
Citation: Francis G., (2014). The frequency of excess success for articles
in Psychological Science. Psychon Bull Rev (2014) 21:1180–1187
DOI 10.3758/s13423-014-0601-x
Introduction
The Open Science Collaboration article in Science has over 1,000 articles (OSC, 2015). It showed that attempting to replicate results published in 2008 in three journals, including Psychological Science, produced more failures than successes (37% success rate). It also showed that failures outnumbered successes 3:1 in social psychology. It did not show or explain why most social psychological studies failed to replicate.
Since 2015 numerous explanations have been offered for the discovery that most published results in social psychology cannot be replicated: decline effect (Schooler), regression to the mean (Fiedler), incompetent replicators (Gilbert), sabotaging replication studies (Strack), contextual sensitivity (vanBavel). Although these explanations are different, they share two common elements, (a) they are not supported by evidence, and (b) they are false.
A number of articles have proposed that the low replicability of results in social psychology are caused by questionable research practices (John et al., 2012). Accordingly, social psychologists often investigate small effects in between-subject experiments with small samples that have large sampling error. A low signal to noise ratio (effect size/sampling error) implies that these studies have a low probability of producing a significant result (i.e., low power and high type-II error probability). To boost power, researchers use a number of questionable research practices that inflate effect sizes. Thus, the published results provide the false impression that effect sizes are large and results are replicated, but actual replication attempts show that the effect sizes were inflated. The replicability projected suggested that effect sizes are inflated by 100% (OSC, 2015).
In an important article, Francis (2014) provided clear evidence for the widespread use of questionable research practices for articles published from 2009-2012 (pre crisis) in the journal Psychological Science. However, because this evidence does not fit the narrative that social psychology was a normal and honest science, this article is often omitted from review articles, like Nelson et al’s (2018) ‘Psychology’s Renaissance’ that claims social psychologists never omitted non-significant results from publications (cf. Schimmack, 2019). Omitting disconfirming evidence from literature reviews is just another sign of questionable research practices that priorities self-interest over truth. Given the influence that Annual Review articles hold, many readers maybe unfamiliar with Francis’s important article that shows why replication attempts of articles published in Psychological Science often fail.
Francis (2014) “The frequency of excess success for articles in Psychological Science”
Francis (2014) used a statistical test to examine whether researchers used questionable research practices (QRPs). The test relies on the observation that the success rate (percentage of significant results) should match the mean power of studies in the long run (Brunner & Schimmack, 2019; Ioannidis, J. P. A., & Trikalinos, T. A., 2007; Schimmack, 2012; Sterling et al., 1995). Statistical tests rely on the observed or post-hoc power as an estimate of true power. Thus, mean observed power is an estimate of the expected number of successes that can be compared to the actual success rate in an article.
It has been known for a long time that the actual success rate in psychology articles is surprisingly high (Sterling, 1995). The success rate for multiple-study articles is often 100%. That is, psychologists rarely report studies where they made a prediction and the study returns a non-significant results. Some social psychologists even explicitly stated that it is common practice not to report these ‘uninformative’ studies (cf. Schimmack, 2019).
A success rate of 100% implies that studies required 99.9999% power (power is never 100%) to produce this result. It is unlikely that many studies published in psychological science have the high signal-to-noise ratios to justify these success rates. Indeed, when Francis applied his bias detection method to 44 studies that had sufficient results to use it, he found that 82 % (36 out of 44) of these articles showed positive signs that questionable research practices were used with a 10% error rate. That is, his method could at most produce 5 significant results by chance alone, but he found 36 significant results, indicating the use of questionable research practices. Moreover, this does not mean that the remaining 8 articles did not use questionable research practices. With only four studies, the test has modest power to detect questionable research practices when the bias is relatively small. Thus, the main conclusion is that most if not all multiple-study articles published in Psychological Science used questionable research practices to inflate effect sizes. As these inflated effect sizes cannot be reproduced, the effect sizes in replication studies will be lower and the signal-to-noise ratio will be smaller, producing non-significant results. It was known that this could happen since 1959 (Sterling, 1959). However, the replicability project showed that it does happen (OSC, 2015) and Francis (2014) showed that excessive use of questionable research practices provides a plausible explanation for these replication failures. No review of the replication crisis is complete and honest, without mentioning this fact.
Limitations and Extension
One limitation of Francis’s approach and similar approaches like my incredibility Index (Schimmack, 2012) is that p-values are based on two pieces of information, the effect size and sampling error (signal/noise ratio). This means that these tests can provide evidence for the use of questionable research practices, when the number of studies is large, and the effect size is small. It is well-known that p-values are more informative when they are accompanied by information about effect sizes. That is, it is not only important to know that questionable research practices were used, but also how much these questionable practices inflated effect sizes. Knowledge about the amount of inflation would also make it possible to estimate the true power of studies and use it as a predictor of the success rate in actual replication studies. Jerry Brunner and I have been working on a statistical method that is able to to this, called z-curve, and we validated the method with simulation studies (Brunner & Schimmack, 2019).
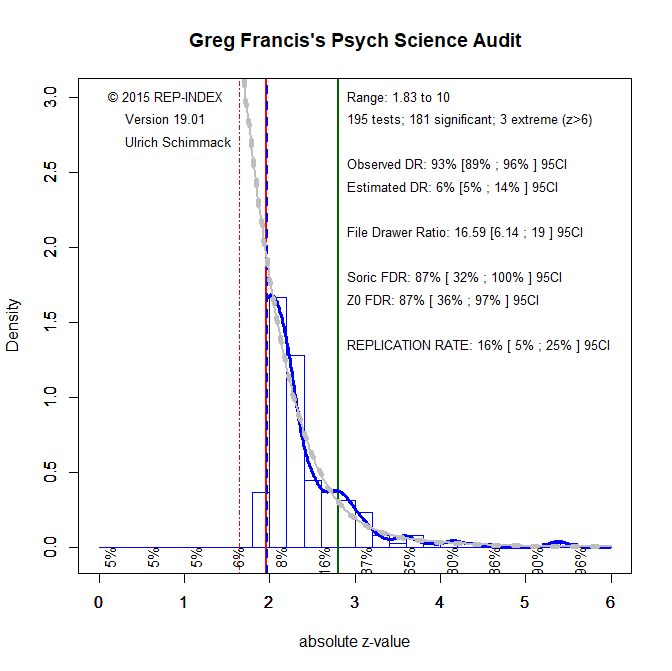
I coded the 195 studies in the 44 articles analyzed by Francis and subjected the results to a z-curve analysis. The results are shocking and much worse than the results for the studies in the replicability project that produced an expected replication rate of 61%. In contrast, the expected replication rate for multiple-study articles in Psychological Science is only 16%. Moreover, given the fairly large number of studies, the 95% confidence interval around this estimate is relatively narrow and includes 5% (chance level) and a maximum of 25%.
There is also clear evidence that QRPs were used in many, if not all, articles. Visual inspection shows a steep drop at the level of significance, and the only results that are not significant with p < .05 are results that are marginally significant with p < .10. Thus, the observed discovery rate of 93% is an underestimation and the articles claimed an amazing success rate of 100%.
Correcting for bias, the expected discovery rate is only 6%, which is just shy of 5%, which would imply that all published results are false positives. The upper limit for the 95% confidence interval around this estimate is 14, which would imply that for every published significant result there are 6 studies with non-significant results if file-drawring were the only QRP that was used. Thus, we see not only that most article reported results that were obtained with QRPs, we also see that massive use of QRPs was needed because many studies had very low power to produce significant results without QRPs.
Conclusion
Social psychologists have used QRPs to produce impressive results that suggest all studies that tested a theory confirmed predictions. These results are not real. Like a magic show they give the impression that something amazing happened, when it is all smoke and mirrors. In reality, social psychologists never tested their theories because they simply failed to report results when the data did not support their predictions. This is not science. The 2010s have revealed that social psychological results in journals and text books cannot be trusted and that influential results cannot be replicated when the data are allowed to speak. Thus, for the most part, social psychology has not been an empirical science that used the scientific method to test and refine theories based on empirical evidence. The major discovery in the 2010s was to reveal this fact, and Francis’s analysis provided valuable evidence to reveal this fact. However, most social psychologists preferred to ignore this evidence. As Popper pointed out, this makes them truly ignorant, which he defined as “the unwillingness to acquire knowledge.” Unfortunately, even social psychologists who are trying to improve it wilfully ignore Francis’s evidence that makes replication failures predictable and undermines the value of actual replication studies. Given the extent of QRPs, a more rational approach would be to dismiss all evidence that was published before 2012 and to invest resources in new research with open science practices. Actual replication failures were needed to confirm predictions made by bias tests that old studies cannot be trusted. The next decade should focus on using open science practices to produce robust and replicable findings that can provide the foundation for theories.
2 thoughts on “Francis’s Audit of Multiple-Study Articles in Psychological Science in 2009-2012”