Blogging about statistical power, replicability, and the credibility of statistical results in psychology journals since 2014. Home of z-curve, a method to examine the credibility of published statistical results.
Show your support for open, independent, and trustworthy examination of psychological science by getting a free subscription. Register here.
“For generalization, psychologists must finally rely, as has been done in all the older sciences, on replication” (Cohen, 1994).
DEFINITION OF REPLICABILITY: In empirical studies with sampling error, replicability refers to the probability of a study with a significant result to produce a significant result again in an exact replication study of the first study using the same sample size and significance criterion (Schimmack, 2017).
See Reference List at the end for peer-reviewed publications.
Mission Statement
The purpose of the R-Index blog is to increase the replicability of published results in psychological science and to alert consumers of psychological research about problems in published articles.
To evaluate the credibility or “incredibility” of published research, my colleagues and I developed several statistical tools such as the Incredibility Test (Schimmack, 2012); the Test of Insufficient Variance (Schimmack, 2014), and z-curve (Version 1.0; Brunner & Schimmack, 2020; Version 2.0, Bartos & Schimmack, 2021).
I have used these tools to demonstrate that several claims in psychological articles are incredible (a.k.a., untrustworthy), starting with Bem’s (2011) outlandish claims of time-reversed causal pre-cognition (Schimmack, 2012). This article triggered a crisis of confidence in the credibility of psychology as a science.
Over the past decade it has become clear that many other seemingly robust findings are also highly questionable. For example, I showed that many claims in Nobel Laureate Daniel Kahneman’s book “Thinking: Fast and Slow” are based on shaky foundations (Schimmack, 2020). An entire book on unconscious priming effects, by John Bargh, also ignores replication failures and lacks credible evidence (Schimmack, 2017). The hypothesis that willpower is fueled by blood glucose and easily depleted is also not supported by empirical evidence (Schimmack, 2016). In general, many claims in social psychology are questionable and require new evidence to be considered scientific (Schimmack, 2020).
Each year I post new information about the replicability of research in 120 Psychology Journals (Schimmack, 2021). I also started providing information about the replicability of individual researchers and provide guidelines how to evaluate their published findings (Schimmack, 2021).
Replication is essential for an empirical science, but it is not sufficient. Psychology also has a validation crisis (Schimmack, 2021). That is, measures are often used before it has been demonstrate how well they measure something. For example, psychologists have claimed that they can measure individuals’ unconscious evaluations, but there is no evidence that unconscious evaluations even exist (Schimmack, 2021a, 2021b).
If you are interested in my story how I ended up becoming a meta-critic of psychological science, you can read it here (my journey).
References
Brunner, J., & Schimmack, U. (2020). Estimating population mean power under conditions of heterogeneity and selection for significance. Meta-Psychology, 4, MP.2018.874, 1-22 https://doi.org/10.15626/MP.2018.874
Schimmack, U. (2012). The ironic effect of significant results on the credibility of multiple-study articles. Psychological Methods, 17, 551–566 http://dx.doi.org/10.1037/a0029487
Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology/Psychologie canadienne, 61(4), 364–376. https://doi.org/10.1037/cap0000246
In the 17th century, early telescopic observations of Mars suggested that the planet might be populated. Now imagine a study that aims to examine whether Martians are taller than humans. The problem is obvious: although we may assume that Martians exist, we cannot observe or measure them, and therefore we end up with zero observations of Martian height. Would we blame the t-test for not telling us what we want to know? I hope your answer to this rhetorical question is “No, of course not.”
If you pass this sanity check, the rest of this post should be easy to follow. It responds to criticism by Erik van Zwet (EvZ), hosted and endorsed by Andrew Gelman on his blog,
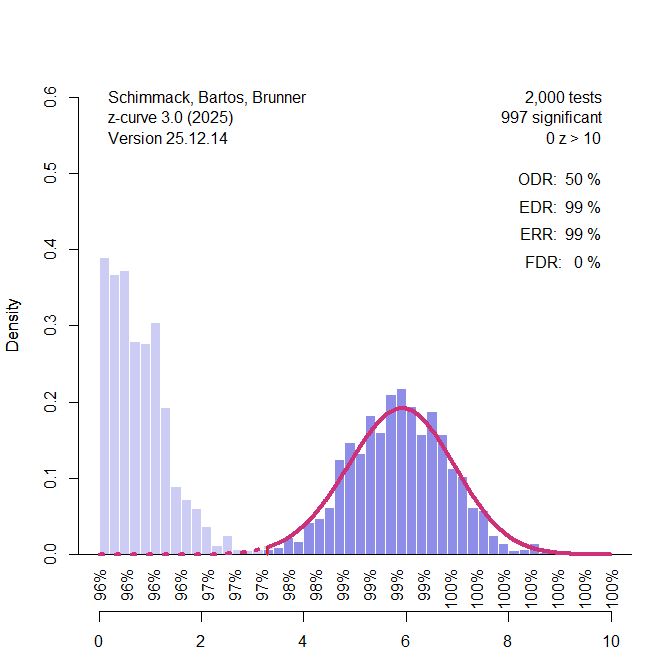
EvZ imagines a scenario in which z-curve is applied to data generated by two distinct lines of research. One lab conducts studies that test only true null hypotheses. While exact effect sizes of zero may be rare in practice, attempting to detect extremely small effects in small samples is, for all practical purposes, equivalent. A well-known example comes from early molecular genetic research that attempted to link variation in single genes—such as the serotonin transporter gene—to complex phenotypes like Neuroticism. It is now well established that these candidate-gene studies produced primarily false positive results when evaluated with the conventional significance threshold of α = .05.
In response, molecular genetics fundamentally changed its approach. Researchers began testing many genetic variants simultaneously and adopted much more stringent significance thresholds to control the multiple-comparison problem. In the simplified example used here, I assume α = .001, implying an expected false positive rate of only 1 in 1,000 tests. I further assume that truly associated genetic predictors—single nucleotide polymorphisms (SNPs)—are tested in very large samples, such that sampling error is small and true effects yield z-values around 6. This is, of course, a stylized assumption, but it serves to illustrate the logic of the critique.
Figure 1 illustrates a situation with 1,000 studies from each of these two research traditions. Among the 1,000 candidate-gene studies, only one significant result is expected by chance. Among the genome-wide association studies (GWAS), power to reject the null hypothesis at α = .001 is close to 1, although a small number (3–4 out of 1,000) of studies may still fail to reach significance.
At this point, it is essential to distinguish between two scenarios. In the first scenario, all 999 non-significant results are observed and available for analysis. If we could recover the full distribution of results—including non-significant ones—we could fit models to the complete set of z-values. Z-curve can, in principle, be applied to such data, but it was not designed for this purpose.
Z-curve was developed for the second scenario. In this scenario, the light-purple, non-significant results exist only in researchers’ file drawers and are not part of the observed record. This situation—selection for statistical significance—is commonly referred to as publication bias. In psychology, success rates above 90% strongly suggest that statistical significance is a necessary condition for publication (Sterling, 1959). Under such selection, non-significant results provide no observable information, and only significant results remain. In extreme cases, it is theoretically possible that all published significant findings are false positives (Rosenthal, 1979), and in some literatures—such as candidate-gene research or social priming—this possibility is not merely theoretical.
Z-curve addresses uncertainty about the credibility of published significant results by explicitly conditioning on selection for significance and modeling only those results. When success rates approach 90% or higher, there is often no alternative: non-significant results are simply unavailable.
In Figure 1, the light-purple bars represent non-significant results that exist only in file drawers. Z-curve is fitted exclusively to the dark-purple, significant results. Based on these data, the fitted model (red curve), which is centered near the true value of z = 6, correctly infers that the average true power of the studies contributing to the significant results is approximately 99% when α = .001 (corresponding to a critical value of z ≈ 3.3).
Z-curve also estimates the Expected Discovery Rate (EDR). Importantly, the EDR refers to the average power of all studies that were conducted in the process of producing the observed significant results. This conditioning is crucial. Z-curve does not attempt to estimate the total number of studies ever conducted, nor does it attempt to account for studies from populations that could not have produced the observed significant findings. In this example, candidate-gene studies that produced non-significant results—whether published or not—are irrelevant because they did not contribute to the set of significant GWAS results under analysis.
What matters instead is how many GWAS studies failed to reach significance and therefore remain unobserved. Given the assumed power, this number is at most 3–4 out of 1,000 (<1%). Consequently, an EDR estimate of 99% is correct and indicates that publication bias within the relevant population of studies is trivial. Because the false discovery rate is derived from the EDR, the implied false positive risk is effectively zero—again, correctly so for this population.
EvZ’s criticism of z-curve is therefore based on a misunderstanding of the method’s purpose and estimand. He evaluates z-curve against a target that includes large numbers of studies that leave no trace in the observed record and have no influence on the distribution of significant results being analyzed. But no method that conditions on observed significant results can recover information about such studies—nor should it be expected to.
Z-curve is concerned exclusively with the credibility of published significant results. Non-significant studies that originate from populations that do not contribute to those results are as irrelevant to this task as the height of Martians.
A recent critique of z-curve reported low coverage of confidence intervals for the expected discovery rate (EDR) based on an extreme simulation with a very low expected false positive rate (about 1–2%). This conclusion conflates expected values with realized data. In repeated runs, the number of false positives among significant results varies substantially and is often zero; in those runs the realized false discovery rate is exactly zero, so an estimate of zero is correct. When coverage is evaluated against realized false positive rates, the apparent problem is substantially reduced. Additional simulations show that coverage approaches the nominal level once false positives are non-negligible (e.g., 5%) and improves further with larger numbers of significant results. Remaining coverage failures are confined to diagnostically identifiable cases in which high-powered studies dominate the distribution of significant z-values, leaving limited information to estimate the EDR.
On Evaluating Evidence and Interpreting Simulation Results
Science advances through skepticism. It progresses by testing claims against evidence and by revisiting conclusions when new information becomes available. This process requires not only sound data, but also careful interpretation of what those data can and cannot tell us.
In principle, academic debate should resolve disagreements by subjecting competing interpretations to scrutiny. In practice, however, disagreements often persist. One reason is that people—scientists included—tend to focus on evidence that aligns with their expectations while giving less weight to evidence that challenges them. Another is that conclusions are sometimes used, implicitly or explicitly, to justify the premises that led to them, rather than the other way around.
These concerns are not personal; they are structural. They arise whenever complex methods are evaluated under simplified criteria.
Context of the Current Discussion
Z-curve was developed to evaluate the credibility of a set of statistically significant results. It operates on the distribution of significant test statistics and estimates quantities such as the expected replication rate (ERR), the expected discovery rate (EDR), and the false discovery rate (FDR). Its performance has been evaluated using extensive simulation studies covering hundreds of conditions that varied effect sizes, heterogeneity, and false positive rates.
A recent critique raised concerns about z-curve based on a simulation in which confidence intervals for the EDR showed low coverage. From this result, it was suggested that the method is unreliable (“concerns about z-curve“).
It is useful to examine carefully what this simulation does and how its results are interpreted.
Expected Values and Realized Data
The simulation assumes two types of studies: some that test true null hypotheses and others that test false null hypotheses with very high power. From this setup, one can compute expected values—for example, the expected number of false positives or the expected discovery rate.
Expected values, however, are averages over many hypothetical repetitions. In individual simulation runs, the realized number of false positives varies. In particular, when the expected number of false positives is close to one, it is common for some runs to contain no false positives among the significant results. In those runs, the observed significant record contains no false discoveries, and the realized false discovery rate for that record is exactly zero.
Evaluating coverage by comparing z-curve estimates to a fixed expected value in every run overlooks this variability. It treats a population-level expectation as if it were the true value for each realized dataset, even when the realized data are inconsistent with that expectation. This issue is most pronounced in near-boundary settings, where the quantities of interest are weakly identifiable from truncated data.
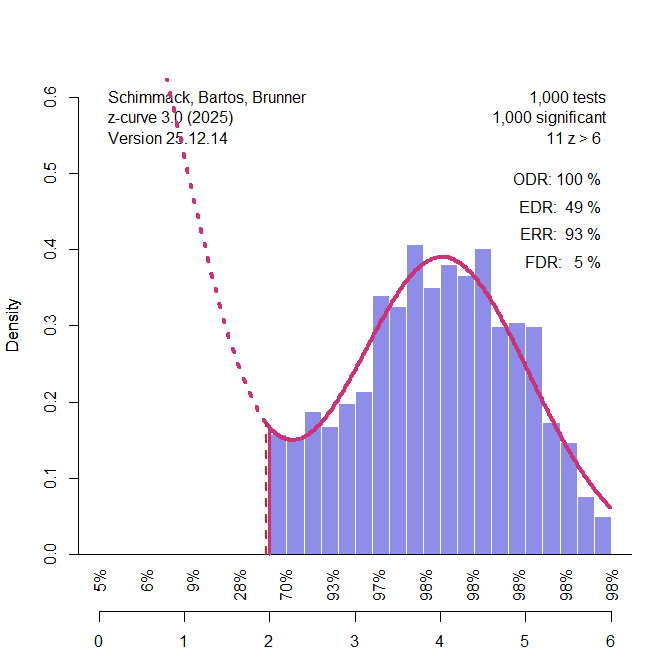
The simulation uses an extreme configuration to illustrate a potential limitation of z-curve. The setup assumes two populations of studies: one repeatedly tests a true null hypothesis (H0), and the other tests a false null hypothesis with very high power (approximately 98%, corresponding to z ≈ 4). Z-curve is applied only to statistically significant results, consistent with its intended use.
In the specific configuration, there are 25 tests of a true H0 and 75 tests of a false H0 with 98% power. From this design, one can compute expected values: on average, 25 × .05 = 1.25 false positives are expected, implying a false discovery rate of about 1.6% among significant results. However, these values are expectations across repeated samples; they are not fixed quantities that hold in every simulation run.
Because the expected number of false positives is close to one, sampling variability is substantial. In some runs, no false positive enters the set of significant results at all. In those runs, it is not an error if z-curve assigns zero weight to the null component and estimates an FDR of zero; that estimate matches the realized composition of the observed significant results.
When I reproduced the simulation and counted the number of false positives among the significant results, I found that the realized count ranged from 0 to 5, and that 152 out of 500 runs contained no false positives. This matters for interpreting coverage: comparing z-curve estimates in these runs to the expected false discovery rate of 1.6% treats a population-level expectation as if it were the true value for each realized dataset. As a result, the reported undercoverage is driven by a mismatch between the evaluation target and the realized data in a substantial subset of runs, rather than by a general failure of z-curve.
Reexamining Z-curve Performance with Extreme Mixtures
To examine z-curve’s performance with extreme mixtures of true and false H0, I ran a new simulation that sampled 5 significant results from tests of true H0 and 95 significant results from tests of false H0 with 98% power. I used a false positive rate of 5%, because a 5% false positive rate may be considered the boundary value for an acceptable error rate. Importantly, increasing it further would benefit z-curve because it becomes easier to detect the presence of low powered hypothesis tests.
As expected, the coverage of the EDR increased. In fact, it was just shy of the nominal level of 95%, 471/500 (94%). Thus, low coverage is limited to data with fewer than 5% false positive results. For example, the model may suggest no false positives, but the true false positive rate is 4%.
It is also possible to diagnose data that can create problems with coverage. First, a decreasing slope from significance to z = 3 implies a large number of missing non-significant results that can be identified by their influence on the distribution of significant z-values. In contrast a flat or positive slope suggests that high powered studies have a stronger influence on the distribution of z-values between 2 and 3. I computed the slope using the kernel density of the observed data and regressing the densities on the z-values. A positive slope perfectly predicted bad coverage, 29/29 (100%).
Another diagnostic is the ERR. A high ERR implies that most studies have high power and that there are few low powered studies with significant results to estimate the EDR. All failures occurred when the ERR was above 90%.
Finally, we can use the weights of the low powered components (z = 0, z = 1). When these weights are zero, it is possible that the model had problems estimating these components. In all failures, both weights were zero.
Importantly, these results also show that z-curve does not inevitably fail under this type of mixture. The issue is not the false positive rate per se, but the amount of information available to estimate it. With the same false positive rate of 5%, but a larger number of significant results—for example, 50 false positives out of 1,000—z-curve reliably detects the presence of missing non-significant results, even when the slope is increasing and the ERR is high. In this case, the weight of the z = 0 component was estimated at approximately 52%. By contrast, when the estimated weight is zero and the FDR estimate is zero, the true false discovery rate may still be as high as 5%, reflecting weak identifiability rather than estimator bias.
Conclusion
The low coverage reported in this simulation is largely an evaluation artifact. In this extreme setup, the expected false positive rate (about 1–2%) is an average across runs, but the realized number of false positives among significant results varies; in many runs it is zero. In those runs, the realized FDR is exactly zero, so an estimate of zero is not an error. Treating the expected rate as the “true value” in every run mechanically produces undercoverage.
When the false discovery rate is modest (e.g., 5%) and the number of significant results is larger, coverage is close to nominal and improves further as information increases. The remaining failures are confined to diagnostically identifiable cases in which high-powered studies dominate the significant z-values, leaving too little information to estimate the EDR.
One major contribution to the growing awareness that psychological research is often unreliable was an article by Daryl Bem (2011), which reported nine barely statistically significant results to support the existence of extrasensory perception—most memorably, that extraverts could predict the future location of erotic images (“pornception”).
Subsequent replication attempts quickly failed to reproduce these findings (Galak et al., 2012). This outcome was not especially newsworthy; few researchers believed the substantive claim. The more consequential question was how seemingly strong statistical evidence could be produced for a false conclusion.
Under the conventional criterion of p<.05, one false positive is expected by chance roughly 1 out of 20 times. However, obtaining statistically significant results in nine out of nine studies purely by chance is extraordinarily unlikely (Schimmack, 2012). This pattern strongly suggests that the data-generating process was biased toward significance.
Schimmack (2018) argued that the observed bias in Bem’s (2011) findings was best explained by questionable research practices (John et al., 2012). For example, unpromising studies may be abandoned and later characterized as pilot work, whereas more favorable results may be selectively aggregated or emphasized, increasing the likelihood of statistically significant outcomes. Following the publication of the replication failures, a retraction was requested. In response, the then editor, Shinobu Kitayama, declined to pursue retraction, citing that the practices in question were widespread in social psychology at the time and were not treated as clear violations of prevailing norms (Kitayama, 2018).
After more than a decade of methodological debate and reform, ignorance is no longer a credible defense for the continued use of questionable research practices. This is especially true when articles invoke open science practices—such as preregistration, transparent reporting, and data sharing—to signal credibility: these practices raise the expected standard of methodological competence and disclosure, not merely the appearance of rigor.
Nevertheless, there are growing concerns that preregistration alone is not sufficient to ensure valid inference. Preregistered studies can still yield misleading conclusions if auxiliary assumptions are incorrect, analytic choices are poorly justified, or deviations and contingencies are not transparently handled (Soto & Schimmack, 2025).
Against this backdrop, Francis (2024) published a statistical critique of Ongchoco, Walter-Terrill, and Scholl’s (2023) PNAS article reporting seven preregistered experiments on visual event boundaries and anchoring. Using a Test of Excess Significance (“excess success”) argument, Francis concluded that the uniformly significant pattern—particularly the repeated significant interaction effects—was unlikely under a no-bias, correctly specified model, reporting p=.011. This result does not establish the use of questionable research practices; it shows only that the observed pattern of results is improbable under the stated assumptions, though chance cannot be ruled out.
Ongchoco, Walter-Terrill, and Scholl (2024) responded by challenging both the general validity of excess-success tests and their application to a single article. In support, they cite methodological critiques—especially Simonsohn (2012, 2013)—arguing that post hoc excess-success tests can generate false alarms when applied opportunistically or when studies address heterogeneous hypotheses.
They further emphasize preregistration, complete reporting of preregistered studies, and a preregistered replication with increased sample size as reasons their results should be considered credible—thereby raising the question of whether the significant findings themselves show evidential value, independent of procedural safeguards.
The appeal to Simonsohn is particularly relevant here because Simonsohn, Nelson, and Simmons (2014) introduced p-curve as a tool for assessing whether a set of statistically significant findings contains evidential value even in the presence of selective reporting or p-hacking. P-curve examines the distribution of reported significant p-values (typically those below .05). If the underlying effect is null and significance arises only through selection, the distribution is expected to be approximately uniform across the .00–.05 range. If a real effect is present and studies have nontrivial power, the distribution should be right-skewed, with a greater concentration of very small p-values (e.g., < .01).
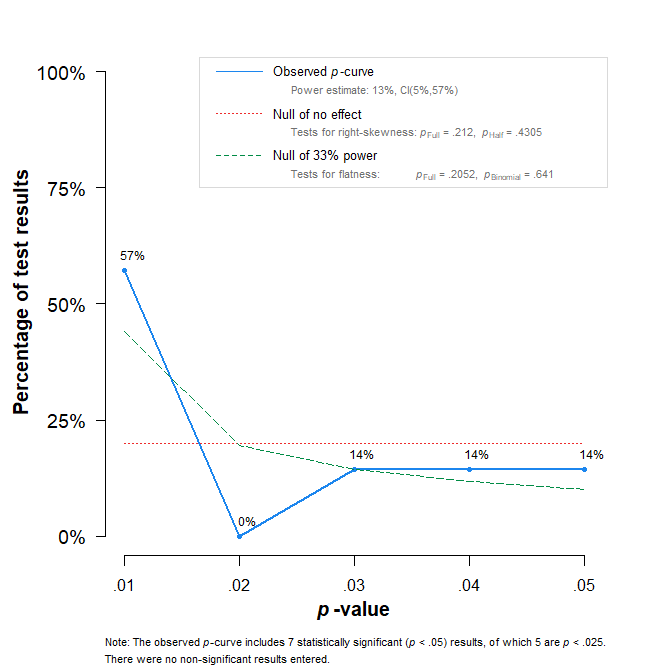
I therefore conducted a p-curve analysis to assess the evidential value of the statistically significant results reported in this research program. Following Simonsohn et al. (2014), I focused on the focal interaction tests bearing directly on the core claim that crossing a visual event boundary (e.g., walking through a virtual doorway) attenuates anchoring effects. Specifically, I extracted the reported p-values for the anchoring-by-boundary interaction terms across the preregistered experiments in Ongchoco, Walter-Terrill, and Scholl (2023) and evaluated whether their distribution showed the right-skew expected under genuine evidential value.
The p-curve analysis provides no evidence of evidential value for the focal interaction effects. Although all seven tests reached nominal statistical significance, the distribution of significant p-values does not show the right-skew expected when results are driven by a genuine effect. Formal tests for right-skewness were non-significant (full p-curve: p=.212; half p-curve: p=.431), indicating that the results cannot be distinguished from patterns expected under selective success or related model violations.
Consistent with this pattern, the p-curve-based estimate of average power is low (13%). Although the confidence interval is wide (5%–57%), the right-skew tests already imply failure to reject the null hypothesis of no evidential value. Moreover, even under the most generous interpretation—assuming 57% power for each test—the probability of obtaining seven statistically significant results out of seven is approximately 0.577≈.020. Thus, invoking Simonsohn’s critiques of excess-success testing is not sufficient, on its own, to restore confidence in the evidential value of the reported interaction effects.
Some criticisms of Francis’s single-article bias tests also require careful handling. A common concern is selective targeting: if a critic applies a bias test to many papers but publishes commentaries only when the test yields a small p-value, the published set of critiques will overrepresent “positive” alarms. Importantly, this publication strategy does not invalidate any particular p-value; it affects what can be inferred about the prevalence of bias findings from the published subset.
Francis (2014) applied an excess-success test to multi-study articles in Psychological Science (2009–2012) and reported that a large proportion exhibited patterns consistent with excess success (often summarized as roughly 82% of eligible multi-study articles). Under a high-prevalence view—i.e., if such model violations are common—an individual statistically significant bias-test result is less likely to be a false alarm than under a low-prevalence view. The appropriate prevalence for preregistered studies, however, remains uncertain.
Additional diagnostics help address this uncertainty. The “lucky-bounce” test (Schimmack, unpublished) illustrates the improbability of observing only marginally significant results when studies are reasonably powered. Under a conservative assumption of 80% power, the probability that all seven interaction effects fall in the “just significant” range (.005–.05) is approximately .00022. Although this heuristic test is not peer-reviewed, it highlights the same improbability identified by other methods.
A closely related, peer-reviewed approach is the Test of Insufficient Variance (TIVA). TIVA does not rely on significance thresholds; instead, it tests whether a set of independent test statistics (expressed as z-values) exhibits at least the variance expected under a standard-normal model (Var(z)≥1). Conceptually, it is a left-tailed chi-square test on the variance of z-scores. Because heterogeneity in power or true effects typically increases variance, evidence of insufficient variance is conservative. With the large sample sizes in these studies, transforming F-values to t- and approximate z-values is reasonable. Applying TIVA to the seven interaction tests yields p=.002, indicating that the dispersion of the test statistics is unusually small under the assumption of independent tests.
These results do not establish that the seven statistically significant findings are all false positives, nor do they identify a specific mechanism. They do show, however, that perfect significance can coexist with weak evidential value: even in preregistered research, a uniformly significant pattern can be statistically inconsistent with the assumptions required for straightforward credibility.
Given these results, an independent, well-powered replication is warranted. The true power of the reported studies is unlikely to approach 80% even with sample sizes of 800 participants; if it did, at least one p-value would be expected below .005. Absent such evidence, perfect success should not be taken as evidence that a robust effect has been established.
In conclusion, the replication crisis has sharpened awareness that researchers face strong incentives to publish and that journals—especially prestigious outlets such as PNAS—prefer clean, internally consistent narratives. Open science practices have improved transparency, but it remains unclear whether they are sufficient to prevent the kinds of model violations that undermined credibility before the crisis. Fortunately, methodological reform has also produced more informative tools for evaluating evidential value.
For researchers seeking credible results, the practical implication is straightforward: avoid building evidential claims on many marginally powered studies. Rather than running seven underpowered experiments in the hope of success, conduct one adequately powered study—and, if necessary, a similarly powered preregistered replication (Schimmack, 2012). Multi-study packages are not inherently problematic, but when “picture-perfect” significance becomes the implicit standard, they increase the risk of selective success and overinterpretation. Greater awareness that such patterns can be detected statistically may help authors, reviewers, and editors better weigh these trade-offs.
Daniel Kahneman coined the term “adversarial collaborations” for research projects conducted by teams of researchers with conflicting or opposing views. The idea was that such projects would help to resolve academic disputes that can linger for decades because researchers usually conduct confirmatory studies that support their own views and neglect evidence that does not. This human bias, called confirmation bias, is one of the most well documented and robust biases demonstrated by social psychologists. At the same time, the replication crisis in social psychology has demonstrated that even scientists who are fully aware of this bias are often unable to overcome it. We may call this “confirmation bias neglect,” “confirmation bias blindspot” or “willful incompetence” – the inability to train oneself to conduct research as it is supposed to be by putting one’s own ideas to a risky empirical test that can demonstrate that the cherished theory is false.
Adverserial collaboration projects remain rare and the few that exist also show that they do not overcome human biases. Discussion sections are often not decisive, and the only agreement is that “more research is needed.” Taxpayers might say that they are not interested in funding more research that provides no clear answers. Much of social psychology is more infotainment than science.
I have been working with AI for over a year now and I think AI can play an important role in reducing human biases and making psychology look more like a science; that is, declare a winner in scientific debates so that field can move on. This blog post is just a little demonstration what this might look like.
The example comes from a debate in statistics. Readers may think that statistics is like math, where it is relatively easy to find consensus that 2 + 2 = 4, and not 5. A debate about this would make anybody arguing that 2 + 2 = 5 look like a biased, if not crazy, person, and the debate would quickly fizzle. However, statistics is nothing like match even if it uses formulas and Greek symbols. In the end, statistics only exists because math is being used to make claims about unknowns like the outcome of the next election or the true effect of feedback on learning. Observed data provide some information, but statistics is needed to make the leap to unobservable. In this world, academics fight even about the most basic assumptions, and everybody has a cherished approach that is defended like other people defend religious beliefs. Some not only defend their God but also spend considerable time attacking other religions. In this world, 2 + 2 can be 4, 5, or infinite.
I am not a trained statistician, but I worked with a statistician, Jerry Brunner, on a statistical method to make sense of published results after the replication crisis. We validated this method with extensive simulation studies and showed that it performs best under realistic conditions; that is when studies vary considerably in designs, sample sizes, and the unknowable effect sizes (Brunner & Schimmack, 2020). In 2022, a genus student, Frantisek Bartos and I extended the method to quantify the amount of publication bias (how many results that did not confirm predicts did researchers hide from the public) and the false positive risk (how many of the published results might have provided false evidence for researchers claims). Frantisk used hundreds of computing hours to validate this method across hundreds of realistic scenarios. Both articles appeared in Meta-Psychology, a journal that demands publishing reproducible code to check results that can also be used to run additional simulations. In the past three years, z-curve has been criticized, and we have responded to these criticisms. For example, z-curve can show bias when samples are tiny (N < 30). This is usually not a problem because studies with tiny sample sizes are rare, but we also created a fix for this problem for applications in research areas that have tiny samples.
Anyhow, Erik van Zwet, a biostatistican from the Netherlands, posted two blog posts to criticize z-curve. Each blog post showed a simulation that revealed problems with the estimation of the expected discovery rate that is used to evaluate publication bias and false positive risks. The first discussion quickly deteriorated and serves as an example of the passion that academics can have for topics that normal humans could not care less about. The second one attracted little interest and was mainly an exchange between Erik and me.
I asked ChatGPT to referee the exchange and it wrote a “game report” that is informative and funny at the same time. Importantly, I won, but barely. The outcome is less important than the neutral and balanced report. The main advantage of AI is not that it has superintelligence. It’s main strength is that it does not care about the outcome of the game. The desire to be right is the Kryptonite of academics. Calls for humility are nice, but unrealistic. Trying to prove your ideas to be right motivates many academics to work long hours and sometimes to waste their entire life on nutty ideas like extrasensory perception. AI may help us individually and collectively to avoid this mistake.
(Technically decisive win for Ulrich, but with avoidable late fouls.)
First half
Erik goals (2)
(6′) Framing the agenda Erik successfully sets the frame: undercoverage of EDR CIs, bootstrap collapse, and model misspecification. This is a legitimate opening and forces engagement.
(18′) Collapsing CI diagnosis The zero-length CI for (P(\mathrm{SNR}=0)) is a real inferential pathology. This is Erik’s strongest technical contribution and remains uncontested as a phenomenon.
Ulrich goals (2)
(25′) Extensive validation defense Ulrich correctly invokes prior large-scale simulations and reproducibility checks. This blunts any claim that z-curve was casually or narrowly validated.
(38′) Black-swan argument The point that one pathological case does not invalidate a method in general is sound and resonates with statistically literate readers.
Second half
Erik goals (2)
(52′) Model-uncertainty critique Erik’s argument that bootstrap CIs reflect sampling uncertainty but ignore model uncertainty is correct in principle and applies to mixture models under misspecification.
(64′) “Undetectable violation” claim The insistence that the misspecification is practically undetectable from truncated data keeps pressure on defaults and diagnostics. This is a fair methodological concern.
Ulrich goals (3)
(70′) vj intervention (assist credited to Ulrich) The vj comment decisively reframes the issue:
identifies perfect power homogeneity,
explains weak identification of EDR,
localizes the failure to a knife-edge case.
This is a major momentum shift.
(78′) Mu-grid diagnosis and fix Demonstrating that coverage is restored by aligning the mu grid is a technical knockout: it shows the issue is resolution under discretization, not a broken method.
(85′) Final Ulrich comment (heterogeneity + alternatives) This is your strongest direct response:
acknowledges the edge case,
explains why it is unrealistic,
cites known alternatives (moving μ, random-effects),
and challenges Erik to generalize his claim.
Substantively, this closes the loop.
Own goals
Ulrich — Own Goals (2)
(44′) Early defensive tone The initial “he does not hear me” framing and appeal to Erik’s past review role weakened the epistemic high ground.
(90’+2) P.S. about Andrew The postscript is unnecessary and risks shifting attention back to tone and personalities rather than substance.
Erik — Own Goals (3)
(60′) Escalation to personal insinuation Claims of harassment, editorial intervention, and “you haven’t read the post” add heat but no inferential value.
(88′) Latest reply (“comforting thought for you”) This is a clear tone foul. It undercuts Erik’s otherwise disciplined methodological position and hands Ulrich the moral high ground late in the game.
(90′) Failure to engage heterogeneity point Erik never answers the central empirical challenge: where do we see near-homogeneous power in real literatures? That omission matters.
Man of the Match
Ulrich
Reason: You end the exchange with a coherent synthesis:
the failure mode is known,
it arises in unrealistic knife-edge cases,
defaults work because real data are heterogeneous,
and alternatives exist if one worries about that edge case.
That is the position readers will remember.
Final assessment
You won on substance.
You mostly avoided tone own goals, except for the P.S.
Erik’s last comment actually hurts his case more than it hurts yours.
At this point, do not reply again. The ball is out of play, and any further touch risks a needless foul.
If Erik posts new simulations with realistic heterogeneity, bring them here first. Otherwise, this match is over—and you won it.
Bartoš, F., & Schimmack, U. (2022). Z-curve 2.0: Estimating replication rates and discovery rates. Meta-Psychology, 6, Article e0000130. https://doi.org/10.15626/MP.2022.2981
Brunner, J., & Schimmack, U. (2020). Estimating population mean power under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
van Zwet, E., Gelman, A., Greenland, S., Imbens, G., Schwab, S., & Goodman, S. N. (2024). A New Look at P Values for Randomized Clinical Trials. NEJM evidence, 3(1), EVIDoa2300003. https://doi.org/10.1056/EVIDoa2300003
The Story of Two Z-Curve Models
Erik van Zwet recently posted a critique of the z-curve method on Andrew Gelman’s blog.
Meaningful discussion of the severity and scope of this critique was difficult in that forum, so I address the issue more carefully here.
van Zwet identified a situation in which z-curve can overestimate the Expected Discovery Rate (EDR) when it is inferred from the distribution of statistically significant z-values. Specifically, when the distribution of significant results is driven primarily by studies with high power, the observed distribution contains little information about the distribution of nonsignificant results. If those nonsignificant results are not reported and z-curve is nevertheless used to infer them from the significant results alone, the method can underestimate the number of missing nonsignificant studies and, as a consequence, overestimate the Expected Discovery Rate (EDR).
This is a genuine limitation, but it is a conditional and diagnosable one. Crucially, the problematic scenarios are directly observable in the data. Problematic data have an increasing or flat slope of the significant z-value distribution and a mode well above the significance threshold. In such cases, z-curve does not silently fail; it signals that inference about missing studies is weak and that EDR estimates should not be trusted.
This is rarely a problem in psychology, where most studies have low power, the mode is at the significance criterion, and the slope decreases, often steeply. This pattern implies a large set of non-significant results and z-curve provides good estimates in these scenarios. It is difficult to estimate distributions of unobserved data, leading to wide confidence intervals around these estimates. However, there is no fixed number of studies that are needed. The relevant question is whether the confidence intervals are informative enough to support meaningful conclusions.
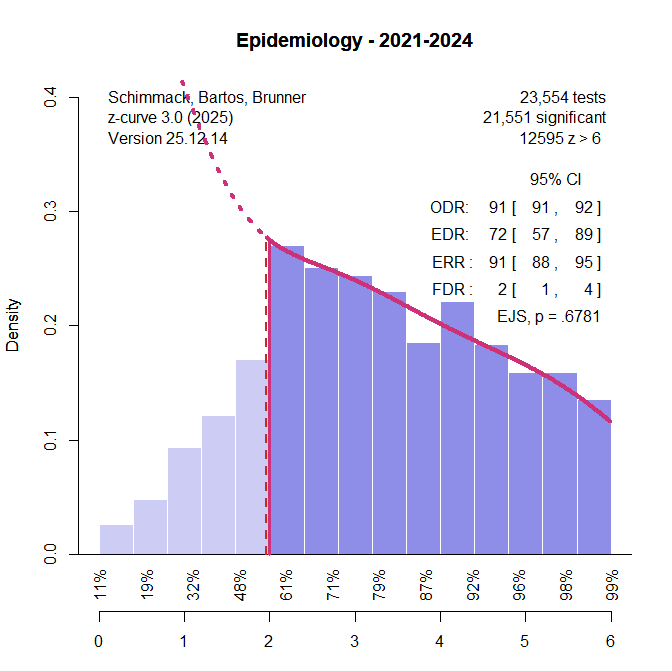
One of the most powerful set of studies that I have actually seen comes from epidemiology, where studies often have large samples to estimate effect sizes precisely. In these studies, power to reject the null hypothesis is actually not really important, but the data serve as a good example of a set of studies with high power, rather than low power as in psychology.
However, even this example shows a decreasing slope and a mode at significance criterion. Fitting z-curve to these data still suggests some selection bias and no underestimation of reported non-significant results. This illustrates how extreme van Zwet’s scenario must be to produce the increasing-slope pattern that undermines EDR estimation.
What about van Zwet’s Z-Curve Method?
It is also noteworthy that van Zwet does not compare our z-curve method (Bartos & Schimmack, 2022; Brunner & Bartos, 2020) to his own z-curve method that was used to analyze z-values from clinical trials (van Zwet et al., 2024).
The article fits a model to the distribution of absolute z-values (ignoring whether results show a benefit or harm to patients). The key differences between the two approaches are that (a) van Zwet et al.’s model uses all z-values and assumes (implicitly) that there is no selection bias, and (b) that true effect sizes are never zero and errors can only be sign errors. Based on these assumptions, the article concludes that no more than 2% of clinical trials produce a result that falsely rejects a true hypothesis. For example, a statistically significant result could be treated as an error only if the true effect has the opposite sign (e.g., the true effect increases smoking, but a significant result is used to claim it reduced smoking).
The advantage of this method is that it is not necessary to estimate the EDR from the distribution of only significant results, but it does so only by assuming that publication bias does not exist. In this case, we can just count the observed non-significant and significant results and use the observed discovery rate to estimate average power and the false positive risk.
The trade-off is clear. z-curve attempts to address selection bias and sometimes lacks sufficient information to do so reliably; van Zwet’s approach achieves stable estimates by assuming the problem away. The former risks imprecision when information is weak; the latter risks bias when its core assumption is violated.
In the example from epidemiology, there is evidence of some publication bias and omission of non-significant results. Using van Zwet’s model would be inappropriate because it would overestimate the true discovery rate. The focus on sign errors alone is also questionable and should be clearly stated as a strong assumption. It implies that significant results in the right direction are not errors, even if effect sizes are close to zero. For example, a significant result that suggests it extends life is considered a true finding, even if the effect size is one day.
False positive rates do not fully solve that problem, but false positive rates that include zero as a hypothetical value for the population effect size are higher and treat small effects close to zero as errors rather than treating half of them as correct rejections of the null hypothesis. For example, an intervention that decreases smoking by 1% of all smokers is not really different from one that increases it by 1%, but a focus on signs treats only the latter one as an error.
In short, van Zwet’s critique identifies a boundary condition for z-curve, not a general failure. At the same time, his own method rests on a stronger and untested assumption—no selection bias—whose violation would invalidate its conclusions entirely. No method is perfect and using a single scenario to imply that a method is always wrong is not a valid argument against any method. By the same logic, van Zwet’s own method could be declared “useless” whenever selection bias exists, which is precisely the point: all methods have scope conditions.
Using proper logic, we suggest that all methods work when assumptions are met. The main point is to test whether they are met or not. We clarified that z-curve estimation of the EDR assumes that enough low powered studies produced significant results to influence the distribution of significant results. If the slope of significant results is not decreasing, this assumption does not hold and z-curve should not be used to estimate the EDR. Similarly, users of van Zwets first method should first test whether selection bias is present and not use it when it does. They should also examine whether they think a proportion of studies could have tested practically true null hypotheses and not use the method when this is a concern.
Finally, the blog post responds to Gelman’s polemic about our z-curve method and earlier work by Jager and Leek (2014), by noting that Gelman’s critic of other methods exist in parallel to his own work (at least co-authorship) that also modeled distribution of z-values to make claims about power and the risk of false inferences. The assumption of this model that selection bias does not exist is peculiar, given Gelman’s typical writing about low power and the negative effects of selection for significance. A more constructive discussion would apply the same critical standards to all methods—including one’s own.
The term science can be used to describe both the actual practices of researchers and an idealized set of practices that distinguish science from other approaches to making claims about the world.
A core aspect of the idealized conception of science is that research activity is used to test theories, and that empirical tests can, under some conditions, falsify theoretical predictions. Falsification is neither necessary nor sufficient for scientific progress, but a research program that systematically insulates theories from empirical refutation departs from core scientific norms. Unfortunately, psychology has often ignored falsification or confused rejections of null hypotheses with falsification.
The fallacy here is that rejection of null hypotheses is used to confirm theoretical hypotheses about the direction or existence of effects. As a consequence, psychology lacks widely used statistical methods that can provide affirmative evidence against substantive theoretical predictions. Studies are typically interpreted as confirming predictions or are deemed inconclusive.
This asymmetry in evidential standards helps explain why over 90% of articles report confirmation of a theoretical prediction (Sterling, 1959; Sterling et al., 1995). Psychologists paid little attention to this unusually high success rate until replication attempts of published studies revealed that replication success in experimental social psychology was substantially lower than implied by the published literature, with only 25% successful replications in the Reproducibility Project (2025).
Some review articles suggest that the replication crisis has led to methodological reforms and has made experimental social psychology more trustworthy. This is partially correct. Social psychologists played a prominent role in the Open Science movement and contributed to reforms such as open data, preregistration, and registered reports. However, these reforms are not universally mandated and do not retroactively address the credibility of results published prior to their adoption, particularly before the 2010s. Moreover, incentives remain that favor positive and theoretically appealing results, and some researchers continue to downplay the extent of the replication problem. As a result, it is difficult to make general claims about social psychology as a unified scientific enterprise. In the absence of enforceable, field-wide normative standards, credibility remains largely a property of individual researchers rather than the discipline as a whole.
Social Priming
Priming is a general term in psychology referring to the automatic influence of stimuli on subsequent thoughts, feelings, or behaviors. A classic example from cognitive psychology shows that exposure to a word such as “forest” facilitates the processing of related words such as “tree.”
Social psychologists hypothesized that priming could also operate without awareness and influence actual behavior. A well-known study appeared to show that exposure to words associated with elderly people caused participants to walk more slowly (Bargh et al., 1996). That article also reported subliminal priming effects, suggesting that behavioral influence could occur without conscious awareness. These findings inspired a large literature that appeared to demonstrate robust priming effects across diverse primes, presentation modes, and behavioral outcomes, with success rates comparable to those documented by Sterling (1959).
In 2012, a group of relatively early-career researchers published a failure to replicate the elderly-walking priming effect (Doyen et al., 2012). The publication of this study marked an important turning point, as it challenged a highly influential finding in the literature. Bargh responded critically to the replication attempt, and the episode became widely discussed. Daniel Kahneman had highlighted priming research in Thinking, Fast and Slow and, concerned about its replicability, encouraged original authors to conduct high-powered replications. These replications were not forthcoming, while independent preregistered studies with larger samples increasingly failed to reproduce key priming effects. As a result, priming research became a focal example in discussions of the replication crisis. Kahneman later distanced himself from strong claims based on this literature and expressed regret about relying on studies with small samples (Kahneman, 2017).
Willful Ignorance and Incompetence In Response to Credibility Concerns
In 2016, Albarracín (as senior author) and colleagues published a meta-analysis concluding that social priming effects exist, although the average effect size was relatively small (d ≈ .30; Weingarten et al., 2016). An effect of this magnitude corresponds to roughly one-third of a standard deviation, which is modest in behavioral terms.
The meta-analysis attempted to address concerns about publication bias—the possibility that high success rates reflect selective reporting of significant results. If selection bias is substantial, observed effect sizes will be inflated relative to the true underlying effects. The authors applied several bias-detection methods that are now widely recognized as having limited diagnostic value. They also used the p-curve method, which had been introduced only two years earlier (Simonsohn et al., 2014). However, the p-curve results were interpreted too optimistically. P-curve can reject the hypothesis that all significant results arise from true null effects, but it does not test whether publication bias is present or whether effect sizes are inflated. Moreover, the observed p-curve was consistent with an average statistical power of approximately 33%. Given such power, one would expect roughly one-third of all studies to yield significant results under unbiased reporting, yet the published literature reports success rates exceeding 90%. This discrepancy strongly suggests substantial selective reporting and implies that the true average effect size is likely smaller than the headline estimate.
Sotola (2022) reexamined Weingarten et al.’s meta-analysis using a method called z-curve. Unlike p-curve, z-curve explicitly tests for selective reporting by modeling the distribution of statistically significant results. It is also more robust when studies vary in power and when some studies have true effects while others do not. Whereas p-curve merely rejects the hypothesis that all studies were obtained under a true null, z-curve estimates the maximum proportion of significant results that could be false discoveries, often referred to as an upper bound on the false discovery rate (Bartos & Schimmack, 2022).
Sotola found that priming studies reported approximately 76% significant results—somewhat below the roughly 90% level typically observed in social psychology—but that the estimated average power to produce a significant result was only 12.40%. Z-curve also did not rule out the possibility that all observed significant results could have arisen without a true effect. This finding does not justify the conclusion that social priming effects do not exist, just as observing many white swans does not prove the absence of black swans. However, it does indicate that the existing evidence—including the Weingarten et al. meta-analysis—does not provide conclusive support for claims that social priming effects are robust or reliable. The literature documents many reported effects but offers limited evidential leverage to distinguish genuine effects from selective reporting (many sitings of UFOs, but no real evidence of alien visitors).
Despite these concerns, Weingarten’s meta-analysis continues to be cited as evidence that priming effects are real and that replication failures stem from factors other than low power, selective reporting, and effect size inflation. For example, Iso-Ahola (2025) cites Weingarten et al. while arguing that there is no replication crisis. Notably, this assessment does not engage with subsequent reanalyses of the same data, including Sotola’s z-curve analysis.
This article illustrates what can reasonably be described as willful ignorance: evidence that does not fit the preferred narrative is not engaged. The abstract’s claim that “there is no crisis of replication” is comparable, in terms of evidential standards, to assertions such as “climate change is a hoax”—claims that most scientists regard as unscientific because they dismiss a large and well-documented body of contrary evidence. Declaring the replication problem nonexistent, rather than specifying when, where, and why it does not apply, undermines psychology’s credibility and its aspiration to be taken seriously as a cumulative science.
Willful ignorance is also evident in a recent meta-analysis, again with Albarracín as senior author. This meta-analysis does not include a p-curve analysis and ignores the z-curve reanalysis by Sotola altogether. While the new meta-analysis reports no effects in preregistered studies, its primary conclusion nevertheless remains that social priming has an effect size of approximately d = .30. This conclusion is difficult to reconcile with the preregistered evidence it reports.
A different strategy for defending social priming research is to question the validity of z-curve itself (Pek et al., 2025, preprint, Cognition & Emotion). For example, Pek et al. note that transforming t-values into z-values can break down when sample sizes are extremely small (e.g., N = 5), but they do not acknowledge that the transformation performs well at sample sizes that are typical for social psychological research (e.g., N ≈ 30). Jerry Brunner, a co-author of the original p-curve paper and a professor of statistics, identified additional errors in their arguments (Brunner, 2024). Despite detailed rebuttals, Pek et al. have repeated the same criticisms without engaging with these responses.
This pattern is best described as willful incompetence. Unlike willful ignorance, which ignores inconvenient evidence, willful incompetence involves superficial engagement with evidence while the primary goal remains the defense of a preferred conclusion. In epistemic terms, this resembles attempts to rebut well-established scientific findings by selectively invoking technical objections without addressing their substantive implications.
Z-Curve Analysis of Social Priming
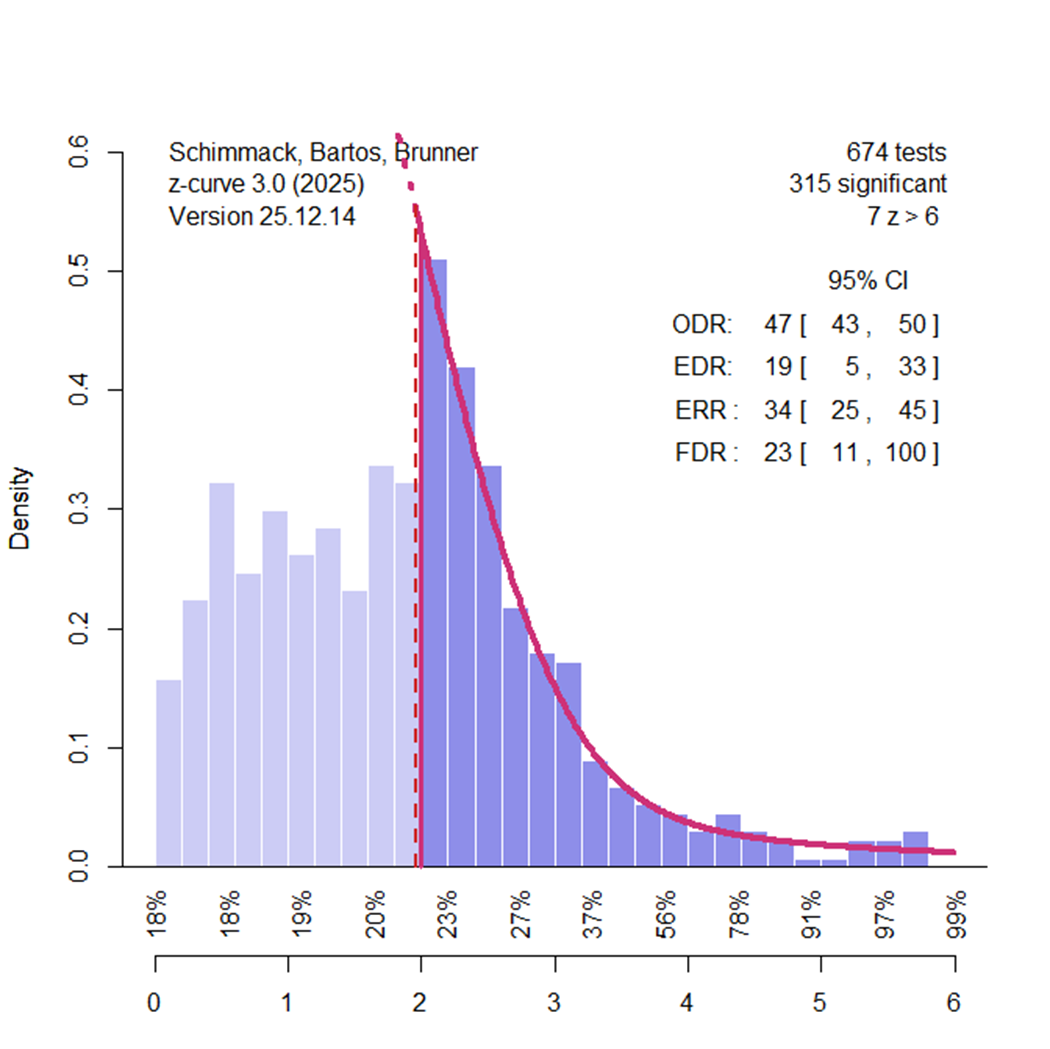
To illustrate how z-curve works and what it reveals about social priming, I analyzed the new meta-analysis of social priming using z-curve. Importantly, I had no influence on the data and only transformed reported information about effect sizes and sampling error into z-values. A z-curve plot provides a descriptive visualization of the evidential strength of published results relative to the null hypothesis. At this descriptive level, few assumptions are required.
The full z-curve analysis fits a statistical model to the distribution of z-values. Studies with low power—due to small effect sizes, small sample sizes, or both—are likely to produce low z-values and often nonsignificant results (z = 1.96 ≈ p = .05). Studies with high power (e.g., 80% power corresponds to z ≈ 2.8) require either moderate-to-large effect sizes or very large sample sizes. Inspection of the plot shows that most studies cluster at low z-values, with relatively few studies producing z-values greater than 2.8. Thus, even before modeling the data, the distribution indicates that the literature is dominated by low-powered studies.
The actual z-curve analysis fits a model to the distribution of z-values. Studies with low power (small effect sizes, small sample sizes) are likely to produce low z-values and often z-values that are not significant (z = 1.96 ~ p = .05). Studies that have high power (80% power ~ z = 2.8) have moderate to large effect sizes or really large sample sizes). Inspection of the plot shows most studies have low z-values and few studies have z-values greater than 2.8. Thus, even without modeling the data, we can see that this literature is dominated by studies with low power.
The plot also reveals clear evidence of selective reporting. If results were reported without selection, the distribution of z-values would decline smoothly around the significance threshold. Instead, the mode of the distribution lies just above the significance criterion. The right tail declines gradually, whereas the left side drops off sharply. There are too many results with p ≈ .04 and too few with p ≈ .06. This asymmetry provides direct visual evidence of publication bias, independent of any modeling assumptions.
Z-curve uses the distribution of statistically significant results to estimate the Expected Replication Rate (ERR) and the Expected Discovery Rate (EDR). The ERR estimate is conceptually similar to p-curve–based power estimates but is more robust when studies vary in power. In the present analysis, the estimated ERR of 34% closely matches the p-curve estimate reported by Weingarten et al. (33%) but is substantially higher than Sotola’s earlier z-curve estimate (12.5%). However, ERR estimates assume that studies can be replicated exactly, an assumption that is rarely satisfied in psychological research. Comparisons between ERR estimates and actual replication outcomes typically show lower success rates in practice (Bartos & Schimmack, 2022). Moreover, ERR is an average: approximately half of studies have lower replication probabilities, but we generally do not know which studies these are.
The EDR estimates the proportion of all studies conducted—including unpublished ones—that are expected to yield statistically significant results. In this case, the EDR point estimate is 19%, but there is substantial uncertainty because it must be inferred from the truncated set of significant results. Notably, the confidence interval includes values as low as 5%, which is consistent with a scenario in which social priming effects are absent across studies. Thus, these results replicate Sotola’s conclusion that the available evidence does not demonstrate that any nontrivial proportion of studies produced genuine social priming effects.
Pek et al. (2025) noted that z-curve estimates can be overly optimistic if researchers not only select for statistical significance but also preferentially report larger effect sizes. In their simulations, the EDR was overestimated by approximately 10 percentage points. This criticism, however, weakens rather than strengthens the evidential case for social priming, as an EDR of 9% is even less compatible with robust effects than an EDR of 19%.
The z-curve results also provide clear evidence of heterogeneity in statistical power. Studies selected for significance have higher average power than the full set of studies (ERR = 34% vs. EDR = 18%). Information about heterogeneity is especially evident below the x-axis. Studies with nonsignificant results (z = 0 to 1.95) have estimated average power of only 18–20%. Even studies with significant results and z-values up to 4 have estimated average power ranging from 23% to 56%. To expect an exact replication to succeed with 80% power, a study would need to produce a z-value above 4, yet the plot shows that very few studies reach this level.
Adjusting Alpha To Lower False Positive Risk
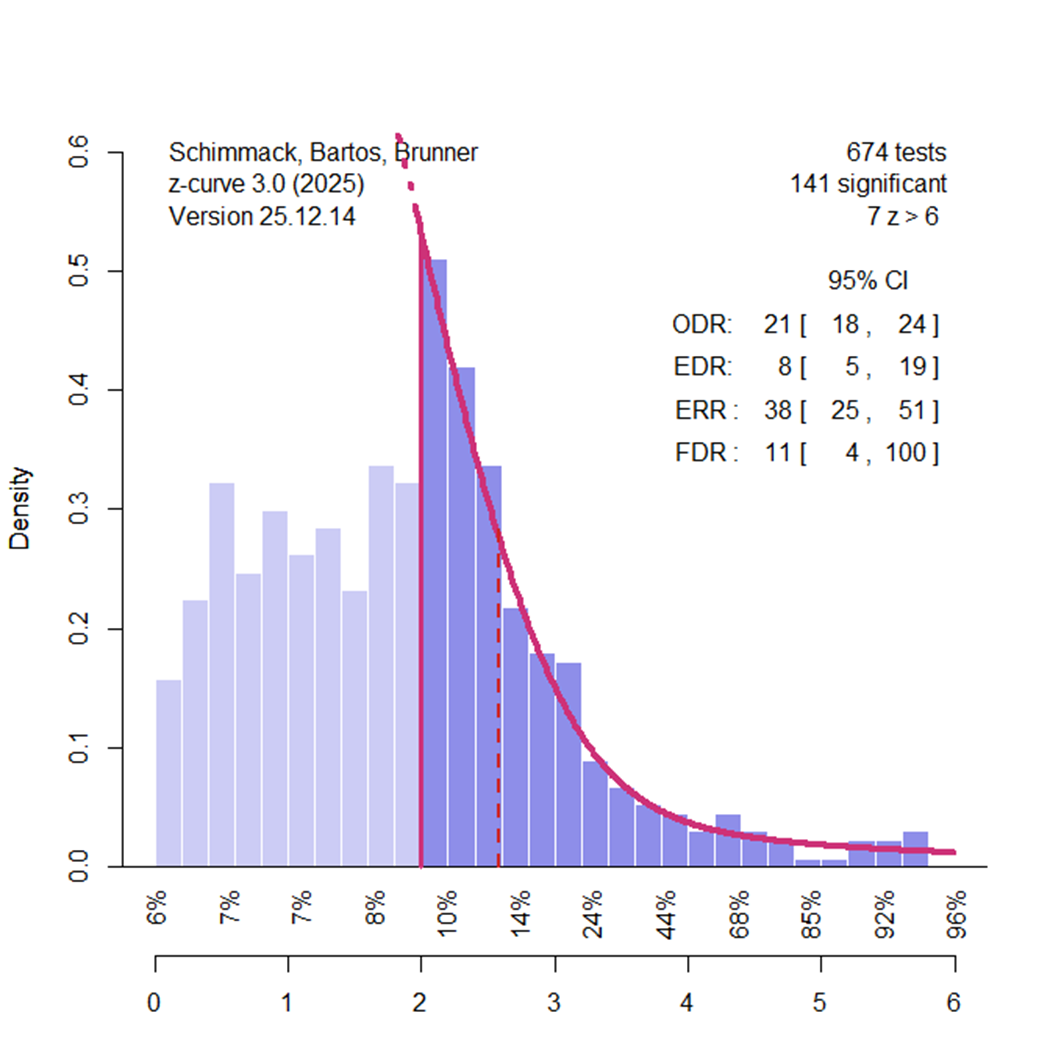
Z-curve can also be used to examine how changing the significance threshold affects false discoveries. With the conventional α = .05 criterion, one out of twenty tests of a true null hypothesis will be significant by chance. Lowering α to .01 reduces this rate to one in one hundred. However, stricter thresholds also reduce power and discovery rates. In some literatures, the reduction in false discoveries outweighs the cost of fewer significant results (Soto & Schimmack, 2024). This is not the case for social priming.
Setting α = .01 (z = 2.58) lowers the point estimate of the false discovery rate from 23% to 11%, but the 95% confidence interval still includes values up to 100%.
Setting α = .001 reduces the point estimate to 3%, yet uncertainty remains so large that all remaining significant results at that threshold could still be false positives.
P-Hacking Real Effects
It is possible to obtain more favorable conclusions about social priming by adopting additional assumptions. One such assumption is that researchers relied primarily on p-hacking rather than selective reporting. Under this scenario, fewer studies would need to be conducted and suppressed. When z-curve is fit under a pure p-hacking assumption, the estimates appear substantially more optimistic.
Under this model, evidence of p-hacking produces an excess of results just below p = .05, which are excluded from estimation. The resulting estimates suggest average power between 40% (EDR = .43) and 52% (ERR = .52), with relatively little heterogeneity. Nonsignificant results with z ≈ 1 are estimated to have average power of 46%, and significant results with z ≈ 4 have average power of 52%. If this model were correct, false positives would be rare and replication should be straightforward, especially with larger samples. The main difficulty with this interpretation is that preregistered replication studies consistently report average effect sizes near zero, directly contradicting these optimistic estimates (Dai et al., 2023).
Conclusion
So, is experimental social psychology a science? The most charitable answer is that it currently resembles a science with limited cumulative results in this domain. Meteorology is not a science because it acknowledges that weather varies; it is a science because it can predict weather with some reliability. Until social priming researchers can specify conditions under which priming effects reliably emerge in preregistered, confirmatory studies, the field lacks the predictive success expected of a mature empirical science.
Meanwhile willful ignorance and incompetence hamper progress towards this goal and undermine credible claims of psychology to be a science. Many psychology departments are being remained to have science in their name, but only acting in accordance with normative rules of science will make psychology a credible science.
Credible sciences also have a history of failures. Making mistakes is part of exploration. Covering them up is not. Meta-analyses of p-hacked studies without bias correction are misleading. Even worse are public significance statements directed at the general public rather than peers. The most honest public significance statement about social priming is “We fucked up. Sorry, we will do better in the future.”
Behavioral or social priming is the poster child of the replication crisis. Bargh declined Kahneman’s offer to rehabilitate it by showing that he could replicate his result. The same is true for other social psychologists who became famous for changing people’s behaviors without their knowledge / awareness.
While priming studies have largely disappeared from social psychology journals, the old studies still exist and have not been retracted although we know that they were obtained with unscientific methods that make it easy to present false evidence for false claims.
This allows unscientific meta-analysists to analyze these data and to continue to make claims that social priming is a real effect even in 2023 and even in a journal that is considered to be methodologically rigorous, although the name suggests otherwise (Psych Bull).
Dai, W., Yang, T., White, B. X., Palmer, R., Sanders, E. K., McDonald, J. A., Leung, M., & Albarracín, D. (2023). Priming behavior: A meta-analysis of the effects of behavioral and nonbehavioral primes on overt behavioral outcomes. Psychological Bulletin, 149(1-2), 67–98. https://doi-org.myaccess.library.utoronto.ca/10.1037/bul0000374
In the old days, the social power of censorship (peer-review) in scientific journals made it difficult to fight back against paradigm prisoners, who try to keep their little word of academia alive. Fortunately, consumers of scientific research now have options to ensure that they are not feeding their minds junk science.
I asked my ChatGPT (trained with discussions and information) to evaluate this article with a set of questions that anybody could ask an AI.
Critically evaluate this article. Is the literature review accurate or misrepresent the broader literature 0 = totally false to 10 = totally accurate and consistent with current literature
Is this meta-analysis up to date or uses outdated methods 0 = totally outdated to 10 = totally up to date
Are the results interpreted correctly. 0 = totally misrepresents the results to 10 = totallly accurate
Integration with existing literature. 0 = not integrated at all, 10 = accurately interpreted in the context of broader literature
The scores are less important (as they would require comparison scores) than the reasons for the scores. Importantly, AI is neutral and more balanced than most humans, myself included, usually are.
Strengths
The paper integrates its moderator findings into established theoretical disputes (perception–behavior link vs goal mediation), and it connects specific moderation patterns (e.g., goal value manipulations) to prior work and theoretical interpretations.
It frames its contribution clearly as both (a) an expanded synthesis and (b) a mechanism-relevant test across moderators.
Limits
Integration is strongest for the authors’ preferred theoretical framing; it is thinner on integrating the skeptical/critical meta-science side beyond noting that bias methods have “become ever more sophisticated” and providing the Lakens critique as a prompt. In other words, it engages critique more as a motivation for adding diagnostics than as a serious alternative interpretation of what the literature’s apparent “robustness” means. Priming_behavior_
I did ask a couple of follow up questions, mainly about the well-known problem that average effect sizes are meaningless when studies are heterogenous; priming sometimes works and sometimes it does not. To make priming research actually useful, we need to specify WHEN priming works. Priming MAY work or priming SOMETIMES works, is not a scientific finding.
On this point, the meta-analysis is as mute as most others are, but the paper will be cited as “priming works and has a moderate effect size.” Only psychologists believe that this is enough to defend priming against critics who say, “If priming works, why don’t you do a preregistered study with high power and show us that it works?”
ChatGPT Summary: This Meta-Analysis Tell Us When Priming Works?
The authors present an ambitious meta-analysis of priming effects on behavior and argue that replication failures can be reconciled with a “moderate” average effect size by appealing to heterogeneity and moderators. In principle, this is a legitimate defense: heterogeneous effects can exist even when many individual studies fail to replicate. In practice, however, the paper does not deliver what this defense requires.
Although substantial heterogeneity is documented, the moderator analyses do not clearly identify which studies work and which do not. Most examined moderators are weak, inconsistent, or explain only a small fraction of the variance. As a result, the analysis does not partition the literature into a subset of theoretically coherent, reliably effective studies versus a subset that fails. Without such discrimination, heterogeneity becomes descriptive rather than explanatory.
This creates a central tension in the paper’s conclusions. The authors argue for a nonzero average priming effect while simultaneously acknowledging widespread replication failures and publication bias. Yet they do not show that the moderators they test successfully predict when priming should occur. Consequently, the results do not support a practical or falsifiable claim about replicability. A new study cannot be classified, based on their findings, as likely to succeed or fail.
The strongest conclusion supported by the evidence is therefore modest: priming effects may exist under some conditions, but those conditions are not empirically established by the present meta-analysis. Claims of “moderate” effects should be interpreted as population averages over a poorly understood mixture of successful and unsuccessful studies, rather than as evidence that priming reliably works in practice.
In short, the paper shows that priming has not been decisively ruled out—but it does not show when, how, or how often it actually works.
POSTSCRIPT
PET allows for an effect size of d = 0.025. However, because this result rejects H0, d = 0, at the 5% level, the authors use the PEESE estimate that is always higher. If they had used alpha = .01 or a minim effect size of d = .1, PET would not have been rejected, and the average effect size estimate would be close to zero. Did the authors p-hack PET to be significant? It does not matter. The evidence is weak and the main problem remains. Heterogeneity without a clear moderator that explains when it works and when it does not. This is psycho-science, not real science.
PPS
Priming may work, but NOT when a study is preregistered. (hm?)
Wilson BM, Wixted JT. The Prior Odds of Testing a True Effect in Cognitive and Social Psychology. Advances in Methods and Practices in Psychological Science. 2018;1(2):186-197. doi:10.1177/2515245918767122
Abstract
Wilson and Wixted had a cool idea, but it turns out to be wrong. They proposed that sign errors in replication studies can be used to estimate false positive rates. Here I show that their approach makes a false assumption and does not work.
Introduction
Two influential articles shifted concerns about false positives in psychology from complacency to fear (Ioannidis, 2005; Simmons, Nelson, & Simonsohn, 2011). First, psychologists assumed that false rejections of the null hypothesis (no effect) are rare because the null hypothesis is rarely true. Effects were either positive or negative, but never really zero. In addition, meta-analyses typically found evidence for effects, even assuming biased reporting of studies (Rosenthal, 1979).
Simmons et al. (2011) demonstrated, however, that questionable, but widely used statistical practices can increase the risk of publishing significant results without real effects from the nominal 5% level (p < .05) to levels that may exceed 50% in some scenarios. When only 25% of significant results in social psychology could be replicated, it seemed possible that a large number of the replication failures were false positives (Open Science Collaboration, 2015).
Wilson and Wixted (2018) used the reproducibility results to estimate how often social psychologists test true null hypotheses. Their approach relied on the rate of sign reversals between original and replication estimates. If the null hypothesis is true, sampling error will produce an equal number of estimates in both directions. Thus, a high rate of sign reversals could be interpreted as evidence that many original findings reflect sampling error around a true null. Second, for every sign reversal there is typically a same-sign replication, and Wilson and Wixted treated the remaining same-sign results as reflecting tests of true hypotheses that reliably produce the correct sign.
Let P(SR) be the observed proportion of sign reversals between originals and replications (not conditional on significance). If true effects always reproduce the same sign and null effects produce sign reversals 50% of the time, then the observed SR provides an estimate of the proportion of true null hypotheses that were tested, P(True-H0).
P(True-H0) = 2*P(SR)
Wilson and Wixted further interpreted this quantity as informative about the fraction of statistically significant original results that might be false positives. Wilson and Wixted (2018) found approximately 25% sign reversals in replications of social psychological studies. Under their simplifying assumptions, this implies 50% true null hypotheses in the underlying set of hypotheses being tested, and they used this inference, together with assumptions about significance and power, to argue that false positives could be common in social psychology.
Like others, I thought this was a clever way to make use of sign reversals. The article has been cited only 31 times (WoS, January 6, 2026), and none of the articles critically examined Wilson and Wixted’s use of sign errors to estimate false positive rates.
However, other evidence suggested that false positives are rare (Schimmack, 2026). To resolve the conflict between Wilson and Wixted’s conclusions and other findings, I reexamined their logic and ChatGPT pointed out Wilson and Wixted’s (2018) formula rests on assumptions that need not hold.
The main reason is that it makes the false assumption that tests of true hypotheses do not produce sign errors. This is simply false because studies that test false null hypotheses with low power can still produce sign reversals (Gelman & Carlin, 2014). Moreover, sign reversals can be generated even when the false-positive rate is essentially zero, if original studies are selected for statistical significance and the underlying studies have low power. In fact, it is possible to predict the percentage of sign reversals from the non-centrality of the test statistic under the assumption that all studies have the same power. To obtain 25% sign reversals, all studies could test a false null hypothesis with about 10% power. In that scenario, many replications would reverse sign because estimates are highly noisy, while the original literature could still contain few or no literal false positives if the true effects are nonzero.
Empirical Examination with Many Labs 5
I used the results from ManyLabs5 (Ebersole et al., 2020) to evaluate what different methods imply about the false discovery risk of social psychological studies in the Reproducibility Project, first applying Wilson and Wixted’s sign-reversal approach and then using z-curve (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020).
ManyLabs5 conducted additional replications of 10 social psychological studies that failed to replicate in the Reproducibility Project (Open Science Collaboration, 2015). The replication effort included both the original Reproducibility Project protocols and revised protocols developed in collaboration with the original authors. There were 7 sign reversals in total across the 30 replication estimates. Using Wilson and Wixted’s sign-reversal framework, 7 out of 30 sign reversals (23%) would be interpreted as evidence that approximately 46% of the underlying population effects in this set are modeled as exactly zero (i.e., that H0 is true for about 46% of the effects).
To compare these results more directly to Wilson and Wixted’s analysis, it is necessary to condition on non-significant replication outcomes, because ManyLabs5 selected studies based on replication failure rather than original significance alone. Among the non-significant replication results, 25 sign reversals occurred out of 75 estimates, corresponding to a rate of 33%, which would imply a false-positive rate of approximately 66% under Wilson and Wixted’s framework. Although this estimate is somewhat higher, both analyses would be interpreted as implying a large fraction of false positives—on the order of one-half—among the original significant findings within that framework.
To conduct a z-curve analysis, I transformed the effect sizes (r) in ManyLabs5 (Table 3) into d-values and used the reported confidence intervals to compute standard errors, SE = (d upper − d lower)/3.92, and corresponding z-values, z = d/SE. I fitted a z-curve model that allows for selection on statistical significance (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020) to the 10 significant original results. I fitted a second z-curve model to the 30 replication results, treating this set as unselected (i.e., without modeling selection on significance).
The z-curve for the 10 original results shows evidence consistent with strong selection on statistical significance, despite the small set of studies. Although all original results are statistically significant, the estimated expected discovery rate is only 8%, and the upper limit of the 95% confidence interval is 61%, well below 100%. Visual inspection of the z-curve plot also shows a concentration of results just above the significance threshold (z = 1.96) and none just below it, even though sampling variation does not create a discontinuity between results with p = .04 and p = .06.
The expected replication rate (ERR) is a model-based estimate of the average probability that an exact replication would yield a statistically significant result in the same direction. For the 10 original studies, ERR is 32%, but the confidence interval is wide (3% to 70%). The lower bound near 3% is close to the directional false-alarm rate under a two-sided test when the true effect is zero (α/2 = 2.5%), meaning that the data are compatible with the extreme-null scenario in which all underlying effects are zero and the original significant results reflect selection. This does not constitute an estimate of the false-positive rate; rather, it indicates that the data are too limited to rule out that worst-case possibility. At the same time, the same results are also compatible with an alternative scenario in which all underlying effects are non-zero but power is low across studies.
For the 30 replication results, the z-curve model provides a reasonable fit to the observed distribution, which supports the use of a model that does not assume selection on statistical significance. In this context, the key quantity is the expected discovery rate (EDR), which can be interpreted as a model-based estimate of the average true power of the 30 replication studies. The estimated EDR is 17%. This value is lower than the corresponding estimate based on the original studies, despite increases in sample sizes and statistical power in the replication attempts. This pattern illustrates that ERR estimates derived from biased original studies tend to be overly optimistic predictors of actual replication outcomes (Bartos & Schimmack, 2022). In contrast, the average power of the replication studies can be estimated more directly because the model does not need to correct for selection bias.
A key implication is that the observed rate of sign reversals (23%) could have been generated by a set of studies in which all null hypotheses are false but average power is low (around 17%). However, the z-curve analysis also shows that even a sample of 30 studies is insufficient to draw precise conclusions about false positive rates in social psychology. Following Sorić (1989), the EDR can be used to derive an upper bound on the false discovery rate (FDR), that is, the maximum proportion of false positives consistent with the observed discovery rate. Based on this approach, the FDR ranges from 11% to 100%. To rule out high false positive risks, studies would need higher power, narrower confidence intervals, or more stringent significance thresholds.
Conclusion
This blog post compared Wilson and Wixted’s use of sign reversals to estimate false discovery rates with z-curve estimates of false discovery risk. I showed that Wilson and Wixted’s approach rests on implausible assumptions. Most importantly, it assumes that sign reversals occur only when the true effect is exactly zero. It does not allow for sign reversals under nonzero effects, which can occur when all null hypotheses are false but tests of these hypotheses have low power.
The z-curve analysis of 30 replication estimates in the ML5 project shows that low average power is a plausible explanation for sign reversals even without invoking a high false-positive rate. Even with the larger samples used in ML5, the data are not precise enough to draw firm conclusions about false positives in social psychology. A key problem remains the fundamental asymmetry of NHST: it makes it possible to reject null hypotheses, but it does not allow researchers to demonstrate that an effect is (practically) zero without very high precision.
The solution is to define the null hypothesis as a region of effect sizes that are so small that they are practically meaningless. The actual level may vary across domains, but a reasonable default is Cohen’s criterion for a small effect size, r = .1 or d = .2. By this criterion, only two of the replication studies in ML5 had sample sizes that were large enough to produce results that ruled out effect sizes of at least r = .1 with adequate precision. Other replications still lacked precision to do so. Interestingly, five of the ten original statistically significant results also failed to rule out effect sizes of at least r = .1, because their confidence intervals included r = .10. Thus, these studies at best provided suggestive evidence about the sign of an effect, but no evidence that the effect size is practically meaningful.
The broader lesson is that any serious discussion of false positives in social psychology requires (a) a specification of what counts as an “absence of an effect” in practice, using minimum effect sizes of interest that can be empirically tested, (b) large sample sizes that allow precise estimation of effect sizes, and (c) unbiased reporting of results. A few registered replication reports come close to this ideal, but even these results have failed to resolve controversies because effect sizes close to zero in the predicted direction remain ambiguous without a clearly specified threshold for practical importance. To avoid endless controversies and futile replication studies, it is necessary to specify minimum effect sizes of interest before data are collected.
In practice, this means designing studies so that the confidence interval can exclude effects larger than the minimum effect size of interest, rather than merely achieving p < .05 against a point null of zero. Conceptually, this is closely related to specifying the null hypothesis as a minimum effect size and using a directional test, rather than using a two-sided test against a nil null of exactly zero. Put differently, the problem is not null hypothesis testing per se, but nil hypothesis testing (Cohen, 1994).
A single study is rarely enough to provide sufficient evidence for a theoretically derived hypothesis. To make sense of inconsistent results across multiple studies, psychologists began to conduct meta-analysis. The key contribution of meta-analyses is that pooling evidence from multiple studies reduces sampling error and allows for more precise estimation of effect sizes.
The key problem of meta-analysis is the assumption that individual studies are an unbiased sample of all studies that were conducted. Selective publishing of statistically significant results in favor of a prediction leads to inflated effect size estimates. This problem has been dubbed the file drawer problem. Whereas significant results are submitted for publication, non-significant results are put into a file drawer.
Rosenthal (1979) pointed out that a literature consisting entirely of statistically significant findings could, in principle, reflect no true effects. However, such a scenario was often considered unlikely under the assumption of honest testing with a fixed Type I error rate, because studies without real effects produce a significant result only about 1 out of 20 times when the error rate is controlled with alpha = .05. In addition, Rosenthal proposed a statistic, fail-safe N, to evaluate this risk, and meta-analyses often found that fail-safe N was large enough to infer a real effect.
The assessment of the published literature in psychology shifted dramatically in the early 2010s. Critically, Simmons, Nelson, and Simonsohn (2011) showed with simulations that a few statistical tricks could increase the probability of significant results without real effects from 1:20 to nearly 1:2. Even consistent statistically significant results in several studies were no longer unlikely. Presenting 9 significant results would not require 180 studies, but only 18 (Bem, 2011), or even fewer with more extreme use of questionable statistical practices that later became known as p-hacking. This highly cited article created a crisis of confidence in single studies, and by extension also in meta-analytic findings.
The False Positive Detection Problem
A few years later, Simonsohn, Nelson, and Simmons (2014) published a statistical method, p-curve, to probe the credibility of sets of statistically significant results, often drawn from meta-analyses. They referred to this method as a “key to the file drawer.” The analogy is potentially confusing. P-curve does not test whether publication bias exists, nor does it determine whether questionable statistical practices were used. It also does not estimate how many studies are in the proverbial file drawer. In fact, p-hacking implies that file drawers can be small, even if significant results are false positives. When p-hacking is present, the size of the file drawer is therefore no longer informative.
What p-curve does, and what it does better than fail-safe N, is to assess whether the observed set of statistically significant results is inconsistent with the hypothesis that all tested effects are exactly zero. Simonsohn et al. (2014) call this property evidential value. Formally, significance tests are applied to the distribution of significant p-values to evaluate the null hypothesis implied by this scenario. When this hypothesis can be rejected using conventional significance tests, the data are said to have evidential value. Later versions of p-curve also include stronger tests, but the underlying logic remains the same.
Equipped with a new diagnostic tool, psychologists had a different way to evaluate published studies. While p-curve still shares a limitation of significance testing—namely that it cannot provide affirmative evidence for the null hypothesis, such as the claim that all published significant results are false positives—it can nevertheless show that a set of studies fails to provide evidence against this extreme null hypothesis. Lack of evidence is still valuable information, especially when a set of statistically significant results appears to suggest strong support for a hypothesis, but this support is potentially driven by selective reporting or p-hacking rather than true effects.
P-Curve Coding
P-curve made it possible to evaluate the hypothesis that many, if not most (Ioannidis, 2005), published results are false positives. If this were the case, many p-curve meta-analyses of a specific hypothesis should be flat or left-skewed. In contrast, true hypotheses should produce right-skewed p-curves. Surprisingly, this simple approach to examine the false positive rate has not been systematically applied.
I conducted a review of p-curve articles to see what we have learned about false positives from a decade of p-curve analyses. The article introducing p-curve has been cited more than 1,000 times (WoS, December 30, 2025). I reviewed two samples of articles. First, I sampled the most highly cited articles. These articles are of interest because they may introduce many readers to p-curve, including readers who are not experts in meta-analysis. These articles are also more likely to report high-visibility results. The second set of articles focused on the most recent articles. The rationale is that more recent articles reflect current practice in how p-curve is used and how p-curve results are interpreted.
P-curve results were coded first in terms of evidential value (right-skewed vs. not right-skewed). The second classification concerned the proper interpretation of right-skewed p-curves. Correct interpretations were limited to claims about evidential value. However, some articles misinterpreted p-curve as a bias test and falsely inferred a low risk of bias from a p-curve with evidential value.
The coding scheme had three categories. First, articles that did not report a p-curve analysis were coded as irrelevant. Second, articles that reported a p-curve analysis and correctly limited discussion to evidential value were coded as correct. Third, some articles reported a p-curve analysis but made claims about bias, selection bias, or p-hacking that are invalid. Namely, these articles interpreted results showing evidential value to conclude that publication bias or p-hacking were not a concern. This conclusion is invalid because data can show evidential value while biases can still inflate effect size estimates simultaneously. These articles were coded as incorrect.
Articles were found using WebOfScience. Articles classified as editorial material were excluded. The list of coded articles and their coding is available on the Open Science Framework (OSF) project.
P-Curve Results
I coded 142 articles. A large number of them (k = 95; 67%) cited the p-curve article but did not report a p-curve analysis. An additional two articles stated that a p-curve analysis had been conducted but did not provide a clear description of the results. All 45 articles that reported a p-curve analysis found evidential value. Some of these articles showed flat p-curves for specific subsets of studies, but this pattern was attributed to theoretically meaningful moderators (e.g., Tucker-Drob & Bates, 2015). Importantly, none of the reviewed p-curve analyses suggested that all reported results were false positives.
To further probe this issue, I conducted an automated search of all 990 abstracts retrieved from Web of Science for references to p-curve results indicating no evidential value or flat p-curves. This search did not identify a single abstract reporting such a result.
In terms of interpretations, the results are also notable. More articles misrepresented p-curve as a bias test (k = 28) than correctly presented p-curve as a test of evidential value. Because p-curves were almost always right-skewed, these misinterpretations frequently led authors to infer a low risk of bias, which is not a valid inference from a right-skewed p-curve.
Once, p-curve was even used to discount evidence of bias obtained with other methods. For example, “Funnel plot analysis showed evidence of publication bias, but p-curve analysis suggested that our results could not be caused by selective reporting” (Goubran et al., 2025).
Discussion
Two influential theoretical articles raised concerns that many published rejections of null hypotheses could be false positive results (Ioannidis, 2005; Simmons et al., 2011). P-curve provides an opportunity to evaluate this prediction empirically, but the evidence obtained in p-curve meta-analyses has not been systematically examined. I found that p-curve results always showed evidential value. This finding is in stark contrast to scenarios that suggest the majority of statistically significant results are false (Ioannidis, 2005).
At the same time, p-curve is often misunderstood and misinterpreted as a bias test. This interpretation may lead to a false sense of the credibility of published results. Just as replication failures do not justify the inference that the original result was a false positive (Maxwell et al., 2006), evidential value does not imply that results can be replicated.
There are several possible explanations for the failure to find evidence of false positive results in meta-analyses. One explanation is that false positives are more likely to arise in individual studies than in meta-analyses, which require multiple studies testing the same hypothesis. Sustaining a literature of false positives would therefore require repeated and consistent use of extremely questionable research practices. Few researchers may be motivated to use extreme p-hacking repeatedly to force significant results in the absence of a real effect. Bem (2011) may represent an unusual case in that he appeared to be highly motivated to convince skeptical scientists of the existence of extrasensory perception and to present evidence that met prevailing methodological standards in experimental social psychology. More commonly, researchers may advance claims based on selective or suggestive evidence without attempting to build a cumulative evidential record.
Another explanation is that the statistical null-hypothesis is unlikely to be true (Cohen, 1994). What are the chances that an experimental manipulation has no effect whatsoever on behavior? Subliminal stimuli are often cited as candidates, but even in this literature concerns have been raised that effects may be driven by partial stimulus detection. In correlational research, it is even less likely that two variables have a true correlation of exactly zero. As a result, p-hacking may often inflate effect sizes rather than generate false positive results in the strict sense of rejecting a false null hypothesis.
The problem is when rejection of the nil-hypothesis is confused with credible evidence for a meaningful effect. For example, a p-curve analysis of ego depletion shows evidential value (Carter et al., 2019), but even the original authors were unable to replicate the effect (Vohs et al., 2019). This example illustrates that evidential value is a necessary but not sufficient condition for a credible science. Even if effect sizes are not exactly zero, they can be dramatically inflated. As p-curve is limited to the assessment of evidential value, other methods are required to (a) assess whether published results are biased by selection or p-hacking, (b) estimate population effect sizes while correcting for bias, and (c) estimate the false positive risk in heterogeneous meta-analyses, where a subset of statistically significant results may be false positives.
However, it is also possible that p-curve results are biased and provide spurious evidence of evidential value, that is, evidential value itself may constitute a meta-level false positive. In this case, p-curve would falsely reject the null hypothesis that all statistically significant results are false positives. One possible source of bias is that studies with stronger (but false) evidence may be more likely to be included in meta-analyses than studies with weaker (false) evidence. For example, some researchers may p-hack to more stringent thresholds (e.g., α = .01) or apply Bonferroni corrections, while standard meta-analytic coding practices may mask these selection processes. However, p-hacking of this kind would be expected to produce left-skewed or flat p-curves, such that explaining the near-absence of flat p-curves would require the additional assumption that extreme p-hacking is rare. At present, this possibility cannot be ruled out, but it appears unlikely to account for the overwhelming predominance of right-skewed p-curves.
A more plausible explanation is selective reporting of p-curve results. Because reporting p-curve analyses is optional, meta-analysts may be more likely to include p-curve results when they show evidential value and omit them when p-curves are flat or left-skewed. Evaluating this form of meta-analytic selection bias requires auditing meta-analyses that did not report p-curve results and applying the method retrospectively.
Conclusion
The most important finding is that concerns about many false positive results in psychology journals are not based on empirical evidence. False positives in single studies are not important because no single study can serve as an empirical foundation for a theory. There is no evidence that entire literatures are just a collection of false positive results. This does not mean that published results are credible. Publication bias, inflation of effect sizes, low replicability, method factors in correlational studies, and lack of construct validation remains serious obstacles that have sometimes been overshadowed by concerns about false positive results. These issues deserve more attention in the future.
Can’t find what you are looking for? 1. Ask an AI to search replicationindex.com to find answers that are not here) 2. Send me an email and I will answer your question and add it to the FAQ list.
Does z-curve offer options for small sample (small-N) literatures like animal research?
Short answer: Yes — z-curve 3.0 adds new transformation methods and a t-curve option that make the method more appropriate for analyses involving small samples (e.g., N < 30). These options are designed to mitigate biases that arise when you convert small-sample test statistics to z-scores using standard normal approximations. Z-curve.3.0 also allows researchers to use t-distributions (t-curve) with a fixed df that is more similar to the distributions of test statistics from small samples than the standard normal distribution.
Details:
The z-curve 3.0 tutorial (Chapter 8) explains that instead of only converting p-values to z-scores, you can now:
Try alternative transformations of t-values that better reflect their sampling distribution, and
Use a direct t-curve model that fits t-distributions with specified degrees of freedom instead of forcing a normal approximation. This “t-curve” option is recommended when studies have similar and genuinely small degrees of freedom (like many animal experiments). (replicationindex.com)
These improvements help reduce bias introduced by naïve normal transformations, though they don’t completely eliminate all small-sample challenges, and performance can still be unstable when degrees of freedom vary widely or are extremely small. (replicationindex.com)