I was going to write this blog post eventually, but the online first publication of Radosic and Diener’s (2021) article “Citation Metrics in Psychological Science” provided a good opportunity to do so now.
Radosic and Diener’s (2021) article’s main purpose was to “provide norms to help evaluate the citation counts of psychological scientists” (p. 1). The authors also specify the purpose of these evaluations. “Citation metrics are one source of information that can be used in hiring, promotion, awards, and funding, and our goal is to help these evaluations” (p. 1).
The authors caution readers that they are agnostic about the validity of citation counts as a measure of good science. “The merits and demerits of citation counts are beyond the scope of the current article” (p. 8). Yet, they suggest that “there is much to recommend citation numbers in evaluating scholarly records” (p. 11).
At the same time, they list some potential limitations of using citation metrics to evaluate researchers.
1. Articles that developed a scale can have high citation counts. For example, Ed Diener has over 71,000 citations. His most cited article is the 1985 article with his Satisfaction with Life Scale. With 12,000 citations, it accounts for 17% of his citations. The fact that articles that published a measure have such high citation counts reflects a problem in psychological science. Researchers continue to use the first measure that was developed for a new construct (e.g., Rosenberg’s 1965 self-esteem scale) instead of improving measurement which would lead to citations of newer articles. So, the high citation counts of articles with scales is a problem, but it is only a problem if citation counts are used as a metric. A better metric is the H-Index that takes number of publications and citations into account. Ed Diener also has a very high H-Index of 108 publications with 108 or more citations. His scale article is only of these articles. Thus, scale development articles are not a major problem.
2. Review articles are cited more heavily than original research articles. Once more, Ed Diener is a good example. His second and third most cited articles are the 1984 and the co-authored 1999 Psychological Bulletin review articles on subjective well-being that together account for another 9,000 citations (13%). However, even review articles are not a problem. First, they also are unlikely to have an undue influence on the H-Index and second it is possible to exclude review articles and to compute metrics only for empirical articles. Web of Science makes this very easy. In WebofScience 361 out of Diener’s 469 publications are listed as articles. The others are listed as reviews, book chapters, or meeting abstracts. With a click of a button, we can produce the citation metrics only for the 361 articles. The H-Index drops from 108 to 102. Careful hand-selection of articles is unlikely to change this.
3. Finally, Radosic and Diener (2021) mention large-scale collaborations as a problem. For example, one of the most important research projects in psychological science in the last decade was the Reproducibility Project that examined the replicability of psychological science with 100 replication studies (Open Science Collaboration, 2015). This project required a major effort by many researchers. Participation earned researchers over 2,000 citations in just five years and the article is likely to be the most cited article for many of the collaborators. I do not see this as a problem because large-scale collaborations are important and can produce results that no single lab can produce. Thus, high citation counts provide a good incentive to engage in these collaborations.
To conclude, Radosic and Diener’s article provides norms for a citation counts that can and will be used to evaluate psychological scientists. However, the article sidesteps the main question about the use of citation metrics, namely (a) what criteria should be used to evaluate scientists and (b) are citation metrics valid indicators of these criteria. In short, the article is just another example that psychologists develop and promote measures without examining their construct validity (Schimmack, 2021).
What is a good scientists?
I didn’t do an online study to examine the ideal prototype of a scientist, so I have to rely on my own image of a good scientist. A key criterion is to search for some objectively verifiable information that can inform our understanding of the world, or in psychology ourselves; that is, humans affect, behavior, and cognition – the ABC of psychology. The second criterion elaborates the term objective. Scientists use methods that produce the same results independent of the user of the methods. That is, studies should be reproducible and results should be replicable within the margins of error. Third, the research question should have some significance beyond the personal interests of a scientist. This is of course a tricky criterion, but research that solves major problems like finding a vaccine for Covid-19 is more valuable and more likely to receive citations than research on the liking of cats versus dogs (I know, this is the most controversial statement I am making; go cats!). The problem is that not everybody can do research that is equally important to a large number of people. Once more Ed Diener is a good example. In the 1980s, he decided to study human happiness, which was not a major topic in psychology. Ed Diener’s high H-Index reflects his choice of a topic that is of interest to pretty much everybody. In contrast, research on stigma of minority groups is not of interest to a large group of people and unlikely to attract the same amount of attention. Thus, a blind focus on citation metrics is likely to lead to research on general topics and avoid research that applies research to specific problems. The problem is clearly visible in research on prejudice, where the past 20 years have produced hundreds of studies with button-press tasks by White researchers with White participants that gobbled up funding that could have been used for BIBOC researchers to study the actual issues in BIPOC populations. In short, relevance and significance of research is very difficult to evaluate, but it is unlikely to be reflected in citation metrics. Thus, a danger is that metrics are being used because they are easy to measure and relevance is not being used because it is harder to measure.
Do Citation Metrics Reward Good or Bad Research?
The main justification for the use of citation metrics is the hypothesis that the wisdom of crowds will lead to more citations of high quality work.
“The argument in favor of personal judgments overlooks the fact that citation counts are also based on judgments by scholars. In the case of citation counts, however, those judgments are broadly derived from the whole scholarly community and are weighted by the scholars who are publishing about the topic of the cited publications. Thus, there is much to recommend citation
numbers in evaluating scholarly records.” (Radosic & Diener, 2021, p. 8).
This statement is out of touch with discussions about psychological science over the past decade in the wake of the replication crisis (see Schimmack, 2020, for a review; I have to cite myself to get up my citation metrics. LOL). In order to get published and cited, researchers of original research articles in psychological science need statistically significant p-values. The problem is that it can be difficult to find significant results when novel hypotheses are false or effect sizes are small. Given the pressure to publish in order to rise in the H-Index rankings, psychologists have learned to use a number of statistical tricks to get significant results in the absence of strong evidence in the data. These tricks are known as questionable research practices, but most researchers think they are acceptable (John et al., 2012). However, these practices undermine the value of significance testing and published results may be false positives or difficult to replicate, and do not add to the progress of science. Thus, citation metrics may have the negative consequence to pressure scientists into using bad practices and to reward scientists who publish more false results just because they publish more.
Meta-psychologists have produced strong evidence that the use of these practices was widespread and accounts for the majority of replication failures that occurred over the past decade.

Motyl et al. (2017) collected focal test statistics from a representative sample of articles in social psychology. I analyzed their data using z-curve.2.0 (Brunner & Schimmack, 2020; Bartos & Schimmack, 2021). Figure 1 shows the distribution of the test-statistics after converting them into absolute z-scores, where higher values show a higher signal/noise (effect size / sampling error) ratio. A z-score of 1.96 is needed to claim a discovery with p < .05 (two-sided). Consistent with publication practices since the 1960s, most focal hypothesis tests confirm predictions (Sterling, 1959). The observed discovery rate is 90% and even higher if marginally significant results are included (z > 1.65). This high success rate is not something to celebrate. Even I could win all marathons if I use a short-cut and run only 5km. The problem with this high success rate is clearly visible when we fit a model to the distribution of the significant z-scores and extrapolate the distribution of z-scores that are not significant (the blue curve in the figure). Based on this distribution, the significant results are only 19% of all tests, indicating that many more non-significant results are expected than observed. The discrepancy between the observed and estimated discovery rate provides some indication of the use of questionable research practices. Moreover, the estimated discovery rate shows how much statistical power studies have to produce significant results without questionable research practices. The results confirm suspicions that power in social psychology is abysmally low (Cohen, 1961; Tversky & Kahneman, 1971).
The use of questionable practices makes it possible that citation metrics may be invalid. When everybody in a research field uses p < .05 as a criterion to evaluate manuscripts and these p-values are obtained with questionable research practices, the system will reward researchers how use the most questionable methods to produce more questionable results than their peers. In other words, citation metrics are no longer a valid criterion of research quality. Instead, bad research is selected and rewarded (Smaldino & McElreath, 2016). However, it is also possible that implicit knowledge helps researchers to focus on robust results and that questionable research practices are not rewarded. For example, prediction markets suggest that it is fairly easy to spot shoddy research and to predict replication failures (Dreber et al., 2015). Thus, we cannot assume that citation metrics are valid or invalid. Instead, citation metrics – like all measures – require a program of construct validation.
Do Citation Metrics Take Statistical Power Into Account?
A few days ago, I published the first results of an ongoing research project that examines the relationship between researchers’ citation metrics and estimates of the average power of their studies based on z-curve analyses like the one shown in Figure 1 (see Schimmack, 2021, for details). The key finding is that there is no statistically or practically significant relationship between researchers H-Index and the average power of their studies. Thus, researchers who invest a lot of resources in their studies to produce results with a low false positive risk and high replicability are not cited more than researchers who flood journals with low powered studies that produce questionable results that are difficult to replicate.

These results show a major problem of citation metrics. Although methodologists have warned against underpowered studies, researchers have continued to use underpowered studies because they can use questionable practices to produce the desired outcome. This strategy is beneficial for scientists and their career, but hurts the larger goal of science to produce a credible body of knowledge. This does not mean that we need to abandon citation metrics altogether, but it must be complemented with other information that reflects the quality of researchers data.
The Power-Corrected H-Index
In my 2020 review article, I proposed to weight the H-Index by estimates of researchers’ replicability. For my illustration, I used the estimated replication rate, which is the average power of significant tests, p < .05 (Brunner & Schimmack, 2020). One advantage of the ERR is that it is highly reliable. The reliability of the ERRs for 300 social psychologists is .90. However, the ERR has some limitations. First, it predicts replication outcomes under the unrealistic assumption that psychological studies can be replicated exactly. However, it has been pointed out that this often impossible, especially in social psychology (Strobe & Strack, 2014). As a result, ERR predictions are overly optimistic and overestimate the success rate of actual replication studies (Bartos & Schimmack, 2021). In contrast, EDR estimates are much more in line with actual replication outcomes because effect sizes in replication studies can regress towards the mean. For example, Figure 1 shows an EDR of 19% for social psychology and the actual success rate (if we can call it that) for social psychology was 25% in the reproducibility project (Open Science Collaboration, 2015). Another advantage of the EDR is that it is sensitive to questionable research practices that tend to produce an abundance of p-values that are just significant. Thus, the EDR more strongly punishes researchers for using these undesirable practices. The main limitation of the EDR is that it is less reliable than the ERR. The reliability for 300 social psychologists was only .5. Of course, it is not necessary to chose between ERR and EDR. Just like there are many citation metrics, it is possible to evaluate the pattern of power-corrected metrics using ERR and EDR. I am presenting both values here, but the rankings are sorted by EDR weighted H-Indices.
The H-Index is an absolute number that can range from 0 to infinity. In contrast, power is limited to a range from 5% (with alpha = .05) to 100%. Thus, it makes sense to use power as a weight and to weight the H-index by a researchers EDR. A researcher who published only studies with 100% power has a power-corrected H-Index that is equivalent to the actual H-Index. The average EDR of social psychologists, however, is 35%. Thus, the average H-index is reduced to a third of the unadjusted value.
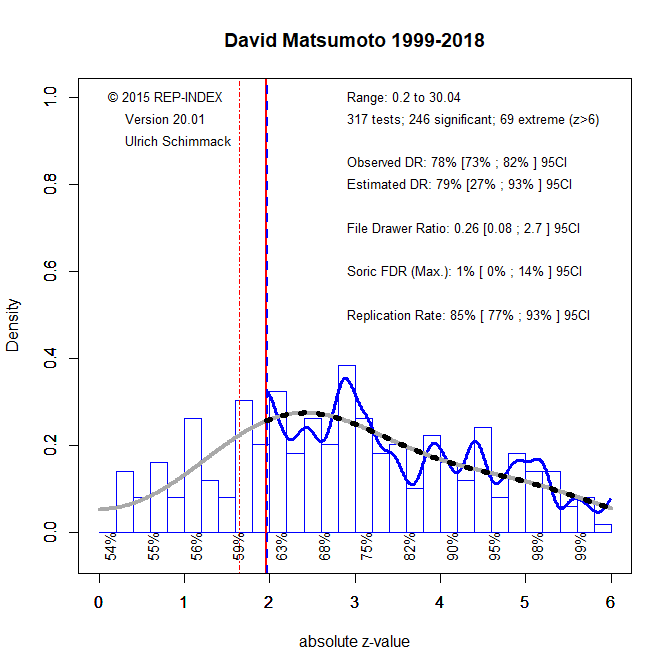
To illustrate this approach, I am using two researchers with a large H-Index, but different EDRs. One researcher is James J. Gross with an H-Index of 99 in WebofScience. His z-curve plot shows some evidence that questionable research practices were used to report 72% significant results with 50% power. However, the 95%CI around the EDR ranges from 23% to 78% and includes the point estimate. Thus, the evidence for QRPs is weak and not statistically significant. More important, the EDR -corrected H-Index is 90 * .50 = 45.

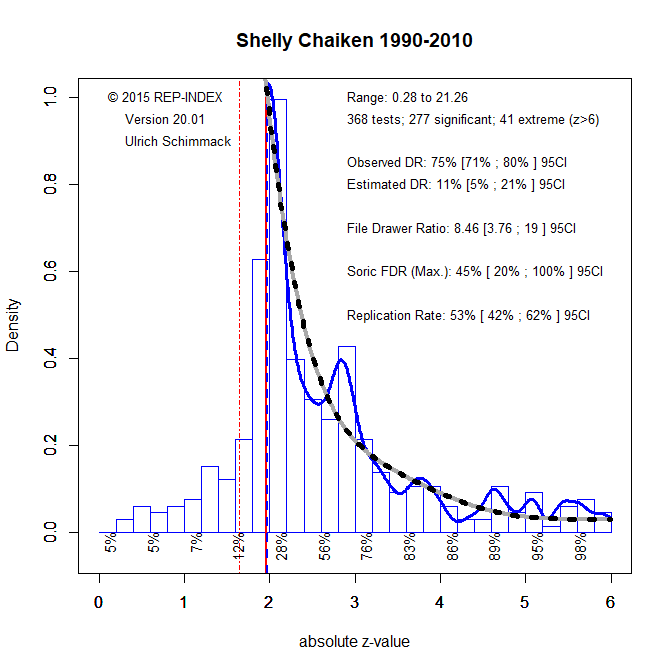
A different example is provided by Shelly E. Taylor with a similarly high H-Index of 84, but her z-curve plot shows clear evidence that the observed discovery rate is inflated by questionable research practices. Her low EDR reduces the H-Index considerably and results in a PC-H-Index of only 12.6.

Weighing the two researchers’ H-Index by their respective ERR’s, 77 vs. 54, has similar, but less extreme effects in absolute terms, ERR-adjusted H-Indices of 76 vs. 45.
In the sample of 300 social psychologists, the H-Index (r = .74) and the EDR (r = .65) contribute about equal amounts of variance to the power-corrected H-Index. Of course, a different formula could be used to weigh power more or less.
Discussion
Ed Diener is best known for his efforts to measure well-being and to point out that traditional economic indicators of well-being are imperfect. While wealth of countries is a strong predictor of citizens’ average well-being, r ~ .8, income is a poor predictor of individuals’ well-being with countries. However, economists continue to rely on income and GDP because it is more easily quantified and counted than subjective life-evaluations. Ironically, Diener advocates the opposite approach when it comes to measuring research quality. Counting articles and citations is relatively easy and objective, but it may not measure what we really want to measure, namely how much is somebody contributing to the advancement of knowledge. The construct of scientific advancement is probably as difficult to define as well-being, but producing replicable results with reproducible studies is one important criterion of good science. At present, citation metrics fail to track this indicator of research quality. Z-curve analyses of published results make it possible to measure this aspect of good science and I recommend to take it into account when researchers are being evaluated.
However, I do not recommend the use of quantitative information for the evaluation of hiring and promotion decisions. The reward system in science is too biased to reward privileged upper-class, White, US Americans (see APS rising stars lists). That being said, a close examination of published articles can be used to detect and eliminate researchers who severely p-hacked to get their significant results. Open science criteria can also be used to evaluate researchers who are just starting their career.
In conclusion, Radosic and Diener’s (2021) article disappointed me because it sidesteps the fundamental questions about the validity of citation metrics as a criterion for scientific excellence.
Conflict of Interest Statement: At the beginning of my career I was motivated to succeed in psychological science by publishing as many JPSP articles as possible and I made the unhealthy mistake to try to compete with Ed Diener. That didn’t work out for me. Maybe I am just biased against citation metrics because my work is not cited as much as I would like. Alternatively, my disillusionment with the system reflects some real problems with the reward structure in psychological science and helped me to see the light. The goal of science cannot be to have the most articles or the most citations, if these metrics do not really reflect scientific contributions. Chasing indicators is a trap, just like chasing happiness is a trap. Most scientists can hope to make maybe one lasting contribution to the advancement of knowledge. You need to please others to stay in the game, but beyond those minimum requirements to get tenure, personal criteria of success are better than social comparisons for the well-being of science and scientists. The only criterion that is healthy is to maximize statistical power. As Cohen said, less is more and by this criterion psychology is not doing well as more and more research is published with little concern about quality.
| Name | EDR.H.Index | ERR.H.Index | H-Index | EDR | ERR |
| James J. Gross | 50 | 76 | 99 | 50 | 77 |
| John T. Cacioppo | 48 | 70 | 102 | 47 | 69 |
| Richard M. Ryan | 46 | 61 | 89 | 52 | 69 |
| Robert A. Emmons | 39 | 40 | 46 | 85 | 88 |
| Edward L. Deci | 36 | 43 | 69 | 52 | 63 |
| Richard W. Robins | 34 | 40 | 57 | 60 | 70 |
| Jean M. Twenge | 33 | 35 | 59 | 56 | 59 |
| William B. Swann Jr. | 32 | 44 | 55 | 59 | 80 |
| Matthew D. Lieberman | 31 | 54 | 67 | 47 | 80 |
| Roy F. Baumeister | 31 | 53 | 101 | 31 | 52 |
| David Matsumoto | 31 | 33 | 39 | 79 | 85 |
| Carol D. Ryff | 31 | 36 | 48 | 64 | 76 |
| Dacher Keltner | 31 | 44 | 68 | 45 | 64 |
| Michael E. McCullough | 30 | 34 | 44 | 69 | 78 |
| Kipling D. Williams | 30 | 34 | 44 | 69 | 77 |
| Thomas N Bradbury | 30 | 33 | 48 | 63 | 69 |
| Richard J. Davidson | 30 | 55 | 108 | 28 | 51 |
| Phoebe C. Ellsworth | 30 | 33 | 46 | 65 | 72 |
| Mario Mikulincer | 30 | 45 | 71 | 42 | 64 |
| Richard E. Petty | 30 | 47 | 74 | 40 | 64 |
| Paul Rozin | 29 | 49 | 58 | 50 | 84 |
| Lisa Feldman Barrett | 29 | 48 | 69 | 42 | 70 |
| Constantine Sedikides | 28 | 44 | 63 | 45 | 70 |
| Alice H. Eagly | 28 | 43 | 61 | 46 | 71 |
| Susan T. Fiske | 28 | 49 | 66 | 42 | 74 |
| Jim Sidanius | 27 | 30 | 42 | 65 | 72 |
| Samuel D. Gosling | 27 | 33 | 53 | 51 | 62 |
| S. Alexander Haslam | 27 | 40 | 62 | 43 | 64 |
| Carol S. Dweck | 26 | 42 | 66 | 39 | 63 |
| Mahzarin R. Banaji | 25 | 53 | 68 | 37 | 78 |
| Brian A. Nosek | 25 | 46 | 57 | 44 | 81 |
| John F. Dovidio | 25 | 41 | 66 | 38 | 62 |
| Daniel M. Wegner | 24 | 34 | 52 | 47 | 65 |
| Benjamin R. Karney | 24 | 27 | 37 | 65 | 73 |
| Linda J. Skitka | 24 | 26 | 32 | 75 | 82 |
| Jerry Suls | 24 | 43 | 63 | 38 | 68 |
| Steven J. Heine | 23 | 28 | 37 | 63 | 77 |
| Klaus Fiedler | 23 | 28 | 38 | 61 | 74 |
| Jamil Zaki | 23 | 27 | 35 | 66 | 76 |
| Charles M. Judd | 23 | 36 | 53 | 43 | 68 |
| Jonathan B. Freeman | 23 | 24 | 30 | 75 | 81 |
| Shinobu Kitayama | 23 | 32 | 45 | 50 | 71 |
| Norbert Schwarz | 22 | 35 | 56 | 40 | 63 |
| Antony S. R. Manstead | 22 | 37 | 59 | 37 | 62 |
| Patricia G. Devine | 21 | 25 | 37 | 58 | 67 |
| David P. Schmitt | 21 | 23 | 30 | 71 | 77 |
| Craig A. Anderson | 21 | 32 | 59 | 36 | 55 |
| Jeff Greenberg | 21 | 39 | 73 | 29 | 54 |
| Kevin N. Ochsner | 21 | 40 | 57 | 37 | 70 |
| Jens B. Asendorpf | 21 | 28 | 41 | 51 | 69 |
| David M. Amodio | 21 | 23 | 33 | 63 | 70 |
| Bertram Gawronski | 21 | 33 | 43 | 48 | 76 |
| Fritz Strack | 20 | 31 | 55 | 37 | 56 |
| Virgil Zeigler-Hill | 20 | 22 | 27 | 74 | 81 |
| Nalini Ambady | 20 | 32 | 57 | 35 | 56 |
| John A. Bargh | 20 | 35 | 63 | 31 | 55 |
| Arthur Aron | 20 | 36 | 65 | 30 | 56 |
| Mark Snyder | 19 | 38 | 60 | 32 | 63 |
| Adam D. Galinsky | 19 | 33 | 68 | 28 | 49 |
| Tom Pyszczynski | 19 | 33 | 61 | 31 | 54 |
| Barbara L. Fredrickson | 19 | 32 | 52 | 36 | 61 |
| Hazel Rose Markus | 19 | 44 | 64 | 29 | 68 |
| Mark Schaller | 18 | 26 | 43 | 43 | 61 |
| Philip E. Tetlock | 18 | 33 | 45 | 41 | 73 |
| Anthony G. Greenwald | 18 | 51 | 61 | 30 | 83 |
| Ed Diener | 18 | 69 | 101 | 18 | 68 |
| Cameron Anderson | 18 | 20 | 27 | 67 | 74 |
| Michael Inzlicht | 18 | 28 | 44 | 41 | 63 |
| Barbara A. Mellers | 18 | 25 | 32 | 56 | 78 |
| Margaret S. Clark | 18 | 23 | 30 | 59 | 77 |
| Ethan Kross | 18 | 23 | 34 | 52 | 67 |
| Nyla R. Branscombe | 18 | 32 | 49 | 36 | 65 |
| Jason P. Mitchell | 18 | 30 | 41 | 43 | 73 |
| Ursula Hess | 18 | 28 | 40 | 44 | 71 |
| R. Chris Fraley | 18 | 28 | 39 | 45 | 72 |
| Emily A. Impett | 18 | 19 | 25 | 70 | 76 |
| B. Keith Payne | 17 | 23 | 30 | 58 | 76 |
| Eddie Harmon-Jones | 17 | 43 | 62 | 28 | 70 |
| Wendy Wood | 17 | 27 | 43 | 40 | 62 |
| John T. Jost | 17 | 30 | 49 | 35 | 61 |
| C. Nathan DeWall | 17 | 28 | 45 | 38 | 63 |
| Thomas Gilovich | 17 | 35 | 50 | 34 | 69 |
| Elaine Fox | 17 | 21 | 27 | 62 | 78 |
| Brent W. Roberts | 17 | 45 | 59 | 28 | 77 |
| Harry T. Reis | 16 | 32 | 43 | 38 | 74 |
| Robert B. Cialdini | 16 | 29 | 51 | 32 | 56 |
| Phillip R. Shaver | 16 | 46 | 65 | 25 | 71 |
| Daphna Oyserman | 16 | 25 | 46 | 35 | 54 |
| Russell H. Fazio | 16 | 31 | 50 | 32 | 61 |
| Jordan B. Peterson | 16 | 31 | 39 | 41 | 79 |
| Bernadette Park | 16 | 24 | 38 | 42 | 64 |
| Paul A. M. Van Lange | 16 | 24 | 38 | 42 | 63 |
| Jeffry A. Simpson | 16 | 31 | 57 | 28 | 55 |
| Russell Spears | 15 | 29 | 52 | 29 | 55 |
| A. Janet Tomiyama | 15 | 17 | 23 | 65 | 76 |
| Jan De Houwer | 15 | 40 | 55 | 27 | 72 |
| Samuel L. Gaertner | 15 | 26 | 42 | 35 | 61 |
| Michael Harris Bond | 15 | 35 | 42 | 35 | 84 |
| Agneta H. Fischer | 15 | 21 | 31 | 47 | 69 |
| Delroy L. Paulhus | 15 | 39 | 47 | 31 | 82 |
| Marcel Zeelenberg | 14 | 29 | 37 | 39 | 79 |
| Eli J. Finkel | 14 | 26 | 45 | 32 | 57 |
| Jennifer Crocker | 14 | 32 | 48 | 30 | 67 |
| Steven W. Gangestad | 14 | 20 | 48 | 30 | 41 |
| Michael D. Robinson | 14 | 27 | 41 | 35 | 66 |
| Nicholas Epley | 14 | 19 | 26 | 55 | 72 |
| David M. Buss | 14 | 52 | 65 | 22 | 80 |
| Naomi I. Eisenberger | 14 | 40 | 51 | 28 | 79 |
| Andrew J. Elliot | 14 | 48 | 71 | 20 | 67 |
| Steven J. Sherman | 14 | 37 | 59 | 24 | 62 |
| Christian S. Crandall | 14 | 21 | 36 | 39 | 59 |
| Kathleen D. Vohs | 14 | 23 | 45 | 31 | 51 |
| Jamie Arndt | 14 | 23 | 45 | 31 | 50 |
| John M. Zelenski | 14 | 15 | 20 | 69 | 76 |
| Jessica L. Tracy | 14 | 23 | 32 | 43 | 71 |
| Gordon B. Moskowitz | 14 | 27 | 47 | 29 | 57 |
| Klaus R. Scherer | 14 | 41 | 52 | 26 | 78 |
| Ayelet Fishbach | 13 | 21 | 36 | 37 | 59 |
| Jennifer A. Richeson | 13 | 21 | 40 | 33 | 52 |
| Charles S. Carver | 13 | 52 | 81 | 16 | 64 |
| Leaf van Boven | 13 | 18 | 27 | 47 | 67 |
| Shelley E. Taylor | 12 | 44 | 84 | 14 | 52 |
| Lee Jussim | 12 | 17 | 24 | 52 | 71 |
| Edward R. Hirt | 12 | 17 | 26 | 48 | 65 |
| Shigehiro Oishi | 12 | 32 | 52 | 24 | 61 |
| Richard E. Nisbett | 12 | 30 | 43 | 29 | 69 |
| Kurt Gray | 12 | 15 | 18 | 69 | 81 |
| Stacey Sinclair | 12 | 17 | 30 | 41 | 57 |
| Niall Bolger | 12 | 20 | 34 | 36 | 58 |
| Paula M. Niedenthal | 12 | 22 | 36 | 34 | 61 |
| Eliot R. Smith | 12 | 31 | 42 | 29 | 73 |
| Tobias Greitemeyer | 12 | 21 | 31 | 39 | 67 |
| Rainer Reisenzein | 12 | 14 | 21 | 57 | 69 |
| Rainer Banse | 12 | 19 | 26 | 46 | 72 |
| Galen V. Bodenhausen | 12 | 28 | 46 | 26 | 61 |
| Ozlem Ayduk | 12 | 21 | 35 | 34 | 59 |
| E. Tory. Higgins | 12 | 38 | 70 | 17 | 54 |
| D. S. Moskowitz | 12 | 21 | 33 | 36 | 63 |
| Dale T. Miller | 12 | 25 | 39 | 30 | 64 |
| Jeanne L. Tsai | 12 | 17 | 25 | 46 | 67 |
| Roger Giner-Sorolla | 11 | 18 | 22 | 51 | 80 |
| Edward P. Lemay | 11 | 15 | 19 | 59 | 81 |
| Ulrich Schimmack | 11 | 22 | 35 | 32 | 63 |
| E. Ashby Plant | 11 | 18 | 36 | 31 | 51 |
| Ximena B. Arriaga | 11 | 13 | 19 | 58 | 69 |
| Janice R. Kelly | 11 | 15 | 22 | 50 | 70 |
| Frank D. Fincham | 11 | 35 | 60 | 18 | 59 |
| David Dunning | 11 | 30 | 43 | 25 | 70 |
| Boris Egloff | 11 | 21 | 37 | 29 | 58 |
| Karl Christoph Klauer | 11 | 25 | 39 | 27 | 65 |
| Caryl E. Rusbult | 10 | 19 | 36 | 29 | 54 |
| Tessa V. West | 10 | 12 | 20 | 51 | 59 |
| Jennifer S. Lerner | 10 | 13 | 22 | 46 | 61 |
| Wendi L. Gardner | 10 | 15 | 24 | 42 | 63 |
| Mark P. Zanna | 10 | 30 | 62 | 16 | 48 |
| Michael Ross | 10 | 28 | 45 | 22 | 62 |
| Jonathan Haidt | 10 | 31 | 43 | 23 | 73 |
| Sonja Lyubomirsky | 10 | 22 | 38 | 26 | 59 |
| Sander L. Koole | 10 | 18 | 35 | 28 | 52 |
| Duane T. Wegener | 10 | 16 | 27 | 36 | 60 |
| Marilynn B. Brewer | 10 | 27 | 44 | 22 | 62 |
| Christopher K. Hsee | 10 | 20 | 31 | 31 | 63 |
| Sheena S. Iyengar | 10 | 15 | 19 | 50 | 80 |
| Laurie A. Rudman | 10 | 26 | 38 | 25 | 68 |
| Joanne V. Wood | 9 | 16 | 26 | 36 | 60 |
| Thomas Mussweiler | 9 | 17 | 39 | 24 | 43 |
| Shelly L. Gable | 9 | 17 | 33 | 28 | 50 |
| Felicia Pratto | 9 | 30 | 40 | 23 | 75 |
| Wiebke Bleidorn | 9 | 20 | 27 | 34 | 74 |
| Jeff T. Larsen | 9 | 17 | 25 | 36 | 67 |
| Nicholas O. Rule | 9 | 23 | 30 | 30 | 75 |
| Dirk Wentura | 9 | 20 | 31 | 29 | 64 |
| Klaus Rothermund | 9 | 30 | 39 | 23 | 76 |
| Joris Lammers | 9 | 11 | 16 | 56 | 69 |
| Stephanie A. Fryberg | 9 | 13 | 19 | 47 | 66 |
| Robert S. Wyer | 9 | 30 | 47 | 19 | 63 |
| Mina Cikara | 9 | 14 | 18 | 49 | 80 |
| Tiffany A. Ito | 9 | 14 | 22 | 40 | 64 |
| Joel Cooper | 9 | 14 | 35 | 25 | 39 |
| Joshua Correll | 9 | 14 | 23 | 38 | 62 |
| Peter M. Gollwitzer | 9 | 27 | 46 | 19 | 58 |
| Brad J. Bushman | 9 | 32 | 51 | 17 | 62 |
| Kennon M. Sheldon | 9 | 32 | 48 | 18 | 66 |
| Malte Friese | 9 | 15 | 26 | 33 | 57 |
| Dieter Frey | 9 | 23 | 39 | 22 | 58 |
| Lorne Campbell | 9 | 14 | 23 | 37 | 61 |
| Monica Biernat | 8 | 17 | 29 | 29 | 57 |
| Aaron C. Kay | 8 | 14 | 28 | 30 | 51 |
| Yaacov Schul | 8 | 15 | 23 | 36 | 64 |
| Joseph P. Forgas | 8 | 23 | 39 | 21 | 59 |
| Guido H. E. Gendolla | 8 | 14 | 30 | 27 | 47 |
| Claude M. Steele | 8 | 13 | 31 | 26 | 42 |
| Igor Grossmann | 8 | 15 | 23 | 35 | 66 |
| Paul K. Piff | 8 | 10 | 16 | 50 | 63 |
| Joshua Aronson | 8 | 13 | 28 | 28 | 46 |
| William G. Graziano | 8 | 20 | 30 | 26 | 66 |
| Azim F. Sharif | 8 | 15 | 22 | 35 | 68 |
| Juliane Degner | 8 | 9 | 12 | 64 | 71 |
| Margo J. Monteith | 8 | 18 | 24 | 32 | 77 |
| Timothy D. Wilson | 8 | 28 | 45 | 17 | 63 |
| Kerry Kawakami | 8 | 13 | 23 | 33 | 56 |
| Hilary B. Bergsieker | 7 | 8 | 11 | 68 | 74 |
| Gerald L. Clore | 7 | 18 | 39 | 19 | 45 |
| Phillip Atiba Goff | 7 | 11 | 18 | 41 | 62 |
| Elizabeth W. Dunn | 7 | 17 | 26 | 28 | 64 |
| Bernard A. Nijstad | 7 | 16 | 31 | 23 | 52 |
| Mark J. Landau | 7 | 13 | 28 | 25 | 45 |
| Christopher R. Agnew | 7 | 16 | 21 | 33 | 76 |
| Brandon J. Schmeichel | 7 | 14 | 30 | 23 | 45 |
| Arie W. Kruglanski | 7 | 28 | 49 | 14 | 58 |
| Eric D. Knowles | 7 | 12 | 18 | 38 | 64 |
| Yaacov Trope | 7 | 32 | 57 | 12 | 57 |
| Wendy Berry Mendes | 7 | 14 | 31 | 22 | 44 |
| Jennifer S. Beer | 7 | 14 | 25 | 27 | 54 |
| Nira Liberman | 7 | 29 | 45 | 15 | 65 |
| Penelope Lockwood | 7 | 10 | 14 | 48 | 70 |
| Jeffrey W Sherman | 7 | 21 | 29 | 23 | 71 |
| Geoff MacDonald | 7 | 12 | 18 | 37 | 67 |
| Eva Walther | 7 | 13 | 19 | 35 | 66 |
| Daniel T. Gilbert | 7 | 27 | 41 | 16 | 65 |
| Grainne M. Fitzsimons | 6 | 11 | 23 | 28 | 49 |
| Elizabeth Page-Gould | 6 | 11 | 16 | 40 | 66 |
| Mark J. Brandt | 6 | 12 | 17 | 37 | 70 |
| Ap Dijksterhuis | 6 | 20 | 37 | 17 | 54 |
| James K. McNulty | 6 | 21 | 33 | 19 | 65 |
| Dolores Albarracin | 6 | 18 | 33 | 19 | 56 |
| Maya Tamir | 6 | 19 | 29 | 21 | 64 |
| Jon K. Maner | 6 | 22 | 43 | 14 | 52 |
| Alison L. Chasteen | 6 | 17 | 25 | 24 | 69 |
| Jay J. van Bavel | 6 | 21 | 30 | 20 | 71 |
| William A. Cunningham | 6 | 19 | 30 | 20 | 64 |
| Glenn Adams | 6 | 12 | 17 | 35 | 73 |
| Wilhelm Hofmann | 6 | 22 | 33 | 18 | 66 |
| Ludwin E. Molina | 6 | 7 | 12 | 49 | 61 |
| Lee Ross | 6 | 26 | 42 | 14 | 63 |
| Andrea L. Meltzer | 6 | 9 | 13 | 45 | 72 |
| Jason E. Plaks | 6 | 10 | 15 | 39 | 67 |
| Ara Norenzayan | 6 | 21 | 34 | 17 | 61 |
| Batja Mesquita | 6 | 17 | 23 | 25 | 73 |
| Tanya L. Chartrand | 6 | 9 | 28 | 20 | 33 |
| Toni Schmader | 5 | 18 | 30 | 18 | 61 |
| Abigail A. Scholer | 5 | 9 | 14 | 38 | 62 |
| C. Miguel Brendl | 5 | 10 | 15 | 35 | 68 |
| Emily Balcetis | 5 | 10 | 15 | 35 | 68 |
| Diana I. Tamir | 5 | 9 | 15 | 35 | 62 |
| Nir Halevy | 5 | 13 | 18 | 29 | 72 |
| Alison Ledgerwood | 5 | 8 | 15 | 34 | 54 |
| Yoav Bar-Anan | 5 | 14 | 18 | 28 | 76 |
| Paul W. Eastwick | 5 | 17 | 24 | 21 | 69 |
| Geoffrey L. Cohen | 5 | 13 | 25 | 20 | 50 |
| Yuen J. Huo | 5 | 13 | 16 | 31 | 80 |
| Benoit Monin | 5 | 16 | 29 | 17 | 56 |
| Gabriele Oettingen | 5 | 17 | 35 | 14 | 49 |
| Roland Imhoff | 5 | 15 | 21 | 23 | 73 |
| Mark W. Baldwin | 5 | 8 | 20 | 24 | 41 |
| Ronald S. Friedman | 5 | 8 | 19 | 25 | 44 |
| Shelly Chaiken | 5 | 22 | 43 | 11 | 52 |
| Kristin Laurin | 5 | 9 | 18 | 26 | 51 |
| David A. Pizarro | 5 | 16 | 23 | 20 | 69 |
| Michel Tuan Pham | 5 | 18 | 27 | 17 | 68 |
| Amy J. C. Cuddy | 5 | 17 | 24 | 19 | 72 |
| Gun R. Semin | 5 | 19 | 30 | 15 | 64 |
| Laura A. King | 4 | 19 | 28 | 16 | 68 |
| Yoel Inbar | 4 | 14 | 20 | 22 | 71 |
| Nilanjana Dasgupta | 4 | 12 | 23 | 19 | 52 |
| Kerri L. Johnson | 4 | 13 | 17 | 25 | 76 |
| Roland Neumann | 4 | 10 | 15 | 28 | 67 |
| Richard P. Eibach | 4 | 10 | 22 | 19 | 47 |
| Roland Deutsch | 4 | 16 | 23 | 18 | 71 |
| Michael W. Kraus | 4 | 13 | 24 | 17 | 55 |
| Steven J. Spencer | 4 | 15 | 34 | 12 | 44 |
| Gregory M. Walton | 4 | 13 | 29 | 14 | 44 |
| Ana Guinote | 4 | 9 | 20 | 20 | 47 |
| Sandra L. Murray | 4 | 14 | 25 | 16 | 55 |
| Leif D. Nelson | 4 | 16 | 25 | 16 | 64 |
| Heejung S. Kim | 4 | 14 | 25 | 16 | 55 |
| Elizabeth Levy Paluck | 4 | 10 | 19 | 21 | 55 |
| Jennifer L. Eberhardt | 4 | 11 | 17 | 23 | 62 |
| Carey K. Morewedge | 4 | 15 | 23 | 17 | 65 |
| Lauren J. Human | 4 | 9 | 13 | 30 | 70 |
| Chen-Bo Zhong | 4 | 10 | 21 | 18 | 49 |
| Ziva Kunda | 4 | 15 | 27 | 14 | 56 |
| Geoffrey J. Leonardelli | 4 | 6 | 13 | 28 | 48 |
| Danu Anthony Stinson | 4 | 6 | 11 | 33 | 54 |
| Kentaro Fujita | 4 | 11 | 18 | 20 | 62 |
| Leandre R. Fabrigar | 4 | 14 | 21 | 17 | 67 |
| Melissa J. Ferguson | 4 | 15 | 22 | 16 | 69 |
| Nathaniel M Lambert | 3 | 14 | 23 | 15 | 59 |
| Matthew Feinberg | 3 | 8 | 12 | 28 | 69 |
| Sean M. McCrea | 3 | 8 | 15 | 22 | 54 |
| David A. Lishner | 3 | 8 | 13 | 25 | 63 |
| William von Hippel | 3 | 13 | 27 | 12 | 48 |
| Joseph Cesario | 3 | 9 | 19 | 17 | 45 |
| Martie G. Haselton | 3 | 16 | 29 | 11 | 54 |
| Daniel M. Oppenheimer | 3 | 16 | 26 | 12 | 60 |
| Oscar Ybarra | 3 | 13 | 24 | 12 | 55 |
| Simone Schnall | 3 | 5 | 16 | 17 | 31 |
| Travis Proulx | 3 | 9 | 14 | 19 | 62 |
| Spike W. S. Lee | 3 | 8 | 12 | 22 | 64 |
| Dov Cohen | 3 | 11 | 24 | 11 | 44 |
| Ian McGregor | 3 | 10 | 24 | 11 | 40 |
| Dana R. Carney | 3 | 9 | 17 | 15 | 53 |
| Mark Muraven | 3 | 10 | 23 | 11 | 44 |
| Deborah A. Prentice | 3 | 12 | 21 | 12 | 57 |
| Michael A. Olson | 2 | 11 | 18 | 13 | 63 |
| Susan M. Andersen | 2 | 10 | 21 | 11 | 48 |
| Sarah E. Hill | 2 | 9 | 17 | 13 | 52 |
| Michael A. Zarate | 2 | 4 | 14 | 13 | 31 |
| Lisa K. Libby | 2 | 5 | 10 | 18 | 54 |
| Hans Ijzerman | 2 | 8 | 18 | 9 | 46 |
| James M. Tyler | 1 | 6 | 8 | 18 | 74 |
| Fiona Lee | 1 | 6 | 10 | 13 | 58 |
References
Open Science Collaboration (OSC). (2015). Estimating the reproducibility
of psychological science. Science, 349, aac4716. http://dx.doi.org/10
.1126/science.aac4716
Radosic, N., & Diener, E. (2021). Citation Metrics in Psychological Science. Perspectives on Psychological Science. https://doi.org/10.1177/1745691620964128
Schimmack, U. (2021). The validation crisis. Meta-psychology. in press
Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology/Psychologie canadienne, 61(4), 364–376. https://doi.org/10.1037/cap0000246