
This blog post focusses on Chapter 4 about Implicit Priming in Kahneman’s book “Thinking” Fast and Slow.” A review of the book and other chapters can be found here: https://replicationindex.com/2020/12/30/a-meta-scientific-perspective-on-thinking-fast-and-slow/
Daniel Kahneman’s response to this blog post:
https://replicationindex.com/2017/02/02/reconstruction-of-a-train-wreck-how-priming-research-went-of-the-rails/comment-page-1/#comment-1454
Authors: Ulrich Schimmack, Moritz Heene, and Kamini Kesavan
Abstract:
We computed the R-Index for studies cited in Chapter 4 of Kahneman’s book “Thinking Fast and Slow.” This chapter focuses on priming studies, starting with John Bargh’s study that led to Kahneman’s open email. The results are eye-opening and jaw-dropping. The chapter cites 12 articles and 11 of the 12 articles have an R-Index below 50. The combined analysis of 31 studies reported in the 12 articles shows 100% significant results with average (median) observed power of 57% and an inflation rate of 43%. The R-Index is 14. This result confirms Kahneman’s prediction that priming research is a train wreck and readers of his book “Thinking Fast and Slow” should not consider the presented studies as scientific evidence that subtle cues in their environment can have strong effects on their behavior outside their awareness.
Introduction
In 2011, Nobel Laureate Daniel Kahneman published a popular book, “Thinking Fast and Slow”, about important finding in social psychology.
In the same year, questions about the trustworthiness of social psychology were raised. A Dutch social psychologist had fabricated data. Eventually over 50 of his articles would be retracted. Another social psychologist published results that appeared to demonstrate the ability to foresee random future events (Bem, 2011). Few researchers believed these results and statistical analysis suggested that the results were not trustworthy (Francis, 2012; Schimmack, 2012). Psychologists started to openly question the credibility of published results.
In the beginning of 2012, Doyen and colleagues published a failure to replicate a prominent study by John Bargh that was featured in Daniel Kahneman’s book. A few month later, Daniel Kahneman distanced himself from Bargh’s research in an open email addressed to John Bargh (Young, 2012):
“As all of you know, of course, questions have been raised about the robustness of priming results…. your field is now the poster child for doubts about the integrity of psychological research… people have now attached a question mark to the field, and it is your responsibility to remove it… all I have personally at stake is that I recently wrote a book that emphasizes priming research as a new approach to the study of associative memory…Count me as a general believer… My reason for writing this letter is that I see a train wreck looming.”
Five years later, Kahneman’s concerns have been largely confirmed. Major studies in social priming research have failed to replicate and the replicability of results in social psychology is estimated to be only 25% (OSC, 2015).
Looking back, it is difficult to understand the uncritical acceptance of social priming as a fact. In “Thinking Fast and Slow” Kahneman wrote “disbelief is not an option. The results are not made up, nor are they statistical flukes. You have no choice but to accept that the major conclusions of these studies are true.”
Yet, Kahneman could have seen the train wreck coming. In 1971, he co-authored an article about scientists’ “exaggerated confidence in the validity of conclusions based on small samples” (Tversky & Kahneman, 1971, p. 105). Yet, many of the studies described in Kahneman’s book had small samples. For example, Bargh’s priming study used only 30 undergraduate students to demonstrate the effect.
Replicability Index
Small samples can be sufficient to detect large effects. However, small effects require large samples. The probability of replicating a published finding is a function of sample size and effect size. The Replicability Index (R-Index) makes it possible to use information from published results to predict how replicable published results are.
Every reported test-statistic can be converted into an estimate of power, called observed power. For a single study, this estimate is useless because it is not very precise. However, for sets of studies, the estimate becomes more precise. If we have 10 studies and the average power is 55%, we would expect approximately 5 to 6 studies with significant results and 4 to 5 studies with non-significant results.
If we observe 100% significant results with an average power of 55%, it is likely that studies with non-significant results are missing (Schimmack, 2012). There are too many significant results. This is especially true because average power is also inflated when researchers report only significant results. Consequently, the true power is even lower than average observed power. If we observe 100% significant results with 55% average powered power, power is likely to be less than 50%.
This is unacceptable. Tversky and Kahneman (1971) wrote “we refuse to believe that a serious investigator will knowingly accept a .50 risk of failing to confirm a valid research hypothesis.”
To correct for the inflation in power, the R-Index uses the inflation rate. For example, if all studies are significant and average power is 75%, the inflation rate is 25% points. The R-Index subtracts the inflation rate from average power. So, with 100% significant results and average observed power of 75%, the R-Index is 50% (75% – 25% = 50%). The R-Index is not a direct estimate of true power. It is actually a conservative estimate of true power if the R-Index is below 50%. Thus, an R-Index below 50% suggests that a significant result was obtained only by capitalizing on chance, although it is difficult to quantify by how much.
How Replicable are the Social Priming Studies in “Thinking Fast and Slow”?
Chapter 4: The Associative Machine
4.1. Cognitive priming effect
In the 1980s, psychologists discovered that exposure to a word causes immediate and measurable changes in the ease with which many related words can be evoked.
[no reference provided]
4.2. Priming of behavior without awareness
Another major advance in our understanding of memory was the discovery that priming is not restricted to concepts and words. You cannot know this from conscious experience, of course, but you must accept the alien idea that your actions and your emotions can be primed by events of which you are not even aware.
“In an experiment that became an instant classic, the psychologist John Bargh and his collaborators asked students at New York University—most aged eighteen to twenty-two—to assemble four-word sentences from a set of five words (for example, “finds he it yellow instantly”). For one group of students, half the scrambled sentences contained words associated with the elderly, such as Florida, forgetful, bald, gray, or wrinkle. When they had completed that task, the young participants were sent out to do another experiment in an office down the hall. That short walk was what the experiment was about. The researchers unobtrusively measured the time it took people to get from one end of the corridor to the other.”
“As Bargh had predicted, the young people who had fashioned a sentence from words with an elderly theme walked down the hallway significantly more slowly than the others. walking slowly, which is associated with old age.”
“All this happens without any awareness. When they were questioned afterward, none of the students reported noticing that the words had had a common theme, and they all insisted that nothing they did after the first experiment could have been influenced by the words they had encountered. The idea of old age had not come to their conscious awareness, but their actions had changed nevertheless.“
[John A. Bargh, Mark Chen, and Lara Burrows, “Automaticity of Social Behavior: Direct Effects of Trait Construct and Stereotype Activation on Action,” Journal of Personality and Social Psychology 71 (1996): 230–44.]
| t(28)=2.86 | 0.008 | 2.66 | 0.76 |
| t(28)=2.16 | 0.039 | 2.06 | 0.54 |
MOP = .65, Inflation = .35, R-Index = .30
4.3. Reversed priming: Behavior primes cognitions
“The ideomotor link also works in reverse. A study conducted in a German university was the mirror image of the early experiment that Bargh and his colleagues had carried out in New York.”
“Students were asked to walk around a room for 5 minutes at a rate of 30 steps per minute, which was about one-third their normal pace. After this brief experience, the participants were much quicker to recognize words related to old age, such as forgetful, old, and lonely.”
“Reciprocal priming effects tend to produce a coherent reaction: if you were primed to think of old age, you would tend to act old, and acting old would reinforce the thought of old age.”
| t(18)=2.10 | 0.050 | 1.96 | 0.50 |
| t(35)=2.10 | 0.043 | 2.02 | 0.53 |
| t(31)=2.50 | 0.018 | 2.37 | 0.66 |
MOP = .53, Inflation = .47, R-Index = .06
4.4. Facial-feedback hypothesis (smiling makes you happy)
“Reciprocal links are common in the associative network. For example, being amused tends to make you smile, and smiling tends to make you feel amused….”
“College students were asked to rate the humor of cartoons from Gary Larson’s The Far Side while holding a pencil in their mouth. Those who were “smiling” (without any awareness of doing so) found the cartoons funnier than did those who were “frowning.”
[“Inhibiting and Facilitating Conditions of the Human Smile: A Nonobtrusive Test of the Facial Feedback Hypothesis,” Journal of Personality and Social Psychology 54 (1988): 768–77.]
The authors used the more liberal and unconventional criterion of p < .05 (one-tailed), z = 1.65, as a criterion for significance. Accordingly, we adjusted the R-Index analysis and used 1.65 as the criterion value.
| t(89)=1.85 | 0.034 | 1.83 | 0.57 |
| t(75)=1.78 | 0.034 | 1.83 | 0.57 |
MOP = .57, Inflation = .43, R-Index = .14
These results could not be replicated in a large replication effort with 17 independent labs. Not a single lab produced a significant result and even a combined analysis failed to show any evidence for the effect.
4.5. Automatic Facial Responses
In another experiment, people whose face was shaped into a frown (by squeezing their eyebrows together) reported an enhanced emotional response to upsetting pictures—starving children, people arguing, maimed accident victims.
[Ulf Dimberg, Monika Thunberg, and Sara Grunedal, “Facial Reactions to
Emotional Stimuli: Automatically Controlled Emotional Responses,” Cognition and Emotion, 16 (2002): 449–71.]
The description in the book does not match any of the three studies reported in this article. The first two studies examined facial muscle movements in response to pictures of facial expressions (smiling or frowning faces). The third study used emotional pictures of snakes and flowers. We might consider the snake pictures as being equivalent to pictures of starving children or maimed accident victims. Participants were also asked to frown or to smile while looking at the pictures. However, the dependent variable was not how they felt in response to pictures of snakes, but rather how their facial muscles changed. Aside from a strong effect of instructions, the study also found that the emotional picture had an automatic effect on facial muscles. Participants frowned more when instructed to frown and looking at a snake picture than when instructed to frown and looking at a picture of a flower. “This response, however, was larger to snakes than to flowers as indicated by both the Stimulus factor, F(1, 47) = 6.66, p < .02, and the Stimulus 6 Interval factor, F(1, 47) = 4.30, p < .05.” (p. 463). The evidence for smiling was stronger. “The zygomatic major muscle response was larger to flowers than to snakes, which was indicated by both the Stimulus factor, F(1, 47) = 18.03, p < .001, and the Stimulus 6 Interval factor, F(1, 47) = 16.78, p < .001.” No measures of subjective experiences were included in this study. Therefore, the results of this study provide no evidence for Kahneman’s claim in the book and the results of this study are not included in our analysis.
4.6. Effects of Head-Movements on Persuasion
“Simple, common gestures can also unconsciously influence our thoughts and feelings.”
“In one demonstration, people were asked to listen to messages through new headphones. They were told that the purpose of the experiment was to test the quality of the audio equipment and were instructed to move their heads repeatedly to check for any distortions of sound. Half the participants were told to nod their head up and down while others were told to shake it side to side. The messages they heard were radio editorials.”
“Those who nodded (a yes gesture) tended to accept the message they heard, but those who shook their head tended to reject it. Again, there was no awareness, just a habitual connection between an attitude of rejection or acceptance and its common physical expression.”
| F(2,66)=44.70 | 0.000 | 7.22 | 1.00 |
MOP = 1.00, Inflation = .00, R-Index = 1.00
[Gary L. Wells and Richard E. Petty, “The Effects of Overt Head Movements on Persuasion: Compatibility and Incompatibility of Responses,” Basic and Applied Social Psychology, 1, (1980): 219–30.]
4.7 Location as Prime
“Our vote should not be affected by the location of the polling station, for example, but it is.”
“A study of voting patterns in precincts of Arizona in 2000 showed that the support for propositions to increase the funding of schools was significantly greater when the polling station was in a school than when it was in a nearby location.”
“A separate experiment showed that exposing people to images of classrooms and school lockers also increased the tendency of participants to support a school initiative. The effect of the images was larger than the difference between parents and other voters!”
[Jonah Berger, Marc Meredith, and S. Christian Wheeler, “Contextual Priming: Where People Vote Affects How They Vote,” PNAS 105 (2008): 8846–49.]
| z = 2.10 | 0.036 | 2.10 | 0.56 |
| p = .05 | 0.050 | 1.96 | 0.50 |
MOP = .53, Inflation = .47, R-Index = .06
4.8 Money Priming
“Reminders of money produce some troubling effects.”
“Participants in one experiment were shown a list of five words from which they were required to construct a four-word phrase that had a money theme (“high a salary desk paying” became “a high-paying salary”).”
“Other primes were much more subtle, including the presence of an irrelevant money-related object in the background, such as a stack of Monopoly money on a table, or a computer with a screen saver of dollar bills floating in water.”
“Money-primed people become more independent than they would be without the associative trigger. They persevered almost twice as long in trying to solve a very difficult problem before they asked the experimenter for help, a crisp demonstration of increased self-reliance.”
“Money-primed people are also more selfish: they were much less willing to spend time helping another student who pretended to be confused about an experimental task. When an experimenter clumsily dropped a bunch of pencils on the floor, the participants with money (unconsciously) on their mind picked up fewer pencils.”
“In another experiment in the series, participants were told that they would shortly have a get-acquainted conversation with another person and were asked to set up two chairs while the experimenter left to retrieve that person. Participants primed by money chose to stay much farther apart than their nonprimed peers (118 vs. 80 centimeters).”
“Money-primed undergraduates also showed a greater preference for being alone.”
[Kathleen D. Vohs, “The Psychological Consequences of Money,” Science 314 (2006): 1154–56.]
| F(2,49)=3.73 | 0.031 | 2.16 | 0.58 |
| t(35)=2.03 | 0.050 | 1.96 | 0.50 |
| t(37)=2.06 | 0.046 | 1.99 | 0.51 |
| t(42)=2.13 | 0.039 | 2.06 | 0.54 |
| F(2,32)=4.34 | 0.021 | 2.30 | 0.63 |
| t(38)=2.13 | 0.040 | 2.06 | 0.54 |
| t(33)=2.37 | 0.024 | 2.26 | 0.62 |
| F(2,58)=4.04 | 0.023 | 2.28 | 0.62 |
| chi^2(2)=10.10 | 0.006 | 2.73 | 0.78 |
MOP = .58, Inflation = .42, R-Index = .16
4.9 Death Priming
“The evidence of priming studies suggests that reminding people of their mortality increases the appeal of authoritarian ideas, which may become reassuring in the context of the terror of death.”
The cited article does not directly examine this question. The abstract states that “three experiments were conducted to test the hypothesis, derived from terror management theory, that reminding people of their mortality increases attraction to those who consensually validate their beliefs and decreases attraction to those who threaten their beliefs” (p. 308). Study 2 found no general effect of death priming. Rather, the effect was qualified by authoritarianism. Mortality salience enhanced the rejection of dissimilar others in Study 2 only among high authoritarian subjects.” (p. 314), based on a three-way interaction with F(1,145) = 4.08, p = .045. We used the three-way interaction for the computation of the R-Index. Study 1 reported opposite effects for ratings of Christian targets, t(44) = 2.18, p = .034 and Jewish targets, t(44)= 2.08, p = .043. As these tests are dependent, only one test could be used, and we chose the slightly stronger result. Similarly, Study 3 reported significantly more liking of a positive interviewee and less liking of a negative interviewee, t(51) = 2.02, p = .049 and t(49) = 2.42, p = .019, respectively. We chose the stronger effect.
[Jeff Greenberg et al., “Evidence for Terror Management Theory II: The Effect of Mortality Salience on Reactions to Those Who Threaten or Bolster the Cultural Worldview,” Journal of Personality and Social Psychology]
| t(44)=2.18 | 0.035 | 2.11 | 0.56 |
| F(1,145)=4.08 | 0.045 | 2.00 | 0.52 |
| t(49)=2.42 | 0.019 | 2.34 | 0.65 |
MOP = .56, Inflation = .44, R-Index = .12
4.10 The “Lacy Macbeth Effect”
“For example, consider the ambiguous word fragments W_ _ H and S_ _ P. People who were recently asked to think of an action of which they are ashamed are more likely to complete those fragments as WASH and SOAP and less likely to see WISH and SOUP.”
“Furthermore, merely thinking about stabbing a coworker in the back leaves people more inclined to buy soap, disinfectant, or detergent than batteries, juice, or candy bars. Feeling that one’s soul is stained appears to trigger a desire to cleanse one’s body, an impulse that has been dubbed the “Lady Macbeth effect.”
[Lady Macbeth effect”: Chen-Bo Zhong and Katie Liljenquist, “Washing Away Your Sins:
Threatened Morality and Physical Cleansing,” Science 313 (2006): 1451–52.]
| F(1,58)=4.26 | 0.044 | 2.02 | 0.52 |
| F(1,25)=6.99 | 0.014 | 2.46 | 0.69 |
MOP = .61, Inflation = .39, R-Index = .22
The article reports two more studies that are not explicitly mentioned, but are used as empirical support for the Lady Macbeth effect. As the results of these studies were similar to those in the mentioned studies, including these tests in our analysis does not alter the conclusions.
| chi^2(1)=4.57 | 0.033 | 2.14 | 0.57 |
| chi^2(1)=5.02 | 0.025 | 2.24 | 0.61 |
MOP = .59, Inflation = .41, R-Index = .18
4.11 Modality Specificity of the “Lacy Macbeth Effect”
“Participants in an experiment were induced to “lie” to an imaginary person, either on the phone or in e-mail. In a subsequent test of the desirability of various products, people who had lied on the phone preferred mouthwash over soap, and those who had lied in e-mail preferred soap to mouthwash.”
[Spike Lee and Norbert Schwarz, “Dirty Hands and Dirty Mouths: Embodiment of the Moral-Purity Metaphor Is Specific to the Motor Modality Involved in Moral Transgression,” Psychological Science 21 (2010): 1423–25.]
The results are presented as significant with a one-sided t-test. “As shown in Figure 1a, participants evaluated mouthwash more positively after lying in a voice mail (M = 0.21, SD = 0.72) than after lying in an e-mail (M = –0.26, SD = 0.94), F(1, 81) = 2.93, p = .03 (one-tailed), d = 0.55 (simple main effect), but evaluated hand sanitizer more positively after lying in an e-mail (M = 0.31, SD = 0.76) than after lying in a voice mail (M = –0.12, SD = 0.86), F(1, 81) = 3.25, p = .04 (one-tailed), d = 0.53 (simple main effect).” We adjusted the significance criterion for the R-Index accordingly.
| F(1,81)=2.93 | 0.045 | 1.69 | 0.52 |
| F(1,81)=3.25 | 0.038 | 1.78 | 0.55 |
MOP = .54, Inflation = .46, R-Index = .08
4.12 Eyes on You
“On the first week of the experiment (which you can see at the bottom of the figure), two wide-open eyes stare at the coffee or tea drinkers, whose average contribution was 70 pence per liter of milk. On week 2, the poster shows flowers and average contributions drop to about 15 pence. The trend continues. On average, the users of the kitchen contributed almost three times as much in ’eye weeks’ as they did in ’flower weeks.’ ”
[Melissa Bateson, Daniel Nettle, and Gilbert Roberts, “Cues of Being Watched Enhance Cooperation in a Real-World Setting,” Biology Letters 2 (2006): 412–14.]
| F(1,7)=11.55 | 0.011 | 2.53 | 0.72 |
MOP = .72, Inflation = .28, R-Index = .44
Combined Analysis
We then combined the results from the 31 studies mentioned above. While the R-Index for small sets of studies may underestimate replicability, the R-Index for a large set of studies is more accurate. Median Obesrved Power for all 31 studies is only 57%. It is incredible that 31 studies with 57% power could produce 100% significant results (Schimmack, 2012). Thus, there is strong evidence that the studies provide an overly optimistic image of the robustness of social priming effects. Moreover, median observed power overestimates true power if studies were selected to be significant. After correcting for inflation, the R-Index is well below 50%. This suggests that the studies have low replicability. Moreover, it is possible that some of the reported results are actually false positive results. Just like the large-scale replication of the facial feedback studies failed to provide any support for the original findings, other studies may fail to show any effects in large replication projects. As a result, readers of “Thinking Fast and Slow” should be skeptical about the reported results and they should disregard Kahneman’s statement that “you have no choice but to accept that the major conclusions of these studies are true.” Our analysis actually leads to the opposite conclusion. “You should not accept any of the conclusions of these studies as true.”
k = 31, MOP = .57, Inflation = .43, R-Index = .14, Grade: F for Fail
Powergraph of Chapter 4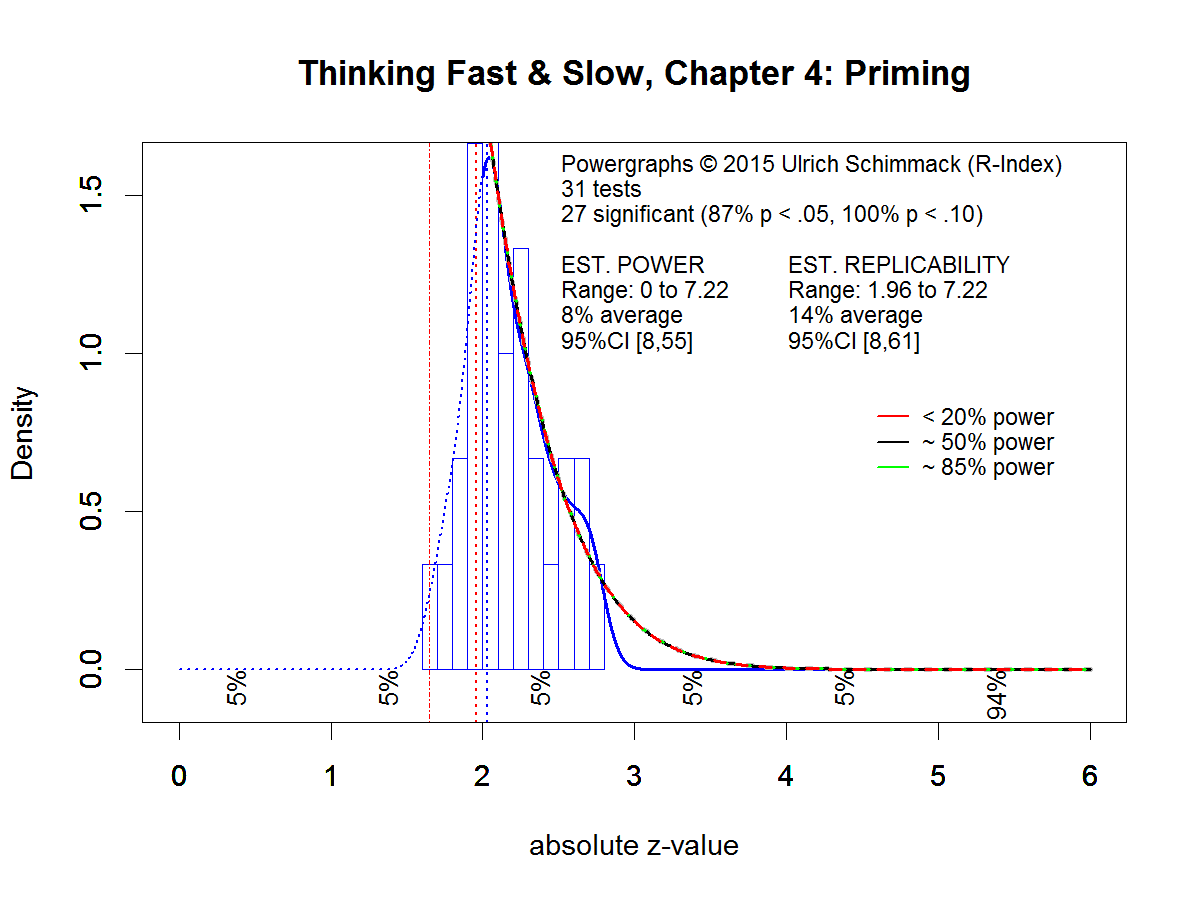
Schimmack and Brunner (2015) developed an alternative method for the estimation of replicability. This method takes into account that power can vary across studies. It also provides 95% confidence intervals for the replicability estimate. The results of this method are presented in the Figure above. The replicability estimate is similar to the R-Index, with 14% replicability. However, due to the small set of studies, the 95% confidence interval is wide and includes values above 50%. This does not mean that we can trust the published results, but it does suggest that some of the published results might be replicable in larger replication studies with more power to detect small effects. At the same time, the graph shows clear evidence for a selection effect. That is, published studies in these articles do not provide a representative picture of all the studies that were conducted. The powergraph shows that there should have been a lot more non-significant results than were reported in the published articles. The selective reporting of studies that worked is at the core of the replicability crisis in social psychology (Sterling, 1959, Sterling et al., 1995; Schimmack, 2012). To clean up their act and to regain trust in published results, social psychologists have to conduct studies with larger samples that have more than 50% power (Tversky & Kahneman, 1971) and they have to stop reporting only significant results. We can only hope that social psychologists will learn from the train wreck of social priming research and improve their research practices.
Great analysis!
Is there some chance you could automate this kind of analysis using e.g. Statcheck? It would enable automatic analysis of large parts of the psychological literature which would be very interesting in estimating the overall trustworthiness of the field, subfields and specific topics. For instance, one can extract article key words and relate these to the measures of scientific quality, including both statistical errors (which Statcheck finds) and signs of QRPs (such as low replication index).
I am working on this. I already have automated analysis of journals (not individual articles), but the drawback is that not all reported hypothesis tests are theoretically relevant. Hard to automate replicability analysis of focal tests.
I think we could perhaps find some heuristics useful for this purpose. I’ve been doing a lot of other text mining, so if you could send me some example PDFs I’ll see what I can think of. It will not be perfect, but could be used as weights to give more weight to the tests that are more likely to be important.
So you have estimates of replicability by journal? So you can compare “prestigious” / “high-impact” journals to society journals etc? Would be very interested to see this, do you have a link?
Here is a list of psychology journals with replicability rankings. A new list for 2016 is coming soon.
I correlated these scores with impact factors and found pretty much no relationship. This makes sense to me. Replicability is just not a criterion that is being used in the review process. As long as p < .05, a result is considered a fact all submitted manuscript meet this criterion. So, other criteria are being used to decide whether a manuscript gets published in a prestigious journal.
https://replicationindex.wordpress.com/2016/01/26/2015-replicability-ranking-of-100-psychology-journals/
didn’t currency priming fail in Many Labs 1?
Thanks for pointing this out. The study was not one of those in the Science article, but another article by Kathleen Vohs.
Currency priming (Caruso, Vohs, Baxter, & Waytz, 2013). Money is a powerful symbol. Caruso et al. (2013) provide evidence that merely exposing participants to money increases their endorsement of the current social system.
No evidence in large replication study.
Thanks for pointing this out.
From Daniel Kahneman
I accept the basic conclusions of this blog. To be clear, I do so (1) without expressing an opinion about the statistical techniques it employed and (2) without stating an opinion about the validity and replicability of the individual studies I cited.
What the blog gets absolutely right is that I placed too much faith in underpowered studies. As pointed out in the blog, and earlier by Andrew Gelman, there is a special irony in my mistake because the first paper that Amos Tversky and I published was about the belief in the “law of small numbers,” which allows researchers to trust the results of underpowered studies with unreasonably small samples. We also cited Overall (1969) for showing “that the prevalence of studies deficient in statistical power is not only wasteful but actually pernicious: it results in a large proportion of invalid rejections of the null hypothesis among published results.” Our article was written in 1969 and published in 1971, but I failed to internalize its message.
My position when I wrote “Thinking, Fast and Slow” was that if a large body of evidence published in reputable journals supports an initially implausible conclusion, then scientific norms require us to believe that conclusion. Implausibility is not sufficient to justify disbelief, and belief in well-supported scientific conclusions is not optional. This position still seems reasonable to me – it is why I think people should believe in climate change. But the argument only holds when all relevant results are published.
I knew, of course, that the results of priming studies were based on small samples, that the effect sizes were perhaps implausibly large, and that no single study was conclusive on its own. What impressed me was the unanimity and coherence of the results reported by many laboratories. I concluded that priming effects are easy for skilled experimenters to induce, and that they are robust. However, I now understand that my reasoning was flawed and that I should have known better. Unanimity of underpowered studies provides compelling evidence for the existence of a severe file-drawer problem (and/or p-hacking). The argument is inescapable: Studies that are underpowered for the detection of plausible effects must occasionally return non-significant results even when the research hypothesis is true – the absence of these results is evidence that something is amiss in the published record. Furthermore, the existence of a substantial file-drawer effect undermines the two main tools that psychologists use to accumulate evidence for a broad hypotheses: meta-analysis and conceptual replication. Clearly, the experimental evidence for the ideas I presented in that chapter was significantly weaker than I believed when I wrote it. This was simply an error: I knew all I needed to know to moderate my enthusiasm for the surprising and elegant findings that I cited, but I did not think it through. When questions were later raised about the robustness of priming results I hoped that the authors of this research would rally to bolster their case by stronger evidence, but this did not happen.
I still believe that actions can be primed, sometimes even by stimuli of which the person is unaware. There is adequate evidence for all the building blocks: semantic priming, significant processing of stimuli that are not consciously perceived, and ideo-motor activation. I see no reason to draw a sharp line between the priming of thoughts and the priming of actions. A case can therefore be made for priming on this indirect evidence. But I have changed my views about the size of behavioral priming effects – they cannot be as large and as robust as my chapter suggested.
I am still attached to every study that I cited, and have not unbelieved them, to use Daniel Gilbert’s phrase. I would be happy to see each of them replicated in a large sample. The lesson I have learned, however, is that authors who review a field should be wary of using memorable results of underpowered studies as evidence for their claims.
Dear Daniel Kahneman,
Thank you for your response to my blog.
Science relies on trust and we all knew that non-significant results were not published, but we had no idea how weak the published results were.
Nobody expected a train-wreck of this magnitude.
Hindsight (like my bias analysis of old studies) is 20/20. The real challenge is how the field and individuals respond to the evidence of a major crisis.
I hope more senior psychologists will follow your example and work towards improving our science.
Although we have fewer answers today than we thought we had five years ago, we still have many important questions that deserve a scientific answer.
Dear Daniel Kahneman, there is another reason to be sceptical of many of the social priming studies. You wrote:
“I still believe that actions can be primed, sometimes even by stimuli of which the person is unaware. There is adequate evidence for all the building blocks: semantic priming, significant processing of stimuli that are not consciously perceived, and ideo-motor activation. I see no reason to draw a sharp line between the priming of thoughts and the priming of actions.”
However, there is an important constraint on subliminal priming that needs to be taken into account. That is, they are very short lived, on the order of seconds. So any claims that a masked prime affects behavior for an extend period of time seems at odd with these more basic findings. Perhaps social priming is more powerful than basic cognitive findings, but it does raise questions. Here is a link to an old paper showing that masked *repetition* priming is short-lived. Presumably semantic effects will be even more transient.
Jeff Bowers
https://www.researchgate.net/profile/Kenneth_Forster/publication/232471563_Masked_repetition_priming_Lexical_activation_or_novel_memory_trace/links/56df0e5708ae9b93f79a89a2.pdf
Good point, Jeff. One might ask if this is something about repetition priming, but associative semantic priming is also fleeting. In our JEP:G paper failing to replicate money priming we noted
“For example, Becker, Moscovitch, Behrmann, and Joordens (1997) found that lexical decision priming effects disappeared if the prime and target were separated by more than 15 seconds, and similar findings were reported by Meyer, Schvaneveldt, and Ruddy (1972). In brief, classic priming effects are small and transient even if the prime and measure are strongly associated (e.g., NURSE-DOCTOR), whereas money priming effects are [purportedly] large and relatively long-lasting even when the prime and measure are seemingly unrelated (e.g., a sentence related to money and the desire to be alone).”
http://laplab.ucsd.edu/articles/RohrerPashlerHarris2015JEPG.pdf
Jeff Bowers,
Semantic priming of a word might last less than conceptual priming.
I would expect (biased…) That activating a larger and more general idea (money, identification with state etc) might last longer than more primes
Not disagreeing with this, but Hal Pashler’s citation of Becker et al (1997) as exemplifying transience is odd in that that paper is precisely about and titled “Long-term semantic priming”. Becker et al showed longterm effects in semantic decision though not in lexical decision.
I am not sure the “file-drawer” effect is the biggest problem. I suspect it is that researchers find interesting or surprising results that do not support their original hypothesis. Instead of accepting the null, they think up a theory to that can be “tested” using the surprising results. Although this turns scientific inquiry upside down, it is a potential path to publication. Here is an economic model of this kind of upside down inference in a litigation setting. http://www.journals.uchicago.edu/doi/pdfplus/10.1086/689283
I am not sure I agree with your conclusions. First, you seem to be assuming that this list of studies is supposed to be an exhaustive set of all such studies, and if any are missing, then there is something wrong here. You call this the ‘file drawer’ problem. Are you inferring that each of the researchers that are being cited have a file drawer full of the other studies (presumably identical to the one they published) they performed that didn’t result in significance? That’s at best p-hacking, and at worst scientific fraud.
Or are you saying that there are N studies in the wild that were similar, that didn’t achieve significance, that were not reported in any journal (hence the file drawer), and are thus, um, what? How many studies have you performed, that didn’t achieve significance, yet were published? Is this a thing now? I work in biology, so maybe it’s different for us, but I have yet to find anybody who will even attempt to publish negative results, let alone anybody who has done so. And even if this is a thing now, are we to expect that it will somehow become retrospective, so Kahneman should have been able to find all these papers that people didn’t publish in the past?
But let’s assume the latter. There are N researchers in the world, each of whom have performed a single study that in some sense is similar enough to the studies published in ‘Thinking Fast and Slow’. Not being a minimally publishable unit, the researchers put the results in their personal file drawer, and go on to the next experiment. Is this actually the problem you make it out to be? And how is this Kahneman’s ‘train wreck’? He searched the literature, found a set of published results that all seem to say the same-ish thing, and said something about them.
It’s my personal contention that people have somehow forgotten how science actually works. Or maybe the social sciences aren’t ‘sciencey’ enough to have learned this to begin with?
1.)We have a hypothesis about how things work and we design an experiment to test that hypothesis. We then perform the experiment and if we achieve significance, we shout ‘Eureka’ and publish. If not, we go on to the next thing.
Note that this isn’t actually an efficient process! The study is most likely underpowered, so there is a significant possibility that we didn’t have power to detect a true difference, so our ‘negative’ result is a false negative. OR, we have an underpowered study AND we used a biased selection process (say, choosing a bunch of undergrads that just so happened to be in this here class), so we get a false positive. Anyway…
2.) Our competitor for academic accolades sees our paper and says ‘Hmmm, seems sketchy to me. I’ll try to replicate.’ This either does or does not replicate, and the wheel goes round and round.
Until we have enough studies and replications thereof, each study is just one little datum that indicates that a particular hypothesis may be true. It’s only after the hypothesis has been tested many many times, that it gets to grow up and become a theory (see, for example the theory of evolution). Until then, it’s just a little baby hypothesis that we think might be true. And even a theory, being the ultimate ‘truth’ in science is still not considered to be actual truth, but just our current best model of what we think the underlying process might be.
I think the ‘replication crisis’ is better described as a crisis in understanding how science actually works. EVERYTHING we currently think is true will either be disproven or modified significantly in future. Gravity used to be big things attracting smaller things, and then it was a curvature in space time and now it’s, like, strings or something.
Other nits to pick. The effect size of a statistic is not necessarily a good indicator of whether or not we have a false positive. In other words, when we do an experiment, we try to get an unbiased sample from the population under study. But this is just a sample, and it may well be biased, particularly if it is small or collected in a silly manner. Under the assumption that the sample is NOT biased, then the effect size is a good indicator of whether or not we should believe the result. However, with a small sample size it is really difficult to say if the sample is biased or not, and it may well be more likely to get a biased sample as N decreases.
In addition, you seem to contend that A.) a study replicates if and only if the replication study has an effect size in the same direction, and is significant. While simultaneously noting that B.) given a power of say X%, we still expect 100 – X such studies to be false negatives, because we have powered the studies in such a way that we expect that to be true. So one could actually argue that a replication study with an effect size in the same direction and within the confidence interval of the original study is sufficient to be considered a replication of the first study. Unless of course the replication study has 100% power to detect the original effect size…
Biology may be 5 years behind psychology in the discussion of these issues, although I am aware that meta-analysis in psychology also show publication bias.
My take on this is that there is a legitimate way to produce significant results that will replicate. To reduce the risk of a type-II error (n.s, cant do anything with these results), you can increase the power of your study. Psychologists Jacob Cohen has made major contributions to performing power analysis and all of the authors of the cited article here probably heard about statistical power and concerns that small samples are often insufficient to produce significant results. (Cohen, 1962). However, the field ignored this and continued publishing only the results of small studies that were significant. The problem is that these results report often greatly inflated effect sizes and will not replicate.
Not publishing failed results or finding creative ways to get significance is not considered scientific fraud in psychology. Only data fabrication or manipulation is. So, the results here do not show evidence of scientific fraud. They show the results of an inappropriate use of the statistical method and a failure to take power into account.
Re: “Not publishing failed results or finding creative ways to get significance is not considered scientific fraud in psychology. … So, the results here do not show evidence of scientific fraud. ”
That reminds me of the piece of wisdom attributed to Lincoln, “How many legs does a dog have if you call his tail a leg? Four. Saying that a tail is a leg doesn’t make it a leg.”
Similarly, any community can choose to recognize or not recognize something for what it is, but that doesn’t require that an outside observer alter his/her own methods or morality to conform to theirs.
If somebody flips a coin 20 times and gets heads 9 times and then reports to me that the coin was flipped only 9 times and got heads each time, am I to think this better than if they would have never flipped the coin, but instead simply fabricated data showing 9 heads on 9 flips? How is one lie fraud, but the other simply some mild form of exaggeration?
This is a fantastic post which is further enhanced by Dr. Kahneman’s reply. Putting aside the specific issue of priming research and the details of the statistical analysis, this post and the comments would provide an excellent example for students and society at large. Many important lessons come to the surface:
1) How can we reflexively attack as “anti-Science” those who profess skepticism (does the term “disbelief” work even better) in certain areas of scientific research? Climate change comes to mind. By allowing sloppy and biased research to persist so long and so publicly, we are creating not only a crisis within science, but a broad crisis in society. The more the public’s trust in science erodes, the more susceptible society becomes to broader crisis, because science is an important pillar of our current order. Articles like this show people that there are real efforts to stop abuses within science.
2) The article shows how to quantitatively detect instances of misleading by omission. Misleading by omission is a particularly pernicious manipulation technique, because it may lead to generalized cynicism. Whereas we can confront outright lies head-on, omissions are harder to detect and pursue. If people begin to suspect that significant omissions are wide-spread, then decisions more easily revert to instinct and tribal loyalty.
3) Dr. Kahneman’s response is an excellent example of strength and self-confidence through humility and an articulate, meaningful examination of one’s errors. This is what real human strength and scientific integrity look like. Society is increasingly dominated by fakers, people who put out strong statements, no matter how poorly founded, as displays of strength and who attack all criticism by ad hominem attack instead of reflecting on it.
Thank you for the great post with great explanations, as always. Your final point is: “To clean up their act and to regain trust in published results, social psychologists have to conduct studies with larger samples that have more than 50% power (Tversky & Kahneman, 1971) and they have to stop reporting only significant results. We can only hope that social psychologists will learn from the train wreck of social priming research and improve their research practices.”
While you are correct that this is needed, I think you lay too much blame on the individual researcher, who is under tremendous competitive pressure to publish many underpowered and significant findings. An individual who does fewer, larger powered, and less significant work is setting themselves up for failure. Decision makers (funders, editors, and hiring/promotion committees) must reward the types of work that lead to better science.
These steps are outlined in the Transparency and Openness Promotion (TOP https://cos.io/top) Guidelines. The most rigorous step would be to implement more “Registered Reports”, where peer review occurs before results are known (https://cos.io/rr) and publication decisions are made based on 1) the necessity to address the proposed questions and 2) the ability of the proposed methods to address those questions. A second round of peer review assures that the study was conducted as agreed upon, but the decision to publish is not based on the outcomes of the tests.
If you’re in a position to reward any part of the scientific process, please consider the issues in this blog when deciding what deserves being rewarded!
Thank you for your comment. My view is that we can analyze problems and recognize the influence of external factors (publish or perish) and internal factors. There are many researchers in psychology and in other areas who are more interested in understanding a research questions than in fame and a position at Harvard and we can identify research areas in psychology that do not look like a train wreck. So, I do think that researchers who contributed to the train wreck have some responsibility because they could have done more rigorous research without risking their career.
“While you are correct that this is needed, I think you lay too much blame on the individual researcher, who is under tremendous competitive pressure to publish many underpowered and significant findings”
I wonder if this is true. For instance, how could this (perceived?) “pressure” explain why it seems that older, tenured researchers don’t conduct their research with some higher standards? I reason they have nothing to lose by adopting higher standards regarding the so-called “pressure to publish”. If anything, this pressure would be mostly applicable to young researchers. So how could this “pressure” explain these findings:
“Results show that tenured social psychologists are more likely to defend the status quo, and to perceive more costs (relative to benefits) to proposed initiatives such as direct replications and pre-registration, than are those who are untenured.”
https://osf.io/preprints/psyarxiv/nn67y/
We have to realize that the articles examined here were published during a time when most people assumed that fishing for significance and not reporting non-significant results was ok. The apparent split in attitudes towards these research method has only occurred during the past 5 years, since Bem (2011) published his imfaous ESP article.
Thank you for the amazing work!
I have recently started reading Thinking Fast and Slow and luckily stumbled upon your blog. I was wondering if in your opinion it means that one interested in this particular area of research should not be reading the book? Priming effect is mentioned in multiple chapters so it might affect the general conclusions of the whole work.
Or maybe it would be a better approach to ignore a few chapter in the book (which ones?) and read the rest, as it is still a valuable intro to the topic?
I think the public should be more aware of your research – everyday a massive number of readers comment on the book on websites such as Goodreads, completely oblivious to the fact that what they are learning is false.
Thank you for your comments. We are working on more detailed reviews of other chapters and there are some chapters that are based on more solid evidence.
Chapters 5, 8, 12, 17, and 24 look better based on our preliminary analyses.
thank you!
(i couldn’t reply to your reaction above so i am copy-pasting it here)
“We have to realize that the articles examined here were published during a time when most people assumed that fishing for significance and not reporting non-significant results was ok. The apparent split in attitudes towards these research method has only occurred during the past 5 years, since Bem (2011) published his imfaous ESP article. ”
The link i posted about tenured researchers attitudes is very recent, so this leaves me wondering if attitudes have really changed, more specifically why tenured researchers (who i reason have nothing to lose by adopting higher standards regarding the “pressure to publish”) seem to be resisting improvements. Your reply, to me, does not tackle the main point made in my comment.
Aside from Registered Reports (currently adopted by only a handful of journals, applied to a handful of papers in their respective journals) there seems to be no system in place which makes hiding non-significant results impossible. This is pathetic! If there really is some change in attitudes, and if researchers are really under pressure to come up with significant results why don’t researchers start a petition, or go on strike, or something like that to demand that journals publish *all* results, irrespective of significance?
That could possibly get rid of all the pressure to come up with significant findings, and according to the reasoning that has been put forward to explain researchers unscientific behavior would be helpful in improving science. What’s so hard about starting a petition to demand journals to change their ways and make it impossible to hide non-significant findings?
If you want to know why tenured, senior researchers are so resistant to change, I offer two explanations.
A successful lab is like an oil-tanker with a pipeline of research projects that supports the existence of an army of graduate students and post-doctoral students. To change this culture is about as easy as trying to avoid an iceberg when you see it.
The second reason is that a switch in research practices will reveal that many of the ‘theoretical’ foundations that are based on old studies by a star, tenured professor are not replicable and there is no theoretical foundation for the whole research program that is build on them. This leads to a huge embarrassment and nobody likes embarrassment.
Finally, time is running out for the senior guys to make a solid new contribution. In contrast, young people see an opportunity to take down the ruins and build new. Think lions in the Savannah.
I think Thomas Kuhn has explained pretty well how paradigm shifts occur. I wonder whether he specified how long a paradigm shift takes. I think we are 5 years into the replicability revolution and it may take another 5 years to see some notable changes in the power structure (Brian Nosek as APS president?) of psychological science.
Anti replications have two aspects. Legitimate and illegitimate
A lot has to do with incentives. Which influence consciously AND unconsciously.
BUT. Many arguments in this sprawling and wide ranging debate are legitimate intellectual points.
We should not generalize that everyone arguing against a point, or changes of focus in methodology is biased and has hidden dishonest motives.
Of course, the essence of statistical evidence etc. cannot change because someone has less than malicious intentions. Replicability should be there. And statistical power must be adhered to etc.
Your ‘second reason’ reminded me of a personal experience. I am a physicist (now retired) who late in my career switched to medical physics. I was asked to referee for a leading journal in the field. One day, a paper came across my desk co-authored by a ‘star’ in the field who had been the previous editor of this very journal. It contained a glaring mathematical error that invalidated the entire paper. I rejected it but became curious about how this could have happened. (perhaps the fact that the second referee did NOT reject the paper should have been a clue) I decided to look back at the paper that had established this star’s career some 20 years earlier. It also had a significant mathematical error, though more subtle, that I would not have let pass. I realized that the problem was that peer review only works if your peers are competent to judge the work. It turns out that many medical physicists come from a biology, not a physics, background and are often out of their depth in mathematics but are unaware of it or will not admit it. This star’s entire career had been built on this failing.
P.S. What did I do about it? Nothing. And I was still asked to referee by the journal.
Thank you for sharing this anecdote.
Can somebody please translate this comment?
What about the published works of Descartes ? I’m so unhappy to hear that Kahneman always says something only useful ! And not true according to… Perhaps but it is so useful ! Same same Descartes !
“If we have 10 studies and the average power is 55%, we would expect approximately 5 to 6 studies with significant results and 4 to 5 studies with non-significant results.”
This is precisely the ‘law of small numbers’ fallacy that you criticize in the previous paragraph!
Not sure what your point is? I am not advocating conducting 10 studies with 55% power. I am just stating what the implications for the probability of a successful (p < .05) outcome are.
right but only partially.
Assuming a 55% odds for success per experiment, the binomial odds for 10 out of 10 to succeed are not extremely low. But quite low. p=0.0025 or so.
In fact, having 8 out of 10 to succeed is not unusual.
Like all numerical arguments, reaching conclusions in complicated statistical situations require precision of definition etc. and good calculations.
“law of small numbers” is when you have minor differences between units and a small sample.
0.55 per unit with N=10 10 out of 10 is not a small sample for this test. if you are satisfied with p<0.003
Hello,
thank you for your work in this blogpost. For me, as just a simple reader of the book without background in psychology, it is not possible to check on the validity of the assumptions or results and conclusions. I was just amazed about the different effects described by Kahnemann in the book!
After reading ths post however (and some of your other posts) i dont know what to trust anymore.
My question regarding the book is: Which part of the book is invalid due to your statements?
Should I stop reading immediatly? : D
from germany – sry for lack of english capabilities
There are parts of the book that are based on more solid evidence. Unfortunately, we haven’t done a detailed analysis of the full book. Most of the studies by Kahneman and Tversky are credible, but chapters based on social psychological findings by others, like priming, should be read with a healthy dose of skepticism. I think it is still interesting to read them, but the effects may not be as big as suggested.
Reblogged this on Picking Up The Tabb and commented:
The concept of “priming” has gained a lot of adherents in psychological research, but is it real? If I lead a group of students to think about the challenges faced by the elderly, do the students walk more slowly because of that “priming?” Several independent studies have produced significant p-values and were published in high-impact journals. As is common in research, however, these studies used relatively few subjects. A recent meta-analysis that attempts to combine the data among these studies, however, concludes that the significant findings in the individual studies were illusory. This negative result was published to relatively little fanfare.
The example from “priming” is illustrative of a greater problem for reproducible research, where under-powered studies are the norm. Academic journals have a clear bias toward positive findings, and negative results frequently fail to be published!
I can’t believe I missed this post when it first came out in February. Great post and the comments are outstanding. I used to talk and write about priming but when the issues with Bargh came out followed by others I stopped including these in my writings and teaching and speaking. However, I have to say that the comment left by James W. MacDonald is especially important — we all need to learn and then remember how science works. We want everything to be sure and tidy and our knowledge of the world to be perfect. Instead science brings us certainties that then become uncertain. The scientific method isn’t perfect, except maybe it is. The world, nature, and especially human nature are complicated. All we can do is keep moving forward, learn as much as we can, use the best methods we have at the time, and be willing to change it all — our methods, our measurements, and our theories — when the data tells us to change.