Psychology is the science of human affect, behavior, and cognition. Since the beginning of psychological science, psychologists have debated fundamental questions about their science. Recently, these self-reflections of a science about itself have been called meta-science. Many meta-psychological discussions are theoretical. However, some meta-psychological articles rely on empirical data. For example, Cohen’s (1961) seminal investigation of statistical power in social and clinical psychology provided an empirical estimate of statistical power to detect small, moderate, or large effect sizes.
Another empirical meta-psychological contribution was the reproducibility project by the Open Science Collaboration (2015). The project reported the outcome of 100 replication attempts of studies that were published in 2008 in three journals. The key finding was that out of 97 original studies that reported a statistically significant result, only 36 replication studies reproduced a statistically significant result; a success rate of 37%.
The low success rate has been widely cited as evidence that psychological science has a replication crisis. It also justifies concerns about the credibility of other significant results that may have an equally low probability of a successful replication.
Optimists point out that some psychology journals have implemented reforms that may have raised the replicability of published findings such as (a) requesting a priori sample size justifications with power analysis and pre-registration of data analysis plans. It is also possible that psychologists voluntarily changed their research practices after they became aware of the low replicability of their findings. Finally, some psychologists may have lowered the significance criterion to reduce the risk of false positive results that do not replicate. Yet, as of today no empirical evidence exists that these reforms have made a notable, practically significant contribution to the replication rate in psychological science.
In this blog post, I provide a new empirical estimate of the replicability of psychological science that relies on published statistical results. It is possible to predict the outcome of replication studies based on published statistical results because both the results of the original study and the outcome of the replication study are a function of statistical power and sampling error (Brunner & Schimmack, 2020). Studies with higher statistical power are more likely to produce smaller p-values and are more likely to replicate. As a result, smaller p-values imply higher replicability. The statistical challenge is only to find a model that can use published p-values to make predictions about the success rate of replication studies. Brunner and Schimmack (2020) developed and validated z-curve as a method that can estimate the expected replication rate (ERR) based on the distribution of significant p-values after converting them into z-scores. Although the method performs well in simulation studies, it is also necessary to validate the method against the outcome of actual replication studies. The results from the OSC reproducibility project provide an opportunity to do so.
For any empirical study it is necessary to clearly define populations and to ensure adequate sampling from populations. In the present context, populations are quantitative results that were used to test statistical hypotheses like F-tests, t-tests, or other tests. Most articles report several statistical tests for each sample. These statistical tests differ in importance. The reproducibility project focused on one statistical result to evaluate whether a replication study was successful. This result was typically chosen because it was deemed the most important or at least one of the most important results. These results are often called focal or critical. Ideally, statistical prediction models that aim to predict the replicability of focal tests would rely on coding of focal hypothesis tests. The main problem with this approach is that coding of focal hypothesis tests requires trained coders and is time consuming.
An alternative approach uses automatic extraction of test-statistics from published articles. The advantage of this approach that it is quick and produces large representative samples of results published in statistical journals. The key disadvantage is that this approach samples from the population of all test-statistics that are detected by the extraction method and that this population is different from the population of focal hypothesis tests. Therefore, the predictions by the statistical model can be biased to the extent that the two populations have different replication rates. This does not mean that these estimates are useless. Rather, a comparison with actual replication rates can be used to correct for this bias and make more accurate predictions about the replication rate of focal hypothesis tests. Ideally, these estimates can be validated in the future using hand-coding of focal hypothesis tests and actual reproducibility projects of articles published in 2021.
Validation of Z-Curve Predictions with the Reproducibility Project Results
The Reproducibility Project invited replications of studies published in three journals: Psychological Science, Journal of Experimental Psychology: Learning, Memory, and Cognition, and Journal of Personality and Social Psychology. Only articles published in 2008 were eligible.
To predict (the data preceded the criterion) the 37% success rate, I downloaded all articles from these three journals and searched the articles for reported chi2, t-test, F-test, and z-test results. Only results reported in the text were included. The extraction method found 10,951 statistical results. Test results were converted into absolute z-scores. The histogram of z-scores is shown in Figure 1.

Visual inspection of the z-curve shows that the peak of the distribution is right at the criterion for statistical significance (z = 1.96, p = .05 two-sided). The figure also shows clear evidence of selection for significance which is a well-known practice in psychology journals (Sterling, 1959; Sterling et al., 1995). The key result is the expected replication rate of 64%. This result is much higher than the actual replication rate of 37%. There are several explanations for this discrepancy. One explanation is of course that the estimate is based on a different population of test statistics. However, even predictions of hand-coded test results overestimate replication outcomes (Schimmack, 2020). Another reason is that z-curve predictions are based on the idealistic assumption that replication studies reproduce the original study exactly. However, it is likely that replication studies deviate at least in some minor details from the original studies. When selection for significance is present, this variation across studies implies regression to the mean and a lower replication rate. Thus, z-curve predictions are expected to overestimate actual success rates when selection for significance is present, which it clearly is.
Bartos and Schimmack (2021) suggested that the expected discovery rate (EDR) could be a better estimate of actual replication studies. The difference between EDR and ERR is again a difference between populations. The EDR is based on the population of all studies that were conducted. The ERR is based on the population of studies that were conducted and produced a significant result. The significance filter would select studies with higher power. However, if effect sizes vary across replications of the same study, this selection is imperfect and a study with less power could be selected because the study had an unusually large effect size that cannot be replicated. if the selection process is totally unable to distinguish between studies with higher or lower power, the success rate would match the EDR estimate. The EDR estimate of 26% is lower than the actual success rate of 37%, but not by much.
Based on these results, we see that z-curve correctly predicts that the actual success rate is higher than the EDR and lower than the ERR estimate. Using the average of the two estimates as the best prediction, we get a prediction of 45%, compared to the actual outcome of 37%. The remaining discrepancy could be partially due to the difference in populations of test statistics. Moreover, the 37% estimate is based on a small sample of studies and the difference may just be a chance finding.
In conclusion, the present results suggest that the average of the ERR and EDR estimates of z-curve models based on automatically extracted test statistics can predict actual replication outcomes. Of course this conclusion is based on a single observation (N = 1), but th problem is that there are no other actual replication outcomes that could be used to cross-validate this result.
Replication in 2010
Research practices did not change notably between 2008 and 2010. Furthermore, 2008 was arbitrarily selected by the Open Science Collaboration to estimate the reproducibility of psychological science. The following results therefore replicate the z-curve prediction based on a new dataset and examine the generalizabilty of the reproducibility project results across time.
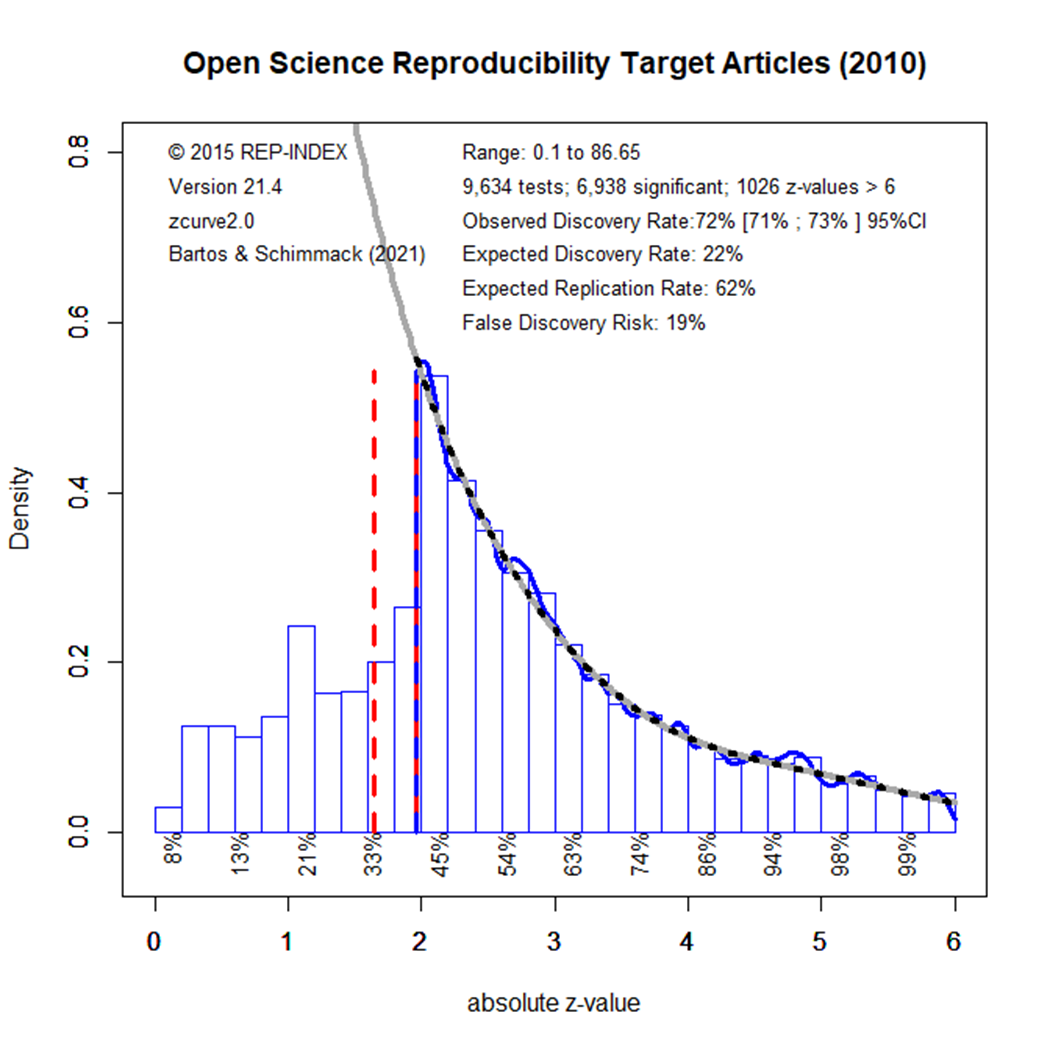
The results are very similar, indeed, and the predicted replication rate for actual replication studies is (62 + 22)/2 = 42%.
Expanding the Sample of Journals
The aim of the OSC project was to estimate the reproducibility of psychological science. A major limitation of the study was the focus on three journals that publish mostly experimental studies in cognitive and social psychology. However, psychology is a much more diverse science that studies development, personality, mental health, and the application of psychology in many areas. It is currently unclear whether replication rates in these other areas of psychology differ from those in experimental cognitive and social psychology. To examine this question, I downloaded all articles from 121 psychology journals published in 2010 (a list of the journals can be found here). Automatic extraction of test statistics from these journals produced 109,117 z-scores. Figure 3 shows the z-curve plot.

The observed discovery rate (i.e., the percentage of statistically significant results) is identical for the 3 OSC journals and the 120 journals, 72%. The expected discovery rate is slightly higher for the 120 journals, 28% vs. 22. The expected replication rate is also slightly higher for the broader set of journals, 67% vs. 62%. This implies a slightly higher estimate of the success rate if a random sample of studies from all areas of psychology were replicated, 48% vs. 42%. However, the difference of 6 percentage points is small and not substantially meaningful. Based on these results, it is reasonable to generalize the results of the OSC project to psychology in general. This average estimate may hide differences between disciplines. For example, the OSC project found that cognitive studies were more replicable than social studies, 50% vs. 25%. Results for individual journals also suggest differences between other disciplines.
Replicability in 2021
Undergraduate students at the University of Toronto Mississauga (Alisar Abdelrahman, Azeb Aboye, Whitney Buluma, Bill Chen, Sahrang Dorazahi, Samer El-Galmady, Surbhi Gupta, Ismail Kanca, Mustafa Khekani, Safana Nasir, Amber Saib, Mohammad Shahan, Swikriti Singh, Stuti Patel, Chuanyu Wu) downloaded all articles published in the same 121 journals in 2021. Automatic extraction of test statistics produced 161,361 z-scores. The increase is due to the publication of more articles in some of the journals.
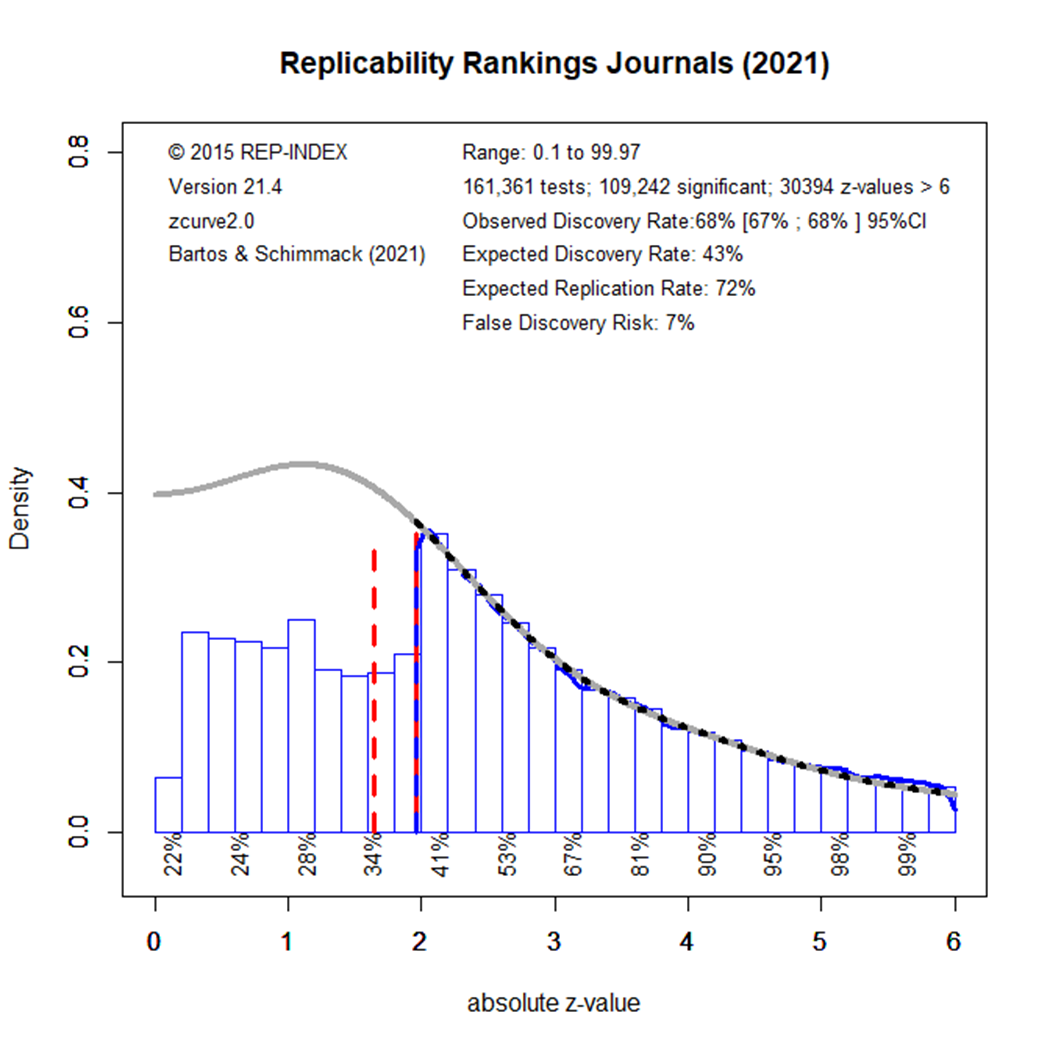
The expected discovery rate increased from 28% in 2010 to 43% in 2021. The expected replication rate showed a smaller increased from 67% to 72%. Based on these results, the z-curve model predicts that replications of a representative sample of focal hypothesis tests from 2021 would produce (43 + 72)/2 = 58%.
Interpretation
The key finding is that replicability in psychological science has increased in response to evidence that the replication rate in psychology is too low. However, replicability has increased only slightly and even a replication rate of 60% suggests that many published studies are underpowered. Moreover, results in 2021 still show evidence of selection for significance; the ODR is 68%, but the EDR is only 48%. It is well known that underpowered studies that are selected for significance produce inflated effect size estimates. Thus, readers of published articles need to be careful when they interpret effect size estimates. Moreover, results of single studies are insufficient to draw strong conclusions. Replication studies are needed to provide conclusive evidence of robust effects.
In sum, these results suggest that psychological science is improving. Whether the amount of improvement over the span of a decade is sufficient is open to subjective interpretation. At least, there is some improvement. This is noteworthy because many previous meta-psychological studies found no signs of improvement in response to concerns abou tthe replicability of published results (Sedlmeier & Gigerenzer, 1989). The present results show that meta-psychology can provide empirical information about psychological science nearly in real time. However, statistical predictions need to be complemented by actual replication studies and meta-psychologists should conduct a new reproducibiltiy project with a broader range of journals and articles published in the past years. This blog post pre-registers the prediction that the success rate will be higher than the 37% rate in the original reproducibility project and a success rate between 50-60%.