
In 1998 Baumeister and colleagues introduced a laboratory experiment to study will-power. Participants are assigned to one of two conditions. In one condition, participants have to exert will-power to work on an effortful task. The other condition is a control condition with a task that does not require will-power. After the manipulation all participants have to perform a second task that requires will-power. The main hypothesis is that participants who already used will-power on the first task will perform more poorly on the second task than participants in the control condition.
In 2010, a meta-analysis examined the results of studies that had used this paradigm (Hagger Wood, & Chatzisarantis, 2010). The meta-analysis uncovered 198 studies with a total of 10,782 participants. The overall effect size in the meta-analysis suggested strong support for the hypothesis with an average effect size of d = .62.
However, the authors of the meta-analysis did not examine the contribution of publication bias to the reported results. Carter and McCullough (2013) compared the percentage of significant results to average observed power. This test showed clear evidence that studies with significant results and inflated effect sizes were overrepresented in the meta-analysis. Carter and McCullough (2014) used meta-regression to examine bias (Stanley and Doucouliagos, 2013). This approach relies on the fact that several sources of reporting bias and publication bias produce a correlation between sampling error and effect size. When effect sizes are regressed on sampling error, the intercept provides an estimate of the unbiased effect size; that is the effect size when sampling error in the population when sampling error is zero. Stanley and Doucouliagos (2013) use two regression methods. One method uses sampling error as a predictor (PET). The other method uses the sampling error squared as a predictor (PEESE). Carter and McCullough (2013) used both methods. PET showed bias and there was no evidence for the key hypothesis. PEESE also showed evidence of bias, but suggested that the effect is present.
There are several problems with the regression-based approach as a way to correct for biases (Replication-Index, December 17, 2014). One problem is that other factors can produce a correlation between sampling error and effect sizes. In this specific case, it is possible that effect sizes vary across experimental paradigms. Hagger and Chatzisarantis (2014) use these problems to caution readers that it is premature to disregard an entire literature on ego-depletion. The R-Index can provide some additional information about the empirical foundation of ego-depletion theory.
The analyses here focus on the handgrip paradigm because this paradigm has high power to detect moderate to strong effects because these studies measured handgrip strengths before and after the manipulation of will-power. Based on published studies, it is possible to estimate the retest correlation of handgrip performance (r ~ .8). Below are some a priori power analysis with common sample sizes and Cohen’s effect sizes of small, moderate, and large effect sizes.
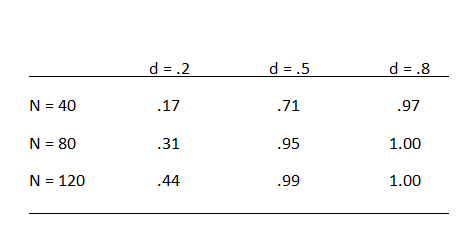
The power analysis shows that the pre-post design is very powerful to detect moderate to large effect sizes. Even with a sample size of just 40 participants (20 per condition), power is 71%. If reporting bias and publication bias exclude 30% non-significant results from the evidence, observed power is inflated to 82%. The comparison of success rate (100%) and observed power (82%) leads to an estimated inflation rate of 18%) and an R-Index is 64% (82% – 18%). Thus a moderate effect size in studies with 40 or more participants is expected to produce an R-Index greater than 64%.
However, with typical sample sizes of less than 120 participants, the expected rate of significant results is less than 50%. With N = 80 and true power of 31%, the reporting of only significant results would boost the observed power to 64%. The inflation rate would be 30% and the R-Index would be 39%. In this case, the R-Index overestimates true power by 9%. Thus, an R-Index less than 50% suggests that the true effect size is small or that the null-hypothesis is true (importantly, the null-hypothesis refers to the effect in the handgrip-paradigm, not to the validity of the broader theory that it becomes more difficult to sustain effort over time).
R-Analysis
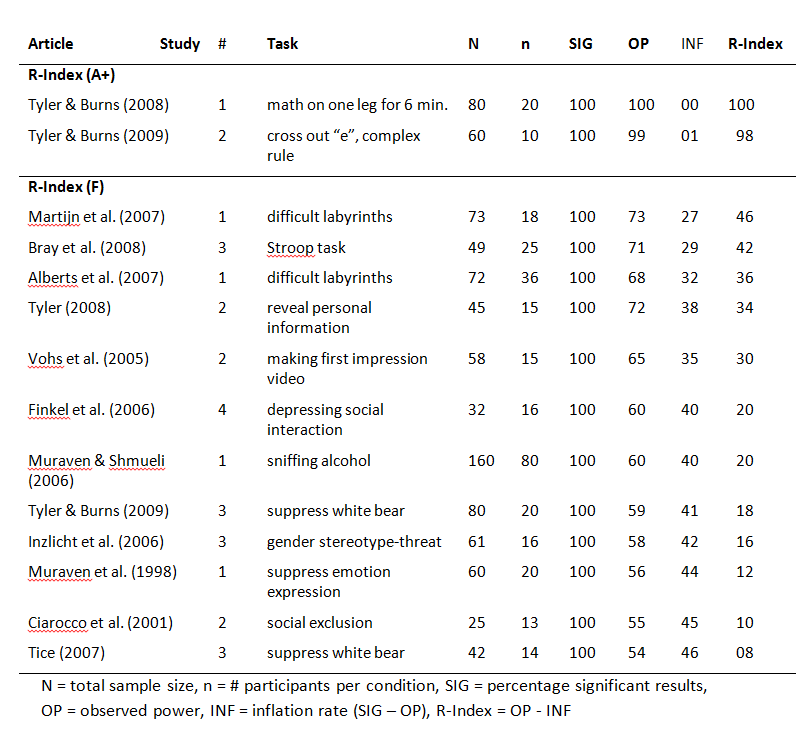
The meta-analysis included 18 effect sizes based on handgrip studies. Two unpublished studies (Ns = 24, 37) were not included in this analysis. Seeley & Gardner (2003)’s study was excluded because it failed to use a pre-post design, which could explain the non-significant result. The meta-analysis reported two effect sizes for this study. Thus, 4 effects were excluded and the analysis below is based on the remaining 14 studies.
All articles presented significant effects of will-power manipulations on handgrip performance. Bray et al. (2008) reported three tests; one was deemed not significant (p = .10), one marginally significant (.06), and one was significant at p = .05 (p = .01). The results from the lowest p-value were used. As a result, the success rate was 100%.
Median observed power was 63%. The inflation rate is 37% and the R-Index is 26%. An R-Index of 22% is consistent with a scenario in which the null-hypothesis is true and all reported findings are type-I errors. Thus, the R-Index supports Carter and McCullough’s (2014) conclusion that the existing evidence does not provide empirical support for the hypothesis that will-power manipulations lower performance on a measure of will-power.
The R-Index can also be used to examine whether a subset of studies provides some evidence for the will-power hypothesis, but that this evidence is masked by the noise generated by underpowered studies with small samples. Only 7 studies had samples with more than 50 participants. The R-Index for these studies remained low (20%). Only two studies had samples with 80 or more participants. The R-Index for these studies increased to 40%, which is still insufficient to estimate an unbiased effect size.
One reason for the weak results is that several studies used weak manipulations of will-power (e.g., sniffing alcohol vs. sniffing water in the control condition). The R-Index of individual studies shows two studies with strong results (R-Index > 80). One study used a physical manipulation (standing one leg). This manipulation may lower handgrip performance, but this effect may not reflect an influence on will-power. The other study used a mentally taxing (and boring) task that is not physically taxing as well, namely crossing out “e”s. This task seems promising for a replication study.
Power analysis with an effect size of d = .2 suggests that a serious empirical test of the will-power hypothesis requires a sample size of N = 300 (150 per cell) to have 80% power in a pre-post study of will-power.
Conclusion
The R-Index of 14 will-power studies with the powerful pre-post handgrip paradigm confirms Carter and McCullough’s (2014) conclusion that a meta-analysis of will-power studies (Hagger Wood, & Chatzisarantis, 2010) provided an inflated estimate of the true effect size and that the existing studies provide no empirical support for the effect of will-power manipulations on a second effortful task. The existing studies have insufficient statistical power to distinguish a true null-effect from a small effect (d = .2). Power analysis suggest that future studies should focus on strong manipulations of will-power and use sample sizes of N = 300 participants.
Limitation
This analysis examined only a small set of studies in the meta-analysis that used handgrip performance as dependent variable. Other studies may show different results, but these studies often used a simple between-subject design with small samples. This paradigm has low power to detect even moderate effect sizes. It is therefore likely that the R-Index will also confirm Carter and McCullough’s (2014) conclusion.
I cry a little at night when I think about situations like the ego-depletion effect in social psychology: hundreds of published studies, and maybe even more unpublished ones. Who knows how much total money, and effort spent on performing all these studies, and after all this time still seemingly contradictory conclusions about whether the effect even exists?!!?
I am not smart enough to follow the ins and outs of every analyses, and the details of every paper, so I just have to read the main conclusions of articles. When I do this for the meta-analysis of Haggar, Wood, Stiff, & Chatzisarantis (2010) and the article by Carter & McCullough (2014) I get to read quite different conclusions about whether the effect exists or not. When I think about all the studies that are published about this effect I cry a little more: how is it possible that so much money and resources were spent on investigating this effect with 2 directly opposing conclusions on the existence of the effect as a result after more than a decade.
To me, this situation is higly unsatisfactory. More importantly I wonder if this situation could be improved, so as to possibly prevent such cases in the future. For instance, do the original studies by Baumeister indicate anything worthy of concern as to whether the effect is real? As I said I am not smart enough to perform an R-Index analysis, but does the R-Index of the original studies indicate that a subsequent replication study would probably not lead to significant results?
If so, then the conclusion of this post and that of Carter & McCullough (to replicate using large samples) could also be an advise that could have been given when just looking at the original article. If this is true, and would have been done back in 1998, this then could have prevented the, to me at least, unsatisfactory situation about uncertainty of the existance of the ego-depletion effect, and all the possible wasted resources that went into examining the effect…
Dear Wonder,
Thank you for sharing your feelings about psychology. I felt the same way when I realized that many results in psychology are incredible.
Fortunately, things have been changing since Daryl Bem (2011) published his unbelievable studies on ESP in the Journal of Personality and Social
Psychology. The R-Index can help psychology to become a respectable science because it allows consumers to focus on replicable research (high R-Index) and ignore results with low replicability (low R-Index). In 2015, http://www.r-index.org will start posting the R-Index of specific journals. Consumers of research like you can then avoid journals that continue to publish studies with a low R-Index.
Thank you for the reply! It seems so easy for psychology to clean up its act when I read about all the possible things it can do to improve matters. It seems to me that if you would have a journal have strict rules like pre-registration combined with having 95% power (like the “Registered Reports” do, https://osf.io/8mpji/wiki/home/) that that could solve a lot of problems with very little effort. Just let journals have stricter rules/ higher standards for their articles.
I wonder if that could have prevented the case of the ego-depletion effect. I wonder if the ego-depletion effect could serve as an example of what can go wrong when non-significant results are not published, when low powered studies are, and when lots of researchers “jump” on a “hot topic” (i.c. perhaps all published results on the topic are all false-positives and the amount of published significant results are merely a reflection of the popularity of the topic and not so much the validity of the results). 16 years and hundreds of studies later, apparently, we need pre-registered, highly powered study to show whether the ego-depletion effect even exists. This could have been the advise from the beginning: just execute a pre-registered, highly powered study to begin with ! Or am I making things to simplistic?
Yes, in theory, it would be that simple, but there are forces that work against rapid change. Scientists who are benefiting from the status quo are not interested in change and the peer-review process is not working because peers are part of the system. It is therefore important that investors (granting agencies) and consumers (journalists, students) hold scientists accountable to ethical standards of scientific integrity.
I reason that journal are mostly interested in their impact factor, so I reason that anything that can help with that, could become a reality relatively easier and sooner. I then wonder if higher standards like pre-registration combined with 95% power would possibly increase a journal’s impact factor.
I can see that it would, and I therefore wonder why there currently are no journals that have these kinds of requirements for their articles. I only know of one that comes close, but only requires pre-registration (http://newsroom.taylorandfrancisgroup.com/news/press-release/comprehensive-results-social-psychology#.VJhe6eAw).
I think high power could be even more important than pre-registration, so I keep wondering whether a journal which would require 1) 95% power and 2) pre-registration for their articles would develop a high impact factor (because their published articles would subsequently be cited a lot because they probably depict “true” findings which other researchers could build their work upon)…
Restating what I did in Twitter.
I’m a little confused by the possibility of conducting an R-index analysis on individual studies as you did for the individual hand-grip studies, or even 2 studies, as you did with the color red/fertility studies. (I’m not questioning the overall R-index for all 10 studies here). My question is this. Since the R-index is based on post-hoc power, and post-hoc power is simply a restated p-value, what can an R-index for one or two studies tell you? That is, since there is nothing inherently wrong/non-replicable with one, two, or maybe even three p-values that are high (less than .05 but higher than .01), how can you determine replicability with so few effects?
With more effects, I understand that you take advantage of the distribution of p-values to say something about the likelihood of an effect being inflated, but with 3 or fewer, I don’t understand how the R-index can be meaningful.
Dear Dr. Inzlicht,
Thank you for your question.
The R-Index is most useful for sets of studies. However, even the R-Index of a single study can provide some information. The main result in the analysis of handgrip studies was that the median R-Index was 26%. This finding provides rather strong evidence that handgrip studies had low power and that published results capitalized on sampling error to produce significant results.
Nevertheless, it is useful to provide information about the R-Index of individual studies in the set of studies for several reasons.
1. First, more information is always better than less information. Some readers may be satisfied with the median. However, other readers may want to dig deeper into the data.
2. Even the R-Index of single studies provides some useful information. As you pointed out, post-hoc power is a transformation of the p-value. Although p-values of .049 and p = .01 are both significant (p < .05), a p-value of .01 provides more evidence against the null-hypothesis than a p-value of .049. It is one of the main problems in the training of statistics that p-values are treated categorically (above or below .05) rather than continuously (lower is better). A p-value of .049 is more similar to a p-value of .051 than to a p-value of .01. Thus, p-values contain information and it is rational to favor studies with lower p-values and higher R-Indices.
3. The median does not provide information about the distribution of R-Indices. For example, a median of 26% is consistent with 7 studies with an R-Index below 26%, one study with an R-Index of 26%, and 6 studies with an R-Index above 80%. If six studies had an R-Index of 80% or higher, it would suggest that there is a moderator effect with some studies providing clear evidence for the effect of will-power on handgrip performance. As it turns out, there were two studies with R-Indices greater than 80%. Although these outliers might be chance findings, it is also possible that these studies differ from the other studies and would replicate in a replication study. I suggested that one reason for the stronger evidence in these studies could be the use of stronger manipulations. The R-Index cannot confirm this hypothesis, but inspection of the R-Indices of individual studies can suggest potential moderating factors.
4. In a forthcoming post, I will explain that there is only a 30% probability that an R-Index below 50% for a single study with a significant result (i.e., observed power between 50% and 75%) is obtained when true power is greater than 50%. Thus, it is roughly 2 times more likely that true power is below 50% than it is for true power to be above 50%. A 30% error rate may seem high, but without additional information it is still rational to infer from an R-Index below 50% that true power was below 50%.
I just came across this:
http://www.psychologicalscience.org/index.php/publications/observer/obsonline/aps-announces-third-replication-project.html
They are planning a “Registered Replication Report” on the ego-depletion effect. That will be interesting!
Dear Wonder,
thanks for posting this link. It will be very interesting to find out about the results of this replication study. I am wondering how they conducted the power analysis for the replication study. If they based it on the published effect sizes in Psychological Science, the study is likely to be underpowered because the published effect sizes were inflated. Based on the new effect size, the study would require a very large N to have 80% power. One common problem with replication studies is that underpowered replication studies are a waste of resources because they are likely to produce a non-significant result that is not significantly different from the original result. The only consequence of this outcome is that it is necessary to run another replication study with more power, which should have been done in the first place.