Update: October 24, 2017.
The preliminary 2017 rankings are now available. They provide information for the years 2010-2017, updated analyses, and a correction in the estimates due to a computational error that lowered estimates by about 10 percentage points, on average. Please check the newer rankings for the most reliable information.
—————————————————————————————————————————————–
I post the rankings on top. Detailed information and statistical analysis are provided below the table. You can click on the journal title to see Powergraphs for each year.
Notes.
1. Change scores are the unstandardized regression weights with replicabilty estimates as outcome variable and year as predictor variable. Year was coded from 0 for 2010 to 1 for 2016 so that the regression coefficient reflects change over the full 7 year period. This method is preferable to a simple difference score because estimates in individual years are variable and are likely to overestimate change.
2. Rich E. Lucas, Editor of JRP, noted that many articles in JRP do not report t of F values in the text and that the replicability estimates based on these statistics may not be representative of the bulk of results reported in this journal. Hand-coding of articles is required to address this problem and the ranking of JRP, and other journals, should be interpreted with caution (see further discussion of these issues below).
Introduction
I define replicability as the probability of obtaining a significant result in an exact replication of a study that produced a significant result. In the past five years, it has become increasingly clear that psychology suffers from a replication crisis. Even results that are replicated internally by the same author multiple times fail to replicate in independent replication attempts (Bem, 2011). The key reason for the replication crisis is selective publishing of significant results (publication bias). While journals report over 95% significant results (Sterling, 1959; Sterling et al., 1995), a 2015 article estimated that less than 50% of these results can be replicated (OSC, 2015).
The OSC reproducibility made an important contribution by demonstrating that published results in psychology have low replicability. However, the reliance on actual replication studies has a a number of limitations. First, actual replication studies are expensive or impossible (e.g., a longitudinal study spanning 20 years). Second, studies selected for replication may not be representative because the replication team lacks expertise to replicate some studies. Finally, replication studies take time and replicability of recent studies may not be known for several years. This makes it difficult to rely on actual replication studies to rank journals and to track replicability over time.
Schimmack and Brunner (2016) developed a statistical method (z-curve) that makes it possible to estimate average replicability for a set of published results based on the original results in published articles. This statistical approach to the estimation of replicability has several advantages over the use of actual replication studies. Replicability can be assessed in real time, it can be estimated for all published results, and it can be used for expensive studies that are impossible to reproduce. Finally, it has the advantage that actual replication studies can be criticized (Gilbert, King, Pettigrew, & Wilson, 2016). Estimates of replicabilty based on original studies do not have this problem because they are based on published results in original articles.
Z-curve has been validated with simulation studies and can be used when replicability varies across studies and when there is selection for significance, and is superior to similar statistical methods that correct for publication bias (Brunner & Schimmack, 2016). I use this method to estimate the average replicability of significant results published in 103 psychology journals. Separate estimates were obtained for the years from 2010, one year before the start of the replication crisis, to 2016 to examine whether replicability increased in response to discussions about replicability. The OSC estimate of replicability was based on articles published in 2008 and it was limited to three journals. I posted replicability estimates based on z-curve for the year 2015 (2015 replicability rankings). There was no evidence that replicability had increased during this time period.
The main empirical question was whether the 2016 rankings show some improvement in replicability and whether some journals or disciplines have responded more strongly to the replication crisis than others.
A second empirical question was whether replicabilty varies across disciplines. The OSC project provided first evidence that traditional cognitive psychology is more replicable than social psychology. Replicability estimates with z-curve confirmed this finding. In the 2015 rankings, The Journal of Experimental Psychology: Learning, Memory and Cognition ranked 25 with a replicability estimate of 74, whereas the two social psychology sections of the Journal of Personality and Social Psychology ranked 73 and 99 (68% and 60% replicability estimates). For this post, I conducted more extensive analyses of disciplines.
Journals
The 103 journals that are included in these rankings were mainly chosen based on impact factors. The list also includes diverse areas of psychology, including cognitive, developmental, social, personality, clinical, biological, and applied psychology. The 2015 list included some new journals that started after 2010. These journals were excluded from the 2016 rankings to avoid missing values in statistical analyses of time trends. A few journals were added to the list and the results may change when more journals are added to the list.
The journals were classified into 9 categories: social (24), cognitive (12), development (15), clinical/medical (19), biological (8), personality (5), and applied(IO,education) (8). Two journals were classified as general (Psychological Science, Frontiers in Psychology). The last category included topical, interdisciplinary journals (emotion, positive psychology).
Data
All PDF versions of published articles were downloaded and converted into text files. The 2015 rankings were based on conversions with the free program pdf2text pilot. The 2016 program used a superior conversion program pdfzilla. Text files were searched for reports of statistical results using my own R-code (z-extraction). Only F-tests, t-tests, and z-tests were used for the rankings. t-values that were reported without df were treated as z-values which leads to a slight inflation in replicability estimates. However, the bulk of test-statistics were F-values and t-values with degrees of freedom. A comparison of the 2015 rankings using the old method and the new method shows that extraction methods have an influence on replicability estimates some differences (r = .56). One reason for the low correlation is that replicability estimates have a relatively small range (50-80%) and low retest correlations. Thus, even small changes can have notable effects on rankings. For this reason, time trends in replicability have to be examined at the aggregate level of journals or over longer time intervals. The change score of a single journal from 2015 to 2016 is not a reliable measure of improvement.
Data Analysis
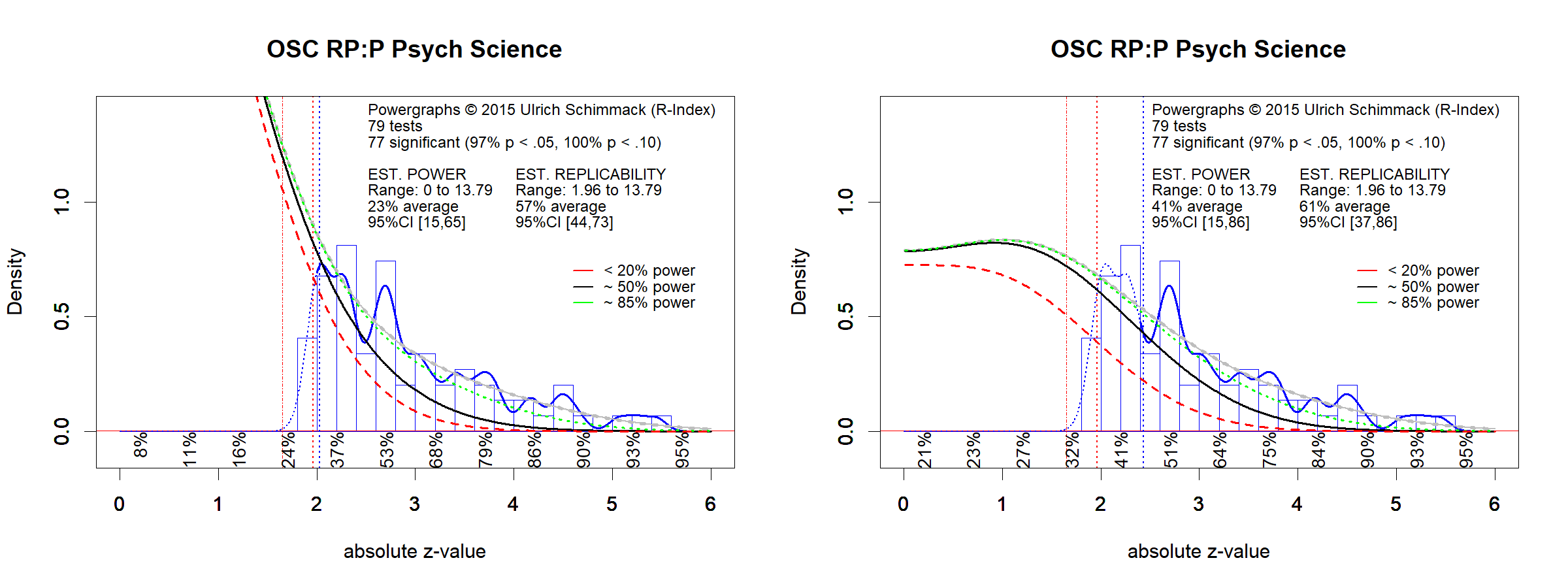
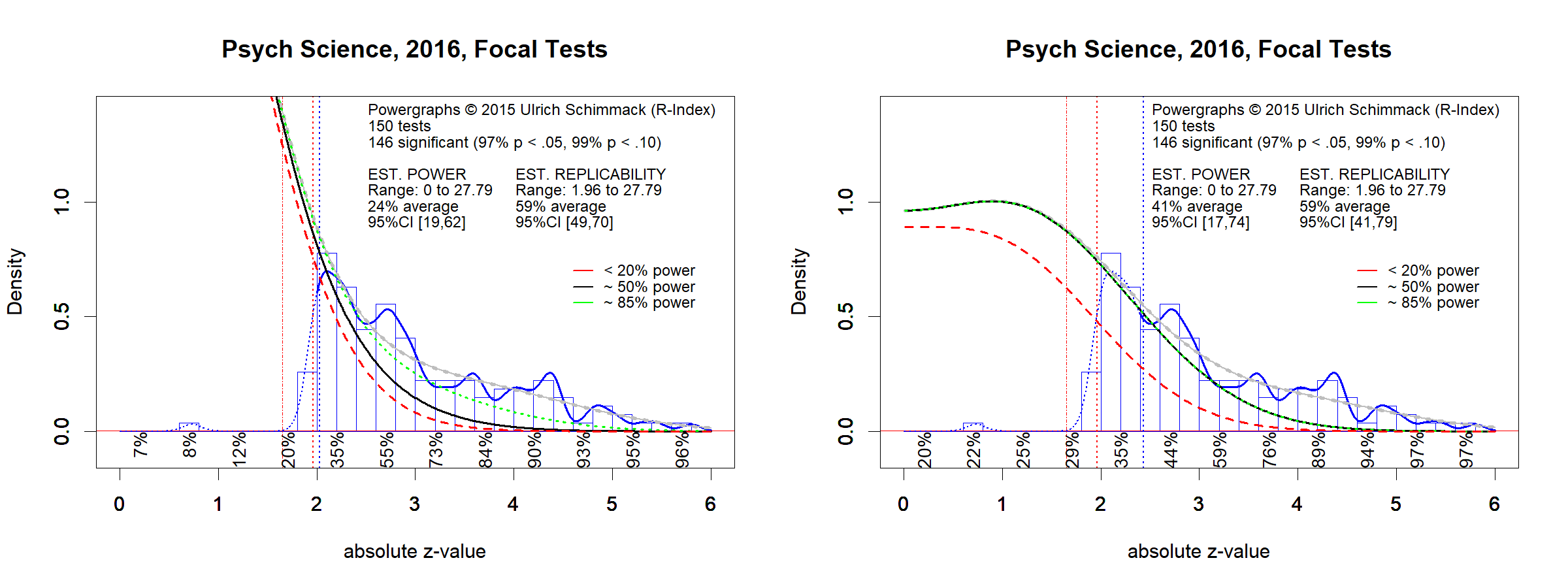
The data for each year were analyzed using z-curve Schimmack and Brunner (2016). The results of individual analysis are presented in Powergraphs. Powergraphs for each journal and year are provided as links to the journal names in the table with the rankings. Powergraphs convert test statistics into absolute z-scores as a common metric for the strength of evidence against the null-hypothesis. Absolute z-scores greater than 1.96 (p < .05, two-tailed) are considered statistically significant. The distribution of z-scores greater than 1.96 is used to estimate the average true power (not observed power) of the set of significant studies. This estimate is an estimate of replicability for a set of exact replication studies because average power determines the percentage of statistically significant results. Powergraphs provide additional information about replicability for different ranges of z-scores (z-values between 2 and 2.5 are less replicable than those between 4 and 4.5). However, for the replicability rankings only the replicability estimate is used.
Results
Table 1 shows the replicability estimates sorted by replicability in 2016.
The data were analyzed with a growth model to examine time trends and variability across journals and disciplines using MPLUS7.4. I compared three models. Model 1 assumed no mean level changes and variability across journals. Model 2 assumed a linear increase. Model 3 tested assumed no change from 2010 to 2015 and allowed for an increase in 2016.
Model 1 had acceptable fit (RMSEA = .043, BIC = 5004). Model 2 increased fit (RMSEA = 0.029, BIC = 5005), but BIC slightly favored the more parsimonious Model 1. Model 3 had the best fit (RMSEA = .000, BIC = 5001). These results reproduce the results of the 2015 analysis that there was no improvement from 2010 to 2015, but there is some evidence that replicability increased in 2016. Adding a variance component to slope in Model 3 produced an unidentified model. Subsequent analyses show that this is due to insufficient power to detect variation across journals in changes over time.
The standardized loadings of individual years on the latent intercept factor ranged from .49 to .58. This shows high variabibility in replicability estimates from year to year. Most of the rank changes can be attributed to random factors. A better way to compare journals is to average across years. A moving average of five years will provide reliable information and allow for improvement over time. The reliability of the 5-year average for the years 2012 to 2016 is 68%.
Figure 1 shows the annual averages with 95%CI as well relative to the average over the full 7-year period.

A paired t-test confirmed that average replicability in 2016 was significantly higher (M = 65, SD = 8) than in the previous years (M = 63, SD = 8), t(101) = 2.95, p = .004. This is the first evidence that psychological scientists are responding to the replicability crisis by publishing slightly more replicable results. Of course, this positive result has to be tempered by the small effect size. But if this trend continuous or even increases, replicability could reach 80% in 10 years.
The next analysis examined changes in replicabilty at the level of individual journals. Replicability estimates were regressed on a dummy variable that contrasted 2016 with the previous years. This analysis produced only 7 significant increases with p < .05 (one-tailed), which is only 2 more significant results than would be expected by chance alone. Thus, the analysis failed to identify particular journals that contribute to the improvement in the average. Figure 2 compares the observed distribution of t-values to the predicted distribution based on the null-hypothesis (no change).
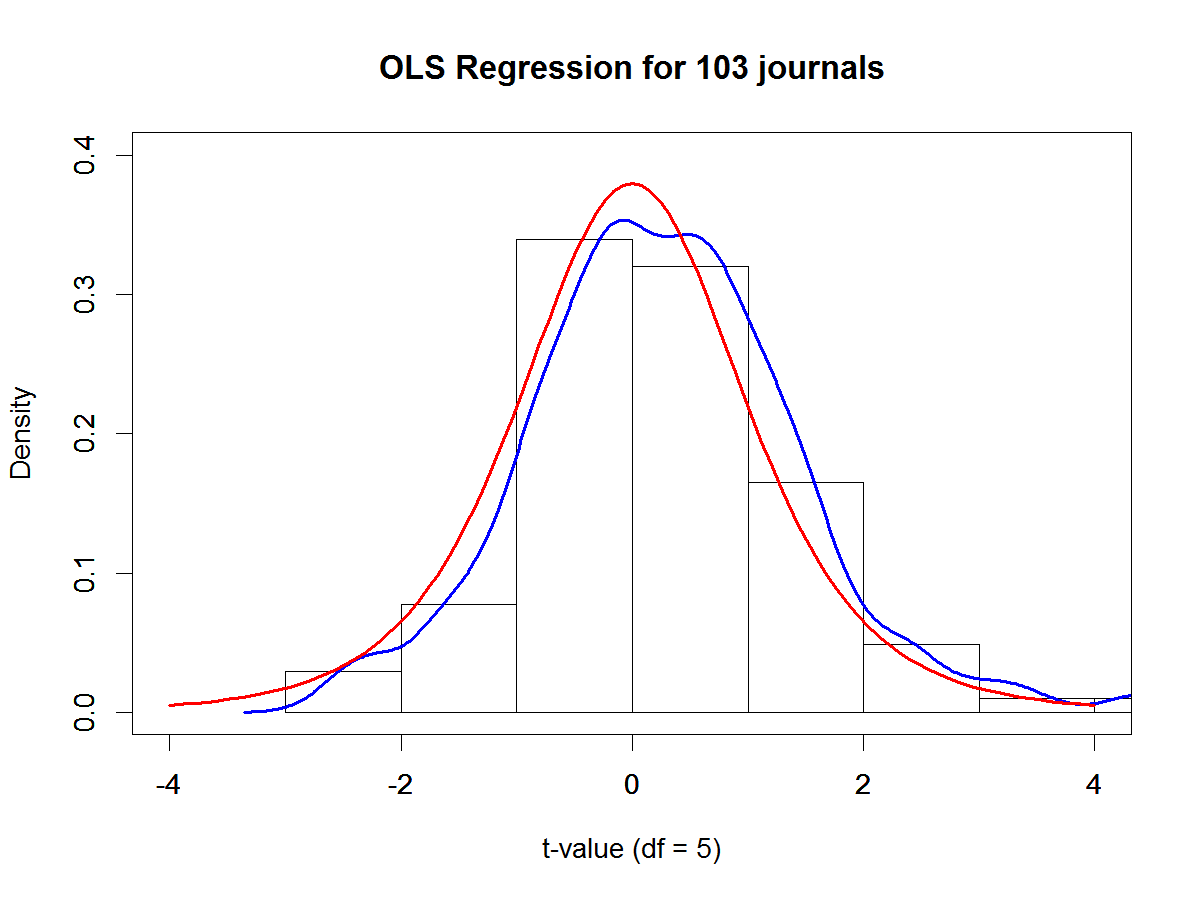
The blue line shows the observed density distribution, which is slightly moved to the right, but there is no set of journals with notably larger t-values. A more sustained and larger increase in replicability is needed to detect variability in change scores.
The next analyses examine stable differences between disciplines. The first analysis compared cognitive journals to social journals. No statistical tests are needed to see that cognitive journals publish more replicable results than social journals. This finding confirms the results with actual replications of studies published in 2008 (OSC, 2015). The Figure suggests that the improvement in 2016 is driven more by social journals, but only 2017 data can tell whether there is a real improvement in social psychology.

The next Figure shows the results for 5 personality journals. The large confidence intervals show that there is considerable variability among personality journals. The Figure shows the averages for cognitive and social psychology as horizontal lines. The average for personality is only slightly above the average for social and like social, personality shows an upward trend. In conclusion, personality and social psychology look very similar. This may be due to considerable overlap between the two disciplines, which is also reflected in shared journals. Larger differences may be visible for specialized social journals that focus on experimental social psychology.
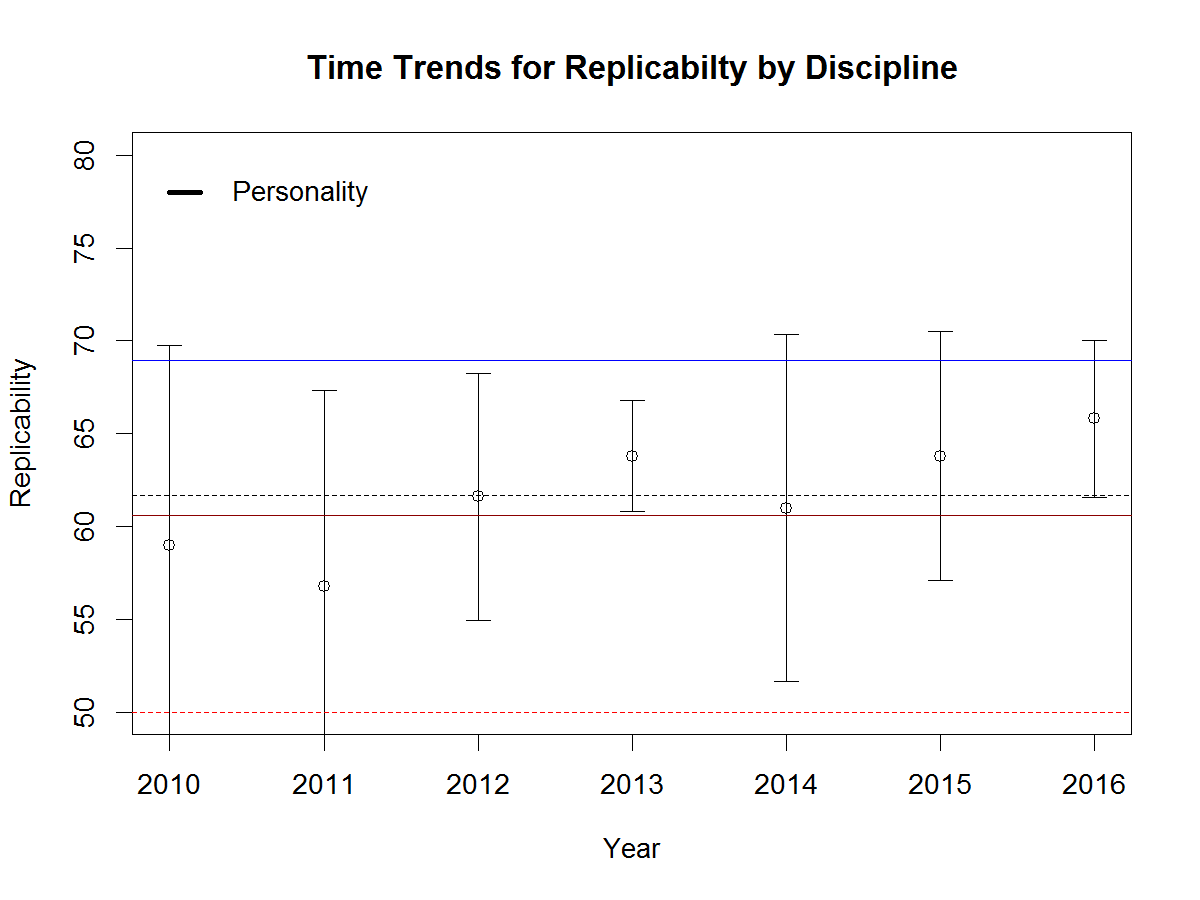
The results for developmental journals show no clear time trend and the average is just about in the middle between cognitive and social psychology. The wide confidence intervals suggest that there is considerable variability among developmental journals. Table 1 shows Developmental Psychology ranks 14 / 103 and Infancy ranks 101/103. The low rank for Infancy may be due to the great difficulty of measuring infant behavior.

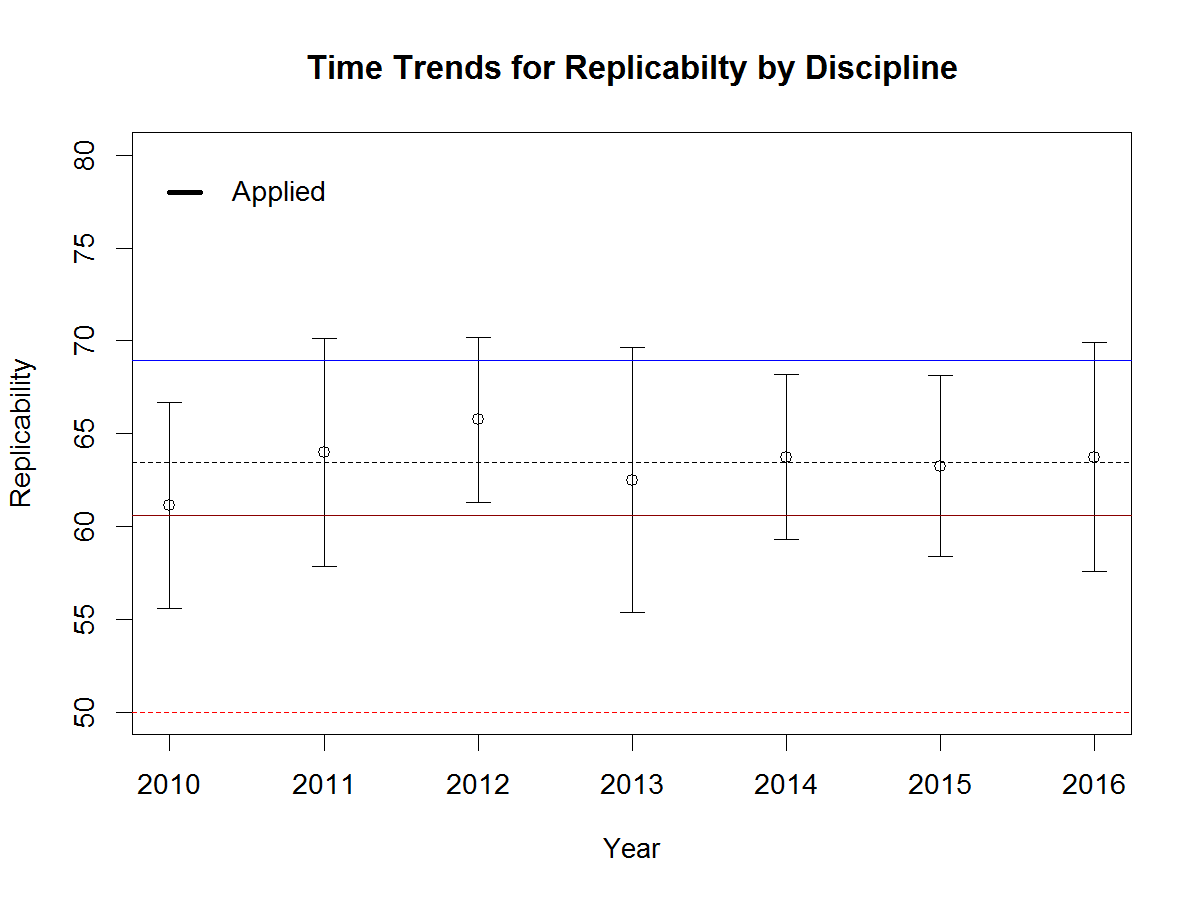
The clinical/medical journals cover a wide range of topics from health psychology to special areas of psychiatry. There has been some concern about replicability in medical research (Ioannidis, 2005). The results for clinical are similar to those for developmental journals. Replicability is lower than for cognitive psychology and higher than for social psychology. This may seem surprising because patient populations and samples tend to be smaller. However, a randomized controlled intervention study uses pre-post designs to boost power, whereas social and personality psychologists use comparisons across individuals, which requires large samples to reduce sampling error.

The set of biological journals is very heterogeneous and small. It includes neuroscience and classic peripheral physiology. Despite wide confidence intervals replicability for biological journals is significantly lower than replicabilty for cognitive psychology. There is no notable time trend. The average is slightly above the average for social journals.
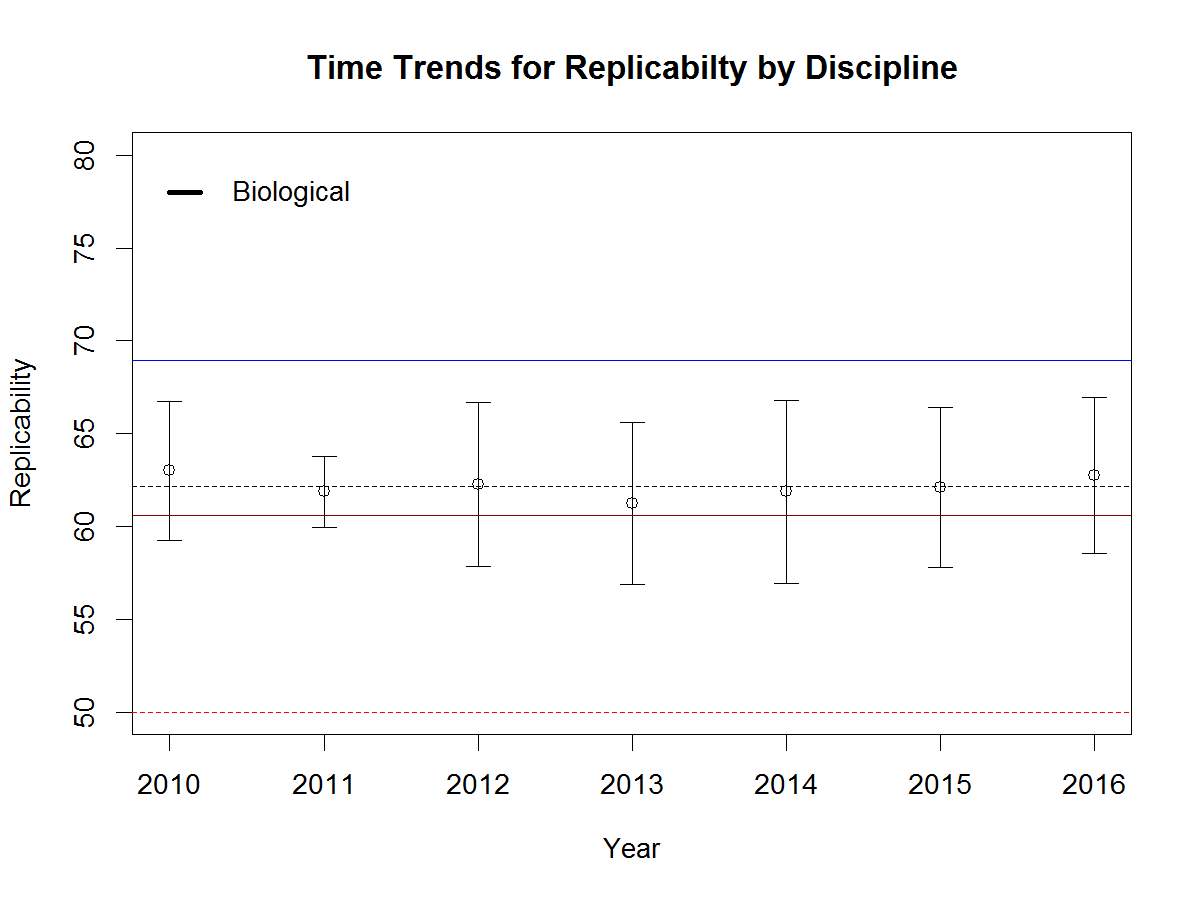
The last category are applied journals. One journal focuses on education. The other journals focus on industrial and organizational psychology. Confidence intervals are wide, but replicabilty is generally lower than for cognitive psychology. There is no notable time trend for this set of journals.
Given the stability of replicability, I averaged replicability estimates across years. The last figure shows a comparison of disciplines based on these averages. The figure shows that social psychology is significantly below average and cognitive psychology is significantly above average with the other disciplines falling in the middle. All averages are significantly above 50% and below 80%.
Discussion
The most exciting finding is that repicability appears to have increased in 2016. This increase is remarkable because averages in the years before consistently tracked the average of 63. The increase by 2 percentage points in 2016 is not large, but it may represent a first response to the replication crisis.
The increase is particularly remarkable because statisticians have been sounding the alarm bells about low power and publication bias for over 50 years (Cohen, 1962; Sterling, 1959), but these warnings have had no effect on research practices. In 1989, Sedlmeier and Gigerenzer (1989) noted that studies of statistical power had no effect on the statistical power of studies. The present results provide the first empirical evidence that psychologists are finally starting to change their research practices.
However, the results also suggest that most journals continue to publish articles with low power. The replication crisis has affected social psychology more than other disciplines with fierce debates in journals and on social media (Schimmack, 2016). On the one hand, the comparisons of disciplines supports the impression that social psychology has a bigger replicability problem than other disciplines. However, the differences between disciplines are small. With the exception of cognitive psychology, other disciplines are not a lot more replicable than social psychology. The main reason for the focus on social psychology is probably that these studies are easier to replicate and that there have been more replication studies in social psychology in recent years. The replicability rankings predict that other disciplines would also see a large number of replication failures, if they would subject important findings to actual replication attempts. Only empirical data will tell.
Limitations
The main limitation of replicability rankings is that the use of an automatic extraction method does not distinguish theoretically important hypothesis tests and other statistical tests. Although this is a problem for the interpretation of the absolute estimates, it is less important for the comparison over time. Any changes in research practices that reduce sampling error (e.g., larger samples, more reliable measures) will not only strengthen the evidence for focal hypothesis tests, but also increase the strength of evidence for non-focal hypothesis tests.
Schimmack and Brunner (2016) compared replicability estimates with actual success rates in the OSC (2015) replication studies. They found that the statistical method overestimates replicability by about 20%. Thus, the absolute estimates can be interpreted as very optimistic estimates. There are several reasons for this overestimation. One reason is that the estimation method assumes that all results with a p-value greater than .05 are equally likely to be published. If there are further selection mechanisms that favor smaller p-values, the method overestimates replicability. For example, sometimes researchers correct for multiple comparisons and need to meet a more stringent significance criterion. Only careful hand-coding of research articles can provide more accurate estimates of replicability. Schimmack and Brunner (2016) hand-coded the articles that were included in the OSC (2015) article and still found that the method overestimated replicability. Thus, the absolute values need to be interpreted with great caution and success rates of actual replication studies are expected to be at least 10% lower than these estimates.
Implications
Power and replicability have been ignored for over 50 years. A likely reason is that replicability is difficult to measure. A statistical method for the estimation of replicability changes this. Replicability estimates of journals make it possible for editors to compete with other journals in the replicability rankings. Flashy journals with high impact factors may publish eye-catching results, but if this journal has a reputation of publishing results that do not replicate, they are not very likely to have a big impact. Science is build on trust and trust has to be earned and can be easily lost. Eventually, journals that publish replicable results may also increase their impact because more researchers are going to build on replicable results published in these journals. In this way, replicability rankings can provide a much needed correction to the current incentive structure in science that rewards publishing as many articles as possible without any concerns about the replicability of these results. This reward structure is undermining science. It is time to change it. It is no longer sufficient to publish a significant result, if this result cannot be replicate in other labs.
Many scientists feel threatened by changes in the incentive structure and the negative consequences of replication failures for their reputation. However, researchers have control over their reputation. First, researchers often carry out many conceptually related studies. In the past, it was acceptable to publish only the studies that worked (p < .05). This selection for significance by researchers is the key factor in the replication crisis. The researchers who are conducting the studies are fully aware that it was difficult to get a significant result, but the selective reporting of these successes produces inflated effect size estimates and an illusion of high replicability that inevitably lead to replication failures. To avoid these embarrassing replication failures researchers need to report results of all studies or conduct fewer studies with high power. The 2016 rankings suggest that some researchers have started to change, but we will have to wait until 2017 to see whether 2017 can replicate the positive trend in the 2016 rankings.










{kind=link}
{kind=link}