
Even statistically sophisticated psychologists struggle with the interpretation of replication studies (Maxwell et al., 2015). This article gives a basic introduction to the interpretation of statistical results within the Neyman Pearson approach to statistical inferences.
I make two important points and correct some potential misunderstandings in Maxwell et al.’s discussion of replication failures. First, there is a difference between providing sufficient evidence for the null-hypothesis (evidence of absence) and providing insufficient evidence against the null-hypothesis (absence of evidence). Replication studies are useful even if they simply produce absence of evidence without evidence that an effect is absent. Second, I point out that publication bias undermines the credibility of significant results in original studies. When publication bias is present, open replication studies are valuable because they provide an unbiased test of the null-hypothesis, while original studies are rigged to reject the null-hypothesis.
DEFINITION OF REPLICATING A STATISTICAL RESULT
Replicating something means to get the same result. If I make the first free throw, replicating this outcome means to also make the second free throw. When we talk about replication studies in psychology we borrow from the common meaning of the term “to replicate.”
If we conduct psychological studies, we can control many factors, but some factors are not under our control. Participants in two independent studies differ from each other and the variation in the dependent variable across samples introduces sampling error. Hence, it is practically impossible to get identical results, even if the two studies are exact copies of each other. It is therefore more complicated to compare the results of two studies than to compare the outcome of two free throws.
To determine whether the results of two studies are identical or not, we need to focus on the outcome of a study. The most common outcome in psychological studies is a significant or non-significant result. The goal of a study is to produce a significant result and for this reason a significant result is often called a success. A successful replication study is a study that also produces a significant result. Obtaining two significant results is akin to making two free throws. This is one of the few agreements between Maxwell and me.
“Generally speaking, a published original study has in all likelihood demonstrated a statistically significant effect. In the current zeitgeist, a replication study is usually interpreted as successful if it also demonstrates a statistically significant effect.” (p. 488)
The more interesting and controversial scenario is a replication failure. That is, the original study produced a significant result (success) and the replication study produced a non-significant result (failure).
I propose that a lot of confusion arises from the distinction between original and replication studies. If a replication study is an exact copy of the first study, the outcome probabilities of original and replication studies are identical. Otherwise, the replication study is not really a replication study.
There are only three possible outcomes in a set of two studies: (a) both studies are successful, (b) one study is a success and one is a failure, or (c) both studies are failures. The probability of these outcomes depends on whether the significance criterion (the type-I error probability) when the null-hypothesis is true and the statistical power of a study when the null-hypothesis is false.
Table 1 shows the probability of the outcomes in two studies. The uncontroversial scenario of two significant results is very unlikely, if the null-hypothesis is true. With conventional alpha = .05, the probability is .0025 or 1 out of 400 attempts. This shows the value of replication studies. False positives are unlikely to repeat themselves and a series of replication studies with significant results is unlikely to occur by chance alone.
| 2 sig, 0 ns | 1 sig, 1 ns | 0 sig, 2 ns | |
| H0 is True | alpha^2 | 2*alpha*(1-alpha) | (1-alpha^2) |
| H1 is True | (1-beta)^2 | 2*(1-beta)*beta | beta^2 |
The probability of a successful replication of a true effect is a function of statistical power (1 – type-II error probability). High power is needed to get significant results in a pair of studies (an original study and a replication study). For example, if power is only 50%, the chance of this outcome is only 25% (Schimmack, 2012). Even with conventionally acceptable power of 80%, only 2/3 (64%) of replication attempts would produce this outcome. However, studies in psychology do not have 80% power and estimates of power can be as low as 37% (OSC, 2015). With 40% power, a pair of studies would produce significant results in no more than 16 out of 100 attempts. Although successful replications of true effects with low power are unlikely, they are still much more likely then significant results when the null-hypothesis is true (16/100 vs. 1/400 = 64:1). It is therefore reasonable to infer from two significant results that the null-hypothesis is false.
If the null-hypothesis is true, it is extremely likely that both studies produce a non-significant result (.95^2 = 90.25%). In contrast, it is unlikely that even a study with modest power would produce two non-significant results. For example, if power is 50%, there is a 75% chance that at least one of the two studies produces a significant result. If power is 80%, the probability of obtaining two non-significant results is only 4%. This means, it is much more likely (22.5 : 1) that the null-hypothesis is true than that the alternative hypothesis is true. This does not mean that the null-hypothesis is true in an absolute sense because power depends on the effect size. For example, if 80% power were obtained with a standardized effect size of Cohen’s d = .5, two non-significant results would suggest that the effect size is smaller than .5, but it does not warrant the conclusion that H0 is true and the effect size is exactly 0. Once more, it is important to distinguish between the absence of evidence for an effect and the evidence of absence of an effect.
The most controversial scenario assumes that the two studies produced inconsistent outcomes. Although theoretically there is no difference between the first and the second study, it is common to focus on a successful outcome followed by a replication failure (Maxwell et al., 2015). When the null-hypothesis is true, the probability of this outcome is low; .05 * (1-.05) = .0425. The same probability exists for the reverse pattern that a non-significant result is followed by a significant one. A probability of 4.25% shows that it is unlikely to observe a significant result followed by a non-significant result when the null-hypothesis is true. However, the low probability is mostly due to the low probability of obtaining a significant result in the first study, while the replication failure is extremely likely.
Although inconsistent results are unlikely when the null-hypothesis is true, they can also be unlikely when the null-hypothesis is false. The probability of this outcome depends on statistical power. A pair of studies with very high power (95%) is very unlikely to produce an inconsistent outcome because both studies are expected to produce a significant result. The probability of this rare event can be as low, or lower, than the probability with a true null effect; .95 * (1-.95) = .0425. Thus, an inconsistent result provides little information about the probability of a type-I or type-II error and is difficult to interpret.
In conclusion, a pair of significance tests can produce three outcomes. All three outcomes can occur when the null-hypothesis is true and when it is false. Inconsistent outcomes are likely unless the null-hypothesis is true or the null-hypothesis is false and power is very high. When two studies produce inconsistent results, statistical significance provides no basis for statistical inferences.
Meta-Analysis
The counting of successes and failures is an old way to integrate information from multiple studies. This approach has low power and is no longer used. A more powerful approach is effect size meta-analysis. Effect size meta-analysis was one way to interpret replication results in the Open Science Collaboration (2015) reproducibility project. Surprisingly, Maxwell et al. (2015) do not consider this approach to the interpretation of failed replication studies. To be clear, Maxwell et al. (2015) mention meta-analysis, but they are talking about meta-analyzing a larger set of replication studies, rather than meta-analyzing the results of an original and a replication study.
“This raises a question about how to analyze the data obtained from multiple studies. The natural answer is to use meta-analysis.” (p. 495)
I am going to show that effect-size meta-analysis solves the problem of interpreting inconsistent results in pairs of studies. Importantly, effect size meta-analysis does not care about significance in individual studies. A meta-analysis of a pair of studies with inconsistent results is no different from a meta-analysis of a pair of studies with consistent results.
Maxwell et al.’s (2015) introduced an example of a between-subject (BS) design with n = 40 per group (total N = 80) and a standardized effect size of Cohen’s d = .5 (a medium effect size). This study has 59% power to obtain a significant result. Thus, it is quite likely that a pair of studies produces inconsistent results (48.38%). However, a pair of studies with N = 80 has the power of a total sample size of N = 160, which means a fixed-effects meta-analysis will produce a significant result in 88% of all attempts. Thus, it is not difficult at all to interpret the results of pairs of studies with inconsistent results if the studies have acceptable power (> 50%). Even if the results are inconsistent, a meta-analysis will provide the correct answer that there is an effect most of the time.
A more interesting scenario are inconsistent results when the null-hypothesis is true. I turned to simulations to examine this scenario more closely. The simulation showed that a meta-analysis of inconsistent studies produced a significant result in 34% of all cases. The percentage slightly varies as a function of sample size. With a small sample of N = 40, the percentage is 35%. With a large sample of 1,000 participants it is 33%. This finding shows that in two-thirds of attempts, a failed replication reverses the inference about the null-hypothesis based on a significant original study. Thus, if an original study produced a false-positive results, a failed replication study corrects this error in 2 out of 3 cases. Importantly, this finding does not warrant the conclusion that the null-hypothesis is true. It merely reverses the result of the original study that falsely rejected the null-hypothesis.
In conclusion, meta-analysis of effect sizes is a powerful tool to interpret the results of replication studies, especially failed replication studies. If the null-hypothesis is true, failed replication studies can reduce false positives by 66%.
DIFFERENCES IN SAMPLE SIZES
We can all agree that, everything else being equal, larger samples are better than smaller samples (Cohen, 1990). This rule applies equally to original and replication studies. Sometimes it is recommended that replication studies should use much larger samples than original studies, but it is not clear to me why researchers who conduct replication studies should have to invest more resources than original researchers. If original researchers conducted studies with adequate power, an exact replication study with the same sample size would also have adequate power. If the original study was a type-I error, the replication study is unlikely to replicate the result no matter what the sample size. As demonstrated above, even a replication study with the same sample size as the original study can be effective in reversing false rejections of the null-hypothesis.
From a meta-analytic perspective, it does not matter whether a replication study had a larger or smaller sample size. Studies with larger sample sizes are given more weight than studies with smaller samples. Thus, researchers who invest more resources are rewarded by giving their studies more weight. Large original studies require large replication studies to reverse false inferences, whereas small original studies require only small replication studies to do the same. Nevertheless, failed replications with larger samples are more likely to reverse false rejections of the null-hypothesis, but there is no magical number about the size of a replication study to be useful.
I simulated a scenario with a sample size of N = 80 in the original study and a sample size of N = 200 in the replication study (a factor of 2.5). In this simulation, only 21% of meta-analyses produced a significant result. This is 13 percentage points lower than in the simulation with equal sample sizes (34%). If the sample size of the replication study is 10 times larger (N = 80 and N = 800), the percentage of remaining false positive results in the meta-analysis shrinks to 10%.
The main conclusion is that even replication studies with the same sample size as the original study have value and can help to reverse false positive findings. Larger sample sizes simply give replication studies more weight than original studies, but it is by no means necessary to increase sample sizes of replication studies to make replication failures meaningful. Given unlimited resources, larger replications are better, but these analysis show that large replication studies are not necessary. A replication study with the same sample size as the original study is more valuable than no replication study at all.
CONFUSING ABSENCE OF EVIDENCE WITH EVIDENCE OF ABSENCE
One problem in Maxwell et al’s (2015) article is to conflate two possible goals of replication studies. One goal is to probe the robustness of the evidence against the null-hypothesis. If the original result was a false positive result, an unsuccessful replication study can reverse the initial inference and produce a non-significant result in a meta-analysis. This finding would mean that evidence for an effect is absent. The status of a hypothesis (e.g., humans have supernatural abilities; Bem, 2011) is back to where it was before the original study found a significant result and the burden of proof is shifted back to proponents of the hypothesis to provide unbiased credible evidence for it.
Another goal of replication studies can be to provide conclusive evidence that an original study reported a false positive result (i..e, humans do not have supernatural abilities). Throughout their article, Maxwell et al. assume that the goal of replication studies is to prove the absence of an effect. They make many correct observations about the difficulties of achieving this goal, but it is not clear why replication studies have to be conclusive when original studies are not held to the same standard.
This makes it easy to produce (potentially false) positive results and very hard to remove false positive results from the literature. It also creates a perverse incentive to conduct underpowered original studies and to claim victory when a large replication study finds a significant result with an effect size that is 90% smaller than the effect size in an original study. The authors of the original article may claim that they do not care about effect sizes and that their theoretical claim was supported. To avoid this problem that replication researchers have to invest large amount of resources for little gain, it is important to realize that even a failure to replicate an original finding with the same sample size can undermine original claims and force researchers to provide stronger evidence for their original ideas in original articles. If they are right and the evidence is strong, others will be able to replicate the result in an exact replication study with the same sample size.
THE DIRTY BIG SECRET
The main problem of Maxwell et al.’s (2015) article is that the authors blissfully ignore the problem of publication bias. They mention publication bias twice to warn readers that publication bias inflates effect sizes and biases power analyses, but they completely ignore the influence of publication bias on the credibility of successful original results (Schimmack, 2012; Sterling; 1959; Sterling et al., 1995).
It is hard to believe that Maxwell is unaware of this problem, if only because Maxwell was action editor of my article that demonstrated how publication bias undermines the credibility of replication studies that are selected for significance (Schimmack, 2012).
I used Bem’s infamous article on supernatural abilities as an example, which appeared to show 8 successful replications of supernatural abilities. Ironically, Maxwell et al. (2015) also cites Bem’s article to argue that failed replication studies can be misinterpreted as evidence of absence of an effect.
“Similarly, Ritchie, Wiseman, and French (2012) state that their failure to obtain significant results in attempting to replicate Bem (2011) “leads us to favor the ‘experimental artifacts’ explanation for Bem’s original result” (p. 4)”
This quote is not only an insult to Ritchie et al.; it also ignores the concerns that have been raised about Bem’s research practices. First, Ritchie et al. do not claim that they have provided conclusive evidence against ESP. They merely express their own opinion that they “favor the ‘experimental artifacts’ explanation. There is nothing wrong with this statement, even if it is grounded in a healthy skepticism about supernatural abilities.
More important, Maxwell et al. ignore the broader context of these studies. Schimmack (2012) discussed many questionable practices in Bem’s original studies and I presented statistical evidence that the significant results in Bem’s article were obtained with the help of questionable research practices. Given this wider context, it is entirely reasonable to favor the experimental artifact explanation over the alternative hypothesis that learning after an exam can still alter the exam outcome.
It is not clear why Maxwell et al. (2015) picked Bem’s article to discuss problems with failed replication studies and ignores that questionable research practices undermine the credibility of significant results in original research articles. One reason why failed replication studies are so credible is that insiders know how incredible some original findings are.
Maxwell et al. (2015) were not aware that in the same year, the OSC (2015) reproducibilty project would replicate only 37% of statistically significant results in top psychology journals, while the apparent success rate in these journals is over 90%. The stark contrast between the apparent success rate and the true power to produce successful outcomes in original studies provided strong evidence that psychology is suffering from a replication crisis. This does not mean that all failed replications are false positives, but it does mean that it is not clear which findings are false positives and which findings are not. Whether this makes things better is a matter of opinion.
Publication bias also undermines the usefulness of meta-analysis for hypothesis testing. In the OSC reproducibility project, a meta-analysis of original and replication studies produced 68% significant results. This result is meaningless because publication bias inflates effect sizes and the probability of obtaining a false positive result in the meta-analysis. Thus, when publication bias is present, unbiased replication studies provide the most credible evidence and the large number of replication failures means that more replication studies with larger samples are needed to see which hypothesis predict real effects with practical significance.
DOES PSYCHOLOGY HAVE A REPLICATION CRISIS?
Maxwell et al.’s (2015) answer to this question is captured in this sentence. “Despite raising doubts about the extent to which apparent failures to replicate necessarily reveal that psychology is in crisis,we do not intend to dismiss concerns about documented methodological flaws in the field.” (p. 496). The most important part of this quote is “raising doubt,” the rest is Orwellian double-talk.
The whole point of Maxwell et al.’s article is to assure fellow psychologists that psychology is not in crisis and that failed replication studies should not be a major concern. As I have pointed out, this conclusion is based on some misconceptions about the purpose of replication studies and by blissful ignorance about publication bias and questionable research practices that made it possible to publish successful replications of supernatural phenomena, while discrediting authors who spend time and resources on demonstrating that unbiased replication studies fail.
The real answer to Maxwell et al.’s question was provided by the OSC (2015) finding that only 37% of published significant results could be replicated. In my opinion that is not only a crisis, but a scandal because psychologists routinely apply for funding with power analyses that claim 80% power. The reproducibilty project shows that the true power to obtain significant results in original and replication studies is much lower than this and that the 90% success rate is no more meaningful than 90% votes for a candidate in communist elections.
In the end, Maxwell et al. draw the misleading conclusion that “the proper design and interpretation of replication studies is less straightforward than conventional practice would suggest.” They suggest that “most importantly, the mere fact that a replication study yields a nonsignificant statistical result should not by itself lead to a conclusion that the corresponding original study was somehow deficient and should no longer be trusted.”
As I have demonstrated, this is exactly the conclusion that readers should draw from failed replication studies, especially if (a) the original study was not preregistered, (b) the original study produced weak evidence (e.g., p = .04), the original study was published in a journal that only publishes significant results, (d) the replication study had a larger sample, (e) the replication study would have been published independent of outcome, and (f) the replication study was preregistered.
We can only speculate why the American Psychologists published a flawed and misleading article that gives original studies the benefit of the doubt and casts doubt on the value of replication studies when they fail. Fortunately, APA can no longer control what is published because scientists can avoid the censorship of peer-reviewed journals by publishing blogs and by criticize peer-reviewed articles in open post-publication peer review on social media.
Long life the replicability revolution. !!!
REFERENCES
http://dx.doi.org/10.1037/0003-066X.45.12.1304
Maxwell, S.E, Lau, M. Y., & Howard, G. S. (2015). Is psychology suffering from a replication crisis? What does ‘failure to replicate’ really mean? American Psychologist, 70, 487-498. http://dx.doi.org/10.1037/a0039400.



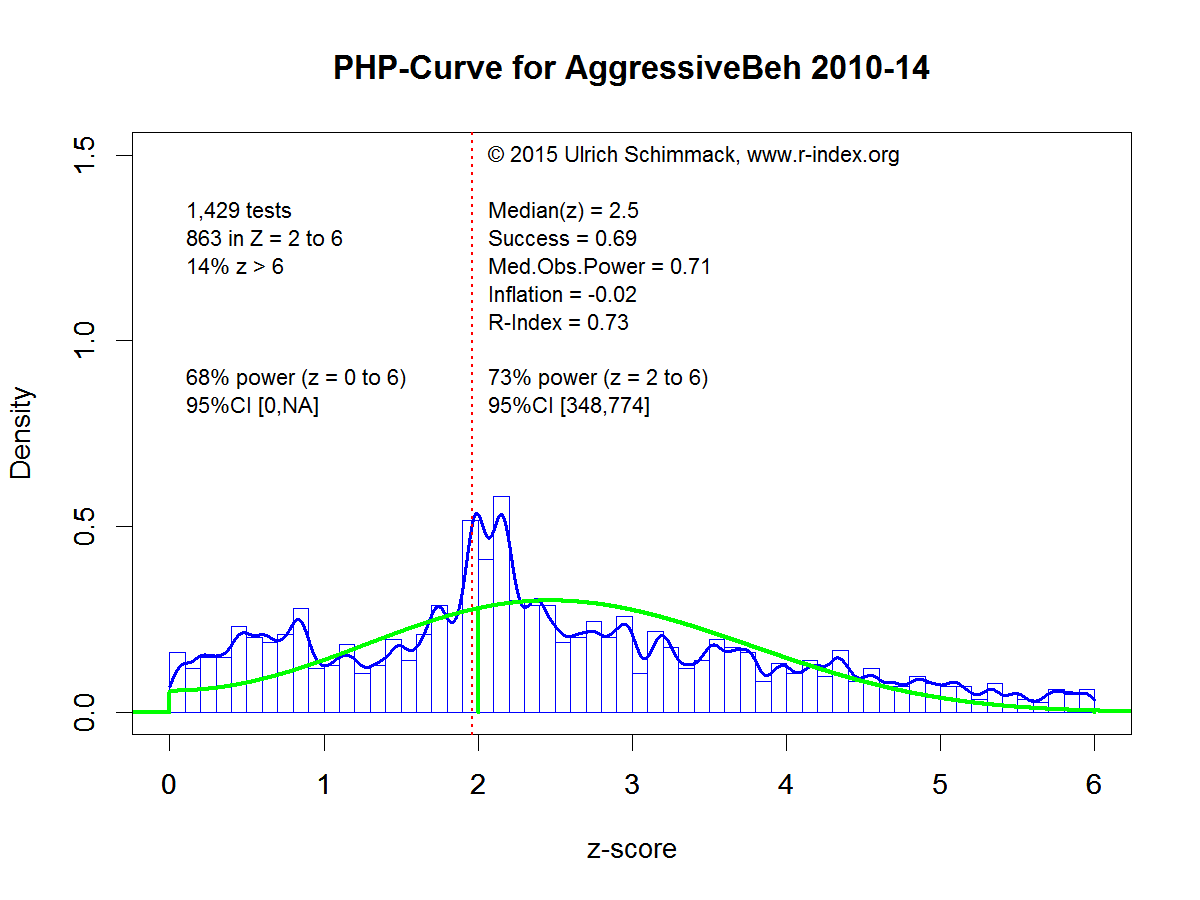
 The histogram and the blue density distribution show the observed data. The green curve shows the predicted distribution based on the post-hoc power analysis. Post-hoc power analysis suggests that the average power of significant results is 67%. Power for all statistical tests is estimated to be 58% (including 11% of z-scores greater than 6, power is .58*.89 + .11 = 63%). More important is the predicted distribution of z-scores. The predicted distribution on the left side of the criterion value matches the observed distribution rather well. This shows that there are not a lot of missing non-significant results. In other words, there does not appear to be a file-drawer of studies with non-significant results. There is also only a very small blip in the observed data just at the level of statistical significance. The close match between the observed and predicted distributions suggests that results in this journal are relatively free of systematic bias due to publication bias or questionable research practices.
The histogram and the blue density distribution show the observed data. The green curve shows the predicted distribution based on the post-hoc power analysis. Post-hoc power analysis suggests that the average power of significant results is 67%. Power for all statistical tests is estimated to be 58% (including 11% of z-scores greater than 6, power is .58*.89 + .11 = 63%). More important is the predicted distribution of z-scores. The predicted distribution on the left side of the criterion value matches the observed distribution rather well. This shows that there are not a lot of missing non-significant results. In other words, there does not appear to be a file-drawer of studies with non-significant results. There is also only a very small blip in the observed data just at the level of statistical significance. The close match between the observed and predicted distributions suggests that results in this journal are relatively free of systematic bias due to publication bias or questionable research practices.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}