
November 28, Open Draft/Preprint (Version 1.0)
[Please provide comments and suggestions]
In this blog post I present a quantitative review of John A Bargh’s book “Before you know it: The unconscious reasons we do what we do” A quantitative book review is different from a traditional book review. The goal of a quantitative review is to examine the strength of the scientific evidence that is provided to support ideas in the book. Readers of a popular science book written by an eminent scientist expect that these ideas are based on solid scientific evidence. However, the strength of scientific evidence in psychology, especially social psychology has been questioned. I use statistical methods to examine how strong the evidence actually is.
One problem in psychological publishing is publication bias in favor of studies that support theories, so called publication bias. The reason for publication bias is that scientific journals can publish only a fraction of results that scientists produce. This leads to heavy competition among scientists to produce publishable results, and journals like to publish statistically significant results; that is studies that provide evidence for an effect (e.g., “eating green jelly beans cures cancer” rather than “eating red jelly beans does not cure cancer”). Statisticians have pointed out that publication bias undermines the meaning of statistical significance, just like counting only hits would undermine the meaning of batting averages. Everybody would have an incredible batting average of 1.00.
For a long time it was assumed that publication bias is just a minor problem. Maybe researchers conducted 10 studies and reported only 8 significant results while not reporting the remaining two studies that did not produce a significant result. However, in the past five years it has become apparent that publication bias, at least in some areas of the social sciences, is much more severe, and that there are more unpublished studies with non-significant results than published results with significant results.
In 2012, Daniel Kahneman (2012) raised doubts about the credibilty of priming research in an open email letter addressed to John A. Bargh, the author of “Before you know it.” Daniel Kahneman is a big name in psychology; he won a Nobel Prize for economics in 2002. He also wrote a popular book that features John Bargh’s priming research (see review of Chapter 4). Kahneman wrote “As all of you know, of course, questions have been raised about the robustness of priming results…. your field is now the poster child for doubts about the integrity of psychological research.”
Kahneman is not an outright critic of priming research. In fact, he was concerned about the future of priming research and made some suggestions how Bargh and colleagues could alleviate doubts about the replicability of priming results. He wrote:
“To deal effectively with the doubts you should acknowledge their existence and confront them straight on, because a posture of defiant denial is self-defeating. Specifically, I believe that you should have an association, with a board that might include prominent social psychologists from other fields. The first mission of the board would be to organize an effort to examine the replicability of priming results.”
However, prominent priming researchers have been reluctant to replicate their old studies. At the same time, other scientists have conducted replication studies and failed to replicate classic findings. One example is Ap Dijksterhuis’s claim that showing words related to intelligence before taking a test can increase test performance. Shanks and colleagues tried to replicate this finding in 9 studies and came up empty in all 9 studies. More recently, a team of over 100 scientists conducted 24 replication studies of Dijsterhuis’s professor priming study. Only 1 study successfully replicated the original finding, but with a 5% error rate, 1 out of 20 studies is expected to produce a statistically significant result by chance alone. This result validates Shanks’ failures to replicate and strongly suggests that the original result was a statistical fluke (i.e., a false positive result).
Proponent of priming research like Dijksterhuis “argue that social-priming results are hard to replicate because the slightest change in conditions can affect the outcome” (Abbott, 2013, Nature News). Many psychologists consider this response inadequate. The hallmark of a good theory is that it predicts the outcome of a good experiment. If the outcome depends on unknown factors and replication attempts fail more often than not, a scientific theory lacks empirical support. For example, Kahneman wrote in an email that the apparent “refusal to engage in a legitimate scientific conversation … invites the interpretation that the believers are afraid of the outcome” (Abbott, 2013, Nature News).
It is virtually impossible to check on all original findings by conducting extensive and expensive replication studies. Moreover, proponents of priming research can always find problems with actual replication studies to dismiss replication failures. Fortunately, there is another way to examine the replicability of priming research. This alternative approach, z-curve, uses a statistical approach to estimate replicability based on the results reported in original studies. Most important, this approach examines how replicable and credible original findings were based on the results reported in the original articles. Therefore, original researches cannot use inadequate methods or slight variations in contextual factors to dismiss replication failures. Z-curve can reveal that the original evidence was not as strong as dozens of published studies may reveal because it takes into account that published studies were selected to provide evidence for priming effects.
My colleagues and I used z-curve to estimate the average replicability of priming studies that were cited in Kahneman’s chapter on priming research. We found that the average probability of a successful replication was only 14%. Given the small number of studies (k = 31), this estimate is not very precise. It could be higher, but it could also be even lower. This estimate would imply that for each published significant result, there are 9 unpublished non-significant results that were omitted due to publication bias. Given these results, the published significant results provide only weak empirical support for theoretical claims about priming effects. In a response to our blog post, Kahneman agreed (“What the blog gets absolutely right is that I placed too much faith in underpowered studies”).
Our analysis of Kahneman’s chapter on priming provided a blue print for this quantitative book review of Bargh’s book “Before you know it.” I first checked the notes for sources and then linked the sources to the corresponding references in the reference section. If the reference was an original research article, I downloaded the original research article and looked for the most critical statistical test of a study. If an article contained multiple studies, I chose one test from each study. I found 168 usable original articles that reported a total of 400 studies. I then converted all test statistics into absolute z-scores and analyzed them with z-curve to estimate replicability (see Excel file for coding of studies).
Figure 1 shows the distribution of absolute z-scores. 90% of test statistics were statistically significant (z > 1.96) and 99% were at least marginally significant (z > 1.65), meaning they passed a less stringent statistical criterion to claim a success. This is not surprising because supporting evidence requires statistical significance. The more important question is how many studies would produce a statistically significant result again if all 400 studies were replicated exactly. The estimated success rate in Figure 1 is less than half (41%). Although there is some uncertainty around this estimate, the 95% confidence interval just reaches 50%, suggesting that the true value is below 50%. There is no clear criterion for inadequate replicability, but Tversky and Kahneman (1971) suggested a minimum of 50%. Professors are also used to give students who scored below 50% on a test an F. So, I decided to use the grading scheme at my university as a grading scheme for replicability scores. So, the overall score for the replicability of studies cited by Bargh to support the ideas in his book is F.

This being said, 41% replicability is a lot more than we would expect by chance alone, namely 5%. Clearly some of the results mentioned in the book are replicable. The question is which findings are replicable and which ones are difficult to replicate or even false positive results. The problem with 41% replicable results is that we do not know which results we can trust. Imagine you are interviewing 100 eyewitnesses and only 42 of them are reliable. Would you be able to identify a suspect?
It is also possible to analyze subsets of studies. Figure 2 shows the results of all experimental studies that randomly assigned participants to two or more conditions. If a manipulation has an effect, it produces mean differences between the groups. Social psychologists like these studies because they allow for strong causal inferences and make it possible to disguise the purpose of a study. Unfortunately, this design requires large samples to produce replicable results and social psychologists often used rather small samples in the past (the rule of thumb was 20 per group). As Figure 2 shows, the replicability of these studies is lower than the replicability of all studies. The average replicability is only 24%. This means for every significant result there are at least three non-significant results that have not been reported due to the pervasive influence of publication bias.
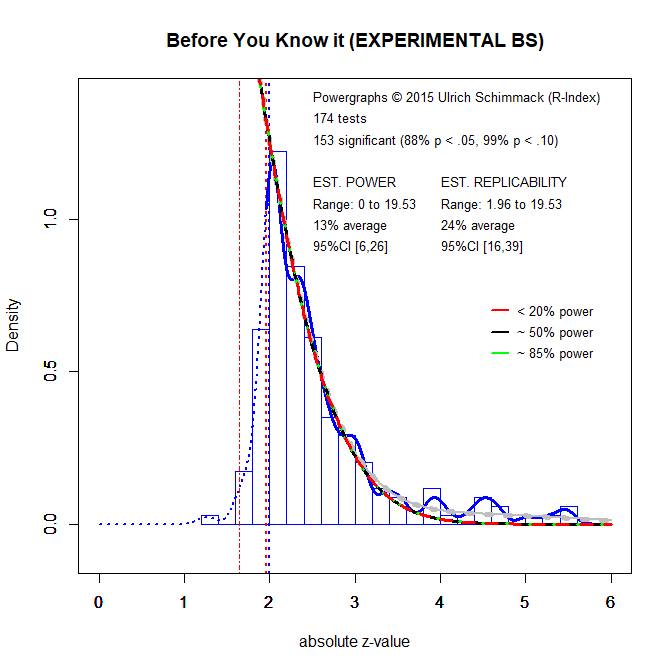
If 24% doesn’t sound bad enough, it is important to realize that this estimate assumes that the original studies can be replicated exactly. However, social psychologists have pointed out that even minor differences between studies can lead to replication failures. Thus, the success rate of actual replication studies is likely to be even less than 24%.
In conclusion, the statistical analysis of the evidence cited in Bargh’s book confirms concerns about the replicability of social psychological studies, especially experimental studies that compared mean differences between two groups in small samples. Readers of the book should be aware that the results reported in the book might not replicate in a new study under slightly different conditions and that numerous claims in the book are not supported by strong empirical evidence.
Replicability of Chapters
I also estimated the replicability separately for each of the 10 chapters to examine whether some chapters are based on stronger evidence than others. Table 1 shows the results. Seven chapters scored an F, two chapters scored a D, and one chapter earned a C-. Although there is some variability across chapters, none of the chapters earned a high score, but some chapters may contain some studies with strong evidence.
Table 1. Chapter Report Card
| Chapter 1 | 28 | F |
| Chapter 2 | 40 | F |
| Chapter 3 | 13 | F |
| Chapter 4 | 47 | F |
| Chapter 5 | 50 | D- |
| Chapter 6 | 57 | D+ |
| Chapter 7 | 24 | F |
| Chapter 8 | 19 | F |
| Chapter 9 | 31 | F |
| Chapter 10 | 62 | C- |
Credible Findings in the Book
Unfortunately, it is difficult to determine the replicability of individual studies with high precision. Nevertheless, studies with high z-scores are more replicable. Particle physicists use a criterion value of z > 5 to minimize the risk that the results of a single study are not a false positive. I found that psychological studies with a z-score greater than 4 had an 80% chance of being replicated in actual replication studies. Using this rule as a rough estimate of replicability, I was also able to identify credible claims in the book. Highlighting these claims does not mean that the other claims are wrong. It simply means that they are not supported by strong evidence.
Chapter 1:
According to Chapter 1, there seems “to be a connection between the strength of the unconscious physical safety motivation and a person’s political attitudes.” The notes list a number of articles to support this claim. The only conclusive evidence in these studies is that self-reported political attitudes (a measure of right-wing authoritarianism) is correlated with self-reported beliefs that the world is dangerous (Duckitt et al., JPSP, 2002, 2 studies, z = 5.42, 6.93). The correlation between self-report measures is hardly evidence for unconscious physical safety motives.
Another claim is that “our biological mandate to reproduce can have surprising manifestations in today’s world.” This claim is linked to a study that examined the influence of physical attractiveness on call backs for a job interview. In a large field experiment, researchers mailed (N = 11,008 resumes) to real job ads and found that both men and women were more likely to be called for an interview if the application included a picture of a highly attractive applicant versus a not so attractive applicant (Busetta et al., 2013, z = 19.53). Although this is an interesting and important finding, it is not clear that the human resource offices preference for attractive applicants was driven by their “biological mandate to reproduce.”
Chapter 2:
Chapter 2 introduces the idea that there is a fundamental connection between physical sensations and social relationships. “… why today we still speak so easily of a warm friend, or a cold father. We always will. Because the connection between physical and social warmth, and between physical and social coldness, is hardwired into the human brain.” Only one z-score surpassed the 4-sigma threshold. This z-score comes from a brain imaging study that found increased sensorimotor activation in response to hand-washing products (soap) after participants had lied in a written email, but not after they had lied verbally; Schaefer et al., 2015, z = 4.65). There are two problems with this supporting evidence. First, z-scores in fMRI studies require a higher threshold than z-scores in other studies because brain imaging studies allow for multiple comparisons that increase the risk of a false positive result (Vul et al., 2009). More important, even if this finding could be replicated, it does not provide support for the claim that these neurological connections are hard-wired into humans’ brains.
The second noteworthy claim in Chapter 2 is that infants “have a preference for their native language over other languages, even though they don’t yet understand a word.” This claim is not very controversial given ample evidence that humans’ prefer familiar over unfamilar stimuli (Zajonc, 1968, also cited in the book). However, it is not so easy to study infants’ preferences (after all, they are not able to tell us). Developmental researchers use a visual attention task to infer preferences. If an infant looks longer at one of two stimuli, it indicates a preference for this stimulus. Kinzler et al. (PNAS, 2007) reported six studies. For five studies, z-scores ranged from 1.85 to 2.92, which is insufficient evidence to draw strong conclusions. However, Study 6 provided convincing evidence (z = 4.61) that 5-year old children in Boston preferred a native speaker to a child with a French accent. The effect was so strong that 8 children were sufficient to demonstrate it. However, a study with 5-year olds hardly provides evidence for infants’ preferences. In addition, the design of this study holds all other features constant. Thus, it is not clear how strong this effect is in the real world when many other factors can influence the choice of a friend.
Chapter 3
Chapter 3 introduces the concept of priming. “Primes are like reminders, whether we are aware of the reminding or not” It uses two examples to illustrate priming with and without awareness. One example implies that people can be aware of the primes that influenced their behavior. If you are in the airport, smell Cinnabon, and find yourself suddenly in front of the Cinnabon counter you are likely to know that the smell made you think about Cinnabon and decide to eat one. The second example introduces the idea that primes can influence behavior without awareness. If you were caught off in traffic, you may respond more hostile to a transgression of a co-worker without being aware that the earlier experience in traffic influenced your reaction. The supporting references contain two noteworthy (z > 4) findings that show how priming can be used effectively as reminders (Rogers & Milkman, 2016, Psychological Science, Studies 2a (N = 920, z = 5.45) and Study 5 (N = 305, z = 5.50). In Study 2a, online participants were presented with the following instruction:
In this survey, you will have an opportunity to
support a charitable organization called Gardens
for Health that provides lasting agricultural
solutions to address the problem of chronic
childhood malnutrition. On the 12th page of this
survey, please choose answer “A” for the last
question on that page, no matter your opinion. The
previous page is Page 1. You are now on Page 2.
The next page is Page 3. The picture below will
be on top of the NEXT button on the 12th page.
This is intended to remind you to select
answer “A” for the last question on that page. If you
follow these directions, we will donate $0.30 to
Gardens for Health.

On pages 2-11 participants either saw distinct animals or other elephants.

Participants in the distinct animal condition were more likely to press the response that led to a donation than participants who saw a variety of elephants (z = 5.45).
Study 5 examined whether respondents would be willing to pay for a reminder. They were offered 60 cents extra payment for responding with “E” to the last question. They could either pay 3 cents to get an elephant reminder or not. 53% of participants were willing to pay for the reminder, which the authors compared to 0, z = 2 × 10^9. This finding implies that participants are not only aware of the prime when they respond in the primed way, but are also aware of this link ahead of time and are willing to pay for it.
In short, Chapter 3 introduces the idea of unconscious or automatic priming, but the only solid evidence in the reference section supports the notion that we can also be consciously aware of priming effects and use them to our advantage.
Chapter 4
Chapter 4 introduces the concept of arousal transfer; the idea that arousal from a previous event can linger and influence how we react to another event. The book reports in detail a famous experiment by Dutton and Aaron (1974).
“In another famous demonstration of the same effect, men who had just crossed a rickety pedestrian bridge over a deep gorge were found to be more attracted to a woman they met while crossing that bridge. How do we know this? Because they were more likely to call that woman later on (she was one of the experimenters for the study and had given these men her number after they filled out a survey for her) than were those who met the same woman while crossing a much safer bridge. The men in this study reported that their decision to call the woman had nothing to do with their experience of crossing the scary bridge. But the experiment clearly showed they were wrong about that, because those in the scary-bridge group were more likely to call the woman than were those who had just crossed the safe bridge.”
First, it is important to correct the impression that men were asked about their reasons to call back. The original article does not report any questions about motives. This is the complete section in the results that mentions the call back.
“Female interviewer. In the experimental group, 18 of the 23 subjects who agreed to
the interview accepted the interviewer’s phone number. In the control group, 16 out of 22 accepted (see Table 1). A second measure of sexual attraction was the number of subjects who called the interviewer. In the experimental group 9 out of 18 called, in the control group 2 out of 16 called (x2 = 5.7, p < .02). Taken in conjunction with the sexual
imagery data, this finding suggests that subjects in the experimental group were more
attracted to the interviewer.”
A second concern is that the sample size was small and the evidence for the effect was not very strong. In the experimental group 9 out of 18 called, in the control
group 2 out of 16 called (x2 = 5.7, p < .02) [z = 2.4].
Finally, the authors mention a possible confound in this field study. It is possible that men who dared to cross the suspension bridge differ from men who crossed the safe bridge, and it has been shown that risk taking men are more likely to engage in casual sex. Study 3 addressed this problem with a less colorful, but more rigorous experimental design.
Male students were led to believe that they were participants in a study on electric shock and learning. An attractive female confederate (a student working with the experimenter but pretending to be a participants) was also present. The study had four conditions. Male participants were told that they would receive weak or strong shock and they were told that the female confederate would receive weak or strong shock. They then were asked to fill out a questionnaire before the study would start; in fact, the study ended after participants completed the questionnaire and they were told about the real purpose of the study.
The questionnaire contained two questions about the attractive female confederate. “How much would you like to kiss her?” and “How much would you like to ask her out on a date?” Participants who were anticipating strong shock had much higher average ratings than those who anticipated weak shock, z = 4.46.
Although this is a strong finding, we also have a large literature on emotions and arousal that suggests frightening your date may not be the best way to get to second base (Reisenzein, 1983; Schimmack, 2005). It is also not clear whether arousal transfer is a conscious or unconscious process. One study cited in the book found that exercise did not influenced sexual arousal right away, presumably because participants attributed their increased heart rate to the exercise. This suggests that arousal transfer is not entirely an unconscious process.
Chapter 4 also brings up global warming. An unusually warm winter day in Canada often make people talk about global warming. A series of studies examined the link between weather and beliefs about global warming more scientifically. “What is fascinating (and sadly ironic) is how opinions regarding this issue fluctuate as a function of the very climate we’re arguing about. In general, what Weber and colleagues found was that when the current weather is hot, public opinion holds that global warming is occurring, and when the current weather is cold, public opinion is less concerned about global warming as a general threat. It is as if we use “local warming” as a proxy for “global warming.” Again, this shows how prone we are to believe that what we are experiencing right now in the present is how things always are, and always will be in the future. Our focus on the present dominates our judgments and reasoning, and we are unaware of the effects of our long-term and short-term past on what we are currently feeling and thinking.”
One of the four studies produced strong evidence (z = 7.05). This study showed a correlation between respondents’ ratings of the current day’s temperature and their estimate of the percentage of above average warm days in the past year. This result does not directly support the claim that we are more concerned about global warming on warm days for two reasons. First, response styles can produce spurious correlations between responses to similar questions on a questionnaire. Second, it is not clear that participants attributed above average temperatures to global warming.
A third credible finding (z = 4.62) is from another classic study (Ross & Sicoly, 1974, JPSP, Study 2a). “You will have more memories of yourself doing something than of your spouse or housemate doing them because you are guaranteed to be there when you do the chores. This seems pretty obvious, but we all know how common those kinds of squabbles are, nonetheless. (“I am too the one who unloads the dishwasher! I remember doing it last week!”)” In this study, 44 students participated in pairs. They were given separate pieces of information and exchange information to come up with a joint answer to a set of questions. Two days later, half of the participants were told that they performed poorly, whereas the other half was told that they performed well. In the success condition, participants were more likely to make self-attributions (i.e., take credit) than expected by chance.
Chapter 5
In Chapter 5, John Bargh tell us about work by his supervisor Robert Zajonc (1968). “Bob was doing important work on the mere exposure effect, which is, basically, our tendency to like new things more, the more often we encounter them. In his studies, he repeatedly showed that we like them more just because they are shown to us more often, even if we don’t consciously remember seeing them” The 1968 classic article contains two studies with strong evidence (Study 2, z = 6.84, Study 3 z = 5.81). Even though the sample sizes were small, this was not a problem because the studies presented many stimuli at different frequencies to all participants. This makes it easy to spot reliable patterns in the data.
Chapter 5 also introduces the concept of affective priming. Affective priming refers to the tendency to respond emotionally to a stimulus even if a task demands to ignore it. We simply cannot help to feel good or bad and turn our emotions off. The experimental way to demonstrate this is to present an emotional stimulus quickly followed by a second emotional stimulus. Participants have to respond to the second stimulus and ignore the first stimulus. It is easier to perform the task when the two stimuli have the same valence, suggesting that the valence of the first stimulus was processed even though participants had to ignore it. Bargh et al. (1996, JESP) reported that this even happens when the task is simply to pronounce the second word (Study 1 z = 5.42, Study 2 z = 4.13, Study 3, z = 3.97).
The book does not inform readers that we have to distinguish two types of affective priming effects. Affective priming is a robust finding when participants’ task is to report on the valence (is it good or bad) of the second stimulus following the prime. However, this finding has been interpreted by some researches as an interference effect, similar to the Stroop effect. This explanation would not predict effects on a simple pronounciation task. However, there are fewer studies with the pronounciation task and some of these have failed to replicate Bargh et al.’s original findings, despite the strong evidence observed in their studies. First, Klauer and Musch (2001) failed to replicate Bargh et al.’s findings that affective priming influences pronunciation of target words in three studies with good statistical power. Second, DeHouwer et al. (2001) were able to replicate it with degraded primes, but also failed to replicate the effect with visible primes that were used by Bargh et al. In conclusion, affective priming is a robust effect when participants have to report on the valence of the second stimulus, but this finding does not necessarily imply that primes unconsciously activate related content in memory.
Chapter 5 also reports about some surprising associations between individuals’ names, or better their initials, and the places they live, professions, and partners. These correlations are relatively small, but they are based on large datasets and very unlikely to be just statistical flukes (z-scores ranging from 4.65 to 49.44). The causal process underlying these correlations is less clear. One possible explanation is that we have unconscious preferences that influence our choices. However, experimental studies that tried to study this effect in the laboratory are less convincing. Moreover, Hodson and Olson failed to find a similar effect across a variety of domains such as liking of animals (Alicia is not more likely to like ants than Samantha), foods, or leisure activities. They found a significant correlation for brand names (p = .007), but this finding requires replication. More recently, Kooti, Magno, and Weber (2014) examined name effects on social media. They found significant effects for some brand comparisons (Sega vs. Nintendo), but not for others (Pepsi vs. Coke). However, they found that twitter users were more likely to follow other twitter uses with the same first name. Taken together, these results suggest that individuals’ names predict some choices, but it is not clear when or why this is the case.
The chapter ends with a not very convincing article (z = 2.39, z = 2.22) that it is actually very easy to resist or override unwanted priming effects. According to this article, simply being told that somebody is a team member can make automatic prejudice go away. If it were so easy to control unwanted feelings, it is not clear why racism is still a problem 50 years after the civil rights movement started.
In conclusion Chapter 5 contains a mix of well-established findings with strong support (mere-exposure effects, affective priming) and several less supported ideas. One problem is that priming is sometimes presented as an unconscious process that is difficult to control and at other times these effects seem to be easily controllable. The chapter does not illuminate under which conditions we should suspect priming to influence our behavior in ways we don’t notice or cannot control and when we notice them and have the ability to control them.
Chapter 6
Chapter 6 deals with the thorny problem in psychological science that most theories make correct predictions sometimes. Even a broken clock tells the time right twice a day. The problem is to know in which context a theory makes correct predictions and when it does not.
“Entire books—bestsellers—have appeared in recent years that seem to give completely conflicting advice on this question: can we trust our intuitions (Blink, by Malcolm Gladwell), or not (Thinking, Fast and Slow, by Daniel Kahneman)? The answer lies in between. There are times when you can and should, and times when you can’t and shouldn’t [trust your gut].
Bargh then proceeds to make 8 evidence-based recommendation when it is advantages to rely on intuition without effortful deliberation (gut feelings).
Rule #1: supplement your gut impulse with at least a little conscious reflection, if you have the time to do so.
Rule # 2: when you don’t have the time to think about it, don’t take big chances for small gains going on your gut alone.
Rule #3: when you are faced with a complex decision involving many factors, and especially when you don’t have objective measurements (reliable data) of those important factors, take your gut feelings seriously.
Rule #4: be careful what you wish for, because your current goals and needs will color what you want and like in the present.
Rule #5: when our initial gut reaction to a person of a different race or ethnic group is negative, we should stifle it.
Rule #6: we should not trust our appraisals of others based on their faces alone, or on photographs, before we’ve had any interaction with them.
Rule #7: (it may be the most important one of all): You can trust your gut about other people—but only after you have seen them in action.
Rule #8: it is perfectly fine for attraction be one part of the romantic equation, but not so fine to let it be the only, or even the main, thing.
Unfortunately, the credible evidence in this chapter (z > 4) is only vaguely related to these rules and insufficient to claim that these rules are based on solid scientific evidence.
Morewedge and Norton (2009) provide strong evidence that people in different cultures (US z = 4.52, South Korea z = 7.18, India z = 6.78) believe that dreams provide meaningful information about themselves. Study 3 used a hypothetical scenario to examine whether people would change their behavior in response to a dream. Participants were more likely to say that they would change a flight after dreaming about a plane crash in the night before the flight than if they thought about a plane crash the evening before and dreams influenced behavior about as much as hearing about an actual plane crash (z = 10.13). In a related article, Morewedge and colleagues (2014) asked participants to rate types of thoughts (e.g., dreams, problem solving, etc.) in terms of spontaneity or deliberation. A second rating asked about the extent to which the type of thought would generate self-insight or is merely a reflection of the current situation. They found that spontaneous thoughts were considered to generate more self-insight (Study 1 z = 5.32, Study 2 z = 5.80). In Study 5, they also found that more spontaneous recollection of a recent positive or negative experience with their romantic partner predicted hypothetical behavioral intention ratings (““To what extent might recalling the experience affect your likelihood of ending the relationship, if it came to mind when you tried to remember it”) (z = 4.06). These studies suggest that people find spontaneous, non-deliberate thoughts meaningful and that they are willing to use them in decision making. The studies do not tell us under which circumstances listening to dreams and other spontaneous thoughts (gut feelings) is beneficial.
Inbar, Cone, and Gilovich (2010) created a set of 25 choice problems (e.g., choosing an entree, choosing a college). They found that “the more a choice was seen as objectively evaluable, the more a rational approach was seen as the appropriate choice strategy” (Study 1a, z = 5.95). In a related study, they found “the more participants
thought the decision encouraged sequential rather than holistic processing, the more they thought it should be based on rational analysis” (Study 1b, z = 5.02). These studies provide some insight into people’s beliefs about optimal decision rules, but they do not tell us whether people’s beliefs are right or wrong, which would require to examine people’s actual satisfaction with their choices.
Frederick (2005) examined personality differences in the processing of simple problems (e.g., A bat and a ball cost $1.10. The bat costs $1.00 more than the ball. How much does the ball cost?). The quick answer is 10 cent, but the correct answer is 5 cent. In this case, the gut response is false. A sample of over 3,000 participants answered several similar questions. Participants who performed above average were more willing to delay gratification (get $3,800 in a month rather than $3,400 now) than participants with below average performance (z > 5). If we consider the bigger reward a better choice, these results imply that it is not good to rely on gut responses when it is possible to use deliberation to get the right answer.
Two studies by Wilson and Schooler (1991) are used to support the claim that we can overthink choices.
“In their first study, they had participants judge the quality of different brands of jam, then compared their ratings with those of experts. They found that the participants who were asked to spend time consciously analyzing the jam had preferences that differed further from those of the experts, compared to those who responded with just the “gut” of their taste buds.” The evidence in this study with a small sample is not very strong and requires replication (N = 49, z = 2.36).
“In Wilson and Schooler’s second study, they interviewed hundreds of college students about the quality of a class. Once again, those who were asked to think for a moment about their decisions were further from the experts’ judgments than were those who just went with their initial feelings.”
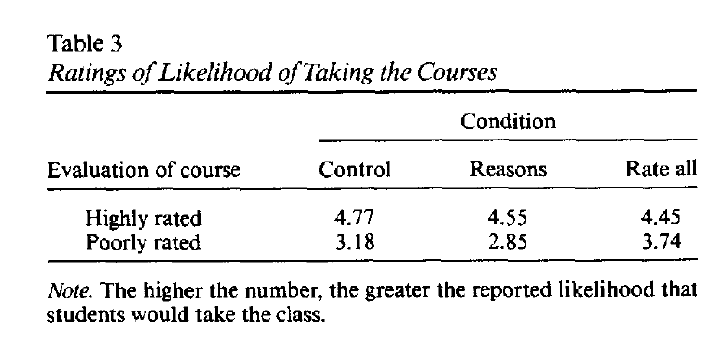
The description in the book does not match the actual study. There were three conditions. In the control condition, participants were asked to read the information about the courses carefully. In the reasons condition, participants were asked to write down their reasons. and in the rate all condition participants were asked to rate all pieces of information, no matter how important, in terms of its effect on their choices. The study showed that considering all pieces of information increased the likelihood of choosing a poorly rated course (a bad choice), but had a much smaller effect on ratings of highly rated courses (z = 4.14 for the interaction effect). All conditions asked for some reflection and it remains unclear how students would respond if they went with their initial feelings, as described in the book. Nevertheless, the study suggests that good choices require focusing on important factors and paying attention to trivial factors can lead to suboptimal choices. For example, real estate agents in hot markets use interior design to drive up prices even though the design is not part of the sale.
We are born sensitive to violations of fair treatment and with the ability to detect those who are causing harm to others, and assign blame and responsibility to them. Recent research has shown that even children three to five years old are quite sensitive to fairness in social exchanges. They preferred to throw an extra prize (an eraser) away than to give more to one child than another—even when that extra prize could have gone to themselves. This is not an accurate description of the studies. Study 1 (z > 5) found that 6 to 8 year old children preferred to give 2 erasers to one kid and 2 erasers to another kid and to throw the fifth eraser away to maintain equality (20 out of 20, p < .0001). However, “the 3-to 5-year-olds showed no preference to throw a resource away (14 out of 24, p = .54)” (p. 386). Subsequent studies used only 6-8 year old children. Study 4 examined how children would respond if erasers are divided between themselves and another kid. 17 out of 20 (p = .003, z = 2.97 preferred to throw the eraser away rather than getting one more for themselves. However, in a related article, Shaw and Olson, 2012b) found that children preferred favoritism (getting more erasers) when receiving more erasers was introduced as winning a contest (Study 2, z = 4.65). These studies are quiet interesting, but they do not support the claim that equality norms are inborn, nor do they help us to figure out when we should or should not listen to our gut or whether it is better for us to be equitable or selfish.
The last, but in my opinion most interesting and relevant, piece of evidence in Chapter 6 is a large (N = 16,624) survey study of relationship satisfaction (Cacioppo et al., 2013, PNAS, z = 6.58). Respondents reported their relationship satisfaction and how they had met. Respondents who had met their partner online were slightly more satisfied than respondents who had met their partner offline. There were also differences between different types of meeting online. Respondents who met their partner in a bar had one of the lowest average level of satisfaction. The study did not reveal why online dating is slightly more successful, but both forms of dating probably involve a combination of deliberation and “gut” reactions.
In conclusion, Chapter 6 provides some interesting insights into the way people make choices. However, the evidence does not provide a scientific foundation for recommendations when it is better to follow your instinct and when it is better to rely on logical reasoning and deliberation. Either the evidence of the reviewed studies is too weak or the studies do not use actual choice outcomes as outcome variable. The comparison of online and offline dating is a notable exception.
Chapter 7
Chapter 7 uses an impressive field experiment to support the idea that “our mental representations of concepts such as politeness and rudeness, as well as innumerable other behaviors such as aggression and substance abuse, become activated by our direct perception of these forms of social behavior and emotion, and in this way are contagious.” Keizer et al. (2008) conducted the study in an alley in Groningen, a city in the Netherlands. In one condition, bikes were parked in front of a wall with graffiti, despite an anti-graffiti sign. In the other condition, the wall was clean. Researchers attached fliers to the bikes and recorded how many users would simply throw the fliers on the ground. They recorded the behaviors of 77 bike riders in each condition. In the graffiti condition, 69% of riders littered. In the clean condition, only 33% of riders littered (z = 4.51).

In Study 2, the researchers put up a fence in front of the entrance to a car park that required car owners to walk an extra 200m to get to their car, but they left a gap that allowed car owners to avoid the detour. There was also a sign that forbade looking bikes to the fence. In one condition, bikes were not locked to the fence. In the experimental condition, the norm was violated and four bikes were locked to the fence. 41 car owners’ behaviors were observed in each condition. In the experimental condition, 82% of participants stepped through the gap. In the control condition, only 27% of car owners stepped through the gap (z = 5.27).

It is unlikely that bike riders or car owners in these studies consciously processed the graffiti or the locked bikes. Thus, these studies support the hypothesis that our environment can influence behavior in subtle ways without our awareness. Moreover, these studies show these effects with real-world behavior.
Another noteworthy study in Chapter 7 examined happiness in social networks (Fowler & Christakis, 2008). The authors used data from the Framingham Heart Study, which is a unique study where most inhabitants of a small town, Framingham, participated in the study. Researchers collected many measures, including a measure of happiness. They also mapped social relationships among them. Fowler and Christakis used sophisticated statistical methods to examine whether people who were connected in the social network (e.g., spouses, friends, neighbors) had similar levels of happiness. They did (z = 9.09). I may be more likely to believe these findings because I have found this in my own research on married couples (Schimmack & Lucas, 2010). Spouses are not only more similar to each other at one moment in time, they also change in the same direction over time. However, the causal mechanism underlying this effect is more elusive. Maybe happiness is contagious and can spread through social networks like a disease. However, it is also possible that related members in social networks are exposed to similar environments. For example, spouses share a common household income and money buys some happiness. It is even less clear whether these effects occur outside of people’s awareness or not.
Chapter 8 ends with the positive message that a single person can change the word because his or her actions influence many people. “The effect of just one act, multiplies and spreads to influence many other people. A single drop becomes a wave” This rosy conclusion overlooks that the impact of one person decreases exponentially when it spreads over social networks. If you are kind to a neighbor, the neighbor may be slightly more likely to be kind to the pizza delivery man, but your effect on the pizza delivery man is already barely noticeable. This may be a good thing when it comes to the spreading of negative behaviors. Even if the friend of a friend is engaging in immoral behaviors, it doesn’t mean that you are more likely to commit a crime. To really change society it is important to change social norms and increase individuals’ reliance on these norms even when situational influences tell them otherwise. The more people have a strong norm not to litter, the less it matters whether there are graffiti on the wall or not.
Chapter 8
Chapter 8 examines dishonesty and suggests that dishonesty is a general human tendency. “When the goal of achievement and high performance is active, people are more likely to bend the rules in ways they’d normally consider dishonest and immoral, if doing so helps them attain their performance goal”
Of course, not all people cheat in all situations even if they think they can get away with it. So, the interesting scientific question is who will be dishonest in which context?
Mazar et al. (2008) examined situational effects on dishonesty. In Study 2 (z = 4.33) students were given an opportunity to cheat in order to receive a higher reward. The study had three conditions, a control condition that did not allow students to cheat, a cheating condition, and a cheating condition with an honor pledge. In the honor pledge condition, the test started with the sentence “I understand that this short survey falls under MIT’s [Yale’s] honor system”. This manipulation eliminated cheating. However, even in the cheating condition “participants cheated only 13.5% of the possible average magnitude. Thus, MIT/Yale students are rather honest or the incentive was too small to tempt them (an extra $2). Study 3 found that students were more likely to cheat if they were rewarded with tokens rather than money, even though they later could exchange tokens for money. The authors suggests that cheating merely for tokens rather than real money made it seem less like “real” cheating (z = 6.72).
Serious immoral acts cannot be studied experimentally in a psychology laboratory. Therefore, research on this topic has to rely on self-report and correlations. Pryor (1987) developed a questionnaire to study “Sexual Harassment Proclivities in Men.” The questionnaire asks men to imagine being in a position of power and to indicate whether they would take advantage of their power to incur sexual favors if they know they can get away with it. To validate the scale, Pryor showed that it correlated with a scale that measures how much men buy into rape myths (r = .40, z = 4.47). Self-reports on these measures have to be taken with a grain of salt, but the results suggest that some men are willing to admit that they would abuse power to gain sexual favors, at least in anonymous questionnaires.
Another noteworthy study found that even prisoners are not always dishonest. Cohn et al. (2015) used a gambling task to study dishonesty in 182 prisoners in a maximum security prison. Participants were given the opportunity to flip 10 coins and to keep all coins that showed head. Importantly, the coin toss was not observed. As it is possible, although unlikely, that all 10 coins show head by chance, inmates could keep all coins and hide behind chance. The randomness of the outcome makes it impossible to accuse a particular prisoner of dishonesty. Nevertheless, the task makes it possible to measure dishonesty of the group (collective dishonesty) because the percentage of coin tosses that were reported should be close to chance (50%). If it is significantly higher than chance, it shows that some prisoners were dishonest. On average, prisoners reported 60% head, which reveals some dishonesty, but even convicted criminals were more likely to respond honestly than not (the percentage increased from 60% to 66% when they were primed with their criminal identity, z = 2.39).
I see some parallels between the gambling task and the world of scientific publishing, at least in psychology. The outcome of a study is partially determined by random factors. Even if a scientist does everything right, a study may produce a non-significant result due to random sampling error. The probability of observing a non-significant result is called a type-II error. The probability of observing a significant result is called statistical power. Just like in a coin toss experiment, the observed percentage of significant results should match the expected percentage based on average power. Numerous studies have shown that researchers report more significant results than the power of their studies justifies. As in the coin toss experiment, it is not possible to point the finger at a single outcome because chance might have been in a researcher’s favor, but in the long run the odds “cannot be always in your favor” (Hunger Games). Psychologists disagree whether the excess of significant results in psychology journals should be attributed to dishonesty. I think it is and it fits Bargh’s observation that humans, and most scientists are humans, have a tendency to bend the rules when doing so helps them to reach their goal, especially when the goal is highly relevant (e.g., get a job, get a grant, get tenure). Sadly, the extent of over-reporting significant results is considerably larger than the 10 to 15% overreporting of heads in the prisoner study.
Chapter 9
Chapter 9 introduces readers to Metcalfe’s work on insight problems (e.g., how to put 27 animals into 4 pens so that there is an odd number of animals in all four pens). Participants had to predict quickly whether they would be able to solve the problem. They then got 5 minutes to actually solve the problem. Participants were not able to predict accurately which insight problems they would solve. Metcalfe concluded that the solution for insight problems comes during a moment of sudden illumination that is not predictable. Bargh adds “This is because the solver was working on the problem unconsciously, and when she reached a solution, it was delivered to her fully formed and ready for use.” In contrast, people are able to predict memory performance on a recognition test, even when they were not able to recall the answer immediately. This phenomenon is known as the tip-of-the-tongue effect (z = 5.02). This phenomenon shows that we have access to our memory even before we can recall the final answer. This phenomenon is similar to the feeling of familiarity that is created by mere exposure (Zajonc, 1968). We often know a face is familiar without being able to recall specific memories where we encountered it.
The only other noteworthy study in Chapter 9 was a study of sleep quality (Fichten et al., 2001). “The researchers found that by far, the most common type of thought that kept them awake, nearly 50 percent of them, was about the future, the short-term events coming up in the next day or week. Their thoughts were about what they needed to get done the following day, or in the next few days.” It is true that 48% thought about future short-term events, but only 1% described these thoughts as worries, and 57% of these thoughts were positive. It is not clear, however, whether this category distinguished good and poor sleepers. What distinguished good sleepers from poor sleepers, especially those with high distress, was the frequency of negative thoughts (z = 5.59).
Chapter 10
Chapter 10 examines whether it is possible to control automatic impulses. Ample research by personality psychologists suggests that controlling impulses is easier for some people than others. The ability to exert self-control is often measured with self-report measures that predict objective life outcomes.
However, the book adds a twist to self-control. “The most effective self-control is not through willpower and exerting effort to stifle impulses and unwanted behaviors. It comes from effectively harnessing the unconscious powers of the mind to much more easily do the self-control for you.”
There is a large body of strong evidence that some individuals, those with high impulse control and conscientiousness, perform better academically or at work (Tangney et al., 2004; Study 1 z = 5.90, Galla & Duckworth, Studies 1, 4, & 6, Ns = 488, 7.62, 5.18). Correlations between personality measures and outcomes do not reveal the causal mechanism that leads to these positive outcomes. Bargh suggests that individuals who score high on self-control measures are “the ones who do the good things less consciously, more automatically, and more habitually. And you can certainly do the same.” This maybe true, but empirical work to demonstrate this is hard to find. At the end of the chapter, Bargh cites a recent study by Milyavskaya and Michael Inzlicht that suggested avoiding temptations is more important than being able to exert self-control in the face of temptation, willful or unconsciously.
Conclusion
The book “Before you know it: The unconscious reasons we do what we do” is based on the authors’ personal experiences, studies he has conducted, and studies he has read. The author is a scientist and I have no doubt that he shares with his readers insights that he believes to be true. However, this does not automatically make them true. John Bargh is well aware that many psychologists are skeptical about some of the findings that are used in the book. Famously, some of Bargh’s own studies have been difficult to replicate. One response to concerns about replicability could have been new demonstrations that important unconscious priming effects can be replicated. In an interview Tom Bartlett (January, 2013) suggested this to John Bargh.
“So why not do an actual examination? Set up the same experiments again, with additional safeguards. It wouldn’t be terribly costly. No need for a grant to get undergraduates to unscramble sentences and stroll down a hallway. Bargh says he wouldn’t want to force his graduate students, already worried about their job prospects, to spend time on research that carries a stigma. Also, he is aware that some critics believe he’s been pulling tricks, that he has a “special touch” when it comes to priming, a comment that sounds like a compliment but isn’t. “I don’t think anyone would believe me,” he says.”
Beliefs are subjective. Readers of the book have their own beliefs and may find part of the book interesting and may be willing to change some of their beliefs about human behavior. Not that there is anything wrong with this, but readers should also be aware that it is reasonable to treat the ideas presented in this book with a healthy does of skepticism. In 2011, Daniel Kahneman wrote ““disbelief is not an option. The results are not made up, nor are they statistical flukes. You have no choice but to accept that the major conclusions of these studies are true.” Five years later, it is pretty clear that Kahneman is more skeptical about the state of priming research and results of experiments with small samples in general. Unfortunately, it is not clear which studies we can believe until replication studies distinguish real effects from statistical flukes. So, until we have better evidence, we are still free to belief what we want about the power of unconscious forces on our behavior.
Hello,
This is a great review with a lot of time, effort, and thought put into it.
I am doing a similar review (which is ongoing) whereby I select some of the studies in the book and critiqued the source studies (i.e. the mere presence of a woman led to impaired cognition in men). If you have the time, I would appreciate your thoughts on my two posts (I’m trying to get a sciency blog going):
https://alexithymicblogger.wordpress.com/
Kind regards