
Over the past five years, psychological science has been in a crisis of confidence. For decades, psychologists have assumed that published significant results provide strong evidence for theoretically derived predictions, especially when authors presented multiple studies with internal replications within a single article (Schimmack, 2012). However, even multiple significant results provide little empirical evidence, when journals only publish significant results (Sterling, 1959; Sterling et al., 1995). When published results are selected for significance, statistical significance loses its ability to distinguish replicable effects from results that are difficult to replicate or results that are type-I errors (i.e., the theoretical prediction was false).
The crisis of confidence led to several initiatives to conduct independent replications. The most informative replication initiative was conducted by the Open Science Collaborative (Science, 2015). It replicated close to 100 significant results published in three high-ranked psychology journals. Only 36% of the replication studies replicated a statistically significant result. The replication success rate varied by journal. The journal “Psychological Science” achieved a success rate of 42%.
The low success rate raises concerns about the empirical foundations of psychology as a science. Without further information, a success rate of 42% implies that it is unclear which published results provide credible evidence for a theory and which findings may not replicate. It is impossible to conduct actual replication studies for all published studies. Thus, it is highly desirable to identify replicable findings in the existing literature.
One solution is to estimate replicability for sets of studies based on the published test statistics (e.g., F-statistic, t-values, etc.). Schimmack and Brunner (2016) developed a statistical method, Powergraphs, that estimates the average replicability of a set of significant results. This method has been used to estimate replicability of psychology journals using automatic extraction of test statistics (2016 Replicability Rankings, Schimmack, 2017). The results for Psychological Science produced estimates in the range from 55% to 63% for the years 2010-2016 with an average of 59%. This is notably higher than the success rate for the actual replication studies, which only produced 42% successful replications.
There are two explanations for this discrepancy. First, actual replication studies are not exact replication studies and differences between the original and the replication studies may explain some replication failures. Second, the automatic extraction method may overestimate replicability because it may include non-focal statistical tests. For example, significance tests of manipulation checks can be highly replicable, but do not speak to the replicability of theoretically important predictions.
To address the concern about automatic extraction of test statistics, I estimated replicability of focal hypothesis tests in Psychological Science with hand-coded, focal hypothesis tests. I used three independent data sets.
Study 1
For Study 1, I hand-coded focal hypothesis tests of all studies in the 2008 Psychological Science articles that were used for the OSC reproducibility project (Science, 2015).
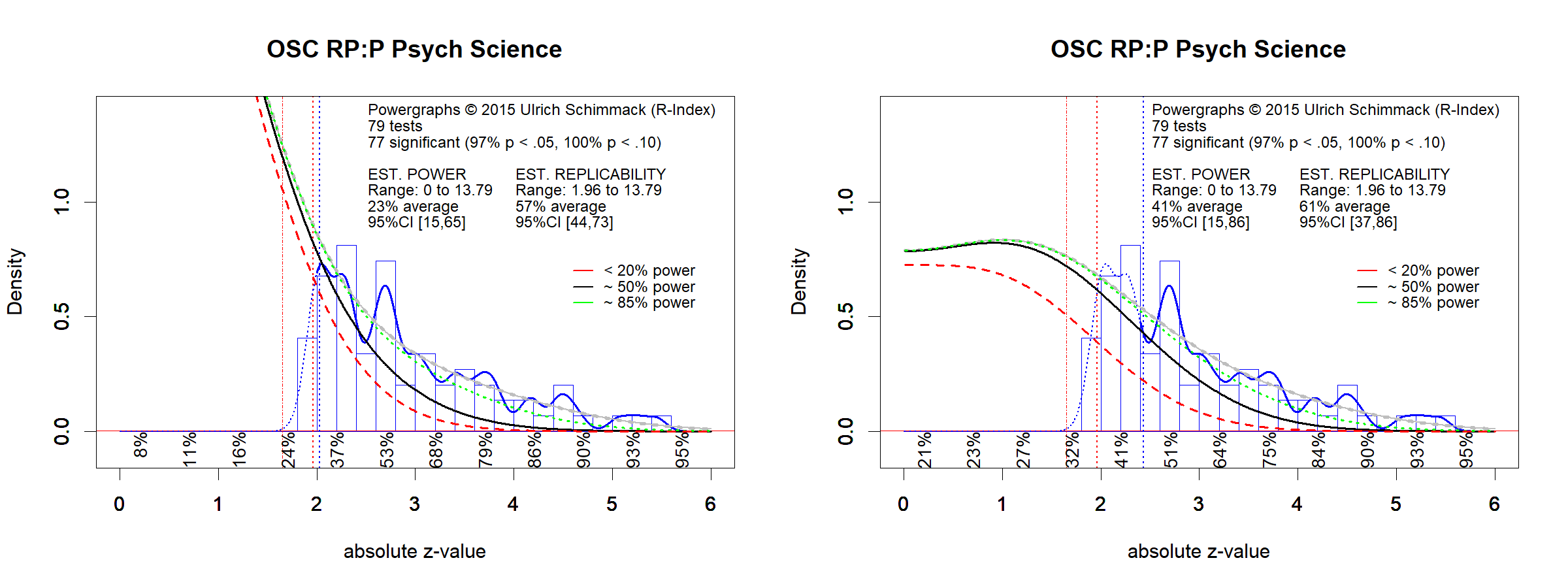
The powergraphs show the well-known effect of publication bias in that most published focal hypothesis tests report a significant result (p < .05, two-tailed, z > 1.96) or at least a marginally significant result (p < .10, two-tailed or p < .05, one-tailed, z > 1.65). Powergraphs estimate the average power of studies with significant results on the basis of the density distribution of significant z-scores. Average power is an estimate of replicabilty for a set of exact replication studies. The left graph uses all significant results. The right graph uses only z-scores greater than 2.4 because questionable research practices may produce many just-significant results and lead to biased estimates of replicability. However, both estimation methods produce similar estimates of replicability (57% & 61%). Given the small number of statistics the 95%CI is relatively wide (left graph: 44% to 73%). These results are compatible with the low actual success rate for actual replication studies (42%) and the estimate based on automated extraction (59%).
Study 2
The second dataset was provided by Motyl et al. (JPSP, in press), who coded a large number of articles from social psychology journals and psychological science. Importantly, they coded a representative sample of Psychological Science studies from the years 2003, 2004, 2013, and 2014. That is, they did not only code social psychology articles published in Psychological Science. The dataset included 281 test statistics from Psychological Science.

The powergraph looks similar to the powergraph in Study 1. More important, the replicability estimates are also similar (57% & 52%). The 95%CI for Study 1 (44% to 73%) and Study 2 (left graph: 49% to 65%) overlap considerably. Thus, two independent coding schemes and different sets of studies (2008 vs. 2003-2004/2013/2014) produce very similar results.
Study 3
Study 3 was carried out in collaboration with Sivaani Sivaselvachandran, who hand-coded articles from Psychological Science published in 2016. The replicability rankings showed a slight positive trend based on automatically extracted test statistics. The goal of this study was to examine whether hand-coding would also show an increase in replicability. An increase was expected based on an editorial by D. Stephen Linday, incoming editor in 2015, who aimed to increase replicability of results published in Psychological Science by introducing badges for open data and preregistered hypotheses. However, the results failed to show a notable increase in average replicability.
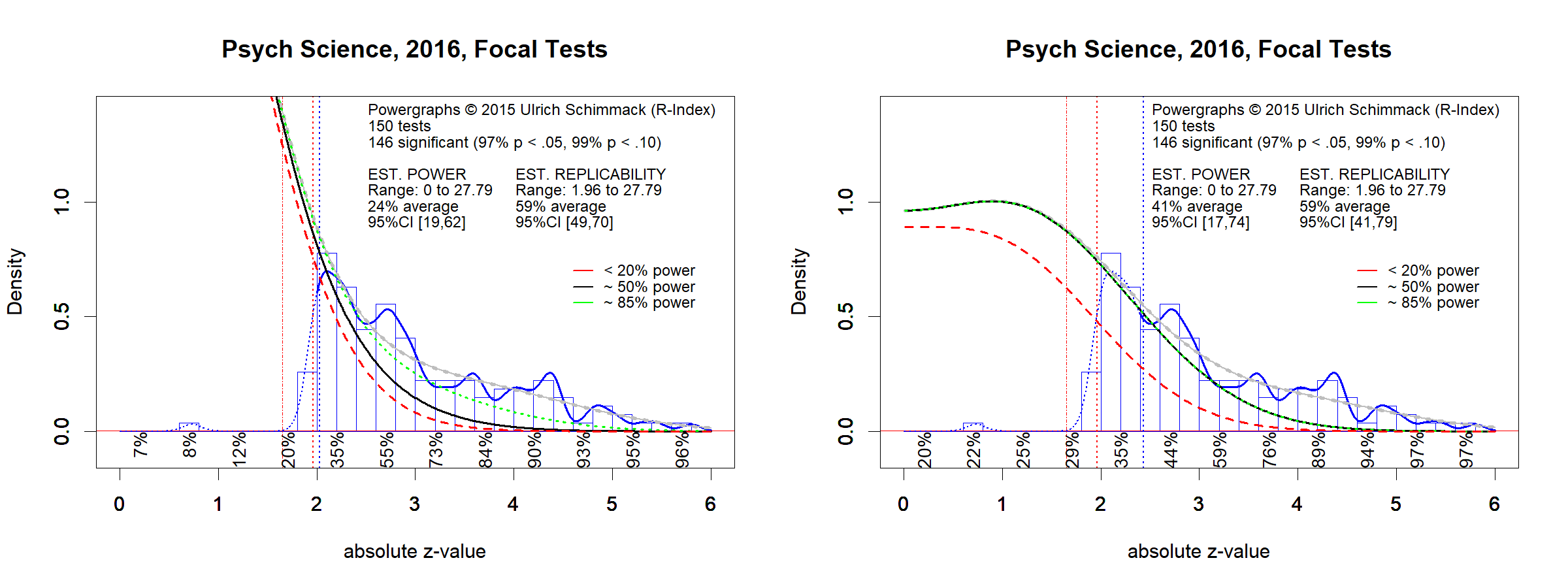
The replicability estimate was similar to those in the first two studies (59% & 59%). The 95%CI ranged from 49% to 70%. These wide confidence intervals make it difficult to notice small improvements, but the histogram shows that just significant results (z = 2 to 2.2) are still the most prevalent results reported in Psychological Science and that non-significant results that are to be expected are not reported.
Combined Analysis
Given the similar results in all three studies, it made sense to pool the data to obtain the most precise estimate of replicability of results published in Psychological Science. With 479 significant test statistics, replicability was estimated at 58% with a 95%CI ranging from 51% to 64%. This result is in line with the estimated based on automated extraction of test statistics (59%). The reason for the close match between hand-coded and automated results could be that Psych Science publishes short articles and authors may report mostly focal results because space does not allow for extensive reporting of other statistics. The hand-coded data confirm that replicabilty in Psychological Science is likely to be above 50%.

It is important to realize that the 58% estimate is an average. Powergraphs also show average replicability for segments of z-scores. Here we see that replicabilty for just-significant results (z < 2.5 ~ p > .01) is only 35%. Even for z-score between 2.5 and 3.0 (~ p > .001) is only 47%. Once z-scores are greater than 3, average replicabilty is above 50% and with z-scores greater than 4, replicability is greater than 80%. For any single study, p-values can vary greatly due to sampling error, but in general a published result with a p-value < .001 is much more likely to replicate than a p-value > .01 (see also OSC, Science, 2015).
Conclusion
This blog-post used hand-coding of test-statistics published in Psychological Science, the flagship journal of the Association for Psychological Science, to estimate replicabilty of published results. Three dataset produced convergent evidence that the average replicabilty of exact replication studies is 58% +/- 7%. This result is consistent with estimates based on automatic extraction of test statistics. It is considerably higher than the success rate of actual replication studies in the OSC reproducibility project (42%). One possible reason for this discrepancy is that actual replication studies are never exact replication studies, which makes it more difficult to obtain statistical significance if the original studies are selected for significance. For example, the original study may have had an outlier in the experimental group that helped to produce a significant result. Not removing this outlier is not considered a questionable research practice, but an exact replication study will not reproduce the same outlier and may fail to reproduce a just-significant result. More broadly, any deviation from the assumptions underlying the computation of test statistics will increase the bias that is introduced by selecting significant results. Thus, the 58% estimate is an optimistic estimate of the maximum replicability under ideal conditions.
At the same time, it is important to point out that 58% replicability for Psychological Science does not mean psychological science is rotten to the core (Motyl et al., in press) or that most reported results are false (Ioannidis, 2005). Even results that did not replicate in actual replication studies are not necessarily false positive results. It is possible that more powerful studies would produce a significant result, but with a smaller effect size estimate.
Hopefully, these analyses will spur further efforts to increase replicability of published results in Psychological Science and in other journals. We are already near the middle of 2017 and can look forward to the 2017 results.
1 thought on “How Replicable are Focal Hypothesis Tests in the Journal Psychological Science?”