The 2010s have seen a replication crisis in social psychology (Schimmack, 2020). The main reason why it is difficult to replicate results from social psychology is that researchers used questionable research practices (QRPs, John et al., 2012) to produce more significant results than their low-powered designs warranted. A catchy term for these practices is p-hacking (Simonsohn, 2014).
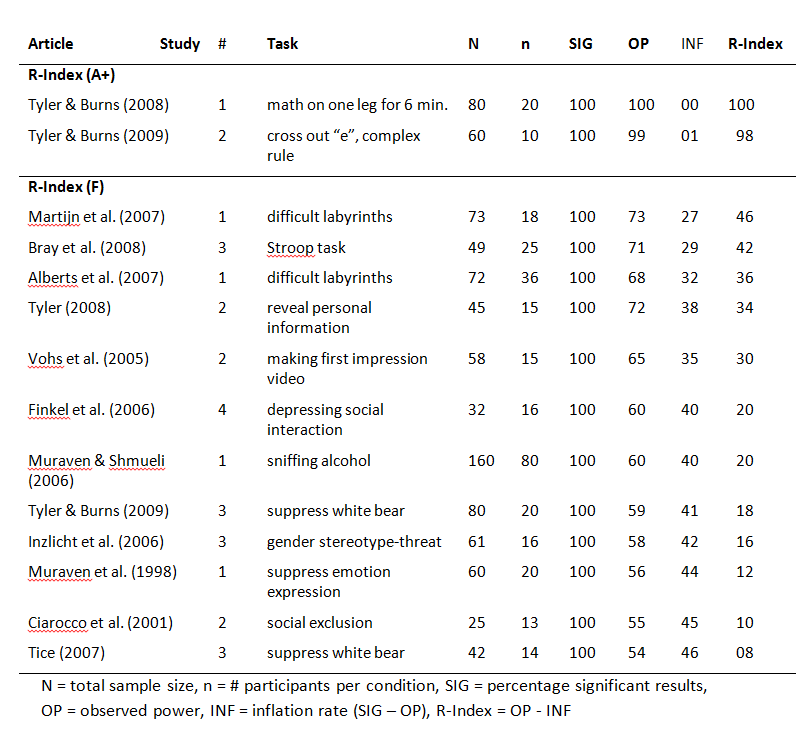
New statistical techniques made it possible to examine whether published results were obtained with QRPs. In 2012, I used the incredibility index to show that Bem (2011) used QRPs to provide evidence for extrasensory perception (Schimmack, 2012). In the same article, I also suggested that Gailliot, Baumeister, DeWall, Maner, Plant, Tice, and Schmeichel, (2007) used QRPs to present evidence that suggested will-power relies on blood glucose levels. During the review process of my manuscript, Baumeister confirmed that QRPs were used (cf. Schimmack, 2014). Baumeister defended the use of these practices with a statement that the use of these practices was the norm in social psychology and that the use of these practices was not considered unethical.
The revelation that research practices were questionable casts a shadow on the history of social psychology. However, many also saw it as an opportunity to change and improve these practices (Świątkowski and Dompnier, 2017). Over the past decades, the evaluation of QRPs has changed. Many researchers now recognize that these practices inflate error rates, make published results difficult to replicate, and undermine the credibility of psychological science (Lindsay, 2019).
However, there are no general norms regarding these practices and some researchers continue to use them (e.g., Adam D. Galinsky, cf. Schimmack, 2019). This makes it difficult for readers of the social psychological literature to identify research that can be trusted or not, and the answer to this question has to be examined on a case by case basis. In this blog post, I examine the responses of Baumeister, Vohs, DeWall, and Schmeichel to the replication crisis and concerns that their results provide false evidence about the causes of will-power (Friese, Loschelder , Gieseler , Frankenbach & Inzlicht, 2019; Inzlicht, 2016).
To examine this question scientifically, I use test-statistics that are automatically extracted from psychology journals. I divide the test-statistics into those that were obtained until 2012, when awareness about QRPs emerged, and those published after 2012. The test-statistics are examined using z-curve (Brunner & Schimmack, 2019; Bartos & Schimmack, 2020). Results provide information about the expected replication rate and discovery rate. The use of QRPs is examined by comparing the observed discovery rate (how many published results are significant) to the expected discovery rate (how many tests that were conducted produced significant results).
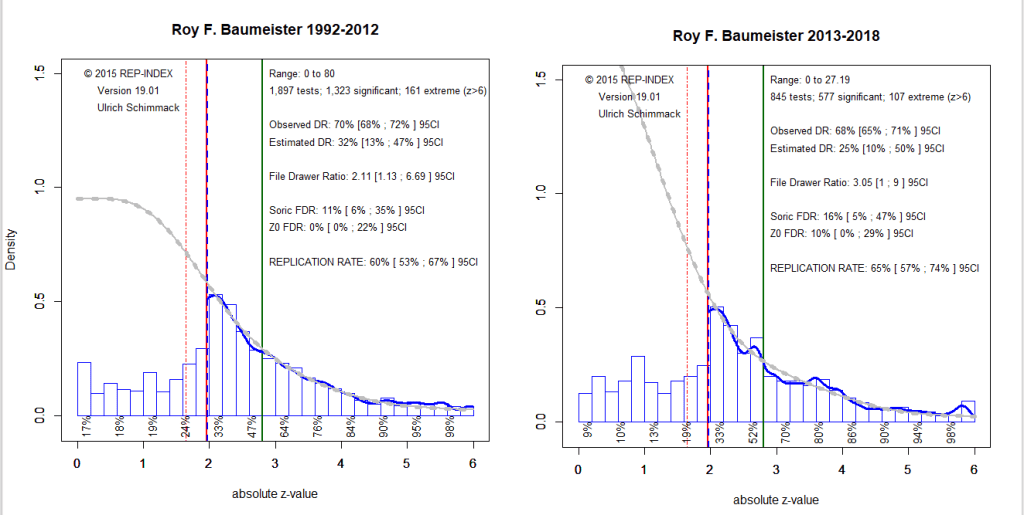
Roy F. Baumeister’s replication rate was 60% (53% to 67%) before 2012 and 65% (57% to 74%) after 2012. The overlap of the 95% confidence intervals indicates that this small increase is not statistically reliable. Before 2012, the observed discovery rate was 70% and it dropped to 68% after 2012. Thus, there is no indication that non-significant results are reported more after 2012. The expected discovery rate was 32% before 2012 and 25% after 2012. Thus, there is also no change in the expected discovery rate and the expected discovery rate is much lower than the observed discovery rate. This discrepancy shows that QRPs were used before 2012 and after 2012. The 95%CI do not overlap before and after 2012, indicating that this discrepancy is statistically significant. Figure 1 shows the influence of QRPs when the observed non-significant results (histogram of z-scores below 1.96 in blue) is compared to the model prediction (grey curve). The discrepancy suggests a large file drawer of unreported statistical tests.
An old saying is that you can’t teach an old dog new tricks. So, the more interesting question is whether the younger contributors to the glucose paper changed their research practices.
The results for C. Nathan DeWall show no notable response to the replication crisis (Figure 2). The expected replication rate increased slightly from 61% to 65%, but the difference is not significant and visual inspection of the plots suggests that it is mostly due to a decrease in reporting p-values just below .05. One reason for this might be a new goal to p-hack at least to the level of .025 to avoid detection of p-hacking by p-curve analysis. The observed discovery rate is practically unchanged from 68% to 69%. The expected discovery rate increased only slightly from 28% to 35%, but the difference is not significant. More important, the expected discovery rates are significantly lower than the observed discovery rates before and after 2012. Thus, there is evidence that DeWall used questionable research practices before and after 2012, and there is no evidence that he changed his research practices.
The results for Brandon J. Schmeichel are even more discouraging (Figure 3). Here the expected replication rate decreased from 70% to 56%, although this decrease is not statistically significant. The observed discovery rate decreased significantly from 74% to 63%, which shows that more non-significant results are reported. Visual inspection shows that this is particularly the case for test-statistics close to zero. Further inspection of the article would be needed to see how these results are interpreted. More important, The expected discovery rates are significantly lower than the observed discovery rates before 2012 and after 2012. Thus, there is evidence that QRPs were used before and after 2012 to produce significant results. Overall, there is no evidence that research practices changed in response to the replication crisis.
The results for Kathleen D. Vohs also show no response to the replication crisis (Figure 4). The expected replication rate dropped slightly from 62% to 58%; the difference is not significant. The observed discovery rate dropped slightly from 69% to 66%, and the expected discovery rate decreased from 43% to 31%, although this difference is also not significant. Most important, the observed discovery rates are significantly higher than the expected discovery rates before 2012 and after 2012. Thus, there is clear evidence that questionable research practices were used before and after 2012 to inflate the discovery rate.
Conclusion
After concerns about research practices and replicability emerged in the 2010s, social psychologists have debated this issue. Some social psychologists changed their research practices to increase statistical power and replicability. However, other social psychologists have denied that there is a crisis and attributed replication failures to a number of other causes. Not surprisingly, some social psychologists also did not change their research practices. This blog post shows that Baumeister and his students have not changed research practices. They are able to publish questionable research because there has been no collective effort to define good research practices and to ban questionable practices and to treat the hiding of non-significant results as a breach of research ethics. Thus, Baumeister and his students are simply exerting their right to use questionable research practices, whereas others voluntarily implemented good, open science, practices. Given the freedom of social psychologists to decide which practices they use, social psychology as a field continuous to have a credibility problem. Editors who accept questionable research in their journals are undermining the credibility of their journal. Authors are well advised to publish in journals that emphasis replicability and credibility with open science badges and with a high replicability ranking (Schimmack, 2019).
2.17.2020 [the blog post has been revised after I received reviews of the ms. The reference list has been expanded to include all major viewpoints and influential articles. If you find something important missing, please let me know.]
7.2.2020 [the blog post has been edited to match the print version behind the paywall]
You can email me to request a copy of the printed article (replicabilityindex@gmail.com)
Citation: Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology/Psychologie canadienne. Advance online publication. https://doi.org/10.1037/cap0000246
Abstract
Bem’s (2011) article triggered a string of replication failures in social psychology. A major replication project found that only 25% of results in social psychology could be replicated. I examine various explanations for this low replication rate and found most of them lacking in empirical support. I then provide evidence that the use of questionable research practices accounts for this result. Using z-curve and a representative sample of focal hypothesis tests, I find that the expected replication rate for social psychology is between 20% and 45%. I argue that quantifying replicability can provide an incentive to use good research practices and to invest more resources in studies that produce replicable results. The replication crisis in social psychology provides important lessons for other disciplines in psychology that have avoided to take a closer look at their research practices.
Keywords: Replication, Replicability, Replicability Crisis, Expected Replication Rate, Expected Discovery Rate, Questionable Research Practices, Power, Social Psychology
Article
The 2010s started with a bang. Journal clubs were discussing the preprint of Bem’s (2011) article “Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect.” Psychologists were confronted with a choice. Either they had to believe in anomalous effects or they had to believe that psychology was an anomalous science. Ten years later, it is pos- sible to look back at Bem’s article with the hindsight of 2020. It is now clear that Bem used questionable practices to produce false evidence for his outlandish claims (Francis, 2012; Schim- mack, 2012, 2018b, 2020). Moreover, it has become apparent that these practices were the norm and that many other findings in social psychology cannot be replicated. This realisation has led to initiatives to change research practices that produce more credible and replicable results. The speed and the extent of these changes has been revolutionary. Akin to the cognitive revolution in the 1960s and the affective revolution in the 1980s, the 2010s have witnessed a method revolution. Two new journals were created that focus on methodological problems and improvements of research practices: Meta-Psychology and Advances in Methods and Practices in Psychological Science.
In my review of the method revolution, I focus on replication failures in experimental social psychology and the different explanations for these failures. I argue that the use of questionable research practices accounts for many replication failures, and I examine how social psychologists have responded to evidence that questionable research practices (QRPs) undermine the trustworthiness of social psychological results. Other disciplines may learn from these lessons and may need to reform their research practices in the coming decade.
Replication Crisis
Arguably, the most important development in psychology has been the publication of replication failures. When Bem (2011) published his abnormal results supporting paranormal phenomena, researchers quickly failed to replicate these sensational results. However, they had a hard time publishing these results. The editor of the journal that published Bem’s findings, the Journal of Personality and Social Psychology (JPSP), did not even send the article out for review. This attempt to suppress negative evidence failed for two reasons. First, online-only journals with unlimited journal space like PLoSOne or Frontiers were willing to publish null results (Ritchie, Wiseman, & French, 2012). Second, the decision to reject the replication studies was made public and created a lot of attention because Bem’s article had attracted so much attention (Aldhous, 2011). In response to social pressure, JPSP did publish a massive replication failure of Bem’s results (Galak, LeBoeuf, Nelson, & Simmons, 2012).
Over the past decade, new article formats have evolved that make it easier to publish results that fail to confirm theoretical predictions such as registered reports (Chambers, 2013) and registered replication reports (Association for Psychological Science, 2015). Registered reports are articles that are accepted for publication before the results are known, thus avoiding the problem of publishing only confirmatory findings. Scheel, Schijen, and Lakens (2020) found that this format reduced the rate of significant results from over 90% to about 50%. This difference suggests that the normal literature has a strong bias to publish significant results (Bakker, van Dijk, & Wicherts, 2012; Sterling, 1959; Sterling, Rosenbaum, & Weinkam, 1995).
Registered replication reports are registered reports that aim to replicate an original study in a high-powered study with many laboratories. Most registered replication reports have produced replication failures (Kvarven, Strømland, & Johannesson, 2020). These failures are especially stunning because registered replication reports have a much higher chance to produce a significant result than the original studies with much smaller samples. Thus, the failure to replicate ego depletion (Hagger et al., 2016) or facial feedback (Acosta et al., 2016) effects was shocking.
Replication failures of specific studies are important for specific theories, but they do not examine the crucial question of whether these failures are anomalies or symptomatic of a wider problem in psychological science. Answering this broader question requires a representative sample of studies from the population of results published in psychology journals. Given the diversity of psychology, this is a monumental task.
A first step toward this goal was the Reproducibility Project that focused on results published in three psychology journals in the year 2008. The journals represented social/personality psychology (JPSP), cognitive psychology (Journal of Experimental Psychology: Learning, Memory, and Cognition), and all areas of psychology (Psychological Science). Although all articles published in 2008 were eligible, not all studies were replicated, in part because some studies were very expensive or difficult to replicate. In the end, 97 studies with significant results were replicated. The headline finding was that only 37% of the replication studies replicated a statistically significant result.
This finding has been widely cited as evidence that psychology has a replication problem. However, headlines tend to blur over the fact that results varied as a function of discipline. While the success rate for cognitive psychology was 50% and even higher for within-subject designs with many observations per participant, the success rate was only 25% for social psychology and even lower for the typical between-subjects design that was employed to study ego depletion, facial feedback, or other prominent topics in social psychology.
These results do not warrant the broad claim that psychology has a replication crisis or that most results published in psychology are false. A more nuanced conclusion is that social psychology has a replication crisis and that methodological factors account for these differences. Disciplines that use designs with low statistical power are more likely to have a replication crisis.
To conclude, the 2010s have seen a rise in publications of nonsignificant results that fail to replicate original results and that contradict theoretical predictions. The replicability of published results is particularly low in social psychology.
Responses to the Replication Crisis in Social Psychology
There have been numerous responses to the replication crisis in social psychology. Broadly, they can be classified as arguments that support the notion of a crisis and arguments that claim that there is no crisis. I first discuss problems with no-crisis arguments. I then examine the pro-crisis arguments and discuss their implications for the future of psychology as a science.
No Crisis: Downplaying the Finding
Some social psychologists have argued that the term crisis is inappropriate and overly dramatic. “Every generation or so, social psychologists seem to enjoy experiencing a ‘crisis.’ While sympathetic to the underlying intentions underlying these episodes— first the field’s relevance, then the field’s methodological and statistical rigor—the term crisis seems to me overly dramatic. Placed in a positive light, social psychology’s presumed ‘crises’ actually marked advances in the discipline” (Pettigrew, 2018, p. 963). Others use euphemistic and vague descriptions of the low replication rate in social psychology. For example, Fiske (2017) notes that “like other sciences, not all our effects replicate” (p. 654). Crandall and Sherman (2016) note that the number of successful replications in social psychology was “at a lower rate than expected” (p. 94).
These comments downplay the stunning finding that only 25% of social psychology results could be replicated. Rather than admitting that there is a problem, these social psychologists find fault with critics of social psychology. “I have been proud of the professional stance of social psychology throughout my long career. But unrefereed blogs and social media attacks sent to thou- sands can undermine the professionalism of the discipline” (Pettigrew, 2018, p. 967). I would argue that lecturing thousands of students each year based on evidence that is not replicable is a bigger problem than talking openly about the low replicability of social psychology on social media.
No Crisis: Experts Can Reliably Produce Effects
After some influential priming results could not be replicated, Daniel Kahneman wrote a letter to John Bargh and suggested that leading priming researchers should conduct a series of replication studies to demonstrate that their original results are replicable (Yong, 2012). In response, Bargh and other prominent social psychologists conducted numerous studies that showed the effects are robust. At least, this is what might have happened in an alternate universe. In this universe, there have been few attempts to self-replicate original findings. Bartlett (2013) asked Bargh why he did not prove his critics wrong by doing the study again. “So why not do an actual examination? Set up the same experiments again, with additional safeguards. It wouldn’t be terribly costly. No need for a grant to get undergraduates to unscramble sentences and stroll down a hallway” (Bartlett, 2013).
Bargh’s answer is not very convincing. “Bargh says he wouldn’t want to force his graduate students, already worried about their job prospects, to spend time on research that carries a stigma. Also, he is aware that some critics believe he’s been pulling tricks, that he has a ‘special touch’ when it comes to priming, a comment that sounds like a compliment but isn’t. ‘I don’t think anyone would believe me,’ he says” (Bartlett, 2013).
One self-replication ended with a replication failure (Elkins- Brown, Saunders, & Inzlicht, 2018). One notable successful self- replication was conducted by Petty and colleagues (Luttrell, Petty, & Xu, 2017), after a replication study by Ebersole et al. (2016) failed to replicate a seminal finding by Cacioppo, Petty, and Morris (1983) that need for cognition moderates the effect of argument strength on attitudes. Luttrell et al. (2017) were able to replicated the original finding by Cacioppo et al., and they repro- duced the nonsignificant result of Ebersole et al.’s replication study. In addition, they found a significant interaction with exper- imental design, indicating that procedural differences made the effect weaker in Ebersole et al.’s replication study. This study has been celebrated as an exemplary way to respond to replication failures. It also suggests that flaws in replication studies are some- times responsible for replication failures. However, it is impossible to generalise from this single instance to other replication failures. Thus, it remains unclear how many replication failures were caused by problems with the replication studies.
No Crisis: Decline Effect
The idea that replication failures occur because effects weaken over time was proposed by Johnathan Schooler and popularized in a New Yorker article (Lehrer, 2010). Schooler coined the term decline effect for the observation that effect sizes often decrease over time. Unfortunately, it does not work for more mundane behaviours like eating cheesecake. No matter how often you eat cheesecakes, they still add pounds to your weight. However, for effects in social psychology, it seems to be the case that it is easier to discover effects than to replicate them (Wegner, 1992). This is also true for Schooler and Engstler-Schooler’s (1990) verbal over- shadowing effect. A registered replication report replicated a statistically significant effect but with smaller effect sizes (Alogna et al., 2014). Schooler (2014) considered this finding a win-win because his original results had been replicated, and the reduced effect size supported the presence of a decline effect. However, the notion of a decline effect is misleading because it merely describes a phenomenon rather than providing an explanation for it. Schooler (2014) offered several possible explanations. One possible explanation was regression to the mean (see next paragraph). A second explanation was that slight changes in experimental procedures can reduce effect sizes (more detailed discussion below). More controversial, Schooler also eludes to the possibility that some paranormal processes may produce a decline effect. “Perhaps, there are some parallels between VO [verbal overshadowing] effects and parapsychology after all, but they reflect genuine unappreciated mechanisms of nature (Schooler, 2011) and not simply the product of publication bias or other artifact” (p. 582). Schooler, however, fails to acknowledge that a mundane explanation for the decline effect involves questionable research practices that inflate effect size estimates in original studies. Using statistical tools, Francis (2012) showed that Schooler’s original verbal over-shadowing studies showed signs of bias. Thus, there is no need to look for paranormal explanation of the decline effect in verbal overshadowing. The normal practices of selectively publishing only significant results are sufficient to explain it. In sum, the decline effect is descriptive rather than explanatory, and Schooler’s suggestion that it reflects some paranormal phenomena is not supported by scientific evidence.
No Crisis: Regression to the Mean Is Normal
Regression to the mean has been invoked as one possible explanation for the decline effect (Fiedler, 2015; Schooler, 2014). Fiedler’s argument is that random measurement error in psycho- logical measures is sufficient to produce replication failures. How- ever, random measurement error is neither necessary nor sufficient to produce replication failures. The outcome of a replication study is determined solely by a study’s statistical power, and if the replication study is an exact replication of an original study, both studies have the same amount of random measurement error and power (Brunner & Schimmack, 2020). Thus, if the Open Science Collaboration (OSC) project found 97 significant results in 100 published studies, the observed discovery rate of 97% suggests that the studies had 97% power to obtain a significant result. Random measurement error would have the same effect on power in the replication studies. Thus, random measurement error cannot ex- plain why the replication studies produced only 37% significant results. Therefore, Fiedler’s claim that random measurement error alone explains replication failures is based on a misunderstanding of the phenomenon of regression to the mean.
Moreover, regression to the mean requires that studies were selected for significance. Schooler (2014) ignores this aspect of regression to the mean when he suggests that regression to the mean is normal and expected. It is not. The effect sizes of eating cheesecake do not decrease over time because there is no selection process. In contrast, the effect sizes of social psychological experiments decrease when original articles selected significant results and replication studies do not select for significance. Thus, it is not normal for success rates to decrease from 97% to 25%, just like it would not be normal for a basketball players’ free-throw percent- age to drop from 97% to 25%. In conclusion, regression to the mean implies that original studies were selected for significance and would suggest that replication failures are produced by questionable research practices. Regression to the mean therefore be- comes an argument why there is a crisis once it is recognized that it requires selective reporting of significant results, which leads to illusory success rates in psychology journals.
No Crisis: Exact Replications Are Impossible
Heraclitus, an ancient Greek philosopher, observed that you can never step into the same river twice. Similarly, it is impossible to exactly re-create the conditions of a psychological experiment. This trivial observation has been used to argue that replication failures are neither surprising nor problematic but rather the norm. We should never expect to get the same result from the same paradigm because the actual experiments are never identical, just like a river is always changing (Stroebe & Strack, 2014). This argument has led to a heated debate about the distinction and value of direct versus conceptual replication studies (Crandall & Sherman, 2016; Pashler & Harris, 2012; Zwaan, Etz, Lucas, & Donnellan, 2018).
The purpose of direct replication studies is to replicate an original study as closely as possible so that replication failures can correct false results in the literature (Pashler & Harris, 2012). However, journals were reluctant to publish replication failures. Thus, a direct replication had little value. Either the results were not significant or they were not novel. In contrast, conceptual replication studies were publishable as long as they produced a significant result. Thus, publication bias provides an explanation for many seemingly robust findings (Bem, 2011) that suddenly cannot be replicated (Galak et al., 2012). After all, it is simply not plausible that conceptual replications that intentionally change features of a study are always successful, while direct replications that try to reproduce the original conditions as closely as possible fail in large numbers.
The argument that exact replications are impossible also ignores the difference between disciplines. Why is there no replication crisis in cognitive psychology if each experiment is like a new river? And why does eating cheesecake always lead to a weight gain, no matter whether it is chocolate cheesecake, raspberry white-truffle cheesecake, or caramel fudge cheesecake? The reason is that the main features of rivers remain the same. Even if the river is not identical, you still get wet every time you step into it. To explain the higher replicability of results in cognitive psychology than in social psychology, Van Bavel, Mende-Siedlecki, Brady, and Reinero (2016) proposed that social psychological studies are more difficult to replicate for a number of reasons. They called this property of studies contextual sensitivity. Coding studies for contextual sensitivity showed the predicted negative correlation between contextual sensitivity and replicability. However, Inbar (2016) found that this correlation was no longer significant when discipline was included as a predictor. Thus, the results suggested that social psychological studies are more contextually sensitive and less replicable but that contextual sensitivity did not explain the lower replicability of social psychology.
It is also not clear that contextual sensitivity implies that social psychology does not have a crisis. Replicability is not the only criterion of good science, especially if exact replications are impossible. Findings that can only be replicated when conditions are reproduced exactly lack generalizability, which makes them rather useless for applications and for construction of broader theories. Take verbal overshadowing as an example. Even a small change in experimental procedures reduced a practically significant effect size of 16% to a no longer meaningful effect size of 4% (Alogna et al., 2014), and neither of these experimental conditions were similar to real-world situations of eyewitness identification. Thus, the practical implications of this phenomenon remain unclear because it depends too much on the specific context.
In conclusion, empirical results are only meaningful if research- ers have a clear understanding of the conditions that can produce a statistically significant result most of the time (Fisher, 1926). Contextual sensitivity makes it harder to do so. Thus, it is one potential factor that may contribute to the replication crisis in social psychology because social psychologists do not know under which conditions their results can be reproduced. For example, I asked Roy F. Baumeister to specify optimal conditions to replicate ego depletion. He was unable or unwilling to do so (Baumeister, 2016).
No Crisis: The Replication Studies Are Flawed
The argument that replication studies are flawed comes in two flavors. One argument is that replication studies are often carried out by young researchers with less experience and expertise. They did their best, but they are just not very good experimenters (Gilbert, King, Pettigrew, & Wilson, 2016). Cunningham and Baumeister (2016) proclaim, “Anyone who has served on university thesis committees can attest to the variability in the competence and commitment of new researchers. Nonetheless, a graduate committee may decide to accept weak and unsuccessful replication studies to fulfill degree requirements if the student appears to have learned from the mistakes” (p. 4). There is little evidence to support this claim. In fact, a meta-analysis found no differences in effect sizes between studies carried out by Baumeister’s lab and other labs (Hagger, Wood, Stiff, & Chatzisarantis, 2010).
The other argument is that replication failures are sexier and more attention grabbing than successful replications. Thus, replication researchers sabotage their studies or data analyses to produce nonsignificant results (Bryan, Yeager, & O’Brien, 2019; Strack, 2016). The latter accusations have been made without empirical evidence to support this claim. For example, Strack (2016) used a positive correlation between sample size and effect size to claim that some labs were motivated to produce nonsignificant results, presumably by using a smaller sample size. However, a proper bias analysis showed no evidence that there were too few significant results (Schimmack, 2018a). Moreover, the overall effect size across all labs was also nonsignificant.
Inadvertent problems, however, may explain some replication failures. For example, some replication studies reduced statistical power by replicating a study with a smaller sample than the original study (OSC, 2015; Ritchie et al., 2012). In this case, a replication failure could be a false negative (Type II error). Thus, it is problematic to conduct replication studies with smaller samples. At the same time, registered replication reports with thou- sands of participants should be given more weight than original studies with fewer than 100 participants. Size matters.
However, size is not the only factor that matters, and researchers disagree about the implications of replication failures. Not surpris- ingly, authors of the original studies typically recognise some problems with the replication attempts (Baumeister & Vohs, 2016; Strack, 2016; cf. Skibba, 2016). Ideally, researchers would agree ahead of time on a research design that is acceptable to all parties involved. Kahneman called this model an adversarial collaboration (Kahneman, 2003). However, original researchers have either not participated in the planning of a study (Strack, 2016) or withdrawn their approval after the negative results were known (Baumeister & Vohs, 2016). No author of an original study that failed to replicate has openly admitted that questionable research practices contributed to replication failures.
In conclusion, replication failures can occur for a number of reasons, just like significant results in original studies can occur for a number of reasons. Inconsistent results are frustrating because they often require further research. This being said, there is no evidence that low quality of replication studies is the sole or the main cause of replication failures in social psychology.
No Crisis: Replication Failures Are Normal
In an opinion piece for the New York Times, Lisa Feldmann Barrett, current president of the Association for Psychological Science, commented on the OSC results and claimed that “the failure to replicate is not a cause for alarm; in fact, it is a normal part of how science works” (Barrett, 2015). On the surface, Barrett makes a valid point. It is true that replication failures are a normal part of science. First, if psychologists would conduct studies with 80% power, one out of five studies would fail to replicate, even if everything is going well and all predictions are true. Second, replication failures are expected when researchers test risky hypotheses (e.g., effects of candidate genes on personality) that have a high probability of being false. In this case, a significant result may be a false-positive result and replication failures demonstrate that it was a false positive. Thus, honest reporting of replication failures plays an integral part in normal science, and the success rate of replication studies provides valuable information about the empirical support for a hypothesis. However, a success rate of 25% or less for social psychology is not a sign of normal science, especially when social psychology journals publish over 90% significant results (Motyl et al., 2017; Sterling, 1959; Sterling et al., 1995). This discrepancy suggests that the problem is not the low success rate in replication studies but the high success rate in psychology journals. If social psychologists tested risky hypotheses that have a high probability of being false, journals should report a lot of nonsignificant results, especially in articles that report multiple tests of the same hypothesis, but they do not (cf. Schimmack, 2012).
Crisis: Original Studies Are Not Credible Because They Used Null-Hypothesis Significance Testing
Bem’s anomalous results were published with a commentary by Wagenmakers, Wetzels, Borsboom, and van der Maas (2011). This commentary made various points that are discussed in more detail below, but one unique and salient point of Wagenmakers et al.’s comment concerned the use of null-hypothesis significance testing (NHST). Bem presented nine results with p values below .05 as evidence for ESP. Wagenmakers et al. object to the use of a significance criterion of .05 and argue that this criterion makes it too easy to publish false-positive results (see also Benjamin et al., 2016).
Wagenmakers et al. (2011) claimed that this problem can be avoided by using Bayes factors. When they used Bayes factors with default priors, several of Bem’s studies no longer showed evidence for ESP. Based on these findings, they argued that psychologists must change the way they analyse their data. Since then, Wagenmakers has worked tirelessly to promote Bayes factors as an alternative to NHST. However, Bayes factors have their own problems. The biggest problem is that they depend on the choice of a prior.
Bem, Utts, and Johnson (2011) pointed out that Wagenmakers et al.’s (2011) default prior assumed that there is a 50% probability that ESP works in the opposite direction (below chance accuracy) and a 25% probability that effect sizes are greater than one stan- dard deviation (Cohen’s d > 1). Only 25% of the prior distribution was allocated to effect sizes in the predicted direction between 0
No Crisis: Replication Failures Are Normal
In an opinion piece for the New York Times, Lisa Feldmann Barrett, current president of the Association for Psychological Science, commented on the OSC results and claimed that “the failure to replicate is not a cause for alarm; in fact, it is a normal part of how science works” (Barrett, 2015). On the surface, Barrett makes a valid point. It is true that replication failures are a normal part of science. First, if psychologists would conduct studies with 80% power, one out of five studies would fail to replicate, even if everything is going well and all predictions are true. Second, replication failures are expected when researchers test risky hy- potheses (e.g., effects of candidate genes on personality) that have a high probability of being false. In this case, a significant result may be a false-positive result and replication failures demonstrate that it was a false positive. Thus, honest reporting of replication failures plays an integral part in normal science, and the success rate of replication studies provides valuable information about the empirical support for a hypothesis. However, a success rate of 25% or less for social psychology is not a sign of normal science, especially when social psychology journals publish over 90% significant results (Motyl et al., 2017; Sterling, 1959; Sterling et al., 1995). This discrepancy suggests that the problem is not the low success rate in replication studies but the high success rate in psychology journals. If social psychologists tested risky hypothe- ses that have a high probability of being false, journals should report a lot of nonsignificant results, especially in articles that report multiple tests of the same hypothesis, but they do not (cf. Schimmack, 2012).
Crisis: Original Studies Are Not Credible Because They Used Null-Hypothesis Significance Testing
Bem’s anomalous results were published with a commentary by Wagenmakers, Wetzels, Borsboom, and van der Maas (2011). This commentary made various points that are discussed in more detail below, but one unique and salient point of Wagenmakers et al.’s comment concerned the use of null-hypothesis significance testing (NHST). Bem presented nine results with p values below .05 as evidence for extrasensory perception (ESP). Wagenmakers et al. object to the use of a significance criterion of .05 and argue that this criterion makes it too easy to publish false-positive results (see also Benjamin et al., 2016).
Wagenmakers et al. (2011) claimed that this problem can be avoided by using Bayes factors. When they used Bayes factors with default priors, several of Bem’s studies no longer showed evidence for ESP. Based on these findings, they argued that psychologists must change the way they analyse their data. Since then, Wagenmakers has worked tirelessly to promote Bayes factors as an alternative to NHST. However, Bayes factors have their own problems. The biggest problem is that they depend on the choice of a prior.
Bem, Utts, and Johnson (2011) pointed out that Wagenmakers et al.’s (2011) default prior assumed that there is a 50% probability that ESP works in the opposite direction (below chance accuracy) and a 25% probability that effect sizes are greater than one standard deviation (Cohen’s d > 1). Only 25% of the prior distribution was allocated to effect sizes in the predicted direction between 0 and 1. This prior makes no sense for research on ESP processes that are expected to produce small effects.
When Bem et al. (2011) specified a more reasonable prior, Bayes factors actually showed more evidence for ESP than NHST. Moreover, the results of individual studies are less important than the combined evidence across studies. A meta-analysis of Bem’s studies shows that even with the default prior, Bayes factors reject the null hypothesis with an odds ratio of 1 billion to 1. Thus, if we trust Bem’s data, Bayes factors also suggest that Bem’s results are robust, and it remains unclear why Galak et al. (2012) were unable to replicate Bem’s results.
Another argument in favour of Bayes-Factors is that NHST is one-sided. Significant results are used to reject the null-hypothesis, but nonsignificant results cannot be used to affirm the null- hypothesis. This makes nonsignificant results difficult to publish, which leads to publication bias. The claim is that Bayes factors solve this problem because they can provide evidence for the null hypothesis. However, this claim is false (Tendeiro & Kiers, 2019). Bayes factors are odds ratios between two alternative hypotheses. Unlike in NHST, these two competing hypotheses are not mutually exclusive. That is, an infinite number of additional hypotheses are not tested. Thus, if the data favour the null hypothesis, they do not provide support for the null hypothesis. They merely provide evidence against one specified alternative hypothesis. There is always another possible alternative hypothesis that fits the data better than the null hypothesis. As a result, even Bayes factors that strongly favour H0 fail to provide evidence that the true effect size is exactly zero.
The solution to this problem is not new but unfamiliar to many psychologists. To demonstrate the absence of an effect, it is necessary to specify a region of effect sizes around zero and to demonstrate that the population effect size is likely to be within this region. This can be achieved using NHST (equivalence tests; Lakens, Scheel, & Isager, 2018) or Bayesian statistics (Kruschke & Liddell, 2018). The main reason why psychologists are not familiar with tests that demonstrate the absence of an effect may be that typical sample sizes in psychology are too small to produce precise estimates of effect sizes that could justify the conclusion that the population effect size is too close to zero to be meaningful.
An even more radical approach was taken by the editors of Basic and Applied Social Psychology (Trafimow & Marks, 2015), who claimed that NHST is logically invalid (Trafimow, 2003). Based on this argument, the editors banned p values from publications, which solves the problem of replication failures because there are no formal inferential tests. However, authors continue to draw causal inferences that are in line with NHST but simply omit statements about p values. It is not clear that this cosmetic change in the presentation of results is a solution to the replication crisis.
In conclusion, Wagenmakers et al. and others have blamed the use of NHST for the replication crisis, but this criticism ignores the fact that cognitive psychology also uses NHST and does not suffer a replication crisis. The problem with Bem’s results was not the use of NHST but the use of questionable research practices to produce illusory evidence (Francis, 2012; Schimmack, 2012, 2018b, 2020).
Crisis: Original Studies Report Many False Positives
An influential article by Ioannidis (2005) claimed that most published research findings are false. This eye-catching claim has been cited thousands of times. Few citing authors have bothered to point out that the claim is entirely based on hypothetical scenarios rather than empirical evidence. In psychology, fear that most published results are false positives was stoked by Simmons, Nelson, and Simonsohn’s (2011) “False-Positive Psychology” ar- ticle that showed with simulation studies that the aggressive use of questionable research practices can dramatically increase the prob- ability that a study produces a significant result without a real effect. These articles shifted concerns about false negatives in the 1990s (e.g., Cohen, 1994) to concerns about false positives.
The problem with the current focus on false-positive results is that it implies that replication failures reveal false-positive results in original studies. This is not necessarily the case. There are two possible explanations for a replication failure. Either the original study had low power to show a true effect (the nil hypothesis is false) or the original study reported a false-positive result and the nil hypothesis is true. Replication failures do not distinguish be- tween true and false nil hypothesis, but they are often falsely interpreted as if replication failures reveal that the original hypothesis was wrong. For example, Nelson, Simmons, and Simonsohn (2018) write, “Experimental psychologists spent several decades relying on methods of data collection and analysis that make it too easy to publish false-positive, nonreplicable results. During that time, it was impossible to distinguish between findings that are true and replicable and those that are false and not replicable” (p. 512). This statement ignores that results can be true but difficult to replicate and that the nil hypothesis is often unlikely to be true.
The false assumption that replication failures reveal false- positive results has created a lot of confusion in the interpretation of replication failures (Maxwell, Lau, & Howard, 2015). For example, Gilbert et al. (2016) attribute the low replication rate in the reproducibility project to low power of the replication studies. This does not make sense when the replication studies had the same or sometimes even larger sample sizes than the original studies. As a result, the replication studies had as much or more power than the original studies. So, how could low power explain that discrepancy between the 97% success rate in original studies and the 25% success rate in replication studies? It cannot.
Gilbert et al.’s (2016) criticism only makes sense if replication failures in the replication studies are falsely interpreted as evidence that the original results were false positives. Now it makes sense to argue that both the original studies and the replication studies had low power to detect true effects and that replication failures are expected when true effects are tested in studies with low power. The only question that remains is why original studies all reported significant results when they had low power, but Gilbert et al. (2016) do not address this question.
Aside from Simmons et al.’s (2011) simulation studies, a few articles tried to examine the rate of false-positive results empirically. One approach is to examine sign changes in replication studies. If 100 true null hypotheses are tested, 50 studies are expected to show a positive sign and 50 studies are expected to show a negative sign due to random sampling error. If these 100 studies are replicated, this will happen again. Just like two coin flips, we would therefore expect 50 studies with the same outcome(both positive or both negative) and 50 studies with different outcomes (one positive, one negative).
Wilson and Wixted (2018) found that 25% of social psychological results in the OSC project showed a sign reversal. This would suggest that 50% of the studies tested a true null hypothesis. Of course, sign reversals are also possible when the effect size is not strictly zero. However, the probability of a sign reversal decreases as effect sizes increase. Thus, it is possible to say that about 50% of the replicated studies had an effect size close to zero. Unfortunately, this estimate is imprecise due to the small sample size.
Gronau, Duizer, Bakker, and Wagenmakers (2017) attempted to estimate the false discovery rate using a statistical model that is fitted to the exact p values of original studies. The applied this model to three data sets and found false discovery rates (FDRs) of 34-46% for cognitive psychology, 40 – 60% for social psychology in general, and 48-88% for social priming. However, Schimmack and Brunner (2019) discovered a statistical flaw in this model that leads to the overestimation of the FDR. They also pointed out that it is impossible to provide exact estimates of the FDR because the distinction between absolutely no effect and a very small effect is arbitrary.
Bartoš and Schimmack (2020) developed a statistical model, called z-curve.2.0, that makes it possible to estimate the maximum FDR. If this maximum is low, it suggests that most replication failures are due to low power. Applying z-curve2.0 to Gronau et al.’s (2017) data sets yields FDRs of 9% (95% CI [2%, 24%]) for cognitive psychology, 26% (95% CI [4%, 100%]) for social psychology, and 61% (95% CI [19%, 100%]) for social priming. The z-curve estimate that up to 61% of social priming results could be false positives justifies Kahneman’s letter to Bargh that called out social priming research as the “poster child for doubts about the integrity of psychological research” (cf. Yong, 2012). The difference between 9% for cognitive psychology and 61% for social priming makes it clear that it is not possible to generalize from the replication crisis in social psychology to other areas of psychology. In conclusion, it is impossible to specify exactly whether an original finding was a false-positive result or not. There have been several attempts to estimate the number of false-positive results in the literature, but there is no consensus about the proper method to do so. I believe that the distinction between false and true positives is not particularly helpful if the null hypothesis is specified as a value of zero. An effect size of d = .0001 is not any more meaningful than an effect size of d = 0000. To be meaningful, published results should be replicable given the same sample sizes as used in original research. Demonstrating a significant result in the same direction in a much larger sample with a much smaller effect size should not be considered a successful replication.
Crisis: Original Studies Are Selected for Significance
The most obvious explanation for the replication crisis is the well-known bias to publish only significant results that confirm theoretical predictions. As a result, it is not necessary to read the results section of a psychological article. It will inevitably report confirmatory evidence, p < .05. This practice is commonly known as publication bias. Concerns about publication bias are nearly as old as empirical psychology (Rosenthal, 1979; Sterling, 1959). Kerr (1998) published his famous “HARKing” (hypothesising after results are known) article to explain how social psychologists were able to report mostly significant results. Social psychology journals responded by demanding that researchers publish multiple replication studies within a single article (cf. Wegner, 1992). These multiple-study articles created a sense of rigor and made false- positive results extremely unlikely. With five significant results with p < .05, the risk of a false-positive result is smaller than the criterion used by particle physicists to claim a discovery (cf. Schimmack, 2012). Thus, Bem’s (2011) article that contained nine successful studies exceeded the stringent criterion that was used to claim the discovery of the Higgs-Boson particle, the most celebrated findings in physics in the 2010s. The key difference be- tween the discovery of the Higgs-Boson particle in 2012 and Bem’s discovery of mental time travel is that physicists conducted a single powerful experiment to test their predictions, while Bem conducted many studies and selectively published results that supported his claim (Schimmack, 2018b). Bem (2012) even admitted that he ran many small studies that were not included in the article. At the same time, he was willing to combine several small studies with promising trends into a single data set. For example, Study 6 was really four studies with Ns = 50, 41, 19, and 40 (cf. Schimmack, Schultz, Carlsson, & Schmukle, 2018). These questionable, to say the least, practices were so common in social psychology that leading social psychologists were unwilling to retract Bem’s article because this practice was considered acceptable (Kitayama, 2018).
There have been three independent approaches to examine the use of questionable research practices. All three approaches show converging evidence that questionable practices inflate the rate of significant results in social psychology journals. Cairo, Green, Forsyth, Behler, and Raldiris (2020) demonstrated that published articles report more significant results than dissertations. John et al. (2012) found evidence for the use of questionable practices with a survey of research practices. The most widely used QRPs were not reporting all dependent variables (65%), collecting more data after snooping (57%), and selectively reporting studies that worked (48%). Moreover, researchers found these QRPs acceptable with defensibility ratings (0 –2) of 1.84, 1.79, and 1.66, respectively. Thus, researchers are using questionable practices because they do not consider them to be problematic. It is unclear whether attitudes toward questionable research practices have changed in response to the replication crisis.
Social psychologists have responded to John et al.’s (2012) article in two ways. One response was to question the importance of the findings. Stroebe and Strack (2014) argued that these practices may not be questionable, but they do not counter Sterling’s argument that these practices invalidate the meaning of significance testing and p values. Fiedler and Schwarz (2016) argue that John et al.’s (2012) survey produced inflated estimates of the use of QRPs. However, they fail to provide an alternative explanation for the low replication rate of social psychological research.
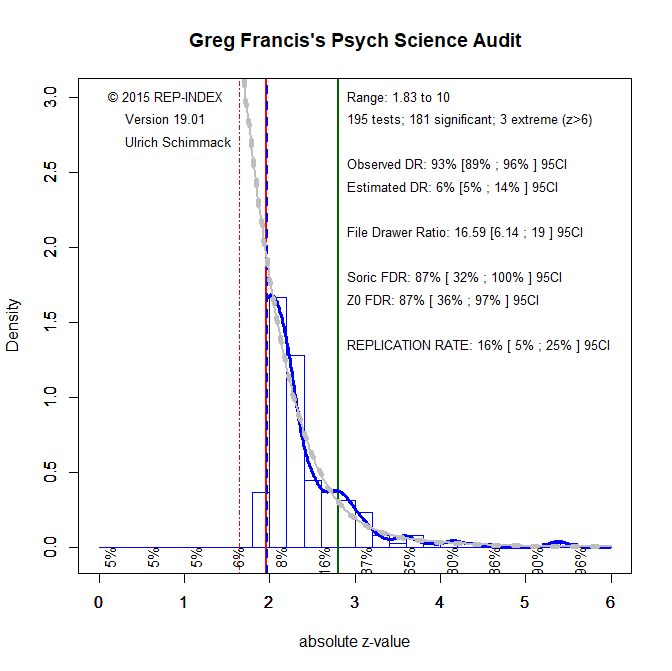
Statistical methods that can reveal publication bias provide additional evidence about the use of QRPs. Although these tests often have low power in small sets of studies (Renkewitz & Keiner, 2019), they can provide clear evidence of publication bias when bias is large (Francis, 2012; Schimmack, 2012) or when the set of studies is large (Carter, Kofler, Forster, & McCullough, 2015; Carter & McCullough, 2013, 2014). One group of bias tests compares the success rate to estimates of mean power. The advantage of these tests is that they provide clear evidence of QRPs. Francis used this approach to demonstrate that 82% of articles with four or more studies that were published between 2009 and 2012 in Psychological Science showed evidence of bias. Given the small set of studies, this finding implies that selection for significance was severe (Schimmack, 2020).
Social psychologists have mainly ignored evidence that QRPs were used to produce significant results. John et al.’s article has been cited over 500 times, but it has not been cited by social psychologists who commented on the replication crisis like Fiske, Baumeister, Gilbert, Wilson, or Nisbett. This is symptomatic of the response by some eminent social psychologists to the replication crisis. Rather than engaging in a scientific debate about the causes of the crisis, they have remained silent or dismissed critics as unscientific. “Some critics go beyond scientific argument and counterargument to imply that the entire field is inept and misguided (e.g., Gelman, 2014; Schimmack, 2014)” (Fiske, 2017, p. 653). Yet, Fiske fails to explain why social psychological results cannot be replicated.
Others have argued that Francis’s work is unnecessary because the presence of publication bias is a well-known fact. Therefore, “one is guaranteed to eventually reject a null we already know is false” (Simonsohn, 2013, p. 599). This argument ignores that bias tests can help to show that social psychology is improving. For example, bias tests show no bias in registered replication reports, indicating that this new format produces more credible results (Schimmack, 2018a).
Murayama, Pekrun, and Fiedler (2014) noted that demonstrating the presence of bias does not justify the conclusion that there is no effect. This is true but not very relevant. Bias undermines the credibility of the evidence that is supposed to demonstrate an effect. Without credible evidence, it remains uncertain whether an effect is present or not. Moreover, Murayama et al. acknowledge that bias always inflates effect size estimates, which makes it more difficult to assess the practical relevance of published results.
A more valid criticism of Francis’s bias analyses is that they do not reveal the amount of bias (Simonsohn, 2013). That is, when we see 95% significant results in a journal and there is bias, it is not clear whether mean power was 75% or 25%. To be more useful, bias tests should also provide information about the amount of bias.
In conclusion, selective reporting of significant results inflates effect sizes, and the observed discovery rate in journals gives a false impression of the power and replicability of published results. Surveys and bias tests show that the use of QRPs in social psychology were widespread. However, bias tests merely show that QRPs were used. They do not show how much QRPs influenced reported results.
z-Curve: Quantifying the Crisis
Some psychologists developed statistical models that can quantify the influence of selection for significance on replicability. Brunner and Schimmack (2020) compared four methods to estimate the expected replication rate (ERR), including the popular p-curve method (Brunner, 2018; Simonsohn, Nelson, & Simmons, 2014; Ulrich & Miller, 2018). They found that p-curve overestimated replicability when effect sizes vary across studies. In contrast, a new method called z-curve performed well across many scenarios, especially when heterogeneity was present.
Bartoš and Schimmack (2020) validated an extended version of z-curve (z-curve2.0) that provides confidence intervals and pro- vides estimates of the expected discovery rate, that is, the percent- age of observed significant results for all tests that were conducted, even if they were not reported. To do so, z-curve estimates the size of the file drawer of unpublished studies with nonsignificant results. The z-curve has already been applied to various data sets of results in social psychology (see R-Index blog for numerous examples).
The most important data set was created by Motyl et al. (2017), who used representative sampling of social psychology journals to examine the credibility of social psychology. The data set was also much larger than the 100 studies of the actual replication project (OSC, 2015). The main drawback of Motyl et al.’s audit of social psychology was that they did not have a proper statistical tool to estimate replicability. I used this data set to estimate the replica- bility of social psychology based on a representative sample of studies. To be included in the z-curve analysis, a study had to use a t test or F test with no more than four numerator degrees of freedom. I excluded studies from the journal Psychological Science to focus on social psychology. This left 678 studies for analysis. The set included 450 between-subjects studies, 139 mixed designs, and 67 within-subject designs. The preponderance of between-subjects designs is typical of social psychology and one of the reasons for the low power of studies in social psychology.
Figure 1. z-Curve of Motyl et al.’s (2017) representative sample of focal tests in social psychology.
Figure 1 was created with the R-package zcurve. The figure shows a histogram of test statistics converted into z-scores. The red line shows statistical significance at z = 1.96, which corresponds to p < .05 (two-tailed). The blue line shows the predicted values based on the best-fitting mixture model that is used to estimate the expected replication rate and the expected discovery rate. The dotted lines show 95% confidence intervals.
The results in Figure 1 show an expected replication rate of 43% (95% CI [36%, 52%]). This result is a bit better than the 25% estimate obtained in the OSC project. There are a number of possible explanations for the discrepancy between the OSC estimate and the z-curve estimate. First of all, the number of studies in the OSC project is very small and sampling error alone could explain some of the differences. Second, the set of studies in the OSC project was not representative and may have selected studies with lower replicability. Third, some actual replication studies may have modified procedures in ways that lowered the chance of obtaining a significant result. Finally, it is never possible to exactly replicate a study (Stroebe & Strack, 2014; Van Bavel et al., 2016). Thus, z-curve estimates are overly optimistic because they assume exact replications. If there is contextual sensitivity, selection for significance will produce additional regression to the mean, and a better estimate of the actual replication rate is the expected discovery rate, EDR (Bartoš & Schimmack, 2020). The estimated EDR of 21% is close to the 25% estimate based on actual replication studies. In combination, the existing evidence suggests that the replicability of social psychological research is somewhere be- tween 20% and 50%, which is clearly unsatisfactory and much lower than the observed discovery rate of 90% or more in social psychology journals.
Figure 1 also clearly shows that questionable research practices explain the gap between success rates in laboratories and success rates in journals. The z-curve estimate of nonsignificant results shows that a large proportion of nonsignificant results is expected, but hardly any of these expected studies ever get published. This is reflected in an observed discovery rate of 90% and an expected discovery rate of 21%. The confidence intervals do not overlap, indicating that this discrepancy is statistically significant. Given such extreme selection for significance, it is not surprising that published effect sizes are inflated and replication studies fail to reproduce significant results. In conclusion, out of all explanations for replication failures in psychology, the use of questionable research practices is the main factor.
The z-curve can also be used to examine the power of subgroups of studies. In the OSC project, studies with a z-score greater than 4 had an 80% chance to be replicated. To achieve an ERR of 80% with Motyl et al.’s (2017) data, z-scores have to be greater than 3.5. In contrast, studies with just significant results (p < .05 and p > .01) have an ERR of only 28%. This information can be used to reevaluate published results. Studies with p values between .05 and .01 should not be trusted unless other information suggests otherwise (e.g., a trustworthy meta-analysis). In contrast, results with z-scores greater than 4 can be used to plan new studies. Unfortunately, there are much more questionable results with p values greater than .01 (42%) than trustworthy results with z > 4 (17%), but at least there are some findings that are likely to replicate even in social psychology.
An Inconvenient Truth
Every crisis is an opportunity to learn from mistakes. Lending practices were changed after the financial crisis in the 2000s. Psychologists and other sciences can learn from the replication crisis in social psychology, but only if they are honest and upfront about the real cause of the replication crisis. Social psychologists did not use the scientific method properly. Neither Fisher nor Neyman and Pearson, who created NHST, proposed that nonsignificant results are irrelevant or that only significant results should be published. The problems of selection for significance is evident and has been well known (Rosenthal, 1979; Sterling, 1959). Cohen (1962) warned about low power, but the main concern was a large file drawer filled with Type II errors. Nobody could imagine that whole literatures with hundreds of studies are built on nothing but sampling error and selection for significance. Bem’s article and replication failures in the 2010s showed that the abuse of questionable research practices was much more excessive than any- body was willing to believe.
The key culprit were conceptual replication studies. Even social psychologists were aware that it is unethical to hide replication failures. For example, Bem advised researchers to use questionable research practices to find significant results in their data. “Go on a fishing expedition for something—anything—interesting, even if this meant to ‘err on the side of discovery’” (Bem, 2000). However, even Bem made it clear that “this is not advice to suppress negative results. If your study was genuinely designed to test hypotheses that derive from a formal theory or are of wide general interest for some other reason, then they should remain the focus of your article. The integrity of the scientific enterprise requires the reporting of disconfirming results.”
How did social psychologists justify to themselves that it is OK to omit nonsignificant results? One explanation is the distinction between direct and conceptual replications. Conceptual replications always vary at least a small detail of a study. Thus, a nonsignificant result is never a replication failure of a previous study. It is just a failure of a specific study to show a predicted effect. Graduate students were explicitly given the advice to “never do a direct replication; that way, if a conceptual replication doesn’t work, you maintain plausible deniability” (Anonymous, cited in Spellman, 2015). This is also how Morewedge, Gilbert, and Wilson (2014) explain why they omitted nonsignificant results from a publication:
Let us be clear: We did not run the same study over and over again until it yielded significant results and then report only the study that “worked.” Doing so would be clearly unethical. Instead, like most researchers who are developing new methods, we did some preliminary studies that used different stimuli and different procedures and that showed no interesting effects. Why didn’t these studies show interesting effects? We’ll never know.
It was only in 2012 that psychologists realized that changing results in their studies were heavily influenced by sampling error and not by some minor changes in the experimental procedure. Only a few psychologists have been open about this. In a commendable editorial, Lindsay (2019) talks about his realization that his research practices were suboptimal:
Early in 2012, Geoff Cumming blew my mind with a talk that led me to realize that I had been conducting underpowered experiments for decades. In some lines of research in my lab, a predicted effect would come booming through in one experiment but melt away in the next. My students and I kept trying to find conditions that yielded consistent statistical significance—tweaking items, instructions, exclusion rules— but we sometimes eventually threw in the towel because results were maddeningly inconsistent.
Rather than invoking some supernatural decline effect, Lindsay realized that his research practices were suboptimal. A first step for social psychologists is to acknowledge their past mistakes and to learn from their mistakes. Making mistakes is a fact of life. What counts is the response to a mistake. So far, the response by social psychologists has been underwhelming. It is time for some leaders to step up or to step down and make room for a new generation of social psychologists who follow open and transparent practices.
The Way Out of the Crisis
A clear analysis of the replication crisis points toward a clear path out of the crisis. Given that “lax data collection, analysis, and reporting” standards (Carpenter, 2012, p. 1558) allowed for the use of QRPs that undermine the credibility of social psychology, the most obvious solution is to ban the use of questionable research practices and to treat them like other types of unethical behaviours (Engel, 2015). However, no scientific organisation has clearly
stated which practices are acceptable and which practices are not, and prominent social psychologists oppose clear rules of scientific misconduct (Fiske, 2016).
At present, the enforcement of good practices is left to editors of journals who can ask pertinent questions during the submission process (Lindsay, 2019). Another solution has been to ask re- searchers to preregister their studies, which limits researchers’ freedom to go on a fishing expedition (Nosek, Ebersole, DeHaven, & Mellor, 2018). Some journals reward preregistering with badges (JESP), but some social psychology journals do not (PSPB, SPPS). There has been a lot of debate about the value of preregistration and concerns that it may reduce creativity. However, preregistra- tion does not imply that all research has to be confirmatory. It merely makes it possible to distinguish clearly between explor- atory and confirmatory research.
It is unlikely that preregistration alone will solve all problems, especially because there are no clear standards about preregistra- tions and how much they constrain the actual analyses. For exam- ple, Noah, Schul, and Mayo (2018) preregistered the prediction of an interaction between being observed and a facial feedback ma- nipulation. Although the predicted interaction was not significant, they interpreted the nonsignificant pattern as confirming their prediction rather than stating that there was no support for their preregistered prediction of an interaction effect. A z-curve analysis of preregistered studies in JESP still found evidence of QRPs, although less so than for articles that were not preregistered (Schimmack, 2020). To improve the value of preregistration, so- cieties should provide clear norms for research ethics that can be used to hold researchers accountable when they try to game preregistration (Yamada, 2018).
Preregistration of studies alone will only produce more nonsig- nificant results and not increase the replicability of significant results because studies are underpowered. To increase replicabil- ity, social psychologists finally have to conduct power analysis to plan studies that can produce significant results without QRPs. This also means they need to publish less because more resources are needed for a single study (Schimmack, 2012).
To ensure that published results are credible and replicable, I argue that researchers should be rewarded for conducting high- powered studies. As a priori power analyses are based on estimates of effect sizes, they cannot provide information about the actual power of studies. However, z-curve can provide information about the typical power of studies that are conducted within a lab. This information provides quantitative information about the research practices of a lab.
This can be useful information to evaluate the contribution of a research to psychological science. Imagine an eminent scholar [I had to delete the name of this imaginary scholar in the published version, I used the R-Index of Roy F. Baumeister for this example] with an H-index of 100, but assume that this H-index was achieved by publishing many studies with low power that are difficult to replicate. A z-curve analysis might produce an estimate of 25%. This information can be integrated with the H-index to produce a replicability-weighted H-index of RH = 100 * .25 = 25. Another researcher may be less prolific and only have an H-index of 50. A z-curve analysis shows that these studies have a replicability of 80%. This yields an RH-index of 40, which is higher than the RH index of the prolific researcher. By quantifying replicability, we can reward researchers who make replicable contributions to psychological science.
By taking replicability into account, the incentive to publish as many discoveries as possible without concerns about their truth- value (i.e., “to err on the side of discovery”) is no longer the best strategy to achieve fame and recognition in a field. The RH-index could also motivate researchers to retract articles that they no longer believe in, which would lower the H-index but increase the R-index. For highly problematic studies, this could produce a net gain in the RH-index.
Conclusion
Social psychology is changing in response to a replication crisis. To (re)gain trust in social psychology as a science, social psychol- ogists need to change their research practices. The problem of low power has been known since Cohen (1962), but only in recent years, power of social psychological studies has increased (Schim- mack, 2020). Aside from larger samples, social psychologists are also starting to use within-subject designs that increase power (Lin, Saunders, Friese, Evans, & Inzlicht, 2020). Finally, social psychologists need to change the way they report their results. Most important, they need to stop reporting only results that confirm their predictions. Fiske (2016) recommended that scientists keep track of their questionable practices, and Wicherts et al. (2016) provided a checklist to do so. I think it would be better to ban these practices altogether. Most important, once a discovery has been made, failures to replicate this finding provide valuable, new information and need to be published (Galak et al., 2012), and theories that fail to provide consistent support need to be abandoned or revised (Ferguson & Heene, 2012).
My personal contribution to improving science has been the development of tools that make it possible to examine whether reported results are credible or not (Bartoš & Schimmack, 2020; Schimmack, 2012; Brunner & Schimmack, 2020). I agree with Fiske (2017) that science works better when we can trust scientists, but a science with a replication rate of 25% is not trustworthy. Ironically, the same tool that reveals shady practices in the past can also demonstrate that practices in social psychology are improving (Schimmack, 2020). Hopefully, z-curve analyses of social psychology will eventually show that social psychology has become a trustworthy science.
References
Acosta, A., Adams, R. B., Jr., Albohn, D. N., Allard, E. S., Beek, T., Benning, S. D., . . . Zwaan, R. A. (2016). Registered replication report: Strack, Martin, & Stepper (1988). Perspectives on Psychological Sci- ence, 11, 917–928. http://dx.doi.org/10.1177/1745691616674458
Alogna, V. K., Attaya, M. K., Aucoin, P., Bahník, Š., Birch, S., Birt, A. R.,. . . Zwaan, R. A. (2014). Registered replication report: Schooler & Engstler-Schooler (1990). Perspectives on Psychological Science, 9, 556 –578. http://dx.doi.org/10.1177/1745691614545653
Bakker, M., van Dijk, A., & Wicherts, J. M. (2012). The Rules of the Game Called Psychological Science. Perspectives on Psychological Science, 7(6), 543–554. https://doi.org/10.1177/1745691612459060
Bartlett, T. (2013). Power of suggestion: The amazing influence of uncon- scious cues is among the most fascinating discoveries of our time—That is, if it’s true. The Chronicle of Higher Education. Retrieved from https://www.chronicle.com/article/Power-of-Suggestion/136907
Bartoš, F., & Schimmack, U. (2020). z-curve.2.0: Estimating replication and discovery rates. Unpublished manuscript.
Baumeister, R. F., & Vohs, K. D. (2016). Misguided Effort With Elusive Implications. Perspectives on Psychological Science, 11(4), 574–575. https://doi.org/10.1177/1745691616652878
Bem, D. J. (2000). Writing an empirical article. In R. J. Sternberg (Ed.), Guide to publishing in psychological journals (pp. 3–16). Cambridge, UK: Cambridge University Press. http://dx.doi.org/10.1017/CBO9780511807862.002
Bem, D. J. (2011). Feeling the future: Experimental evidence for anoma- lous retroactive influences on cognition and affect. Journal of Person- ality and Social Psychology, 100, 407– 425. http://dx.doi.org/10.1037/a0021524
Bem, D. J., Utts, J., & Johnson, W. O. (2011). Must psychologists change the way they analyze their data? Journal of Personality and Social Psychology, 101, 716 –719. http://dx.doi.org/10.1037/a0024777
Benjamin, D.J., Berger, J.O., Johannesson, M. et al. Redefine statistical significance. Nature Human Behaviour 2, 6–10 (2018). https://doi.org/10.1038/s41562-017-0189-z
Brunner, J., & Schimmack, U. (2020). Estimating population mean power under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
Bryan, C. J., Yeager, D. S., & O’Brien, J. M. (2019). Replicator degrees of freedom allow publication of misleading failures to replicate. Proceed- ings of the National Academy of Sciences USA, 116, 25535–25545. http://dx.doi.org/10.1073/pnas.1910951116
Cacioppo, J. T., Petty, R. E., & Morris, K. (1983). Effects of need for cognition on message evaluation, recall, and persuasion. Journal of Personality and Social Psychology, 45, 805– 818. http://dx.doi.org/10.1037/0022-3514.45.4.805
Cairo, A. H., Green, J. D., Forsyth, D. R., Behler, A. M. C., & Raldiris, T. L. (2020). Gray (literature) mattes: Evidence of selective hypothesis reporting in social psychological research. Personality and Social Psy- chology Bulletin. Advance online publication. http://dx.doi.org/10.1177/ 0146167220903896
Carter, E. C., Kofler, L. M., Forster, D. E., & McCullough, M. E. (2015). A series of meta-analytic tests of the depletion effect: Self-control does not seem to rely on a limited resource. Journal of Experimental Psy- chology: General, 144, 796 – 815. http://dx.doi.org/10.1037/xge0000083 Carter, E. C., & McCullough, M. E. (2013). Is ego depletion too incredible? Evidence for the overestimation of the depletion effect. Behavioraland Brain Sciences, 36, 683– 684. http://dx.doi.org/10.1017/S0140525X13000952
Carter, E. C., & McCullough, M. E. (2014). Publication bias and the limited strength model of self-control: Has the evidence for ego depletion been overestimated? Frontiers in Psychology, 5, 823.http://dx.doi.org/10.3389/fpsyg.2014.00823
Cohen, J. (1962). The statistical power of abnormal-social psychological research: A review. Journal of Abnormal and Social Psychology, 65, 145–153. http://dx.doi.org/10.1037/h0045186
Crandall, C. S., & Sherman, J. W. (2016). On the scientific superiority of conceptual replications for scientific progress. Journal of Experimental Social Psychology, 66, 93–99. http://dx.doi.org/10.1016/j.jesp.2015.10.002
Cunningham, M. R., & Baumeister, R. F. (2016). How to make nothing out of something: Analyses of the impact of study sampling and statistical interpretation in misleading meta-analytic conclusions. Frontiers in Psy- chology, 7, 1639. http://dx.doi.org/10.3389/fpsyg.2016.01639
Ebersole, C. R., Atherton, O. E., Belanger, A. L., Skulborstad, H. M., Allen, J. M., Banks, J. B., . . . Nosek, B. A. (2016). Many Labs 3: Evaluating participant pool quality across the academic semester via replication. Journal of Experimental Social Psychology, 67, 68 – 82. http://dx.doi.org/10.1016/j.jesp.2015.10.012
Elkins-Brown, N., Saunders, B., & Inzlicht, M. (2018). The misattribution of emotions and the error-related negativity: A registered report. Cortex, 109, 124 –140. http://dx.doi.org/10.1016/j.cortex.2018.08.017
Ferguson, C. J., & Heene, M. (2012). A vast graveyard of undead theories: Publication bias and psychological science’s aversion to the null. Per- spectives on Psychological Science, 7, 555–561. http://dx.doi.org/10.1177/1745691612459059
Fiedler, K., & Schwarz, N. (2016). Questionable research practices revis- ited. Social Psychological & Personality Science, 7, 45–52. http://dx.doi.org/10.1177/1948550615612150
Fisher, R. A. (1926). The arrangement of field experiments. Journal of the Ministry of Agriculture, 33, 503–513.
Fiske, S. T. (2016). How to publish rigorous experiments in the 21st century. Journal of Experimental Social Psychology, 66, 145–147. http://dx.doi.org/10.1016/j.jesp.2016.01.006
Francis, G. (2012). Too good to be true: Publication bias in two prominent studies from experimental psychology. Psychonomic Bulletin & Review, 19, 151–156. http://dx.doi.org/10.3758/s13423-012-0227-9
Galak, J., LeBoeuf, R. A., Nelson, L. D., & Simmons, J. P. (2012). Correcting the past: Failures to replicate. Journal of Personality andSocial Psychology, 103, 933–948. http://dx.doi.org/10.1037/a0029709
Gilbert, D. T., King, G., Pettigrew, S., & Wilson, T. D. (2016). Comment on “Estimating the reproducibility of psychological science.” Science, 351, 1037–1103. http://dx.doi.org/10.1126/science.aad7243
Gronau, Q. F., Duizer, M., Bakker, M., & Wagenmakers, E.-J. (2017). Bayesian mixture modeling of significant p values: A meta-analytic method to estimate the degree of contamination from Ho. Journal of Experimental Psychology: General, 146, 1223–1233. http://dx.doi.org/10.1037/xge0000324
Hagger, M. S., Chatzisarantis, N. L. D., Alberts, H., Anggono, C. O., Batailler, C., Birt, A. R., . Zwienenberg, M. (2016). A multilab preregistered replication of the ego-depletion effect. Perspectives on Psychological Science, 11, 546 –573. http://dx.doi.org/10.1177/1745691616652873
Hagger, M. S., Wood, C., Stiff, C., & Chatzisarantis, N. L. D. (2010). Ego depletion and the strength model of self-control: A meta-analysis. Psychological Bulletin, 136, 495–525. http://dx.doi.org/10.1037/a0019486
Inbar, Y. (2016). Association between contextual dependence and replicability in psychology may be spurious. Proceedings of the National Academy of Sciences, 113(34):E4933-9334, doi.org/10.1073/pnas.1608676113
John, L. K., Loewenstein, G., & Prelec, D. (2012). Measuring the Prevalence of Questionable Research Practices With Incentives for Truth Telling. Psychological Science, 23(5), 524–532. https://doi.org/10.1177/0956797611430953
Kerr, N. L. (1998). HARKing: Hypothesizing After the Results are Known. Personality and Social Psychology Review, 2(3), 196–217. https://doi.org/10.1207/s15327957pspr0203_4
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian new statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25, 178 –206. http://dx.doi.org/10.3758/s13423-016-1221-4
Kvarven, A., Strømland, E. & Johannesson, M. (2020). Comparing meta-analyses and preregistered multiple-laboratory replication projects. Nature Human Behaviour 4, 423–434 (2020). https://doi.org/10.1038/s41562-019-0787-z
Lakens, D., Scheel, A. M., & Isager, P. M. (2018). Equivalence testing for psychological research: A tutorial. Advances in Methods and Practices in Psychological Science, 1, 259 –269. http://dx.doi.org/10.1177/2515245918770963
Luttrell, A., Petty, R. E., & Xu, M. (2017). Replicating and fixing failed replications: The case of need for cognition and argument quality. Journal of Experimental Social Psychology, 69, 178 –183. http://dx.doi.org/10.1016/j.jesp.2016.09.006
Maxwell, S. E., Lau, M. Y., & Howard, G. S. (2015). Is psychology suffering from a replication crisis? What does “failure to replicate” really mean? American Psychologist, 70, 487– 498. http://dx.doi.org/10.1037/a0039400
Motyl, M., Demos, A. P., Carsel, T. S., Hanson, B. E., Melton, Z. J., Mueller, A. B., . . . Skitka, L. J. (2017). The state of social and personality science: Rotten to the core, not so bad, getting better, or getting worse? Journal of Personality and Social Psychology, 113, 34 –58. http://dx.doi.org/10.1037/pspa0000084
Murayama, K., Pekrun, R., & Fiedler, K. (2014). Research practices that can prevent an inflation of false-positive rates. Personality and Social Psychology Review, 18, 107–118. http://dx.doi.org/10.1177/1088868313496330
Noah, T., Schul, Y., & Mayo, R. (2018). When both the original study and its failed replication are correct: Feeling observed eliminates the facial- feedback effect. Journal of Personality and Social Psychology, 114, 657– 664. http://dx.doi.org/10.1037/pspa0000121
Nosek, B. A., Ebersole, C. R., DeHaven, A. C., & Mellor, D. T. (2018). The preregistration revolution. Proceedings of the National Academy of Sciences USA, 115, 2600 –2606. http://dx.doi.org/10.1073/pnas.1708274114
Pashler, H., & Harris, C. R. (2012). Is the replicability crisis overblown? Three arguments examined. Perspectives on Psychological Science, 7, 531–536. http://dx.doi.org/10.1177/1745691612463401
Pettigrew, T. F. (2018). The emergence of contextual social psychology. Personality and Social Psychology Bulletin, 44, 963–971. http://dx.doi.org/10.1177/0146167218756033
Renkewitz, F., & Keiner, M. (2019). How to detect publication bias in psychological research: A comparative evaluation of six statistical methods. Zeitschrift für Psychologie, 227(4), 261-279. http://dx.doi.org/10.1027/2151-2604/a000386
Ritchie, S. J., Wiseman, R., & French, C. C. (2012). Failing the future: Three unsuccessful attempts to replicate Bem’s ‘retroactive facilitation of recall’ effect. PLoS One, 7, e33423. http://dx.doi.org/10.1371/journal.pone.0033423
Scheel, A. M., Schijen, M., & Lakens, D. (2020). An excess of positive results: Comparing the standard psychology literature with registered reports. Retrieved from https://psyarxiv.com/p6e9c
Schimmack, U. (2012). The ironic effect of significant results on the credibility of multiple-study articles. Psychological Methods, 17, 551– 566. http://dx.doi.org/10.1037/a0029487
Schimmack, U. (2018b). Why the Journal of Personality and Social Psychology Should Retract Article DOI:10.1037/a0021524 “Feeling the future: Experimental evidence for anomalous retroactive influences on cognition and affect” by Daryl J. Bem. Retrieved January 6, 2020, from https://replicationindex.com/2018/01/05/bem-retraction
Schooler, J. W. (2014). Turning the lens of science on itself: Verbal overshadowing, replication, and metascience. Perspectives on Psycho- logical Science, 9, 579 –584. http://dx.doi.org/10.1177/1745691614547878
Schooler, J. W., & Engstler-Schooler, T. Y. (1990). Verbal overshadowing of visual memories: Some things are better left unsaid. Cognitive Psy- chology, 22, 36 –71. http://dx.doi.org/10.1016/0010-0285(90)90003-M
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22, 1359 –1366. http://dx.doi.org/10.1177/0956797611417632
Simonsohn, U. (2013). It does not follow: Evaluating the one-off publication bias critiques by Francis (2012a, 2012b, 2012c, 2012d, 2012e, in press). Perspective on Psychological Science, 7, 597–599. http://dx.doi.org/10.1177/1745691612463399
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014). P-curve and effect size: Correcting for publication bias using only significant results. Perspectives on Psychological Science, 9, 666 – 681. http://dx.doi.org/10.1177/1745691614553988
Sterling, T. D. (1959). Publication decision and the possible effects on inferences drawn from tests of significance— or vice versa. Journal of the American Statistical Association, 54, 30 –34.
Sterling, T. D., Rosenbaum, W. L., & Weinkam, J. J. (1995). Publication decisions revisited: The effect of the outcome of statistical tests on the decision to publish and vice versa. The American Statistician, 49, 108 –112.
Strack, F. (2016). Reflection on the smiling registered replication report. Perspectives on Psychological Science, 11, 929 –930. http://dx.doi.org/10.1177/1745691616674460
Stroebe, W., & Strack, F. (2014). The alleged crisis and the illusion of exact replication. Perspectives on Psychological Science, 9, 59 –71. http://dx.doi.org/10.1177/1745691613514450
Tendeiro, J. N., & Kiers, H. A. L. (2019). A review of issues about null hypothesis Bayesian testing. Psychological Methods, 24, 774 –795. http://dx.doi.org/10.1037/met0000221
Trafimow, D. (2003). Hypothesis testing and theory evaluation at the boundaries: Surprising insights from Bayes’s theorem. Psychological Review, 110, 526 –535. http://dx.doi.org/10.1037/0033-295X.110.3.526 Trafimow, D., & Marks, M. (2015). Editorial. Basic and Applied Social Psychology, 37, 1–2. http://dx.doi.org/10.1080/01973533.2015.1012991 Ulrich, R., & Miller, J. (2018). Some properties of p-curves, with an application to gradual publication bias. Psychological Methods, 23, 546 –560. http://dx.doi.org/10.1037/met0000125
Van Bavel, J. J., Mende-Siedlecki, P., Brady, W. J., & Reinero, D. A. (2016). Contextual sensitivity in scientific reproducibility. Proceedings of the National Academy of Sciences USA, 113, 6454 – 6459. http://dx.doi.org/10.1073/pnas.1521897113
Wagenmakers, E. J., Wetzels, R., Borsboom, D., & van der Maas, H. L. (2011). Why psychologists must change the way they analyze their data: The case of psi: Comment on Bem (2011). Journal of Personality and Social Psychology, 100, 426 – 432. http://dx.doi.org/10.1037/a0022790
Wagenmakers, E.-J., Beek, T., Dijkhoff, L., Gronau, Q. F., Acosta, A., Adams, R. B., … Zwaan, R. A. (2016). Registered Replication Report: Strack, Martin, & Stepper (1988). Perspectives on Psychological Science, 11(6), 917–928. https://doi.org/10.1177/1745691616674458
Wicherts, J. M., Veldkamp, C. L. S., Augusteijn, H. E. M., Bakker, M., van Aert, R. C. M., & van Assen, M. A. L. M. (2016). Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Frontiers in Psychology, 7, 1832.http://dx.doi.org/10.3389/fpsyg.2016.01832
Wilson, B. M., & Wixted, J. T. (2018). The prior odds of testing a true effect in cognitive and social psychology. Advances in Methods and Practices in Psychological Science, 1, 186 –197. http://dx.doi.org/10.1177/2515245918767122
Zwaan, R. A., Etz, A., Lucas, R. E., & Donnellan, M. B. (2018). Improving social and behavioral science by making replication mainstream: A response to commentaries. Behavioral and Brain Sciences, 41, e157. http://dx.doi.org/10.1017/S0140525X18000961
This blog post is heavily based on one of my first blog-posts in 2014 (Schimmack, 2014). The blog post reports a meta-analysis of ego-depletion studies that used the hand-grip paradigm. When I first heard about the hand-grip paradigm, I thought it was stupid because there is so much between-subject variance in physical strength. However, then I learned that it is the only paradigm that uses a pre-post design, which removes between-subject variance from the error term. This made the hand-grip paradigm the most interesting paradigm because it has the highest power to detect ego-depletion effects. I conducted a meta-analysis of the hand-grip studies and found clear evidence of publication bias. This finding is very damaging to the wider ego-depletion research because other studies used between-subject designs with small samples which have very low power to detect small effects.
This prediction was confirmed in meta-analyses by Carter,E.C., Kofler, L.M., Forster, D.E., and McCulloch,M.E. (2015) that revealed publication bias in ego-depletion studies with other paradigms.
The results also explain why attempts to show ego-depletion effects with within-subject designs failed (Francis et al., 2018). Within-subject designs increase power by removing fixed between-subject variance such as physical strength. However, given the lack of evidence with the hand-grip paradigm it is not surprising that within-subject designs also failed to show ego-depletion effects with other dependent variables in within-subject designs. Thus, these results further suggest that ego-depletion effects are too small to be used for experimental investigations of will-power.
Of course, Roy F. Baumeister doesn’t like this conclusion because his reputation is to a large extent based on the resource model of will-power. His response to the evidence that most of the evidence is based on questionable practices that produced illusory evidence has been to attack the critics (cf. Schimmack, 2019).
In 2016, he paid to publish a critique of Carter’s (2015) meta-analysis in Frontiers of Psychology (Cunningham & Baumeister, 2016). In this article, the authors question the results obtained by bias-tests that reveal publication bias and suggest that there is no evidence for ego-depletion effects.
Unfortunately, Cunningham and Baumeister’s (2016) article is cited frequently as if it contained some valid scientific arguments.
For example, Christodoulou, Lac, and Moore (2017) cite the article to dismiss the results of a PEESE analysis that suggests publication bias is present and there is no evidence that infants can add and subtract. Thus, there is a real danger that meta-analysts will use Cunningham & Baumeister’s (2016) article to dismiss evidence of publication bias and to provide false evidence for claims that rest on questionable research practices.
Fact Checking Cunningham and Baumeister’s Criticisms
Cunningham and Baumeister (2016) claim that results from bias tests are difficult to interpret, but there criticism is based on false arguments and inaccurate claims.
Confusing Samples and Populations
This scientifically sounding paragraph is a load of bull. The authors claim that inferential tests require sampling from a population and raise a question about the adequacy of a sample. However, bias tests do not work this way. They are tests of the population, namely the population of all of the studies that could be retrieved that tested a common hypothesis (e.g., all handgrip studies of ego-depletion). Maybe more studies exist than are available. Maybe the results based on the available studies differ from results if all studies were available, but that is irrelevant. The question is only whether the available studies are biased or not. So, why do we even test for significance? That is a good question. The test for significance only tells us whether bias is merely a product of random chance or whether it was introduced by questionable research practices. However, even random bias is bias. If a set of studies reports only significant results, and the observed power of the studies is only 70%, there is a discrepancy. If this discrepancy is not statistically significant, there is still a discrepancy. If it is statistically significant, we are allowed to attribute it to questionable research practices such as those that Baumeister and several others admitted using.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication) (Schimmack, 2014).
Given the widespread use of questionable research practices in experimental social psychology, it is not surprising that bias-tests reveal bias. It is actually more surprising when these tests fail to reveal bias, which is most likely a problem of low statistical power (Renkewitz & Keiner, 2019).
Misunderstanding Power
The claims about power are not based on clearly defined constructs in statistics. Statistical power is a function of the strength of a signal (the population effect size) and the amount of noise (sampling error). Researches skills are not a part of statistical power. Results should be independent of a researcher. A researcher could of course pick procedures that maximize a signal (powerful interventions) or reduce sampling error (e.g., pre-post designs), but these factors play a role in the designing of a study. Once a study is carried out, the population effect size is what it was and the sampling error is what it was. Thus, honestly reported test statistics tell us about the signal-to-noise ratio in a study that was conducted. Skillful researchers would produce stronger test-statistics (higher t-values, F-values) than unskilled researchers. The problem for Baumeister and other ego-depletion researchers is that the t-values and F-values tend to be weak and suggest questionable research practices rather than skill produced significant results. In short, meta-analysis of test-statistics reveal whether researchers used skill or questionable research practices to produce significant results.
The reference to Morey (2013) suggests that there is a valid criticism of bias tests, but that is not the case. Power-based bias tests are based on sound statistical principles that were outlined by a statistician in the journal American Statistician (Sterling, Rosenbaum, & Weinkam, 1995). Building on this work, Jerry Brunner (professor of statistics) and I published theorems that provide the basis of bias tests like TES to reveal the use of questionable research practices (Brunner & Schimmack, 2019). The real challenge for bias tests is to estimate mean power without information about the population effect sizes. In this regard, TES is extremely conservative because it relies on a meta-analysis of observed effect sizes to estimate power. These effect sizes are inflated when questionable research practices were used, which makes the test conservative. However, there is a problem with TES when effect sizes are heterogeneous. This problem is avoided by alternative bias tests like the R-Index that I used to demonstrate publication bias in the handgrip studies of ego-depletion. In sum, bias tests like the R-Index and TES are based on solid mathematical foundations and simulation studies show that they work well in detecting the use of questionable research practices.
Confusing Absence of Evidence with Evidence of Absence
PET and PEESE are extension of Eggert’s regression test of publication bias. All methods relate sample sizes (or sampling error) to effect size estimates. Questionable research practices tend to introduce a negative correlation between sample size and effect sizes or a positive correlation between sampling error and effect sizes. The reason is that significance requires a signal to noise ratio of 2:1 for t-tests or 4:1 for F-tests to produce a significant result. To achieve this ratio with more noise (smaller sample, more sampling error), the signal has to be inflated more.
The novel contribution of PET and PEESE was to use the intercept of the regression model as an effect size estimate that corrects for publication bias. This estimate needs to be interpreted in the context of the sampling error of the regression model, using a 95%CI around the point estimate.
Carter et al. (2015) found that the 95%CI often included a value of zero, which implies that the data are too weak to reject the null-hypothesis. Such non-significant results are notoriously difficult to interpret because they neither support nor refute the null-hypothesis. The main conclusion that can be drawn from this finding is that the existing data are inconclusive.
This main conclusion does not change when the number of studies is less than 20. Stanley and Doucouliagos (2014) were commenting on the trustworthiness of point estimates and confidence intervals in smaller samples. Smaller samples introduce more uncertainty and we should be cautious in the interpretation of results that suggest there is an effect because the assumptions of the model are violated. However, if the results already show that there is no evidence, small samples merely further increase uncertainty and make the existing evidence even less conclusive.
Aside from the issues regarding the interpretation of the intercept, Cunningham and Baumeister also fail to address the finding that sample sizes and effect sizes were negatively correlated. If this negative correlation is not caused by questionable research practices, it must be caused by something else. Cunningham and Baumeister fail to provide an answer to this important question.
No Evidence of Flair and Skill
Earlier Cunningham and Baumeister (2016) claimed that power depends on researchers’ skills and they argue that new investigators may be less skilled than the experts who developed paradigms like Baumeister and colleagues.
However, they then point out that Carter et al.’s (2015) examined lab as a moderator and found no difference between studies conducted by Baumeister and colleagues or other laboratories.
Thus, there is no evidence whatsoever that Baumeister and colleagues were more skillful and produced more credible evidence for ego-depletion than other laboratories. The fact that everybody got ego-depletion effects can be attributed to the widespread use of questionable research practices that made it possible to get significant results even for implausible phenomena like extrasensory perception (John et al., 2012; Schimmack, 2012). Thus, the large number of studies that support ego-depletion merely shows that everybody used questionable research practices like Baumeister did (Schimmack, 2014; Schimmack, 2016), which is also true for many other areas of research in experimental social psychology (Schimmack, 2019). Francis (2014) found that 80% of articles showed evidence that QRPs were used.
Handgrip Replicability Analysis
The meta-analysis included 18 effect sizes based on handgrip studies. Two unpublished studies (Ns = 24, 37) were not included in this analysis. Seeley & Gardner (2003)’s study was excluded because it failed to use a pre-post design, which could explain the non-significant result. The meta-analysis reported two effect sizes for this study. Thus, 4 effects were excluded and the analysis below is based on the remaining 14 studies.
All articles presented significant effects of will-power manipulations on handgrip performance. Bray et al. (2008) reported three tests; one was deemed not significant (p = .10), one marginally significant (.06), and one was significant at p = .05 (p = .01). The results from the lowest p-value were used. As a result, the success rate was 100%.
Median observed power was 63%. The inflation rate is 37% and the R-Index is 26%. An R-Index of 22% is consistent with a scenario in which the null-hypothesis is true and all reported findings are type-I errors. Thus, the R-Index supports Carter and McCullough’s (2014) conclusion that the existing evidence does not provide empirical support for the hypothesis that will-power manipulations lower performance on a measure of will-power.
The R-Index can also be used to examine whether a subset of studies provides some evidence for the will-power hypothesis, but that this evidence is masked by the noise generated by underpowered studies with small samples. Only 7 studies had samples with more than 50 participants. The R-Index for these studies remained low (20%). Only two studies had samples with 80 or more participants. The R-Index for these studies increased to 40%, which is still insufficient to estimate an unbiased effect size.
One reason for the weak results is that several studies used weak manipulations of will-power (e.g., sniffing alcohol vs. sniffing water in the control condition). The R-Index of individual studies shows two studies with strong results (R-Index > 80). One study used a physical manipulation (standing one leg). This manipulation may lower handgrip performance, but this effect may not reflect an influence on will-power. The other study used a mentally taxing (and boring) task that is not physically taxing as well, namely crossing out “e”s. This task seems promising for a replication study.
Power analysis with an effect size of d = .2 suggests that a serious empirical test of the will-power hypothesis requires a sample size of N = 300 (150 per cell) to have 80% power in a pre-post study of will-power.
Conclusion
Baumeister has lost any credibility as a scientist. He is pretending to engage in a scientific dispute about the validity of ego-depletion research, but he is ignoring the most obvious evidence that has accumulated during the past decade. Social psychologists have misused the scientific method and engaged in a silly game of producing significant p-values that support their claims. Data were never used to test predictions and studies that failed to support hypotheses were not published.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication)
As a result, the published record lacks credibility and cannot be used to provide empirical evidence for scientific claims. Ego-depletion is a glaring example of everything that went wrong in experimental social psychology. This is not surprising because Baumeister and his students used questionable research practices more than other social psychologists (Schimmack, 2018). Now he is trying to to repress this truth, which should not surprise any psychologist familiar with motivated biases and repressive coping. However, scientific journals should not publish his pathetic attempts to dismiss criticism of his work. Cunningham and Baumeister’s article provides not a single valid scientific argument. Frontiers of Psychology should retract the article.
References
Carter,E.C.,Kofler,L.M.,Forster,D.E.,and McCulloch,M.E. (2015).A series of meta-analytic tests of the depletion effect: Self-control does not seem to rely on a limited resource. J. Exp.Psychol.Gen. 144, 796–815. doi:10.1037/xge0000083
Social psychologists have responded differently to the replication crisis. Some eminent social psychologists were at the end of their careers when the crisis started in 2011. Their research output in the 2010s is too small for quantitative investigations. Thus, it makes sense to look at the younger generation of future leaders in the field.
A prominent social psychologist is Mickey Inzlicht. Not only is he on the path to becoming an eminent social psychologist (current H-Index in WebOfScience 40, over 1,000 citations in 2018), he is also a prominent commentator on the replication crisis. Most notable are Mickey’s blog posts that document his journey from believing in social psychology to becoming a skeptic, if not nihilist as more and more studies failed to replicate, including his areas of research (ego-depletion, stereotype threat; Inzlicht, 2016). Mickey is also one of the few researchers who has expressed doubts about his own findings that were obtained with methods that are now considered questionable and are difficult to replicate (Inzlicht, 2015).
He used some bias-detection tools on older and newer articles and found that the older articles showed clear evidence that questionable practices were used. His critical self-analysis was meant to stimulate more critical self-examinations, but it remains a rare example of honesty among social psychologists.
In 2016, Mickey did another self-examination that showed some positive trends in research practices. However, 2016 leaves little time for improvement and the tools were not the best tools. Here I use the most powerful method to examine questionable research practices and replicability, z-curve (Brunner & Schimmack, 2019). Following another case-study (Adam D. Galinsky), I divide the time periods into before and including 2012 and the years after 2012.
One notable difference between the two time periods is that the observed discovery rate decreased from 64% , 95%CI 59%-69%), to 49%, 95%CI = 44%-55%. This change shows that there is less selection for significance after 2012. There is also positive evidence that results before 2012 were selected for significance. The Observed Discovery Rate of 64% is higher than the expected discovery rate based on z-curve, EDR = 26%, 95%CI = 7% to 41%. However, the results after 2012 show no significant evidence that results are selected for significance because the ODR = 49% is within the 95%CI of the EDR, 7% to 64%. Visual inspection suggests a large file-drawer but that is caused by the blip of p-values just below .05 (z = 2 to z = 2.2). If these values are excluded and z-curve is fitted to z-values greater than 2.2, the model even suggests that there are more non-significant results than expected (Figure 2).
Overall, these results show that the reported results after 2013 are more trustworthy, in part because more non-significant results are reported.
Honest reporting of non-significant results is valuable, but these results are inconclusive. Thus, another important question is whether power has increased to produce more credible significant results. This is evaluated by examining the replicability of significant results. Replicability increased from 47%, 95%CI = 36% to 59%, to 68%, 95% 57% to 78%. This shows that significant results published after 2012 are more likely to replicate. However, an average replicability of 68% is still a bit short of the recommended level of 80%. Moreover, this estimate includes focal and non-focal tests and there is heterogeneity. For p-values in the range between .05 and .01, replicability is estimated to be only 30%. However, this estimate increases to 56% for the model in Figure 2. Thus, there is some uncertainty about the replicability of just significant p-values. For p-values beween .01 and .001 replicabilty is about 50%, which is acceptable but not ideal.
In conclusion, Mickey Inzlicht has been more self-critical about his past research practices than other social psychologists who have used the same questionable research practices to produce publishable significant results. Consistent with his own self-analysis, these results show that research practices changed mostly by reporting more non-significant results, but also by increasing power of studies.
I hope these positive results make Mickey revise his opinion about the value of z-curve results (Inzlicht, 2015). In 2015, Mickey argued that z-curve results are not ready for prime time. Meanwhile, z-curve has been vetted in simulation studies and is in press in Meta-Psychology. The present results show that z-curve is a valuable tool to reward the use of open science practices that lead to the publication of more credible results.
Social psychologists have responded differently to the replication crisis. Some eminent social psychologists were at the end of their careers when the crisis started in 2011. Their research output in the 2010s is too small for quantitative investigations. Thus, it makes sense to look at the younger generation of future leaders in the field.
By quantitative measures one of the leading social psychologists with an active lab in the 2010s is Adam D. Galinsky. Web of Science shows that he is on track to become a social psychologists with an H-Index of 100. He currently has 213 articles with 14,004 citations and an H-Index of 62.
Several of Adam D. Galinsky’s Psychological Science articles published between 2009-2012 were examined by Greg Francis and showed signs of questionable research practices. This is to be expected because the use of QRPs was the norm in social psychology. The more interesting question is how a productive and influential social psychologists like Adam D. Galinsky responded to the replication crisis. Given his large number of articles, it is possible to examine this quantiatively by z-curving the automatically extracted test-statistics of the articles. Although automatic extraction has the problem that it does not distinguish between focal and non-focal tests, it has the advantage that it is 100% objective and can reveal changes in research practices over time.
The good news is that results have become more replicable. The average replicability for all tests was 48% (95%CI = 42%-57%) before 2012 and 61% (95%CI = 54%-69%) since then. Zooming in on p-values between .05 and .01, replicability increased from 23% to 38%.
The observed discovery rate has not changed (71% vs. 69%). Thus, articles do not report more non-significant results, although it is not clear whether articles report more non-significant focal (and fewer non-significant non-focal tests). This observed discovery rates are significantly higher than the estimated discovery rates before 2012, 26% (9%-36%) and after 2012, 40% (18%-59%). Thus, there is evidence of selection bias; that is published results are selected for significance. The extend of selection bias can be seen visually by comparing the histogram of observed non-significant results to the predicted densities shown by the grey line. This ‘file-drawer’ has decreased but is still clearly visible after 2012.
Conclusion
Social psychology is a large field and the response to the replication crisis has been mixed. Whereas some social psychologists are leaders in open science practices and have changed their research practices considerably, others have not. At present, journals still reward significant results and researchers who continue to use questionable research practices continue to have an advantage. The good news is that it is now possible to examine and quantify the use of questionable research practices and to take this information into account. The 2020s will show whether the field will finally take information about replicability into account and reward slow and solid results more than fast and wobbly results.
Citation: Francis G., (2014). The frequency of excess success for articles in Psychological Science. Psychon Bull Rev (2014) 21:1180–1187 DOI 10.3758/s13423-014-0601-x
Introduction
The Open Science Collaboration article in Science has over 1,000 articles (OSC, 2015). It showed that attempting to replicate results published in 2008 in three journals, including Psychological Science, produced more failures than successes (37% success rate). It also showed that failures outnumbered successes 3:1 in social psychology. It did not show or explain why most social psychological studies failed to replicate.
Since 2015 numerous explanations have been offered for the discovery that most published results in social psychology cannot be replicated: decline effect (Schooler), regression to the mean (Fiedler), incompetent replicators (Gilbert), sabotaging replication studies (Strack), contextual sensitivity (vanBavel). Although these explanations are different, they share two common elements, (a) they are not supported by evidence, and (b) they are false.
A number of articles have proposed that the low replicability of results in social psychology are caused by questionable research practices (John et al., 2012). Accordingly, social psychologists often investigate small effects in between-subject experiments with small samples that have large sampling error. A low signal to noise ratio (effect size/sampling error) implies that these studies have a low probability of producing a significant result (i.e., low power and high type-II error probability). To boost power, researchers use a number of questionable research practices that inflate effect sizes. Thus, the published results provide the false impression that effect sizes are large and results are replicated, but actual replication attempts show that the effect sizes were inflated. The replicability projected suggested that effect sizes are inflated by 100% (OSC, 2015).
In an important article, Francis (2014) provided clear evidence for the widespread use of questionable research practices for articles published from 2009-2012 (pre crisis) in the journal Psychological Science. However, because this evidence does not fit the narrative that social psychology was a normal and honest science, this article is often omitted from review articles, like Nelson et al’s (2018) ‘Psychology’s Renaissance’ that claims social psychologists never omitted non-significant results from publications (cf. Schimmack, 2019). Omitting disconfirming evidence from literature reviews is just another sign of questionable research practices that priorities self-interest over truth. Given the influence that Annual Review articles hold, many readers maybe unfamiliar with Francis’s important article that shows why replication attempts of articles published in Psychological Science often fail.
Francis (2014) “The frequency of excess success for articles in Psychological Science”
Francis (2014) used a statistical test to examine whether researchers used questionable research practices (QRPs). The test relies on the observation that the success rate (percentage of significant results) should match the mean power of studies in the long run (Brunner & Schimmack, 2019; Ioannidis, J. P. A., & Trikalinos, T. A., 2007; Schimmack, 2012; Sterling et al., 1995). Statistical tests rely on the observed or post-hoc power as an estimate of true power. Thus, mean observed power is an estimate of the expected number of successes that can be compared to the actual success rate in an article.
It has been known for a long time that the actual success rate in psychology articles is surprisingly high (Sterling, 1995). The success rate for multiple-study articles is often 100%. That is, psychologists rarely report studies where they made a prediction and the study returns a non-significant results. Some social psychologists even explicitly stated that it is common practice not to report these ‘uninformative’ studies (cf. Schimmack, 2019).
A success rate of 100% implies that studies required 99.9999% power (power is never 100%) to produce this result. It is unlikely that many studies published in psychological science have the high signal-to-noise ratios to justify these success rates. Indeed, when Francis applied his bias detection method to 44 studies that had sufficient results to use it, he found that 82 % (36 out of 44) of these articles showed positive signs that questionable research practices were used with a 10% error rate. That is, his method could at most produce 5 significant results by chance alone, but he found 36 significant results, indicating the use of questionable research practices. Moreover, this does not mean that the remaining 8 articles did not use questionable research practices. With only four studies, the test has modest power to detect questionable research practices when the bias is relatively small. Thus, the main conclusion is that most if not all multiple-study articles published in Psychological Science used questionable research practices to inflate effect sizes. As these inflated effect sizes cannot be reproduced, the effect sizes in replication studies will be lower and the signal-to-noise ratio will be smaller, producing non-significant results. It was known that this could happen since 1959 (Sterling, 1959). However, the replicability project showed that it does happen (OSC, 2015) and Francis (2014) showed that excessive use of questionable research practices provides a plausible explanation for these replication failures. No review of the replication crisis is complete and honest, without mentioning this fact.
Limitations and Extension
One limitation of Francis’s approach and similar approaches like my incredibility Index (Schimmack, 2012) is that p-values are based on two pieces of information, the effect size and sampling error (signal/noise ratio). This means that these tests can provide evidence for the use of questionable research practices, when the number of studies is large, and the effect size is small. It is well-known that p-values are more informative when they are accompanied by information about effect sizes. That is, it is not only important to know that questionable research practices were used, but also how much these questionable practices inflated effect sizes. Knowledge about the amount of inflation would also make it possible to estimate the true power of studies and use it as a predictor of the success rate in actual replication studies. Jerry Brunner and I have been working on a statistical method that is able to to this, called z-curve, and we validated the method with simulation studies (Brunner & Schimmack, 2019).
I coded the 195 studies in the 44 articles analyzed by Francis and subjected the results to a z-curve analysis. The results are shocking and much worse than the results for the studies in the replicability project that produced an expected replication rate of 61%. In contrast, the expected replication rate for multiple-study articles in Psychological Science is only 16%. Moreover, given the fairly large number of studies, the 95% confidence interval around this estimate is relatively narrow and includes 5% (chance level) and a maximum of 25%.
There is also clear evidence that QRPs were used in many, if not all, articles. Visual inspection shows a steep drop at the level of significance, and the only results that are not significant with p < .05 are results that are marginally significant with p < .10. Thus, the observed discovery rate of 93% is an underestimation and the articles claimed an amazing success rate of 100%.
Correcting for bias, the expected discovery rate is only 6%, which is just shy of 5%, which would imply that all published results are false positives. The upper limit for the 95% confidence interval around this estimate is 14, which would imply that for every published significant result there are 6 studies with non-significant results if file-drawring were the only QRP that was used. Thus, we see not only that most article reported results that were obtained with QRPs, we also see that massive use of QRPs was needed because many studies had very low power to produce significant results without QRPs.
Conclusion
Social psychologists have used QRPs to produce impressive results that suggest all studies that tested a theory confirmed predictions. These results are not real. Like a magic show they give the impression that something amazing happened, when it is all smoke and mirrors. In reality, social psychologists never tested their theories because they simply failed to report results when the data did not support their predictions. This is not science. The 2010s have revealed that social psychological results in journals and text books cannot be trusted and that influential results cannot be replicated when the data are allowed to speak. Thus, for the most part, social psychology has not been an empirical science that used the scientific method to test and refine theories based on empirical evidence. The major discovery in the 2010s was to reveal this fact, and Francis’s analysis provided valuable evidence to reveal this fact. However, most social psychologists preferred to ignore this evidence. As Popper pointed out, this makes them truly ignorant, which he defined as “the unwillingness to acquire knowledge.” Unfortunately, even social psychologists who are trying to improve it wilfully ignore Francis’s evidence that makes replication failures predictable and undermines the value of actual replication studies. Given the extent of QRPs, a more rational approach would be to dismiss all evidence that was published before 2012 and to invest resources in new research with open science practices. Actual replication failures were needed to confirm predictions made by bias tests that old studies cannot be trusted. The next decade should focus on using open science practices to produce robust and replicable findings that can provide the foundation for theories.
“As was evident from my questions after the talk, I was less enthused by the idea of doing a large, replication of Darryl Bem’s studies on extra-sensory perception. Zoltán Kekecs and his team have put in a huge amount of work to ensure that this study meets the highest standards of rigour, and it is a model of collaborative planning, ensuring input into the research questions and design from those with very different prior beliefs. I just wondered what the point was. If you want to put in all that time, money and effort, wouldn’t it be better to investigate a hypothesis about something that doesn’t contradict the laws of physics?”
I think she makes a valid and important point. Bem’s (2011) article highlighted everything that was wrong with the research practices in social psychology. Other articles in JPSP are equally incredible, but this was ignored because naive readers found the claims more plausible (e.g., blood glucose is the energy for will power). We know now that none of these published results provide empirical evidence because the results were obtained with questionable research practices (Schimmack, 2014; Schimmack, 2018). It is also clear that these were not isolated incidents, but that hiding results that do not support a theory was (and still is) a common practice in social psychology (John et al., 2012; Schimmack, 2019).
A large attempt at estimating the replicability of social psychology revealed that only 25% of published significant results could be replicated (OSC). The rate for between-subject experiments was even lower. Thus, the a-priori probability (base rate) that a randomly drawn study from social psychology will produce a significant result in a replication attempt is well below 50%. In other words, a replication failure is the more likely outcome.
The low success rate of these replication studies was a shock. However, it is sometimes falsely implied that the low replicability of results in social psychology was not recognized earlier because nobody conducted replication studies. This is simply wrong. In fact, social psychology is one of the disciplines in psychology that required researchers to conduct multiple studies that showed the same effect to ensure that a result was not a false positive result. Bem had to present 9 studies with significant results to publish his crazy claims about extrasensory perception (Schimmack, 2012). Most of the studies that failed to replicate in the OSC replication project were taken from multiple-study articles that reported several successful demonstrations of an effect. Thus, the problem in social psychology was not that nobody conducted replication studies. The problem was that social psychologists only reported replication studies that were successful.
The proper analyses of the problem also suggests a different solution to the problem. If we pretend that nobody did replication studies, it may seem useful to starting doing replication studies. However, if social psychologists conducted replication studies, but did not report replication failures, the solution is simply to demand that social psychologists report all of their results honestly. This demand is so obvious that undergraduate students are surprised when I tell them that this is not the way social psychologists conduct their research.
In sum, it has become apparent that questionable research practices undermine the credibility of the empirical results in social psychology journals, and that the majority of published results cannot be replicated. Thus, social psychology lacks a solid empirical foundation.
What Next?
It is implied by information theory that little information is gained by conducting actual replication studies in social psychology because a failure to replicate the original result is likely and uninformative. In fact, social psychologists have responded to replication failures by claiming that these studies were poorly conducted and do not invalidate the original claims. Thus, replication studies are both costly and have not advanced theory development in social psychology. More replication studies are unlikely to change this.
A better solution to the replication crisis in social psychology is to characterize research in social psychology from Festinger’s classic small-sample, between-subject study in 1957 to research in 2017 as exploratory and hypotheses generating research. As Bem suggested to his colleagues, this was a period of adventure and exploration where it was ok to “err on the side of discovery” (i.e., publish false positive results, like Bem’s precognition for erotica). Lot’s of interesting discoveries were made during this period; it is just not clear which of these findings can be replicated and what they tell us about social behavior.
Thus, new studies in social psychology should not try to replicate old studies. For example, nobody should try to replicate Devine’s subliminal priming study with racial primes with computers and software from the 1980s (Devine, 1989). Instead, prominent theoretical predictions should be tested with the best research methods that are currently available. Thus, the way forward is not to do more replication studies, but rather to use open science (a.k.a. honest science) that uses experiments to subject theories to empirical tests that may also falsify a theory (e.g., subliminal racial stimuli have no influence on behavior). The main shift that is required is to get away from research that can only confirm theories and to allow for empirical data to falsify theories.
This was exactly the intent of Danny Kahneman’s letter, when he challenged social priming researchers to respond to criticism of their work by going into their labs and to demonstrate that these effects can be replicated across many labs.
Kahneman makes it clear that the onus of replication is on the original researchers who want others to believe their claims. The response to this letter speaks volumes. Not only did social psychologists fail to provide new and credible evidence that their results can be replicated, they also demonstrated defiant denial in the face of replication failures by others. The defiant denial by prominent social psychologists (e.g., Baumeister, 2019) make it clear that they will not be convinced by empirical evidence, while others who can look at the evidence objectively do not need more evidence to realize that the social psychological literature is a train-wreck (Schimmack, 2017; Kahneman, 2017). Thus, I suggest that young social psychologists search the train wreck for survivors, but do not waste their time and resources on replication studies that are likely to fail.
A simple guide through the wreckage of social psychology is to distrust any significant result with a p-value greater than .01 (Schimmack, 2019). Prediction markets also suggest that readers are able to distinguish credible and incredible results (Atlantic). Thus, I recommend to build on studies that are credible and to stay clear of sexy findings that are unlikely to replicate. As Danny Kahneman pointed out, young social psychologists who work in questionable areas face a dilemma. Either they have to replicate the questionable methods that were used to get the original results, which is increasingly considered unethical, or they end up with results that are not very informative. On the positive side, the replication crisis implies that there are many important topics in social psychology that need to be studied properly with the scientific method. Addressing these important questions may be the best way to rescue social psychology.
Roy Baumeister wrote a book chapter with the title “Self-Control, Ego Depletion, and Social Psychology’s Replication CrisisRoy” (preprint). I think this chapter will make a valuable contribution to the history of psychology and provides valuable insights into the minds of social psychologists.
I fact-checked the chapter and comment on 31 misleading or false statements.
In 2008, the world was wondering whether there is a financial crisis. In an editorial Richard S. Fuld Jr concluded that there was no crisis. This is not really what happened. Richard S. Fuld is actually known as the CEO of Lehman Brothers, a bank that declared bankruptcy in the wake of the 2008 financial crisis, when it became apparent that banks had taken on a lot of bad debt that wasn’t worth the servers it was stored on.
A few years later, there were concerns that a crisis was looming in social psychology. Although this crisis was mostly harmless because the outcome of lab experiments with undergraduate students have very little to do with real world events, it was still disconcerting that the top journal of social psychology published false evidence that extraverts have the ability to foresee the location of erotic stimuli (but not a financial crisis) (Bem, 2011).
Although Bem’s fake claims have been debunked by means of statistical investigation of his data and by means of failed replications, the article created healthy skepticism about other findings published by social psychologists. An attempt to replicate findings in social psychology could only reproduce 25% of significant results and the percentage was even lower for between-subject experiments.
Eight years later, two prominent social psychologists, Wendy Wood and Timothy D. Wilson, take stock of the status of experimental social psychology. Given the well-established finding in social psychology that humans have a strong self-serving bias and that positive illusions are good for people, they come to the conclusion that “there is no crisis” (Wood & Wilson, 2018).
Timothy Wilson fails to mention that he has a conflict of interest because he is the writer of a textbook that would be less valuable if the content in the textbook were based on studies that cannot be replicated. Wendy Wood also is the author of a popular book in which she observes that ” we spend a shocking 43 percent of our day doing things without thinking about them” I am not sure she was thinking about the research social psychologists do, which also often appears to be a frantic activism rather than planned testing of theories.
So, what evidence do Wood and Wilson marshal for their claim that there is no crisis in social psychology?
To be clear, Wood and Wilson’s article is based on their involvement in an interdisciplinary committee across scientific disciplines. “No crisis” may be a reasonable verdict for all sciences. After all, the natural sciences are making tremendous progress and the only question is whether their advances will destroy or save the planet, but there is no doubt that advances in the natural sciences have made humans de facto rulers of this planets.
But we cannot generalize from the natural science to the social science or social psychology more specifically. So, the real question for social psychologists is whether there is a crisis in social psychology. Wood and Wilson do not have much to say about this issue, but they make the trivial and misleading observation that “the goal of science is not, and ought not to be, for all results to be replicable” (p. 28).
Why is this true and trivial? After all, all scientists acknowledge that we only do studies to test hypotheses that are not already known to be true. This means, we will sometimes test a false hypothesis (e.g., Extraverts can guess above chance which underwear I am going to pick for my first day of classes.) Sometimes, our data will give us the wrong answer, which is called a false positive or a type-I error. The whole point of statistical significance testing, which social psychologists routinely do in their journals, is to keep the rate of such false discoveries at an acceptable minimum.
However, social psychologists convinced themselves that doing proper science that keeps the false positive rate at a low rate is not interesting. Their cheerleader Bem told them “Let’s err on the side of discovery.” The more discoveries, the merrier social psychologists will be. Who cares whether they are true or not as long as they make for good stories in social psychology textbooks. And so they went on a rampage and erred on the side of discovery (social priming, ego-depletion, unconscious racism, stereotype-threat, terror-management, etc. etc.) and now their textbooks are filled with findings that cannot be replicated.
So how did Wood and Wilson mislead readers? They were right that the goal of science is not to replicate ALL results, but they fail to point out that a good science is build on findings that do replicate and that a good science aims to have a high percentage of findings that replicate. 25 percent or less is a failing grade and nowhere near the goal of a good science.
So, Wood and Wilson’s quote is a distraction. They state a trivial truth to imply that there is no crisis because failures are ok, but they avoid talking about the embarrassing frequency of replication failures in social psychology.
And the political nature of their article is clear when the authors conclude with their personal beliefs” “We were more convinced than ever in the fundamental soundness of our field” without pointing to a shred of evidence that would make this more than wishful thinking.
Their self-serving statement totally disregards the evidence that has accumulated over the past eight years that social psychologists were some of the most outrageous users of questionable research practices to produce significant results that do not replicate (search this blog for numerous demonstrations, but here is one (Social Psychology Audit), including an audit of Wilson’s work.
Social psychologists would be the first to warn you about the credibility of a messenger who wants you to buy something. I would say, don’t buy what social psychologists tell you about the credibility of social psychology.
Over the past years, psychologists have become increasingly concerned about the credibility of published results. The credibility crisis started in 2011, when Bem published incredible results that seemed to suggest that humans can foresee random future events. Bem’s article revealed fundamental flaws in the way psychologists conduct research. The main problem is that psychology journals only publish statistically significant results (Sterling, 1959). If only significant results are published, all hypotheses will receive empirical support as long as they are tested. This is akin to saying that everybody has a 100% free throw average or nobody ever makes a mistake if we do not count failures.
The main problem of selection for significance is that we do not know the real strength of evidence that empirical studies provide. Maybe the selection effect is small and most studies would replicate. However, it is also possible that many studies might fail a replication test. Thus, the crisis of confidence is a crisis of uncertainty.
The Open Science Collaboration conducted actual replication studies to estimate the replicability of psychological science. They replicated 97 studies with statistically significant results and were able to reproduce 35 significant results (a 36% success rate). This is a shockingly low success rate. Based on this finding, most published results cannot be trusted, especially because there is heterogeneity across studies. Some studies would have an even lower chance of replication and several studies might even be outright false positives (there is actually no real effect).
As important as this project was to reveal major problems with the research culture in psychological science, there are also some limitations that cast doubt about the 36% estimate as a valid estimate of the replicability of psychological science. First, the sample size is small and sampling error alone might have lead to an underestimation of the replicability in the population of studies. However, sampling error could also have produced a positive bias. Another problem is that most of the studies focused on social psychology and that replicability in social psychology could be lower than in other fields. In fact, a moderator analysis suggested that the replication rate in cognitive psychology is 50%, while the replication rate in social psychology is only 25%. The replicated studies were also limited to a single year (2008) and three journals. It is possible that the replication rate has increased since 2008 or could be higher in other journals. Finally, there have been concerns about the quality of some of the replication studies. These limitations do not undermine the importance of the project, but they do imply that the 36% estimate is an estimate and that it may underestimate the replicability of psychological science.
Over the past years, I have been working on an alternative approach to estimate the replicability of psychological science. This approach starts with the simple fact that replicabiliity is tightly connected to the statistical power of a study because statistical power determines the long-run probability of producing significant results (Cohen, 1988). Thus, estimating statistical power provides valuable information about replicability. Cohen (1962) conducted a seminal study of statistical power in social psychology. He found that the average power to detect an average effect size was around 50%. This is the first estimate of replicability of psychological science, although it was only based on one journal and limited to social psychology. However, subsequent studies replicated Cohen’s findings and found similar results over time and across journals (Sedlmeier & Gigerenzer, 1989). It is noteworthy that the 36% estimate from the OSC project is not statistically different from Cohen’s estimate of 50%. Thus, there is convergent evidence that replicability in social psychology is around 50%.
In collaboration with Jerry Brunner, I have developed a new method that can estimate mean power for a set of studies that are selected for significance and that vary in effect sizes and samples sizes, which produces heterogeneity in power (Brunner & Schimmack, 2018). The input for this method are the actual test statistics of significance tests (e.g., t-tests, F-tests). These test-statistics are first converted into two-tailed p-values and then converted into absolute z-scores. The magnitude of these absolute z-scores provides information about the strength of evidence against the null-hypotheses. The histogram of these z-scores, called a z-curve, is then used to fit a finite mixture model to the data that estimates mean power, while taking selection for significance intro account. Extensive simulation studies demonstrate that z-curve performs well and provides better estimates than alternative methods. Thus, z-curve is the method of choice for estimating the replicability of psychological science on the basis of the test statistics that are reported in original articles.
For this blog post, I am reporting results based on preliminary results from a large project that extracts focal hypothesis from a broad range of journals that cover all areas of psychology for the years 2010 to 2017. The hand-coding of these articles complements a similar project that relies on automatic extraction of test statistics (Schimmack, 2018).
Table 1 shows the journals that have been coded so far. It also shows the estimates based on the automated method and for hand-coding of focal hypotheses.
Journal
Hand
Automated
Psychophysiology
84
75
Journal of Abnormal Psychology
76
68
Journal of Cross-Cultural Psychology
73
77
Journal of Research in Personality
68
75
J. Exp. Psych: Learning, Memory, &
Cognition
58
77
Journal of Experimental Social Psychology
55
62
Infancy
53
68
Behavioral Neuroscience
53
68
Psychological Science
52
66
JPSP-Interpersonal Relations & Group
Processes
33
63
JPSP-Attitudes and Social Cognition
30
65
Mean
58
69
Hand coding of focal hypothesis produces lower estimates than the automated method because the automated analysis also codes manipulation checks and other highly significant results that are not theoretically important. The correlation between the two methods shows consistency across the two methods, r = .67. Finally, the mean for the automated method, 69%, is close to the mean for over 100 journals, 72%, suggesting that the sample of journals is an unbiased sample.
The hand coding results also confirm results found with the automated method that social psychology has a lower replicability than some other disciplines. Thus, the OSC reproducibility results that are largely based on social psychology should not be used to make claims about psychological science in general.
The figure below shows the output of the latest version of z-curve. The first finding is that the replicability estimate for all 1,671 focal tests is 56% with a relatively tight confidence interval ranging from 45% to 56%. ZZZ The next finding is that the discovery rate or success rate is 92%, using p < .05 as the criterion. This confirms that psychology journals continue to published results are selected for significance (Sterling, 1959). The histogram further shows that even more results would be significant if p-values below .10 are included as evidence for “marginal significance.”
Z-Curve.19.1 also provides an estimate of the size of the file drawer. It does so by projecting the distribution of observed significant results into the range of non-significant results (grey curve). The file drawer ratio shows that for every published result, we would expect roughly two unpublished studies with non-significant results. However, z-curve cannot distinguish between different questionable research practices. Rather than not disclosing failed studies researchers may not disclose other statistical analyses within a published study to report significant results.
Z-Curve.19.1 also provides an estimate of the false positive rate (FDR). FDR is the percentage of significant results that may arise from testing a true nil-hypothesis, where the population effect size is zero. For a long time, the consensus has been that false positives are rare because the nil-hypothesis is rarely true (Cohen, 1994). Consistent with this view, Soric’s estimate of the maximum false discovery rate is only 10% with a tight CI ranging from 8% to 16%.
However, the focus on the nil-hypothesis is misguided because it treats tiny deviations from zero as true hypotheses even if the effect size has no practical or theoretical significance. These effect sizes also lead to low power and replication failures. Therefore, Z-Curve 19.1 also provides an estimate of the FDR that treats studies with very low power as false positives. This broader definition of false positives raises the FDR estimate slightly, but 15% is still a low percentage. Thus, the modest replicability of results in psychological science is mostly due to low statistical power to detect true effects rather than a high number of false positive discoveries.
The reproducibility project showed that studies with low p-values were more likely to replicate. This relationship follows from the influence of statistical power on p-values and replication rates. To achieve a replication rate of 80%, p-values had to be less than .00005 or the z-score had to exceed 4 standard deviations. However, this estimate was based on a very small sample of studies. Z-Curve.19.1 also provides estimates of replicability for different levels of evidence. These values are shown below the x-axis. Consistent with the OSC results, a replication rate over 80% is only expected once z-scores are greater than 4.
The results also provide information about the choice of the alpha criterion to draw inferences from significance tests in psychology. To do so, it is important to distinguish observed p-values and type-I probabilities. For a single unbiased tests, we can infer from an observed p-value less than .05 that the risk of a false positive result is less than 5%. However, when multiple comparisons are made or results are selected for significance, an observed p-values less than .05 does not imply that the type-I error risk is below .05. To claim a type-I error risk of 5% or less, we have to correct the observed p-values, just like a Bonferroni correction. As 50% power corresponds to statistical significance, we see that z-scores between 2 and 3 are not statistically significant; that is, the type-I error risk is greater than 5%. Thus, the standard criterion to claim significance with alpha = .05 is a p-value of .003. Given the popularity of .005, I suggest to use p = .005 as a criterion for statistical significance. However, this claim is not based on lowering the criterion for statistical significance because p < .005 still only allows to claim that the type-I error probability is less than 5%. The need for a lower criterion value stems from the inflation of the type-I error rate due to selection for significance. This is a novel argument that has been overlooked in the significance wars, which ignored the influence of publication bias on false positive risks.
Finally, z-curve.19.1 makes it possible to examine the robustness of the estimates by using different selection criteria. One problem with selection models is that p-values just below .05, say in the .01 to .05 range, can arise from various questionable research practices that have different effects on replicability estimates. To address this problem, it is possible to estimate the density with a different selection criterion, while still estimating the replicability with alpha = .05 as the criterion. Figure 2 shows the results by using only z-scores greater than 2.5, p = .012) to fit the observed z-curve for z-scores greater than 2.5.
The blue dashed line at z = 2.5 shows the selection criterion. The grey curve between 1.96 and 2.5 is projected form the distribution for z-scores greater than 2.5. Results show a close fit with the observed distribution. A s a result, the parameter estimates are also very similar. Thus, the results are robust and the selection model seems to be reasonable.
Conclusion
Psychology is in a crisis of confidence about the credibility of published results. The fundamental problems are as old as psychology itself. Psychologists have conducted low powered studies and selected only studies that worked for decades (Cohen, 1962; Sterling, 1959). However, awareness of these problems has increased in recent years. Like many crises, the confidence crisis in psychology has created confusion. Psychologists are aware that there is a problem, but they do not know how large the problem is. Some psychologists believe that there is no crisis and pretend that most published results can be trusted. Others are worried that most published results are false positives. Meta-psychologists aim to reduce the confusion among psychologists by applying the scientific method to psychological science itself.
This blog post provided the most comprehensive assessment of the replicability of psychological science so far. The evidence is largely consistent with previous meta-psychological investigations. First, replicability is estimated to be slightly above 50%. However, replicability varies across discipline and the replicability of social psychology is below 50%. The fear that most published results are false positives is not supported by the data. Replicability increases with the strength of evidence against the null-hypothesis. If the p-value is below .00001, studies are likely to replicate. However, significant results with p-values above .005 should not be considered statistically significant with an alpha level of 5%, because selection for significance inflates the type-I error. Only studies with p < .005 can claim statistical significance with alpha = .05.
The correction for publication bias implies that researchers have to increase sample sizes to meet the more stringent p < .005 criterion. However, a better strategy is to preregister studies to ensure that reported results can be trusted. In this case, p-values below .05 are sufficient to demonstrate statistical significance with alpha = .05. Given the low prevalence of false positives in psychology, I do see no need to lower the alpha criterion.
Future Directions
This blog post is just an interim report. The final project requires hand-coding of a broader range of journals. Readers who think that estimating the replicability of psychological science is beneficial and who want information about a particular journal are invited to collaborate on this project and can obtain authorship if their contribution is substantial enough to warrant authorship. Please consider taking part in this project. Although it is a substantial time commitment, it doesn’t require participants or materials that are needed for actual replication studies. Please consider taking part in this project. Contact me, if you are interested and want to know how you can get involved.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.