In 2015, Daryl J. Bem shared the datafiles for the 9 studies reported in the 2011 article “Feeling the Future” with me. In a blog post, I reported an unexplained decline effect in the data. In an email exchange with Daryl Bem, I asked for some clarifications about the data, comments on the blog post, and permission to share the data.
Today, Daryl J. Bem granted me permission to share the data. He declined to comment on the blog post and did not provide an explanation for the decline effect. He also did not comment on my observation that the article did not mention that “Experiment 5” combined two experiments with N = 50 and that “Experiment 6” combined three datasets with Ns = 91, 19, and 40. It is highly unusual to combine studies and this practice contradicts Bem’s claim that sample sizes were determined a priori based on power analysis.
Footnote on p. 409. “I set 100 as the minimum number of participants/sessions for each of the experiments reported in this article because most effect sizes (d) reported in the
psi literature range between 0.2 and 0.3. If d = 0.25 and N = 100, the power
to detect an effect significant at .05 by a one-tail, one-sample t test is .80
(Cohen, 1988).”
The undisclosed concoction of datasets is another questionable research practice that undermines the scientific integrity of significance tests reported in the original article. At a minimum, Bem should issue a correction that explains how the nine datasets were created and what decision rules were used to stop data collection.
I am sharing the datafiles so that other researchers can conduct further analyses of the data.
Datafiles: EXP1 EXP2 EXP3 EXP4 EXP5 EXP6 EXP7 EXP8 EXP9
Below is the complete email correspondence with Daryl J. Bem.
=======================================================
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Wednesday, February 25, 2015 2:47 AM
Dear Dr. Schimmack,
Attached is a folder of the data from my nine “Feeling the Future” experiments. The files are plain text files, one line for each session, with variables separated by tabs. The first line of each file is the list of variable names, also separated by tabs. I have omitted participants’ names but supplied their sex and age.
You should consult my 2011 article for the descriptions and definitions of the dependent variables for each experiment.
Most of the files contain the following variables: Session#, Date, StartTime, Session Length, Participant’s Sex, Participant’s Age, Experimenter’s Sex, [the main dependent variable or variables], Stimulus Seeking score (from 1 to 5).
For the priming experiments (#3 & #4), the dependent variables are LnRT Forward and LnRT Retro, where Ln is the natural log of Response Times. As described in my 2011 publication, each response time (RT) is transformed by taking the natural log before being entered into calculations. The software subtracts the mean transformed RT for congruent trials from the mean Transformed RT for incongruent trials, so positive values of LnRT indicate that the person took longer to respond to incongruent trials than to congruent trials. Forward refers to the standard version of affective priming and Retro refers to the time-reversed version. In the article, I show the results for both the Ln transformation and the inverse transformation (1/RT) for two different outlier definitions. In the attached files, I provide the results using the Ln transformation and the definition of a too-long RT outlier as 2500 ms.
Subjects who made too many errors (> 25%) in judging the valence of the target picture were discarded. Thus, 3 subjects were discarded from Experiment #3 (hence N = 97) and 1 subject was discarded from Experiment #4 (hence N = 99). Their data do not appear in the attached files.
Note that the habituation experiment #5 used only negative and control (neutral) stimuli.
Habituation experiment #6 used Negative, erotic, and Control (neutral) stimuli.
Retro Boredom experiment #7 used only neutral stimuli.
In Experiment #8, the first Retro Recall, the first 100 sessions are experimental sessions. The last 25 sessions are no-practice control sessions. The type of session is the second variable listed.
In Experiment #9, the first 50 sessions are the experimental sessions and the last 25 are no-practice control sessions. Be sure to exclude the control sessions when analyzing the main experimental sessions. The summary measure of psi performance is the Precog% Score (DR%) whose definition you will find on page 419 of my article.
Let me know if you encounter any problems or want additional data.
Sincerely,
Daryl J. Bem
Professor Emeritus of Psychology
================================================
3 years later, ….
================================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Wednesday, January 3, 2018 4:12 PM
Dear Dr. Bem,
I am finally writing up the results of my reanalyses of your ESP studies.
I encountered one problem with the data for Study 6.
I cannot reproduce the test results reported in the article.
The article :
Both retroactive habituation hypothesis were supported. On trials with negative picture pairs, participants preferred the target significantly more frequently than the nontarget, 51.8%, t(149) _ 1.80, p _ .037, d _ 0.15, binomial z _ 1.74, p _ .041, thereby providing a successful replication of Experiment 5. On trials with erotic picture pairs, participants preferred the target significantly less frequently than the nontarget, 48.2%, t(149) _ _1.77, p _.039, d _ 0.14, binomial z _ _1.74, p _ .041.
I obtain
(negative)
t = 1.4057, df = 149, p-value = 0.1619
(erotic)
t = -1.3095, df = 149, p-value = 0.1924
Also, I wonder why the first 100 cases often produce decimals of .25 and the last 50 cases produce decimals of .33.
It would be nice if you could look into this and let me know what could explain the discrepancy.
Best,
Uli Schimmack
=========================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Saturday, January 6, 2018 11:43 AM
Dear Dr. Bem,
Please reply as soon as possible to my email. Other researchers are interested in analyzing the data and if I submit my analyses some journals want me to provide data or an explanation why I cannot share the data. I hope to hear from you by the end of this week.
Best, Dr. Schimmack
———————————————————–
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Saturday, January 6, 2018 11:43 AM
Dear Dr. Bem,
Meanwhile I posted a blog post about your 2011 article. It has been well received by the scientific community. I would like to encourage you to comment on it.
Best,
Dr. Schimmack
=====================================================
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Wednesday, January 10, 2018 4:42 PM
Dear Dr. Schimmack,
Sorry for the delay. I have been busy re-programming my new experiments so they can be run online, requiring me to relearn the programming language.
The confusion you have experienced arises because the data from Experiments 5 and 6 in my article were split differently for exposition purposes. If you read the report of those two experiments in the article, you will see that Experiment 5 contained 100 participants experiencing only negative (and control) stimuli. Experiment contained 150 participants who experienced negative, erotic, and control stimuli.
I started Experiment 5 (my first precognitive experiment) in the Spring semester of 2002. I ran the pre-planned 100 sessions, using only negative and control stimuli. During that period, I was alerted to the 2002 publication by Dijksterhuis & Smith in the journal Emotion, in which they claimed to demonstrate the reverse of the standard “familiarity-promotes-liking” effect, showing that people also adapt to stimuli that are initially very positive and hence become less attractive as the result of multiple exposures.
So after completing my 100 sessions, I used what remained of the Spring semester to design and run a version of my own retroactive experiment that included erotic stimuli in addition to the negative and control stimuli. I was able to run 50 sessions before the Spring semester ended, and I resumed that extended version the experiment in the following Fall semester when student-subjects again became available until I had a total of 150 sessions of this extended version. For purposes of analysis and exposition, I then divided the experiments as described in the article: 100 sessions with only negative stimuli and 150 sessions with negative and erotic stimuli. No subjects or sessions have been added or omitted, just re-assembled to reflect the change in protocol.
I don’t remember how I sent you the original data, so I am attaching a comma-delimited file (which will open automatically in Excel if you simply double or right click it). It contains all 250 sessions ordered by dates. The fields provided are: Session number (numbered from 1 to 250 in chronological order), the date of the session, the sex of the participant, % of hits on negative stimuli, % of hits on erotic stimuli (which is blank for the 100 subjects in Experiment 5) and % of hits on neutral stimuli.
Let me know if you need additional information.
I hope to get to your blog post soon.
Best,
Daryl Bem
———————————————————–
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Wednesday, January 10, 2018 5:03 PM
Dear Dr. Bem,
Frequencies of male and female in dataset 5.
> table(bem5$Participant.Sex)
Female Male
63 37
Article “One hundred Cornell undergraduates, 63 women and 37 men,
were recruited through the Psychology Department’s”
Analysis of dataset 5
One Sample t-test
data: bem5$N.PC.C.PC[b:e]
t = 2.7234, df = 99, p-value = 0.007639
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
1.137678 7.245655
sample estimates:
mean of x
4.191667
Article “t(99) = 2.23, p = .014”
Conclusion:
Gender of participants matches.
t-values do not match, but both are significant.
Frequencies of male and female in dataset 6.
> table(bem6$Participant.Sex)
Female Male
87 63
Article: Experiment 6: Retroactive Habituation II
One hundred fifty Cornell undergraduates, 87 women and 63
men,
Negative
Paired t-test
data: bem6$NegHits.PC and bem6$ControlHits.PC
t = 1.4057, df = 149, p-value = 0.1619
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.8463098 5.0185321
sample estimates:
mean of the differences
2.086111
Erotic
Paired t-test
data: bem6$EroticHits.PC and bem6$ControlHits.PC
t = -1.3095, df = 149, p-value = 0.1924
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4.2094289 0.8538733
sample estimates:
mean of the differences
-1.677778
Article
Both retroactive habituation hypothesis were supported. On
trials with negative picture pairs, participants preferred the target
significantly more frequently than the nontarget, 51.8%, t(149) _
1.80, p _ .037, d _ 0.15, binomial z _ 1.74, p _ .041, thereby
providing a successful replication of Experiment 5. On trials with
erotic picture pairs, participants preferred the target significantly
less frequently than the nontarget, 48.2%, t(149) _ _1.77, p _
.039, d _ 0.14, binomial z _ _1.74, p _ .041.
Conclusion:
t-values do not match, article reports significant results, but data you shared show non-significant results, although gender composition matches article.
I will double check the datafiles that you sent me in 2015 against the one you are sending me now.
Let’s first understand what is going on here before we discuss other issues.
Best, Dr. Schimmack
———————————————————–
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Wednesday, January 10, 2018 5.41 PM
Dear Dr. Bem,
I just double checked the data you sent me today and they match the data you sent me in 2015.
This means neither of these datasets reproduces the results reported in your 2011 article.
This means your article reported two more significant results (Study 6, Negative and Erotic) than the data support.
This raises further concerns about the credibility of your published results, in addition to the decline effect that I found in your data (except in Study 6, which also produced non-significant results).
Do you still believe that your 2011 studies provided credible information about timer-reversed causality or do you think that you may have capitalized on chance by conducting many pilot studies?
Best, Dr. Schimmack
=======================================
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Thursday, January 11, 2018 10.53 PM
I’ll check them tomorrow to see where the problems are.
==========================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Friday, January 12, 2018 11.08 AM
Dear Dr. Bem,
I conducted further analyses and I figured out why I obtained discrepant results for Study 6.
I computed difference scores with the control condition, but the article reports results for a one-sample t-test of the hit rates against an expected value of 50%.
I also figured out that the first 91 participants were exposed to 16 critical trials and participants 92 to 150 were exposed to 30 critical trials. Can you please confirm this?
Best, Dr. Schimmack
—————————————————————–
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Friday, January 12, 2018 2.17 PM
Dear Dr. Schimmack,
You are correct that I calculated all hit rates against a fixed null of 50%.
You are also correct that the first 91 participants (Spring semester of 2002) were exposed to 48 trials: 16 Negative images, 16, Erotic images, and 16 Neutral Images.
We continued with that same protocol in the Fall semester of 2002 for 19 additional sessions, sessions 51-91.
At this point, it was becoming clear from post-session debriefings of participants that the erotic pictures from the Affective Picture System (IAPS) were much too mild, especially for male participants.
(Recall that this was chronologically my first experiment and also the first one to use erotic materials. The observation that mild erotic stimuli are insufficiently arousing, at least for college students, was later confirmed in our 2016 meta-analysis, which found that Wagenmakers attempt to replicate my Experiment #1 (Which of two curtains hides an erotic picture?) using only mild erotic pictures was the only replication failure out of 11 replication attempts of that protocol in our database.) In all my subsequent experiments with erotic materials, I used the stronger images and permitted participants to choose which kind of erotic images (same-sex vs. opposite-sex erotica) they would be seeing.
For this reason, I decided to introduce more explicit erotic pictures into this attempted replication of the habituation protocol.
In particular, Sessions 92-110 (19 sessions) also consisted of 48 trials, but they were divided into 12 Negative trials, 12 highly Erotic trials, & 24 Neutral trials.
Finally, Sessions 111-150 (40 sessions) increased the number of trials to 60: 15 Negative trials, 15 Highly Erotic trials, & 30 Neutral trials. With the stronger erotic materials, we felt we needed to have relatively more neutral stimuli interspersed with the stronger erotic materials.
Best,
Daryl Bem
——————————————————————-
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Friday, January 12, 2018 7.01 PM
Dear Dr. Bem,
Now that my question about Study 6 has been answered, I would like to hear your thoughts about my blog post. How do you explain the decline effect in your data; that is effect sizes decrease over the course of each experiment and when two experiments are combined into a single dataset, the decline effect seems to repeat at the beginning of the new study. Study 6, your earliest study, doesn’t show the effect, but most other studies show this pattern. As I pointed out on my blog, I think there are two explanations (see also Schooler, 2011). Either unpublished studies with negative results were omitted or measurement of PSI makes the effect disappear. What is probably most interesting is to know what you did when you encountered a promising pilot study. Did you then start collecting new data with this promising procedure or did you continue collecting data and retained the pilot data?
Best, Dr. Schimmack
———————————————————————
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Friday, January 12, 2018 7.47 PM
Dear. Dr. Bem,
Also, is it ok for me to share your data in public or would you rather post them in public?
Best, Dr. Schimmack
===================================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Saturday, January 13, 2018 2.42 PM
Dear Dr. Bem,
I wrote another blog post about Study 6. If you have any comments about this blog post or the earlier blog post, please let me know.
Also, other researchers are interested in looking at the data and I still need to hear from you how to share the datafiles.
Best, Dr. Schimmack
[Attachment: Draft of Blog Post]
————————————————————————–
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Saturday, January 13, 2018 3.53 PM
Dear Dr. Bem,
I put together a table that summarizes when studies were done and how they were combined into datasets.
Please confirm that this is accurate or let me know if there are any mistakes.
Best, Dr. Schimmack
| Dataset | Sample | Year | N |
| 5 | 1 | 2002 | 50 |
| 5 | 2 | 2002 | 50 |
| 6 | 1 | 2002 | 91 |
| 6 | 2 | 2002 | 19 |
| 6 | 3 | 2002 | 40 |
| 7 | 1 | 2005 | 200 |
| 1 | 1 | 2006 | 40 |
| 1 | 2 | 2006 | 60 |
| 3 | 1 | 2007 | 100 |
| 8 | 1 | 2007 | 100 |
| 2 | 1 | 2008 | 100 |
| 2 | 2 | 2008 | 50 |
| 4 | 1 | 2008 | 100 |
| 9 | 1 | 2009 | 50 |
================================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Monday, January 15, 2018 10.46 AM
Dear Dr. Bem,
I am sorry to bother you with my requests. It would be helpful if you could let me know if you are planning to respond to my questions and if so, when you will be able to do so?
Best regards,
Dr. Ulrich Schimmack
————————————————————————–
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Monday, January 15, 2018, 4.17 PM
Dear Dr. Schimmack,
Here is my analysis of your Table. I will try to get to the rest of your commentary in the coming week.
Attached Word document:
Dear Dr. Schimmack,
In looking at your table, I wasn’t sure from your numbering of Datasets & Samples which studies corresponded to those reported in my Feeling the Future article. So I have prepared my own table in the same ordering you have provided and added a column identifying the phenomenon under investigation (It is on the next page)
Unless I have made a mistake in identifying them, I find agreement between us on most of the figures. I have marked in red places where we seem to disagree, which occur on Datasets identified as 3 & 8. You have listed the dates for both as 2007, whereas my datafiles have 2008 listed for all participant sessions which describe the Precognitive Avoidance experiment and its replication. Perhaps I have misidentified the two Datasets. The second discrepancy is that you have listed Dataset 8 as having 100 participants, whereas I ran only 50 sessions with a revised method of selecting the negative stimulus for each trial. As noted in the article, this did not produce a significant difference in the size of the effect, so I included all 150 sessions in the write-up of that experiment.
I do find it useful to identify the Datasets & Samples with their corresponding titles in the article. This permits readers to read the method sections along with the table. Perhaps it will also identify the discrepancy between our Tables. In particular, I don’t understand the separation in your table between Datasets 8 & 9. Perhaps you have transposed Datasets 4 & 8.
If so, then Datasets 4 & 9 would each comprise 50 sessions.
More later.
Your Table:
Dataset Sample Year N
5 1 2002 50
5 2 2002 50
6 1 2002 91
6 2 2002 19
6 3 2002 40
7 1 2005 200
1 1 2006 40
1 2 2006 60
3 1 2007 100
8 1 2007 100
2 1 2008 100
2 2 2008 50
4 1 2008 100
9 1 2009 50
My Table:
Dataset Sample Year N Experiment
5 1 2002 50 #5: Retroactive Habituation I (Neg only)
5 2 2002 50 #5: Retroactive Habituation I (Neg only)
6 1 2002 91 #6: Retroactive Habituation II (Neg & Erot)
6 2 2002 19 #6: Retroactive Habituation II (Neg & Erot)
6 3 2002 40 #6: Retroactive Habituation II (Neg & Erot)
7 1 2005 200 #7: Retroactive Induction of Boredom
1 1 2006 40 #1: Precognitive Detection of Erotic Stimuli
1 2 2006 60 #1: Precognitive Detection of Erotic Stimuli
3 1 2008 100 #2: Precognitive Avoidance of Negative Stimuli
8? 1 2008 50 #2: Precognitive Avoidance of Negative Stimuli
2 1 2007 100 #3: Retroactive Priming I
2 2 2008 100 #4: Retroactive Priming II
4? 1 2008 100 #8: Retroactive Facilitation of Recall I
9 1 2009 50 #9: Retroactive Facilitation of Recall II
———————————————————
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Monday, January 15, 2018, 8.52 PM
Dear Dr. Bem,
Thank you for your table. I think we are mostly in agreement (sorry, if I confused you by calling studies datasets. The numbers are supposed to correspond to the experiment numbers in your table.
The only remaining inconsistency is that the datafile for study 8 shows year 2007, while you have 2008 in your table.
Best, Dr. Schimmack
Study Sample Year N Experiment
5 1 2002 50 #5: Retroactive Habituation I (Neg only)
5 2 2002 50 #5: Retroactive Habituation I (Neg only)
6 1 2002 91 #6: Retroactive Habituation II (Neg & Erot)
6 2 2002 19 #6: Retroactive Habituation II (Neg & Erot)
6 3 2002 40 #6: Retroactive Habituation II (Neg & Erot)
7 1 2005 200 #7: Retroactive Induction of Boredom
1 1 2006 40 #1: Precognitive Detection of Erotic Stimuli
1 2 2006 60 #1: Precognitive Detection of Erotic Stimuli
2 1 2008 100 #2: Precognitive Avoidance of Negative Stimuli
2 2 2008 50 #2: Precognitive Avoidance of Negative Stimuli
3 1 2007 100 #3: Retroactive Priming I
4 1 2008 100 #4: Retroactive Priming II
8? 1 2007/08 100 #8: Retroactive Facilitation of Recall I
9 1 2009 50 #9: Retroactive Facilitation of Recall II
—————————————————————————
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Monday, January 15, 2018, 10.35 PM
You are correct: Experiment 8, the first Retroactive Recall experiment was conducted in 2007 and its replication (Experiment 9) was conducted in 2009.
The Avoidance of Negative Stimuli (Study/Experiment 2) was conducted (and reported as a single experiment with 150 sessions) in 2008. More later.
Best,
Daryl Bem
===========================================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Saturday, January 20, 2018, 1.06 PM
Dear Dr. Bem,
Please let me know by tomorrow how your data should be made public.
I want to post my blog about Study 6 tomorrow. If you want to comment on it before I post it, please do so today.
Best, Dr. Schimmack
——————————————————————————————
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Saturday, January 20, 2018 5:56 PM
Dear Dr. Schimmack,
I hereby grant you permission to be the conduit for making my data available to those requesting them. Most of the researchers who contributed to our 2015/16 meta-analysis of 90 retroactive “feeling-the-future” experiments have already received the data they required for replicating my experiments.
At the moment, I am planning to follow up our meta-analysis of 90 experiments by setting up pre-registered studies. That seems to me to be the most profitable response to the methodological, statistical, and reporting critiques that have emerged since I conducted my original experiments more than a decade ago. To respond to your most recent request, I am not planning at this time to write any commentary to your posts. I am happy to let replications settle the matter.
(One minor point: I did not spend $90,000 to conduct my experiments. Almost all of the participants in my studies at Cornell were unpaid volunteers taking psychology courses that offered (or required) participation in laboratory experiments. Nor did I discard failed experiments or make decisions on the basis of the results obtained.)
What I did do was spend a lot of time and effort preparing and discarding early versions of written instructions, stimulus sets and timing procedures. These were pretested primarily on myself and my graduate assistants, who served repeatedly as pilot subjects. If instructions or procedures were judged to be too time consuming, confusing, or not arousing enough, they were changed before the formal experiments were begun on “real” participants. Changes were not made on the basis of positive or negative results because we were only testing the procedures on ourselves.
When I did decide to change a formal experiment after I had started it, I reported it explicitly in my article. In several cases I wrote up the new trials as a modified replication of the prior experiment. That’s why there are more experiments than phenomena in my article: 2 approach/avoidance experiments, 2 priming experiments, 3 habituation experiments, & 2 recall experiments.)
In some cases the literature suggested that some parameters would be systematically related to the dependent variables in nonlinear fashion—e.g., the number of subliminal presentations used in the familiarity-produces-increased liking effect, which has a curvilinear relationship. In that case, I incorporated the variable as a systematic independent variable. That is also reported in the article.
It took you approximately 3 years to post your responses to my experiments after I sent you the data. Understandable for a busy scholar. But a bit unziemlich for you to then send me near-daily reminders the past 3 weeks to respond back to you (as Schumann commands in the first movement of his piano Sonata in g Minor) “so schnell wie möglich!” And then a page later, “Schneller!”
Solche Unverschämtheit! Wenn ich es sage.
Daryl J. Bem
Professor Emeritus of Psychology
——————————————————————–
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Saturday, January 20, 2018 6:48 PM
Dear Dr. Bem,
Thank you for your final response. It answers all of my questions.
I am sorry if you felt bothered by my emails, but I am confident that many psychologists are interested in your answers to my questions.
Best, Dr. Schimmack
============================================
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Thursday, January 25, 2018 12:05 PM
Dear Dr. Bem,
I now started working on the meta-analysis.
I see another study by you listed (Bem, 2012, N = 42).
Can you please send me the original data for this study?
Best, Dr. Schimmack
———————————————————————————
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Thursday, January 25, 2018 4:45 PM
Dear Dr. Schimmack,
You reference Schooler who has documented the decline effect in several areas—not just in psi research—and has advanced some hypotheses about its possible causes. The hypothesis that strikes me as most plausible is that it is an experimenter effect whereby experimenters and their assistants begin with high expectations and enthusiasm begin to get bored after conducting a lot of sessions. This increasing lack of enthusiasm gets transmitted to the participants during the sessions. I also refer you to Bob Rosenthal’s extensive work with experimenter effects—which show up even in studies with maze-running rats.
Most of Galak’s sessions were online, thereby diminishing this factor. Now that I am retired and no longer have a laboratory with access to student assistants and participants, I, too, am shifting to online administration, so it will provide a rough test of this hypothesis.
Were you planning to publish our latest exchange concerning the meta-analysis? I would not like to leave your blog followers with only your statement that it was “contaminated” by my own studies when, in fact, we did a separate meta-analysis on the non-Bem replications, as I noted in my previous email to you.
Best,
Daryl Bem
————————————————————————-
From: Daryl J. Bem
To: Ulrich Schimmack
Sent: Thursday, January 25, 2018 4:45 PM
Dear Dr. Shimmack,
I was not able to figure out how to leave a comment on your blog post at the website. (I kept being asked to register a site of my own.) So, I thought I would simply write you a note. You are free to publish it as my response to your most recent post if you wish.
In reading your posts on my precognitive experiments, I kept puzzling over why you weren’t mentioning the published Meta-analysis of 90 “Feeling the Future” studies that I published in 2015 with Tessoldi, Rabeyron, & Duggan. After all, the first question we typically ask when controversial results are presented is “Can Independent researchers replicate the effect(s)?” I finally spotted a fleeting reference to our meta-analysis in one of your posts, in which you simply dismissed it as irrelevant because it included my own experiments, thereby “contaminating” it.
But in the very first Table of our analysis, we presented the results for both the full sample of 90 studies and, separately, for the 69 replications conducted by independent researchers (from 33 laboratories in 14 countries on 10,000 participants).
These 69 (non-Bem-contaminated) independent replications yielded a z score of 4.16, p =1.2 x E-5. The Bayes Factor was 3.85—generally considered large enough to provide “Substantial Evidence” for the experimental hypothesis.
Of these 69 studies, 31 were exact replications in that the investigators used my computer programs for conducting the experiments, thereby controlling the stimuli, the number of trials, all event timings, and automatic data recording. The data were also encrypted to ensure that no post-experiment manipulations were made on them by the experimenters or their assistants. (My own data were similarly encrypted to prevent my own assistants from altering them.) The remaining 38 “modified” independent replications variously used investigator-designed computer programs, different stimuli, or even automated sessions conducted online.
Both exact and modified replications were statistically significant and did not differ from one another. Both peer reviewed and non-peer reviewed replications were statistically significant and did not differ from one another. Replications conducted prior to the publication of my own experiments and those conducted after their publication were each statistically significant and did not differ from one another.
We also used the recently introduced p-curve analysis to rule out several kinds of selection bias (file drawer problems), p-hacking, and to estimate “true” effect sizes.
There was no evidence of p-hacking in the database, and the effect size for the non-bem replications was 0.24, somewhat higher than the average effect size of my 11 original experiments (0.22.) (This is also higher than the mean effect size of 0.21 achieved by Presentiment experiments in which indices of participants’ physiological arousal “precognitively” anticipate the random presentation of an arousing stimulus.)
For various reasons, you may not find our meta-analysis any more persuasive than my original publication, but your website followers might.
Best,
Daryl J. Bem
————————————————————–
From: Ulrich Schimmack
To: Daryl J. Bem
Sent: Thursday, January 25, 2018 5:23 PM
Dear Dr. Bem,
I am going to share your comments on the blog.
I find the enthusiasm explanation less plausible than you. More important, it doesn’t explain the lack of a decline effect in studies with significant results.
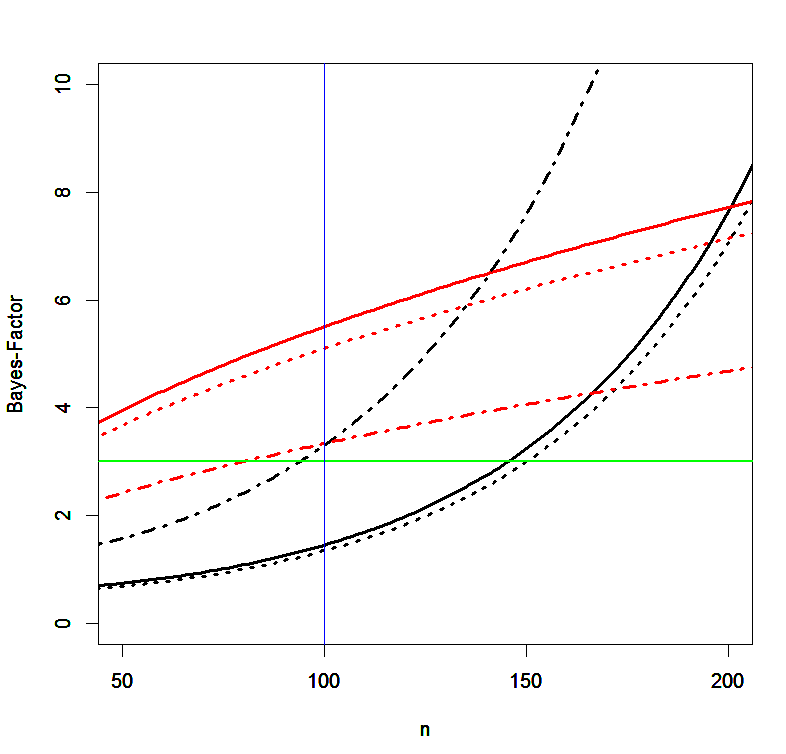
I just finished the analysis of the 6 studies with N > 100 by Maier that are also included in the meta-analysis (see Figure below).
Given the lack of a plausible explanation for your data, I think JPSP should retract your article or at least issue an expression of concern because the published results are based on abnormally strong effect sizes in the beginning of each study. Moreover, Study 5 is actually two studies of N = 50 and the pattern is repeated at the beginning of the two datasets.
I also noticed that the meta-analysis included one more study by you with an underpowered study of N = 42 that surprisingly produced yet another significant result. As I pointed out in my article that you reviewed that you reviewed points out, this success makes it even more likely that some non-significant (pilot) studies were omitted. Your success record is simply too good to be true (Francis, 2012). Have you conducted any other studies since 2012? A non-significant result is overdue.
Regarding the meta-analysis itself, most of these studies are severely underpowered and there is still evidence for publication bias after excluding your studies.
 When I used puniform to control for publication bias and limited the dataset to studies with N > 90 and excluded your studies (as we agree, N < 90 is low power) the p-value was not significant, and even if it were less than .05, it would not be convincing evidence for an effect. In addition, I computed t-values using the effect size that you assumed in 2011, d = .2, and found significant evidence against the null-hypothesis that the ESP effect size could be as large as d = .2. This means, even studies with N = 100 are underpowered. Any serious test of the hypothesis requires much larger sample sizes.
When I used puniform to control for publication bias and limited the dataset to studies with N > 90 and excluded your studies (as we agree, N < 90 is low power) the p-value was not significant, and even if it were less than .05, it would not be convincing evidence for an effect. In addition, I computed t-values using the effect size that you assumed in 2011, d = .2, and found significant evidence against the null-hypothesis that the ESP effect size could be as large as d = .2. This means, even studies with N = 100 are underpowered. Any serious test of the hypothesis requires much larger sample sizes.
However, the meta-analysis and the existence of ESP are not my concern. My concern is the way (social) psychologists have conducted research in the past and are responding to the replication crisis. We need to understand how researchers were able to produce seemingly convincing evidence like your 9 studies in JPSP that are difficult to replicate. How can original articles have success rates of 90% or more and replications produce only a success rate of 30% or less? You are well aware that your 2011 article was published with reservations and concerns about the way social psychologists conducted research. You can make a real contribution to the history of psychology by contributing to the understanding of the research process that led to your results. This is independent of any future tests of PSI with more rigorous studies.
Best, Dr. Schimmack
=================================================
=================================================