Welcome to the replicability rankings for 120 psychology journals. More information about the statistical method that is used to create the replicability rankings can be found elsewhere (Z-Curve; Video Tutorial; Talk; Examples). The rankings are based on automated extraction of test statistics from all articles published in these 120 journals from 2010 to 2020 (data). The results can be reproduced with the R-package zcurve.
To give a brief explanation of the method, I use the journal with the highest ranking and the journal with the lowest ranking as examples. Figure 1 shows the z-curve plot for the 2nd highest ranking journal for the year 2020 (the Journal of Organizational Psychology is ranked #1, but it has very few test statistics). Plots for all journals that include additional information and information about test statistics are available by clicking on the journal name. Plots for previous years can be found on the site for the 2010-2019 rankings (previous rankings).

To create the z-curve plot in Figure 1, the 361 test statistics were first transformed into exact p-values that were then transformed into absolute z-scores. Thus, each value represents the deviation from zero for a standard normal distribution. A value of 1.96 (solid red line) corresponds to the standard criterion for significance, p = .05 (two-tailed). The dashed line represents the treshold for marginal significance, p = .10 (two-tailed). A z-curve analysis fits a finite mixture model to the distribution of the significant z-scores (the blue density distribution on the right side of the solid red line). The distribution provides information about the average power of studies that produced a significant result. As power determines the success rate in future studies, power after selection for significance is used to estimate replicability. For the present data, the z-curve estimate of the replication rate is 84%. The bootstrapped 95% confidence interval around this estimate ranges from 75% to 92%. Thus, we would expect the majority of these significant results to replicate.
However, the graph also shows some evidence that questionable research practices produce too many significant results. The observed discovery rate (i.e., the percentage of p-values below .05) is 82%. This is outside of the 95%CI of the estimated discovery rate which is represented by the grey line in the range of non-significant results; EDR = .31%, 95%CI = 18% to 81%. We see that there are fewer results reported than z-curve predicts. This finding casts doubt about the replicability of the just significant p-values. The replicability rankings ignore this problem, which means that the predicted success rates are overly optimistic. A more pessimistic predictor of the actual success rate is the EDR. However, the ERR still provides useful information to compare power of studies across journals and over time.
Figure 2 shows a journal with a low ERR in 2020.

The estimated replication rate is 64%, with a 95%CI ranging from 55% to 73%. The 95%CI does not overlap with the 95%CI for the Journal of Sex Research, indicating that this is a significant difference in replicability. Visual inspection also shows clear evidence for the use of questionable research practices with a lot more results that are just significant than results that are not significant. The observed discovery rate of 75% is inflated and outside the 95%CI of the EDR that ranges from 10% to 56%.
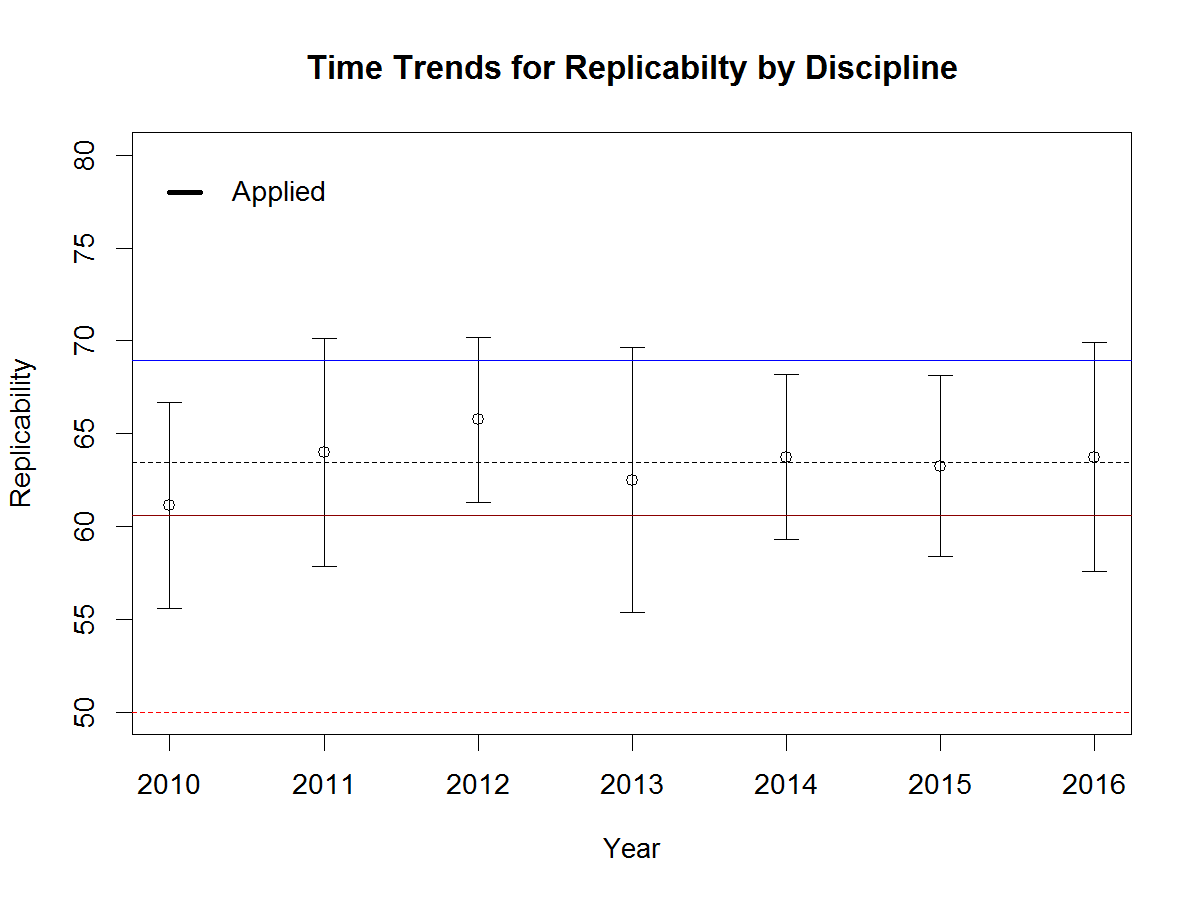
To examine time trends, I regressed the ERR of each year on the year and computed the predicted values and 95%CI. Figure 3 shows the results for the journal Social Psychological and Personality Science as an example (x = 0 is 2010, x = 1 is 2020). The upper bound of the 95%CI for 2010, 62%, is lower than the lower bound of the 95%CI for 2020, 74%.

This shows a significant difference with alpha = .01. I use alpha = .01 so that only 1.2 out of the 120 journals are expected to show a significant change in either direction by chance alone. There are 22 journals with a significant increase in the ERR and no journals with a significant decrease. This shows that about 20% of these journals have responded to the crisis of confidence by publishing studies with higher power that are more likely to replicate.
| Rank | Journal | Observed 2020 | Predicted 2020 | Predicted 2010 |
| 1 | Journal of Organizational Psychology | 88 [69 ; 99] | 84 [75 ; 93] | 73 [64 ; 81] |
| 2 | Journal of Sex Research | 84 [75 ; 92] | 84 [74 ; 93] | 75 [65 ; 84] |
| 3 | Evolution & Human Behavior | 84 [74 ; 93] | 83 [77 ; 90] | 62 [56 ; 68] |
| 4 | Judgment and Decision Making | 81 [74 ; 88] | 83 [77 ; 89] | 68 [62 ; 75] |
| 5 | Personality and Individual Differences | 81 [76 ; 86] | 81 [78 ; 83] | 68 [65 ; 71] |
| 6 | Addictive Behaviors | 82 [75 ; 89] | 81 [77 ; 86] | 71 [67 ; 75] |
| 7 | Depression & Anxiety | 84 [76 ; 91] | 81 [77 ; 85] | 67 [63 ; 71] |
| 8 | Cognitive Psychology | 83 [75 ; 90] | 81 [76 ; 87] | 71 [65 ; 76] |
| 9 | Social Psychological and Personality Science | 85 [78 ; 92] | 81 [74 ; 89] | 54 [46 ; 62] |
| 10 | Journal of Experimental Psychology – General | 80 [75 ; 85] | 80 [79 ; 81] | 67 [66 ; 69] |
| 11 | J. of Exp. Psychology – Learning, Memory & Cognition | 81 [75 ; 87] | 80 [77 ; 84] | 73 [70 ; 77] |
| 12 | Journal of Memory and Language | 79 [73 ; 86] | 80 [76 ; 83] | 73 [69 ; 77] |
| 13 | Cognitive Development | 81 [75 ; 88] | 80 [75 ; 85] | 67 [62 ; 72] |
| 14 | Sex Roles | 81 [74 ; 88] | 80 [75 ; 85] | 72 [67 ; 77] |
| 15 | Developmental Psychology | 74 [67 ; 81] | 80 [75 ; 84] | 67 [63 ; 72] |
| 16 | Canadian Journal of Experimental Psychology | 77 [65 ; 90] | 80 [73 ; 86] | 74 [68 ; 81] |
| 17 | Journal of Nonverbal Behavior | 73 [59 ; 84] | 80 [68 ; 91] | 65 [53 ; 77] |
| 18 | Memory and Cognition | 81 [73 ; 87] | 79 [77 ; 81] | 75 [73 ; 77] |
| 19 | Cognition | 79 [74 ; 84] | 79 [76 ; 82] | 70 [68 ; 73] |
| 20 | Psychology and Aging | 81 [74 ; 87] | 79 [75 ; 84] | 74 [69 ; 79] |
| 21 | Journal of Cross-Cultural Psychology | 83 [76 ; 91] | 79 [75 ; 83] | 75 [71 ; 79] |
| 22 | Psychonomic Bulletin and Review | 79 [72 ; 86] | 79 [75 ; 83] | 71 [67 ; 75] |
| 23 | Journal of Experimental Social Psychology | 78 [73 ; 84] | 79 [75 ; 82] | 52 [48 ; 55] |
| 24 | JPSP-Attitudes & Social Cognition | 82 [75 ; 88] | 79 [69 ; 89] | 55 [45 ; 65] |
| 25 | European Journal of Developmental Psychology | 75 [64 ; 86] | 79 [68 ; 91] | 74 [62 ; 85] |
| 26 | Journal of Business and Psychology | 82 [71 ; 91] | 79 [68 ; 90] | 74 [63 ; 85] |
| 27 | Psychology of Religion and Spirituality | 79 [71 ; 88] | 79 [66 ; 92] | 72 [59 ; 85] |
| 28 | J. of Exp. Psychology – Human Perception and Performance | 79 [73 ; 84] | 78 [77 ; 80] | 75 [73 ; 77] |
| 29 | Attention, Perception and Psychophysics | 77 [72 ; 82] | 78 [75 ; 82] | 73 [70 ; 76] |
| 30 | Psychophysiology | 79 [74 ; 84] | 78 [75 ; 82] | 66 [62 ; 70] |
| 31 | Psychological Science | 77 [72 ; 84] | 78 [75 ; 82] | 57 [54 ; 61] |
| 32 | Quarterly Journal of Experimental Psychology | 81 [75 ; 86] | 78 [75 ; 81] | 72 [69 ; 74] |
| 33 | Journal of Child and Family Studies | 80 [73 ; 87] | 78 [74 ; 82] | 67 [63 ; 70] |
| 34 | JPSP-Interpersonal Relationships and Group Processes | 81 [74 ; 88] | 78 [73 ; 82] | 53 [49 ; 58] |
| 35 | Journal of Behavioral Decision Making | 77 [70 ; 86] | 78 [72 ; 84] | 66 [60 ; 72] |
| 36 | Appetite | 78 [73 ; 84] | 78 [72 ; 83] | 72 [67 ; 78] |
| 37 | Journal of Comparative Psychology | 79 [65 ; 91] | 78 [71 ; 85] | 68 [61 ; 75] |
| 38 | Journal of Religion and Health | 77 [57 ; 94] | 78 [70 ; 87] | 75 [67 ; 84] |
| 39 | Aggressive Behaviours | 82 [74 ; 90] | 78 [70 ; 86] | 70 [62 ; 78] |
| 40 | Journal of Health Psychology | 74 [64 ; 82] | 78 [70 ; 86] | 72 [64 ; 80] |
| 41 | Journal of Social Psychology | 78 [70 ; 87] | 78 [70 ; 86] | 69 [60 ; 77] |
| 42 | Law and Human Behavior | 81 [71 ; 90] | 78 [69 ; 87] | 70 [61 ; 78] |
| 43 | Psychological Medicine | 76 [68 ; 85] | 78 [66 ; 89] | 74 [63 ; 86] |
| 44 | Political Psychology | 73 [59 ; 85] | 78 [65 ; 92] | 59 [46 ; 73] |
| 45 | Acta Psychologica | 81 [75 ; 88] | 77 [74 ; 81] | 73 [70 ; 76] |
| 46 | Experimental Psychology | 73 [62 ; 83] | 77 [73 ; 82] | 73 [68 ; 77] |
| 47 | Archives of Sexual Behavior | 77 [69 ; 83] | 77 [73 ; 81] | 78 [74 ; 82] |
| 48 | British Journal of Psychology | 73 [65 ; 81] | 77 [72 ; 82] | 74 [68 ; 79] |
| 49 | Journal of Cognitive Psychology | 77 [69 ; 84] | 77 [72 ; 82] | 74 [69 ; 78] |
| 50 | Journal of Experimental Psychology – Applied | 82 [75 ; 88] | 77 [72 ; 82] | 70 [65 ; 76] |
| 51 | Asian Journal of Social Psychology | 79 [66 ; 89] | 77 [70 ; 84] | 70 [63 ; 77] |
| 52 | Journal of Youth and Adolescence | 80 [71 ; 89] | 77 [70 ; 84] | 72 [66 ; 79] |
| 53 | Memory | 77 [71 ; 84] | 77 [70 ; 83] | 71 [65 ; 77] |
| 54 | European Journal of Social Psychology | 82 [75 ; 89] | 77 [69 ; 84] | 61 [53 ; 69] |
| 55 | Social Psychology | 81 [73 ; 90] | 77 [67 ; 86] | 73 [63 ; 82] |
| 56 | Perception | 82 [74 ; 88] | 76 [72 ; 81] | 78 [74 ; 83] |
| 57 | Journal of Anxiety Disorders | 80 [71 ; 89] | 76 [72 ; 80] | 71 [67 ; 75] |
| 58 | Personal Relationships | 65 [54 ; 76] | 76 [68 ; 84] | 62 [54 ; 70] |
| 59 | Evolutionary Psychology | 63 [51 ; 75] | 76 [67 ; 85] | 77 [68 ; 86] |
| 60 | Journal of Research in Personality | 63 [46 ; 77] | 76 [67 ; 84] | 70 [61 ; 79] |
| 61 | Cognitive Behaviour Therapy | 88 [73 ; 99] | 76 [66 ; 86] | 68 [58 ; 79] |
| 62 | Emotion | 79 [73 ; 85] | 75 [72 ; 79] | 67 [64 ; 71] |
| 63 | Animal Behavior | 79 [72 ; 87] | 75 [71 ; 80] | 68 [64 ; 73] |
| 64 | Group Processes & Intergroup Relations | 80 [73 ; 87] | 75 [71 ; 80] | 60 [56 ; 65] |
| 65 | JPSP-Personality Processes and Individual Differences | 78 [70 ; 86] | 75 [70 ; 79] | 64 [59 ; 69] |
| 66 | Psychology of Men and Masculinity | 88 [77 ; 96] | 75 [64 ; 87] | 78 [67 ; 89] |
| 67 | Consciousness and Cognition | 74 [67 ; 80] | 74 [69 ; 80] | 67 [62 ; 73] |
| 68 | Personality and Social Psychology Bulletin | 78 [72 ; 84] | 74 [69 ; 79] | 57 [52 ; 62] |
| 69 | Journal of Cognition and Development | 70 [60 ; 80] | 74 [67 ; 81] | 65 [59 ; 72] |
| 70 | Journal of Applied Psychology | 69 [59 ; 78] | 74 [67 ; 80] | 73 [66 ; 79] |
| 71 | European Journal of Personality | 80 [67 ; 92] | 74 [65 ; 83] | 70 [61 ; 79] |
| 72 | Journal of Positive Psychology | 75 [65 ; 86] | 74 [65 ; 83] | 66 [57 ; 75] |
| 73 | Journal of Research on Adolescence | 83 [74 ; 92] | 74 [62 ; 87] | 67 [55 ; 79] |
| 74 | Psychopharmacology | 75 [69 ; 80] | 73 [71 ; 75] | 67 [65 ; 69] |
| 75 | Frontiers in Psychology | 75 [70 ; 79] | 73 [70 ; 76] | 72 [69 ; 75] |
| 76 | Cognitive Therapy and Research | 73 [66 ; 81] | 73 [68 ; 79] | 67 [62 ; 73] |
| 77 | Behaviour Research and Therapy | 70 [63 ; 77] | 73 [67 ; 79] | 70 [64 ; 76] |
| 78 | Journal of Educational Psychology | 82 [73 ; 89] | 73 [67 ; 79] | 76 [70 ; 82] |
| 79 | British Journal of Social Psychology | 74 [65 ; 83] | 73 [66 ; 81] | 61 [54 ; 69] |
| 80 | Organizational Behavior and Human Decision Processes | 70 [65 ; 77] | 72 [69 ; 75] | 67 [63 ; 70] |
| 81 | Cognition and Emotion | 75 [68 ; 81] | 72 [68 ; 76] | 72 [68 ; 76] |
| 82 | Journal of Affective Disorders | 75 [69 ; 83] | 72 [68 ; 76] | 74 [71 ; 78] |
| 83 | Behavioural Brain Research | 76 [71 ; 80] | 72 [67 ; 76] | 70 [66 ; 74] |
| 84 | Child Development | 81 [75 ; 88] | 72 [66 ; 78] | 68 [62 ; 74] |
| 85 | Journal of Abnormal Psychology | 71 [60 ; 82] | 72 [66 ; 77] | 65 [60 ; 71] |
| 86 | Journal of Vocational Behavior | 70 [59 ; 82] | 72 [65 ; 79] | 84 [77 ; 91] |
| 87 | Journal of Experimental Child Psychology | 72 [66 ; 78] | 71 [69 ; 74] | 72 [69 ; 75] |
| 88 | Journal of Consulting and Clinical Psychology | 81 [73 ; 88] | 71 [64 ; 78] | 62 [55 ; 69] |
| 89 | Psychology of Music | 78 [67 ; 86] | 71 [64 ; 78] | 79 [72 ; 86] |
| 90 | Behavior Therapy | 78 [69 ; 86] | 71 [63 ; 78] | 70 [63 ; 78] |
| 91 | Journal of Occupational and Organizational Psychology | 66 [51 ; 79] | 71 [62 ; 80] | 87 [79 ; 96] |
| 92 | Journal of Happiness Studies | 75 [65 ; 83] | 71 [61 ; 81] | 79 [70 ; 89] |
| 93 | Journal of Occupational Health Psychology | 77 [65 ; 90] | 71 [58 ; 83] | 65 [52 ; 77] |
| 94 | Journal of Individual Differences | 77 [62 ; 92] | 71 [51 ; 90] | 74 [55 ; 94] |
| 95 | Frontiers in Behavioral Neuroscience | 70 [63 ; 76] | 70 [66 ; 75] | 66 [62 ; 71] |
| 96 | Journal of Applied Social Psychology | 76 [67 ; 84] | 70 [63 ; 76] | 70 [64 ; 77] |
| 97 | British Journal of Developmental Psychology | 72 [62 ; 81] | 70 [62 ; 79] | 76 [67 ; 85] |
| 98 | Journal of Social and Personal Relationships | 73 [63 ; 81] | 70 [60 ; 79] | 69 [60 ; 79] |
| 99 | Behavioral Neuroscience | 65 [57 ; 73] | 69 [64 ; 75] | 69 [63 ; 75] |
| 100 | Psychology and Marketing | 71 [64 ; 77] | 69 [64 ; 74] | 67 [63 ; 72] |
| 101 | Journal of Family Psychology | 71 [59 ; 81] | 69 [63 ; 75] | 62 [56 ; 68] |
| 102 | Journal of Personality | 71 [57 ; 85] | 69 [62 ; 77] | 64 [57 ; 72] |
| 103 | Journal of Consumer Behaviour | 70 [60 ; 81] | 69 [59 ; 79] | 73 [63 ; 83] |
| 104 | Motivation and Emotion | 78 [70 ; 86] | 69 [59 ; 78] | 66 [57 ; 76] |
| 105 | Developmental Science | 67 [60 ; 74] | 68 [65 ; 71] | 65 [63 ; 68] |
| 106 | International Journal of Psychophysiology | 67 [61 ; 73] | 68 [64 ; 73] | 64 [60 ; 69] |
| 107 | Self and Identity | 80 [72 ; 87] | 68 [60 ; 76] | 70 [62 ; 78] |
| 108 | Journal of Counseling Psychology | 57 [41 ; 71] | 68 [55 ; 81] | 79 [66 ; 92] |
| 109 | Health Psychology | 63 [50 ; 73] | 67 [62 ; 72] | 67 [61 ; 72] |
| 110 | Hormones and Behavior | 67 [58 ; 73] | 66 [63 ; 70] | 66 [62 ; 70] |
| 111 | Frontiers in Human Neuroscience | 68 [62 ; 75] | 66 [62 ; 70] | 76 [72 ; 80] |
| 112 | Annals of Behavioral Medicine | 63 [53 ; 75] | 66 [60 ; 71] | 71 [65 ; 76] |
| 113 | Journal of Child Psychology and Psychiatry and Allied Disciplines | 58 [45 ; 69] | 66 [55 ; 76] | 63 [53 ; 73] |
| 114 | Infancy | 77 [69 ; 85] | 65 [56 ; 73] | 58 [50 ; 67] |
| 115 | Biological Psychology | 64 [58 ; 70] | 64 [61 ; 67] | 66 [63 ; 69] |
| 116 | Social Development | 63 [54 ; 73] | 64 [56 ; 72] | 74 [66 ; 82] |
| 117 | Developmental Psychobiology | 62 [53 ; 70] | 63 [58 ; 68] | 67 [62 ; 72] |
| 118 | Journal of Consumer Research | 59 [53 ; 67] | 63 [55 ; 71] | 58 [50 ; 66] |
| 119 | Psychoneuroendocrinology | 63 [53 ; 72] | 62 [58 ; 66] | 61 [57 ; 65] |
| 120 | Journal of Consumer Psychology | 64 [55 ; 73] | 62 [57 ; 67] | 60 [55 ; 65] |








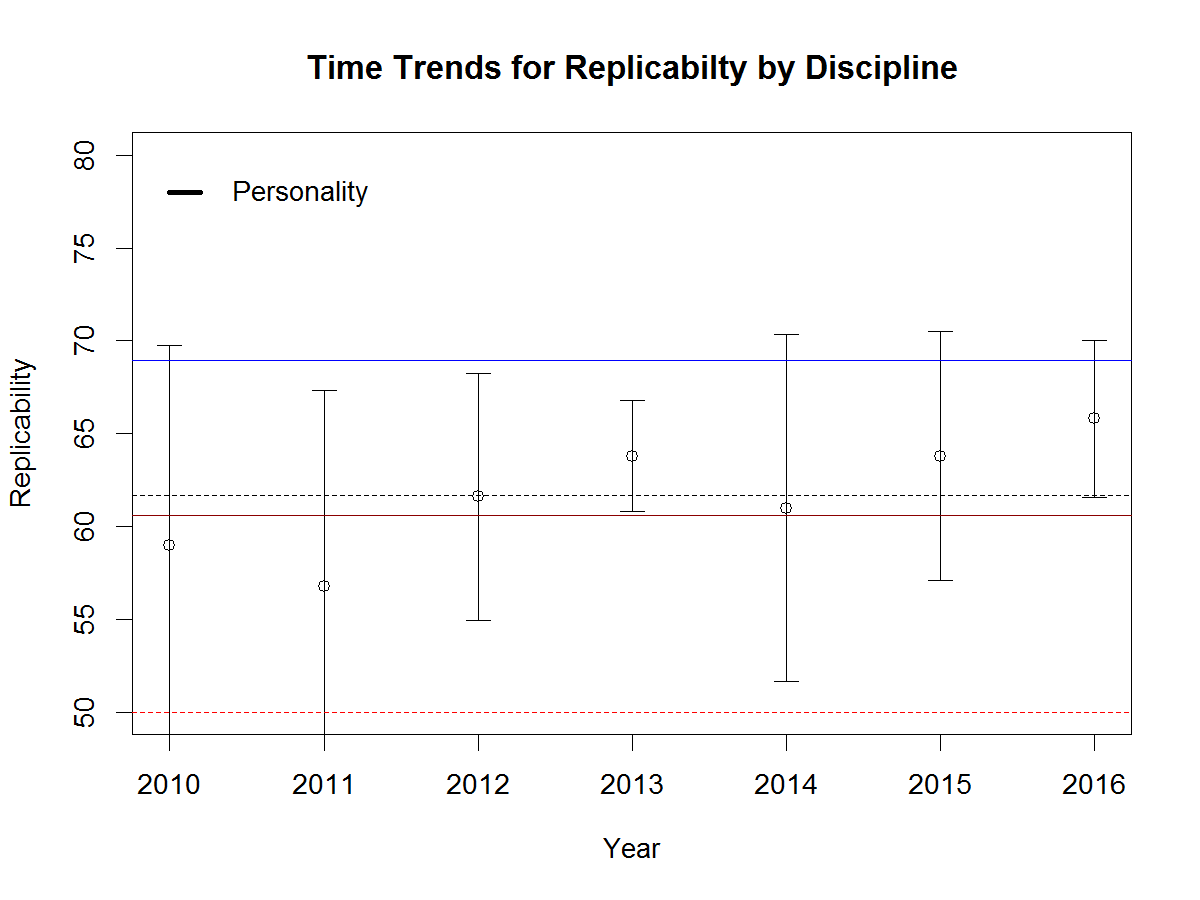


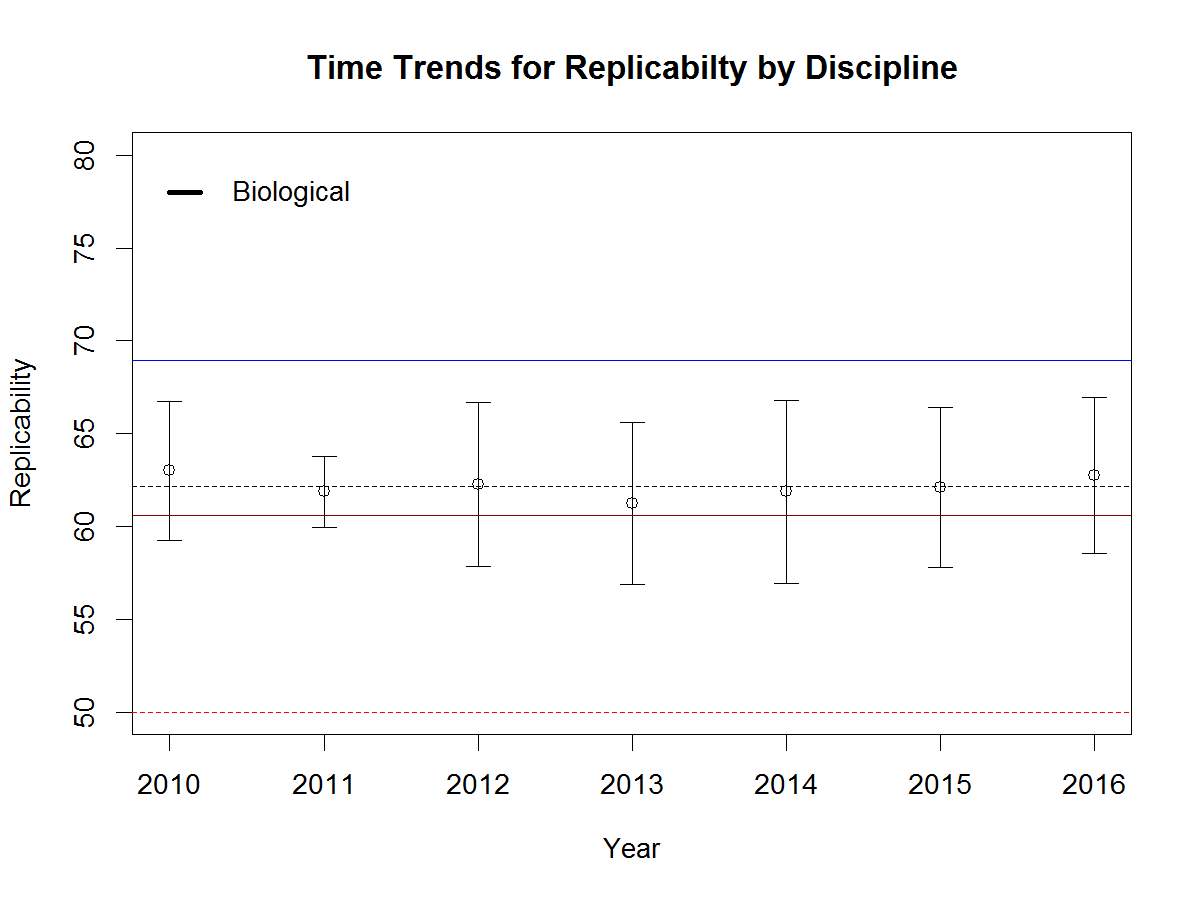



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}