The concept of statistical power is approaching its one-hundredth birthday, but its impact on inferential statistics has been less impressive than its name suggests. Power was introduced by Neyman and Pearson (1933) as part of a decision-theoretic framework for making principled choices under uncertainty and limited information. It found practical applications in industrial quality control, where decisions often had to be made before all uncertainty could be resolved. In scientific research, however, power was largely ignored for decades. Researchers continued to rely on Fisher’s significance-testing framework, in which statistically significant results were treated as discoveries and nonsignificant results often had little inferential consequence. As a result, statistical practice developed around the control of false positives, while the problem of false negatives received far less attention.
In psychology, Jacob Cohen revived Neyman and Pearson’s concept of power and tried to persuade psychologists that it was not enough to control the probability of false positive results. Researchers also had to consider the probability that a study would produce a statistically significant result if the hypothesis under investigation was true. Low power implied that a study could easily fail to provide evidence for a real effect. Cohen also showed that many studies in psychology had a high probability of producing false negative results for effect sizes that were typical and realistic in psychological research (Cohen, 1962, 1988). Nevertheless, formal power calculations remained rare. For decades, many studies relied on convenience samples with conventional sample sizes, such as 20 undergraduate students per group, rather than on sample sizes justified by the desired probability of detecting an effect.
This changed only after the replication crisis. Long before then, Sterling (1959) had pointed out that success rates of 90% or more in psychology journals were implausible if studies had modest statistical power. Sterling et al. (1995) later showed that the problem had persisted. These high success rates were not evidence that most studies were highly powered; they were evidence that nonsignificant results were being filtered out of the published record. It was therefore not surprising that the first large-scale attempt to replicate a representative sample of psychological studies produced many nonsignificant replication results (Open Science Collaboration, 2015). This sobering finding had been anticipated by Cohen’s power analyses: if original studies were underpowered, many true effects would fail to replicate, and if statistically significant results were selectively published, some original findings would also be false positives. The replication crisis therefore led to a broader recognition that low power and selection bias are not separate problems. Together, they produce a published literature with too many significant results, too many inflated effect sizes, too many unpublished nonsignificant results, and a higher risk that some published discoveries are false positives (Ioannidis, 2005; Simmons et al., 2011).
Over the past decade, dozens of articles about statistical power have been written and it is impossible to mention all of them (see, e.g., Giner-Sorolla et al., 2024, for a recent review). While Cohen’s problem was that power was ignored, the new problem is that a growing literature makes contradictory and confusing claims about statistical power, sometimes by the same authors. The aim of this post is to clarify confusion about the use of power in the context of planning of future and in the use of power to evaluate completed studies.
Post-Hoc Power
The term post hoc is not unique to power analysis. Psychologists are familiar with post-hoc tests that follow complex statistical analyses. For example, a three-way interaction in an ANOVA does not reveal the specific pattern of means that produced the interaction. To interpret the result, researchers typically follow up the omnibus test with lower-order interactions, simple effects, or pairwise comparisons. In this context, post hoc does not mean invalid. It means that the analysis is conducted after a broader result has been obtained, often to clarify its meaning.
In power analysis, post-hoc power usually refers to the calculation of power using the effect-size estimate from a completed study. Dozens of articles have warned against this practice. However, the main reason for the warning is often poorly communicated.
Previous discussions have recognized that post-hoc power is not automatically invalid. O’Keefe emphasized that labels such as post hoc and observed power are often imprecise, and Giner-Sorolla et al. (2024) cautioned that criticisms of observed power should not be generalized to all power analyses conducted after data collection.
However, these discussions do not address the deeper asymmetry in the treatment of power. A priori power analysis is often treated as unconditionally desirable, whereas post-hoc power is treated as suspect. This contrast is unwarranted whenever both calculations rely on empirical effect-size estimates from completed studies. In that case, both calculations inherit the same uncertainty about the population effect size, but the uncertainty about true power in a priori power analyses has been neglected, leading to the imbalanced perception that power analysis is useful to plan studies, but not to evaluate the outcome of studies.
True A Priori and Post-Hoc Power are Identical
Sometimes the same authors recommend the use of effect sizes from past studies to plan future studies and warn against the computation of post-hoc power of completed studies (McShane & Böckenholt, 2016; McShane & Böckenholt, 2019). This is paradoxical because the true power of a study does not depend on the timing or the purpose of a power analysis. Moreover, when researchers plan a direct replication of a previous study, the population effect size of the completed study and the planed study are the same. If the replication study has the same sample size as the original study, and uses the same significance criterion, the two studies also have the same power. So, how can it be possible to use the effect size estimate of a completed study to ensure that a replication study has adequate power, while it is impossible to use the same effect size estimate to estimate the true power of the completed study? This is what we might call the McShane/Böckenholt paradox. The same information is used to calculate a power estimate, but we cannot use this information retrospectively, and only use it prospectively.
The Ontological Error
A common objection to post-hoc power calculations is that power is the probability of a future event and therefore loses its meaning once a study has been completed. After all, the study either produced a significant result or it did not. Once the outcome is known, there is no longer any uncertainty about that particular event.
This objection is valid only if the purpose of a power calculation is to predict the already-observed outcome. But that is not the purpose of post-hoc evaluations of power. The aim is not to ask whether the observed result occurred; it did. The aim is to evaluate the observed result in relation to the probability model that generated it. A significant result in a high-powered study is expected. A significant result in a low-powered study is surprising. A long series of significant results from studies with low power is not merely surprising but statistically incredible (Schimmack, 2012).
The occurrence of an event does not change its prior probability. A near accident remains a near accident even if disaster was avoided. A lottery win remains remarkable because it was unlikely before it happened and is unlikely to happen again. The same logic applies to statistical power. If a study had only a 10% probability of producing a significant result, a researcher who obtains a significant result was lucky. Observing the lucky outcome does not make it any less lucky.
In statistical terms, events must be distinguished from probabilities. Events are observed outcomes; probabilities are properties of the data-generating process. If 10 coin flips produce 10 heads and zero tails, this does not imply that the probability of heads was 100%. The observed outcome is evidence that can be evaluated against alternative probability models. Indeed, this is the logic of many statistical tests, including chi-square tests, which compare observed frequencies to theoretically expected frequencies. The real ontological error is therefore not the use of probability after an event has occurred. It is the conflation of the observed event with the probability that produced it.
For this reason, the strongest version of the ontological objection to post-hoc power is untenable. Meaningful debate remains about how post-hoc power should be estimated, whether observed-effect-size power is too noisy, and whether aggregated power estimates are biased or imprecise. These are statistical and methodological concerns, not ontological ones. Recent discussions of post-hoc power and z-curve have largely shifted toward these issues rather than defending the claim that power becomes meaningless once a study has been completed (Giner-Sorolla et al., 2024; Pek et al., 2026; Soto & Schimmack, 2026; Schimmack & Soto, 2026).
Uncertainty in A Priori Power Calculations
A second criticism of post-hoc power calculations is that they provide unreliable information about the true power of a study. This criticism is valid in one respect: the power of a study depends on the population effect size, which is unknown. A power estimate based on an observed effect size can therefore be highly uncertain. However, this problem is not unique to post-hoc power analysis. The same uncertainty arises whenever an empirical effect-size estimate is used to plan a future study.
Consider an example from McShane and Böckenholt. In their example, the standardized effect-size estimate was d = .40 / .92 = .43. With sample sizes of 52 and 74 participants in the two groups, the standard error of the effect-size estimate was approximately .18. The corresponding 95% confidence interval ranged from d = .07 to d = .80.
We can use these values to ask how lucky the researcher was to obtain a significant result. If the point estimate of d = .43 is used as the assumed population effect size, the estimated power of the study is 65%. However, this is not the true power of the study. It is only an estimate based on an uncertain estimate of the population effect size. If the lower bound of the confidence interval is used instead, d = .07, the estimated power is only 6%. If the upper bound is used, d = .80, the estimated power is 99%. Thus, the implied power of the completed study ranges from 6% to 99%. This wide interval has been used to argue that post-hoc power calculations based on a single observed effect size are uninformative, even if they are not conceptually wrong (McShane & Böckenholt, 2019).
The problem is that the same argument also applies to a priori power analyses. McShane and Böckenholt (2016) proposed a method for planning future sample sizes from the result of a single prior study with d = .40 and SE = .18. Their method applies a downward correction to the original effect-size estimate, yielding an assumed planning effect of approximately d = .36. On this basis, they recommend a replication study with n = 95 participants per condition to achieve 80% power in a one-sided test. Under a conventional two-sided test, however, the same study would have only about 65% power, no more than the completed study. They conclude that their procedure “yields the desired level of power on average and strikes a balance between the point estimate approach that uses too few subjects and thus has too little power on average and the safeguard power approach that uses too many subjects and thus has too much power on average” (p. 52).
This conclusion obscures the central issue. The true power of both the original study and the proposed replication study remains highly uncertain because the population effect size remains unknown. Even if the planned replication study produced the assumed effect size of d = .36 with n = 95 participants per condition, the standard error of d would still be approximately .15. The resulting 95% confidence interval would range from about d = .07 to d = .65. In McShane and Böckenholt’s one-sided framework, this interval implies a power range from roughly 14% to nearly 100%. Under a two-sided test, the corresponding range is approximately 7% to 99%. Thus, even under their own planning assumptions, the power of the proposed replication study would remain highly uncertain.
The broader point is that uncertainty about power follows from uncertainty about the population effect size. This uncertainty does not disappear simply because the calculation is performed before the study rather than after it. If an observed effect-size estimate is too uncertain to evaluate the power of a completed study, the same estimate is equally uncertain when used to plan the power of a future study. It is therefore inconsistent to reject post-hoc power estimates because they are uncertain while endorsing a priori power analyses based on the same uncertain empirical estimates.
The correct conclusion is not that all power calculations are useless. A priori power analyses can be useful for planning studies, just as post-hoc power analyses can be useful for evaluating the evidential value of completed research. But neither type of calculation reveals the true power of a study unless the population effect size is known. In practice, it rarely is. All empirical power calculations are conditional on assumptions about the effect size, model, design, and analysis. The relevant question is therefore not whether a power estimate is uncertain, but whether the assumptions behind it are explicit, plausible, and appropriate for the inferential purpose.
This point is especially important for critiques of post-hoc power. Uncertainty is a valid reason to reject naïve point estimates of power based on a single noisy study. It is not a valid reason to declare post-hoc power uniquely defective. The same uncertainty affects a priori power calculations whenever they rely on uncertain empirical effect-size estimates. McShane and Böckenholt’s argument therefore cuts both ways: if uncertainty invalidates post-hoc power, it also invalidates the empirical a priori power calculations they recommend.
The Abuse of Power Calculations
The most influential criticism of post-hoc power calculations was made by Hoenig and Heisey (2001). Their argument addressed a common misuse of post-hoc power: researchers sometimes calculated observed power after obtaining a nonsignificant result in order to decide whether the result supported the null hypothesis or merely reflected insufficient power. In this setting, a nonsignificant result could have two explanations. The null hypothesis may be true, or the null hypothesis may be false but the study failed to reject it because power was low.
Hoenig and Heisey correctly pointed out that observed power cannot solve this problem. When power is computed from the observed effect size, it is largely a transformation of the same information contained in the test statistic or p-value. Results below the critical value are nonsignificant and tend to yield low observed power. Results above the critical value are significant and tend to yield high observed power. Thus, observed power cannot reveal a pattern in which the study had high power but failed to reject the null, nor can it independently show that a nonsignificant result was a false negative. The calculation recycles the observed result rather than adding independent evidence about the population effect size.
This criticism is valid, but its scope is limited. It shows that naïve observed-power calculations should not be used to interpret a single nonsignificant result. It does not show that post-hoc power is meaningless, false, or conceptually incoherent. The actual problem is that the observed effect size is an uncertain estimate of the population effect size. Because true power is defined by the population effect size, any power calculation based on the observed effect size inherits this uncertainty.
The proper lesson is therefore not that power cannot be evaluated after a study has been completed. The proper lesson is that point estimates of power should not be confused with true power. Confidence intervals make this clear. A point estimate of 80% power may be compatible with a lower bound below 10%, and a point estimate of 20% power may be compatible with an upper bound above 90%. These wide intervals do not show that power is meaningless. They show that a single study often provides insufficient information to estimate its true power with useful precision.
Hoenig and Heisey’s critique is therefore best understood as a warning against overinterpreting noisy point estimates. It is not a categorical argument against post-hoc power analysis. Once uncertainty is acknowledged, the issue becomes the same as in any empirical power calculation: how much information do the data provide about the population effect size, and how precisely can the corresponding power be estimated?
Asymmetrical Uncertainty for Low and High Power
Discussions of post-hoc power usually focus on studies with low or modest power. This focus is understandable. Many researchers work with small samples, noisy measures, and between-subject designs where high power is difficult to achieve. However, this emphasis can create a misleading impression: that post-hoc power calculations are always uninformative. They are not. A single study can provide strong evidence that its true power was high when the observed evidence is very strong.
The reason is that power approaches 1 as the noncentrality parameter increases. For a two-sided test with α = .05, a noncentrality parameter of 2 implies roughly 50% power, a value of 4 implies roughly 98% power, and a value of 6 implies power greater than 99.9%. Thus, if a study produces an observed z-value of 6, the point estimate of power is practically 100%. More importantly, even the lower bound of the confidence interval around the effect size still implies very high power. Because the lower 95% confidence limit is approximately z = 6 − 1.96 = 4.04, the corresponding lower-bound power estimate is still about 98%.
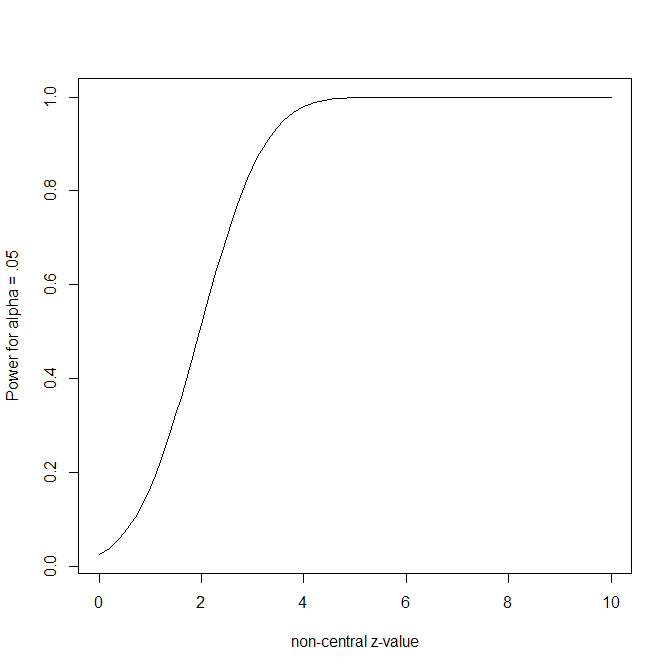
This illustrates an important asymmetry. Low or moderate observed power in a single study is highly uncertain. A point estimate of 20% or 50% power may be compatible with a wide range of true power values. But very high observed power is different. A result with z = 6 is not easily explained by a study with only 50% true power. Under 50% power, the expected z-value is near the significance threshold, not three standard errors above it. Such an extreme result could occur by chance, but it is rare.
This matters because z-values greater than 6 are not uncommon in some areas of research, especially when studies use large samples, precise measures, strong manipulations, or repeated observations. These results are not merely statistically significant. They are highly replicable under the same design and population assumptions. If a replication study fails to reproduce such a finding, the most plausible explanation is often not ordinary sampling error but some substantive difference between the original and replication studies, such as a weaker manipulation, a different population, a changed measurement procedure, or a failure to reproduce the relevant conditions.
The real difficulty concerns low power in literatures with many studies. A single borderline-significant result cannot demonstrate that a study truly had low power, because the effect-size estimate is too uncertain. But a series of significant results from studies that all appear to have low or modest power is informative in a different way. The problem is not that any one study proves low power with precision. The problem is that repeated success becomes increasingly implausible when the studies, taken together, imply low probabilities of success.
In short, post-hoc power estimates from a single study are not uniformly uninformative. They are often weak for borderline results, but they can be informative when observed evidence is very strong. High power can sometimes be demonstrated from a single study. Low power is usually harder to establish from one study and is better diagnosed from patterns across multiple studies.
Average “Post-Hoc Power” As Bias Test
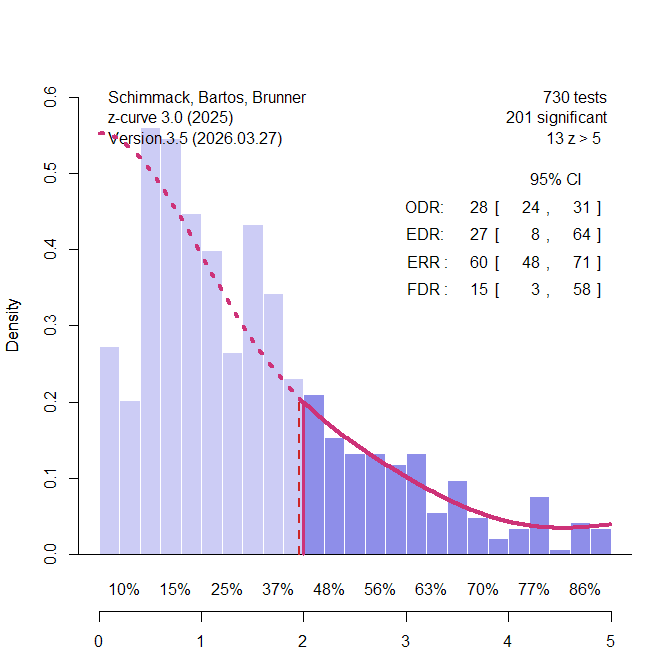
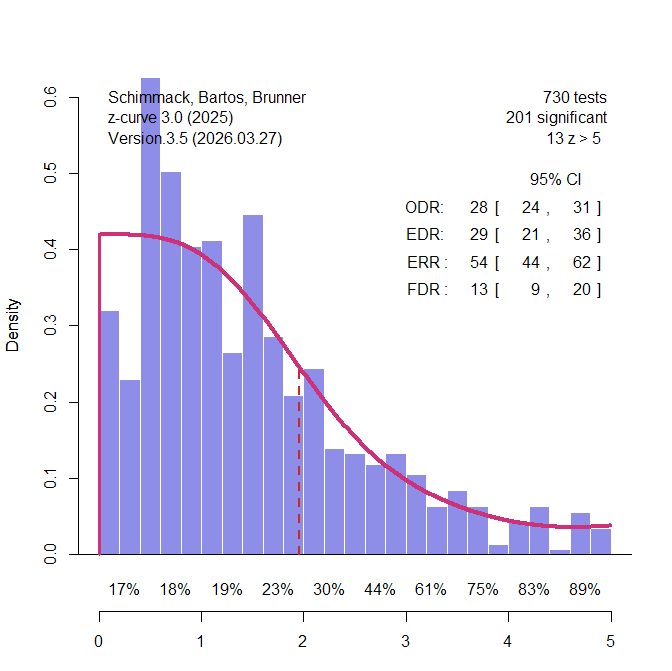
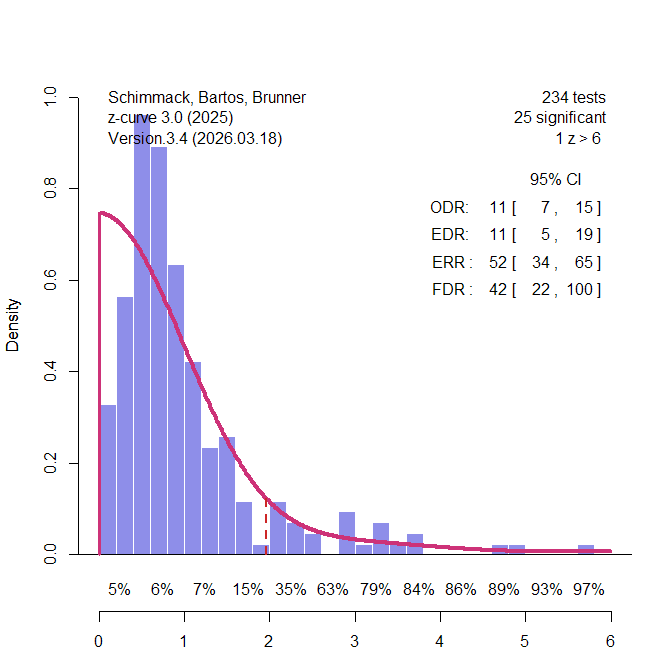
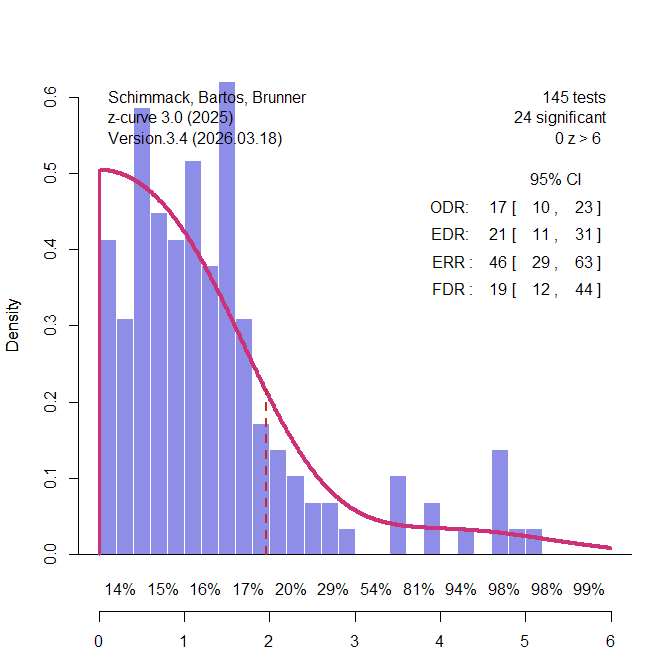
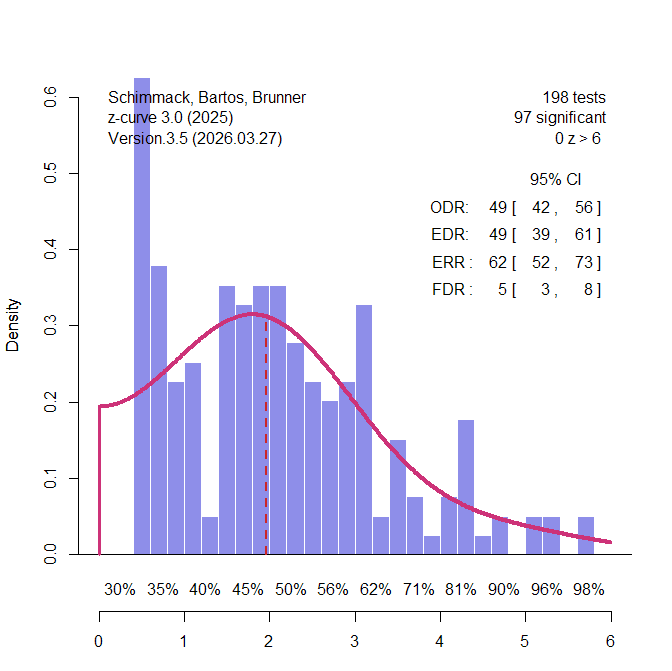
Power analyses of single studies are often uninformative because the population effect size is unknown and the observed effect-size estimate is noisy. This limitation, however, does not generalize to sets of studies. Post-hoc power analyses of multiple studies can be informative because they allow researchers to compare the expected number of significant results with the number of significant results that was actually observed. This comparison is the basis of several bias tests, including tests proposed by Ioannidis and Trikalinos (2007), Francis (2014), Schimmack (2012), and the z-curve selection model (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020).
Before discussing these tests, it is important to distinguish statistical power from the unconditional probability of obtaining a significant result. In the Neyman-Pearson framework, power is the probability of rejecting a false null hypothesis. It is therefore conditional on H0 being false. After a study has been completed, however, we usually do not know whether the tested null hypothesis was true or false. A set of studies may contain some true effects and some true null hypotheses. Consequently, the expected rate of significant results in such a set is not identical to average power in the strict Neyman-Pearson sense. It is the unconditional probability that a study produces a significant result.
Bartoš and Schimmack introduced the term expected discovery rate (EDR) for this unconditional probability. The EDR is related to power, but it is also influenced by the proportion of true null hypotheses that were tested. If all tested hypotheses are false, the EDR corresponds to average power. If some tested hypotheses are true, the EDR is lower because true null hypotheses can produce significant results only as Type I errors (Sterling et al., 1995).
The EDR is useful because it can be compared with the observed discovery rate (ODR), that is, the actual proportion of significant results in a set of studies. When the ODR is much higher than the EDR, the literature contains more significant results than the population effect sizes and sample sizes of the studies could have produced. This discrepancy provides evidence of selection bias, questionable research practices, or other reporting processes that favor significant results.
This use of post-hoc power is especially important because it addresses a problem that conventional publication-bias methods often handle poorly. Funnel plots and regression-based methods can be difficult to interpret when studies are heterogeneous. A relation between sampling error and effect size may reflect publication bias, but it may also reflect real heterogeneity, differences in study design, or differences in the populations and measures used across studies. Power-based bias tests do not require effect sizes to be homogeneous in the same way. They ask a different question: given the estimated probability that each study would produce a significant result, is the observed number of significant results credible? This makes power-based bias tests a valuable complement to funnel-plot and regression-based methods.
The logic is simple. If five studies each had only a 30% probability of producing a significant result, the probability that all five would be significant is .30⁵ = .0024. A set of five significant results is therefore not impossible, but it is statistically surprising. The problem becomes even more severe in literatures with success rates above 90%, which were common in psychology before the replication crisis. In such literatures, the question is not whether a single significant result was lucky. The question is whether the entire pattern of significant results is plausible under the estimated EDR.
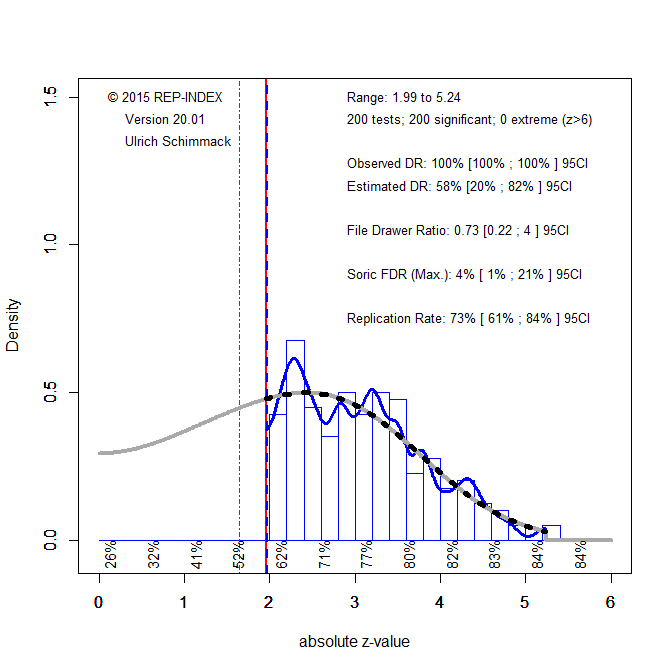
Publication bias also creates a problem for a priori power analyses based on completed studies. When studies are selected for significance, their effect-size estimates are inflated. Sample-size planning based on those inflated estimates will therefore overestimate the power of future replication studies. This is precisely what happened in the Reproducibility Project. The replication studies were planned to have high power based on the original published effect sizes, yet the actual success rate was much lower. This discrepancy has often been treated as puzzling, but it is exactly what should be expected when original effect sizes are inflated by selection for significance.
The more important fact is not simply that the replication success rate was 36%. A low replication rate can have many explanations. The more diagnostic fact is that the original journals had success rates above 90%, whereas the expected discovery rate was much lower. This discrepancy reveals that the published literature contained too many significant results. It also explains why the original effect-size estimates were larger than the replication effect-size estimates and why a priori power analyses based on the original studies overstated the true power of the replications.
In short, “post-hoc power” of a set of studies (i.e., the expected discovery rate) has become an important application for power analyses of completed studies. The results of this application of power analysis also have implications for a priori power analyses. A priori power analysis based on meta-analyses of previous studies with publication bias will produce inflated estimates of power and suggest sample sizes that are too small. Estimating and correction biases in these meta-analyses is therefore important to avoid high type-II error rates in replication studies.
Conclusion
After the cognitive revolution of the 1970s, the affective revolution of the 1980s, the implicit revolution of the 1990s, and the neuroscience revolution of the 2000s, psychology underwent a methodological revolution in the 2010s. This revolution revealed serious defects in how psychologists designed studies, analyzed data, and reported results. It also vindicated Cohen’s long-standing warnings about low statistical power. The replication crisis was therefore not a surprise. It was the predictable consequence of a discipline that had embraced small samples despite Cohen’s reminder that “less is more except for sample size.”
Psychological science is now more attentive to statistical power, but misconceptions about power continue to impede progress. Power analysis is increasingly accepted as a tool for planning better studies, yet researchers still disagree about how to choose the population effect size needed for a meaningful a priori power analysis. At the same time, the focus on a priori planning has encouraged the mistaken belief that power becomes irrelevant once a study has been completed. This belief has led to overly broad claims that post-hoc power calculations should not be conducted.
Giner-Sorolla et al. (2024) already recognized legitimate uses of power calculations for completed studies, especially for evaluating the sensitivity of focal tests rather than relying on sample size alone. However, they remained skeptical of observed-power calculations that use the effect-size estimate from the same completed study, because such estimates often add little beyond the p-value and remain highly uncertain.
Here, I marshal a stronger defense of power calculations based on completed studies. First, I argue that uncertainty about the population effect size is not unique to post-hoc power. Sampling error in effect-size estimates affects a priori power calculations just as much as post-hoc power calculations when both rely on empirical estimates from completed studies. Second, I argue that power calculations based on actual results are essential for evaluating the credibility of published literatures. Only the observed results of completed studies can be used to estimate the expected discovery rate and compare it with the observed discovery rate. This comparison is the basis of power-based tests of publication bias. As long as power calculations are restricted to hypothetical effect sizes, they remain planning exercises; they cannot evaluate whether a published literature contains too many significant results. In this sense, a priori power analyses have limited diagnostic consequences because they are not based on the actual pattern of published findings. By contrast, bias tests that estimate expected discovery rates can challenge the credibility of entire literatures with hundreds of statistically significant results (Chen et al., 2025).
The central problem is not whether a power calculation is conducted before or after data are collected. The central problem is uncertainty. All empirical power calculations are affected by random error, and all calculations based on published findings may be affected by systematic error, especially selection bias. A priori power analyses are not exempt from this problem. If they rely on inflated effect-size estimates from selected literatures, they will overestimate the power of future studies. Conversely, post-hoc power analyses can be informative when they are used to evaluate whether published success rates are credible given the estimated probability of significant results.
Thus, the familiar objections to “post-hoc power” identify real problems, but they misdiagnose their source. The problem is not that power is calculated after the study. The problem is that point estimates are often confused with population quantities. Terms such as “effect size” and “power” are frequently used as shorthand for noisy estimates, while the uncertainty around those estimates is ignored. Clearer language would help: researchers should distinguish effect-size estimates from population effect sizes and power estimates from actual power, and they should report point estimates together with confidence intervals whenever possible.
The future of power analysis should therefore not be limited to a priori sample-size planning. Power estimates also have an important diagnostic function. They can reveal when published literatures contain too many significant results, when effect-size estimates are likely to be inflated, and when a priori power analyses based on those estimates are misleading. Properly understood, post-hoc power analysis is not an abuse of power. It is one tool for correcting the very biases that made the replication crisis possible.