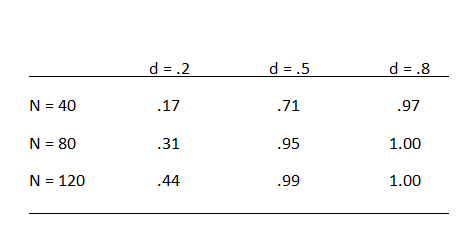This blog post is heavily based on one of my first blog-posts in 2014 (Schimmack, 2014). The blog post reports a meta-analysis of ego-depletion studies that used the hand-grip paradigm. When I first heard about the hand-grip paradigm, I thought it was stupid because there is so much between-subject variance in physical strength. However, then I learned that it is the only paradigm that uses a pre-post design, which removes between-subject variance from the error term. This made the hand-grip paradigm the most interesting paradigm because it has the highest power to detect ego-depletion effects. I conducted a meta-analysis of the hand-grip studies and found clear evidence of publication bias. This finding is very damaging to the wider ego-depletion research because other studies used between-subject designs with small samples which have very low power to detect small effects.
This prediction was confirmed in meta-analyses by Carter,E.C., Kofler, L.M., Forster, D.E., and McCulloch,M.E. (2015) that revealed publication bias in ego-depletion studies with other paradigms.
The results also explain why attempts to show ego-depletion effects with within-subject designs failed (Francis et al., 2018). Within-subject designs increase power by removing fixed between-subject variance such as physical strength. However, given the lack of evidence with the hand-grip paradigm it is not surprising that within-subject designs also failed to show ego-depletion effects with other dependent variables in within-subject designs. Thus, these results further suggest that ego-depletion effects are too small to be used for experimental investigations of will-power.
Of course, Roy F. Baumeister doesn’t like this conclusion because his reputation is to a large extent based on the resource model of will-power. His response to the evidence that most of the evidence is based on questionable practices that produced illusory evidence has been to attack the critics (cf. Schimmack, 2019).
In 2016, he paid to publish a critique of Carter’s (2015) meta-analysis in Frontiers of Psychology (Cunningham & Baumeister, 2016). In this article, the authors question the results obtained by bias-tests that reveal publication bias and suggest that there is no evidence for ego-depletion effects.
Unfortunately, Cunningham and Baumeister’s (2016) article is cited frequently as if it contained some valid scientific arguments.

For example, Christodoulou, Lac, and Moore (2017) cite the article to dismiss the results of a PEESE analysis that suggests publication bias is present and there is no evidence that infants can add and subtract. Thus, there is a real danger that meta-analysts will use Cunningham & Baumeister’s (2016) article to dismiss evidence of publication bias and to provide false evidence for claims that rest on questionable research practices.
Fact Checking Cunningham and Baumeister’s Criticisms
Cunningham and Baumeister (2016) claim that results from bias tests are difficult to interpret, but there criticism is based on false arguments and inaccurate claims.
Confusing Samples and Populations

This scientifically sounding paragraph is a load of bull. The authors claim that inferential tests require sampling from a population and raise a question about the adequacy of a sample. However, bias tests do not work this way. They are tests of the population, namely the population of all of the studies that could be retrieved that tested a common hypothesis (e.g., all handgrip studies of ego-depletion). Maybe more studies exist than are available. Maybe the results based on the available studies differ from results if all studies were available, but that is irrelevant. The question is only whether the available studies are biased or not. So, why do we even test for significance? That is a good question. The test for significance only tells us whether bias is merely a product of random chance or whether it was introduced by questionable research practices. However, even random bias is bias. If a set of studies reports only significant results, and the observed power of the studies is only 70%, there is a discrepancy. If this discrepancy is not statistically significant, there is still a discrepancy. If it is statistically significant, we are allowed to attribute it to questionable research practices such as those that Baumeister and several others admitted using.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication) (Schimmack, 2014).
Given the widespread use of questionable research practices in experimental social psychology, it is not surprising that bias-tests reveal bias. It is actually more surprising when these tests fail to reveal bias, which is most likely a problem of low statistical power (Renkewitz & Keiner, 2019).
Misunderstanding Power

The claims about power are not based on clearly defined constructs in statistics. Statistical power is a function of the strength of a signal (the population effect size) and the amount of noise (sampling error). Researches skills are not a part of statistical power. Results should be independent of a researcher. A researcher could of course pick procedures that maximize a signal (powerful interventions) or reduce sampling error (e.g., pre-post designs), but these factors play a role in the designing of a study. Once a study is carried out, the population effect size is what it was and the sampling error is what it was. Thus, honestly reported test statistics tell us about the signal-to-noise ratio in a study that was conducted. Skillful researchers would produce stronger test-statistics (higher t-values, F-values) than unskilled researchers. The problem for Baumeister and other ego-depletion researchers is that the t-values and F-values tend to be weak and suggest questionable research practices rather than skill produced significant results. In short, meta-analysis of test-statistics reveal whether researchers used skill or questionable research practices to produce significant results.
The reference to Morey (2013) suggests that there is a valid criticism of bias tests, but that is not the case. Power-based bias tests are based on sound statistical principles that were outlined by a statistician in the journal American Statistician (Sterling, Rosenbaum, & Weinkam, 1995). Building on this work, Jerry Brunner (professor of statistics) and I published theorems that provide the basis of bias tests like TES to reveal the use of questionable research practices (Brunner & Schimmack, 2019). The real challenge for bias tests is to estimate mean power without information about the population effect sizes. In this regard, TES is extremely conservative because it relies on a meta-analysis of observed effect sizes to estimate power. These effect sizes are inflated when questionable research practices were used, which makes the test conservative. However, there is a problem with TES when effect sizes are heterogeneous. This problem is avoided by alternative bias tests like the R-Index that I used to demonstrate publication bias in the handgrip studies of ego-depletion. In sum, bias tests like the R-Index and TES are based on solid mathematical foundations and simulation studies show that they work well in detecting the use of questionable research practices.
Confusing Absence of Evidence with Evidence of Absence

PET and PEESE are extension of Eggert’s regression test of publication bias. All methods relate sample sizes (or sampling error) to effect size estimates. Questionable research practices tend to introduce a negative correlation between sample size and effect sizes or a positive correlation between sampling error and effect sizes. The reason is that significance requires a signal to noise ratio of 2:1 for t-tests or 4:1 for F-tests to produce a significant result. To achieve this ratio with more noise (smaller sample, more sampling error), the signal has to be inflated more.
The novel contribution of PET and PEESE was to use the intercept of the regression model as an effect size estimate that corrects for publication bias. This estimate needs to be interpreted in the context of the sampling error of the regression model, using a 95%CI around the point estimate.
Carter et al. (2015) found that the 95%CI often included a value of zero, which implies that the data are too weak to reject the null-hypothesis. Such non-significant results are notoriously difficult to interpret because they neither support nor refute the null-hypothesis. The main conclusion that can be drawn from this finding is that the existing data are inconclusive.
This main conclusion does not change when the number of studies is less than 20. Stanley and Doucouliagos (2014) were commenting on the trustworthiness of point estimates and confidence intervals in smaller samples. Smaller samples introduce more uncertainty and we should be cautious in the interpretation of results that suggest there is an effect because the assumptions of the model are violated. However, if the results already show that there is no evidence, small samples merely further increase uncertainty and make the existing evidence even less conclusive.
Aside from the issues regarding the interpretation of the intercept, Cunningham and Baumeister also fail to address the finding that sample sizes and effect sizes were negatively correlated. If this negative correlation is not caused by questionable research practices, it must be caused by something else. Cunningham and Baumeister fail to provide an answer to this important question.
No Evidence of Flair and Skill
Earlier Cunningham and Baumeister (2016) claimed that power depends on researchers’ skills and they argue that new investigators may be less skilled than the experts who developed paradigms like Baumeister and colleagues.

However, they then point out that Carter et al.’s (2015) examined lab as a moderator and found no difference between studies conducted by Baumeister and colleagues or other laboratories.

Thus, there is no evidence whatsoever that Baumeister and colleagues were more skillful and produced more credible evidence for ego-depletion than other laboratories. The fact that everybody got ego-depletion effects can be attributed to the widespread use of questionable research practices that made it possible to get significant results even for implausible phenomena like extrasensory perception (John et al., 2012; Schimmack, 2012). Thus, the large number of studies that support ego-depletion merely shows that everybody used questionable research practices like Baumeister did (Schimmack, 2014; Schimmack, 2016), which is also true for many other areas of research in experimental social psychology (Schimmack, 2019). Francis (2014) found that 80% of articles showed evidence that QRPs were used.
Handgrip Replicability Analysis
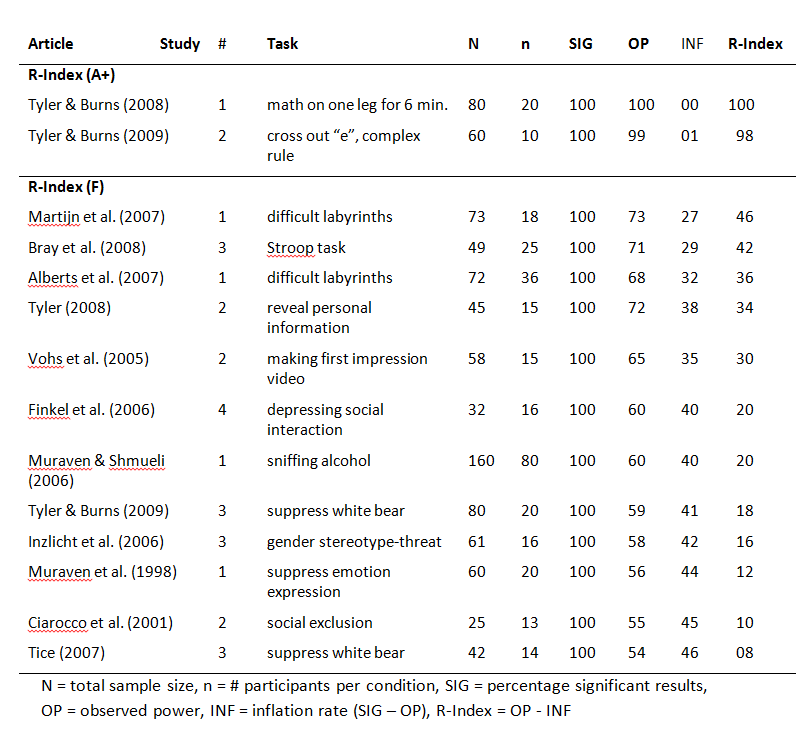
The meta-analysis included 18 effect sizes based on handgrip studies. Two unpublished studies (Ns = 24, 37) were not included in this analysis. Seeley & Gardner (2003)’s study was excluded because it failed to use a pre-post design, which could explain the non-significant result. The meta-analysis reported two effect sizes for this study. Thus, 4 effects were excluded and the analysis below is based on the remaining 14 studies.
All articles presented significant effects of will-power manipulations on handgrip performance. Bray et al. (2008) reported three tests; one was deemed not significant (p = .10), one marginally significant (.06), and one was significant at p = .05 (p = .01). The results from the lowest p-value were used. As a result, the success rate was 100%.
Median observed power was 63%. The inflation rate is 37% and the R-Index is 26%. An R-Index of 22% is consistent with a scenario in which the null-hypothesis is true and all reported findings are type-I errors. Thus, the R-Index supports Carter and McCullough’s (2014) conclusion that the existing evidence does not provide empirical support for the hypothesis that will-power manipulations lower performance on a measure of will-power.
The R-Index can also be used to examine whether a subset of studies provides some evidence for the will-power hypothesis, but that this evidence is masked by the noise generated by underpowered studies with small samples. Only 7 studies had samples with more than 50 participants. The R-Index for these studies remained low (20%). Only two studies had samples with 80 or more participants. The R-Index for these studies increased to 40%, which is still insufficient to estimate an unbiased effect size.
One reason for the weak results is that several studies used weak manipulations of will-power (e.g., sniffing alcohol vs. sniffing water in the control condition). The R-Index of individual studies shows two studies with strong results (R-Index > 80). One study used a physical manipulation (standing one leg). This manipulation may lower handgrip performance, but this effect may not reflect an influence on will-power. The other study used a mentally taxing (and boring) task that is not physically taxing as well, namely crossing out “e”s. This task seems promising for a replication study.
Power analysis with an effect size of d = .2 suggests that a serious empirical test of the will-power hypothesis requires a sample size of N = 300 (150 per cell) to have 80% power in a pre-post study of will-power.
Conclusion
Baumeister has lost any credibility as a scientist. He is pretending to engage in a scientific dispute about the validity of ego-depletion research, but he is ignoring the most obvious evidence that has accumulated during the past decade. Social psychologists have misused the scientific method and engaged in a silly game of producing significant p-values that support their claims. Data were never used to test predictions and studies that failed to support hypotheses were not published.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication)
As a result, the published record lacks credibility and cannot be used to provide empirical evidence for scientific claims. Ego-depletion is a glaring example of everything that went wrong in experimental social psychology. This is not surprising because Baumeister and his students used questionable research practices more than other social psychologists (Schimmack, 2018). Now he is trying to to repress this truth, which should not surprise any psychologist familiar with motivated biases and repressive coping. However, scientific journals should not publish his pathetic attempts to dismiss criticism of his work. Cunningham and Baumeister’s article provides not a single valid scientific argument. Frontiers of Psychology should retract the article.
References
Carter,E.C.,Kofler,L.M.,Forster,D.E.,and McCulloch,M.E. (2015).A series of meta-analytic tests of the depletion effect: Self-control does not seem to rely on a limited resource. J. Exp.Psychol.Gen. 144, 796–815. doi:10.1037/xge0000083