Bakker, M., van Dijk, A., & Wicherts, J. M. (2012). The Rules of the Game Called Psychological Science. Perspectives on Psychological Science, 7(6), 543–554. https://doi.org/10.1177/1745691612459060
Bartlett, T. (2013). Power of suggestion: The amazing influence of uncon- scious cues is among the most fascinating discoveries of our time—That is, if it’s true. The Chronicle of Higher Education. Retrieved from https://www.chronicle.com/article/Power-of-Suggestion/136907
Bartoš, F., & Schimmack, U. (2022). Z-curve 2.0: Estimating replication rates and discovery rates. Meta-Psychology, 6, Article e0000130. https://doi.org/10.15626/MP.2022.2981
Baumeister, R. F., & Vohs, K. D. (2016). Misguided effort with elusive implications. Perspectives on Psychological Science, 11(4), 574–575. https://doi.org/10.1177/1745691616652878
Bem, D. J. (2000). Writing an empirical article. In R. J. Sternberg (Ed.), Guide to publishing in psychological journals (pp. 3–16). Cambridge, UK: Cambridge University Press. http://dx.doi.org/10.1017/CBO9780511807862.002
Bem, D. J. (2011). Feeling the future: Experimental evidence for anoma- lous retroactive influences on cognition and affect. Journal of Personality and Social Psychology, 100, 407– 425. http://dx.doi.org/10.1037/a0021524
Bem, D. J., Utts, J., & Johnson, W. O. (2011). Must psychologists change the way they analyze their data? Journal of Personality and Social Psychology, 101, 716 –719. http://dx.doi.org/10.1037/a0024777
Benjamin, D.J., Berger, J.O., Johannesson, M. et al. (2018) Redefine statistical significance. Nature Human Behaviour 2, 6–10. https://doi.org/10.1038/s41562-017-0189-z
Brunner, J., & Schimmack, U. (2020). Estimating population mean power under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
Bryan, C. J., Yeager, D. S., & O’Brien, J. M. (2019). Replicator degrees of freedom allow publication of misleading failures to replicate. Proceedings of the National Academy of Sciences USA, 116, 25535–25545. http://dx.doi.org/10.1073/pnas.1910951116 [Rating 2/10, review]
Cacioppo, J. T., Petty, R. E., & Morris, K. (1983). Effects of need for cognition on message evaluation, recall, and persuasion. Journal of Personality and Social Psychology, 45, 805– 818. http://dx.doi.org/10.1037/0022-3514.45.4.805
Cairo, A. H., Green, J. D., Forsyth, D. R., Behler, A. M. C., & Raldiris, T. L. (2020). Gray (literature) mattes: Evidence of selective hypothesis reporting in social psychological research. Personality and Social Psy- chology Bulletin. Advance online publication. http://dx.doi.org/10.1177/ 0146167220903896
Carter, E. C., Kofler, L. M., Forster, D. E., & McCullough, M. E. (2015). A series of meta-analytic tests of the depletion effect: Self-control does not seem to rely on a limited resource. Journal of Experimental Psy- chology: General, 144, 796 – 815. http://dx.doi.org/10.1037/xge0000083
Carter EC, Schönbrodt FD, Gervais WM, Hilgard J. (2019). Correcting for Bias in Psychology: A Comparison of Meta-Analytic Methods. Advances in Methods and Practices in Psychological Science. 2019;2(2):115-144. doi:10.1177/2515245919847196 [ChatGPT review, rating 9/10]
Carter, E. C., & McCullough, M. E. (2013). Is ego depletion too incredible? Evidence for the overestimation of the depletion effect. Behavioraland Brain Sciences, 36, 683– 684. http://dx.doi.org/10.1017/S0140525X13000952
Carter, E. C., & McCullough, M. E. (2014). Publication bias and the limited strength model of self-control: Has the evidence for ego depletion been overestimated? Frontiers in Psychology, 5, 823.http://dx.doi.org/10.3389/fpsyg.2014.00823
Cohen, J. (1962). The statistical power of abnormal-social psychological research: A review. Journal of Abnormal and Social Psychology, 65, 145–153. http://dx.doi.org/10.1037/h0045186
Crandall, C. S., & Sherman, J. W. (2016). On the scientific superiority of conceptual replications for scientific progress. Journal of Experimental Social Psychology, 66, 93–99. http://dx.doi.org/10.1016/j.jesp.2015.10.002
Cunningham, M. R., & Baumeister, R. F. (2016). How to make nothing out of something: Analyses of the impact of study sampling and statistical interpretation in misleading meta-analytic conclusions. Frontiers in Psy- chology, 7, 1639. http://dx.doi.org/10.3389/fpsyg.2016.01639
Ebersole, C. R., Atherton, O. E., Belanger, A. L., Skulborstad, H. M., Allen, J. M., Banks, J. B., . . . Nosek, B. A. (2016). Many Labs 3: Evaluating participant pool quality across the academic semester via replication. Journal of Experimental Social Psychology, 67, 68 – 82. http://dx.doi.org/10.1016/j.jesp.2015.10.012
Elkins-Brown, N., Saunders, B., & Inzlicht, M. (2018). The misattribution of emotions and the error-related negativity: A registered report. Cortex, 109, 124 –140. http://dx.doi.org/10.1016/j.cortex.2018.08.017
Ferguson, C. J., & Heene, M. (2012). A vast graveyard of undead theories: Publication bias and psychological science’s aversion to the null. Per- spectives on Psychological Science, 7, 555–561. http://dx.doi.org/10.1177/1745691612459059
Fiedler, K., & Schwarz, N. (2016). Questionable research practices revis- ited. Social Psychological & Personality Science, 7, 45–52. http://dx.doi.org/10.1177/1948550615612150
Fisher, R. A. (1926). The arrangement of field experiments. Journal of the Ministry of Agriculture, 33, 503–513.
Fiske, S. T. (2016). How to publish rigorous experiments in the 21st century. Journal of Experimental Social Psychology, 66, 145–147. http://dx.doi.org/10.1016/j.jesp.2016.01.006
Francis, G. (2012). Too good to be true: Publication bias in two prominent studies from experimental psychology. Psychonomic Bulletin & Review, 19, 151–156. http://dx.doi.org/10.3758/s13423-012-0227-9
Galak, J., LeBoeuf, R. A., Nelson, L. D., & Simmons, J. P. (2012). Correcting the past: Failures to replicate. Journal of Personality andSocial Psychology, 103, 933–948. http://dx.doi.org/10.1037/a0029709
Gilbert, D. T., King, G., Pettigrew, S., & Wilson, T. D. (2016). Comment on “Estimating the reproducibility of psychological science.” Science, 351, 1037–1103. http://dx.doi.org/10.1126/science.aad7243
Gronau, Q. F., Duizer, M., Bakker, M., & Wagenmakers, E.-J. (2017). Bayesian mixture modeling of significant p values: A meta-analytic method to estimate the degree of contamination from Ho. Journal of Experimental Psychology: General, 146, 1223–1233. http://dx.doi.org/10.1037/xge0000324
Hagger, M. S., Chatzisarantis, N. L. D., Alberts, H., Anggono, C. O., Batailler, C., Birt, A. R., . Zwienenberg, M. (2016). A multilab preregistered replication of the ego-depletion effect. Perspectives on Psychological Science, 11, 546 –573. http://dx.doi.org/10.1177/1745691616652873
Hagger, M. S., Wood, C., Stiff, C., & Chatzisarantis, N. L. D. (2010). Ego depletion and the strength model of self-control: A meta-analysis. Psychological Bulletin, 136, 495–525. http://dx.doi.org/10.1037/a0019486
Inbar, Y. (2016). Association between contextual dependence and replicability in psychology may be spurious. Proceedings of the National Academy of Sciences, 113(34):E4933-9334, doi.org/10.1073/pnas.1608676113
John, L. K., Loewenstein, G., & Prelec, D. (2012). Measuring the Prevalence of Questionable Research Practices With Incentives for Truth Telling. Psychological Science, 23(5), 524–532. https://doi.org/10.1177/0956797611430953
Kerr, N. L. (1998). HARKing: Hypothesizing After the Results are Known. Personality and Social Psychology Review, 2(3), 196–217. https://doi.org/10.1207/s15327957pspr0203_4
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian new statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25, 178 –206. http://dx.doi.org/10.3758/s13423-016-1221-4
Kvarven, A., Strømland, E. & Johannesson, M. (2020). Comparing meta-analyses and preregistered multiple-laboratory replication projects. Nature Human Behaviour 4, 423–434 (2020). https://doi.org/10.1038/s41562-019-0787-z
Lakens, D., Scheel, A. M., & Isager, P. M. (2018). Equivalence testing for psychological research: A tutorial. Advances in Methods and Practices in Psychological Science, 1, 259 –269. http://dx.doi.org/10.1177/2515245918770963
Lengersdorff LL, Lamm C. With Low Power Comes Low Credibility? Toward a Principled Critique of Results From Underpowered Tests. Advances in Methods and Practices in Psychological Science. 2025;8(1). doi:10.1177/25152459241296397 [Rating 4/10, review]
Lin, H., Saunders, B., Friese, M., Evans, N. J., & Inzlicht, M. (2020). Strong effort manipulations reduce response caution: A preregistered reinvention of the ego-depletion paradigm. Psychological Science, 31, 531–547. http://dx.doi.org/10.1177/0956797620904990
Luttrell, A., Petty, R. E., & Xu, M. (2017). Replicating and fixing failed replications: The case of need for cognition and argument quality. Journal of Experimental Social Psychology, 69, 178 –183. http://dx.doi.org/10.1016/j.jesp.2016.09.006
Maxwell, S. E., Lau, M. Y., & Howard, G. S. (2015). Is psychology suffering from a replication crisis? What does “failure to replicate” really mean? American Psychologist, 70, 487– 498. http://dx.doi.org/10.1037/a0039400
McShane BB, Böckenholt U, Hansen KT. Average Power: A Cautionary Note. Advances in Methods and Practices in Psychological Science. 2020;3(2):185-199. doi:10.1177/2515245920902370
Morey, R. D., & Davis-Stober, C. P. (2025). On the poor statistical properties of the P-curve meta-analytic procedure. Journal of the American Statistical Association. Advance online publication. https://doi.org/10.1080/01621459.2025.2544397 [see Blog post for info]
Motyl, M., Demos, A. P., Carsel, T. S., Hanson, B. E., Melton, Z. J., Mueller, A. B., . . . Skitka, L. J. (2017). The state of social and personality science: Rotten to the core, not so bad, getting better, or getting worse? Journal of Personality and Social Psychology, 113, 34 –58. http://dx.doi.org/10.1037/pspa0000084
Murayama, K., Pekrun, R., & Fiedler, K. (2014). Research practices that can prevent an inflation of false-positive rates. Personality and Social Psychology Review, 18, 107–118. http://dx.doi.org/10.1177/1088868313496330
Noah, T., Schul, Y., & Mayo, R. (2018). When both the original study and its failed replication are correct: Feeling observed eliminates the facial- feedback effect. Journal of Personality and Social Psychology, 114, 657– 664. http://dx.doi.org/10.1037/pspa0000121
Nosek, B. A., Ebersole, C. R., DeHaven, A. C., & Mellor, D. T. (2018). The preregistration revolution. Proceedings of the National Academy of Sciences USA, 115, 2600 –2606. http://dx.doi.org/10.1073/pnas.1708274114
Pashler, H., & Harris, C. R. (2012). Is the replicability crisis overblown? Three arguments examined. Perspectives on Psychological Science, 7, 531–536. http://dx.doi.org/10.1177/1745691612463401
Patil, P., Peng, R. D., & Leek, J. T. (2016). What Should Researchers Expect When They Replicate Studies? A Statistical View of Replicability in Psychological Science. Perspectives on Psychological Science, 11(4), 539-544. https://doi-org.myaccess.library.utoronto.ca/10.1177/1745691616646366 [Rating 3/10, review]
Pek, J., Hoisington-Shaw, K. J., & Wegener, D. T. (2024). Uses of uncertain statistical power: Designing future studies, not evaluating completed studies.. Psychological Methods. Advance online publication. https://dx.doi.org/10.1037/met0000577 [Rating 1/10, review]
Pettigrew, T. F. (2018). The e`mergence of contextual social psychology. Personality and Social Psychology Bulletin, 44, 963–971. http://dx.doi.org/10.1177/0146167218756033
Renkewitz, F., & Keiner, M. (2019). How to detect publication bias in psychological research: A comparative evaluation of six statistical methods. Zeitschrift für Psychologie, 227(4), 261-279. http://dx.doi.org/10.1027/2151-2604/a000386
Ritchie, S. J., Wiseman, R., & French, C. C. (2012). Failing the future: Three unsuccessful attempts to replicate Bem’s ‘retroactive facilitation of recall’ effect. PLoS One, 7, e33423. http://dx.doi.org/10.1371/journal.pone.0033423
Scheel, A. M., Schijen, M., & Lakens, D. (2020). An excess of positive results: Comparing the standard psychology literature with registered reports. Retrieved from https://psyarxiv.com/p6e9c
Schimmack, U. (2012). The ironic effect of significant results on the credibility of multiple-study articles. Psychological Methods, 17, 551– 566. http://dx.doi.org/10.1037/a0029487
Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology / Psychologie canadienne, 61(4), 364–376. https://doi.org/10.1037/cap0000246
Schimmack, U. (2018b). Why the Journal of Personality and Social Psychology Should Retract Article DOI:10.1037/a0021524 “Feeling the future: Experimental evidence for anomalous retroactive influences on cognition and affect” by Daryl J. Bem. Retrieved January 6, 2020, from https://replicationindex.com/2018/01/05/bem-retraction
Schimmack, U., & Bartoš, F. (2023). Estimating the false discovery risk of (randomized) clinical trials in medical journals based on published p-values. PLOS ONE, 18(7), e0290084. https://doi.org/10.1371/journal.pone.0290084
Schooler, J. W. (2014). Turning the lens of science on itself: Verbal overshadowing, replication, and metascience. Perspectives on Psycho- logical Science, 9, 579 –584. http://dx.doi.org/10.1177/1745691614547878
Schooler, J. W., & Engstler-Schooler, T. Y. (1990). Verbal overshadowing of visual memories: Some things are better left unsaid. Cognitive Psy- chology, 22, 36 –71. http://dx.doi.org/10.1016/0010-0285(90)90003-M
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22, 1359 –1366. http://dx.doi.org/10.1177/0956797611417632
Simonsohn, U. (2013). It does not follow: Evaluating the one-off publication bias critiques by Francis (2012a, 2012b, 2012c, 2012d, 2012e, in press). Perspective on Psychological Science, 7, 597–599. http://dx.doi.org/10.1177/1745691612463399
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014). P-curve and effect size: Correcting for publication bias using only significant results. Perspectives on Psychological Science, 9, 666 – 681. http://dx.doi.org/10.1177/1745691614553988
Sorić, B. (1989). Statistical “Discoveries” and Effect-Size Estimation. Journal of the American Statistical Association,84(406), 608-610. doi:10.2307/2289950
Soto, M. D., & Schimmack, U. (2024). Credibility of results in emotion science: A Z-curve analysis of results in the journals Cognition & Emotion and Emotion. Cognition & Emotion. Advance online publication. https://doi.org/10.1080/02699931.2024.244301
Soto, M. D., & Schimmack, U. (2025). Credibility of results in psychological science: A z-curve analysis across journals and time [Preprint]. PsyArXiv.https://doi.org/10.31234/osf.io/6ybeu
Sterling, T. D. (1959). Publication decision and the possible effects on inferences drawn from tests of significance— or vice versa. Journal of the American Statistical Association, 54, 30 –34.
Sterling, T. D., Rosenbaum, W. L., & Weinkam, J. J. (1995). Publication decisions revisited: The effect of the outcome of statistical tests on the decision to publish and vice versa. The American Statistician, 49, 108 –112.
Strack, F. (2016). Reflection on the smiling registered replication report. Perspectives on Psychological Science, 11, 929 –930. http://dx.doi.org/10.1177/1745691616674460
Stroebe, W., & Strack, F. (2014). The alleged crisis and the illusion of exact replication. Perspectives on Psychological Science, 9, 59 –71. http://dx.doi.org/10.1177/1745691613514450
Tendeiro, J. N., & Kiers, H. A. L. (2019). A review of issues about null hypothesis Bayesian testing. Psychological Methods, 24, 774 –795. http://dx.doi.org/10.1037/met0000221
Trafimow, D. (2003). Hypothesis testing and theory evaluation at the boundaries: Surprising insights from Bayes’s theorem. Psychological Review, 110, 526 –535. http://dx.doi.org/10.1037/0033-295X.110.3.526
Ulrich, R., & Miller, J. (2018). Some properties of p-curves, with an application to gradual publication bias. Psychological Methods, 23, 546 –560. http://dx.doi.org/10.1037/met0000125
Van Bavel, J. J., Mende-Siedlecki, P., Brady, W. J., & Reinero, D. A. (2016). Contextual sensitivity in scientific reproducibility. Proceedings of the National Academy of Sciences USA, 113, 6454 – 6459. http://dx.doi.org/10.1073/pnas.1521897113
Vohs, K. D., Schmeichel, B. J., Lohmann, S., Gronau, Q. F., Finley, A. J., Ainsworth, S. E., Alquist, J. L., Baker, M. D., Brizi, A., Bunyi, A., Butschek, G. J., Campbell, C., Capaldi, J., Cau, C., Chambers, H., Chatzisarantis, N. L. D., Christensen, W. J., Clay, S. L., Curtis, J., De Cristofaro, V., … Albarracín, D. (2021). A Multisite Preregistered Paradigmatic Test of the Ego-Depletion Effect. Psychological science, 32(10), 1566–1581. https://doi.org/10.1177/0956797621989733
Wagenmakers, E. J., Wetzels, R., Borsboom, D., & van der Maas, H. L. (2011). Why psychologists must change the way they analyze their data: The case of psi: Comment on Bem (2011). Journal of Personality and Social Psychology, 100, 426 – 432. http://dx.doi.org/10.1037/a0022790
Wagenmakers, E.-J., Beek, T., Dijkhoff, L., Gronau, Q. F., Acosta, A., Adams, R. B., … Zwaan, R. A. (2016). Registered Replication Report: Strack, Martin, & Stepper (1988). Perspectives on Psychological Science, 11(6), 917–928. https://doi.org/10.1177/1745691616674458
Wegener, D. T., Fabrigar, L. R., Pek, J., & Hoisington-Shaw, K. (2021). Evaluating Research in Personality and Social Psychology: Considerations of Statistical Power and Concerns About False Findings. Personality and Social Psychology Bulletin, 48(7), 1105-1117. https://doi-org.myaccess.library.utoronto.ca/10.1177/01461672211030811
Wicherts, J. M., Veldkamp, C. L. S., Augusteijn, H. E. M., Bakker, M., van Aert, R. C. M., & van Assen, M. A. L. M. (2016). Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Frontiers in Psychology, 7, 1832.http://dx.doi.org/10.3389/fpsyg.2016.01832
Wilson, B. M., & Wixted, J. T. (2018). The prior odds of testing a true effect in cognitive and social psychology. Advances in Methods and Practices in Psychological Science, 1, 186 –197. http://dx.doi.org/10.1177/2515245918767122
Yuan, K.-H., & Maxwell, S. (2005). On the Post Hoc Power in Testing Mean Differences. Journal of Educational and Behavioral Statistics, 30(2), 141–167. https://doi.org/10.3102/10769986030002141
Zwaan, R. A., Etz, A., Lucas, R. E., & Donnellan, M. B. (2018). Improving social and behavioral science by making replication mainstream: A response to commentaries. Behavioral and Brain Sciences, 41, e157. http://dx.doi.org/10.1017/S0140525X18000961
In the 2010s, it became apparent that empirical psychology had a replication problem. When psychologists tested the replicability of 100 results, they found that only 36% of the 97 significant results in original studies could be reproduced (Open Science Collaboration, 2015). In addition, several prominent cases of research fraud further undermined trust in published results. Over the past decade, several proposals were made to improve the credibility of psychology as a science. Replicability Reports aim to improve the credibilty of psychological science by examining the amount of publication bias and the strength of evidence for empirical claims in psychology journals.
The main problem in psychological science is the selective publishing of statistically significant results and the blind trust in statistically significant results as evidence for researchers’ theoretical claims. Unfortunately, psychologists have been unable to self-regulate their behaviour and continue to use unscientific practices to hide evidence that disconfirms their predictions. Moreover, ethical researchers who do not use unscientific practices are at a disadvantage in a game that rewards publishing many articles without concern about these findings’ replicability.
My colleagues and I have developed a statistical tool that can reveal the use of unscientific practices and predict the outcome of replication studies (Brunner & Schimmack, 2021; Bartos & Schimmack, 2022). This method is called z-curve. Z-curve cannot be used to evaluate the credibility of a single study. However, it can provide valuable information about the research practices in a particular research domain.
Replicability-Reports (RR) use z-curve to provide information about psychological journal research and publication practices. This information can aid authors choose journals they want to publish in, provide feedback to journal editors who influence selection bias and replicability of published results, and, most importantly, to readers of these journals.
Evolutionary Psychology
Evolutionary Psychology was founded in 2003. The journal focuses on publishing empirical theoretical and review articles investigating human behaviour from an evolutionary perspective. On average, Evolutionary Psychology publishes about 35 articles in 4 annual issues.
As a whole, evolutionary psychology has produced both highly robust and questionable results. Robust results have been found for sex differences in behaviors and attitudes related to sexuality. Questionable results have been reported for changes in women’s attitudes and behaviors as a function of hormonal changes throughout their menstrual cycle.
According to Web of Science, the impact factor of Evolutionary Psychology ranks 88th in the Experimental Psychology category (Clarivate, 2024). The journal has a 48 H-Index (i.e., 48 articles have received 48 or more citations).
In its lifetime, Evolutionary Psychology has published over 800 articles The average citation rate in this journal is 13.76 citations per article. So far, the journal’s most cited article has been cited 210 times. The article was published in 2008 and investigated the influence of women’s mate value on standards for a long-term mate (Buss & Shackelford, 2008).
The current Editor-in-Chief is Professor Todd K. Shackelford. Additionally, the journal has four other co-editors Dr. Bernhard Fink, Professor Mhairi Gibson, Professor Rose McDermott, and Professor David A. Puts.
Extraction Method
Replication reports are based on automatically extracted test statistics such as F-tests, t-tests, z-tests, and chi2-tests. Additionally, we extracted 95% confidence intervals of odds ratios and regression coefficients. The test statistics were extracted from collected PDF files using a custom R-code. The code relies on the pdftools R package (Ooms, 2024) to render all textboxes from a PDF file into character strings. Once converted the code proceeds to systematically extract the test statistics of interest (Soto & Schimmack, 2024). PDF files identified as editorials, review papers and meta-analyses were excluded. Meta-analyses were excluded to avoid the inclusion of test statistics that were not originally published in Evolution & Human Behavior. Following extraction, the test statistics are converted into absolute z-scores.
Results For All Years
Figure 1 shows a z-curve plot for all articles from 2003-2023 (see Schimmack, 2023, for a detailed description of z-curve plots). However, the total available test statistics available for 2003, 2004 and 2005 were too low to be used individually. Therefore, these years were joined to ensure the plot had enough test statistics for each year. The plot is essentially a histogram of all test statistics converted into absolute z-scores (i.e., the direction of an effect is ignored). Z-scores can be interpreted as the strength of evidence against the null hypothesis that there is no statistical relationship between two variables (i.e., the effect size is zero and the expected z-score is zero). A z-curve plot shows the standard criterion of statistical significance (alpha = .05, z = 1.96) as a vertical red dotted line.
Figure 1
Z-curve plots are limited to values less than z = 6. The reason is that values greater than 6 are so extreme that a successful replication is all but certain unless the value is a computational error or based on fraudulent data. The extreme values are still used for the computation of z-curve statistics but omitted from the plot to highlight the shape of the distribution for diagnostic z-scores in the range from 2 to 6. Using the expectation maximization (EM) algorithm, Z-curve estimates the optimal weights for seven components located at z-values of 0, 1, …. 6 to fit the observed statistically significant z-scores. The predicted distribution is shown as a blue curve. Importantly, the model is fitted to the significant z-scores, but the model predicts the distribution of non-significant results. This makes it possible to examine publication bias (i.e., selective publishing of significant results). Using the estimated distribution of non-significant and significant results, z-curve provides an estimate of the expected discovery rate (EDR); that is, the percentage of significant results that were actually obtained without selection for significance. Using Soric’s (1989) formula the EDR is used to estimate the false discovery risk; that is, the maximum number of significant results that are false positives (i.e., the null-hypothesis is true).
Selection for Significance
The extent of selection bias in a journal can be quantified by comparing the Observed Discovery Rate (ODR) of 68%, 95%CI = 67% to 70% with the Expected Discovery Rate (EDR) of 49%, 95%CI = 26%-63%. The ODR is higher than the upper limit of the confidence interval for the EDR, suggesting the presence of selection for publication. Even though the distance between the ODR and the EDR estimate is narrower than those commonly seen in other journals the present results may underestimate the severity of the problem. This is because the analysis is based on all statistical results. Selection bias is even more problematic for focal hypothesis tests and the ODR for focal tests in psychology journals is often close to 90%.
Expected Replication Rate
The Expected Replication Rate (ERR) estimates the percentage of studies that would produce a significant result again if exact replications with the same sample size were conducted. A comparison of the ERR with the outcome of actual replication studies shows that the ERR is higher than the actual replication rate (Schimmack, 2020). Several factors can explain this discrepancy, such as the difficulty of conducting exact replication studies. Thus, the ERR is an optimist estimate. A conservative estimate is the EDR. The EDR predicts replication outcomes if significance testing does not favour studies with higher power (larger effects and smaller sampling error) because statistical tricks make it just as likely that studies with low power are published. We suggest using the EDR and ERR in combination to estimate the actual replication rate.
The ERR estimate of 72%, 95%CI = 67% to 77%, suggests that the majority of results should produce a statistically significant, p < .05, result again in exact replication studies. However, the EDR of 49% implies that there is some uncertainty about the actual replication rate for studies in this journal and that the success rate can be anywhere between 49% and 72%.
False Positive Risk
The replication crisis has led to concerns that many or even most published results are false positives (i.e., the true effect size is zero). Using Soric’s formula (1989), the maximum false discovery rate can be calculated based on the EDR.
The EDR of 49% implies a False Discovery Risk (FDR) of 6%, 95%CI = 3% to 15%, but the 95%CI of the FDR allows for up to 15% false positive results. This estimate contradicts claims that most published results are false (Ioannidis, 2005).
Changes Over Time
One advantage of automatically extracted test-statistics is that the large number of test statistics makes it possible to examine changes in publication practices over time. We were particularly interested in changes in response to awareness about the replication crisis in recent years.
Z-curve plots for every publication year were calculated to examine time trends through regression analysis. Additionally, the degrees of freedom used in F-tests and t-tests were used as a metric of sample size to observe if these changed over time. Both linear and quadratic trends were considered. The quadratic term was included to observe if any changes occurred in response to the replication crisis. That is, there may have been no changes from 2000 to 2015, but increases in EDR and ERR after 2015.
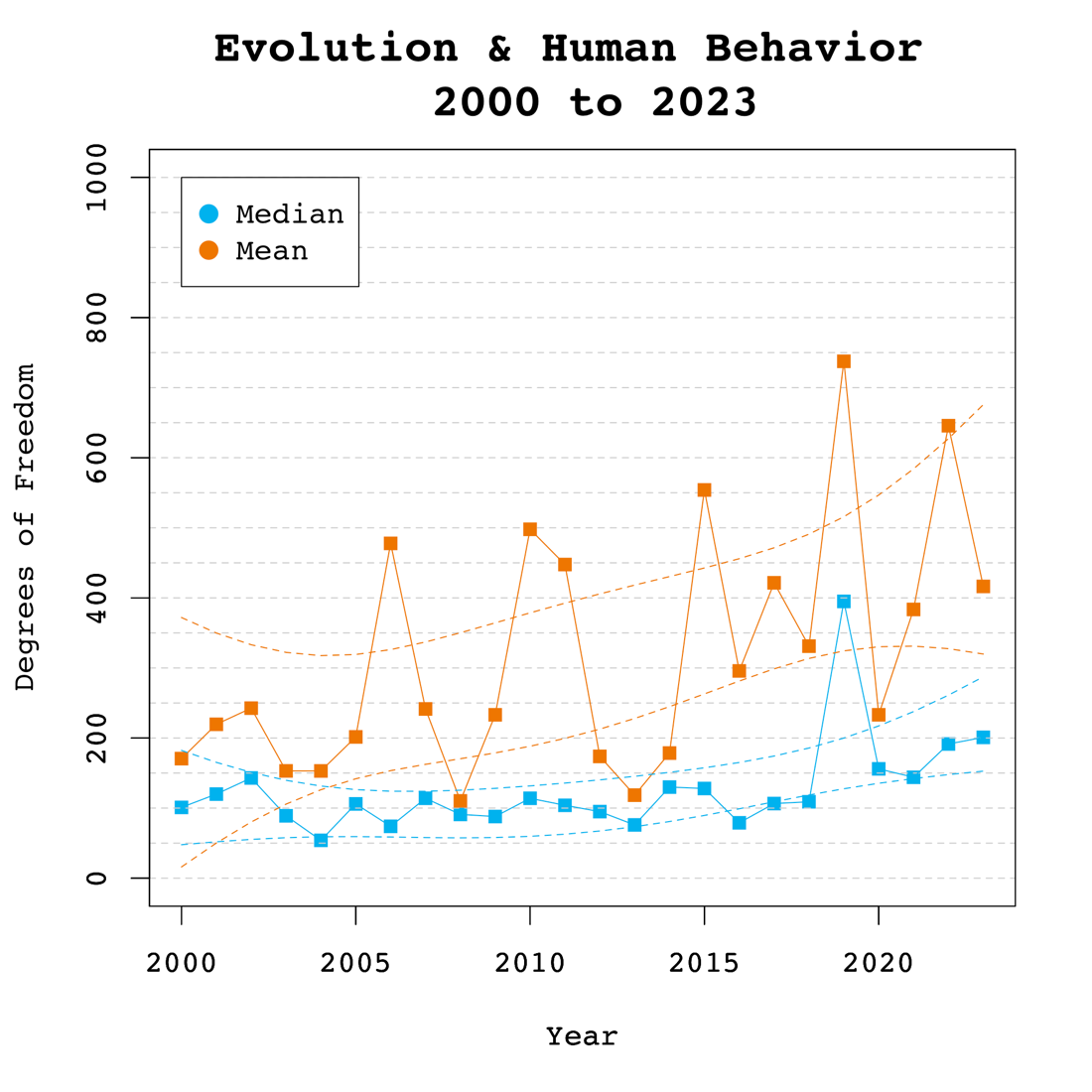
Degrees of Freedom
Figure 2 shows the median and mean degrees of freedom used in F-tests and t-tests reported in Evolutionary Psychology. The mean results are highly variable due to a few studies with extremely large sample sizes. Thus, we focus on the median to examine time trends. The median degrees of freedom over time was 121.54, ranging from 75 to 373. Regression analyses of the median showed a significant linear increase by 6 degrees of freedom per year, b = 6.08, SE = 2.57, p = 0.031. However, there was no evidence that the replication crisis influenced a significant increase in sample sizes as seen by the lack of a significant non-linear trend and a small regression coefficient, b = 0.46, SE = 0.53, p = 0.400.
Figure 2
Observed and Expected Discovery Rates
Figure 3 shows the changes in the ODR and EDR estimates over time. There were no significant linear, b = -0.52 (SE = 0.26 p = 0.063) or non-linear, b = -0.02 (SE = 0.05, p = 0.765) trends observed in the ODR estimate. The regression results for the EDR estimate showed no significant linear, b = -0.66 (SE = 0.64 p = 0.317) or non-linear, b = 0.03 (SE = 0.13 p = 0.847) changes over time. These findings indicate the journal has not increased its publication of non-significant results and continues to report more significant results than one would predict based on the mean power of studies.
Expected Replicability Rates and False Discovery Risks
Figure 4 depicts the false discovery risk (FDR) and the Estimated Replication Rate (ERR). It also shows the Expected Replication Failure rate (EFR = 1 – ERR). A comparison of the EFR with the FDR provides information for the interpretation of replication failures. If the FDR is close to the EFR, many replication failures may be due to false positive results in original studies. In contrast, if the FDR is low, most replication failures will likely be false negative results in underpowered replication studies.
The ERR estimate did not show a significant linear increase over time, b = 0.36, SE = 0.24, p = 0.165. Additionally, no significant non-linear trend was observed, b = -0.03, SE = 0.05, p = 0.523. These findings suggest the increase in sample sizes did not contribute to a statistically significant increase in the power of the published results. These results suggests that replicability of results in this journal has not increased over time and that the results in Figure 1 can be applied to all years.
Figure 4
Visual inspection of Figure 4 depicts the EFR between 30% and 40% and an FDR between 0 and 10%. This suggests that more than half of replication failures are likely to be false negatives in replication studies with the same sample sizes rather than false positive results in the original studies. Studies with large sample sizes and small confidence intervals are needed to distinguish between these two alternative explanations for replication failures.
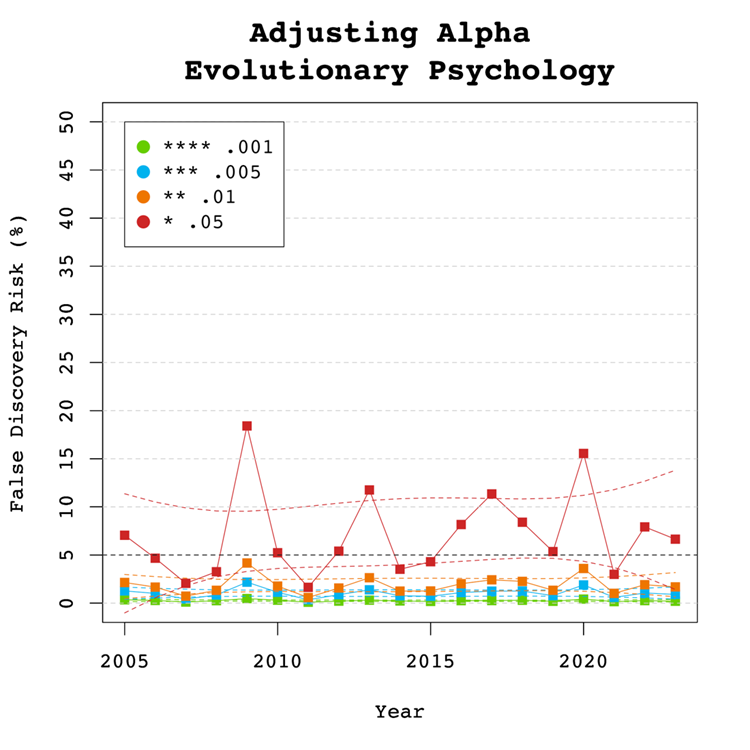
Adjusting Alpha
A simple solution to a crisis of confidence in published results is to adjust the criterion to reject the null-hypothesis. For example, some researchers have proposed to set alpha to .005 to avoid too many false positive results. With z-curve we can calibrate alpha to keep the false discovery risk at an acceptable level without discarding too many true positive results. To do so, we set alpha to .05, .01, .005, and .001 and examined the false discovery risk.
Figure 5
Figure 5 shows that the conventional criterion of p < .05 produces false discovery risks above 5%. The high variability in annual estimates also makes it difficult to provide precise estimates of the FDR. However, adjusting alpha to .01 is sufficient to produce an FDR with tight confidence intervals below 5%. The benefits of reducing alpha further to .005 or .001 are minimal.
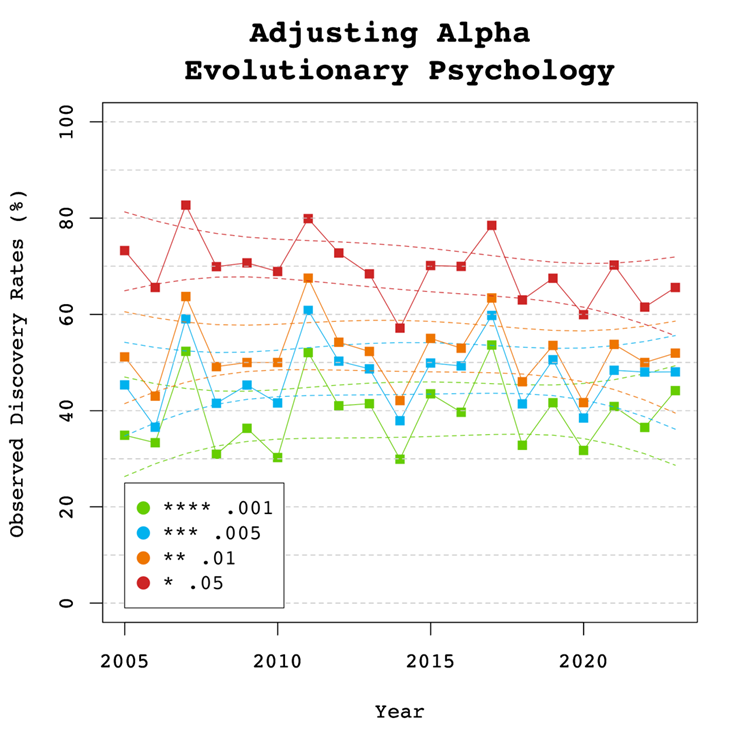
Figure 6
Figure 6 shows the impact of lowering the significance criterion, alpha, on the discovery rate (lower alpha implies fewer significant results). In Evolutionary Psychology lowering alpha to .01 reduces the observed discovery rate by about 20 to 10 percentage points. This implies that 20% of results reported p-values between .05 and .01. These results often have low success rates in actual replication studies (OSC, 2015). Thus, our recommendation is to set alpha to .01 to reduce the false positive risk to 5% and to disregard studies with weak evidence against the null-hypothesis. These studies require actual successful replications with larger samples to provide credible evidence for an evolutionary hypothesis.
There are relatively few studies with p-values between .01 and .005. Thus, more conservative researchers can use alpha = .005 without losing too many additional results.
Limitations
The main limitation of these results is the use of automatically extracted test statistics. This approach cannot distinguish between theoretically important statistical results and other results that are often reported but do not test focal hypotheses (e.g., testing the statistical significance of a manipulation check, reporting a non-significant result for a factor in a complex statistical design that was not expected to produce a significant result).
To examine the influence of automatic extraction on our results, we can compare the results to hand-coding results of over 4,000 hand-coded focal hypotheses in over 40 journals in 2010 and 2020. The ODR was 90% around 2010 and 88% around 2020. Thus, the tendency to report significant results for focal hypothesis tests is even higher than the ODR for all results and there is no indication that this bias has decreased notably over time. The ERR increased a bit from 61% to 67%, but these values are a bit lower than those reported here. Thus, it is possible that focal tests also have lower average power than other tests, but this difference seems to be small. The main finding is that the publishing of non-significant results for focal tests remains an exception in psychology journals and probably also in this journal.
One concern about the publication of our results is that it merely creates a new criterion to game publications. Rather than trying to get p-values below .05, researchers may use tricks to get p-values below .01. However, this argument ignores that it becomes increasingly harder to produce lower p-values with tricks (Simmons et al., 2011). Moreover, z-curve analysis makes it easy to see selection bias for different levels of significance. Thus, a more plausible response to these results is that researchers will increase sample sizes or use other methods to reduce sampling error to increase power.
Conclusion
The replicability report shows that the average power to report a significant result (i.e., a discovery) ranges from 49% to 72% in Evolutionary Psychology. This finding is higher than previous estimates observed in evolutionary psychology journals. However, the confidence intervals are wide and suggest that many published studies remain underpowered. The report did not capture any significant changes over time in the power and replicability as captured by the EDR and the ERR estimates. The false positive risk is modest and can be controlled by setting alpha to .01. Replication attempts of original findings with p-values above .01 should increase sample sizes to produce more conclusive evidence. Lastly, the journal shows clear evidence of selection bias.
There are several ways, the current or future editors of this journal can improve the credibility of results published in this journal. First, results with weak evidence (p-values between .05 and .01) should only be reported as suggestive results that require replication or even request a replication before publication. Second, editors should try to reduce publication bias by prioritizing research questions over results. A well-conducted study with an important question should be published even if the results are not statistically significant. Pre-registration and registered reports can help to reduce publication bias. Editors may also ask for follow-up studies with higher power to follow up on a non-significant result.
Publication bias also implies that point estimates of effect sizes are inflated. It is therefore important to take uncertainty in these estimates into account. Small samples with large sampling errors are usually unable to provide meaningful information about effect sizes and conclusions should be limited to the direction of an effect.
The present results serve as a benchmark for future years to track progress in this journal to ensure trust in research by evolutionary psychologists.
In the 2010s, it became apparent that empirical psychology had a replication problem. When psychologists tested the replicability of 100 results, they found that only 36% of the 97 significant results in original studies could be reproduced (Open Science Collaboration, 2015). In addition, several prominent cases of research fraud further undermined trust in published results. Over the past decade, several proposals were made to improve the credibility of psychology as a science. Replicability Reports aim to improve the credibilty of psychological science by examining the amount of publication bias and the strength of evidence for empirical claims in psychology journals.
The main problem in psychological science is the selective publishing of statistically significant results and the blind trust in statistically significant results as evidence for researchers’ theoretical claims. Unfortunately, psychologists have been unable to self-regulate their behaviour and continue to use unscientific practices to hide evidence that disconfirms their predictions. Moreover, ethical researchers who do not use unscientific practices are at a disadvantage in a game that rewards publishing many articles without concern about these findings’ replicability.
My colleagues and I have developed a statistical tool that can reveal the use of unscientific practices and predict the outcome of replication studies (Brunner & Schimmack, 2021; Bartos & Schimmack, 2022). This method is called z-curve. Z-curve cannot be used to evaluate the credibility of a single study. However, it can provide valuable information about the research practices in a particular research domain.
Replicability-Reports (RR) use z-curve to provide information about psychological journal research and publication practices. This information can aid authors choose journals they want to publish in, provide feedback to journal editors who influence selection bias and replicability of published results, and, most importantly, to readers of these journals.
Evolution & Human Behavior
Evolution & Human Behavior is the official journal of the Human Behaviour and Evolution Society. It is an interdisciplinary journal founded in 1997. The journal publishes articles on human behaviour from an evolutionary perspective. On average, Evolution & Human Behavior publishes about 70 articles a year in 6 annual issues.
Evolutionary psychology has produced both highly robust and questionable results. Robust results have been found for sex differences in behaviors and attitudes related to sexuality. Questionable results have been reported for changes in women’s attitudes and behaviors as a function of hormonal changes throughout their menstrual cycle.
According to Web of Science, the impact factor of Evolution & Human Behaviour ranks 5th in the Behavioural Sciences category and 2nd in the Psychology, Biological category (Clarivate, 2024). The journal has an H-Index of 122 (i.e., 122 articles have received 122 or more citations).
In its lifetime, Evolution & Human Behavior has published over 1,400. Articles published by this journal have an average citation rate of 46.2 citations. So far, the journal has published 2 articles with more than 1,000 citations. The most highly cited article dates back to 2001 in which the authors argued that prestige evolved as a non-coercive social status to enhance the quality of “information goods” acquired via cultural transmission (Henrich & Gil-White, 2001).
The current Editor-in-Chief is Professor Debra Lieberman. The associate editors are Professor Greg Bryant, Professor Aaron Lukaszewski, and Professor David Puts.
Extraction Method
Replication reports are based on automatically extracted test statistics such as F-tests, t-tests, z-tests, and chi2-tests. Additionally, we extracted 95% confidence intervals of odds ratios and regression coefficients. The test statistics were extracted from collected PDF files using a custom R-code. The code relies on the pdftools R package (Ooms, 2024) to render all textboxes from a PDF file into character strings. Once converted the code proceeds to systematically extract the test statistics of interest (Soto & Schimmack, 2024). PDF files identified as editorials, review papers and meta-analyses were excluded. Meta-analyses were excluded to avoid the inclusion of test statistics that were not originally published in Evolution & Human Behavior. Following extraction, the test statistics are converted into absolute z-scores.
Results For All Years
Figure 1 shows a z-curve plot for all articles from 2000-2023 (see Schimmack, 2023, for a detailed description of z-curve plots). The plot is essentially a histogram of all test statistics converted into absolute z-scores (i.e., the direction of an effect is ignored). Z-scores can be interpreted as the strength of evidence against the null hypothesis that there is no statistical relationship between two variables (i.e., the effect size is zero and the expected z-score is zero). A z-curve plot shows the standard criterion of statistical significance (alpha = .05, z = 1.96) as a vertical red dotted line.
Figure 1
Z-curve plots are limited to values less than z = 6. The reason is that values greater than 6 are so extreme that a successful replication is all but certain unless the value is a computational error or based on fraudulent data. The extreme values are still used for the computation of z-curve statistics but omitted from the plot to highlight the shape of the distribution for diagnostic z-scores in the range from 2 to 6. Using the expectation maximization (EM) algorithm, Z-curve estimates the optimal weights for seven components located at z-values of 0, 1, …. 6 to fit the observed statistically significant z-scores. The predicted distribution is shown as a blue curve. Importantly, the model is fitted to the significant z-scores, but the model predicts the distribution of non-significant results. This makes it possible to examine publication bias (i.e., selective publishing of significant results). Using the estimated distribution of non-significant and significant results, z-curve provides an estimate of the expected discovery rate (EDR); that is, the percentage of significant results that were actually obtained without selection for significance. Using Soric’s (1989) formula the EDR is used to estimate the false discovery risk; that is, the maximum number of significant results that are false positives (i.e., the null-hypothesis is true).
Selection for Significance
The extent of selection bias in a journal can be quantified by comparing the Observed Discovery Rate (ODR) of 64%, 95%CI = 63% to 65% with the Expected Discovery Rate (EDR) of 28%, 95%CI = 17%-42%. The ODR is notably higher than the upper limit of the confidence interval for the EDR, indicating statistically significant publication bias. The ODR is also more than double than the point estimate of the EDR, indicating that publication bias is substantial. Thus, there is clear evidence of the common practice to omit reports of non-significant results. The present results may underestimate the severity of the problem because the analysis is based on all statistical results. Selection bias is even more problematic for focal hypothesis tests and the ODR for focal tests in psychology journals is often close to 90%.
Expected Replication Rate
The Expected Replication Rate (ERR) estimates the percentage of studies that would produce a significant result again if exact replications with the same sample size were conducted. A comparison of the ERR with the outcome of actual replication studies shows that the ERR is higher than the actual replication rate (Schimmack, 2020). Several factors can explain this discrepancy, such as the difficulty of conducting exact replication studies. Thus, the ERR is an optimist estimate. A conservative estimate is the EDR. The EDR predicts replication outcomes if significance testing does not favour studies with higher power (larger effects and smaller sampling error) because statistical tricks make it just as likely that studies with low power are published. We suggest using the EDR and ERR in combination to estimate the actual replication rate.
The ERR estimate of 71%, 95%CI = 66% to 77%, suggests that the majority of results should produce a statistically significant, p < .05, result again in exact replication studies. However, the EDR of 28% implies that there is considerable uncertainty about the actual replication rate for studies in this journal and that the success rate can be anywhere between 28% and 71%.
False Positive Risk
The replication crisis has led to concerns that many or even most published results are false positives (i.e., the true effect size is zero). Using Soric’s formula (1989), the maximum false discovery rate can be calculated based on the EDR.
The EDR of 28% implies a False Discovery Risk (FDR) of 14%, 95%CI = 7% to 26%, but the 95%CI of the FDR allows for up to 26% false positive results. This estimate contradicts claims that most published results are false (Ioannidis, 2005), but the results also create uncertainty about the credibility of results with statistically significant results, if up to 1 out of 4 results can be false positives.
Changes Over Time
One advantage of automatically extracted test-statistics is that the large number of test statistics makes it possible to examine changes in publication practices over time. We were particularly interested in changes in response to awareness about the replication crisis in recent years.
Z-curve plots for every publication year were calculated to examine time trends through regression analysis. Additionally, the degrees of freedom used in F-tests and t-tests were used as a metric of sample size to observe if these changed over time. Both linear and quadratic trends were considered. The quadratic term was included to observe if any changes occurred in response to the replication crisis. That is, there may have been no changes from 2000 to 2015, but increases in EDR and ERR after 2015.
Degrees of Freedom
Figure 2 shows the median and mean degrees of freedom used in F-tests and t-tests reported in Evolution & Human Behavior. The mean results are highly variable due to a few studies with extremely large sampel sizes. Thus, we focus on the median to examine time trends. The median degrees of freedom over time was 107.75, ranging from 54 to 395. Regression analyses of the median showed a significant linear increase by 4 to 5 degrees of freedom per year, b = 4.57, SE = 1.69, p = 0.013. However, there was no evidence that the replication crisis influenced a significant increase in sample sizes as seen by the lack of a significant non-linear trend and a small regression coefficient, b = 0.50, SE = 0.27, p = 0.082.
Figure 2
Observed and Expected Discovery Rates
Figure 3 shows the changes in the ODR and EDR estimates over time. There were no significant linear, b = 0.06 (SE = 0.17 p = 0.748) or non-linear, b = -0.02 (SE = 0.03, p = 0.435) trends observed in the ODR estimate. The regression results for the EDR estimate showed no significant linear, b = 0.75 (SE = 0.51 p = 0.153) or non-linear, b = 0.04 (SE = 0.08 p = 0.630) changes over time. These findings indicate the journal has not increased its publication of non-significant results even though selection bias is heavily present. Furthermore, the lack of changes to the EDR suggests that many studies continue to be statistically underpowered to measure the effect sizes of interest.
Figure 3
Expected Replicability Rates and False Discovery Risks
Figure 4 depicts the false discovery risk (FDR) and the Estimated Replication Rate (ERR). It also shows the Expected Replication Failure rate (EFR = 1 – ERR). A comparison of the EFR with the FDR provides information for the interpretation of replication failures. If the FDR is close to the EFR, many replication failures may be due to false positive results in original studies. In contrast, if the FDR is low, most replication failures will likely be false negative results in underpowered replication studies.
The ERR estimate showed a significant linear increase over time, b = 0.61, SE = 0.26, p = 0.031. No significant non-linear trend was observed, b = 0.07, SE = 0.4, p = 0.127. These findings are consistent with the observed significant increase in sample sizes as the reduction in sampling error increases the likelihood that an effect will replicate.
The significant increase in the ERR without a significant increase in the EDR is partially explained by the higher power of the test for the ERR that can be estimated with higher precision. However, it is also possible that the ERR increases more because there is an increase in the heterogeneity of studies. That is, the number of studies with low power has remained constant, but the number of studies with high power has increased. This would result in a bigger increase in the ERR than the EDR.
Figure 4
Visual inspection of Figure 4 depicts the EFR higher than the FDR over time, suggesting that replication failures of studies in Evolution & Human Behavior are more likely to be false negatives rather than false positives. Up to 30% of the published results might not be replicable, and up to 50% of those results may be false positives.
It is noteworthy that the gap between the EFR and the FDR appears to be narrowing over time. This trend is supported by the significant increase in the Estimated Replicability Rate (ERR), where EFR is defined as 1 – ERR. Meanwhile, the Expected Discovery Rate (EDR) has remained constant, indicating that the FDR has also remained unchanged, given that the FDR is derived from a transformation of the EDR. The findings suggest that while original results have become more likely to replicate, the probability that replication failures are false positives remains unchanged.
Adjusting Alpha
A simple solution to a crisis of confidence in published results is to adjust the criterion to reject the null-hypothesis. For example, some researchers have proposed to set alpha to .005 to avoid too many false positive results. With z-curve we can calibrate alpha to keep the false discovery risk at an acceptable level without discarding too many true positive results. To do so, we set alpha to .05, .01, .005, and .001 and examined the false discovery risk.
Figure 5
Figure 5 shows that the conventional criterion of p < .05 produces false discovery risks above 5%. The high variability in annual estimates also makes it difficult to provide precise estimates of the FDR. However, adjusting alpha to .01 is sufficient to produce an FDR with tight confidence intervals below 5%. The benefits of reducing alpha further to .005 or .001 are minimal.
Figure 6
Figure 6 shows the impact of lowering the significance criterion, alpha, on the discovery rate (lower alpha implies fewer significant results). In Evolution & Human Behavior lowering alpha to .01 reduces the observed discovery rate by about 20 percentage points. This implies that 20% of results reported p-values between .05 and .01. These results often have low success rates in actual replication studies (OSC, 2015). Thus, our recommendation is to set alpha to .01 to reduce the false positive risk to 5% and to disregard studies with weak evidence against the null-hypothesis. These studies require actual successful replications with larger samples to provide credible evidence for an evolutionary hypothesis.
There are relatively few studies with p-values between .01 and .005. Thus, more conservative researchers can use alpha = .005 without losing too many additional results.
Limitations
The main limitation of these results is the use of automatically extracted test statistics. This approach cannot distinguish between theoretically important statistical results and other results that are often reported but do not test focal hypotheses (e.g., testing the statistical significance of a manipulation check, reporting a non-significant result for a factor in a complex statistical design that was not expected to produce a significant result).
To examine the influence of automatic extraction on our results, we can compare the results to hand-coding results of over 4,000 hand-coded focal hypotheses in over 40 journals in 2010 and 2020. The ODR was 90% around 2010 and 88% around 2020. Thus, the tendency to report significant results for focal hypothesis tests is even higher than the ODR for all results and there is no indication that this bias has decreased notably over time. The ERR increased a bit from 61% to 67%, but these values are a bit lower than those reported here. Thus, it is possible that focal tests also have lower average power than other tests, but this difference seems to be small. The main finding is that publishing of non-significant results for focal tests remains an exception in psychology journals and probably also in this journal.
One concern about the publication of our results is that it merely creates a new criterion to game publications. Rather than trying to get p-values below .05, researchers may use tricks to get p-values below .01. However, this argument ignores that it becomes increasingly harder to produce lower p-values with tricks (Simmons et al., 2011). Moreover, z-curve analysis makes it easy to see selection bias for different levels of significance. Thus, a more plausible response to these results is that researchers will increase sample sizes or use other methods to reduce sampling error to increase power.
Conclusion
The replicability report for Evolution & Human Behavior suggests that the power to obtain a significant result to report a significant result (i.e., a discovery) ranges from 28% to 71%. This finding suggests that many studies are underpowered and require luck to get a significant result. The false positive risk is modest and can be controlled by setting alpha to .01. Replication attempts of original findings with p-values above .01 should increase sample sizes to produce more conclusive evidence. The journal shows clear evidence of selection bias.
There are several ways, the current or future editors of this journal can improve credibility of results published in this journal. First, results with weak evidence (p-values between .05 and .01) should only be reported as suggestive results that require replication or even request a replication before publication. Second, editors should try to reduce publication bias by prioritizing research questions over results. A well-conducted study with an important question should be published even if the results are not statistically significant. Pre-registration and registered reports can help to reduce publication bias. Editors may also ask for follow-up studies with higher power to follow up on a non-significant result.
Publication bias also implies that point estimates of effect sizes are inflated. It is therefore important to take uncertainty in this estimates into account. Small samples with large sampling error are usually unable to provide meaningful information about effect sizes and conclusions should be limited to the direct of an effect.
The present results serve as a benchmark for future years to track progress in this journal to ensure trust in research by evolutionary psychologists.
One of the bigger stories in Psychological (WannaBe) Science was the forced resignation of Klaus Fiedler from his post as editor-in-chief at the prestigious journal “Perspectives on Psychological Science.” In response to his humiliating eviction, Klaus Fiedler declared “I am the victim.”
In an interview, he claimed that the his actions that led to the vote of no confidence by the Board of Directors of the Association of Psychological Science (APS) were “completely fair, respectful, and in line with all journal standards.” In contrast, the Board of Directors listed several violations of editorial policies and standards.
The APS board listed the following complaints.
accept an article criticizing the original article based on three reviews that were also critical of the original article and did not reflect a representative range of views on the topic of the original article;
invite the three reviewers who reviewed the critique favorably to themselves submit commentaries on the critique;
accept those commentaries without submitting them to peer review; and,
inform the author of the original article that his invited reply would also not be sent out for peer review. The EIC then sent that reply to be reviewed by the author of the critical article to solicit further comments.
As bystanders, we have to decide whether these accusations by several board members are accurate or whether these are trumped up charges that misrepresent the facts and Fiedler is an innocent victim. Even without specific knowledge about this incidence and the people involved, bystanders are probably forming an impression about Fiedler and his accusers. First, it is a natural human response to avoid embarrassment after a public humiliation. Thus, Fiedler’s claims of no wrong-doing have to be taken with a grain of salt. On the other hand, APS board members could also have motives to distort the facts, although they are less obvious.
To understand the APS board’s responses to Fiedler’s actions, it is necessary to take into account that Fiedler’s questionable editorial decisions affected Steven Roberts, an African American scholar, who had published an article about systemic racism in psychology in the same journal under a previous editor (Roberts et al., 2020). Fiedler’s decision to invite three White critical reviewers to submit their criticisms as additional commentaries was perceived by Roberts’ as racially biased. When he made his concerns public, over 1,000 bystanders agreed and signed an open letter asking for Fiedler’s resignation. In contrast, an opposing open letter received much fewer signatures. While some of the signatures on both sides have their own biases because they know Fiedler as a friend or foe, most of the signatures did not know anything about Fiedler, but reacted to Roberts’ description of his treatment. Fiedler never denied that this account was an accurate description of events. He merely claims that his actions were “completely fair, respectful, and in line with journal standards.” Yet, nobody else has supported Fiedler’s claim that it is entirely fair and acceptable to invite three White-ish reviewers to submit their reviews as commentaries and to accept these commentaries without peer-review.
I conducted an informal and unrepresentative poll that confirmed my belief that inviting reviewers to submit a commentary is rare.
What is even more questionable is that all the three reviews support with Hommel’s critical commentary of Robert’s target article. It is not clear why reviews of a commentary were needed to be published as additional commentaries if these reviews agreed with Hommel’s commentary. The main point of reviews is to determine whether a submission is suitable for publication. If Hommel’s commentary was so deficient that all three reviewers were able to make additional points that were missing from his commentary, his submission should have been rejected with or without a chance of resubmission. In short, Fiedler’s actions were highly unusual and questionable, even if they were not racially motivated.
Even if Fiedler thought that his actions were fair and unbiased when he was acting, the response by Roberts, over 1,000 signatories, and the APS board of directors could have made him realize that others viewed his behaviors differently and maybe recognize that his actions were not as fair as he assumed. He could even have apologized for his actions or at least the harm they caused however unintentional. Yet, he chose to blame others for his resignation – “I am the victim”. I believe that Fiedler is indeed a victim, but not in the way he perceives the situation. Rather than blaming others for his disgraceful resignation, he should blame himself. To support my argument, I will propose a mediation model and provide a case-study of Fiedler’s response to criticism as empirical support.
From Arrogance to Humiliation
A well-known biblical proverb states that arrogance is the cause of humiliation (“Hochmut kommt vor dem Fall). I am proposing a median model of this assumed relationship. Fiedler is very familiar with mediation models (Fiedler, Harris, & Schott, 2018). A mediation model is basically a causal chain. I propose that arrogance may lead to humiliation because it breeds ignorance. Figure 1 shows ignorance as the mediator. That is, arrogance makes it more likely that somebody is discounting valid criticism. In turn, individuals may act in ways that are not adaptive or socially acceptable. This leads to either personal harm or a damage to a person’s reputation. Arrogance and ignorance will also shape the response to social rejection. Rather than making an internal attribution that elicits feelings of embarrassed, an emotion that repairs social relationships, arrogant and ignorant individuals will make an external attribution (blame) that leads to anger, an emotion that further harms social relationships.
Fiedler’s claim that his actions were fair and that he is the victim makes it clear that he made an external attribution. He blames others, but the real problem is that Fiedler is unable to recognize when he is wrong and criticism is justified. This attributional bias is well known in psychology and called a self-serving attribution. To enhance one’s self-esteem, some individuals attribute successes to their own abilities and blame others for their failures. I present a case-study of Fiedler’s response to the replication crisis as evidence that his arrogance blinds him to valid criticism.
Replicability and Regression to the Mean
In 2011, social psychology was faced with emerging evidence that many findings, including fundamental findings like unconscious priming, cannot be replicated. A major replication project found that only 25% of social psychology studies produced a significant result again in an attempt to replicate the original study. These findings have triggered numerous explanations for the low replication rate in social psychology (OSC, 2015; Schimmack, 2020; Wiggins & Christopherson, 2019).
Explanations for the replication crisis in social psychology can be divided into two camps. One camp believes that replication failures reveal major problems with the studies that social psychologists conducted for decades. The other camp argues that replication failures are a normal part of science and that published results can be trusted even if they failed to replicate in recent replication studies. A notable difference between these two camps is that defenders of the credibility of social psychology tend to be established and prominent figures in social psychology. As a result, they also tend to be old, men, and White. However, these surface characteristics are only correlated with views about the replication crisis. The main causal factor is likely to be the threat to eminent social psychologists concerns about their reputation and legacy. Rather than becoming famous names along with Allport, their names may be used to warn future generations about the dark days when social psychologists invented theories based on unreliable results.
Consistent with the stereotype of old, White, male social psychologists, Fiedler has become an outspoken critic of the replication movement and tried to normalize replication failures. After the credibility of psychology was challenged in news outlets, the board of the German Psychological Society (DGPs) issued a reassuring (whitewashing) statement that tried to reassure the public that psychology is a science. The web page has been deleted, but a copy of the statement is preserved here (Stellungnahme). This official statement triggered outrage among some members and DGPs created a discussion forum (also deleted now). Fiedler participated in this discussion with the claim that replication failures can be explained by a statistical phenomenon known as regression to the mean. He repeated this argument in an email with a reporter that was shared by Mickey Inzlicht in the International Social Cognition Network group (ISCON) on Facebook. This post elicited many commentaries that were mostly critical of Fiedler’s attempt to cast doubt about the scientific validity of the replication project. The ISCON post and the comments were deleted (when Mickey left Facebook), but they were preserved in my Google inbox. Here is the post and the most notable comments.
Michael Inzlicht shares Fiedler’s response to the outcome of the Reproducibility Project that only 25% of significant results in social psychology could be replicated (i.e., produced a p-value below .05).
August 31 at 9:46am
Klaus Fiedler has granted me permission to share a letter that he wrote to a reported (Bruce Bowers) in response to the replication project. This letter contains Klaus’s words only and the only part I edited was to remove his phone number. I thought this would be of interest to the group.
Dear Bruce:
Thanks for your email. You can call me tomorrow but I guess what I have to say is summarized in this email.
Before I try to tell it like it is, I ask you to please attend to my arguments, not just the final evaluations, which may appear unbalanced. So if you want to include my statement in your article, maybe along with my name, I would be happy not to detach my evaluative judgment from the arguments that in my opinion inevitably lead to my critical evaluation.
First of all I want to make it clear that I have been a big fan of properly conducted replication and validation studies for many years – long before the current hype of what one might call a shallow replication research program. Please note also that one of my own studies has been included in the present replication project; the original findings have been borne out more clearly than in the original study. So there is no self-referent motive for me to be overly critical.
However, I have to say that I am more than disappointed by the present report. In my view, such an expensive, time-consuming, and resource-intensive replication study, which can be expected to receive so much attention and to have such a strong impact on the field and on its public image, should live up (at least) to the same standards of scientific scrutiny as the studies that it evaluates. I’m afraid this is not the case, for the following reasons …
The rationale is to plot the effect size of replication results as a function of original results. Such a plot is necessarily subject to regression toward the mean. On a-priori-grounds, to the extent that the reliability of the original results is less than perfect, it can be expected that replication studies regress toward weaker effect sizes. This is very common knowledge. In a scholarly article one would try to compare the obtained effects to what can be expected from regression alone. The rule is simple and straightforward. Multiply the effect size of the original study (as a deviation score) with the reliability of the original test, and you get the expected replication results (in deviation scores) – as expected from regression alone. The informative question is to what extent the obtained results are weaker than the to-be-expected regressive results.
To be sure, the article’s muteness regarding regression is related to the fact that the reliability was not assessed. This is a huge source of weakness. It has been shown (in a nice recent article by Stanley & Spence, 2014, in PPS) that measurement error and sampling error alone will greatly reduce the replicability of empirical results, even when the hypothesis is completely correct. In order not to be fooled by statistical data, it is therefore of utmost importance to control for measurement error and sampling error. This is the lesson we took from Frank Schmidt (2010). It is also very common wisdom.
The failure to assess the reliability of the dependent measures greatly reduces the interpretation of the results. Some studies may use single measures to assess an effect whereas others may use multiple measures and thereby enhance the reliability, according to a principle well-known since Spearman & Brown. Thus, some of the replication failures may simply reflect the naïve reliance on single-item dependent measures. This is of course a weakness of the original studies, but a weakness different from non-replicability of the theoretically important effect. Indeed, contrary to the notion that researchers perfectly exploit their degrees of freedom and always come up with results that overestimate their true effect size, they often make naïve mistakes.
By the way, this failure to control for reliability might explain the apparent replication advantage of cognitive over social psychology. Social psychologists may simply often rely on singular measure, whereas cognitive psychologists use multi-trial designs resulting in much higher reliability.
The failure to consider reliability refers to the dependent measure. A similar failure to systematically include manipulation checks renders the independent variables equivocal. The so-called Duhem-Quine problem refers to the unwarranted assumption that some experimental manipulation can be equated with the theoretical variable. An independent variable can be operationalized in multiple ways. A manipulation that worked a few years ago need to work now, simply because no manipulation provides a plain manipulation of the theoretical variable proper. It is therefore essential to include a manipulation check, to make sure that the very premise of a study is met, namely a successful manipulation of the theoretical variable. Simply running the same operational procedure as years before is not sufficient, logically.
Last but not least, the sampling rule that underlies the selection of the 100 studies strikes me as hard to tolerate. Replication teams could select their studies from the first 20 articles published in a journal in a year (if I correctly understand this sentence). What might have motivated the replication teams’ choices? Could this procedure be sensitive to their attitude towards particular authors or their research? Could they have selected simply studies with a single dependent measure (implying low reliability)? – I do not want to be too suspicious here but, given the costs of the replication project and the human resources, does this sampling procedure represent the kind of high-quality science the whole project is striving for?
Across all replication studies, power is presupposed to be a pure function of the size of participant samples. The notion of a truly representative design in which tasks and stimuli and context conditions and a number of other boundary conditions are taken into account is not even mentioned (cf. Westfall & Judd).
Comments
Brent W. Roberts, 10:02am Sep 4 This comment just killed me “What might have motivated the replication teams’ choices? Could this procedure be sensitive to Their attitude towards Particular authors or Their research?” Once again, we have an eminent, high powered scientist impugning the integrity of, in this case, close to 300, mostly young researchers. What a great example to set.
Daniel Lakens, 12:32pm Sep 4 I think the regression to the mean comment just means: if you start from an extreme initial observation, there will be regression to the mean.He will agree there is publication bias – but just argues the reduction in effect sizes is nothing unexpected – we all agree with that, I think. I find his other points less convincing – there is data about researchers expectencies about whether a study would replicate. Don’t blabla, look at data. The problem with moderators is not big – original researchers OKéd the studies – if they can not think of moderators, we cannot be blamed for not including others checks. Finally, it looks like our power was good, if you examine the p-curve. Not in line with the idea we messed up. I wonder why, with all commentaries I’ve seen, no one takes the effort to pre-register their criticisms, and then just look at the studies and data, and let us know how much it really matters?
Felix Cheung, ,2:11pm Sep 4 I don’t understand why the regression to mean cannot be understood in a more positive light when the “mean” in regression to the mean refers to the effect sizes of interests. If that’s the case, then regressing to mean would mean that we are providing more accurate estimates of the effect sizes.
Joachim Vandekerckhove, 2:15pm Aug 31 The dismissive “regression to the mean” argument either simply takes publication bias as given or assumes that all effect sizes are truly zero. Either of those assumptions make for an interesting message to broadcast, I feel.
Michael Inzlicht, 2:54pm Aug 31 I think we all agree with this, Jeff, but as Simine suggested, if the study in question is a product of all the multifarious biases we’ve discussed and cannot be replicated (in an honest attempt), what basis do we have to change our beliefs at all? To me the RP–plus lots of other stuff that has come to light in the past few years–make me doubt the evidentiary basis of many findings, and by extension, many theories/models. Theories are based on data…and it turns out that data might not be as solid as we thought.
Jeff Sherman, 2:58pm Aug 31 Michael, I don’t disagree. I think RP–plus was an important endeavor. I am sympathetic to Klaus’s lament that the operationalizations of the constructs weren’t directly validated in the replications.
Uli Schimmack, 11:15am Sep 1 This is another example that many psychologists are still trying to maintain the illusion that psychology doesn’t have a replicabiltiy problem. A recurrent argument is that human behavior is complex and influenced by many factors that will produce variation in results across seemingly similar studies. Even if this were true, it would not explain why all original studies find significant effects. If moderators can make effects appear or disappear, there would be an equal number of non-significant results in original and replication studies. If psychologists were really serious about moderating factors, non-significant results would be highly important to understand under what conditions an effect does not occur. The publication of only significant results in psychology (since 1959 Sterling) shows that psychologists are not really serious about moderating factors and that moderators are only invoked post-hoc to explain away failed replications of significant results. Just like Klaus Fiedler’s illusory regression to the mean, these arguments are hollow and only reveal the motivated biases of their proponents to deny a fundamental problem in the way psychologists collect, analyze, and report their research findings. If a 25% replication rate for social psychology is not enough to declare a crisis then psychology is really in a crisis and psychologists provide the best evidence for the validity of Freud’s theory of repression. Has Daniel Kahneman commented on the reproducibility-project results?
Garriy Shteynberg, 10:33pm Sep 7 Again, I agree that there is publication bias and its importance even in a world where all H0 are false (as you show in your last comment). Now, do you see that in that very world, regression to the mean will still occur? Also, in the spirit of the dialogue, try to refrain from claiming what others do not know. I am sure you realize that making such truth claims on very little data is at best severely underpowered.
Uli Schimmack, 10:38pm Sep 7 Garriy Shteynberg Sorry, but I always said that regression to the mean occurs when there is selection bias, but without selection bias it will not occur. That is really the issue here and I am not sure what point you are trying to make. We agree that studies were selected and that low replication rate is a result of this selection and regression to the mean. If you have any other point to make, you have to make it clearer.
Malte Elson, 3:38am Sep 8 Garriy Shteynberg would you maybe try me instead? I followed your example of the perfect discipline with great predictions and without publication bias. What I haven’t figured out is what would cause regression to the mean to only occur in one direction (decreased effect size at replication level). The predictions are equally great at both levels since they are exactly the same. Why would antecedent effect sizes in publications be systematically larger if there was no selection at that level?
Marc Halusic, 12:53pm Sep 1 Even if untold moderators affect the replicability of a study that describes a real effect, it would follow that any researcher who cannot specify the conditions under which an effect will replicate does not understand that effect well enough to interpret it in the discussion section.
Maxim Milyavsky, 11:16am Sep 3 I am not sure whether Klaus meant that regression to mean by itself can explain the failure of replication or regression to mean given a selection bias. I think that without selection bias regression to mean cannot count as an alternative explanation.If it could, every subsequent experiment would yield a smaller effect than the previous one, which sounds like absurd.I assume that Klaus knows that. So, probably he admits that there was a selection bias. Maybe he just wanted to say – it’s nobody’s fault. Nobody played with data, people were just publishing effects that “worked”. Yet, what is sounds puzzling to me is that he does not see any problem in this process.
– Mickey shared some of the responses with Klaus and posted Klaus’s responses to the comment. Several commentators tried to defend Klaus by stating that he would agree with the claim that selection for significance is necessary to see an overall decrease in effect sizes. However, Klaus Fiedler doubles down on the claim that this is not necessary even though the implication would be that effect sizes shrink every time a study is replicated which is “absurd” (Maxim Milyavsk), although even this absurd claim has been made (Schooler, 2011).
Michael Inzlicht, September 2 at 1:08pm
More from Klaus Fiedler. He has asked me to post a response to a sample of the replies I sent him. Again, this is unedited, directly copying and pasting from a note Klaus sent me. (Also not sure if I should post it here or the other, much longer, conversation).
Having read the echo to my earlier comment on the Nosek report, I got the feeling that I should add some more clarifying remarks.
(1) With respect to my complaints about the complete failure to take regressiveness into account, some folks seem to suggest that this problem can be handled simply by increasing the power of the replication study and that power is a sole function of N, the number of participants. Both beliefs are mistaken. Statistical power is not just a function of N, but also depends on treating stimuli as a random factor (cf. recent papers by Westfall & Judd). Power is 1 minus β, the probability that a theoretical hypothesis, which is true, will be actually borne out in a study. This probability not only depends on N. It also depends on the appropriateness of selected stimuli, task parameters, instructions, boundary conditions etc. Even with 1000 participant per cell, measurement and sampling error can be high, for instance, when a test includes weakly selected items, or not enough items. It is a cardinal mistake to reduce power to N.
(2) The only necessary and sufficient condition for regression (to the mean or toward less pronounced values) is a correlation less than zero. This was nicely explained and proven by Furby (1973). We all “learned” that lesson in the first semester, but regression remains a counter-intuitive thing. When you plot effect sizes in the replication studies as a function of effect sizes in the original studies and the correlation between corresponding pairs is < 1, then there will be regression. The replication findings will be weaker than the original ones. One can refrain from assuming that the original findings have been over-estimations. One might represent the data the other way around, plotting the original results as a function of given effects in the replication studies, and one will also see regression. (Note in this connection that Etz’ Bayesian analysis of the replication project also identified quite a few replications that were “too strong”). For a nice illustration of this puzzling phenomenon, you may also want to read the Erev, Wallsten & Budescu (1994) paper, which shows both overconfidence and underconfidence in the same data array.
(3) I’m not saying that regression is easy to understand intuitively (Galton took many years to solve the puzzle). The very fact that people are easily fooled by regression is the reason why controlling for expected regression effects is standard in the kind of research published here. It is almost a prototypical example of what Don Campbell (1996) had in mind when he tried to warn the community from drawing erroneous inferences.
(4) I hope it is needless to repeat that controlling for the reliability of the original studies is essential, because variation in reliability affects the degree of regressiveness. It is particularly important to avoid premature interpretations of seemingly different replication results (e.g., for cognitive and social psychology) that could reflect nothing but unequal reliability.
(5) My critical remark that the replication studies did not include manipulation checks was also met with some spontaneous defensive reactions. Please note that the goal to run so-called “exact” replications (I refrain from discussing this notion here) does not prevent replication researchers from including additional groups supposed to estimate the effectiveness of a manipulation under the current conditions. (Needless to add that a manipulation check must be more than a compliant repetition of the instruction).
(6) Most importantly perhaps, I would like to reinforce my sincere opinion that methodological and ethical norms have to be applied to such an expensive, pretentious and potentially very consequential project even more carefully and strictly than they are applied to ordinary studies. Hardly any one of the 100 target studies could have a similarly strong impact, and call for a similar degree of responsibility, as the present replication project.
Kind regards, Klaus
This response elicited an even more heated discussion. Unfortunately, only some of these comments were mailed to my inbox. I must have made a very negative comment about Klaus Fiedler that elicited a response by Jeff Sherman, the moderator of the group. Eventually, I was banned from the group and created the Psychological Methods Discussion Group. that became the main group for critical discussion of psychological science.
Uli Schimmack, 2:36pm Sep 2 Jeff Sherman The comparison extends to the (in German) official statement regarding the results of the OSF-replication project. It does not mention that publication bias is at least a factor that contributed to the outcome or mentions any initiatives to improve the way psychologists conduct their research. It would be ironic if a social psychologists objects to a comparison that is based on general principles of social behavior. I think I don’t have to mention that the United States of America pride themselves on freedom of expression that even allows Nazis to publish their propaganda which German law does not allow. In contrast, censorship was used by socialist Germany to maintain in power. So, please feel free to censor my post. and send me into Psychological Method exile.
Jeff Sherman, 2:49pm Sep 2 Uli Schimmack I am not censoring the ideas you wish to express. I am saying that opinions expressed on this page must be expressed respectfully. Calling this a freedom of speech issue is a red herring. Ironic, too, given that one impact of trolling and bullying is to cause others to self-censor. I am working on a policy statement. If you find the burden unbearable, you can choose to not participate.
Uli Schimmack, 2:53pm Sep 2 Jeff Sherman Klaus is not even part of this. So, how am I bullying him? Plus, I don’t think Klaus is easily intimidated by my comment. And, as a social psychologist how do you explain that Klaus doubled down when every comment pointed out that he ignores the fact that regression to the mean can only produce a decrease in the average if the original sample was selected to be above the mean?
This discussion led to a letter to the DGPs board by Moritz Heene that expressed outrage about the whitewashing of the replication results in their official statement.
From: Moritz Heene To: Andrea Abele-Brehm, Mario Gollwitzer, & Fritz Strack Subject: DGPS-Stellungnahme zu Replikationsprojekt Date: Wed, 02 Sep 2015
[I suggest to copy and past the German text into DeepL, a powerful translation program]
Sehr geehrte Mitglieder des Vorstandes der DGPS,
Zunächst Dank an Sie für das Bemühen, die Ergebnisse des OSF-Replikationsprojektes der Öffentlichkeit klarer zu machen. Angesichts dieser Stellungnahme der DGPS möchte ich jedoch persönlich meinen Widerspruch dazu ausdrücken, da ich als Mitglied der DGPS durch diese Stellungnahmen in keiner Weise eine ausgewogene Sichtweise ausgedrückt sehe, sie im Gegenteil als sehr einseitig empfinde. Ich sehe diese Stellungnahme vielmehr als einen Euphemismus der Replikationsproblematik in der Psychologie an, um es milde auszudrücken, bin davon enttäuscht und hatte mir mehr erwartet. Meine Kritikpunkte an ihrer Stellungnahme:
1. Zum Argument 68% der Studien seien repliziert worden: Der Test dazu prüft, ob der replizierte Effekte im Konfidenzintervall um den originalen Effekt liegt, ob diese also signifikant voneinander verschieden sind, so die Logik der Autoren. Lassen wir mal großzügig beiseite, dass dies kein Test über die Differenz der Effektgrößen ist, da das Konfidenzintervall um den originalen beobachteten Effekt gelegt wird, nicht um die Differenz. Wesentlicher ist, dass dies ein schlechtes Maß für Replizierbarkeit ist, denn die originalen Effekte sind upward biased (sieht man in dem originalen paper auch), und vergessen wir den publication bias nicht (siehe density distribution der p-Werte im originalen paper). Anzunehmen, dass die originalen Effektgrößen die Populationseffektgrößen sind, ist wirklich eine heroische Annahme, gerade angesichts des positiven bias der originalen Effekte. Nebenbei: In einem offenen Brief von Klaus Fiedler auf Facebook dazu publiziert wurde, wird argumentiert, die Regression zur Mitte habe die im Schnitt geringeren Effektgrößen im OSF-Projekt produziert, könne diesen Effekt erklären. Dieses Argument mag teilweise stimmen, impliziert aber, dass die originalen Effekte extrem (also biased, weil selektiv publiziert wurde) waren, denn genau das ist ja das Charakteristikum dieses Regressionseffektes: Ergebnisse, die in einer ersten Messung extrem waren, “tendieren” in einer zweiten Messung zum Mittelwert. Die Tatsache, dass die originalen Effekte einen deutlichen positiven bias aufweisen, wird in Ihrer Stellungnahme ignoriert, bzw. gar nicht erst erwähnt.
Das Argument der 68%-Replizierbarkeit wird im übrigen auch vom Hauptautor in Antwort auf ihre Stellungnahme ganz offen in ähnlicher Weise kritisiert:
Kurzum: Sich genau diese Statistik als Unterstützung dafür aus der OSF-Studie herauszusuchen, um der Öffentlichkeit zu erklären, dass in der Psychologie im Grunde alles in Ordnung ist, sehe ich als “cherry picking” von Ergebnissen an.
2. Das Moderatoren-Argument ist letztlich unhaltbar, denn erstens > wurde dies insbesondere im OSF-Projekt 3 intensiv getestet. Das Ergebnis ist u.a. hier zusammengefasst:
Siehe u.a.: In Many Labs 1 and Many Labs 3 (which I reviewed here), different labs followed standardized replication protocols for a series of experiments. In principle, different experimenters, different lab settings, and different subject populations could have led to differences between lab sites. But in analyses of heterogeneity across sites, that was not the result. In ML1, some of the very large and obvious effects (like anchoring) varied a bit in just how large they were (from “kinda big” to “holy shit”). Across both projects, more modest effects were quite consistent. Nowhere was there evidence that interesting effects wink in and out of detectability for substantive reasons linked to sample or setting. Länger findet man es hier zusammengefasst:
The authors put the interpretation so well that I’ll quote them at length here [emphasis added]: A common explanation for the challenges of replicating results across samples and settings is that there are many seen and unseen moderators that qualify the detectability of effects (Cesario, 2014). As such, when differences are observed across study administrations, it is easy to default to the assumption that it must be due to features differing between the samples and settings. Besides time of semester, we tested whether the site of data collection, and the order of administration during the study session moderated the effects. None of these had a substantial impact on any of the investigated effects. This observation is consistent with the first “Many Labs” study (Klein et al., 2014) and is the focus of the second (Klein et al., 2015). The present study provides further evidence against sample and setting differences being a default explanation for variation in replicability. That is not to deny that such variation occurs, just that direct evidence for a given effect is needed to demonstrate that it is a viable explanation. Zweitens schreiben Sie In ihrer Stellungnahme: Solche Befunde zeigen vielmehr, dass psychologische Prozesse oft kontextabhängig sind und ihre Generalisierbarkeit weiter erforscht werden muss. Die Replikation einer amerikanischen Studie erbringt möglicherweise andere Ergebnisse, wenn diese in Deutschland oder in Italien durchgeführt wird (oder umgekehrt). In ähnlicher Weise können sich unterschiedliche Merkmale der Stichprobe (Geschlechteranteil, Alter, Bildungsstand, etc.) auf das Ergebnis auswirken. Diese Kontextabhängigkeit ist kein Zeichen von fehlender Replizierbarkeit, sondern vielmehr ein Zeichen für die Komplexität psychologischer Phänomene und Prozesse. Nein, das zeigen diese neuen Befunde eben nicht, denn dies ist eine (Post-hoc-)Interpretation die durch die im neuen OSF-Projekt erhobenen Moderatoren nicht unterstützt wird, da diese Moderatorenanalysen gar nicht durchgeführt wurden. Die postulierte Kontextabhängigkeit wurde zudem im OSF-Projekt #3 nicht gefunden. Was man zwischen den labs als Variationsquelle fand war schlicht und einfach Stichprobenvariation, wie man sie nun mal in der Statistik erwarten muss. Ich sehe für Ihre Behauptung also gar keine empirische Basis, wie sie doch in einer sich empirisch nennenden Wissenschaft doch vorhanden sein sollte. Was mir als abschließende Aussage in der Stellungnahme deutlich fehlt ist, dass die Psychologie (und gerade die Sozialpsychologie) in Zukunft keine selektiv publizierten und “underpowered studies” mehr akzeptieren sollte. Das hätte den Kern des Problems etwas besser getroffen. Mit freundlichen Grüßen, Moritz Heene
Moritz Heene received the following response from one of the DGPs board members.
From: Mario Gollwitzer To: Moritz Heene Subject: Re: DGPS-Stellungnahme zu Replikationsprojekt Date: Thu, 03 Sep 2015 10:19:28 +0200
Lieber Moritz,
vielen Dank für deine Mail — sie ist eine von vielen Rückmeldungen, die uns auf unsere Pressemitteilung vom Montag hin erreicht hat, und wir finden es sehr gut, dass in der DGPs-Mitgliedschaft dadurchoffenbar eine Diskussion angestoßen wurde. Wir glauben, dass diese Diskussion offen geführt werden sollte; daher haben wir uns entschlossen, zu unserer Pressemitteilung (und der Science-Studie bzw. dem ganzen Replikations-Projekt) eine Art Diskussionsforum auf unserer DGPs-Homepage einzurichten. Wir arbeiten gerade daran, die Seite aufzubauen. Ich fände es gut, wenn auch du dich hier beteiligen würdest, gerne mit deiner kritischen Haltung gegenüber unserer Pressemitteilung.
Deine Argumente kann ich gut nachvollziehen — und ich stimme dir zu, dass die Zahl “68%” nicht einen “Replikationsanteil” wiederspiegelt. Das war eine missverständliche Äußerung.
Aber abgesehen davon war unser Ziel, mit dieser Pressemitteilung den negativen, teilweise hämischen und destruktiven Reaktionen vieler Medien auf die Science-Studie etwas Konstruktives hinzuzufügen bzw. entgegenzusetzen. Keineswegs wollten wir die Ergebnisse der Studie”schönreden” oder eine Botschaft im Sinne von “alles gut, business as usual” verbreiten! Vielmehr wollten wir argumentieren, dass Replikationsversuche wie diese die Chance auf einen Erkenntnisgewinn bieten, die man nutzen sollte. Das ist die konstruktive Botschaft, die wir gerne auch ein bisschen stärker in den Medien vertreten sehen wollen.
Anders als du bin ich allerdings der Überzeugung, dass es durchaus möglich ist, dass die Unterschiede zwischen einer Originalstudie undihren Replikationen durchaus durch eine (unbekannte) Menge (teilweise bekannter, teilweise unbekannter) Moderatorvariablen (und deren Interaktionen) zustande kommen. Auch “Stichprobenvariation” ist nicht anderes als ein Sammelbegriff für solche Moderatoreffekte. Einige dieser Effekte sind für den Erkenntnisgewinn über ein psychologisches Phänomen zentral, andere nicht. Es gilt, die zentralen Effekte besser zu beschreiben und zu erklären. Darin sehe ich auch einen Wert von Replikationen, insbesondere von konzeptuellen Replikationen.
Abgesehen davon bin ich aber mit dir völlig einer Meinung, dass man nicht ausschließen kann, dass einige der nicht-replizierbaren, aber publizierten Effekte — übrigens nicht bloß in der Sozialpsychologie, sondern in allen Disziplinen — falsch Positive sind, für die es eine Reihe von Gründen gibt (selektives Publizieren, fragwürdige Auswertungspraktiken etc.), die hoch problematisch sind. Über diese Dinge wird ja andernorts auch heftig diskutiert. Diese Diskussionwollten wir aber in unserer Pressemitteilung erst einmal beseite lassen und stattdessen speziell auf die neue Science-Studiefokussieren.
Nochmals vielen Dank für deine Email. Solche Reaktionen sind für uns ein wichtiger Spiegel unserer Arbeit.
Herzliche Grüße, Mario
After the DGPs created a discussion forum, Klaus Fiedler, Moritz Heene and I shared our exchange of views openly on this site. The website is no longer available, but Moritz Heene saved a copy. He also shared our contribution on The Winnower.
1), that the notably lower average effect size in the OSF-project are a statistical artifact of regression to the mean,
2) that low reliability contributed to the lower effect sizes in the replication studies.
Response to 1) as noted in Heene’s previous post, Fiedler’s regression to the mean argument (results that were extreme in a first assessment tend to be closer to the mean in a second assessment) implicitly assumes that the original effects were biased; that is, they are extreme estimates of population effect sizes because they were selected for publication. However, Fiedler does not mention the selection of original effects, which leads to a false interpretation of the OSF-results in Fiedler’s commentary:
“(2) The only necessary and sufficient condition for regression (to the mean or toward less pronounced values) is a correlation less than zero. … One can refrain from assuming that the original findings have been over-estimations.” (Fiedler)
It is NOT possible to avoid the assumption that original results are inflated estimates because selective publication of results is necessary to account for the notable reduction in observed effect sizes.
a) Fiedler is mistaken when he cites Furby (1973) as evidence that regression to the mean can occur without selection. “The only necessary and sufficient condition for regression (to the mean or toward less pronounced values) is a correlation less than zero. This was nicely explained and proven by Furby (1973)” (Fiedler). It is noteworthy that Furby (1973) explicitly mentions a selection above or below the population mean in his example, when Furby (1973) writes: “Now let us choose a certain aggression level at Time 1 (any level other than the mean)”.
The math behind regression to the mean further illustrates this point. The expected amount of regression to the mean is defined as (1 – r)(mu – M), where r = correlation between first and second measurement, mu: population mean, and M = mean of the selected group (sample at time 1). For example, if r = .80 (thus, less than 1 as assumed by Fiedler) and the observed mean in the selected group (M) equals the population mean (mu) (e.g., M = .40, mu = .40, and M – mu = .40 – .40 = 0), no regression to the mean will occur because (1 – .80)(.40-.40) = .20*0 = 0. Consequently, a correlation less than 1 is not a necessary and sufficient condition for regression to the mean. The effect occurs only if the correlation is less than 1 and the sample mean differs from the population mean. [Actually the mean will decrease even if the correlation is 1, but individual scores will maintain their position relative to other scores]
b) The regression to the mean effect can be positive or negative. If M < mu and r < 1, the second observations would be higher than the first observations, and the trend towards the mean would be positive. On the other hand, if M > mu and r < 1, the regression effect is negative. In the OSF-project, the regression effect was negative, because the average effect size in the replication studies was lower than the average effect size in the original studies. This implies that the observed effects in the original studies overestimated the population effect size (M > mu), which is consistent with publication bias (and possibly p-hacking).
Thus, the lower effect sizes in the replication studies can be explained as a result of publication bias and regression to the mean. The OSF-results make it possible to estimate, how much publication bias inflates observed effect sizes in original studies. We calculated that for social psychology the average effect size fell from Cohen’s d = .6 to d = .2. This shows inflation by 200%. It is therefore not surprising that the replication studies produced so few significant results because the increase in sample size did not compensate for the large decrease in effect sizes.
Regarding Fiedler’s second point 2)
In a regression analysis, the observed regression coefficient (b) for an observed measure with measurement error is a function of the true relationship (bT) and an inverse function of the amount of measurement error (1 – error = reliability; Rel(X)):
(Interested readers can obtain the mathematical proof from Dr. Heene).
The formula implies that an observed regression coefficient (and other observed effect sizes) is always smaller than the true coefficient that could have been obtained with a perfectly reliable measure, when the reliability of the measure is less than 1. As noted by Dr. Fiedler, unreliability of measures will reduce the statistical power to obtain a statistically significant result. This statistical argument cannot explain the reduction in effect sizes in the replication studies because unreliability has the same influence on the outcome in the original studies and the replication studies. In short, the unreliability argument does not provide a valid explanation for the low success rate in the OSF-replication project.
REFERENCES Furby, L. (1973). Interpreting regression toward the mean in developmental research. Developmental Psychology, 8(2), 172-179. doi:10.1037/h0034145
On September 5, Klaus Fiedler emailed me to start a personal discussion over email.
From: klaus.fiedler [klaus.fiedler@psychologie.uni-heidelberg.de] Sent: September-05-15 7:17 AM To: Uli Schimmack; kf@psychologie.uni-heidelberg.de Subject: iscon gossip
Dear Uli … auf Deutsch … lieber Uli,
Du weisst vielleicht, dass ich nicht fuer Facebook registriert bin, aber ich kriege gelegentlich von anderen Notizen aus dem Chat geschickt. Du bist der Einzige, dem ich mal kurz schreibe. Du hattest geschrieben, dass meine Kommentare falsch waren und ich deshalb keinerlei Repsekt mehr verdiene.
Du bist ein methodisch motivierter und versierter Kollege, und ich waere daher sehr dankbar, wenn Du mir sagen koenntest, inwiefern meine Punkte nicht zutreffen. Was ist falsch:
— dass es die regression trap gibt? — dass eine state-of-the art Studie der Art Retest = f(Test) für Regression kontrollieren muss? — dass Regression eine Funktion der Reliabilitaet ist? — dass allein ein hohes participant N keineswegs dieses Problem behebt? — dass ein fehlender manipulation check die zentral Praemisse unterminiert, dass die UV ueberhaupt hergestellt wurde? — dass fehlende Kontrolle von measurement + sampling error die Interpretation der Ergebnisse unterminiert?
Oder ist der Punkt, dass scientific scrutiny nicht mehr zaehlt, wenn “junge Leute” fuer eine “gute Sache” kaempfen?
Sorry, die letzte Frage driftet ein bisschen ab ins Polemische. Das war nicht so gemeint. Ich moechte wirklich wissen, warum ich falsch liege, dann wuerde ich das auch gern richtigstellen. Ich habe doch nicht behauptet, dass ich empirische Daten habe, die den Vergleich von kognitiver und sozialer Psychologie erhellen (obwohl es stimmt, dass man den Vergleich nur machen kann, wenn man Reliabilitaet und Effektivitaet der Manipulationen kontrolliert). Was mich motiviert, ist lediglich das Ziel, dass auch Meta-Science (und gerade Meta-Science) denselben strengen Standards unterliegt wie jene Forschung, die sie bewertet (und oft leichtfertig schaedigt).
Was die Sozialpsychologie angeht, so hast Du sicher schon gemerkt, dass ich auch ihr Kritiker bin … Vielleicht koennen wir uns ja mal darueber unterhalten …
Schoene Gruesse aus Heidelberg, Klaus
I responded to this email and asked him directly to comment on selection bias as a reasonable explanation for the low replicability of social psychology results.
Dear Klaus Fiedler,
Moritz Heene and I have written a response to your comments posted on the DGPS website, which is waiting for moderation. I cc Moritz so that he can send you the response (in German), but I will try to answer your question myself.
First, I don’t think it was good that Mickey posted your comments. I think it would have been better to communicate directly with you and have a chance to discuss these issues in an exchange of arguments. It is also unfortunate that I mixed my response to the official DGPSs statement with your comments. I see some similarities, but you expressed a personal opinion and did not use the authority of an official position to speak for all psychologists when many psychologists disagree with the statement, which led to the post-hoc creation of a discussion forum to find out about members’ opinions on this issue.
Now let me answer your question. First, I would like to clarify that we are trying to answer the same question. To me the most important question is why the reproducibility of published results in psychology journals is so low (it is only 8% for social psychology, see my post https://replicationindex.wordpress.com/2015/08/26/predictions-about-replicat ion-success-in-osf-reproducibility-project/ )?
One answer to this question is publication bias. This argument has been made since Sterling (1959). Cohen (1962) estimated the replication rate at 60% based on his analysis of typical effect sizes and sample sizes in Journal of Abnormal and Social Psychology (now JPSP). The 60% estimate has been replicated by Sedlmeier and Giegerenzer (1989). So, with this figure in mind we could have expected that 60 out of 100 randomly selected results in JPSP would replicate. However, the actual success rate for JPSP is much lower. How can we explain this?
For the past five years I have been working on a better method to estimate post-hoc power, starting with my Schimmack (2012) Psych Method paper, followed by publications on my R-Index website. Similar work has been conducted by Simonsohn (p-curve) and Wicherts (puniform) approach. The problem with the 60% estimate is that it uses reported effect sizes which are inflated. After correcting for information, the estimated power for social psychology studies in the OSF-project is only 35%. This still does not explain why only 8% were replicated and I think it is an interesting question how much moderators or mistakes in the replication study explain this discrepancy. However, a low replication rate of 35% is entirely predicted based on the published result after taking power and publication bias into account.
In sum, it is well established and known that selectin of significant results distorts the evidence in the published literature and that this creates a discrepancy between the posted success rate (95%) and the replication rate (let’s say less than 50% to be conservative). I would be surprised if you would disagree with my argument that (a) publication bias is present and (b) that publication bias at least partially contributes to the low rate of successful replications in the OSF-project.
A few days later, I sent a reminder email.
Dear Klaus Fiedler,
I hope you received my email from Saturday in reply to your email “iscon gossip”. It would be nice if you could confirm that you received it and let me know whether you are planning to respond to it.
Best regards, Uli Schimmack
Klaus Fiedler responds without answering my question about the fact that regression to the mean can only explain a decrease in the mean effect sizes if the original values were inflated by selection for significance.
Hi:
as soon as my time permits, I will have a look. Just a general remark in response to your email, I do not undersatand what argument applies to my critical evaluation of the Nosek report. What you are telling me in the email does not apply to my critique.
Or do you contest that
a state-of the art study of retest = f(original test) has to tackle the regression beast
reliability of the dependent measure has to be controlled
manipulation check is crucial to assess the effective variation of the independent variable
the sampling of studies was suboptimal
If you disagree, I wonder if there is any common ground in scientific methodology.
I am not sure if I want to contribute to Facebook debates … As you can see, the distance from a scientitic argument to personal attacks is so short that I do not believe in the value of such a forum
Kind regards, Klaus
P.S. If I have a chance to read what you have posted, I may send a reply to the DPGs. By the way, I just sent my comments to Andrea Abele Brehm. I did not ask her to publicize it. But that’s OK
As in a chess game, I am pressing my advantage – Klaus Fiedler is clearly alone and wrong with his immaculate regression argument – in a follow up email.
Dear Klaus Fiedler,
I am waiting for a longer response from you, but to answer your question I find it hard to see how my comments are irrelevant as they are challenge direct quotes from your response.
My main concern is that you appear to neglect the fact that regression to the mean can only occur when selection occurred in the original set of studies.
Moritz Heene and I responded to this claim and find that it is invalid. If the original studies were not a selection of studies, the average mean should be an estimate of the average population mean and there would be no reason to expect a dramatic decrease in effect size in the OSF replication studies. Let’s just focus on this crucial point.
You can either maintain that selection is not necessary and try to explain how regression to the mean can occur without selection or you can concede that selection is necessary and explain how the OSF replication study should have taken selection into account. At a minimum, it would be interesting to hear your response to our quote of Furby (1973) that shows he assumed selection, while you cite Furby as evidence that selection is not necessary.
Although we may not be able to settle all disputes, we should be able to determine whether Furby assumed selection or not.
Here are my specific responses to your questions.
– a state-of the art study of retest = f(original test) has to tackle the regression beast [we can say that it tackeled it by examining how much selection contributed to the original results by seeing how much means regressed towards a lower mean of population effect sizes.
Result: there was a lot of selection and a lot of regression.
– reliability of the dependent measure has to be controlled
in a project that aims to replicate original studies exactly, reliability is determined by the methods of the original study
– manipulation check is crucial to assess the effective variation of the independent variable
sure, we can question how good the replication studies were, but adding additional manipulation checks might also introduce concerns that the study is not an exact replication. Nobody is claiming that the replication studies are conclusive, but no study can assure that it was a perfect study.
– the sampling of studies was suboptimal
how so? The year was selected at random. To take the first studies in a year was also random. Moreover it is possible to examine whether the results are representative of other studies in the same journals and they are; see my blog
You may decide that my responses are not satisfactory, but I would hope that you answer at least one of my questions: Do you maintain that the OSF-results could have been obtained without selection of results that overestimate the true population effect sizes (a lot)?
Sincerely,
Uli Schimmack
Moritz Heene comments.
Thanks, Uli! Don’t let them get away by tactically ignoring these facts. BTW, since we share the same scientific rigor, as far as I can see, we could ponder about a possible collaboration study. Just an idea. [This led to the statistical examination of Kahneman’s book Thinking: Fast and Slow]
Regards, Moritz
Too busy to really think about the possibility that he might have been wrong, Fiedler sends a terse response.
Klaus Fiedler
Very briefly … in a mad rush this morning: This is not true. A necessary and sufficient condition for regression is r < 1. So if the correlation between the original results and the replications is less than unity, there will be regression. Draw a scatter plot and you will easily see. An appropriate reference is Furby (1973 or 1974).
I try to clarify the issue in another attempt.
Dear Klaus Fiedler,
The question is what you mean by regression. We are talking about the mean at time 1 and time 2.
Of course, there will be regression of individual scores, but we are interested in the mean effect size in social psychology (which also determines power and percentage of significant results given equal N).
It is simply NOT true that the mean will change systematically unless there is systematic selection of observations.
As regression to the mean is defined by (1- r) * (mu – M), the formula implies that a selection effect (mu – M unequal 0) is necessary. Otherwise the whole term becomes 0.
There are three ways to explain mean differences between two sets of exact replication studies. The original set was selected to produce significant results. The replication studies are crappy and failed to reproduce the same conditions. Random sampling error (which can be excluded because the difference in OSF is highly significant).
In the case of the OSF replication studies, selection occurred because the published results were selected to be significant from a larger set of results with non-significant results.
If you see another explanation, it would be really helpful if you would elaborate on your theory.
Sincerely, Uli Schimmack
Moritz Heene joins the email exchange and makes a clear case that Fiedler’s claims are statistically wrong.
Dear Klaus Fiedler, dear Uli,
Just to add another clarification:
Once again, Furby (1973, p.173, see attached file) explicitly mentioned selection: “Now let us choose a certain aggression level at Time 1 (any level other than the mean) and call it x’ “.
Furthermore, regression to the mean is defined by (1- r)*(mu – M). See Shepard and Finison (1983, p.308, eq. [1]): “The term in square brackets, the product of two factors, is the estimated reduction in BP [blood pressure] due to regression.”
Now let us fix terms:
Definition of necessity and sufficiency
Necessity: ~p –> ~q , with “~” denoting negation
So, if r is not smaller than 1 than regression to the mean does not occur.
This is true as can be verified by the formula.
Sufficiency: p –> q
So, if r is smaller than 1 than regression to the mean does occur. This is not true as can be verified by the formula as explained in our reply on https://www.dgps.de/index.php?id=2000735#c2001225 and in Ulrich’s previous email.
Sincerely,
Moritz Heene
I sent another email to Klaus to see whether he is going to respond.
Lieber Dr. Fiedler,
Kann ich noch auf eine Antwort von Ihnen warten oder soll ich annehmen dass Sie sich entschieden haben nicht auf meine Anfrage zu antworten?
LG, Uli Schimmack
Klaus Fiedler does respond.
Dear Ullrich:
Yes, I was indeed very, very busy over two weeks, working for the Humboldt foundation, for two conferences where I had to play leading roles, the Leopoldina Academy, and many other urgent jobs. Sorry but this is simply so. I now received your email reminder to send you my comments to what you and Moritz Heene have written. However, it looks like you have already committed yourself publicly (I was sent this by colleagues who are busy on facebook): Fiedler was quick to criticize the OSF-project and Brian Nosek for making the mistake to ignore the well-known regression to the mean effect. This silly argument ignores that regression to the mean requires that the initial scores are selected, which is exactly the point of the OSF-replication studies.
Look, this passage shows that there is apparently a deep misunderstanding about the “silly argument”. Let me briefly try to explain once more what my critique of the Science article (not Brian Nosek personally – this is not my style) referred to. At the statistical level, I was simply presupposing that there is common ground on the premise that regressiveness is ubiquitous; it is not contingent on selected initial scores. Take a scatter plot of 100 bi-variate points (jointly distributed in X and Y). If r(X,Y) < 1(disregarding sign), regressing Y on X will result in a regression slope less than 1. The variance of predicted Y scores will be reduced. I very much hope we all agree that this holds for every correlation, not just those in which X is selected. If you don’t believe, I can easily demonstrate it with random (i.e., non-selective vectors x and y). Across the entire set of data pairs, large values of X will be underestimated in Y, and small values of X will be overestimated. By analogy, large original findings can be expected to be much smaller in the replication. However, when we regress X on Y, we can also expect to see that large Y scores (i.e., i.e., strong replication effects) have been weaker in the original. The Bayes factors reported by Alexander Etz in his “Bayesian reproducibility project”, although not explicit about reverse regression, strongly suggest that there are indeed quite a few cases in which replication results have been stronger than the original ones. Etz’ analysis, which nicely illustrates how a much more informative and scientifically better analysis than the one provided by Nosek might look like, also reinforces my point that the report published in Science is very weak. By the way, the conclusions are markedly different from Nosek, showing that most replication studies were equivocal. The link (that you have certainly found yourself) is provided below.
We know since Rulon (1941 or so) and even since Galton (1986 or so) that regression is a tricky thing, and here I get to the normative (as opposed to the statistical, tautological) point of my critique, which is based on the recommendation of such people as Don Campbell, Daniel Kahneman & Amos Tversky, Ido Erev, Tom Wallsten & David Budescu and many others, who have made it clear that the interpretation of retesting or replication studies will be premature and often mistaken, if one does not take the vicissitudes of regression into account. A very nice historical example is Erev, Wallsten & Budescu’s 1994 Psych. Review article on overconfidence. They make it clear you find very strong evidence for both overconfidence and underconfidence in the same data array, when you regress either accuracy on confidence or confidence on accuracy, respectively. Another wonderful demonstration is Moore and Small’s 2008 Psych. Review analysis of several types of self-serving biases.
So, while my statistical point is analytically true (because regression slope with a single predictor is always < 1; I know there can be suppressor effects with slopes > 1 in multiple regression), my normative point is also well motivated. I wonder if the audience of your Internet allusion to my “silly argument” has a sufficient understanding of the “regression trap” so that, as you write:
Everybody can make up their own mind and decide where they want to stand, but the choices are pretty clear. You can follow Fiedler, Strack, Baumeister, Gilbert, Bargh and continue with business as usual or you can change. History will tell what the right choice will be.
By the way, why you put me in the same pigeon hole as Fritz, Roy, Dan, and John. The role I am playing is completely different and it definitely not aims at business as usual. My very comment on the Nosek article is driven my deep concerns about the lack of scientific scrutiny in such a prominent journal, in which there is apparently no state-of-the-art quality control. A replication project is the canonical case of a scientific interpretation that strongly calls for awareness of the regression trap. That is, the results are only informative if one takes into account what shrinkage of strong effects could be expected by regression alone. Regressiveness imposes an upper limit on the possible replication success, which ought to be considered as a baseline for the presentation of the replication results.
To do that, it is essential to control for reliability. (I know that the reliability of individual scores within a study is not the same as the reliability of the aggregate study results, but they are of course related). I also continue to believe, strongly, that a good replication project ought to control for the successful induction of the independent variable, as evident in a manipulation check (maybe in an extra group), and that the sampling of the 100 studies itself was suboptimal. If Brian Nosek (or others) come up with a convincing interpretation of this replication project, then it is fine. However, the present analysis is definitely not convincing. It is rather a symptom of shallow science.
So, as you can see, the comments that you and Moritz Heene have sent me do not really affect these considerations. And, because there is obviously no common ground between the two of us, not even about the simplest statistical constraints, I have decided not to engage in a public debate with you. I’m afraid hardly anybody in this Facebook cycle will really invest time and work to read the literature necessary to judge the consequences of the regression trap, in order to make an informed judgment. And I do not want to nourish the malicious joy of an audience that apparently likes personal insults and attacks, detached from scientific arguments.
Kind regards, Klaus
P.S. As you can see, I CC this email to myself and to Joachim Krueger, who spontaneously sent me a similar note on the Nosek article and the regression trap.
Am 9/18/2015 um 3:21 PM schrieb Ulrich Schimmack: Lieber Dr. Fiedler,
Kann ich noch auf eine Antwort von Ihnen warten oder soll ich annehmen dass Sie sich entschieden haben nicht auf meine Anfrage zu antworten?
LG, Uli Schimmack
Klaus Fiedler responds
Dear Ullrich:
Yes, I was indeed very, very busy over two weeks, working for the Humboldt foundation, for two conferences where I had to play leading roles, the Leopoldina Academy, and many other urgent jobs. Sorry but this is simply so.
I now received your email reminder to send you my comments to what you and Moritz Heene have written. However, it looks like you have already committed yourself publicly (I was sent this by colleagues who are busy on facebook):
Fiedler was quick to criticize the OSF-project and Brian Nosek for making the mistake to ignore the well-known regression to the mean effect. This silly argument ignores that regression to the mean requires that the initial scores are selected, which is exactly the point of the OSF-replication studies.
Look, this passage shows that there is apparently a deep misunderstanding about the “silly argument”. Let me briefly try to explain once more what my critique of the Science article (not Brian Nosek personally – this is not my style) referred to.
At the statistical level, I was simply presupposing that there is common ground on the premise that regressiveness is ubiquitous; it is not contingent on selected initial scores. Take a scatter plot of 100 bi-variate points (jointly distributed in X and Y). If r(X,Y) < 1(disregarding sign), regressing Y on X will result in a regression slope less than 1. The variance of predicted Y scores will be reduced. I very much hope we all agree that this holds for every correlation, not just those in which X is selected. If you don’t believe, I can easily demonstrate it with random (i.e., non-selective vectors x and y).
Across the entire set of data pairs, large values of X will be underestimated in Y, and small values of X will be overestimated. By analogy, large original findings can be expected to be much smaller in the replication. However, when we regress X on Y, we can also expect to see that large Y scores (i.e., i.e., strong replication effects) have been weaker in the original. The Bayes factors reported by Alexander Etz in his “Bayesian reproducibility project”, although not explicit about reverse regression, strongly suggest that there are indeed quite a few cases in which replication results have been stronger than the original ones. Etz’ analysis, which nicely illustrates how a much more informative and scientifically better analysis than the one provided by Nosek might look like, also reinforces my point that the report published in Science is very weak. By the way, the conclusions are markedly different from Nosek, showing that most replication studies were equivocal. The link (that you have certainly found yourself) is provided below.
We know since Rulon (1941 or so) and even since Galton (1986 or so) that regression is a tricky thing, and here I get to the normative (as opposed to the statistical, tautological) point of my critique, which is based on the recommendation of such people as Don Campbell, Daniel Kahneman & Amos Tversky, Ido Erev, Tom Wallsten & David Budescu and many others, who have made it clear that the interpretation of retesting or replication studies will be premature and often mistaken, if one does not take the vicissitudes of regression into account. A very nice historical example is Erev, Wallsten & Budescu’s 1994 Psych. Review article on overconfidence. They make it clear you find very strong evidence for both overconfidence and underconfidence in the same data array, when you regress either accuracy on confidence or confidence on accuracy, respectively. Another wonderful demonstration is Moore and Small’s 2008 Psych. Review analysis of several types of self-serving biases.
So, while my statistical point is analytically true (because regression slope with a single predictor is always < 1; I know there can be suppressor effects with slopes > 1 in multiple regression), my normative point is also well motivated. I wonder if the audience of your Internet allusion to my “silly argument” has a sufficient understanding of the “regression trap” so that, as you write:
Everybody can make up their own mind and decide where they want to stand, but the choices are pretty clear. You can follow Fiedler, Strack, Baumeister, Gilbert, Bargh and continue with business as usual or you can change. History will tell what the right choice will be.
By the way, why you put me in the same pigeon hole as Fritz, Roy, Dan, and John. The role I am playing is completely different and it definitely not aims at business as usual. My very comment on the Nosek article is driven my deep concerns about the lack of scientific scrutiny in such a prominent journal, in which there is apparently no state-of-the-art quality control. A replication project is the canonical case of a scientific interpretation that strongly calls for awareness of the regression trap. That is, the results are only informative if one takes into account what shrinkage of strong effects could be expected by regression alone. Regressiveness imposes an upper limit on the possible replication success, which ought to be considered as a baseline for the presentation of the replication results.
To do that, it is essential to control for reliability. (I know that the reliability of individual scores within a study is not the same as the reliability of the aggregate study results, but they are of course related). I also continue to believe, strongly, that a good replication project ought to control for the successful induction of the independent variable, as evident in a manipulation check (maybe in an extra group), and that the sampling of the 100 studies itself was suboptimal. If Brian Nosek (or others) come up with a convincing interpretation of this replication project, then it is fine. However, the present analysis is definitely not convincing. It is rather a symptom of shallow science.
So, as you can see, the comments that you and Moritz Heene have sent me do not really affect these considerations. And, because there is obviously no common ground between the two of us, not even about the simplest statistical constraints, I have decided not to engage in a public debate with you. I’m afraid hardly anybody in this Facebook cycle will really invest time and work to read the literature necessary to judge the consequences of the regression trap, in order to make an informed judgment. And I do not want to nourish the malicious joy of an audience that apparently likes personal insults and attacks, detached from scientific arguments.
Kind regards, Klaus
P.S. As you can see, I CC this email to myself and to Joachim Krueger, who spontaneously sent me a similar note on the Nosek article and the regression trap.
I made another attempt to talk about selection bias and ended pretty much with a simple yes/no question as a prosecutor asking a hostile witness.
Dear Klaus,
I don’t understand why we cannot even agree about the question that regression to the mean is supposed to answer.
Moritz Heene and I are talking about the mean difference in effect sizes (the intercept, not the slope, in a regression). According to the Science article, the effect sizes in the replication studies were, on average, 50% lower than the effect sizes in the original studies. My own analysis for social psychology show a difference of d = .6 and d = .2, which suggests results published in original articles are inflated by 200%. Do you believe that regression to the mean can explain this finding? Again, this is not a question about the slope, so please try to provide an explanation that can account for mean differences in effect sizes.
Of course, you can just say that we know that a published significant result is inflated by publication bias. After all, power is never 100% so if you select 100% significant results for publication, you cannot expect 100% successful replications. The percentage that you can expect is determined by the true power of the set of studies (this has nothing to do with regression to the mean, it is simply power + publication bias. However, the OSF-reproducibility project did take power into account and increased sample sizes to account for the problem. They are also aware that the replication studies will not produce 100% successes if the replication studies were planned with 90% power.
The problem that I see with the OSF-project is that they were naïve to use the observed effect sizes to conduct their power analyses. As these effect sizes were strongly inflated by publication bias, the true power was much lower than they thought it would be. For social psychology, I calculated the true power of the original studies to be only 35%. Increasing sample sizes from 90 to 120 does not make much of a difference with power this low. If your point is simply to say that the replication studies were underpowered to reject the null-hypothesis, I agree with you. But the reason for the low power is that reported results in the literature are not credible and strongly influenced by bias. Published effect sizes in social psychology are, on average, 1/3 real and 2/3 bias. Good luck finding the false positive results with evidence like this.
Do you disagree with any of my arguments about power, publication bias, and the implication that social psychological results lack credibility?
Best regards,
Uli
Klaus Fiedler’s response continues to evade the topic of selection bias that undermines the credibility of published results with a replication rate of 25%, but he acknowledges for the first time that regression works in both directions and cannot explain mean changes without selection bias..
Dear Uli, Moritz and Krueger:
I’m afraid it’s getting very basic now … we are talking about problems which are not really there … very briefly, just for the sake of politeness
First, as already clarified in my letter to Uli yesterday, nobody will come to doubt that every correlation < 1 will produce regression in both directions. The scatter plot does not have to be somehow selected. Let’s talk about (or simulate) a bi-variate random sample. Given r < 1, if you plot Y as a function of X (i.e., “given” X values), the regression curve will have a slope < 1, that is, Y values corresponding to high X values will be smaller and Y values corresponding to low X values will be higher. In one word, the variance in Y predictions (in what can be expected in Y) will shrink. If you regress X on Y, the opposite will be the case in the same data set. That’s the truism that I am referring to.
Of course, regression is always a conditional phenomenon. Assuming a regression of Y on X: If X is (very) high, the predicted Y analogue is (much) lower. If X is (very) low, the predicted Y analogue is (much) higher. But this conditional IF phrase does not imply any selectivity. The entire sample is drawn randomly. By plotting Y as a function of given X levels (contaminated with error and unreliability), you conditionalize Y values on (too) high or (too) low X values. But this is always the case with regression.
If I correctly understand the point, you simply equate the term “selective” with “conditional on” or “given”. But all this is common sense, or isn’t it. If you believe you have found a mathematical or Monte-Carlo proof that a correlation (in a bivariate distribution) is 1 and there is no regression (in the scatter plot), then you can probably make a very surprising contribution to statistics and numerical mathematics.
Of course, regression a multiplicative function of unreliability and extremity. So points have to be extreme to be regressive. But I am talking about the entire distribution …
Best, Klaus
… who is now going back to work, sorry.
At this point, Moritz Heene is willing to let it go. There is really no point in arguing with a dickhead – a slightly wrong translation of the German term “Dickkopf” (bull-headed, stubborn).
Lieber Uli,
Sorry, schnell auf Deutsch: Angesichts der Email unten von Fiedler sehe ich es als “fruitless endeavour” an, da noch weiter zu diskutieren. Er geht auf unsere -formal korrekten!- Argumente überhaupt nicht ein und mittlerweile ist er schon bei “Ihr seid es gar nicht wert, dass ich mit Euch diskutiere” angekommen. Auch, dass er Ferby (1973) nachweislich falsch zitiert, ist ihm keine Erwähnung wert. Ich diskutiere das nun nicht mehr mit ihm, weil er es einfach nicht einsehen will und daher unsere mathematisch korrekten Argumente einfach nicht mehr erwähnt (tactical ignorance).
Eines der großen Probleme der Psychologie ist, dass die Probleme grauenhaft basal zu widerlegen sind. Bspw. ist das “hidden-moderatorArgument” am Stammtisch mit 1.3 Promille noch zu widerlegen. Taucht aber leider in Artikeln von Strack und Stroebe und anderen immer wieder auf.
I agreed with him and decided to write a blog post about this fruitless discussion. I didn’t until now, when the PoPS scandal reminded me of Fiedler’s “I am never wrong” attitude.
Hallo Moritz,
Ja Diskussion ist zu Ende. Nun werde ich ein blog mit den emails schreiben um zu zeigen mit welchen schadenfeinigen (? Ist das wirklich ein Wort) Argumenten gearbeitet wird.
Null Respekt fuer Klaus Fiedler.
LG, Uli
I communicated our decision to end the discussion to Klaus Fiedler in a final email.
Dear Klaus,
Last email from me to you.
It is sad that you are not even trying to answer my questions about the results of the reproducibility project.
I also going back to work now, where my work is to save psychology from psychologists like you who continue to deny that psychology has been facing a crisis for 50 years, make some quick bogus statistical arguments to undermine the credibility of the OSF-reproducibility project, and then go back to work as usual.
History will decide who wins this argument.
Disappointed (which implies that I had expected more for you when I started this attempt at a scientific discussion), Uli
Klaus Fiedler replied with his last email.
Dear Uli:
no, sorry that is not my intention … and not my position. I would like to share with you my thoughts about reproducibility … and I am not at all happy with the (kernel of truth) of the Nosek report. However, I believe the problems are quite different from those focused in the current debate, and in the premature consequences drawn by Nosek, Simonsohn, an others. You may have noticed that I have published a number of relevant articles, arguing that what we are lacking is not better statistics and larger subject samples but a better methodology more broader. Why should we two (including Moritz and Joachim and others) not share our thoughts, and I would also be willing to read your papers. Sure. For the moment, we have been only debating about my critique of the Nosek report. My point was that in such a report of replications plotted against originals,
an informed interpretation is not possible unless one takes regression into acount
one has to control for reliability as a crucial moderator
one has to consider manipulation checks
one has to contemplate sampling of studies
Our “debate” about 2+2=4 (I agree that’s what it was) does not affect this critique. I do not believe that I am at variance with your mathematical sketch, but it does not undo the fact that in a bivariate distribution of 100 bivariate points, the devil is lurking in the regression trap.
So please distinguish between the two points: (a) Nosek’s report does not live up to appropriate standards; but (b) I am not unwilling to share with you my thoughts about replicability. (By the way, I met Ioannidis some weeks ago and I never saw as clearly as now that he, like Fanelli, whom I also met, believe that all behavioral science is unreliable and invalid)
Kind regards, Klaus
More Gaslighting about the Replication Crisis by Klaus Fiedler
Klaus Fiedler and Norbert Schwarz are both German-born influential social psychologists. Norbert Schwarz migrated to the United States but continued to collaborate with German social psychologists like Fritz Strack. Klaus Fiedler and Norbert Schwarz have only one peer-reviewed joined publication titled “Questionable Research Practices Revisited” This article is based on John, Loewenstein, & Prelec’s (2012) influential article that coined the term “questionable research practices” In the original article, John et al. (2012) conducted a survey and found that many researchers admit that they used QRPs and also found these practices were acceptable (i.e., not a violation of ethical norms about scientific integrity). John et al.’s (2012) results provide a simple explanation for the outcome of the reproducibility project. Researchers use QRPs to get statistically significant results in studies with low statistical power. This leads to an inflation of effect sizes. When these studies are replicated WITHOUT QRPs, effect sizes are closer to the real effect sizes and lower than the inflated estimates in replications. As a result, the average effect size shrinks and the percentage of significant results decreases. All of this was clear, when Moritz Heene and I debated with Fiedler.
Fiedler and Schwarz’s article had one purpose, namely to argue that John et al.’s (2012) article did not provide credible evidence for the use of QRPs. The article does not make any connection between the use of QRPs and the outcome of the reproducibility project.
The resulting prevalence estimates are lower by order of magnitudes. We conclude that inflated prevalence estimates, due to problematic interpretation of survey data, can create a descriptive norm (QRP is normal) that can counteract the injunctive norm to minimize QRPs and unwantedly damage the image of behavioral sciences, which are essential to dealing with many societal problems” (Fiedler & Schwarz, 2016, p. 45).
Indeed, the article has been cited to claim that “questionable research practices” are not always questionable and that “QRPs may be perfectly acceptable given a suitable context and verifiable justification (Fiedler & Schwarz, 2016; …) (Rubin & Dunkin, 2022).
To be clear what this means. Rubin and Dunkin claim that it is perfectly acceptable to run multiple studies and publish only those that worked, drop observations to increase effect sizes, and to switch outcome variables after looking at the results. No student will agree that these practices are scientific or trust results based on such practices. However, Fiedler and other social psychologists want to believe that they did nothing wrong when they engaged in these practices to publish.
Fiedler triples down on Immaculate Regression
I assumed everybody had moved on from the heated debates in the wake of the reproducibility project, but I was wrong. Only a week ago, I discovered an article by Klaus Fiedler – with a co-author with one of his students that repeats the regression trap claims in an English-language peer-reviewed journal with the title “The Regression Trap and Other Pitfalls of Replication Science—Illustrated by the Report of the Open Science Collaboration” (Fiedler & Prager, 2018).
ABSTRACT The Open Science Collaboration’s 2015 report suggests that replication effect sizes in psychology are modest. However, closer inspection reveals serious problems.
A more general aim of our critical note, beyond the evaluation of the OSC report, is to emphasize the need to enhance the methodology of the current wave of simplistic replication science.
Moreover, there is little evidence for an interpretation in terms of insufficient statistical power.
Again, it is sufficient to assume a random variable of positive and negative deviations (from the overall mean) in different study domains or ecologies, analogous to deviations of high and low individual IQ scores. One need not attribute such deviations to “biased” or unfair measurement procedures, questionable practices, or researcher expectancies.
Yet, when concentrating on a domain with positive deviation scores (like gifted students), it is permissible—though misleading and unfortunate—to refer to a “positive bias” in a technical sense, to denote the domain-specific enhancement.
Depending on the selectivity and one- sided distribution of deviation scores in all these domains, domain-specific regression effects can be expected.
How about the domain of replication science? Just as psychopathology research produces overall upward regression, such that patients starting in a crisis or a period of severe suffering (typically a necessity for psychiatric diagnoses) are better off in a retest, even without therapy (Campbell, 1996), research on scientific findings must be subject to an opposite, downward regression effect. Unlike patients representing negative deviations from normality, scientific studies published in highly selective journals constitute a domain of positive deviations, of well-done empirical demonstrations that have undergone multiple checkson validity and a very strict review process. In other words, the domain of replication science, major empirical findings, is inherently selective. It represents a selection of the most convincing demonstrations of obtained effect sizes that should exceed most everyday empirical observations. Note once more that the emphasis here is not on invalid effects or outliers but on valid and impressive effects, which are, however, naturally contaminated with overestimation error (cf. Figure 2).
The domain-specific overestimation that characterizes all science is by no means caused by publication bias alone. [!!!!! the addition of alone here is the first implicit acknowledgement that publication bias contributes to the regression effect!!!!]
To summarize, it is a moot point to speculate about the reasons for more or less successful replications as long as no evidence is available about the reliability of measures and the effectiveness of manipulations.
In the absence of any information about the internal and external validity (Campbell, 1957) of both studies, there is no logical justification to attribute failed replications to the weakness of scientific hypotheses or to engage in speculations about predictors of replication success.
A recent simulation study by Stanley and Spence (2014) highlights this point, showing that measurement error and sampling error alone (Schmidt, 2010) can greatly reduce the replication success of empirical tests of correct hypotheses in studies that are not underpowered.
Our critical comments on the OSC report highlight the conclusion that the development of such a methodology is sorely needed.
Final Conclusion
Fiedler’s illusory regression account of the replication crisis was known to me since 2015. It was not part of the official record. However, his articles with Schwarz in 2016 and Prager in 2018 are part of his official CV. The articles show a clear motivated bias against Open Science and the reforms initiated by social psychologists to fix their science. He was fired because he demonstrated the same arrogant dickheadedness in interactions with a Black scholar. Does this mean he is a racist? No, he also treats White colleagues with the same arrogance, yet when he treated Roberts like this he abused his position as gate-keeper at an influential journal. I think APS made the right decision to fire him, but they were wrong to hire him in the first place. The past editors of PoPS have shown that old White eminent psychologists are unable to navigate the paradigm shift in psychology towards credibility, transparency, and inclusivity. I hope APS will learn a lesson from the reputational damage caused by Fiedler’s actions and search for a better editor that represents the values of contemporary psychologists.
P.S. This blog post is about Klaus Fiedler, the public figure and his role in psychological science. It has nothing to do with the human being.
P.P.S I also share the experience of being forced from an editorial position with Klaus. I was co-founding editor of Meta-Psychology and made some controversial comments about another journal that led to a negative response. To save the new journal, I resigned. It was for the better and Rickard Carlsson is doing a much better job alone than we could have done together. It hurt a little, but live goes on. Reputations are not made by a single incidence, especially if you can admit to mistakes.
Social psychologists have failed to clean up their act and their literature. Here I show unusually high effect sizes in non-retracted articles by Sanna, who retracted several articles. I point out that non-retraction does not equal credibility and I show that co-authors like Norbert Schwarz lack any motivation to correct the published record. The inability of social psychologists to acknowledge and correct their mistakes renders social psychology a para-science that lacks credibility. Even meta-analyses cannot be trusted because they do not correct properly for the use of questionable research practices.
Introduction
When I grew up, a popular German Schlager was the song “Aber bitte mit Sahne.” The song is about Germans love of deserts with whipped cream. So, when I saw articles by Sanna, I had to think about whipped cream, which is delicious. Unfortunately, articles by Sanna are the exact opposite. In the early 2010s, it became apparent that Sanna had fabricated data. However, unlike the thorough investigation of a similar case in the Netherlands, the extent of Sanna’s fraud remains unclear (Retraction Watch, 2012). The latest count of Sanna’s retracted articles was 8 (Retraction Watch, 2013).
WebOfScience shows 5 retraction notices for 67 articles, which means 62 articles have not been retracted. The question is whether these article can be trusted to provide valid scientific information? The answer to this question matters because Sanna’s articles are still being cited at a rate of over 100 citations per year.
Meta-Analysis of Ease of Retrieval
The data are also being used in meta-analyses (Weingarten & Hutchinson, 2018). Fraudulent data are particularly problematic for meta-analysis because fraud can produce large effect size estimates that may inflate effect size estimates. Here I report the results of my own investigation that focusses on the ease-of-retrieval paradigm that was developed by Norbert Schwarz and colleagues (Schwarz et al., 1991).
The meta-analysis included 7 studies from 6 articles. Two studies produced independent effect size estimates for 2 conditions for a total of 9 effect sizes.
Sanna, L. J., Schwarz, N., & Small, E. M. (2002). Accessibility experiences and the hindsight bias: I knew it all along versus it could never have happened. Memory & Cognition, 30(8), 1288–1296. https://doi.org/10.3758/BF03213410 [Study 1a, 1b]
Sanna, L. J., Schwarz, N., & Stocker, S. L. (2002). When debiasing backfires: Accessible content and accessibility experiences in debiasing hindsight. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(3), 497–502. https://doi.org/10.1037/0278-7393.28.3.497 [Study 1 & 2]
Sanna, L. J., & Schwarz, N. (2003). Debiasing the hindsight bias: The role of accessibility experiences and (mis)attributions. Journal of Experimental Social Psychology, 39(3), 287–295. https://doi.org/10.1016/S0022-1031(02)00528-0 [Study 1]
Sanna, L. J., Chang, E. C., & Carter, S. E. (2004). All Our Troubles Seem So Far Away: Temporal Pattern to Accessible Alternatives and Retrospective Team Appraisals. Personality and Social Psychology Bulletin, 30(10), 1359–1371. https://doi.org/10.1177/0146167204263784 [Study 3a]
Sanna, L. J., Parks, C. D., Chang, E. C., & Carter, S. E. (2005). The Hourglass Is Half Full or Half Empty: Temporal Framing and the Group Planning Fallacy. Group Dynamics: Theory, Research, and Practice, 9(3), 173–188. https://doi.org/10.1037/1089-2699.9.3.173 [Study 3a, 3b]
Carter, S. E., & Sanna, L. J. (2008). It’s not just what you say but when you say it: Self-presentation and temporal construal. Journal of Experimental Social Psychology, 44(5), 1339–1345. https://doi.org/10.1016/j.jesp.2008.03.017 [Study 2]
When I examined Sanna’s results, I found that all 9 of these 9 effect sizes were extremely large with effect size estimates being larger than one standard deviation. A logistic regression analysis that predicted authorship (With Sanna vs. Without Sanna) showed that the large effect sizes in Sanna’s articles were unlikely to be due to sampling error alone, b = 4.6, se = 1.1, t(184) = 4.1, p = .00004 (1 / 24,642).
These results show that Sanna’s effect sizes are not typical for the ease-of-retrieval literature. As one of his retracted articles used the ease-of retrieval paradigm, it is possible that these articles are equally untrustworthy. As many other studies have investigated ease-of-retrieval effects, it seems prudent to exclude articles by Sanna from future meta-analysis.
These articles should also not be cited as evidence for specific claims about ease-of-retrieval effects for the specific conditions that were used in these studies. As the meta-analysis shows, there have been no credible replications of these studies and it remains unknown how much ease of retrieval may play a role under the specified conditions in Sanna’s articles.
Discussion
The blog post is also a warning for young scientists and students of social psychology that they cannot trust researchers who became famous with the help of questionable research practices that produced too many significant results. As the reference list shows, several articles by Sanna were co-authored by Norbert Schwarz, the inventor of the ease-of-retrieval paradigm. It is most likely that he was unaware of Sanna’s fraudulent practices. However, he seemed to lack any concerns that the results might be too good to be true. After all, he encountered replicaiton failures in his own lab.
“of course, we had studies that remained unpublished. Early on we experimented with different manipulations. The main lesson was: if you make the task too blatantly difficult, people correctly conclude the task is too difficult and draw no inference about themselves. We also had a couple of studies with unexpected gender differences” (Schwarz, email communication, 5/18,21).
So, why was he not suspicious when Sanna only produced successful results? I was wondering whether Schwarz had some doubts about these studies with the help of hindsight bias. After all, a decade or more later, we know that he committed fraud for some articles on this topic, we know about replication failures in larger samples (Yeager et al., 2019), and we know that the true effect sizes are much smaller than Sanna’s reported effect sizes (Weingarten & Hutchinson, 2018).
Hi Norbert, thank you for your response. I am doing my own meta-analysis of the literature as I have some issues with the published one by Evan. More about that later. For now, I have a question about some articles that I came across, specifically Sanna, Schwarz, and Small (2002). The results in this study are very strong (d ~ 1). Do you think a replication study powered for 95% power with d = .4 (based on meta-analysis) would produce a significant result? Or do you have concerns about this particular paradigm and do not predict a replication failure? Best, Uli (email
His response shows that he is unwilling or unable to even consider the possibility that Sanna used fraud to produce the results in this article that he co-authored.
Uli, that paper has 2 experiments, one with a few vs many manipulation and one with a facial manipulation. I have no reason to assume that the patterns won’t replicate. They are consistent with numerous earlier few vs many studies and other facial manipulation studies (introduced by Stepper & Strack, JPSP, 1993). The effect sizes always depend on idiosyncracies of topic, population, and context, which influence accessible content and accessibility experience. The theory does not make point predictions and the belief that effect sizes should be identical across decades and populations is silly — we’re dealing with judgments based on accessible content, not with immutable objects.
This response is symptomatic of social psychologists response to decades of research that has produced questionable results that often fail to replicate (see Schimmack, 2020, for a review). Even when there is clear evidence of questionable practices, journals are reluctant to retract articles that make false claims based on invalid data (Kitayama, 2020). And social psychologist Daryl Bem wants rather be remembered as loony para-psychologists than as real scientists (Bem, 2021).
The problem with these social psychologists is not that they made mistakes in the way they conducted their studies. The problem is their inability to acknowledge and correct their mistakes. While they are clinging to their CVs and H-Indices to protect their self-esteem, they are further eroding trust in psychology as a science and force junior scientists who want to improve things out of academia (Hilgard, 2021). After all, the key feature of science that distinguishes it from ideologies is the ability to correct itself. A science that shows no signs of self-correction is a para-science and not a real science. Thus, social psychology is currently para-science (i.e., “Parascience is a broad category of academic disciplines, that are outside the scope of scientific study, Wikipedia).
The only hope for social psychology is that young researchers are unwilling to play by the old rules and start a credibility revolution. However, the incentives still favor conformists who suck up to the old guard. Thus, it is unclear if social psychology will ever become a real science. A first sign of improvement would be to retract articles that make false claims based on results that were produced with questionable research practices. Instead, social psychologists continue to write review articles that ignore the replication crisis (Schwarz & Strack, 2016) as if repression can bend reality.
Information about the replicability of published results is important because empirical results can only be used as evidence if the results can be replicated. However, the replicability of published results in social psychology is doubtful. Brunner and Schimmack (2020) developed a statistical method called z-curve to estimate how replicable a set of significant results are, if the studies were replicated exactly. In a replicability audit, I am applying z-curve to the most cited articles of psychologists to estimate the replicability of their studies.
John A. Bargh
Bargh is an eminent social psychologist (H-Index in WebofScience = 61). He is best known for his claim that unconscious processes have a strong influence on behavior. Some of his most cited article used subliminal or unobtrusive priming to provide evidence for this claim.
Bargh also played a significant role in the replication crisis in psychology. In 2012, a group of researchers failed to replicate his famous “elderly priming” study (Doyen et al., 2012). He responded with a personal attack that was covered in various news reports (Bartlett, 2013). It also triggered a response by psychologist and Nobel Laureate Daniel Kahneman, who wrote an open letter to Bargh (Young, 2012).
“As all of you know, of course, questions have been raised about the robustness of priming results…. your field is now the poster child for doubts about the integrity of psychological research.”
Kahneman also asked Bargh and other social priming researchers to conduct credible replication studies to demonstrate that the effects are real. However, seven years later neither Bargh nor other prominent social priming researchers have presented new evidence that their old findings can be replicated.
Instead other researchers have conducted replication studies and produced further replication failures. As a result, confidence in social priming is decreasing – but not as fast as it should gifen replication failures and lack of credibility – as reflected in Bargh’s citation counts (Figure 1)
Figure 1. John A. Bargh’s citation counts in Web of Science (updated 9/29/23)
In this blog post, I examine the replicability and credibility of John A. Bargh’s published results using z-curve. It is well known that psychology journals only published confirmatory evidence with statistically significant results, p < .05 (Sterling, 1959). This selection for significance is the main cause of the replication crisis in psychology because selection for significance makes it impossible to distinguish results that can be replicated from results that cannot be replicated because selection for significance ensures that all results will be replicated (we never see replication failures).
While selection for significance makes success rates uninformative, the strength of evidence against the null-hypothesis (signal/noise or effect size / sampling error) does provide information about replicability. Studies with higher signal to noise ratios are more likely to replicate. Z-curve uses z-scores as the common metric of signal-to-noise ratio for studies that used different test statistics. The distribution of observed z-scores provides valuable information about the replicability of a set of studies. If most z-scores are close to the criterion for statistical significance (z = 1.96), replicability is low.
Given the requirement to publish significant results, researches had two options how they could meet this goal. One option requires obtaining large samples to reduce sampling error and therewith increase the signal-to-noise ratio. The other solution is to conduct studies with small samples and conduct multiple statistical tests. Multiple testing increases the probability of obtaining a significant results with the help of chance. This strategy is more efficient in producing significant results, but these results are less replicable because a replication study will not be able to capitalize on chance again. The latter strategy is called a questionable research practice (John et al., 2012), and it produces questionable results because it is unknown how much chance contributed to the observed significant result. Z-curve reveals how much a researcher relied on questionable research practices to produce significant results.
Data
I used WebofScience to identify the most cited articles by John A. Bargh (datafile). I then selected empirical articles until the number of coded articles matched the number of citations, resulting in 43 empirical articles (H-Index = 41). The 43 articles reported 111 studies (average 2.6 studies per article). The total number of participants was 7,810 with a median of 56 participants per study. For each study, I identified the most focal hypothesis test (MFHT). The result of the test was converted into an exact p-value and the p-value was then converted into a z-score. The z-scores were submitted to a z-curve analysis to estimate mean power of the 100 results that were significant at p < .05 (two-tailed). Four studies did not produce a significant result. The remaining 7 results were interpreted as evidence with lower standards of significance. Thus, the success rate for 111 reported hypothesis tests was 96%. This is a typical finding in psychology journals (Sterling, 1959).
Results
The z-curve estimate of replicability is 29% with a 95%CI ranging from 15% to 38%. Even at the upper end of the 95% confidence interval this is a low estimate. The average replicability is lower than for social psychology articles in general (44%, Schimmack, 2018) and for other social psychologists. At present, only one audit has produced an even lower estimate (Replicability Audits, 2019).
The histogram of z-values shows the distribution of observed z-scores (blue line) and the predicted density distribution (grey line). The predicted density distribution is also projected into the range of non-significant results. The area under the grey curve is an estimate of the file drawer of studies that need to be conducted to achieve 100% successes if hiding replication failures were the only questionable research practice that is used. The ratio of the area of non-significant results to the area of all significant results (including z-scores greater than 6) is called the File Drawer Ratio. Although this is just a projection, and other questionable practices may have been used, the file drawer ratio of 7.53 suggests that for every published significant result about 7 studies with non-significant results remained unpublished. Moreover, often the null-hypothesis may be false, but the effect size is very small and the result is still difficult to replicate. When the definition of a false positive includes studies with very low power, the false positive estimate increases to 50%. Thus, about half of the published studies are expected to produce replication failures.
Finally, z-curve examines heterogeneity in replicability. Studies with p-values close to .05 are less likely to replicate than studies with p-values less than .0001. This fact is reflected in the replicability estimates for segments of studies that are provided below the x-axis. Without selection for significance, z-scores of 1.96 correspond to 50% replicability. However, we see that selection for significance lowers this value to just 14% replicability. Thus, we would not expect that published results with p-values that are just significant would replicate in actual replication studies. Even z-scores in the range from 3 to 3.5 average only 32% replicability. Thus, only studies with z-scores greater than 3.5 can be considered to provide some empirical evidence for this claim.
Inspection of the datafile shows that z-scores greater than 3.5 were consistently obtained in 2 out of the 43 articles. Both articles used a more powerful within-subject design.
The automatic evaluation effect: Unconditional automatic attitude activation with a pronunciation task (JPSP, 1996)
Subjective aspects of cognitive control at different stages of processing (Attention, Perception, & Psychophysics, 2009).
Conclusion
John A. Bargh’s work on unconscious processes with unobtrusive priming task is at the center of the replication crisis in psychology. This replicability audit suggests that this is not an accident. The low replicability estimate and the large file-drawer estimate suggest that replication failures are to be expected. As a result, published results cannot be interpreted as evidence for these effects.
So far, John Bargh has ignored criticism of his work. In 2017, he published a popular book about his work on unconscious processes. The book did not mention doubts about the reported evidence, while a z-curve analysis showed low replicability of the cited studies (Schimmack, 2017).
Recently, another study by John Bargh failed to replicate (Chabris et al., in press), and Jessy Singal wrote a blog post about this replication failure (Research Digest) and John Bargh wrote a lengthy comment.
In the commentary, Bargh lists several studies that successfully replicated the effect. However, listing studies with significant results does not provide evidence for an effect unless we know how many studies failed to demonstrate the effect and often we do not know this because these studies are not published. Thus, Bargh continues to ignore the pervasive influence of publication bias.
Bargh then suggests that the replication failure was caused by a hidden moderator which invalidates the results of the replication study.
One potentially important difference in procedure is the temperature of the hot cup of coffee that participants held: was the coffee piping hot (so that it was somewhat uncomfortable to hold) or warm (so that it was pleasant to hold)? If the coffee was piping hot, then, according to the theory that motivated W&B, it should not activate the concept of social warmth – a positively valenced, pleasant concept. (“Hot” is not the same as just more “warm”, and actually participates in a quite different metaphor – hot vs. cool – having to do with emotionality.) If anything, an uncomfortably hot cup of coffee might be expected to activate the concept of anger (“hot-headedness”), which is antithetical to social warmth. With this in mind, there are good reasons to suspect that in C&S, the coffee was, for many participants, uncomfortably hot. Indeed, C&S purchased a hot or cold coffee at a coffee shop and then immediately handed that coffee to passersby who volunteered to take the study. Thus, the first few people to hold a hot coffee likely held a piping hot coffee (in contrast, W&B’s coffee shop was several blocks away from the site of the experiment, and they used a microwave for subsequent participants to keep the coffee at a pleasantly warm temperature). Importantly, C&S handed the same cup of coffee to as many as 7 participants before purchasing a new cup. Because of that feature of their procedure, we can check if the physical-to-social warmth effect emerged after the cups were held by the first few participants, at which point the hot coffee (presumably) had gone from piping hot to warm.
He overlooks that his original study produced only weak evidence for the effect with a p-value of .0503, that is technically not below the .05 value for significance. As shown in the z-curve plot, results with a p-value of .0503 have only an average replicability of 13%. Moreover, the 95%CI for the effect size touches 0. Thus, the original study did not rule out that the effect size is extremely small and has no practical significance. To make any claims that the effect of holding a warm cup on affection is theoretically relevant for our understanding of affection would require studies with larger samples and more convincing evidence.
At the end of his commentary, John A. Bargh assures readers that he is purely motivated by a search for the truth.
Let me close by affirming that I share your goal of presenting the public with accurate information as to the state of the scientific evidence on any finding I discuss publicly. I also in good faith seek to give my best advice to the public at all times, again based on the present state of evidence. Your and my assessments of that evidence might differ, but our motivations are the same.
Let me be crystal clear. I have no reasons to doubt that John A. Bargh believes what he says. His conscious mind sees himself as a scientist who employs the scientific method to provide objective evidence. However, Bargh himself would be the first to acknowledge that our conscious mind is not fully aware of the actual causes of human behavior. I submit that his response to criticism of his work shows that he is less capable of being objective than he thinks he his. I would be happy to be proven wrong in a response by John A. Bargh to my scientific criticism of his work. So far, eminent social psychologists have preferred to remain silent about the results of their replicability audits.
Disclaimer
It is nearly certain that I made some mistakes in the coding of John A. Bargh’s articles. However, it is important to distinguish consequential and inconsequential mistakes. I am confident that I did not make consequential errors that would alter the main conclusions of this audit. However, control is better than trust and everybody can audit this audit. The data are openly available and the data can be submitted to a z-curve analysis using a shinny app. Thus, this replicability audit is fully transparent and open to revision.
Postscript
Many psychologists do not take this work seriously because it has not been peer-reviewed. However, nothing is stopping them from conducting a peer-review of this work and to publish the results of their review as a commentary here or elsewhere. Thus, the lack of peer-review is not a reflection of the quality of this work, but rather a reflection of the unwillingness of social psychologists to take criticism of their work seriously.
If you found this audit interesting, you might also be interested in other replicability audits of eminent social psychologists.
In 1962, Jacob Cohen wrote an important article about a fundamental problem in the way psychologists conduct their studies. He noted that psychologists pay a lot of attention to the problem that a statistically significant result might be a false-positive finding (a so-called type-I error). At the same time, psychologists mostly ignored the complementary error that a study might fail to reject the null-hypothesis when the predicted effect actually exists (a so called type-II error).
It is surprising that researchers would not be concerned with type-II errors because studies are often designed to demonstrate effects and a study is considered a failed study if it does not provide evidence for a predicted effect. Most researchers do not even bother to write up these studies. Given the high investment of researchers in their theories, one would expect that they do everything they can to minimize the risk of failure.
Cohen noted that the type-II error is inversely related to sample size. As sample sizes increase, sampling error decreases, and it becomes easier to demonstrate that an observed effect is a real effect rather than just a random event due to sampling error. Thus, researchers can control the probability of a type-II error by conducting studies with reasonable sample sizes. However, Cohen observed that researchers in the early 1960s used ad-hoc rules (e.g., n = 20 per cell) to plan sample sizes. He concluded that “these nonrational bases for setting sample size must often result in investigations being undertaken which have little chance of success despite the actual falsity of the null hypothesis” (p. 145).
Many psychologists at that time were not aware of more rational ways to determine sample sizes. To address this fundamental problem in psychological research, Cohen provided the first power analysis of psychological research. To conduct this analysis, he examined the statistical results in Volume 61 of the Journal of Abnormal and Social Psychology (which later was split into the Journal of Abnormal Psychology and the Journal of Personality and Social Psychology).
The main purpose of Cohen’s seminal article was to answer the question: “What kind of chance did these investigators have of rejecting false null hypotheses?” (Cohen, 1962, p. 145).
STATISTICAL POWER
The probability of avoiding a type-II error (i.e, obtaining a statistically non-significant result when a predicted effect exists) is called statistical power (Power = 1 – Type-II-Error). The main problem in estimation of statistical power is that statistical power depends on the size of the effect in the population. Psychological theories rarely make precise predictions about effect sizes. Thus, it is not clear what size should be used for a power analysis. Another problem is that the size of an effect depends on the unit of measurement. The effect of sex (men vs. women) on height depends on the measurement of height in centimeters, meters, or inches. To conduct a power analysis of published results, Cohen had to find a way to quantify effect sizes for studies with measures that had different measurement units.
To the best of my knowledge, Cohen (1962) invented standardized effect sizes to deal with this problem. For example, the mean difference in height between men and women would be much smaller if it were measured in meters than if it were measured in centimeters. However, the unit of measurement would have the same effect on the standard deviation, which measures the variability of observed scores in meters or centimeters, or inches. Cohen realized that one can obtain a standardized measurement of the effect size by dividing the mean difference (in meters or centimeters) by the standard deviation (in meters or centimeters). The ratio of means divided by the standard deviation is no longer influenced by the original unit of measurement.
In Cohen’s honor, the mean difference divided by the pooled standard deviation is called Cohen’s d, where d stands for a difference score.
Cohen also introduced the broad distinction between standardized effect sizes into three ordinal categories of effect sizes. Standardized effect sizes could be statistically small (hard to detect), moderate, and large (easy to detect). Nowadays it is often overlooked that the distinction between small and large effects refers to the implications of the effect size for statistical power and it is sometimes argued that small effects lack practical importance or significance. However, statistically small effects can have huge practical importance. For example, relative to the normal variation in temperature in Toronto from a daily high of -10 degrees in winter to 40 degrees in summer, a 4 degree difference may seem small. However, if global warming would raise the average temperature on each day by 4 degrees it could have huge practical implications. Whether an effect is theoretically or practically important is not a statistical question that can be answered by computing a standardized effect size. The primary purpose of standardized effect sizes was to allow researchers to estimate and control type-II errors.
For a mean difference between two groups (a typical scenario in experimental psychology), Cohen called an effect size of d = 25 small, an effect size of d = .50 medium, and an effect size of d = 1 as large (he later revised these values to d = .2, d = .5, and d = .8). He illustrated the implications of these values with IQ scores, which are standardized scores where the average performance on an intelligence test is set to 100. Nowadays, the standard deviation is 15 IQ points, but Cohen used the Stanford-Binet test with a standard deviation of 16 points as an example. He pointed out that conducting a study with an expected population effect size of half a standard deviation (d = .5, medium) is equivalent to a study where a researcher expects an 8 point difference in IQ.
After creating these valuable statistical tools, Cohen (1962) conducted the laborious task of extracting statistical information from the articles published in Volume 61 of the Journal of Abnormal and Social Psychology. There were 78 articles in this volume, but 6 articles did not include statistical tests. The remaining 72 articles reported 4,829 statistical tests. However, not all of these tests were testing a theoretically important hypothesis. Cohen (1962) was concerned that a power analysis of all tests might underestimate power of theoretically important tests. Therefore, he limited his analysis to 2,088 statistical tests of theoretically important hypotheses. Two articles did not report tests of a theoretical hypothesis and were not included, leaving 70 articles.
For each reported result, Cohen computed the power the design and sample size of the statistical test assuming a small, medium, or large effect size. This means, Cohen did not use the actually observed effect sizes for his power calculations. His power estimates are hypothetical estimates for three scenarios with varying degrees of effect sizes.
He then computed the mean power for each article. The results showed that studies had very low power to detect small effects (18% power), modest power to detect medium effects (48% power), and good power to detect large effects (83%). When the analysis was repeated with all statistical tests, very similar results were obtained (20%, 50%, and 83%). The actual power of these studies depends on the unknown effect sizes. Assuming that effect sizes might range from small to large with an average effect size of d = .5, the results would suggest that published results are based on studies with about 50% power.
Cohen next observed that, despite modest power, most articles did report significant results. This might suggest that these studies did examine large effects (d = 1), but Cohen pointed out that “this argument rests on the implicit assumption that the research which is published is representative of the research undertaken in this area” (p. 151). He then pointed out that this assumption is likely to be false. “It seems obvious that investigators are less likely to submit for publication unsuccessful than successful research, to say nothing of a similar editorial bias in accepting research for publication.”
Given reporting bias and publication bias, the percentage of reported significant results (versus non-significant ones) is a poor indicator of the probability that a replication study will also produce a significant result. If the typical effect size were d = .5, only 50% of studies would replicate even if the published literature reports 100% significant results.
Moreover, Cohen assumed that a d = .5 would be a medium effect size for the relationship between two constructs or an experimental variable and a perfectly reliable measure, but statistical tests are based on the observed effects with unreliable measures. Based on this considerations, Cohen suggested that researchers would be optimistic if they conducted power analyses with an effect size of d = .5.
Cohen also noticed that most studies had small samples. The average sample size for the test of a theoretically important effect was N = 68. Given the skewed distribution of sample sizes, the median would be even less. Cohen points out that a between-subject design with n = 34 in each cell (N = 68 total) has 52% power to detect a medium effect size of d = .5. This would suggest that for every published study, there is an unpublished study that produced a non-significant result.
Cohen then points out several ways to increase power. One solution is to increase sample size, but when this is not possible, researchers could use a number of other strategies to increase power. “Other means for increasing power: improving experimental design efficiency and/or experimental control, and renouncing a slavish adherence to a standard Type I level, usually .05.” (p. 153). This means that it is irrational to maintain a 5% type-I error probability in a study that has an 80% type-II error probability because the study examines a small effect with limited resources. In this case, it would make sense to increase the type-I error probability, say to 20%, in order to have a reasonable chance to obtain a statistically significant result. Otherwise, it would be best not to do the study.
Cohen then points out the high cost of conducting studies with small samples and low power. The most likely outcome of these studies is that they produce a non-significant result and remain unpublished. As a result, valuable resources were wasted on studies that were unlikely to produce a meaningful result.
Cohen concludes with the following recommendation.
“Since power is a direct monotonic function of sample size, it is recommended that investigators use larger sample sizes than they customarily do. It is further recommended that research plans be routinely subjected to power analysis, using as conventions the criteria of population effect size employed in this survey” (p. 153).
One can only imagine where psychology would be today, more than half a decade later, if psychologists had taken Cohen’s advice and increased the statistical power of their studies. However, thousands of subject hours have been wasted on underpowered studies that ended up with inconclusive results. Moreover, published studies often achieved significance only because observed effect sizes dramatically overestimated the true population effect sizes. As a result, published results are often not credible and difficult to replicate. The current replication crisis in psychology would not have surprised Cohen. His power analysis from 1960 predicted the dismal success rate in the OSF-reproducibility project (36% success rate, which implies only 36% power in original studies that reported 97% significant results). If psychology doesn’t want to waste another half-decade, it is time to honor Cohen and to start taking type-II errors and power more seriously.
The editor of Psychological Science published an Editorial with the title “Business Not as Usual.” (see also Observer interview and new Submission Guidelines) The new submission guidelines recommend the following statistical approach.
Effective January 2014, Psychological Science recommends the use of the “new statistics”—effect sizes, confidence intervals, and meta-analysis—to avoid problems associated with null-hypothesis significance testing (NHST). Authors are encouraged to consult this Psychological Science tutorial by Geoff Cumming, which shows why estimation and meta-analysis are more informative than NHST and how they foster development of a cumulative, quantitative discipline. Cumming has also prepared a video workshop on the new statistics that can be found here.
The editorial is a response to the current crisis in psychology that many findings cannot be replicated and the discovery that numerous articles in Psychological Science show clear evidence of reporting biases that lead to inflated false-positive rates and effect sizes (Francis, 2013).
The editorial is titled “Business not as usual.” So what is the radical response that will ensure increased replicability of results published in Psychological Science? One solution is to increase transparency and openness to discourage the use of deceptive research practices (e.g., not publishing undesirable results or selective reporting of dependent variables that showed desirable results). The other solution is to abandon null-hypothesis significance testing.
Problem of the Old Statistics: Researchers had to demonstrate that their empirical results could have occurred only with a 5% probability if there is no effect in the population.
Null-hypothesis testing has been the main method to relate theories to empirical data. An article typically first states a theory and then derives a theoretical prediction from the theory. The theoretical prediction is then used to design a study that can be used to test the theoretical prediction. The prediction is tested by computing the ratio of the effect size and sampling error (signal-to-noise) ratio. The next step is to determine the probability of obtaining the observed signal-to-noise ratio or an even more extreme one under the assumption that the true effect size is zero. If this probability is smaller than a criterion value, typically p < .05, the results are interpreted as evidence that the theoretical prediction is true. If the probability does not meet the criterion, the data are considered inconclusive.
However, non-significant results are irrelevant because Psychological Science is only interested in publishing research that supports innovative novel findings. Nobody wants to know that drinking fennel tea does not cure cancer, but everybody wants to know about a treatment that actually cures cancer. So, the main objective of statistical analyses was to provide empirical evidence for a predicted effect by demonstrating that an obtained result would occur only with a 5% probability if the hypothesis were false.
Solution to the problem of Significance Testing: Drop the Significance Criterion. Just report your sample mean and the 95% confidence interval around it.
Eich claims that “researchers have recognized,…, essential problems with NHST in general, and with dichotomous thinking (“significant” vs. “non-significant” ) thinking it engenders in particular. It is true that statisticians have been arguing about the best way to test theoretical predictions with empirical data. In fact, they are still arguing. Thus, it is interesting to examine how Psychological Science found a solution to the elusive problem of statistical inference. The answer is to avoid statistical inferences altogether and to avoid dichotomous thinking. Does fennel tea cure cancer? Maybe, 95%CI d = -.4 to d = +4. No need to test for statistical significance. No need to worry about inadequate sample sizes. Just do a study and report your sample means with a confidence interval. It is that easy to fix the problems of psychological science.
The problem is that every study produces a sample mean and a confidence interval. So, how do the editors of Psychological Science pick the 5% of submitted manuscripts that will be accepted for publication? Eich lists three criteria.
What will the reader of this article learn about psychology that he or she did not know (or could not have known) before?
The effect of manipulation X on dependent variable Y is d = .2, 95%CI = -.2 to .6. We can conclude from this result that it is unlikely that the manipulation leads to a moderate decrease or a strong increase in the dependent variable Y.
Why is that knowledge important for the field?
The finding that the experimental manipulation of Y in the laboratory is somewhat more likely to produce an increase than a decrease, but could also have no effect at all has important implications for public policy.
How are the claims made in the article justified by the methods used?
The claims made in this article are supported by the use of Cumming’s New Statistics. Based on a precision analysis, the sample size was N = 100 (n = 50 per condition) to achieve a precision of .4 standard deviations. The study was preregistered and the data are publicly available with the code to analyze the data (SPPS t-test groups x (1,2) / var y.).
If this sounds wrong to you and you are a member of APS, you may want to write to Erich Eich and ask for some better guidelines that can be used to evaluate whether a sample mean or two or three or four sample means should be published in your top journal.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.