2011 was an important year in the history of psychology, especially social psychology. First, it became apparent that one social psychologist had faked results for dozens of publications (https://en.wikipedia.org/wiki/Diederik_Stapel). Second, a highly respected journal published an article with the incredible claim that humans can foresee random events in the future, if they are presented without awareness (https://replicationindex.com/2018/01/05/bem-retraction/). Third, Nobel Laureate Daniel Kahneman published a popular book that reviewed his own work, but also many findings from social psychology (https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow).
It is likely that Kahneman’s book, or at least some of his chapters, would be very different from the actual book, if it had been written just a few years later. However, in 2011 most psychologists believed that most published results in their journals can be trusted. This changed when Bem (2011) was able to provide seemingly credible scientific evidence for paranormal phenomena nobody was willing to believe. It became apparent that even articles with several significant statistical results could not be trusted.
Kahneman also started to wonder whether some of the results that he used in his book were real. A major concern was that implicit priming results might not be replicable. Implicit priming assumes that stimuli that are presented outside of awareness can still influence behavior (e.g., you may have heard the fake story that a movie theater owner flashed a picture of a Coke bottle on the screen and that everybody rushed to the concession stand to buy a Coke without knowing why they suddenly wanted one). In 2012, Kahneman wrote a letter to the leading researcher of implicit priming studies, expressing his doubts about priming results, that attracted a lot of attention (Young, 2012).
Several years later, it has become clear that the implicit priming literature is not trustworthy and that many of the claims in Kahneman’s Chapter 4 are not based on solid empirical foundations (Schimmack, Heene, & Kesavan, 2017). Kahneman acknowledged this in a comment on our work (Kahneman, 2017).
We initially planned to present our findings for all chapters in more detail, but we got busy with other things. However, once in a while I am getting inquires about the other chapters (Engber). So, I am using some free time over the holidays to give a brief overview of the results for all chapters.
The Replicability Index (R-Index) is based on two statistics (Schimmack, 2016). One statistic is simply the percentage of significant results. In a popular book that discusses discoveries, this value is essentially 100%. The problem with selecting significant results from a broader literature is that significance alone, p < .05, does not provide sufficient information about true versus false discoveries. It also does not tell us how replicable a result is. Information about replicability can be obtained by converting the exact p-value into an estimate of statistical power. For example, p = .05 implies 50% power and p = .005 implies 80% power with alpha = .05. This is a simple mathematical transformation. As power determines the probability of a significant result, it also predicts the probability of a successful replication. A study with p = .005 is more likely to replicate than a study with p = .05.
There are two problems with point-estimates of power. One problem is that p-values are highly variable, which also produces high variability / uncertainty in power estimates. With a single p-value, the actual power could range pretty much from the minimum of .05 to the maximum of 1 for most power estimates. This problem is reduced in a meta-analysis of p-values. As more values become available, the average power estimate is closer to the actual average power.
The second problem is that selection of significant results (e.g., to write a book about discoveries) inflates power estimates. This problem can be addressed by comparing the success rate or discovery rate (i.e., the percentage of significant results) with the average power. Without publication bias, the discovery rate should match average power (Brunner & Schimmack, 2020). When publication bias is present, the discovery rate exceeds average power (Schimmack, 2012). Thus, the difference between the discovery rate (in this case 100%) and the average power estimates provides information about the extend of publication bias. The R-Index is a simple correction for the inflation that is introduced by selecting significant results. To correct for inflation the difference between the discovery rate and the average power estimate is subtracted from the mean power estimate. For example, if all studies are significant and the mean power estimate is 80%, the discrepancy is 20%, and the R-Index is 60%. If all studies are significant and the mean power estimate is only 60%, the R-Index is 20%.
When I first developed the R-Index, I assumed that it would be better to use the median (e.g.., power estimates of .50, .80, .90 would produce a median value of .80 and an R-Index of 60. However, the long-run success rate is determined by the mean. For example, .50, .80, .90 would produce a mean of .73, and an R-Index of 47. However, the median overestimates success rates in this scenario and it is more appropriate to use the mean. As a result, the R-Index results presented here differ somewhat from those shared publically in an article by Engber.
Table 1 shows the number of results that were available and the R-Index for chapters that mentioned empirical results. The chapters vary dramatically in terms of the number of studies that are presented (Table 1). The number of results ranges from 2 for chapters 14 and 16 to 55 for Chapter 5. For small sets of studies, the R-Index may not be very reliable, but it is all we have unless we do a careful analysis of each effect and replication studies.

Chapter 4 is the priming chapter that we carefully analyzed (Schimmack, Heene, & Kesavan, 2017).Table 1 shows that Chapter 4 is the worst chapter with an R-Index of 19. An R-Index below 50 implies that there is a less than 50% chance that a result will replicate. Tversky and Kahneman (1971) themselves warned against studies that provide so little evidence for a hypothesis. A 50% probability of answering multiple choice questions correctly is also used to fail students. So, we decided to give chapters with an R-Index below 50 a failing grade. Other chapters with failing grades are Chapter 3, 6, 711, 14, 16. Chapter 24 has the highest highest score (80, wich is an A- in the Canadian grading scheme), but there are only 8 results.
Chapter 24 is called “The Engine of Capitalism”
A main theme of this chapter is that optimism is a blessing and that individuals who are more optimistic are fortunate. It also makes the claim that optimism is “largely inherited” (typical estimates of heritability are about 40-50%), and that optimism contributes to higher well-being (a claim that has been controversial since it has been made, Taylor & Brown, 1988; Block & Colvin, 1994). Most of the research is based on self-ratings, which may inflate positive correlations between measures of optimism and well-being (cf. Schimmack & Kim, 2020). Of course, depressed individuals have lower well-being and tend to be pessimistic, but whether optimism is really preferable over realism remains an open question. Many other claims about optimists are made without citing actual studies.
Even some of the studies with a high R-Index seem questionable with the hindsight of 2020. For example, Fox et al.’s (2009) study of attentional biases and variation in the serotonin transporter gene is questionable because single-genetic variant research is largely considered unreliable today. Moreover, attentional-bias paradigms also have low reliability. Taken together, this implies that correlations between genetic markers and attentional bias measures are dramatically inflated by chance and unlikely to replicate.
Another problem with narrative reviews of single studies is that effect sizes are often omitted. For example, Puri and Robinson’s finding that optimism (estimates of how long you are going to live) and economic risk-taking are correlated is based on a large sample. This makes it possible to infer that there is a relationship with high confidence. A large sample also allows fairly precise estimates of the size of the relationship, which is a correlation of r = .09. A simple way to understand what this correlation means is to think about the increase in predicting in risk taking. Without any predictor, we have a 50% chance for somebody to be above or below the average (median) in risk-taking. With a predictor that is correlated r = .09, our ability to predict risk taking increases from 50% to 55%.
Even more problematic, the next article that is cited for a different claim shows a correlation of r = -.04 between a measure of over-confidence and risk-taking (Busenitz & Barney, 1997). In this study with a small sample (N = 124 entrepreneurs, N = 95 managers), over-confidence was a predictor of being an entrepreneur, z = 2.89, R-Index = .64.
The study by Cassar and Craig (2009) provides strong evidence for hindsight bias, R-Index = 1. Entrepreneurs who were unable to turn a start-up into an operating business underestimated how optimistic they were about their venture (actual: 80%, retrospective: 60%).
Sometimes claims are only loosely related to a cited article (Hmieleski & Baron, 2009). The statement “this reasoning leads to a hypothesis: the people who have the greatest influence on the lives of others are likely to be optimistic and overconfident, and to take more risks than they realize” is linked to a study that used optimism to predict revenue growth and employment growth. Optimism was a negative predictor, although the main claim was that the effect of optimism also depends on experience and dynamism.
A very robust effect was used for the claim that most people see themselves as above average on positive traits (e.g., overestimate their intelligence) (Williams & Gilovich, 2008), R-Index = 1. However, the meaning of this finding is still controversial. For example, the above average effect disappears when individuals are asked to rate themselves and familiar others (e.g., friends). In this case, ratings of others are more favorable than ratings of self (Kim et al., 2019).
Kahneman then does mention the alternative explanation for better-than-average effects (Windschitl et al., 2008). Namely rather than actually thinking that they are better than average, respondents simply respond positively to questions about qualities that they think they have without considering others or the average person. For example, most drivers have not had a major accident and that may be sufficient to say that they are a good driver. They then also rate themselves as better than the average driver without considering that most other drivers also did not have a major accident. R-Index = .92.
So, are most people really overconfident and does optimism really have benefits and increase happiness? We don’t really know, even 10 years after Kahneman wrote his book.
Meanwhile, the statistical analysis of published results has also made some progress. I analyzed all test statistics with the latest version of z-curve (Bartos & Schimmack, 2020). All test-statistics are converted into absolute z-scores that reflect the strength of evidence against the null-hypothesis that there is no effect.
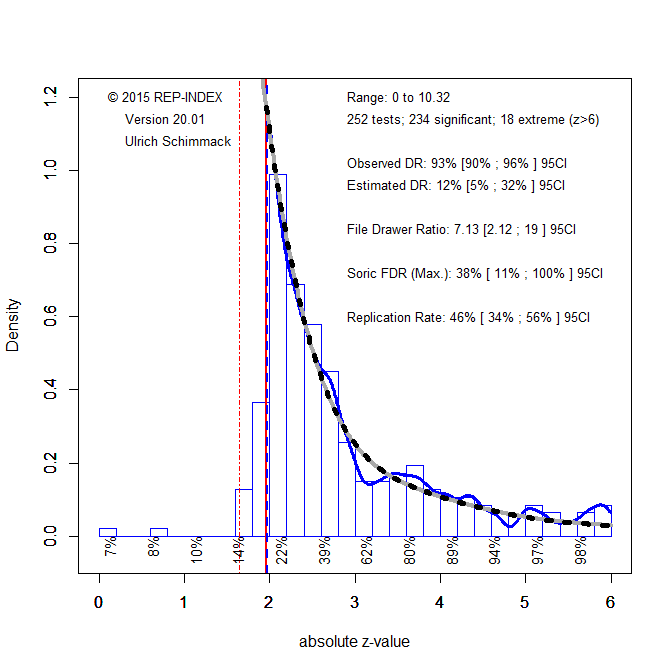
The figure shows the distribution of z-scores. As the book focussed on discoveries most test-statistics are significant with p < .05 (two-tailed, which corresponds to z = 1.96. The distribution of z-scores shows that these significant results were selected from a larger set of tests that produced non-significant results. The z-curve estimate is that the significant results are only 12% of all tests that were conducted. This is a problem.
Evidently, these results are selected from a larger set of studies that produced non-significant results. These results may not even have been published (publication bias). To estimate how replicable the significant results are, z-curve estimates the mean power of the significant results. This is similar to the R-Index, but the R-Index is only an approximate correction for information. Z-curve does properly correct for the selection for significance. The mean power is 46%, which implies that only half of the results would be replicated in exact replication studies. The success rate in actual replication studies is often lower and may be as low as the estimated discovery rate (Bartos & Schimmack, 2020). So, replicability is somewhere between 12% and 46%. Even if half of the results are replicable, we do not know which results are replicable and which one’s are not. The Chapter-based analyses provide some clues which findings may be less trustworthy (implicit priming) and which ones may be more trustworthy (overconfidence), but the main conclusion is that the empirical basis for claims in “Thinking: Fast and Slow” is shaky.
Conclusion
In conclusion, Daniel Kahneman is a distinguished psychologist who has made valuable contributions to the study of human decision making. His work with Amos Tversky was recognized with a Nobel Memorial Prize in Economics (APA). It is surely interesting to read what he has to say about psychological topics that range from cognition to well-being. However, his thoughts are based on a scientific literature with shaky foundations. Like everybody else in 2011, Kahneman trusted individual studies to be robust and replicable because they presented a statistically significant result. In hindsight it is clear that this is not the case. Narrative literature reviews of individual studies reflect scientists’ intuitions (Fast Thinking, System 1) as much or more than empirical findings. Readers of “Thinking: Fast and Slow” should read the book as a subjective account by an eminent psychologists, rather than an objective summary of scientific evidence. Moreover, ten years have passed and if Kahneman wrote a second edition, it would be very different from the first one. Chapters 3 and 4 would probably just be scrubbed from the book. But that is science. It does make progress, even if progress is often painfully slow in the softer sciences.
71 thoughts on “A Meta-Scientific Perspective on “Thinking: Fast and Slow”