
One of the worst articles about the decade of replication failures is the “Psychology’s Renaissance” article by the datacolada team (Leif Nelson, Joseph Simmons, & Uri Simonsohn).
This is not your typical Annual Review article that aims to give a review over developments in the field. it is an opinion piece filled with bold claims that lack empirical evidence.
The worst claim is that p-hacking is so powerful that pretty much every study can be made to work.
“Experiments that work are sent to a journal, whereas experiments that fail are sent to the file drawer (Rosenthal 1979). We believe that this “file-drawer explanation” is incorrect. Most failed studies are not missing. They are published in our journals, masquerading as successes.”
We can all see that not publishing failed studies is a bit problematic. Even Bem’s famous manual for p-hackers warned that it is unethical to hide contradictory evidence. “The integrity of the scientific enterprise requires the reporting of disconfirming results” (Bem). Thus, the idea that researchers are sitting on a pile of failed studies that they failed to disclose makes psychologists look bad and we can’t have that in Fiske’s Annual Review of Psychology journal. Thus, psychologists must have been doing something that is not dishonest and can be sold as normal science.
“P-hacking is the only honest and practical way to consistently get underpowered studies to be statistically significant. Researchers did not learn from experience to increase their sample sizes precisely because their underpowered studies were not failing.” (p. 515).
This is utter nonsense. First, researchers have file-drawers of studies that did not work. Just ask them and they may tell you that they do.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister, personal email communication)
Leading social psychologists, Gilbert and Wilson provide an even more detailed account of their research practices that produce many non-significant results that are not reported (a.k.a. a file drawer), which has been preserved thanks to Greg Francis.
First, it’s important to be clear about what “publication bias” means. It doesn’t mean that anyone did anything wrong, improper, misleading, unethical, inappropriate, or illegal. Rather it refers to the well known fact that scientists in every field publish studies whose results tell them something interesting about the world, and don’t publish studies whose results tell them nothing. Francis uses sophisticated statistical tools to discover what everyone already knew—and what he could easily have discovered simply by asking us. Yes, of course we ran some studies on “consuming experience” that failed to show interesting effects and are not reported in our JESP paper. Let us be clear: We did not run the same study over and over again until it yielded significant results and then report only the study that “worked.” Doing so would be clearly unethical. Instead, like most researchers who are developing new methods, we did some preliminary studies that used different stimuli and different procedures and that showed no interesting effects. Why didn’t these studies show interesting effects? We’ll never know. Failed studies are often (though not always) inconclusive, which is why they are often (but not always) unpublishable. So yes, we had to mess around for a while to establish a paradigm that was sensitive and powerful enough to observe the effects that we had hypothesized. In one study we might have used foods that didn’t differ sufficiently in quality, in another we might have made the metronome tick too fast for people to chew along. Exactly how good a potato chip should be and exactly how fast a person can chew it are the kinds of mundane things that scientists have to figure out in preliminary testing, and they are the kinds of mundane things that scientists do not normally report in journals (but that they informally share with other scientists who work on similar phenomenon). Looking back at our old data files, it appears that in some cases we went hunting for potentially interesting mediators of our effect (i.e., variables that might make it larger or smaller) and although we replicated the effect, we didn’t succeed in making it larger or smaller. We don’t know why, which is why we don’t describe these blind alleys in our paper. All of this is the hum-drum ordinary stuff of day-to-day science.
Aside from this anecdotal evidence, the datacolada crew actually had access to empirical evidence in an article that they cite, but maybe never read. An important article in the 2010s reported a survey of research practices (John, Loewenstein, & Prelec, 2012). The survey asked about several questionable research practices, including not reporting entire studies that failed to support the main hypothesis.
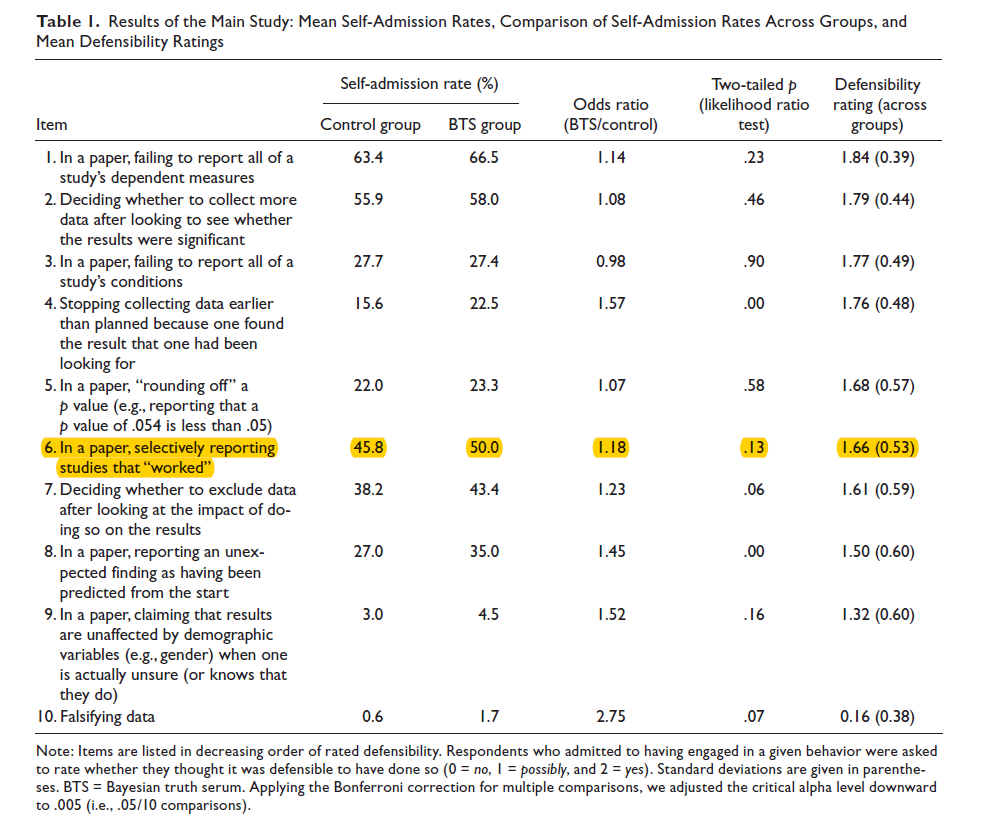
Not reporting studies that “did not work” was the third most frequently used QRP. Unfortunately, this result contradicts datacolada’s claim that there are no studies in file-drawers and so they ignore this inconvenient empirical fact to tell their fairy tail of honest p-hackers that didn’t know better until 2011 when they published their famous “False Positive Psychology” article.
This is a cute story that isn’t supported by evidence, but that has never stopped psychologists from writing articles that advance their own career. The beauty of review articles is that you don’t even have to phack data. You just pick and choose citations or make claims without evidence. As long as the editor (Fiske) likes what you have to say, it will be published. Welcome to psychology’s renaissance; same bullshit as always.
3 thoughts on “When DataColada kissed Fiske’s ass to publish in Annual Review of Psychology”