Summary
The z-curve analysis of results in this journal shows (a) that many published results are based on studies with low to modest power, (b) selection for significance inflates effect size estimates and the discovery rate of reported results, and (c) there is no evidence that research practices have changed over the past decade. Readers should be careful when they interpret results and recognize that reported effect sizes are likely to overestimate real effect sizes, and that replication studies with the same sample size may fail to produce a significant result again. To avoid misleading inferences, I suggest using alpha = .005 as a criterion for valid rejections of the null-hypothesis. Using this criterion, the risk of a false positive result is below 2%. I also recommend computing a 99% confidence interval rather than the traditional 95% confidence interval for the interpretation of effect size estimates.
Given the low power of many studies, readers also need to avoid the fallacy to report non-significant results as evidence for the absence of an effect. With 50% power, the results can easily switch in a replication study so that a significant result becomes non-significant and a non-significant result becomes significant. However, selection for significance will make it more likely that significant results become non-significant than observing a change in the opposite direction.
The average power of studies in a heterogeneous journal like Frontiers of Psychology provides only circumstantial evidence for the evaluation of results. When other information is available (e.g., z-curve analysis of a discipline, author, or topic, it may be more appropriate to use this information).
Report
Frontiers of Psychology was created in 2010 as a new online-only journal for psychology. It covers many different areas of psychology, although some areas have specialized Frontiers journals like Frontiers in Behavioral Neuroscience.
The business model of Frontiers journals relies on publishing fees of authors, while published articles are freely available to readers.
The number of articles in Frontiers of Psychology has increased quickly from 131 articles in 2010 to 8,072 articles in 2022 (source Web of Science). With over 8,000 published articles Frontiers of Psychology is an important outlet for psychological researchers to publish their work. Many specialized, print-journals publish fewer than 100 articles a year. Thus, Frontiers of Psychology offers a broad and large sample of psychological research that is equivalent to a composite of 80 or more specialized journals.
Another advantage of Frontiers of Psychology is that it has a relatively low rejection rate compared to specialized journals that have limited journal space. While high rejection rates may allow journals to prioritize exceptionally good research, articles published in Frontiers of Psychology are more likely to reflect the common research practices of psychologists.
To examine the replicability of research published in Frontiers of Psychology, I downloaded all published articles as PDF files, converted PDF files to text files, and extracted test-statistics (F, t, and z-tests) from published articles. Although this method does not capture all published results, there is no a priori reason that results reported in this format differ from other results. More importantly, changes in research practices such as higher power due to larger samples would be reflected in all statistical tests.
As Frontiers of Psychology only started shortly before the replication crisis in psychology increased awareness about the problem of low statistical power and selection for significance (publication bias), I was not able to examine replicability before 2011. I also found little evidence of changes in the years from 2010 to 2015. Therefore, I use this time period as the starting point and benchmark for future years.
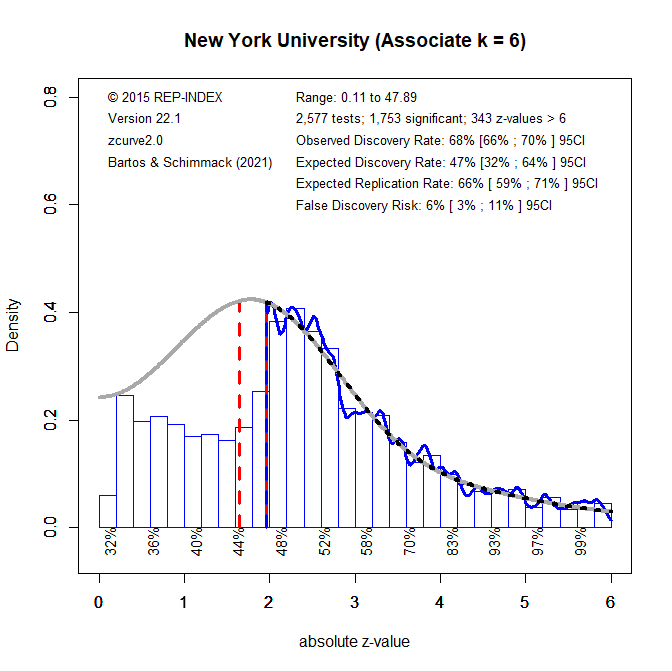
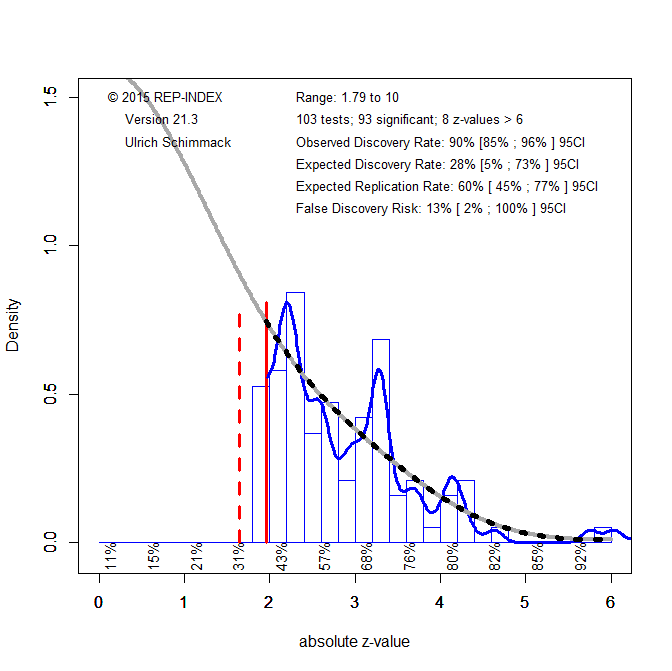
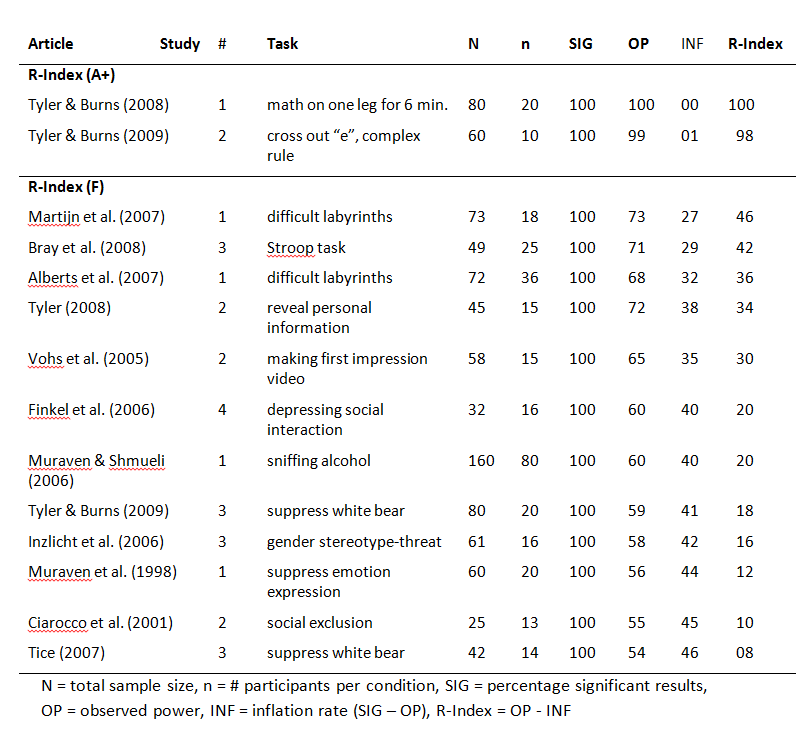
Figure 1 shows a z-curve plot of results published from 2010 to 2014. All test-statistics are converted into z-scores. Z-scores greater than 1.96 (the solid red line) are statistically significant at alpha = .05 (two-sided) and typically used to claim a discovery (rejection of the null-hypothesis). Sometimes even z-scores between 1.65 (the dotted red line) and 1.96 are used to reject the null-hypothesis either as a one-sided test or as marginal significance. Using alpha = .05, the plot shows 71% significant results, which is called the observed discovery rate (ODR).

Visual inspection of the plot shows a peak of the distribution right at the significance criterion. It also shows that z-scores drop sharply on the left side of the peak when the results do not reach the criterion for significance. This wonky distribution cannot be explained with sampling error. Rather it shows a selective bias to publish significant results by means of questionable practices such as not reporting failed replication studies or inflating effect sizes by means of statistical tricks. To quantify the amount of selection bias, z-curve fits a model to the distribution of significant results and estimates the distribution of non-significant (i.e., the grey curve in the range of non-significant results). The discrepancy between the observed distribution and the expected distribution shows the file-drawer of missing non-significant results. Z-curve estimates that the reported significant results are only 31% of the estimated distribution. This is called the expected discovery rate (EDR). Thus, there are more than twice as many significant results as the statistical power of studies justifies (71% vs. 31%). Confidence intervals around these estimates show that the discrepancy is not just due to chance, but active selection for significance.
Using a formula developed by Soric (1989), it is possible to estimate the false discovery risk (FDR). That is, the probability that a significant result was obtained without a real effect (a type-I error). The estimated FDR is 12%. This may not be alarming, but the risk varies as a function of the strength of evidence (the magnitude of the z-score). Z-scores that correspond to p-values close to p =.05 have a higher false positive risk and large z-scores have a smaller false positive risk. Moreover, even true results are unlikely to replicate when significance was obtained with inflated effect sizes. The most optimistic estimate of replicability is the expected replication rate (ERR) of 69%. This estimate, however, assumes that a study can be replicated exactly, including the same sample size. Actual replication rates are often lower than the ERR and tend to fall between the EDR and ERR. Thus, the predicted replication rate is around 50%. This is slightly higher than the replication rate in the Open Science Collaboration replication of 100 studies which was 37%.
Figure 2 examines how things have changed in the next five years.
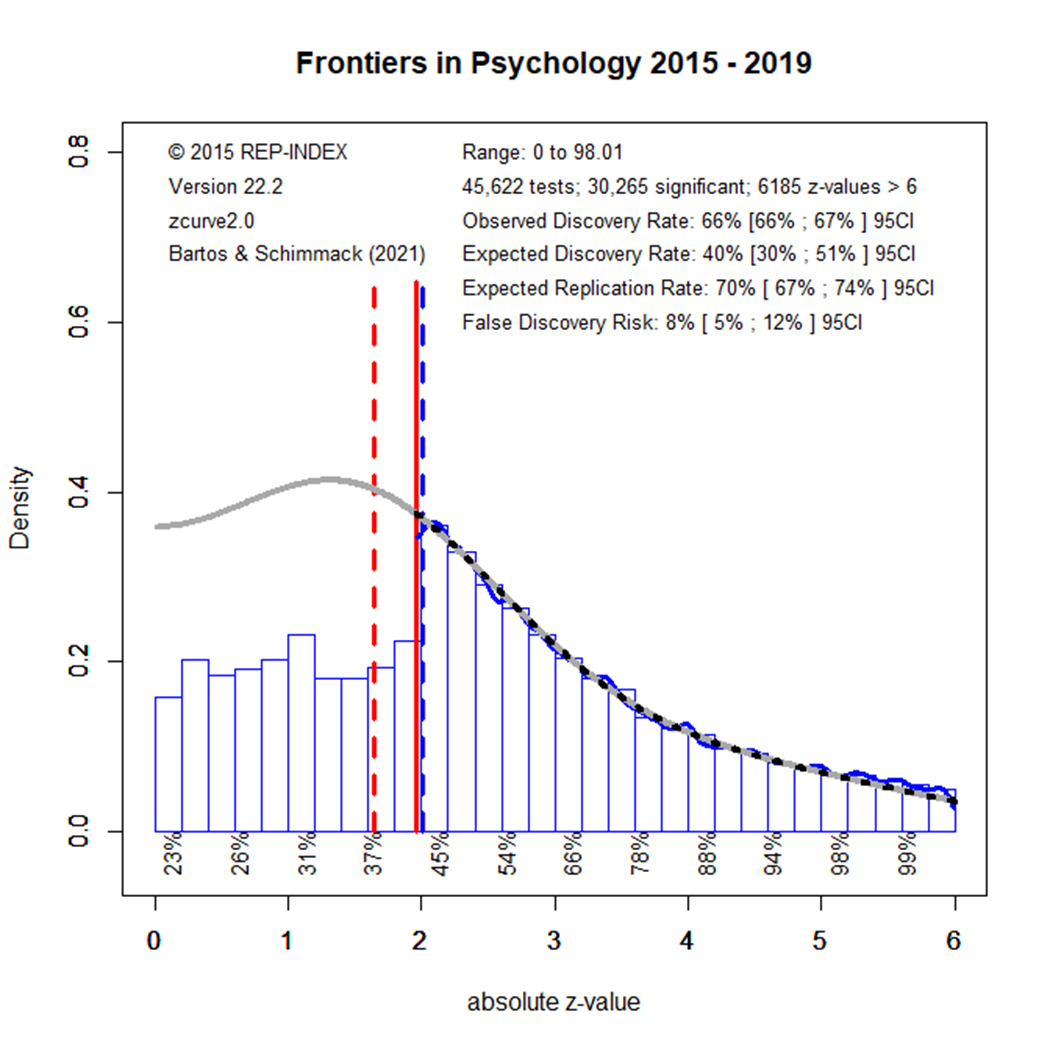
The observed discovery rate decreased slightly, but statistically significantly, from 71% to 66%. This shows that researchers reported more non-significant results. The expected discovery rate increased from 31% to 40%, but the overlapping confidence intervals imply that this is not a statistically significant increase at the alpha = .01 level. (if two 95%CI do not overlap, the difference is significant at around alpha = .01). Although smaller, the difference between the ODR of 60% and the EDR of 40% is statistically significant and shows that selection for significance continues. The ERR estimate did not change, indicating that significant results are not obtained with more power. Overall, these results show only modest improvements, suggesting that most researchers who publish in Frontiers in Psychology continue to conduct research in the same way as they did before, despite ample discussions about the need for methodological reforms such as a priori power analysis and reporting of non-significant results.

The results for 2020 show that the increase in the EDR was a statistical fluke rather than a trend. The EDR returned to the level of 2010-2015 (29% vs. 31), but the ODR remained lower than in the beginning, showing slightly more reporting of non-significant results. The size of the file drawer remains large with an ODR of 66% and an EDR of 72%.
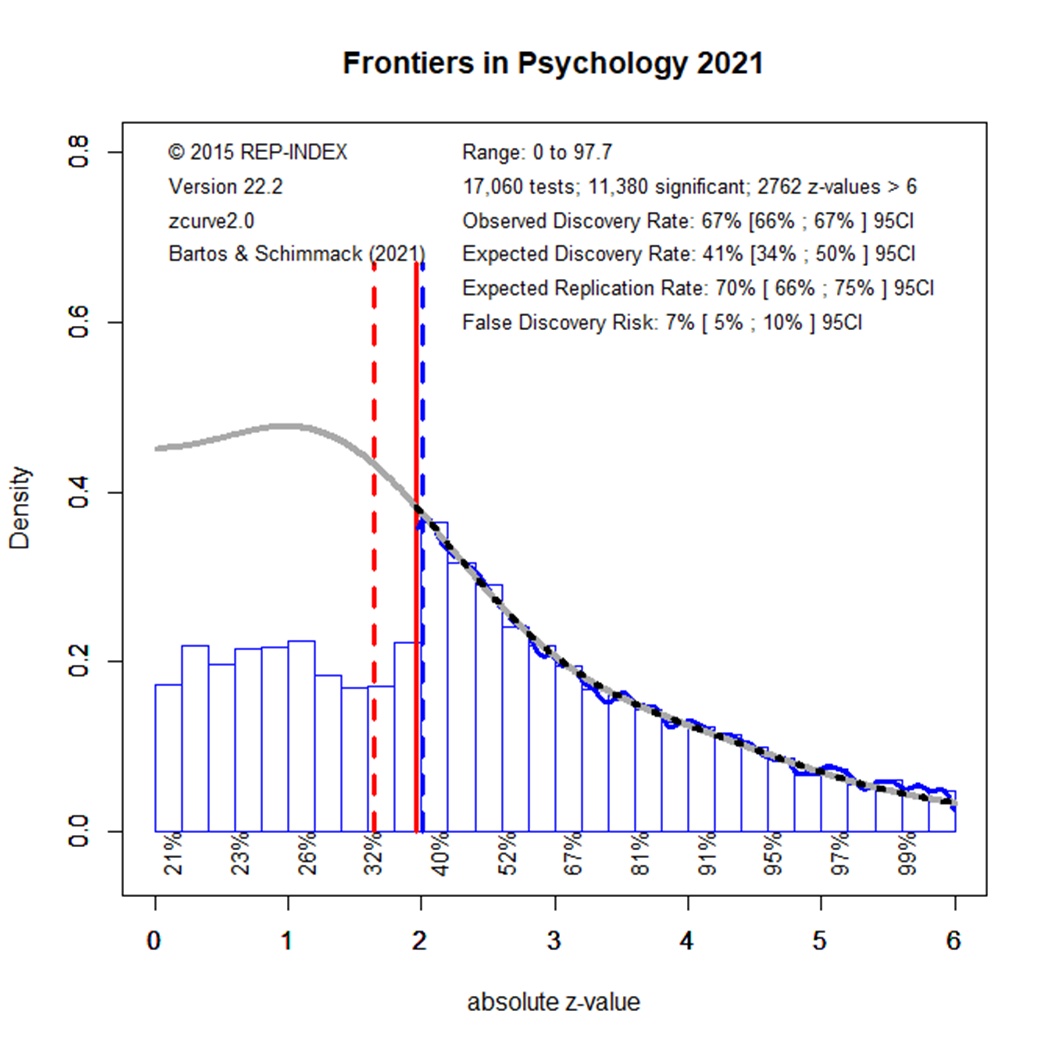
The EDR results for 2021 look again better, but the difference to 2020 is not statistically significant. Moreover, the results in 2022 show a lower EDR that matches the EDR in the beginning.
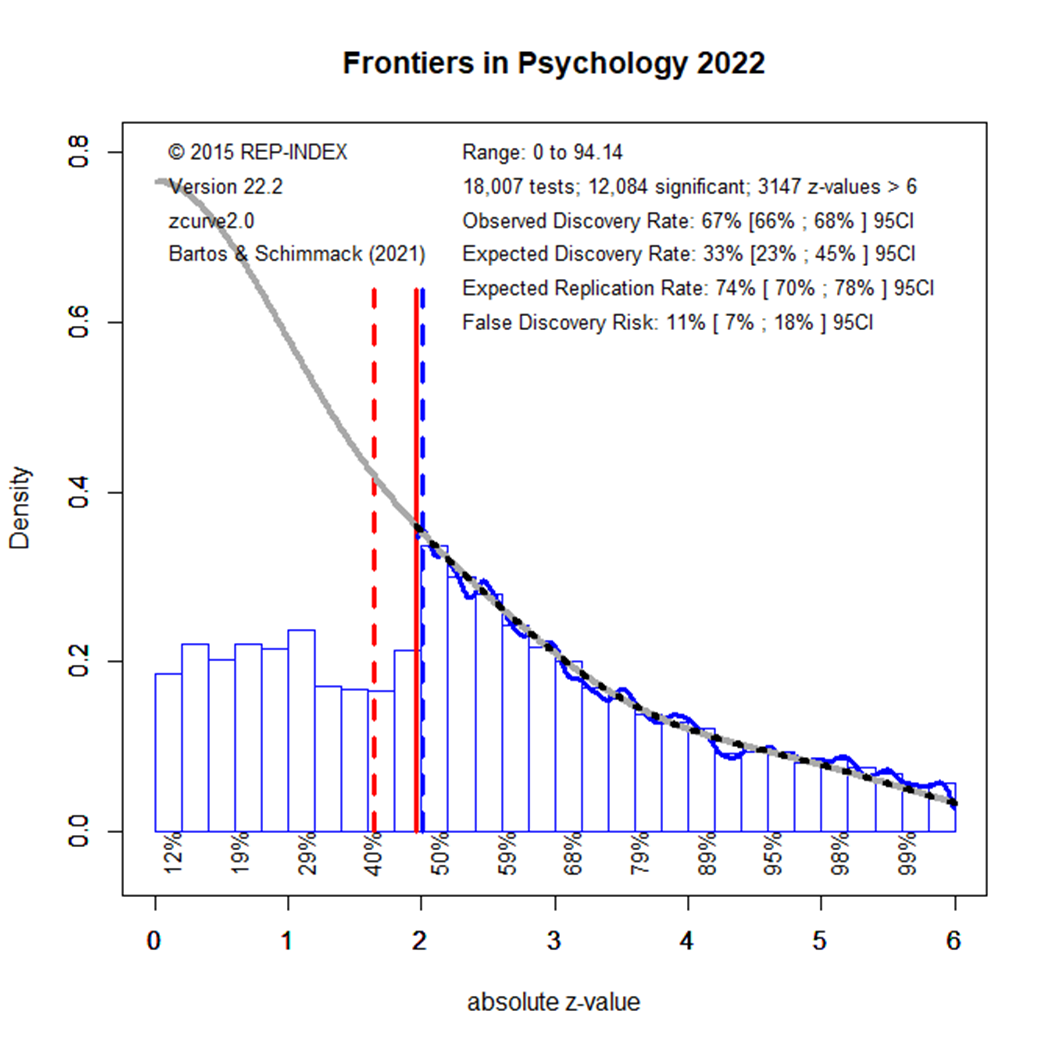
Overall, these results show that results published in Frontiers in Psychology are selected for significance. While the observed discovery rate is in the upper 60%s, the expected discovery rate is around 35%. Thus, the ODR is nearly twice the rate of the power of studies to produce these results. Most concerning is that a decade of meta-psychological discussions about research practices has not produced any notable changes in the amount of selection bias or the power of studies to produce replicable results.
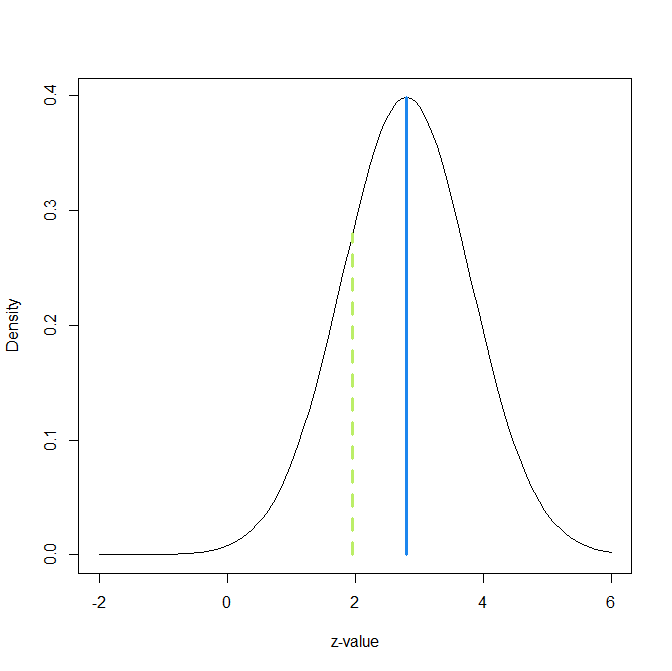
How should readers of Frontiers in Psychology articles deal with this evidence that some published results were obtained with low power and inflated effect sizes that will not replicate? One solution is to retrospectively change the significance criterion. Comparisons of the evidence in original studies and replication outcomes suggest that studies with a p-value below .005 tend to replicate at a rate of 80%, whereas studies with just significant p-values (.050 to .005) replicate at a much lower rate (Schimmack, 2022). Demanding stronger evidence also reduces the false positive risk. This is illustrated in the last figure that uses results from all years, given the lack of any time trend.
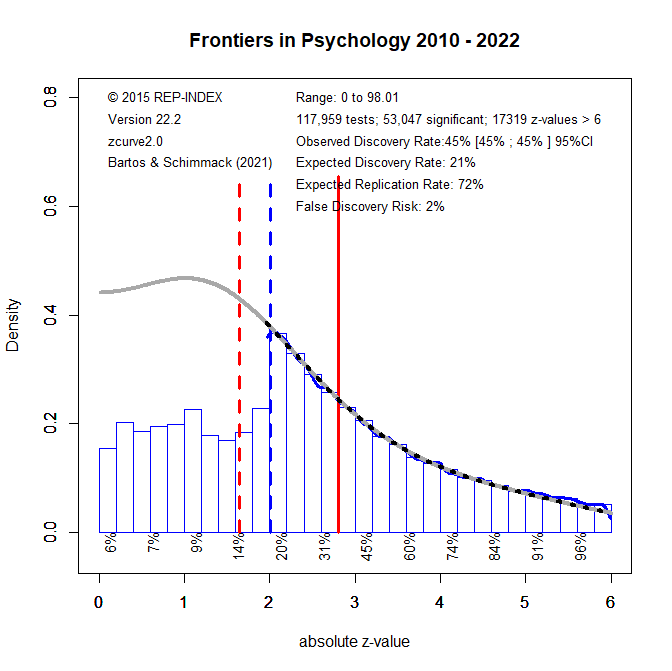
In the Figure the red solid line moved to z = 2.8; the value that corresponds to p = .005, two-sided. Using this more stringent criterion for significance, only 45% of the z-scores are significant. Another 25% were significant with alpha = .05, but are no longer significant with alpha = .005. As power decreases when alpha is set to more stringent, lower, levels, the EDR is also reduced to only 21%. Thus, there is still selection for significance. However, the more effective significance filter also selects for more studies with high power and the ERR remains at 72%, even with alpha = .005 for the replication study. If the replication study used the traditional alpha level of .05, the ERR would be even higher, which explains the finding that the actual replication rate for studies with p < .005 is about 80%.
The lower alpha also reduces the risk of false positive results, even though the EDR is reduced. The FDR is only 2%. Thus, the null-hypothesis is unlikely to be true. The caveat is that the standard null-hypothesis in psychology is the nil-hypothesis and that the population effect size might be too small to be of practical significance. Thus, readers who interpret results with p-values below .005 should also evaluate the confidence interval around the reported effect size, using the more conservative 99% confidence interval that correspondence to alpha = .005 rather than the traditional 95% confidence interval. In many cases, this confidence interval is likely to be wide and provide insufficient information about the strength of an effect.