
The 2010s have seen a replication crisis in social psychology (Schimmack, 2020). The main reason why it is difficult to replicate results from social psychology is that researchers used questionable research practices (QRPs, John et al., 2012) to produce more significant results than their low-powered designs warranted. A catchy term for these practices is p-hacking (Simonsohn, 2014).
New statistical techniques made it possible to examine whether published results were obtained with QRPs. In 2012, I used the incredibility index to show that Bem (2011) used QRPs to provide evidence for extrasensory perception (Schimmack, 2012). In the same article, I also suggested that Gailliot, Baumeister, DeWall, Maner, Plant, Tice, and Schmeichel, (2007) used QRPs to present evidence that suggested will-power relies on blood glucose levels. During the review process of my manuscript, Baumeister confirmed that QRPs were used (cf. Schimmack, 2014). Baumeister defended the use of these practices with a statement that the use of these practices was the norm in social psychology and that the use of these practices was not considered unethical.
The revelation that research practices were questionable casts a shadow on the history of social psychology. However, many also saw it as an opportunity to change and improve these practices (Świątkowski and Dompnier, 2017). Over the past decades, the evaluation of QRPs has changed. Many researchers now recognize that these practices inflate error rates, make published results difficult to replicate, and undermine the credibility of psychological science (Lindsay, 2019).
However, there are no general norms regarding these practices and some researchers continue to use them (e.g., Adam D. Galinsky, cf. Schimmack, 2019). This makes it difficult for readers of the social psychological literature to identify research that can be trusted or not, and the answer to this question has to be examined on a case by case basis. In this blog post, I examine the responses of Baumeister, Vohs, DeWall, and Schmeichel to the replication crisis and concerns that their results provide false evidence about the causes of will-power (Friese, Loschelder , Gieseler , Frankenbach & Inzlicht, 2019; Inzlicht, 2016).
To examine this question scientifically, I use test-statistics that are automatically extracted from psychology journals. I divide the test-statistics into those that were obtained until 2012, when awareness about QRPs emerged, and those published after 2012. The test-statistics are examined using z-curve (Brunner & Schimmack, 2019; Bartos & Schimmack, 2020). Results provide information about the expected replication rate and discovery rate. The use of QRPs is examined by comparing the observed discovery rate (how many published results are significant) to the expected discovery rate (how many tests that were conducted produced significant results).
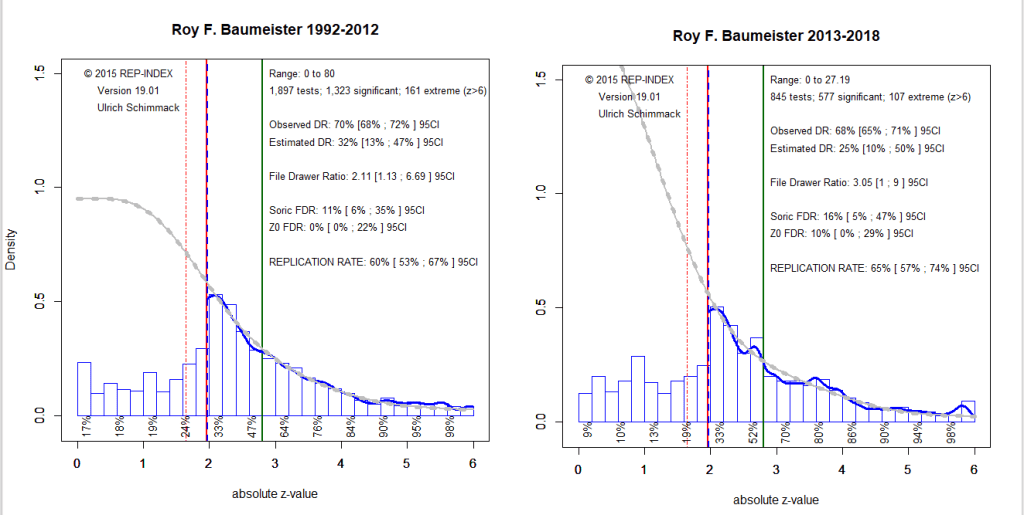
Roy F. Baumeister’s replication rate was 60% (53% to 67%) before 2012 and 65% (57% to 74%) after 2012. The overlap of the 95% confidence intervals indicates that this small increase is not statistically reliable. Before 2012, the observed discovery rate was 70% and it dropped to 68% after 2012. Thus, there is no indication that non-significant results are reported more after 2012. The expected discovery rate was 32% before 2012 and 25% after 2012. Thus, there is also no change in the expected discovery rate and the expected discovery rate is much lower than the observed discovery rate. This discrepancy shows that QRPs were used before 2012 and after 2012. The 95%CI do not overlap before and after 2012, indicating that this discrepancy is statistically significant. Figure 1 shows the influence of QRPs when the observed non-significant results (histogram of z-scores below 1.96 in blue) is compared to the model prediction (grey curve). The discrepancy suggests a large file drawer of unreported statistical tests.
An old saying is that you can’t teach an old dog new tricks. So, the more interesting question is whether the younger contributors to the glucose paper changed their research practices.
The results for C. Nathan DeWall show no notable response to the replication crisis (Figure 2). The expected replication rate increased slightly from 61% to 65%, but the difference is not significant and visual inspection of the plots suggests that it is mostly due to a decrease in reporting p-values just below .05. One reason for this might be a new goal to p-hack at least to the level of .025 to avoid detection of p-hacking by p-curve analysis. The observed discovery rate is practically unchanged from 68% to 69%. The expected discovery rate increased only slightly from 28% to 35%, but the difference is not significant. More important, the expected discovery rates are significantly lower than the observed discovery rates before and after 2012. Thus, there is evidence that DeWall used questionable research practices before and after 2012, and there is no evidence that he changed his research practices.

The results for Brandon J. Schmeichel are even more discouraging (Figure 3). Here the expected replication rate decreased from 70% to 56%, although this decrease is not statistically significant. The observed discovery rate decreased significantly from 74% to 63%, which shows that more non-significant results are reported. Visual inspection shows that this is particularly the case for test-statistics close to zero. Further inspection of the article would be needed to see how these results are interpreted. More important, The expected discovery rates are significantly lower than the observed discovery rates before 2012 and after 2012. Thus, there is evidence that QRPs were used before and after 2012 to produce significant results. Overall, there is no evidence that research practices changed in response to the replication crisis.

The results for Kathleen D. Vohs also show no response to the replication crisis (Figure 4). The expected replication rate dropped slightly from 62% to 58%; the difference is not significant. The observed discovery rate dropped slightly from 69% to 66%, and the expected discovery rate decreased from 43% to 31%, although this difference is also not significant. Most important, the observed discovery rates are significantly higher than the expected discovery rates before 2012 and after 2012. Thus, there is clear evidence that questionable research practices were used before and after 2012 to inflate the discovery rate.

Conclusion
After concerns about research practices and replicability emerged in the 2010s, social psychologists have debated this issue. Some social psychologists changed their research practices to increase statistical power and replicability. However, other social psychologists have denied that there is a crisis and attributed replication failures to a number of other causes. Not surprisingly, some social psychologists also did not change their research practices. This blog post shows that Baumeister and his students have not changed research practices. They are able to publish questionable research because there has been no collective effort to define good research practices and to ban questionable practices and to treat the hiding of non-significant results as a breach of research ethics. Thus, Baumeister and his students are simply exerting their right to use questionable research practices, whereas others voluntarily implemented good, open science, practices. Given the freedom of social psychologists to decide which practices they use, social psychology as a field continuous to have a credibility problem. Editors who accept questionable research in their journals are undermining the credibility of their journal. Authors are well advised to publish in journals that emphasis replicability and credibility with open science badges and with a high replicability ranking (Schimmack, 2019).