The article by Stroebe and Strack (2014) [henceforth S&S] illustrates how experimental social psychologists responded to replication failures in the beginning of the replicability revolution. The response is a classic example of repressive coping: Houston, we do not have a problem. Even in 2014, problems with the way experimental social psychologists had conducted research for decades were obvious (Bem, 2011; Wagenmakers et al., 2011; John et al., 2012; Francis, 2012; Schimmack, 2012; Hasher & Wagenmakers, 2012). S&S article is an attempt to dismiss these concerns as misunderstandings and empirically unsupported criticism.
“In contrast to the prevalent sentiment, we will argue that the claim of a replicability crisis is greatly exaggerated” (p. 59).
Although the article was well received by prominent experimental social psychologists (see citations in appendix), future events proved S&S wrong and vindicated critics of research methods in experimental social psychology. Only a year later, the Open Science Collaboration (2015) reported that only 25% of studies in social psychology could be replicated successfully. A statistical analysis of focal hypothesis tests in social psychology suggests that roughly 50% of original studies could be replicated successfully if these studies were replicated exactly (Motyl et al., 2017). Ironically, one of S&S’s point is that exact replication studies are impossible. As a result, the 50% estimate is an optimistic estimate of the success rate for actual replication studies, suggesting that the actual replicability of published results in social psychology is less than 50%.
Thus, even if S&S had reasons to be skeptical about the extent of the replicability crisis in experimental social psychology, it is now clear that experimental social psychology has a serious replication problem. Many published findings in social psychology textbooks may not replicate and many theoretical claims in social psychology rest on shaky empirical foundations.
What explains the replication problem in experimental social psychology? The main reason for replication failures is that social psychology journals mostly published significant results. The selective publishing of significant results is called publication bias. Sterling pointed out that publication bias in psychology is rampant. He found that psychology journals publish over 90% significant results (Sterling, 1959; Sterling et al., 1995). Given new estimates that the actual success rate of studies in experimental social psychology is less than 50%, only publication bias can explain why journals publish over 90% results that confirm theoretical predictions.
It is not difficult to see that reporting only studies that confirm predictions undermines the purpose of empirical tests of theoretical predictions. If studies that do not confirm predictions are hidden, it is impossible to obtain empirical evidence that a theory is wrong. In short, for decades experimental social psychologists have engaged in a charade that pretends that theories are empirically tested, but publication bias ensured that theories would never fail. This is rather similar to Volkswagen’s emission tests that were rigged to pass because emissions were never subjected to a real test.
In 2014, there were ample warning signs that publication bias and other dubious practices inflated the success rate in social psychology journals. However, S&S claim that (a) there is no evidence for the use of questionable research practices and (b) that it is unclear which practices are questionable or not.
“Thus far, however, no solid data exist on the prevalence of such research practices in either social or any other area of psychology. In fact, the discipline still needs to reach an agreement about the conditions under which these practices are unacceptable” (p. 60).
Scientists like to hedge their statements so that they are immune to criticism. S&S may argue that the evidence in 2014 was not “solid” and surely there was and still is no agreement about good research practices. However, this is irrelevant. What is important is that success rates in social psychology journals were and still are inflated by suppressing disconfirming evidence and biasing empirical tests of theories in favor of positive outcomes.
Although S&S’s main claims are not based on empirical evidence, it is instructive to examine how they tried to shield published results and established theories from the harsh light of open replication studies that report results without selection for significance and subject social psychological theories to real empirical tests for the first time.
Failed Replication of Between-Subject Priming Studies
S&S discuss failed replications of two famous priming studies in social psychology: Bargh’s elderly priming study and Dijksterhuis’s professor priming studies. Both seminal articles reported several successful tests of the prediction that a subtle priming manipulation would influence behavior without participants even noticing the priming effect. In 2012, Doyen et al., failed to replicate elderly priming. Schanks et al. (2013) failed to replicate professor priming effects and more recently a large registered replication report also provided no evidence for professor priming. For naïve readers it is surprising that original studies had a 100% success rate and replication studies had a 0% success rate. However, S&S are not surprised at all.
“as in most sciences, empirical findings cannot always be replicated” (p. 60).
Apparently, S&S knows something that naïve readers do not know. The difference between naïve readers and experts in the field is that experts have access to unpublished information about failed replications in their own labs and in the labs of their colleagues. Only they know how hard it sometimes was to get the successful outcomes that were published. With the added advantage of insider knowledge, it makes perfect sense to expect replication failures, although may be not 0%.
The problem is that S&S give the impression that replication failures are too be expected, but that this expectation cannot be based on the objective scientific record that hardly ever reports results that contradict theoretical predictions. Replication failures occur all the time, but they remained unpublished. Doyen et al. and Schanks et al.’s articles only violated the code to publish only supportive evidence.
Kahneman’s Train Wreck Letter
S&S also comment on Kahneman’s letter to Bargh that compared priming research to a train wreck. In response S&S claim that
“priming is an entirely undisputed method that is widely used to test hypotheses about associative memory (e.g., Higgins, Rholes, & Jones, 1977; Meyer & Schvaneveldt, 1971; Tulving & Schacter, 1990).” (p. 60).
This argument does not stand the test of time. Since S&S published their article researchers have distinguished more clearly between highly replicable priming effects in cognitive psychology with repeated measures and within-subject designs and difficult to replicate between-subject social priming studies with subtle priming manipulations and a single outcome measure (BS social priming). With regards to BS social priming, it is unclear which of these effects can be replicated and leading social psychologists have been reluctant to demonstrate replicability of their famous studies by conducting self-replications as they were encouraged to do in Kahneman’s letter.
S&S also point to empirical evidence for robust priming effects.
“A meta-analysis of studies that investigated how trait primes influence impression formation identified 47 articles based on 6,833 participants and found overall effects to be statistically highly significant (DeCoster & Claypool, 2004).” (p. 60).
The problem with this evidence is that this meta-analysis did not take publication bias into account; in fact, it does not even mention publication bias as a possible problem. A meta-analysis of studies that were selected for significance produces is also biased by selection for significance.
Several years after Kahneman’s letter, it is widely agreed that past research on social priming is a train wreck. Kahneman published a popular book that celebrated social priming effects as a major scientific discovery in psychology. Nowadays, he agrees with critiques that the existing evidence is not credible. It is also noteworthy that none of the researchers in this area have followed Kahneman’s advice to replicate their own findings to show the world that these effects are real.
It is all a big misunderstanding
S&S suggest that “the claim of a replicability crisis in psychology is based on a major misunderstanding.” (p. 60).
Apparently, lay people, trained psychologists, and a Noble laureate are mistaken in their interpretation of replication failures. S&S suggest that failed replications are unimportant.
“the myopic focus on “exact” replications neglects basic epistemological principles” (p. 60).
To make their argument, they introduce the notion of exact replications and suggest that exact replication studies are uninformative.
“a finding may be eminently reproducible and yet constitute a poor test of a theory.” (p. 60).
The problem with this line of argument is that we are supposed to assume that a finding is eminently reproducible, which probably means it has been successfully replicate many times. It seems sensible that further studies of gender differences in height are unnecessary to convince us that there is a gender difference in height. However, results in social psychology are not like gender differences in height. According to S&S own accord earlier, “empirical findings cannot always be replicated” (p. 60). And if journals only publish significant results, it remains unknown which results are eminently reproducible and which results are not. S&S ignore publication bias and pretend that the published record suggests that all findings in social psychology are eminently reproducible. Apparently, they would suggest that even Bem’s findings that people have supernatural abilities is eminently reproducible. These days, few social psychologists are willing to endorse this naïve interpretation of the scientific record as a credible body of empirical facts.
Exact Replication Studies are Meaningful if they are Successful
Ironically, S&S next suggest that exact replication studies can be useful.
Exact replications are also important when studies produce findings that are unexpected and only loosely connected to a theoretical framework. Thus, the fact that priming individuals with the stereotype of the elderly resulted in a reduction of walking speed was a finding that was unexpected. Furthermore, even though it was consistent with existing theoretical knowledge, there was no consensus about the processes that mediate the impact of the prime on walking speed. It was therefore important that Bargh et al. (1996) published an exact replication of their experiment in the same paper.
Similarly, Dijksterhuis and van Knippenberg (1998) conducted four studies in which they replicated the priming effects. Three of these studies contained conditions that were exact replications.
Because it is standard practice in publications of new effects, especially of effects that are surprising, to publish one or two exact replications, it is clearly more conducive to the advancement of psychological knowledge to conduct conceptual replications rather than attempting further duplications of the original study.
Given these citations it is problematic that S&S article is often cited to claim that exact replications are impossible or unnecessary. The argument that S&S are making here is rather different. They are suggesting that original articles already provide sufficient evidence that results in social psychology are eminently reproducible because original articles report multiple studies and some of these studies are often exact replication studies. At face value, S&S have a point. An honest series of statistically significant results makes it practically impossible that an effect is a false positive result (Schimmack, 2012). The problem is that multiple study articles are not honest reports of all replication attempts. Francis (2014) found that at least 80% of multiple study articles showed statistical evidence of questionable research practices. Given the pervasive influence of selection for significance, exact replication studies in original articles provide no information about the replicability of these results.
What made the failed replications by Doyen et al. and Shank et al. so powerful was that these studies were the first real empirical tests of BS social priming effects because the authors were willing to report successes or failures. The problem for social psychology is that many textbook findings that were obtained with selection for significance cannot be reproduced in honest empirical tests of the predicted effects. This means that the original effects were either dramatically inflated or may not exist at all.
Replication Studies are a Waste of Resources
S&S want readers to believe that replication studies are a waste of resources.
Given that both research time and money are scarce resources, the large scale attempts at duplicating previous studies seem to us misguided” (p. 61).
This statement sounds a bit like a plea to spare social psychology from the embarrassment of actual empirical tests that reveal the true replicability of textbook findings. After all, according to S&S it is impossible to duplicate original studies (i.e., conduct exact replication studies) because replication studies differ in some way from original studies and may not reproduce the original results. So, none of the failed replication studies is an exact replication. Doyen et al. replicate Bargh’s study that was conducted in New York city in Belgium and Shanks et al. replicated Dijksterhuis’s studies from the Netherlands in the United States. The finding that the original results could not be replicate the original results does not imply that the original findings were false positives, but they do imply that these findings may be unique to some unspecified specifics of the original studies. This is noteworthy when original results are used in textbook as evidence for general theories and not as historical accounts of what happened in one specific socio-cultural context during a specific historic period. As social situations and human behavior are never exact replications of the past, social psychological results need to be permanently replicated and doing so is not a waste of resources. Suggesting that replications is a waste of resources is like suggesting that measuring GDP or unemployment every year is a waste of resources because we can just use last-year’s numbers.
As S&S ignore publication bias and selection for significance, they are also ignoring that publication bias leads to a massive waste of resources. First, running empirical tests of theories that are not reported is a waste of resources. Second, publishing only significant results is also a waste of resources because researchers design new studies based on the published record. When the published record is biased, many new studies will fail, just like airplanes who are designed based on flawed science would drop from the sky. Thus, a biased literature creates a massive waste of resources.
Ultimately, a science that publishes only significant result wastes all resources because the outcome of the published studies is a foregone conclusion: the prediction was supported, p < .05. Social psychologists might as well publish purely theoretical article, just like philosophers in the old days used “thought experiments” to support their claims. An empirical science is only a real science if theoretical predictions are subjected to tests that can fail. By this simple criterion, experimental social psychology is not (yet) a science.
Should Psychologists Conduct Exact Replications or Conceptual Replications?
Strobe and Strack’s next cite Pashler and Harris (2012) to claim that critiques of experimental social psychology have dismissed the value of so-called conceptual replications and generalize.
The main criticism of conceptual replications is that they are less informative than exact replications (e.g., Pashler & Harris, 2012).”
Before I examine S&S’s counterargument, it is important to realize that S&S misrepresented, and maybe misunderstood, Pashler and Harris’s main point. Here is the relevant quote from Pashler and Harris’s article.
We speculate that the harmful interaction of publication bias and a focus on conceptual rather than direct replications may even shed light on some of the famous and puzzling “pathological science” cases that embarrassed the natural sciences at several points in the 20th century (e.g., Polywater; Rousseau & Porto, 1970; and cold fusion; Taubes, 1993).
The problem for S&S is that they cannot address the problem of publication bias and therefore carefully avoid talking about it. As a result, they misrepresent Pashler and Harris’s critique of conceptual replications in combination with publication bias as a criticism of conceptual replication studies, which is absurd and not what Pashler and Harris’s intended to say or actually said. The following quote from their article makes this crystal clear.
However, what kept faith in cold fusion alive for some time (at least in the eyes of some onlookers) was a trickle of positive results achieved using very different designs than the originals (i.e., what psychologists would call conceptual replications). This suggests that one important hint that a controversial finding is pathological may arise when defenders of a controversial effect disavow the initial methods used to obtain an effect and rest their case entirely upon later studies conducted using other methods. Of course, productive research into real phenomena often yields more refined and better ways of producing effects. But what should inspire doubt is any situation where defenders present a phenomenon as a “moving target” in terms of where and how it is elicited (cf. Langmuir, 1953/1989). When this happens, it would seem sensible to ask, “If the finding is real and yet the methods used by the original investigators are not reproducible, then how were these investigators able to uncover a valid phenomenon with methods that do not work?” Again, the unavoidable conclusion is that a sound assessment of a controversial phenomenon should focus first and foremost on direct replications of the original reports and not on novel variations, each of which may introduce independent ambiguities.
I am confident that unbiased readers will recognize that Pashler and Harris did not suggest that conceptual replication studies are bad. Their main point is that a few successful conceptual replication studies can be used to keep theories alive in the face of a string of many replication failures. The problem is not that researchers conduct successful conceptual replication studies. The problem is dismissing or outright hiding of disconfirming evidence in replication studies. S&S misconstrue Pashler and Harris’s claim to avoid addressing this real problem of ignoring and suppressing failed studies to support an attractive but false theory.
The illusion of exact replications.
S&S next argument is that replication studies are never exact.
If one accepts that the true purpose of replications is a (repeated) test of a theoretical hypothesis rather than an assessment of the reliability of a particular experimental procedure, a major problem of exact replications becomes apparent: Repeating a specific operationalization of a theoretical construct at a different point in time and/or with a different population of participants might not reflect the same theoretical construct that the same procedure operationalized in the original study.
The most important word in this quote is “might.” Ebbinghaus’s memory curve MIGHT not replicate today because he was his own subject. Bargh’s elderly priming study MIGHT not work today because Florida is no longer associated with the elderly, and Disjterhuis’s priming study MIGHT no longer works because students no longer think that professors are smart or that Hooligans are dumb.
Just because there is no certainty in inductive inferences doesn’t mean we can just dismiss replication failures because something MIGHT have changed. It is also possible that the published results MIGHT be false positives because significant results were obtained by chance, with QRPs, or outright fraud. Most people think that outright fraud is unlikely, but the Stapel debacle showed that we cannot rule it out. So, we can argue forever about hypothetical reasons why a particular study was successful or a failure. These arguments are futile and have nothing to do with scientific arguments and objective evaluation of facts.
This means that every study, whether it is a groundbreaking success or a replication failure needs to be evaluate in terms of the objective scientific facts. There is no blanket immunity for seminal studies that protects them from disconfirming evidence. No study is an exact replication of another study. That is a truism and S&S article is often cited for this simple fact. It is as true as it is irrelevant to understand the replication crisis in social psychology.
Exact Replications Are Often Uninformative
S&S contradict themselves in the use of the term exact replication. First it is impossible to do exact replications, but then they are uninformative. I agree with S&S that exact replication studies are impossible. So, we can simply drop the term “exact” and examine why S&S believe that some replication studies are uninformative.
First they give an elaborate, long and hypothetical explanation for Doyen et al.’s failure to replicate Bargh’s pair of elderly priming studies. After considering some possible explanations, they conclude
It is therefore possible that the priming procedure used in the Doyen et al. (2012) study failed in this respect, even though Doyen et al. faithfully replicated the priming procedure of Bargh et al. (1996).
Once more the realm of hypothetical conjectures has to rescue seminal findings. Just as it is possible that S&S are right it is also possible that Bargh faked his data. To be sure, I do not believe that he faked his data and I apologized for a Facebook comment that gave the wrong impression that I did. I am only raising this possibility here to make the point that everything is possible. Maybe Bargh just got lucky. The probability of this is 1 out of 1,600 attempts (the probability to get the predicted effect with .05 two-tailed (!) twice is .025^2). Not very likely, but also not impossible.
No matter what the reason for the discrepancy between Bargh and Doyen’s findings is, the example does not support S&S’s claim that replication studies are uninformative. The failed replication raised concerns about the robustness of BS social priming studies and stimulated further investigation of the robustness of social priming effects. In the short span of six years, the scientific consensus about these effects has shifted dramatically, and the first publication of a failed replication is an important event in the history of social psychology.
S&S’s critique of Shank et al.’s replication studies is even weaker. First, they have to admit that professor probably still primes intelligence more than soccer hooligans. To rescue the original finding S&S propose
“the priming manipulation might have failed to increase the cognitive representation of the concept “intelligence.”
S&S also think that
another LIKELY reason for their failure could be their selection of knowledge items.
Meanwhile a registered replication report with a design that was approved by Dijksterhuis failed to replicate the effect. Although it is possible to come up with more possible reasons for these failures, real scientific creativity is revealed in creating experimental paradigms that produce replicable results, not in coming up with many post-hoc explanations for replication failures.
Ironically, S&S even agree with my criticism of their argument.
“To be sure, these possibilities are speculative” (p. 62).
In contrast, S&S fail to consider the possibility that published significant results are false positives, even though there is actual evidence for publication bias. The strong bias against published failures may be rooted in a long history of dismissing unpublished failures that social psychologists routinely encounter in their own laboratory. To avoid the self-awareness that hiding disconfirming evidence is unscientific, social psychologists made themselves believe that minute changes in experimental procedures can ruin a study (Stapel). Unfortunately, a science that dismisses replication failures as procedural hiccups is fated to fail because it removed the mechanism that makes science self-correcting.
Failed Replications are Uninformative
S&S next suggest that “nonreplications are uninformative unless one can demonstrate that the theoretically relevant conditions were met” (p. 62).
This reverses the burden of proof. Original researchers pride themselves on innovative ideas and groundbreaking discoveries. Like famous rock stars, they are often not the best musicians, nor is it impossible for other musicians to play their songs. They get rewarded because they came up with something original. Take the Implicit Association Test as an example. The idea to use cognitive switching tasks to measure attitudes was original and Greenwald deserves recognition for inventing this task. The IAT did not revolutionize attitude research because only Tony Greenwald could get the effects. It did so because everybody, including my undergraduate students, could replicate the basic IAT effect.
However, let’s assume that the IAT effect could not have been replicated. Is it really the job of researchers who merely duplicated a study to figure out why it did not work and develop a theory under which circumstances an effect may occur or not? I do not think so. Failed replications are informative even if there is no immediate explanation why the replication failed. As Pashler and Harris’s cold fusion example shows there may not even be a satisfactory explanation after decades of research. Most probably, cold fusion never really worked and the successful outcome of the original study was a fluke or a problem of the experimental design. Nevertheless, it was important to demonstrate that the original cold fusion study could not be replicated. To ask for an explanation why replication studies fail is simply a way to make replication studies unattractive and to dismiss the results of studies that fail to produce the desired outcome.
Finally, S&S ignore that there is a simple explanation for replication failures in experimental social psychology: publication bias. If original studies have low statistical power (e.g., Bargh’s studies with N = 30) to detect small effects, only vastly inflated effect sizes reach significance. An open replication study without inflated effect sizes is unlikely to produce a successful outcome. Statistical analysis of original studies show that this explanation accounts for a large proportion of replication failures. Thus, publication bias provides one explanation for replication failures.
Conceptual Replication Studies are Informative
S&S cite Schmidt (2009) to argue that conceptual replication studies are informative.
With every difference that is introduced the confirmatory power of the replication increases, because we have shown that the phenomenon does not hinge on a particular operationalization but “generalizes to a larger area of application” (p. 93).
S&S continue
“An even more effective strategy to increase our trust in a theory is to test it using completely different manipulations.”
This is of course true as long as conceptual replication studies are successful. However, it is not clear why conceptual replication studies that for the first time try a completely different manipulation should be successful. As I pointed out in my 2012 article, reading multiple-study articles with only successful conceptual replication studies is a bit like watching a magic show.
Multiple-study articles are most common in experimental psychology to demonstrate the robustness of a phenomenon using slightly different experimental manipulations. For example, Bem (2011) used a variety of paradigms to examine ESP. Demonstrating a phenomenon in several different ways can show that a finding is not limited to very specific experimental conditions. Analogously, if Joe can hit the bull’s-eye nine times from different angles, with different guns, and in different light conditions, Joe truly must be a sharpshooter. However, the variation of experimental procedures also introduces more opportunities for biases (Ioannidis, 2005). The reason is that variation of experimental procedures allows researchers to discount null findings. Namely, it is possible to attribute nonsignificant results to problems with the experimental procedure rather than to the absence of an effect.
I don’t know whether S&S are impressed by Bem’s article with 9 conceptual replication studies that successfully demonstrated supernatural abilities. According to their line of arguments, they should be. However, even most social psychologists found it impossible to accept that time-reversed subliminal priming works. Unfortunately, this also means that successful conceptual replication studies are meaningless if only successful results are published. Once more, S&S cannot address this problem because they ignore the simple fact that selection for significance undermines the purpose of empirical research to test theoretical predictions.
Exact Replications Contribute Little to Scientific Knowledge
Without providing much evidence for their claims, S&S conclude
one reason why exact replications are not very interesting is that they contribute little to scientific knowledge.
Ironically, one year later Science published 100 replication studies with the only goal of estimating the replicability of psychology, with a focus on social psychology. The article has already been cited 640 times, while S&S’s criticism of replication studies has been cited (only) 114 times.
Although the article did nothing else then to report the outcome of replication studies, it made a tremendous empirical contribution to psychology because it reported results of studies without the filter of publication bias. Suddenly the success rate plummeted from over 90% to 37% and for social psychology to 25%. While S&S could claim in 2014 that “Thus far, however, no solid data exist on the prevalence of such [questionable] research practices in either social or any other area of psychology,” the reproducibility project revealed that these practices dramatically inflated the percentage of successful studies reported in psychology journals.
The article has been celebrated by scientists in many disciplines as a heroic effort and a sign that psychologists are trying to improve their research practices. S&S may disagree, but I consider the reproducibility project a big contribution to scientific knowledge.
Why null findings are not always that informative
To fully appreciate the absurdity of S&S’s argument, I let them speak for themselves.
One reason is that not all null findings are interesting. For example, just before his downfall, Stapel published an article on how disordered contexts promote stereotyping and discrimination. In this publication, Stapel and Lindenberg (2011) reported findings showing that litter or a broken-up sidewalk and an abandoned bicycle can increase social discrimination. These findings, which were later retracted, were judged to be sufficiently important and interesting to be published in the highly prestigious journal Science. Let us assume that Stapel had actually conducted the research described in this paper and failed to support his hypothesis. Such a null finding would have hardly merited publication in the Journal of Articles in Support of the Null Hypothesis. It would have been uninteresting for the same reason that made the positive result interesting, namely, that (a) nobody expected a relationship between disordered environments and prejudice and (b) there was no previous empirical evidence for such a relationship. Similarly, if Bargh et al. (1996) had found that priming participants with the stereotype of the elderly did not influence walking speed or if Dijksterhuis and van Knippenberg (1998) had reported that priming participants with “professor” did not improve their performance on a task of trivial pursuit, nobody would have been interested in their findings.
Notably, all of the examples are null-findings in original studies. Thus, they have absolutely no relevance for the importance of replication studies. As noted by Strack and Stroebe earlier
Thus, null findings are interesting only if they contradict a central hypothesis derived from an established theory and/or are discrepant with a series of earlier studies.” (p. 65).
Bem (2011) reported 9 significant results to support unbelievable claims about supernatural abilities. However, several failed replication studies allowed psychologists to dismiss these findings and to ignore claims about time-reversed priming effects. So, while not all null-results are important, null-results in replication studies are important because they can correct false positive results in original articles. Without this correction mechanism, science looses its ability to correct itself.
Failed Replications Do Not Falsify Theories
S&S state that failed replications do not falsify theories
The nonreplications published by Shanks and colleagues (2013) cannot be taken as a falsification of that theory, because their study does not explain why previous research was successful in replicating the original findings of Dijksterhuis and van Knippenberg (1998).” (p. 64).
I am unaware of any theory in psychology that has been falsified. The reason for this is not that failed replication studies are not informative. The reason is that theories have been protected by hiding failed replication studies until recently. Only in recent years have social psychologists started to contemplate the possibility that some theories in social psychology might be false. The most prominent example is ego-depletion theory, which has been one of the first prominent theories that has been put under the microscope of open science without the protection of questionable research practices in recent years. While ego-depletion theory is not entirely dead, few people still believe in the simple theory that 20 Stroop trials deplete individuals’ will power. Falsification is hard, but falsification without disconfirming evidence is impossible.
Inconsistent Evidence
S&S argue that replication failures have to be evaluated in the context of replication successes.
Even multiple failures to replicate an established finding would not result in a rejection of the original hypothesis, if there are also multiple studies that supported that hypothesis.
Earlier S&S wrote
in social psychology, as in most sciences, empirical findings cannot always be replicated (this was one of the reasons for the development of meta-analytic methods).
Indeed. Unless studies have very high statistical power, inconsistent results are inevitable; which is one reason why publishing only significant results is a sign of low credibility (Schimmack, 2012). Meta-analysis is the only way to make sense of these inconsistent findings. However, it is well known that publication bias makes meta-analytic results meaningless (e.g., meta-analysis show very strong evidence for supernatural abilities). Thus, it is important that all tests of a theoretical prediction are reported to produce meaningful meta-analyses. If social psychologists would take S&S seriously and continue to suppress non-significant results because they are uninformative, meta-analysis would continue to provide biased results that support even false theories.
Failed Replications are Uninformative II
Sorry that this is getting really long. But S&S keep on making the same arguments and the editor of this article didn’t tell them to shorten the article. Here they repeat the argument that failed replications are uninformative.
One reason why null findings are not very interesting is because they tell us only that a finding could not be replicated but not why this was the case. This conflict can be resolved only if researchers develop a theory that could explain the inconsistency in findings.
A related claim is that failed replications never demonstrate that original findings were false because the inconsistency is always due to some third variable; a hidden moderator.
Methodologically, however, nonreplications must be understood as interaction effects in that they suggest that the effect of the crucial influence depends on the idiosyncratic conditions under which the original experiment was conducted” (p. 64).
These statements reveal a fundamental misunderstanding of statistical inferences. A significant result never proofs that the null-hypothesis is false. The inference that a real effect rather than sampling error caused the observed result can be a mistake. This mistake is called a false positive or a type-I error. S&S seems to believe that type-I errors do not exist. Accordingly, Bem’s significant results show real supernatural abilities. If this were the case, it would be meaningless to report statistical significance tests. The only possible error that could be made would be false negatives or type-II error; the theory makes the correct prediction, but a study failed to produce a significant result. And if theoretical predictions are always correct, it is also not necessary to subject theories to empirical tests, because these tests either correctly show that a prediction was confirmed or falsely fail to confirm a prediction.
S&S’s belief in published results has a religious quality. Apparently we know nothing about the world, but once a significant result is published in a social psychology journal, ideally JPSP, it becomes a holy truth that defies any evidence that non-believers may produce under the misguided assumption that further inquiry is necessary. Elderly priming is real, amen.
More Confusing Nonsense
At some point, I was no longer surprised by S&S’s claims, but I did start to wonder about the reviewers and editors who allowed this manuscript to be published apparently with light or no editing. Why would a self-respecting journal publish a sentence like this?
As a consequence, the mere coexistence of exact replications that are both successful and unsuccessful is likely to leave researchers helpless about what to conclude from such a pattern of outcomes.
Didn’t S&S claim that exact replication studies do not exist? Didn’t they tell readers that every inconsistent finding has to be interpreted as an interaction effect? And where do they see inconsistent results if journals never publish non-significant results?
Aside from these inconsistencies, inconsistent results do not lead to a state of helpless paralysis. As S&S suggested themselves, they conduct a meta-analysis. Are S&S suggesting that we need to spare researchers from inconsistent results to protect them from a state of helpless confusion? Is this their justification for publishing only significant results?
Even Massive Replication Failures in Registered Replication Reports are Uninformative
In response to the replication crisis, some psychologists started to invest time and resources in major replication studies called many lab studies or registered replication studies. A single study was replicated in many labs. The total sample size of many labs gives these studies high precision in estimating the average effect size and makes it even possible to demonstrate that an effect size is close to zero, which suggests that the null-hypothesis may be true. These studies have failed to find evidence for classic social psychology findings, including Strack’s facial feedback studies. S&S suggest that even these results are uninformative.
Conducting exact replications in a registered and coordinated fashion by different laboratories does not remove the described shortcomings. This is also the case if exact replications are proposed as a means to estimate the “true size” of an effect. As the size of an experimental effect always depends on the specific error variance that is generated by the context, exact replications can assess only the efficiency of an intervention in a given situation but not the generalized strength of a causal influence.
Their argument does not make any sense to me. First, it is not clear what S&S mean by “the size of an experimental effect always depends on the specific error variance.” Neither unstandardized nor standardized effect sizes depend on the error variance. This is simple to see because error variance depends on the sample size and effect sizes do not depend on sample size. So, it makes no sense to claim that effect sizes depend on error variance.
Second, it is not clear what S&S mean by specific error variance that is generated by the context. I simply cannot address this argument because the notion of context generated specific error variance is not a statistical construct and S&S do not explain what they are talking about.
Finally, it is not clear why meta-analysis of replication studies cannot be used to estimate the generalized strength of a causal influence, which I believe to mean “an effect size”? Earlier S&S alluded to meta-analysis as a way to resolve inconsistencies in the literature, but now they seem to suggest that meta-analysis cannot be used.
If S&S really want to imply that meta-analyses are useless, it is unclear how they would make sense of inconsistent findings. The only viable solution seems to be to avoid inconsistencies by suppressing non-significant results in order to give the impression that every theory in social psychology is correct because theoretical predictions are always confirmed. Although this sounds absurd, it is the inevitable logical consequence of S&S’s claim that non-significant results are uninformative, even if over 20 labs independently and in combination failed to provide evidence for a theoretical predicted effect.
The Great History of Social Psychological Theories
S&S next present Über-social psychologist, Leon Festinger, as an example why theories are good and failed studies are bad. The argument is that good theories make correct predictions, even if bad studies fail to show the effect.
“Although their theoretical analysis was valid, it took a decade before researchers were able to reliably replicate the findings reported by Festinger and Carlsmith (1959).”
As a former student, I was surprised by this statement because I had learned that Festinger’s theory was challenged by Bem’s theory and that social psychologists had been unable to resolve which of the two theories was correct. Couldn’t some of these replication failures be explained by the fact that Festinger’s theory sometimes made the wrong prediction?
It is also not surprising that researchers had a hard time replicating Festinger and Carlsmith original findings. The reason is that the original study had low statistical power and replication failures are expected even if the theory is correct. Finally, I have been around social psychologists long enough to have heard some rumors about Festinger and Carlsmith’s original studies. Accordingly, some of Festinger’s graduate students also tried and failed to get the effect. Carlsmith was the ‘lucky’ one who got the effect, in one study p < .05, and he became the co-author of one of the most cited articles in the history of social psychology. Naturally, Festinger did not publish the failed studies of his other graduate students because surely they must have done something wrong. As I said, that is a rumor. Even if the rumor is not true, and Carlsmith got lucky on the first try, luck played a factor and nobody should expect that a study replicates simply because a single published study reported a p-value less than .05.
Failed Replications Did Not Influence Social Psychological Theories
Argument quality reaches a new low with the next argument against replication studies.
“If we look at the history of social psychology, theories have rarely been abandoned because of failed replications.”
This is true, but it reveals the lack of progress in theory development in social psychology rather than the futility of replication studies. From an evolutionary perspective, theory development requires selection pressure, but publication bias protects bad theories from failure.
The short history of open science shows how weak social psychological theories are and that even the most basic predictions cannot be confirmed in open replication studies that do not selectively report significant results. So, even if it is true that failed replications have played a minor role in the past of social psychology, they are going to play a much bigger role in the future of social psychology.
The Red Herring: Fraud
S&S imply that Roediger suggested to use replication studies as a fraud detection tool.
if others had tried to replicate his [Stapel’s] work soon after its publication, his misdeeds might have been uncovered much more quickly
S&S dismiss this idea in part on the basis of Stroebe’s research on fraud detection.
To their own surprise, Stroebe and colleagues found that replications hardly played any role in the discovery of these fraud cases.
Now this is actually not surprising because failed replications were hardly ever published. And if there is no variance in a predictor variable (significance), we cannot see a correlation between the predictor variable and an outcome (fraud). Although failed replication studies may help to detect fraud in the future, this is neither their primary purpose, nor necessary to make replication studies valuable. Replication studies also do not bring world peace or bring an end to global warming.
For some inexplicable reason S&S continue to focus on fraud. For example, they also argue that meta-analyses are poor fraud detectors, which is as true as it is irrelevant.
They conclude their discussion with an observation by Stapel, who famously faked 50+ articles in social psychology journals.
As Stapel wrote in his autobiography, he was always pleased when his invented findings were replicated: “What seemed logical and was fantasized became true” (Stapel, 2012). Thus, neither can failures to replicate a research finding be used as indicators of fraud, nor can successful replications be invoked as indication that the original study was honestly conducted.
I am not sure why S&S spend so much time talking about fraud, but it is the only questionable research practice that they openly address. In contrast, they do not discuss other questionable research practices, including suppressing failed studies, that are much more prevalent and much more important for the understanding of the replication crisis in social psychology than fraud. The term “publication bias” is not mentioned once in the article. Sometimes what is hidden is more significant than what is being published.
Conclusion
The conclusion section correctly predicts that the results of the reproducibility project will make social psychology look bad and that social psychology will look worse than other areas of psychology.
But whereas it will certainly be useful to be informed about studies that are difficult to replicate, we are less confident about whether the investment of time and effort of the volunteers of the Open Science Collaboration is well spent on replicating studies published in three psychology journals. The result will be a reproducibility coefficient that will not be greatly informative, because of justified doubts about whether the “exact” replications succeeded in replicating the theoretical conditions realized in the original research.
As social psychologists, we are particularly concerned that one of the outcomes of this effort will be that results from our field will be perceived to be less “reproducible” than research in other areas of psychology. This is to be expected because for the reasons discussed earlier, attempts at “direct” replications of social psychological studies are less likely than exact replications of experiments in psychophysics to replicate the theoretical conditions that were established in the original study.
Although psychologists should not be complacent, there seem to be no reasons to panic the field into another crisis. Crises in psychology are not caused by methodological flaws but by the way people talk about them (Kruglanski & Stroebe, 2012).
S&S attribute the foreseen (how did they know?) bad outcome in the reproducibility project to the difficulty of replicating social psychological studies, but they fail to explain why social psychology journals publish as many successes as other disciplines.
The results of the reproducibility project provide an answer to this question. Social psychologists use designs with less statistical power that have a lower chance of producing a significant result. Selection for significance ensures that the success rate is equally high in all areas of psychology, but lower power makes these successes less replicable.
To avoid further embarrassments in an increasingly open science, social psychologists must improve the statistical power of their studies. Which social psychological theories will survive actual empirical tests in the new world of open science is unclear. In this regard, I think it makes more sense to compare social psychology to a ship wreck than a train wreck. Somewhere down on the floor of the ocean is some gold. But it will take some deep diving and many failed attempts to find it. Good luck!
Appendix
S&S’s article was published in a “prestigious” psychology journal and has already garnered 114 citations. It ranks #21 in my importance rankings of articles in meta-psychology. So, I was curious why the article gets cited. The appendix lists 51 citing articles with the relevant citation and the reason for citing S&S’s article. The table shows the reasons for citations in decreasing order of frequency.
S&S are most frequently cited for the claim that exact replications are impossible, followed by the reason for this claim that effects in psychological research are sensitive to the unique context in which a study is conducted. The next two reasons for citing the article are that only conceptual replications (CR) test theories, whereas the results of exact replications (ER) are uninformative. The problem is that every study is a conceptual replication because exact replications are impossible. So, even if exact replications were uninformative this claim has no practical relevance because there are no exact replications. Some articles cite S&S with no specific claim attached to the citation. Only two articles cite them for the claim that there is no replication crisis and only 1 citation cites S&S for the claim that there is no evidence about the prevalence of QRPs. In short, the article is mostly cited for the uncontroversial and inconsequential claim that exact replications are impossible and that effect sizes in psychological studies can vary as a function of unique features of a particular sample or study. This observation is inconsequential because it is unclear how unknown unique characteristics of studies influence results. The main implication of this observation is that study results will be more variable than we would expect from a set of exact replication studies. For this reason, meta-analysts often use random-effects model because fixed-effects meta-analysis assumes that all studies are exact replications.
| ER impossible |
11 |
| Contextual Sensitivity |
8 |
| CR test theory |
8 |
| ER uninformative |
7 |
| Mention |
6 |
| ER/CR Distinction |
2 |
| No replication crisis |
2 |
| Disagreement |
1 |
| CR Definition |
1 |
| ER informative |
1 |
| ER useful for applied research |
1 |
| ER cannot detect fraud |
1 |
| No evidence about prevalence of QRP |
1 |
| Contextual sensitivity greater in social psychology |
1 |
the most influential citing articles and the relevant citation. I haven’t had time to do a content analysis, but the article is mostly cited to say (a) exact replications are impossible, and (b) conceptual replications are valuable, and (c) social psychological findings are harder to replicate. Few articles cite to article to claim that the replication crisis is overblown or that failed replications are uninformative. Thus, even though the article is cited a lot, it is not cited for the main points S&S tried to make. The high number of citation therefore does not mean that S&S’s claims have been widely accepted.
(Disagreement)
The value of replication studies.
Simmons, DJ.
“In this commentary, I challenge these claims.”
(ER/CR Distinction)
Bilingualism and cognition.
Valian, V.
“A host of methodological issues should be resolved. One is whether the field should undertake exact replications, conceptual replications, or both, in order to determine the conditions under which effects are reliably obtained (Paap, 2014; Simons, 2014; Stroebe & Strack, 2014).”
(Contextual Sensitivity)
Is Psychology Suffering From a Replication Crisis? What Does “Failure to Replicate” Really Mean?“
Maxwell et al. (2015)
A particular replication may fail to confirm the results of an original study for a variety of reasons, some of which may include intentional differences in procedures, measures, or samples as in a conceptual replication (Cesario, 2014; Simons, 2014; Stroebe & Strack, 2014).”
(ER impossible)
The Chicago face database: A free stimulus set of faces and norming data
Debbie S. Ma, Joshua Correll, & Bernd Wittenbrink.
The CFD will also make it easier to conduct exact replications, because researchers can use the same stimuli employed by other researchers (but see Stroebe & Strack, 2014).”
(Contextual Sensitivity)
“Contextual sensitivity in scientific reproducibility”
vanBavel et al. (2015)
“Many scientists have also argued that the failure to reproduce results might reflect contextual differences—often termed “hidden moderators”—between the original research and the replication attempt”
(Contextual Sensitivity)
Editorial Psychological Science
Linday,
As Nosek and his coauthors made clear, even ideal replications of ideal studies are expected to fail some of the time (Francis, 2012), and failure to replicate a previously observed effect can arise from differences between the original and replication studies and hence do not necessarily indicate flaws in the original study (Maxwell, Lau, & Howard, 2015; Stroebe & Strack, 2014). Still, it seems likely that psychology journals have too often reported spurious effects arising from Type I errors (e.g., Francis, 2014).
(ER impossible)
Best Research Practices in Psychology: Illustrating Epistemological and Pragmatic Considerations With the Case of Relationship Science
Finkel et al. (2015).
“Nevertheless, many scholars believe that direct replications are impossible in the human sciences—S&S (2014) call them “an illusion”— because certain factors, such as a moment in historical time or the precise conditions under which a sample was obtained and tested, that may have contributed to a result can never be reproduced identically.”
Conceptualizing and evaluating the replication of research results
Fabrigar and Wegener (2016)
(CR test theory)
“Traditionally, the primary presumed strength of conceptual replications has been their ability to address issues of construct validity (e.g., Brewer & Crano, 2014; Schmidt, 2009; Stroebe & Strack, 2014). “
(ER impossible)
“First, it should be recognized that an exact replication in the strictest sense of the term can never be achieved as it will always be impossible to fully recreate the contextual factors and participant characteristics present in the original experiment (see Schmidt (2009); S&S (2014).”
(Contextual Sensitivity)
“S&S (2014) have argued that there is good reason to expect that many traditional and contemporary experimental manipulations in social psychology would have different psychological properties and effects if used in contexts or populations different from the original experiments for which they were developed. For example, classic dissonance manipulations and fear manipulations or more contemporary priming procedures might work very differently if used in new contexts and/or populations. One could generate many additional examples beyond those mentioned by S&S.”
(ER impossible)
“Another important point illustrated by the above example is that the distinction between exact and conceptual replications is much more nebulous than many discussions of replication would suggest. Indeed, some critics of the exact/conceptual replication distinction have gone so far as to argue that the concept of exact replication is an “illusion” (Stroebe & Strack, 2014). Though we see some utility in the exact/conceptual distinction (especially regarding the goal of the researcher in the work), we agree with the sentiments expressed by S&S. Classifying studies on the basis of the exact/conceptual distinction is more difficult than is often appreciated, and the presumed strengths and weaknesses of the approaches are less straightforward than is often asserted or assumed.”
(Contextual Sensitivity)
“Furthermore, assuming that these failed replication experiments have used the same operationalizations of the independent and dependent variables, the most common inference drawn from such failures is that confidence in the existence of the originally demonstrated effect should be substantially undermined (e.g., see Francis (2012); Schimmack (2012)). Alternatively, a more optimistic interpretation of such failed replication experiments could be that the failed versus successful experiments differ as a function of one or more unknown moderators that regulate the emergence of the effect (e.g., Cesario, 2014; Stroebe & Strack, 2014).”
Replicating Studies in Which Samples of Participants Respond to Samples of Stimuli.
(CR Definition)
Westfall et al. (2015).
Nevertheless, the original finding is considered to be conceptually replicated if it can be convincingly argued that the same theoretical constructs thought to account for the results of the original study also account for the results of the replication study (Stroebe & Strack, 2014). Conceptual replications are thus “replications” in the sense that they establish the reproducibility of theoretical interpretations.”
(Mention)
“Although establishing the generalizability of research findings is undoubtedly important work, it is not the focus of this article (for opposing viewpoints on the value of conceptual replications, see Pashler & Harris, 2012; Stroebe & Strack, 2014).“
Introduction to the Special Section on Advancing Our Methods and Practices
(Mention)
Ledgerwood, A.
We can and surely should debate which problems are most pressing and which solutions most suitable (e.g., Cesario, 2014; Fiedler, Kutzner, & Krueger, 2012; Murayama, Pekrun, & Fiedler, 2013; Stroebe & Strack, 2014). But at this point, most can agree that there are some real problems with the status quo.
***Theory Building, Replication, and Behavioral Priming: Where Do We Need to Go From Here?
Locke, EA
(ER impossible)
As can be inferred from Table 1, I believe that the now popular push toward “exact” replication (e.g., see Simons, 2014) is not the best way to go. Everyone agrees that literal replication is impossible (e.g., Stroebe & Strack, 2014), but let us assume it is as close as one can get. What has been achieved?
The War on Prevention: Bellicose Cancer: Metaphors Hurt (Some) Prevention Intentions”
(CR test theory)
David J. Hauser1 and Norbert Schwarz
“As noted in recent discussions (Stroebe & Strack, 2014), consistent effects of multiple operationalizations of a conceptual variable across diverse content domains are a crucial criterion for the robustness of a theoretical approach.”
ON THE OTHER SIDE OF THE MIRROR: PRIMING IN COGNITIVE AND SOCIAL PSYCHOLOGY
Doyen et al. “
(CR test theory)
In contrast, social psychologists assume that the primes activate culturally and situationally contextualized representations (e.g., stereotypes, social norms), meaning that they can vary over time and culture and across individuals. Hence, social psychologists have advocated the use of “conceptual replications” that reproduce an experiment by relying on different operationalizations of the concepts under investigation (Stroebe & Strack, 2014). For example, in a society in which old age is associated not with slowness but with, say, talkativeness, the outcome variable could be the number of words uttered by the subject at the end of the experiment rather than walking speed.”
***Welcome back Theory
Ap Dijksterhuis
(ER uninformative)
“it is unavoidable, and indeed, this commentary is also about replication—it is done against the background of something we had almost forgotten: theory! S&S (2014, this issue) argue that focusing on the replication of a phenomenon without any reference to underlying theoretical mechanisms is uninformative”
On the scientific superiority of conceptual replications for scientific progress
Christian S. Crandall, Jeffrey W. Sherman
(ER impossible)
But in matters of social psychology, one can never step in the same river twice—our phenomena rely on culture, language, socially primed knowledge and ideas, political events, the meaning of questions and phrases, and an ever-shifting experience of participant populations (Ramscar, 2015). At a certain level, then, all replications are “conceptual” (Stroebe & Strack, 2014), and the distinction between direct and conceptual replication is continuous rather than categorical (McGrath, 1981). Indeed, many direct replications turn out, in fact, to be conceptual replications. At the same time, it is clear that direct replications are based on an attempt to be as exact as possible, whereas conceptual replications are not.
***Are most published social psychological findings false?
Stroebe, W.
(ER uninformative)
This near doubling of replication success after combining original and replication effects is puzzling. Because these replications were already highly powered, the increase is unlikely to be due to the greater power of a meta-analytic synthesis. The two most likely explanations are quality problems with the replications or publication bias in the original studies or. An evaluation of the quality of the replications is beyond the scope of this review and should be left to the original authors of the replicated studies. However, the fact that all replications were exact rather than conceptual replications of the original studies is likely to account to some extent for the lower replication rate of social psychological studies (Stroebe & Strack, 2014). There is no evidence either to support or to reject the second explanation.”
(ER impossible)
“All four projects relied on exact replications, often using the material used in the original studies. However, as I argued earlier (Stroebe & Strack, 2014), even if an experimental manipulation exactly replicates the one used in the original study, it may not reflect the same theoretical variable.”
(CR test theory)
“Gergen’s argument has important implications for decisions about the appropriateness of conceptual compared to exact replication. The more a phenomenon is susceptible to historical change, the more conceptual replication rather than exact replication becomes appropriate (Stroebe & Strack, 2014).”
(CR test theory)
“Moonesinghe et al. (2007) argued that any true replication should be an exact replication, “a precise processwhere the exact same finding is reexamined in the same way”. However, conceptual replications are often more informative than exact replications, at least in studies that are testing theoretical predictions (Stroebe & Strack, 2014). Because conceptual replications operationalize independent and/or dependent variables in a different way, successful conceptual replications increase our trust in the predictive validity of our theory.”
There’s More Than One Way to Conduct a Replication Study: Beyond Statistical Significance”
Anderson & Maxwell
(Mention)
“It is important to note some caveats regarding direct (exact) versus conceptual replications. While direct replications were once avoided for lack of originality, authors have recently urged the field to take note of the benefits and importance of direct replication. According to Simons (2014), this type of replication is “the only way to verify the reliability of an effect” (p. 76). With respect to this recent emphasis, the current article will assume direct replication. However, despite the push toward direct replication, some have still touted the benefits of conceptual replication (Stroebe & Strack, 2014). Importantly, many of the points and analyses suggested in this paper may translate well to conceptual replication.”
Reconceptualizing replication as a sequence of different studies: A replication typology
Joachim Hüffmeier, Jens Mazei, Thomas Schultze
(ER impossible)
The first type of replication study in our typology encompasses exact replication studies conducted by the author(s) of an original finding. Whereas we must acknowledge that replications can never be “exact” in a literal sense in psychology (Cesario, 2014; Stroebe & Strack, 2014), exact replications are studies that aspire to be comparable to the original study in all aspects (Schmidt, 2009). Exact replications—at least those that are not based on questionable research practices such as the arbitrary exclusion of critical outliers, sampling or reporting biases (John, Loewenstein, & Prelec, 2012; Simmons, Nelson, & Simonsohn, 2011)—serve the function of protecting against false positive effects (Type I errors) right from the start.
(ER informative)
Thus, this replication constitutes a valuable contribution to the research process. In fact, already some time ago, Lykken (1968; see also Mummendey, 2012) recommended that all experiments should be replicated before publication. From our perspective, this recommendation applies in particular to new findings (i.e., previously uninvestigated theoretical relations), and there seems to be some consensus that new findings should be replicated at least once, especially when they were unexpected, surprising, or only loosely connected to existing theoretical models (Stroebe & Strack, 2014; see also Giner-Sorolla, 2012; Murayama et al., 2014).”
(Mention)
Although there is currently some debate about the epistemological value of close replication studies (e.g., Cesario, 2014; LeBel & Peters, 2011; Pashler & Harris, 2012; Simons, 2014; Stroebe & Strack, 2014), the possibility that each original finding can—in principal—be replicated by the scientific community represents a cornerstone of science (Kuhn, 1962; Popper, 1992).”
(CR test theory)
So far, we have presented “only” the conventional rationale used to stress the importance of close replications. Notably, however, we will now add another—and as we believe, logically necessary—point originally introduced by S&S (2014). This point protects close replications from being criticized (cf. Cesario, 2014; Stroebe & Strack, 2014; see also LeBel & Peters, 2011). Close replications can be informative only as long as they ensure that the theoretical processes investigated or at least invoked by the original study are shown to also operate in the replication study.
(CR test theory)
The question of how to conduct a close replication that is maximally informative entails a number of methodological choices. It is important to both adhere to the original study proceedings (Brandt et al., 2014; Schmidt, 2009) and focus on and meticulously measure the underlying theoretical mechanisms that were shown or at least proposed in the original studies (Stroebe & Strack, 2014). In fact, replication attempts are most informative when they clearly demonstrate either that the theoretical processes have unfolded as expected or at which point in the process the expected results could no longer be observed (e.g., a process ranging from a treatment check to a manipulation check and [consecutive] mediator variables to the dependent variable). Taking these measures is crucial to rule out that a null finding is simply due to unsuccessful manipulations or changes in a manipulation’s meaning and impact over time (cf. Stroebe & Strack, 2014). “
(CR test theory)
Conceptual replications in laboratory settings are the fourth type of replication study in our typology. In these replications, comparability to the original study is aspired to only in the aspects that are deemed theoretically relevant (Schmidt, 2009; Stroebe & Strack, 2014). In fact, most if not all aspects may differ as long as the theoretical processes that have been studied or at least invoked in the original study are also covered in a conceptual replication study in the laboratory.”
(ER useful for applied research)
For instance, conceptual replications may be less important for applied disciplines that focus on clinical phenomena and interventions. Here, it is important to ensure that there is an impact of a specific intervention and that the related procedure does not hurt the members of the target population (e.g., Larzelere et al., 2015; Stroebe & Strack, 2014).”
From intrapsychic to ecological theories in social psychology: Outlines of a functional theory approach
Klaus Fiedler
(ER uninformative)
Replicating an ill-understood finding is like repeating a complex sentence in an unknown language. Such a “replication” in the absence of deep understanding may appear funny, ridiculous, and embarrassing to a native speaker, who has full control over the foreign language. By analogy, blindly replicating or running new experiments on an ill-understood finding will rarely create real progress (cf. Stroebe & Strack, 2014). “
Into the wild: Field research can increase both replicability and real-world impact
Jon K. Maner
(CR test theory)
Although studies relying on homogeneous samples of laboratory or online participants might be highly replicable when conducted again in a similar homogeneous sample of laboratory or online participants, this is not the key criterion (or at least not the only criterion) on which we should judge replicability (Westfall, Judd & Kenny, 2015; see also Brandt et al., 2014; Stroebe & Strack, 2014). Just as important is whether studies replicate in samples that include participants who reflect the larger and more diverse population.”
Romance, Risk, and Replication: Can Consumer Choices and Risk-Taking Be Primed by Mating Motives?
Shanks et al.
(ER impossible)
There is no such thing as an “exact” replication (Stroebe & Strack, 2014) and hence it must be acknowledged that the published studies (notwithstanding the evidence for p-hacking and/or publication bias) may have obtained genuine effects and that undetected moderator variables explain why the present studies failed to obtain priming. Some of the experiments reported here differed in important ways from those on which they were modeled (although others were closer replications and even these failed to obtain evidence of reliable romantic priming).
(CR test theory)
As S&S (2014) point out, what is crucial is not so much exact surface replication but rather identical operationalization of the theoretically relevant variables. In the present case, the crucial factors are the activation of romantic motives and the appropriate assessment of consumption, risk-taking, and other measures.”
A Duty to Describe: Better the Devil You Know Than the Devil You Don’t
Brown, Sacha D et al.
(Mention)
Ioannidis (2005) has been at the forefront of researchers identifying factors interfering with self-correction. He has claimed that journal editors selectively publish positive findings and discriminate against study replications, permitting errors in data and theory to enjoy a long half-life (see also Ferguson & Brannick, 2012; Ioannidis, 2008, 2012; Shadish, Doherty, & Montgomery, 1989; Stroebe & Strack, 2014). We contend there are other equally important, yet relatively unexplored, problems.
A Room with a Viewpoint Revisited: Descriptive Norms and Hotel Guests’ Towel Reuse Behavior
(Contextual Sensitivity)
Bohner, Gerd; Schlueter, Lena E.
On the other hand, our pilot participants’ estimates of towel reuse rates were generally well below 75%, so we may assume that the guests participating in our experiments did not perceive the normative messages as presenting a surprisingly low figure. In a more general sense, the issue of greatly diverging baselines points to conceptual issues in trying to devise a ‘‘direct’’ replication: Identical operationalizations simply may take on different meanings for people in different cultures.
***The empirical benefits of conceptual rigor: Systematic articulation of conceptual hypotheses can reduce the risk of non-replicable results (and facilitate novel discoveries too)
Mark Schaller
(Contextual Sensitivity)
Unless these subsequent studies employ methods that exactly replicate the idiosyncratic context in which the effect was originally detected, these studies are unlikely to replicate the effect. Indeed, because many psychologically important contextual variables may lie outside the awareness of researchers, even ostensibly “exact” replications may fail to create the conditions necessary for a fragile effect to emerge (Stroebe & Strack, 2014)
A Concise Set of Core Recommendations to Improve the Dependability of Psychological Research
David A. Lishner
(CR test theory)
The claim that direct replication produces more dependable findings across replicated studies than does conceptual replication seems contrary to conventional wisdom that conceptual replication is preferable to direct replication (Dijksterhuis, 2014; Neulip & Crandall, 1990, 1993a, 1993b; Stroebe & Strack, 2014).
(CR test theory)
However, most arguments advocating conceptual replication over direct replication are attempting to promote the advancement or refinement of theoretical understanding (see Dijksterhuis, 2014; Murayama et al., 2014; Stroebe & Strack, 2014). The argument is that successful conceptual replication demonstrates a hypothesis (and by extension the theory from which it derives) is able to make successful predictions even when one alters the sampled population, setting, operations, or data analytic approach. Such an outcome not only suggests the presence of an organizing principle, but also the quality of the constructs linked by the organizing principle (their theoretical meanings). Of course this argument assumes that the consistency across the replicated findings is not an artifact of data acquisition or data analytic approaches that differ among studies. The advantage of direct replication is that regardless of how flexible or creative one is in data acquisition or analysis, the approach is highly similar across replication studies. This duplication ensures that any false finding based on using a flexible approach is unlikely to be repeated multiple times.
(CR test theory)
Does this mean conceptual replication should be abandoned in favor of direct replication? No, absolutely not. Conceptual replication is essential for the theoretical advancement of psychological science (Dijksterhuis, 2014; Murayama et al., 2014; Stroebe & Strack, 2014), but only if dependability in findings via direct replication is first established (Cesario, 2014; Simons, 2014). Interestingly, in instances where one is able to conduct multiple studies for inclusion in a research report, one approach that can produce confidence in both dependability of findings and theoretical generalizability is to employ nested replications.
(ER cannot detect fraud)
A second advantage of direct replications is that they can protect against fraudulent findings (Schmidt, 2009), particularly when different research groups conduct direct replication studies of each other’s research. S&S (2014) make a compelling argument that direct replication is unlikely to prove useful in detection of fraudulent research. However, even if a fraudulent study remains unknown or undetected, its impact on the literature would be lessened when aggregated with nonfraudulent direct replication studies conducted by honest researchers.
***Does cleanliness influence moral judgments? Response effort moderates the effect of cleanliness priming on moral judgments.
Huang
(ER uninformative)
Indeed, behavioral priming effects in general have been the subject of increased scrutiny (see Cesario, 2014), and researchers have suggested different causes for failed replication, such as measurement and sampling errors (Stanley and Spence,2014), variation in subject populations (Cesario, 2014), discrepancy in operationalizations (S&S, 2014), and unidentified moderators (Dijksterhuis,2014).
UNDERSTANDING PRIMING EFFECTS IN SOCIAL PSYCHOLOGY: AN OVERVIEW AND INTEGRATION
Daniel C. Molden
(ER uninformative)
Therefore, some greater emphasis on direct replication in addition to conceptual replication is likely necessary to maximize what can be learned from further research on priming (but see Stroebe and Strack, 2014, for costs of overemphasizing direct replication as well).
On the automatic link between affect and tendencies to approach and avoid: Chen and Bargh (1999) revisited
Mark Rotteveel et al.
(no replication crisis)
Although opinions differ with regard to the extent of this “replication crisis” (e.g., Pashler and Harris, 2012; S&S, 2014), the scientific community seems to be shifting its focus more toward direct replication.
(ER uninformative)
Direct replications not only affect one’s confidence about the veracity of the phenomenon under study, but they also increase our knowledge about effect size (see also Simons, 2014; but see also S&S, 2014).
Single-Paper Meta-Analysis: Benefits for Study Summary, Theory Testing, and Replicability
McShane and Bockenholt
(ER impossible)
The purpose of meta-analysis is to synthesize a set of studies of a common phenomenon. This task is complicated in behavioral research by the fact that behavioral research studies can never be direct or exact replications of one another (Brandt et al. 2014; Fabrigar and Wegener 2016; Rosenthal 1991; S&S 2014; Tsang and Kwan 1999).
(ER impossible)
Further, because behavioral research studies can never be direct or exact replications of one another (Brandt et al. 2014; Fabrigar and Wegener 2016; Rosenthal 1991; S&S 2014; Tsang and Kwan 1999), our SPM methodology estimates and accounts for heterogeneity, which has been shown to be important in a wide variety of behavioral research settings (Hedges and Pigott 2001; Klein et al. 2014; Pigott 2012).
A Closer Look at Social Psychologists’ Silver Bullet: Inevitable and Evitable Side Effects of the Experimental Approach
Herbert Bless and Axel M. Burger
(ER/CR Distinction)
Given the above perspective, it becomes obvious that in the long run, conceptual replications can provide very fruitful answers because they address the question of whether the initially observed effects are potentially caused by some perhaps unknown aspects of the experimental procedure (for a discussion of conceptual versus direct replications, see e.g., Stroebe & Strack, 2014; see also Brandt et al., 2014; Cesario, 2014; Lykken, 1968; Schwarz & Strack, 2014). Whereas conceptual replications are adequate solutions for broadening the sample of situations (for examples, see Stroebe & Strack, 2014), the present perspective, in addition, emphasizes that it is important that the different conceptual replications do not share too much overlap in general aspects of the experiment (see also Schwartz, 2015, advocating for conceptual replications)
Men in red: A reexamination of the red-attractiveness effect
Vera M. Hesslinger, Lisa Goldbach, & Claus-Christian Carbon
(ER impossible)
As Brandt et al. (2014) pointed out, a replication in psychological research will never be absolutely exact or direct (see also, Stroebe & Strack, 2014), which is, of course, also the case in the present research.
***On the challenges of drawing conclusions from p-values just below 0.05
Daniel Lakens
(no evidence about QRP)
In recent years, researchers have become more aware of how flexibility during the data-analysis can increase false positive results (e.g., Simmons, Nelson & Simonsohn, 2011). If the true Type 1 error rate is substantially inflated, for example because researchers analyze their data until a p-value smaller than 0.05 is observed, the robustness of scientific knowledge can substantially decrease. However, as Stroebe & Strack (2014, p. 60) have pointed out: ‘Thus far, however, no solid data exist on the prevalence of such research practices.’
***Does Merely Going Through the Same Moves Make for a ‘‘Direct’’ Replication? Concepts, Contexts, and Operationalizations
Norbert Schwarz and Fritz Strack
(Contextual Sensitivity)
In general, meaningful replications need to realize the psychological conditions of the original study. The easier option of merely running through technically identical procedures implies the assumption that psychological processes are context insensitive and independent of social, cultural, and historical differences (Cesario, 2014; Stroebe & Strack, 2014). Few social (let alone cross-cultural) psychologists would be willing to endorse this assumption with a straight face. If so, mere procedural equivalence is an insufficient criterion for assessing the quality of a replication.
The Replication Paradox: Combining Studies can Decrease Accuracy of Effect Size Estimates
(ER uninformative)
Michèle B. Nuijten, Marcel A. L. M. van Assen, Coosje L. S. Veldkamp, and Jelte M. Wicherts
Replications with nonsignificant results are easily dismissed with the argument that the replication might contain a confound that caused the null finding (Stroebe & Strack, 2014).
Retro-priming, priming, and double testing: psi and replication in a test-retest design
Rabeyron, T
(Mention)
Bem’s paper spawned numerous attempts to replicate it (see e.g., Galak et al., 2012; Bem et al., submitted) and reflections on the difficulty of direct replications in psychology (Ritchie et al., 2012). This aspect has been associated more generally with debates concerning the “decline effect” in science (Schooler, 2011) and a potential “replication crisis” (S&S, 2014) especially in the fields of psychology and medical sciences (De Winter and Happee, 2013).
Do p Values Lose Their Meaning in Exploratory Analyses? It Depends How You Define the Familywise Error Rate
Mark Rubin
(ER impossible)
Consequently, the Type I error rate remains constant if researchers simply repeat the same test over and over again using different samples that have been randomly drawn from the exact same population. However, this first situation is somewhat hypothetical and may even be regarded as impossible in the social sciences because populations of people change over time and location (e.g., Gergen, 1973; Iso-Ahola, 2017; Schneider, 2015; Serlin, 1987; Stroebe & Strack, 2014). Yesterday’s population of psychology undergraduate students from the University of Newcastle, Australia, will be a different population to today’s population of psychology undergraduate students from the University of Newcastle, Australia.
***Learning and the replicability of priming effects
Michael Ramscar
(ER uninformative)
In the limit, this means that in the absence of a means for objectively determining what the information that produces a priming effect is, and for determining that the same information is available to the population in a replication, all learned priming effects are scientifically unfalsifiable. (Which also means that in the absence of an account of what the relevant information is in a set of primes, and how it produces a specific effect, reports of a specific priming result — or failures to replicate it — are scientifically uninformative; see also [Stroebe & Strack, 2014.)
***Evaluating Psychological Research Requires More Than Attention to the N: A Comment on Simonsohn’s (2015) “Small Telescopes”
Norbert Schwarz and Gerald L. Clore
(CR test theory)
Simonsohn’s decision to equate a conceptual variable (mood) with its manipulation (weather) is compatible with the logic of clinical trials, but not with the logic of theory testing. In clinical trials, which have inspired much of the replicability debate and its statistical focus, the operationalization (e.g., 10 mg of a drug) is itself the variable of interest; in theory testing, any given operationalization is merely one, usually imperfect, way to realize the conceptual variable. For this reason, theory tests are more compelling when the results of different operationalizations converge (Stroebe & Strack, 2014), thus ensuring, in the case in point, that it is not “the weather” but indeed participants’ (sometimes weather-induced) mood that drives the observed effect.
Internal conceptual replications do not increase independent replication success
Kunert, R
(Contextual Sensitivity)
According to the unknown moderator account of independent replication failure, successful internal replications should correlate with independent replication success. This account suggests that replication failure is due to the fact that psychological phenomena are highly context-dependent, and replicating seemingly irrelevant contexts (i.e. unknown moderators) is rare (e.g., Barrett, 2015; DGPS, 2015; Fleming Crim, 2015; see also Stroebe & Strack, 2014; for a critique, see Simons, 2014). For example, some psychological phenomenon may unknowingly be dependent on time of day.
(Contextual Sensitivity greater in social psychology)
When the chances of unknown moderator influences are greater and replicability is achieved (internal, conceptual replications), then the same should be true when chances are smaller (independent, direct replications). Second, the unknown moderator account is usually invoked for social psychological effects (e.g. Cesario, 2014; Stroebe & Strack, 2014). However, the lack of influence of internal replications on independent replication success is not limited to social psychology. Even for cognitive psychology a similar pattern appears to hold.
On Klatzky and Creswell (2014): Saving Social Priming Effects But Losing Science as We Know It?
Barry Schwartz
(ER uninformative)
The recent controversy over what counts as “replication” illustrates the power of this presumption. Does “conceptual replication” count? In one respect, conceptual replication is a real advance, as conceptual replication extends the generality of the phenomena that were initially discovered. But what if it fails? Is it because the phenomena are unreliable, because the conceptual equivalency that justified the new study was logically flawed, or because the conceptual replication has permitted the intrusion of extraneous variables that obscure the original phenomenon? This ambiguity has led some to argue that there is no substitute for strict replication (see Pashler & Harris, 2012; Simons, 2014, and Stroebe & Strack, 2014, for recent manifestations of this controversy). A significant reason for this view, however, is less a critique of the logic of conceptual replication than it is a comment on the sociology (or politics, or economics) of science. As Pashler and Harris (2012) point out, publication bias virtually guarantees that successful conceptual replications will be published whereas failed conceptual replications will live out their lives in a file drawer. I think Pashler and Harris’ surmise is probably correct, but it is not an argument for strict replication so much as it is an argument for publication of failed conceptual replication.
Commentary and Rejoinder on Lynott et al. (2014)
Lawrence E. Williams
(CR test theory)
On the basis of their investigations, Lynott and colleagues (2014) conclude ‘‘there is no evidence that brief exposure to warm therapeutic packs induces greater prosocial responding than exposure to cold therapeutic packs’’ (p. 219). This conclusion, however, does not take into account other related data speaking to the connection between physical warmth and prosociality. There is a fuller body of evidence to be considered, in which both direct and conceptual replications are instructive. The former are useful if researchers particularly care about the validity of a specific phenomenon; the latter are useful if researchers particularly care about theory testing (Stroebe & Strack, 2014).
The State of Social and Personality Science: Rotten to the Core, Not So Bad, Getting Better, or Getting Worse?
(no replication crisis)
Motyl et al. (2017) “The claim of a replicability crisis is greatly exaggerated.” Wolfgang Stroebe and Fritz Strack, 2014
Promise, peril, and perspective: Addressing concerns about reproducibility in social–personality psychology
Harry T. Reis, Karisa Y. Lee
(ER impossible)
Much of the current debate, however, is focused narrowly on direct or exact replications—whether the findings of a given study, carried out in a particular way with certain specific operations, would be repeated. Although exact replications are surely desirable, the papers by Fabrigar and by Crandall and Sherman remind us that in an absolute sense they are fundamentally impossible in social–personality psychology (see also S&S, 2014).
Show me the money
(Contextual Sensitivity)
Of course, it is possible that additional factors, which varied or could have varied among our studies and previously published studies (e.g., participants’ attitudes toward money) or among the online studies and laboratory study in this article (e.g., participants’ level of distraction), might account for these apparent inconsistencies. We did not aim to conduct a direct replication of any specific past study, and therefore we encourage special care when using our findings to evaluate existing ones (Doyen, Klein, Simons, & Cleeremans, 2014; Stroebe & Strack, 2014).
***From Data to Truth in Psychological Science. A Personal Perspective.
Strack
(ER uninformative)
In their introduction to the 2016 volume of the Annual Review of Psychology, Susan Fiske, Dan Schacter, and Shelley Taylor point out that a replication failure is not a scientific problem but an opportunity to find limiting conditions and contextual effects. To allow non-replications to regain this constructive role, they must come with conclusions that enter and stimulate a critical debate. It is even better if replication studies are endowed with a hypothesis that relates to the state of the scientific discourse. To show that an effect occurs only under one but not under another condition is more informative than simply demonstrating noneffects (S&S, 2014). But this may require expertise and effort.







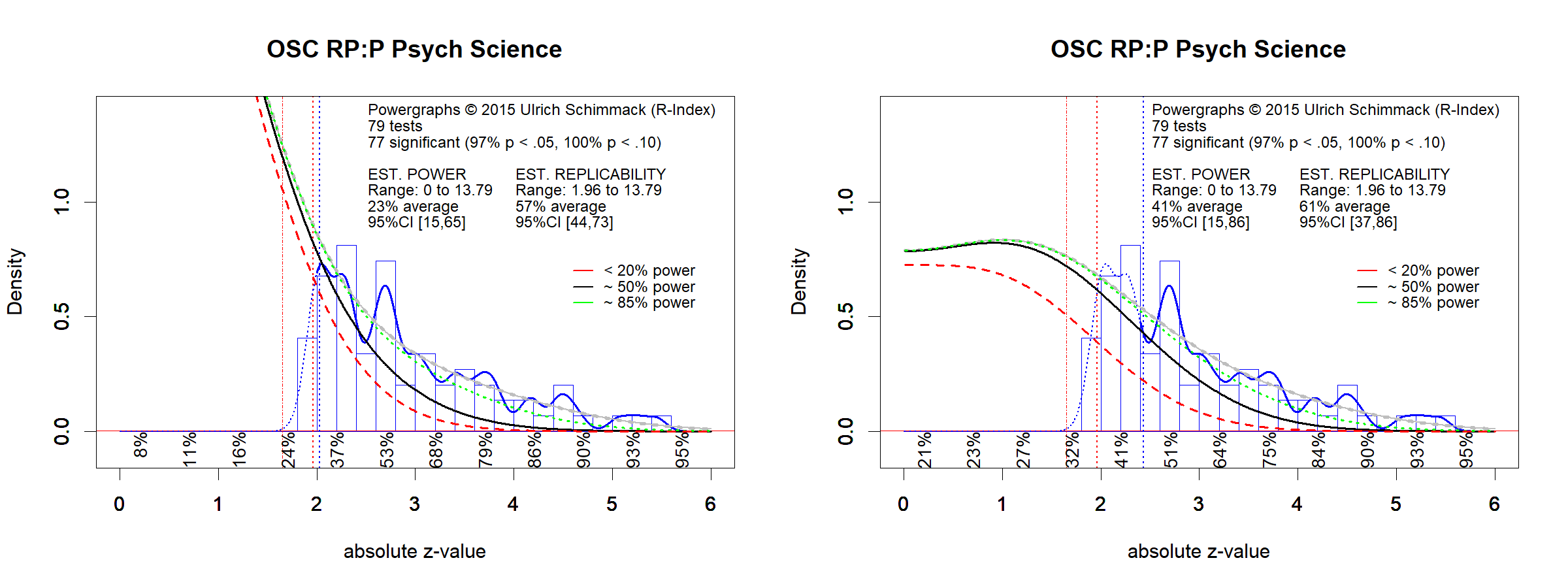

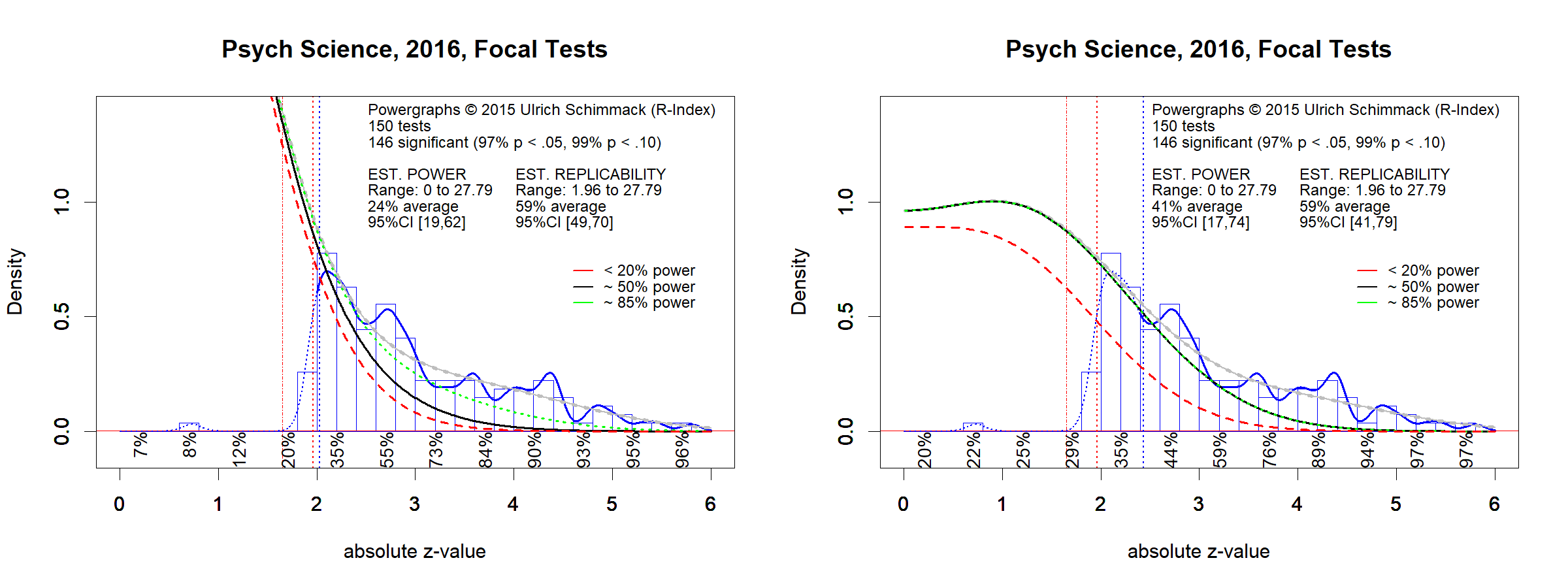



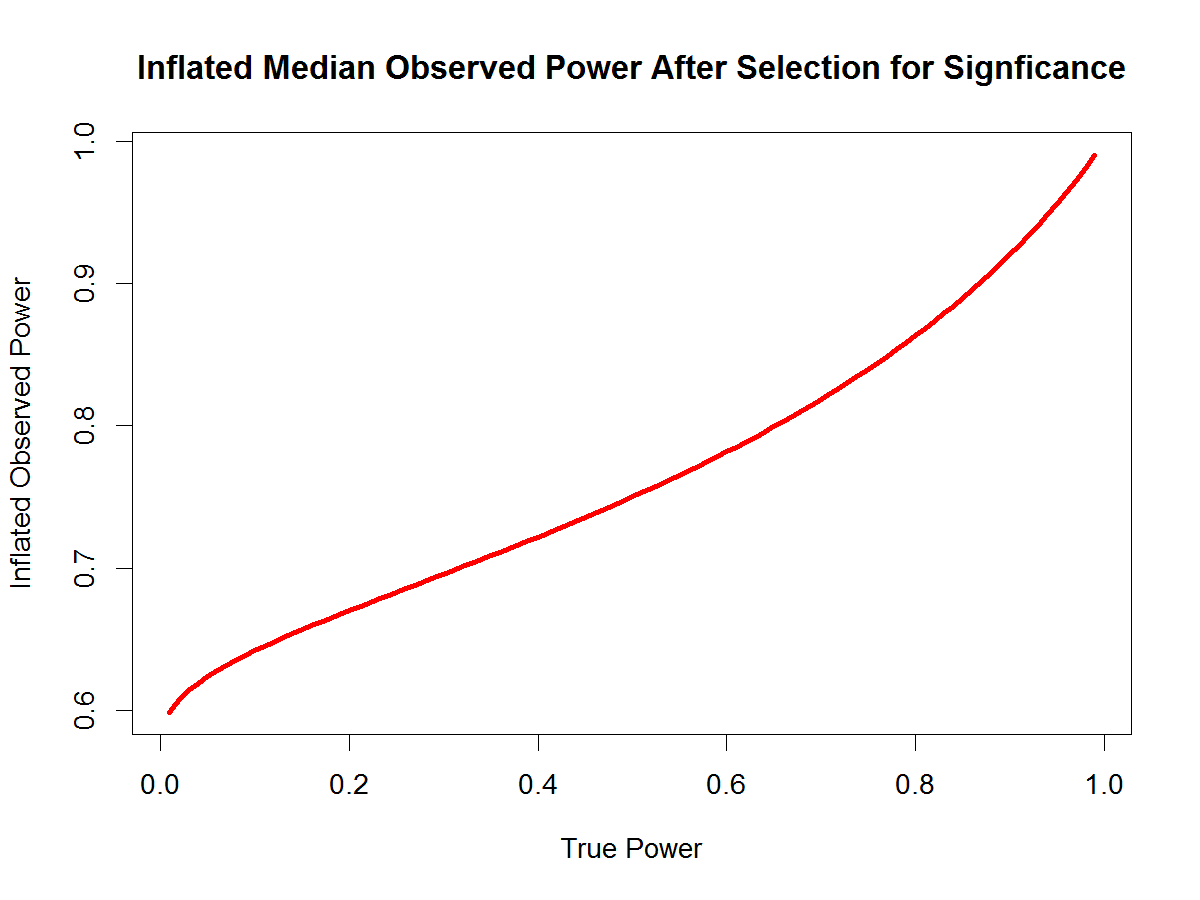


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
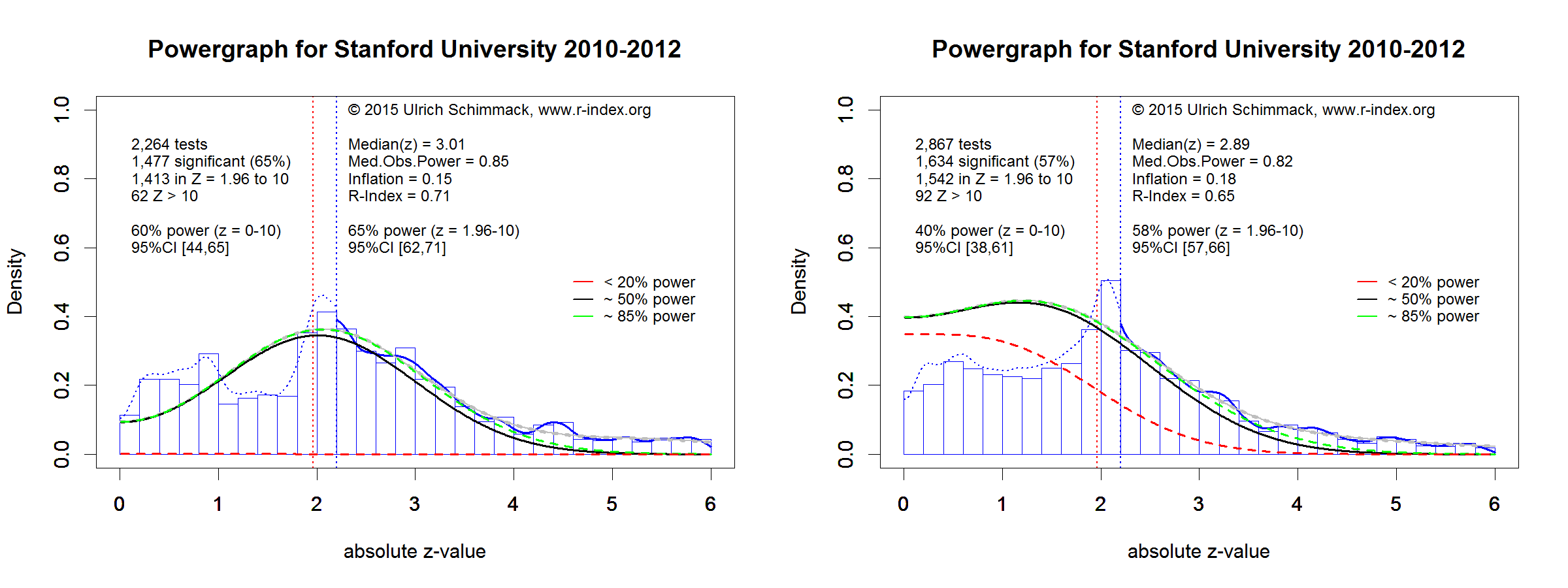{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}