conflicting views around controversial topics such as the existence of parapsychological phenomena or homeopathic medicine that lack a scientific explanation, but are believed by many to be real phenomena. The scientific method could show that these phenomena are real, if they were real, but the lack of evidence for these effects cannot rule out the possibility that a small effect may exist. In this post, I explore two statistical solutions to the problem of demonstrating that an effect is absent.
Neyman-Pearson Significance Testing (NPST)
The first solution is to follow Neyman-Pearsons’s orthodox significance test. NPST differs from the widely practiced null-hypothesis significance test (NHST) in that non-significant results are interpreted as evidence for the null-hypothesis. Thus, using the standard criterion of p = .05 as the criterion for significance, a p-value below .05 is used to reject the null-hypothesis and to infer that an effect is present. Importantly, if the p-value is greater than .05 the results are used to accept the null-hypothesis; that is, the hypothesis that there is no effect is true. As all statistical inferences, it is possible that the evidence is misleading and leads to the wrong conclusion. NPST distinguishes between two types or errors that are called type-I and type-II error. Type-I errors are errors when a p-value is below the criterion value (p < .05), but the null-hypothesis is actually true; that is there is no effect and the observed effect size was caused by a rare random event. Type-II errors are made when the null-hypothesis is accepted, but the null-hypothesis is false; there actually is an effect. The probability of making a type-II error depends on the size of the effect and the amount of noise in the data. Strong effects are unlikely to produce a type-II error even with noise data. Studies with very little noise are also unlikely to produce type-II errors because even small effects can still produce a high signal-to-noise ratio and significant results (p-values below the criterion value). Type-II error rates can be very high in studies with small effects and a large amount of noise. NPST makes it possible to quantify the probability of a type-II error for a given effect size. By investing a large amount of resources, it is possible to reduce noise to a level that is sufficient to have a very low type-II error probability for very small effect sizes. The only requirement for using NPST to provide evidence for the null-hypothesis is to determine a margin of error that is considered acceptable. For example, it may be acceptable to infer that a weight-loss-medication has no effect on weight if weight loss is less than 1 pound over a one month period. It is impossible to demonstrate that the medication has absolutely no effect, but it is possible to demonstrate with high probability that the effect is unlikely to be more than 1 pound.
Bayes-Factors
The main difference between Bayes-Factors and NPST is that NPST yields type-II error rates for an a priori effect size. In contrast, Bayes-Factors do not postulate a single effect size, but use an a priori distribution of effect sizes. Bayes-Factors are based on the probability that the observed effect sizes is based on a true effect size of zero relative to the probability that the observed effect size was based on a true effect size within a range of a priori effect sizes. Bayes-Factors are the ratio of the probabilities for the two hypotheses. It is arbitrary, which hypothesis is in the numerator and which hypothesis is in the denominator. When the null-hypothesis is placed in the numerator and the alternative hypothesis is placed in the denominator, Bayes-Factors (BF01) decrease towards zero the more the data suggest that an effect is present. In this way, Bayes-Factors behave very much like p-values. As the signal-to-noise ratio increases, p-values and BF01 decrease.
There are two practical problems in the use of Bayes-Factors. One problem is that Bayes-Factors depend on the specification of the a priori distribution of effect sizes. It is therefore important that results can never be interpreted as evidence for the null-hypothesis or against the null-hypothesis per se. A Bayes-Factor that favors the null-hypothesis in the comparison to one a priori distribution can favor the alternative hypothesis for another a priori distribution of effect sizes. This makes Bayes-Factors impractical for the purpose of demonstrating that an effect does not exist (e.g., a drug does not have positive treatment effects). The second problem is that Bayes-Factors only provide quantitative information about the two hypotheses. Without a clear criterion value, Bayes-Factors cannot be used to claim that an effect is present or absent.
Selecting a Criterion Value for Bayes-Factors
A number of criterion values seem plausible. NPST always leads to a decision depending on the criterion for p-values. An equivalent criterion value for Bayes-Factors would be a value of 1. Values greater than 1 favor the null-hypothesis over the alternative, whereas values less than 1 favor the alternative hypothesis. This criterion avoids inconclusive results. The disadvantage with this criterion is that Bayes-Factors close to 1 are very variable and prone to have high type-I and type-II error rates. To avoid this problem, it is possible to use more stringent criterion values. This reduces the type-I and type-II error rates, but it also increases the rate of inconclusive results in noisy studies. Bayes-Factors of 3 (a 3 to 1 ratio in favor of the null over an alternative hypothesis) are often used to suggest that the data favor one hypothesis over another, and Bayes-Factors of 10 or more are often considered strong support. One problem with these criterion values is that there have been no systematic studies of the type-I and type-II error rates for these criterion values. Moreover, there have been no systematic sensitivity studies; that is, the ability of studies to reach a criterion value for different signal-to-noise ratios.
Wagenmakers et al. (2011) argued that p-values can be misleading and that Bayes-Factors provide more meaningful results. To make their point, they investigated Bem’s (2011) controversial studies that seemed to demonstrate the ability to anticipate random events in the future (time –reversed causality). Using a significance criterion of p < .05 (one-tailed), 9 out of 10 studies showed evidence of an effect. For example, in Study 1, participants were able to predict the location of erotic pictures 54% of the time, even before a computer randomly generated the location of the picture. Using a more liberal type-I error rate of p < .10 (one-tailed), all 10 studies produced evidence for extrasensory perception.
Wagenmakers et al. (2011) re-examined the data with Bayes-Factors. They used a Bayes-Factor of 3 as the criterion value. Using this value, six tests were inconclusive, three provided substantial support for the null-hypothesis (the observed effect was just due to noise in the data) and only one test produced substantial support for ESP. The most important point here is that the authors interpreted their results using a Bayes-Factor of 3 as criterion. If they had used a Bayes-Factor of 10 as criterion, they would have concluded that all studies were inconclusive. If they had used a Bayes-Factor of 1 as criterion, they would have concluded that 6 studies favored the null-hypothesis and 4 studies favored the presence of an effect.
Matzke, Nieuwenhuis, van Rijn, Slagter, van der Molen, and Wagenmakers used Bayes-Factors in a design with optional stopping. They agreed to stop data-collection when the Bayes-Factor reached a criterion value of 10 in favor of either hypothesis. The implementation of a decision to stop data collection suggests that a Bayes-Factor of 10 was considered decisive. One reason for this stopping rule would be that it is extremely unlikely that a Bayes-Factor might swing to favoring the alternative hypothesis if more data were collected. By the same logic, a Bayes-Factor of 10 that favors the presence of an effect in an ESP effect would suggest that further data collection would be unnecessary because the evidence already shows rather strong evidence that an effect is present.
Tan, Dienes, Jansari, and Goh, (2014) report a Bayes-Factor of 11.67 and interpret as being “greater than 3 and strong evidence for the alternative over the null” (p. 19). Armstrong and Dienes (2013) report a Bayes-Factor of 0.87 and state that no conclusion follows from this finding because the Bayes-Factor is between 3 and 1/3. This statement implies that Bayes-Factors that meet the criterion value are conclusive.
In sum, a criterion-value of 3 has often been used to interpret empirical data and a criterion of 10 has been used as strong evidence in favor of an effect or in favor of the null-hypothesis.
Meta-Analysis of Multiple Studies
As sample sizes increase, noise decreases and the signal-to-noise ratio increases. Rather than increasing the sample size of a single study, it is also possible to conduct multiple smaller studies and to combine the evidence of studies in a meta-analysis. The effect is the same. A meta-analysis based on several original studies reduces random noise in the data and can produce higher signal-to-noise ratios when an effect is present. On the flip side, a low signal-to-noise ratio in a meta-analysis implies that the signal is very weak and that the true effect size is close to zero. As the evidence in a meta-analysis is based on the aggregation of several smaller studies, the results should be consistent. That is, the effect size in the smaller studies and the meta-analysis is the same. The only difference is that aggregation of studies reduces noise, which increases the signal-to-noise ratio. A meta-analysis therefore can highlight the problem of interpreting a low signal-to-noise ratio (BF10 < 1, p > .05) in small studies as evidence for the null-hypothesis. In NPST this result would be flagged as not trustworthy because the type-II error probability is high. For example, a non-significant result with a type-II error of 80% (20% power) is not particularly interesting and nobody would want to accept the null-hypothesis with such a high error probability. Holding the effect size constant, the type-II error probability decreases as the number of studies in a meta-analysis increases and it becomes increasingly more probable that the true effect size is below the value that was considered necessary to demonstrate an effect. Similarly, Bayes-Factors can be misleading in small samples and they become more conclusive as more information becomes available.
A simple demonstration of the influence of sample size on Bayes-Factors comes from Rouder and Morey (2011). The authors point out that it is not possible to combine Bayes-Factors by multiplying Bayes-Factors of individual studies. To address this problem, they created a new method to combine Bayes-Factors. This Bayesian meta-analysis is implemented in the Bayes-Factor r-package. Rouder and Morey (2011) applied their method to a subset of Bem’s data. However, they did not use it to examine the combined Bayes-Factor for the 10 studies that Wagenmakers et al. (2011) examined individually. I submitted the t-values and sample sizes of all 10 studies to a Bayesian meta-analysis and obtained a strong Bayes-Factor in favor of an effect, BF10 = 16e7, that is, 16 million to 1 in favor of ESP. Thus, a meta-analysis of all 10 studies strongly suggests that Bem’s data are not random.
Another way to meta-analyze Bem’s 10 studies is to compute a Bayes-Factor based on the finding that 9 out of 10 studies produced a significant result. The p-value for this outcome under the null-hypothesis is extremely small; 1.86e-11, that is p < .00000000002. It is also possible to compute a Bayes-Factor for the binomial probability of 9 out of 10 successes with a probability of 5% to have a success under the null-hypothesis. The alternative hypothesis can be specified in several ways, but one common option is to use a uniform distribution from 0 to 1 (beta(1,1). This distribution allows for the power of a study to range anywhere from 0 to 1 and makes no a priori assumptions about the true power of Bem’s studies. The Bayes-Factor strongly favors the presence of an effect, BF10 = 20e9. In sum, a meta-analysis of Bem’s 10 studies strongly supports the presence of an effect and rejects the null-hypothesis.
The meta-analytic results raise concerns about the validity of Wagenmakers et al.’s (2011) claim that Bem presented weak evidence and that p-values misleading information. Instead, Wagenmakers et al.’s Bayes-Factors are misleading and fail to detect an effect that is clearly present in the data.
The Devil is in the Priors: What is the Alternative Hypothesis in the Default Bayesian t-test?
Wagenmakers et al. (2011) computed Bayes-Factors using the default Bayesian t-test. The default Bayesian t-test uses a Cauchy distribution centered over zero as the alternative hypothesis. The Cauchy distribution has a scaling factor. Wagenmakers et al. (2011) used a default scaling factor of 1. Since then, the default scaling parameter has changed to .707.Figure 1 illustrates Cauchi distributions with scaling factors .2, .5, .707, and 1.
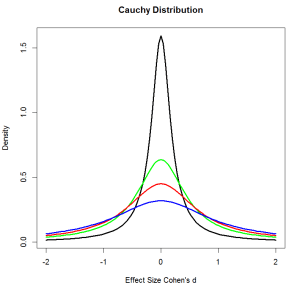
The black line shows the Cauchy distribution with a scaling factor of d = .2. A scaling factor of d = .2 implies that 50% of the density of the distribution is in the interval between d = -.2 and d = .2. As the Cauchy-distribution is centered over 0, this specification also implies that the null-hypothesis is considered much more likely than many other effect sizes, but it gives equal weight to effect sizes below and above an absolute value of d = .2. As the scaling factor increases, the distribution gets wider. With a scaling factor of 1, 50% of the density distribution is within the range from -1 to 1 and 50% covers effect sizes greater than 1. The choice of the scaling parameter has predictable consequences on the Bayes-Factor. As long as the true effect size is more extreme than the scaling parameter, Bayes-Factors will favor the alternative hypothesis and Bayes-Factors will increase towards infinity as sampling error decreases. However, for true effect sizes that are below the scaling parameter, Bayes-Factors may initially favor the null-hypothesis because the alternative hypothesis includes effect sizes that are more extreme than the alternative hypothesis. As sample sizes increase, the Bayes-Factor will change from favoring the null-hypothesis to favoring the alternative hypothesis. This can explain why Wagenmakers et al. (2011) found no support for ESP when Bem’s studies were examined individually, but a meta-analysis of all studies shows strong evidence in favor of an effect.
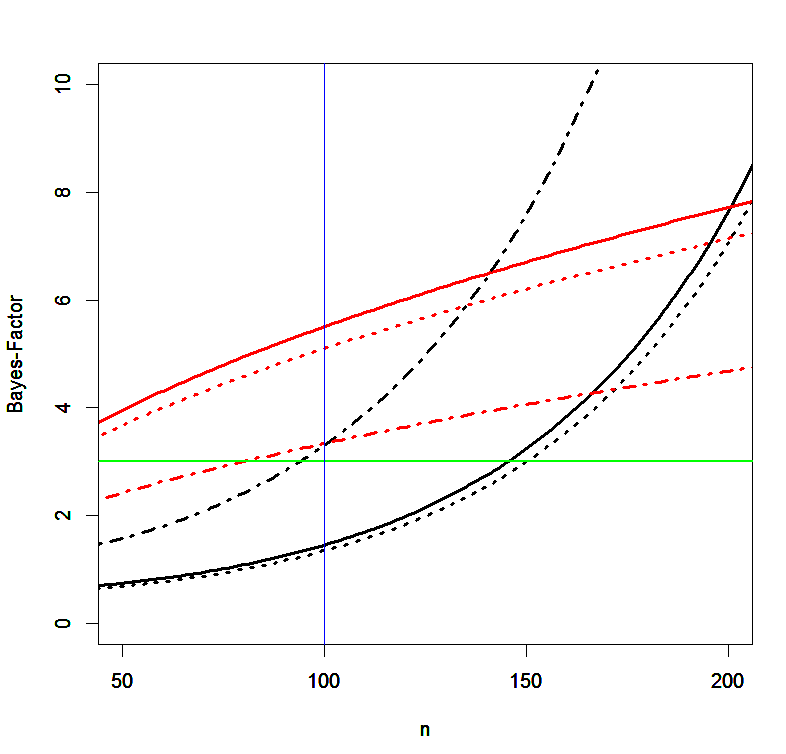
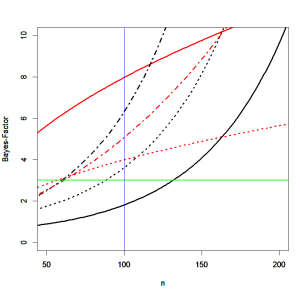
The effect of the scaling parameter on Bayes-Factors is illustrated in the following Figure.

The straight lines show Bayes-Factors (y-axis) as a function of sample size for a scaling parameter of 1. The black line shows Bayes-Factors favoring an effect of d = .2 when the effect size is actually d = .2 (BF10) and the red line shows Bayes-Factor favoring the null-hypothesis when the effect size is actually 0. The green line implies a criterion value of 3 to suggest “substantial” support for either hypothesis (Wagenmakers et al., 2011). The figure shows that Bem’s sample sizes of 50 to 150 participants could never produce substantial evidence for an effect when the observed effect size is d = .2. In contrast, an effect size of 0 would produce provide substantial support for the null-hypothesis. Of course, actual effect sizes in samples will deviated from these hypothetical values, but sampling error will average out. Thus, for studies that occasionally show support for an effect there will also be studies that underestimate support for an effect. The dotted lines illustrate how the choice of the scaling factor influences Bayes-Factors. With a scaling factor of d = .2, Bayes-Factors would never favor the null-hypothesis. They would also not support the alternative hypothesis in studies with less than 150 participants and even in these studies the Bayes-Factor is likely to be just above 3.
Figure 2 explains why Wagenmakers et al.’s (2011) did mainly find inconclusive results. On the one hand, the effect size was typically around d = .2. As a result, the Bayes-Factor did not provide clear support for the null-hypothesis. On the other hand, an effect size of d = .2 in studies with 80% power is insufficient to produce Bayes-Factors favoring the presence of an effect, when the alternative hypothesis is specified as a Cauchy distribution centered over 0. This is especially true when the scaling parameter is larger, but even for a seemingly small scaling parameter Bayes-Factors would not provide strong support for a small effect. The reason is that the alternative hypothesis is centered over 0. As a result, it is difficult to distinguish the null-hypothesis from the alternative hypothesis.
A True Alternative Hypothesis: Centering the Prior Distribution over a Non-Null Effect Size
A Cauchy-distribution is just one possible way to formulate an alternative hypothesis. It is also possible to formulate alternative hypothesis as (a) a uniform distribution of effect sizes in a fixed range (e.g., the effect size is probably small to moderate, d = .2 to .5) or as a normal distribution centered over an effect size (e.g., the effect is most likely to be small, but there is some uncertainty about how small, d = 2 +/- SD = .1) (Dienes, 2014).
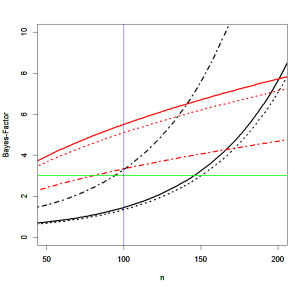
Dienes provided an online app to compute Bayes-Factors for these prior distributions. I used the posted r-code by John Christie to create the following figure. It shows Bayes-Factors for three a priori uniform distributions. Solid lines show Bayes-Factors for effect sizes in the range from 0 to 1. Dotted lines show effect sizes in the range from 0 to .5. The dot-line pattern shows Bayes-Factors for effect sizes in the range from .1 to .3. The most noteworthy observation is that prior distributions that are not centered over zero can actually provide evidence for a small effect with Bem’s (2011) sample sizes. The second observation is that these priors can also favor the null-hypothesis when the true effect size is zero (red lines). Bayes-Factors become more conclusive for more precisely formulate alternative hypotheses. The strongest evidence is obtained by contrasting the null-hypothesis with a narrow interval of possible effect sizes in the .1 to .3 range. The reason is that in this comparison weak effects below .1 clearly favor the null-hypothesis. For an expected effect size of d = .2, a range of values from 0 to .5 seems reasonable and can produce Bayes-Factors that exceed a value of 3 in studies with 100 to 200 participants. Thus, this is a reasonable prior for Bem’s studies.
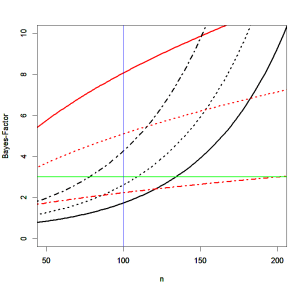
It is also possible to formulate alternative hypotheses with normal distributions around an a priori effect size. Dienes recommends setting the mean to 0 and to set the standard deviation of the expected effect size. The problem with this approach is again that the alternative hypothesis is centered over 0 (in a two-tailed test). Moreover, the true effect size is not known. Like the scaling factor in the Cauchy distribution, using a higher value leads to a wider spread of alternative effect sizes and makes it harder to show evidence for small effects and easier to find evidence in favor of H0. However, the r-code also allows specifying non-null means for the alternative hypothesis. The next figure shows Bayes-Factors for three normally distributed alternative hypotheses. The solid lines show Bayes-Factors with mean = 0 and SD = .2. The dotted line shows Bayes-Factors for d = .2 (a small effect and the effect predicted by Bem) and a relatively wide standard deviation of .5. This means 95% of effect sizes are in the range from -.8 to 1.2. The broken (dot/dash) line shows Bayes-Factors with a mean of d = .2 and a narrower SD of d = .2. The 95% CI still covers a rather wide range of effect sizes from -.2 to .6, but due to the normal distribution effect sizes close to the expected effect size of d = .2 are weighted more heavily.
The first observation is that centering the normal distribution over 0 leads to the same problem as the Cauchy-distribution. When the effect size is really 0, Bayes-Factors provide clear support for the null-hypothesis. However, when the effect size is small, d = .2, Bayes-Factors fail to provide support for the presence for samples with fewer than 150 participants (this is a ones-sample design, the equivalent sample size for between-subject designs is N = 600). The dotted line shows that simply moving the mean from d = 0 to d = .2 has relatively little effect on Bayes-Factors. Due to the wide range of effect sizes, a small effect is not sufficient to produce Bayes-Factors greater than 3 in small samples. The broken line shows more promising results. With d = .2 and SD = .2, Bayes-Factors in small samples with less than 100 participants are inconclusive. For sample sizes of more than 100 participants, both lines are above the criterion value of 3. This means, a Bayes-Factor of 3 or more can support the null-hypothesis when it is true and it can show that a small effect is present when an effect is present.
Another way to specify the alternative hypothesis is to use a one-tailed alternative hypothesis (a half-normal). The mode (the center of the normal-distribution) of the distribution is 0. The solid line shows a standard deviation of .8. The dotted line shows results with standard deviation = .5 and the broken line shows results for a standard deviation of d = .2. The solid line favors the null-hypothesis and it requires sample sizes of more than 130 participants before an effect size of d = .2 produces a Bayes-Factor of 3 or more. In contrast, the broken line discriminates against the null-hypothesis and practically never supports the null-hypothesis when it is true. The dotted line with a standard deviation of .5 works best. It always shows support for the null-hypothesis when it is true and it can produce Bayes-Factors greater than 3 with a bit more than 100 participants.
In conclusion, the simulations show that Bayes-Factors depend on the specification of the prior distribution and sample size. This has two implications. Unreasonable priors will lower the sensitivity/power of Bayes-Factors to support either the null-hypothesis or the alternative hypothesis when these hypotheses are true. Unreasonable priors will also bias the results in favor of one of the two hypotheses. As a result, researchers need to justify the choice of their priors and they need to be careful when they interpret results. It is particularly difficult to interpret Bayes-Factors when the alternative hypothesis is diffuse and the null-hypothesis is supported. In this case, the evidence merely shows that the null-hypothesis fits the data better than the alternative, but the alternative is a composite of many effect sizes and some of these effect sizes may fit the data better than the null-hypothesis.
Comparison of Different Prior Distributions with Bem’s (2011) ESP Experiments
To examine the influence of prior distributions on Bayes-Factors, I computed Bayes-Factors using several prior distributions. I used a d~Cauchy(1) distribution because this distribution was used by Wagenmakers et al. (2011). I used three uniform prior distributions with ranges of effect sizes from 0 to 1, 0 to .5, and .1 to .3. Based on Dienes recommendation, I also used a normal distribution centered on zero with the expected effect size as the standard deviation. I used both two-tailed and one-tailed (half-normal) distributions. Based on a twitter-recommendation by Alexander Etz, I also centered the normal distribution on the effect size, d = .2, with a standard deviation of d = .2.

The d~Cauchy(1) prior used by Wagenmakers et al. (2011) gives the weakest support for an effect. The table also includes the product of Bayes-Factors. The results confirm that the product is not a meaningful statistic that can be used to conduct a meta-analysis with Bayes-Factors. The last column shows Bayes-Factors based on a traditional fixed-effect meta-analysis of effect sizes in all 10 studies. Even the d~Cauchy(1) prior now shows strong support for the presence of an effect even though it often favored the null-hypotheses for individual studies. This finding shows that inferences about small effects in small samples cannot be trusted as evidence that the null-hypothesis is correct.
Table 1 also shows that all other prior distributions tend to favor the presence of an effect even in individual studies. Thus, these priors show consistent results for individual studies and for a meta-analysis of all studies. The strength of evidence for an effect is predictable from the precision of the alternative hypothesis. The uniform distribution with a wide range of effect sizes from 0 to 1, gives the weakest support, but it still supports the presence of an effect. This further emphasizes how unrealistic the Cauchy-distribution with a scaling factor of 1 is for most studies in psychology. For most studies in psychology effect sizes greater than 1 are rare. Moreover, effect sizes greater than one do not need fancy statistics. A simple visual inspection of a scatter plot is sufficient to reject the null-hypothesis. The strongest support for an effect is obtained for the uniform distribution with a range of effect sizes from .1 to .3. The advantage of this range is that the lower bound is not 0. Thus, effect sizes below the lower bound provide evidence for H0 and effect sizes above the lower bound provide evidence for an effect. The lower bound can be set by a meaningful consideration of what effect sizes might be theoretically or practically so small that they would be rather uninteresting even if they are real. Personally, I find uniform distributions appealing because they best express uncertainty about an effect size. Most theories in psychology do not make predictions about effect sizes. Thus, it seems impossible to say that an effect is expected to be small (d = .2) or moderate (d = .5). It seems easier to say that an effect is expected to be small (d = .1 to .3) or moderate (.3 to .6) or large (.6 to 1). Cohen used fixed values only because power analysis requires a single value. As Bayesian statistics allows the specification of ranges, it makes sense to specify a range of values with the need to make predictions which values in this range are more likely. However, results for the normal distribution provide similar results. Again, the strength of evidence of an effect increases with the precision of the predicted effect. The weakest support for an effect is obtained with a normal distribution centered over 0 and a two-tailed test. This specification is similar to a Cauchy distribution but it uses the normal distribution. However, by setting the standard deviation to the expected effect sizes, Bayes-Factors show evidence for an effect. The evidence for an effect becomes stronger by centering the distribution over the expected effect size or by using a half-normal (one-tailed) test that makes predictions about the direction of the effect.
To summarize, the main point is that Bayes-Factors depend on the choice of the alternative distribution. Bayesian statisticians are of course well aware of this fact. However, in practical applications of Bayesian statistics, the importance of the prior distribution is often ignored, especially when Bayes-Factors favor the null-hypothesis. Although this finding only means that the data support the null-hypothesis more than the alternative hypothesis, the alternative hypothesis is often described in vague terms as a hypothesis that predicted an effect. However, the alternative hypothesis does not just predict that there is an effect. It makes predictions about the strength of effects and it is always possible to specify an alternative that predicts an effect that is still consistent with the data by choosing a small effect size. Thus, Bayesian statistics can only produce meaningful results if researchers specify a meaningful alternative hypothesis. It is therefore surprising how little attention Bayesian statisticians have devoted to the issue of specifying the prior distribution. The most useful advice comes from Dienes recommendation to specify the prior distribution as a normal distribution centered over 0 and to set the standard deviation to the expected effect size. If researchers are uncertain about the effect size, they could try different values for small (d = .2), moderate (d = .5), or large (d = .8) effect sizes. Researchers should be aware that the current default setting of .707 in Rouder’s online app implies an expectation of a strong effect and that this setting will make it harder to show evidence for small effects and inflates the risk of obtaining false support for the null-hypothesis.
Why Psychologists Should not Change the Way They Analyze Their Data
Wagenmakers et al. (2011) did not simply use Bayes-Factors to re-examine Bem’s claims about ESP. Like several other authors, they considered Bem’s (2011) article an example of major flaws in psychological science. Thus, they titled their article with the rather strong admonition that “Psychologists Must Change The Way They Analyze Their Data.” They blame the use of p-values and significance tests as the root cause of all problems in psychological science. “We conclude that Bem’s p values do not indicate evidence in favor of precognition; instead, they indicate that experimental psychologists need to change the way they conduct their experiments and analyze their data” (p. 426). The crusade against p-values starts with the claim that it is easy to obtain data that reject the null-hypothesis even when the null-hypothesis is true. “These experiments highlight the relative ease with which an inventive researcher can produce significant results even when the null hypothesis is true” (p. 427). However, this statement is incorrect. The probability of getting significant results is clearly specified by the type-I error rate. When the null-hypothesis is true, a significant result will emerge only 5% of the time; that is in 1 out of 20 studies. The probability of making a type-I error repeatedly decrease exponentially. For two studies, the probability to obtain two type-I errors is only p = .0025 or 1 out of 400 (20 * 20 studies). If some non-significant results are obtained, the binomial probability gives the probability that the frequency of significant results that could have been obtained if the null-hypothesis were true. Bem obtained 9 out of 10 significant results. With a probability of p = .05, the binomial probability is 18e-10. Thus, there is strong evidence that Bem’s results are not type-I errors. He did not just go in his lab and run 10 studies and obtained 9 significant results by chance alone. P-values correctly quantify how unlikely this event is in a single study and how this probability decrease as the number of studies increases. The table also shows that all Bayes-Factors confirm this conclusion when the results of all studies are combined in a meta-analysis. It is hard to see how p-values can be misleading when they lead to the same conclusion as Bayes-Factors. The combined evidence presented by Bem cannot be explained by random sampling error. The data are inconsistent with the null-hypothesis. The only misleading statistic is provided by a Bayes-Factor with an unreasonable prior distribution of effect sizes in small samples. All other statistics agree that the data show an effect.
Wagenmakers et al. (2011) next argument is that p-values only consider the conditional probability when the null-hypothesis is true, but that it is also important to consider the conditional probability if the alternative hypothesis is true. They fail to mention, however, that this alternative hypothesis is equivalent to the concept of statistical power. A p-values of less than .05 means that a significant result would be obtained only 5% of the time when the null-hypothesis is true. The probability of a significant result when an effect is present depends on the size of the effect and sampling error and can be computed using standard tools for power analysis. Importantly, Bem (2011) actually carried out an a priori power analysis and planned his studies to have 80% power. In a one-sample t-test, standard error is defined as 1/sqrt(N). Thus, with 100 participants, the standard error is .1. With an effect size of d = .2, the signal-to-noise ratio is .2/.1 = 2. Using a one-tailed significance test, the criterion value for significance is 1.66. The implied power is 63%. Bem used an effect size of d = .25 to suggest that he has 80% power. Even with a conservative estimate of 50% power, the likelihood ratio of obtaining a significant is .50/.05 = 10. This likelihood ratio can be interpreted like Bayes-Factors. Thus, in a study with 50% power, it is 10 times more likely to obtain a significant result when an effect is present than when the null-hypothesis is true. Thus, even in studies with modest power, favors the alternative hypothesis much more than the null-hypothesis. To argue that p-values provide weak evidence for an effect implies that a study had very low power to show an effect. For example, if a study has only 10% power, the likelihood ratio is only 2 in favor of an effect being present. Importantly, low power cannot explain Bem’s results because low power would imply that most studies produced non-significant results. However, he obtained 9 significant results in 10 studies. This success rate is itself an estimate of power and would suggest that Bem had 90% power in his studies. With 90% power, the likelihood ratio is .90/.05 = 18. The Bayesian argument against p-values is only valid for the interpretation of p-values in a single study in the absence of any information about power. Not surprisingly, Bayesians often focus on Fisher’s use of p-values. However, Neyman-Pearson emphasized the need to also consider type-II error rates and Cohen has emphasized the need to conduct power analysis to ensure that small effects can be detected. In recent years, there has been an encouraging trend to increase power of studies. One important consequence of high powered studies is that significant results increase the evidential value of significant results because a significant result is much more likely to emerge when an effect is present than when it is not present. However, it is important to note that the most likely outcome in underpowered studies is a non-significant result. Thus, it is unlikely that a set of studies can produce false evidence for an effect because a meta-analysis would reveal that most studies fail to show an effect. The main reason for the replication crisis in psychology is the practice not to report non-significant results. This is not a problem of p-values, but a problem of selective reporting. However, Bayes-Factors are not immune to reporting biases. As Table 1 shows, it would have been possible to provide strong evidence for ESP using Bayes-Factors as well.
To demonstrate the virtues of Bayesian statistics, Wagenmakers et al. (2011) then presented their Bayesian analyses of Bem’s data. What is important here, is how the authors explain the choice of their priors and how the authors interpret their results in the context of the choice of their priors. The authors state that they “computed a default Bayesian t test” (p. 430). The important word is default. This word makes it possible to present a Bayesian analysis without a justification of the prior distribution. The prior distribution is the default distribution, a one-size-fits-all prior that does not need any further elaboration. The authors do note that “more specific assumptions about the effect size of psi would result in a different test.” (p. 430). They do not mention that these different tests would also lead to different conclusions because the conclusion is always relative to the specified alternative hypothesis. Even less convincing is their claim that “we decided to first apply the default test because we did not feel qualified to make these more specific assumptions, especially not in an area as contentious as psi” (p. 430). It is true that the authors are not experts on PSI, but that is hardly necessary when Bem (2011) presented a meta-analysis and made an a prior prediction about effect size. Moreover, they could have at least used a half-Cauchy given that Bem used one-tailed tests.
The results of the default t-test are then used to suggest that “a default Bayesian test confirms the intuition that, for large sample sizes, one-sided p values higher than .01 are not compelling” (p. 430). This statement ignores their own critique of p-values that the compelingness of p-values depends on the power of a study. A p-value of .01 in a study with 10% power is not compelling because it is very unlikely outcome no matter whether an effect is present or not. However, in a study with 50% power, a p-value of .01 is very compelling because the likelihood ratio is 50. That is, it is 50 times more likely to get a significant result at p = .01 in a study with 50% power when an effect is present than when an effect is not present.
The authors then emphasize that they “did not select priors to obtain a desired result” (p. 430). This statement can be confusing to non-Bayesian readers. What this statement means is that Bayes-Factors do not entail statements about the probability that ESP exists or does not exist. However, Bayes-Factors do require specification of a prior distribution. Thus, the authors did select a prior distribution, namely the default distribution, and Table 1 shows that their choice of the prior distribution influenced the results.
The authors do directly address the choice of the prior distribution and state “we also examined other options, however, and found that our conclusions were robust. For a wide range of different non-default prior distributions on effect sizes, the evidence for precognition is either non-existent or negligible” (p. 430). These results are reported in a supplementary document. In these materials., the authors show how the scaling factor clearly influences results and that small scaling factors suggest an effect is present whereas larger scaling factors favor the null-hypothesis. However, Bayes-Factors in favor of an effect are not very strong. The reason is that the prior distribution is centered over 0 and a two-tailed test is being used. This makes it very difficult to distinguish the null-hypothesis from the alternative hypothesis. As shown in Table 1, priors that contrast the null-hypothesis with an effect provide much stronger evidence for the presence of an effect. In their conclusion, the authors state “In sum, we conclude that our results are robust to different specifiications of the scale parameter for the effect size prior under H1 “ This statement is more correct than the statement in the article, where they claim that they considered a wide range of non-default prior distributions. They did not consider a wide range of different distributions. They considered a wide range of scaling parameters for a single distribution; a Cauchy-distribution centered over 0. If they had considered a wide range of prior distributions, like I did in Table 1, they would have found that Bayes-Factors for some prior distributions suggest that an effect is present.
The authors then deal with the concern that Bayes-Factors depend on sample size and that larger samples might lead to different conclusions, especially when smaller samples favor the null-hypothesis. “At this point, one may wonder whether it is feasible to use the Bayesian t test and eventually obtain enough evidence against the null hypothesis to overcome the prior skepticism outlined in the previous section.” The authors claimed that they are biased against the presence of an effect by a factor of 10e-24. Thus, it would require a Bayes-Factor greater than 10e24 to sway them that ESP exists. They then point out that the default Bayesian t-test, a Cauchi(0,1) prior distribution, would produce this Bayes-Factor in a sample of 2,000 participants. They then propose that a sample size of N = 2,000 is excessive. This is not a principled robustness analysis. A much easier way to examine what would happen in a larger sample, is to conduct a meta-analysis of the 10 studies, which already included 1,196 participants. As shown in Table 1, the meta-analysis would have revealed that even the default t-test favors the presence of an effect over the null-hypothesis by a factor of 6.55e10. This is still not sufficient to overcome prejudice against an effect of a magnitude of 10e-24, but it would have made readers wonder about the claim that Bayes-Factors are superior than p-values. There is also no need to use Bayesian statistics to be more skeptical. Skeptical researchers can also adjust the criterion value of a p-value if they want to lower the risk of a type-I error. Editors could have asked Bem to demonstrate ESP with p < .001 rather than .05 in each study, but they considered 9 out of 10 significant results at p < .05 (one-tailed) sufficient. As Bayesians provide no clear criterion values when Bayes-Factors are sufficient, Bayesian statistics does not help editors in the decision process how strong evidence has to be.
Does This Mean ESP Exists?
As I have demonstrated, even Bayes-Factors using the most unfavorable prior distribution favors the presence of an effect in a meta-analysis of Bem’s 10 studies. Thus, Bayes-Factors and p-values strongly suggest that Bem’s data are not the result of random sampling error. It is simply too improbable that 9 out of 10 studies produce significant results when the null-hypothesis is true. However, this does not mean that Bem’s data provide evidence for a real effect because there are two explanations for systematic deviations from a random pattern (Schimmack, 2012). One explanation is that a true effect is present and that a study had good statistical power to produce a signal-to-noise ratio that produces a significant outcome. The other explanation is that no true effect is present, but that the reported results were obtained with the help of questionable research practices that inflate the type-I error rate. In a multiple study article, publication bias cannot explain the result because all studies were carried out by the same researcher. Publication bias can only occur when a researcher conducts a single study and reports a significant result that was obtained by chance alone. However, if a researcher conducts multiple studies, type-I errors will not occur again and again and questionable research practices (or fraud) are the only explanation for significant results when the null-hypothesis is actually true.
There have been numerous analyses of Bem’s (2011) data that show signs of questionable research practices (Francis, 2012; Schimmack, 2012; Schimmack, 2015). Moreover, other researchers have failed to replicate Bem’s results. Thus, there is no reason to believe in ESP based on Bem’s data even though Bayes-Factors and p-values strongly reject the hypothesis that sample means are just random deviations from 0. However, the problem is not that the data were analyzed with the wrong statistical method. The reason is that the data are not credible. It would be problematic to replace the standard t-test with the default Bayesian t-test because the default Bayesian t-test gives the right answer with questionable data. The reason is that it would give the wrong answer with credible data, namely it would suggest that no effect is present when a researcher conducts 10 studies with 50% power and honestly reports 5 non-significant results. Rather than correctly inferring from this pattern of results that an effect is present, the default-Bayesian t-test, when applied to each study individually, would suggest that the evidence is inconclusive.
Conclusion
There are many ways to analyze data. There are also many ways to conduct Bayesian analysis. The stronger the empirical evidence is, the less important the statistical approach will be. When different statistical approaches produce different results, it is important to carefully examine the different assumptions of statistical tests that lead to the different conclusions based on the same data. There is no superior statistical method. Never trust a statistician who tells you that you are using the wrong statistical method. Always ask for an explanation why one statistical method produces one result and why another statistical method produces a different result. If one method seems to make more reasonable assumptions than another (data are not normally distributed, unequal variances, unreasonable assumptions about effect size), use the more reasonable statistical method. I have repeatedly asked Dr. Wagenmakers to justify his choice of the Cauchi(0,1) prior, but he has not provide any theoretical or statistical arguments for this extremely wide range of effect sizes.
So, I do not think that psychologists need to change the way they analyze their data. In studies with reasonable power (50% or more), significant results are much more likely to occur when an effect is present than when an effect is not present, and likelihood ratios will show similar results as Bayes-Factors with reasonable priors. Moreover, the probability of a type-I errors in a single study is less important for researchers and science than long-term rate of type-II errors. Researchers need to conduct many studies to build up a CV, get jobs, grants, and take care of their graduate students. Low powered studies will lead to many non-significant results that provide inconclusive results. Thus, they need to conduct powerful studies to be successful. In the past, researchers often used questionable research practices to increase power without declaring the increased risk of a type-I error. However, in part due to Bem’s (2011) infamous article, questionable research practices are becoming less acceptable and direct replication attempts more quickly reveal questionable evidence. In this new culture of open science, only researchers who carefully plan studies will be able to provide consistent empirical support for a theory because the theory actually makes correct predictions. Once researchers report all of the relevant data, it is less important how these data are analyzed. In this new world of psychological science, it will be problematic to ignore power and to use the default Bayesian t-test because it will typically show no effect. Unless researches are planning to build a career on confirming the absence of effects, they should conduct studies with high-power and control type-I error rates by replicating and extending their own work.