“You can’t teach an old dog new tricks.” (Proverb)
Dolores Albarracín and the Defense of Old Social Psychology
Dolores Albarracín is a prominent social psychologist at the University of Pennsylvania whose work focuses on attitudes, persuasion, and behavior change. She has held major editorial positions in the field, including editor-in-chief of Psychological Bulletin from 2014 to 2020 and currently editor of the Attitudes and Social Cognition section of the Journal of Personality and Social Psychology (JPSP).
But which social psychology does she represent: the old social psychology of selectively publishing studies that confirmed researcher expectations, or the new open science that reports results independent of their desirability.
The answer can be found in two meta-analyses of the contested social (implicit) priming literature that has been the posterchild of the replication crisis. Albarracin published not one, but two meta-analyses in defense of social priming in Psychological Bulletin (Weingarten et al., 2016; Dai et al., 2023); the first one while she was editor of the journal.
The second one had to deal with the fact that many replication failures by new social psychologists willing to publish replication failures showed no evidence. Albarracin and her co-authors dismiss this evidence. They suggest that replication studies are themselves biased toward null results — a “reverse publication bias” — and therefore should be discounted or at least treated with the same suspicion as the old studies that used unscientific practices and selection of significant results to claim the effects are real and important.
The support for their claim is a blog-post about political bias in social psychology. In contrast, the publication bias in the older studies is not taken seriously leading to the dubious claim that implicit priming is a real phenomenon, even though Albarracin herself has not been able to demonstrate her own findings again in pre-registered new studies.
It is telling that somebody with this track-record and open hostility to the new and open social psychology is now editor of the very same journal that published Bem’s (2011) pseud-scientific evidence of extrasensory abilities. The irony is hard to miss. The journal that published false claims about extrasensory abilities is now controlled by somebody who makes false claims about open science practices and the credibility of implicit priming studies This is not a good look for social psychology in the 2020s.
Science is self-correcting, but nobody said that this process is fast and painless. It may require another decade for social psychology to fix all the problems that gave JPSP the name Journal of Pseudo-Scientific Psychology. Sadly, Albarracin is part of the problem, not of the solution. Fortunately, time is on the side of progress and the time for old social psychology is running out.
The concept of statistical power is approaching its one-hundredth birthday, but its impact on inferential statistics has been less impressive than its name suggests. Power was introduced by Neyman and Pearson (1933) as part of a decision-theoretic framework for making principled choices under uncertainty and limited information. It found practical applications in industrial quality control, where decisions often had to be made before all uncertainty could be resolved. In scientific research, however, power was largely ignored for decades. Researchers continued to rely on Fisher’s significance-testing framework, in which statistically significant results were treated as discoveries and nonsignificant results often had little inferential consequence. As a result, statistical practice developed around the control of false positives, while the problem of false negatives received far less attention.
In psychology, Jacob Cohen revived Neyman and Pearson’s concept of power and tried to persuade psychologists that it was not enough to control the probability of false positive results. Researchers also had to consider the probability that a study would produce a statistically significant result if the hypothesis under investigation was true. Low power implied that a study could easily fail to provide evidence for a real effect. Cohen also showed that many studies in psychology had a high probability of producing false negative results for effect sizes that were typical and realistic in psychological research (Cohen, 1962, 1988). Nevertheless, formal power calculations remained rare. For decades, many studies relied on convenience samples with conventional sample sizes, such as 20 undergraduate students per group, rather than on sample sizes justified by the desired probability of detecting an effect.
This changed only after the replication crisis. Long before then, Sterling (1959) had pointed out that success rates of 90% or more in psychology journals were implausible if studies had modest statistical power. Sterling et al. (1995) later showed that the problem had persisted. These high success rates were not evidence that most studies were highly powered; they were evidence that nonsignificant results were being filtered out of the published record. It was therefore not surprising that the first large-scale attempt to replicate a representative sample of psychological studies produced many nonsignificant replication results (Open Science Collaboration, 2015). This sobering finding had been anticipated by Cohen’s power analyses: if original studies were underpowered, many true effects would fail to replicate, and if statistically significant results were selectively published, some original findings would also be false positives. The replication crisis therefore led to a broader recognition that low power and selection bias are not separate problems. Together, they produce a published literature with too many significant results, too many inflated effect sizes, too many unpublished nonsignificant results, and a higher risk that some published discoveries are false positives (Ioannidis, 2005; Simmons et al., 2011).
Over the past decade, dozens of articles about statistical power have been written and it is impossible to mention all of them (see, e.g., Giner-Sorolla et al., 2024, for a recent review). While Cohen’s problem was that power was ignored, the new problem is that a growing literature makes contradictory and confusing claims about statistical power, sometimes by the same authors. The aim of this post is to clarify confusion about the use of power in the context of planning of future and in the use of power to evaluate completed studies.
Post-Hoc Power
The term post hoc is not unique to power analysis. Psychologists are familiar with post-hoc tests that follow complex statistical analyses. For example, a three-way interaction in an ANOVA does not reveal the specific pattern of means that produced the interaction. To interpret the result, researchers typically follow up the omnibus test with lower-order interactions, simple effects, or pairwise comparisons. In this context, post hoc does not mean invalid. It means that the analysis is conducted after a broader result has been obtained, often to clarify its meaning.
In power analysis, post-hoc power usually refers to the calculation of power using the effect-size estimate from a completed study. Dozens of articles have warned against this practice. However, the main reason for the warning is often poorly communicated.
Previous discussions have recognized that post-hoc power is not automatically invalid. O’Keefe emphasized that labels such as post hoc and observed power are often imprecise, and Giner-Sorolla et al. (2024) cautioned that criticisms of observed power should not be generalized to all power analyses conducted after data collection.
However, these discussions do not address the deeper asymmetry in the treatment of power. A priori power analysis is often treated as unconditionally desirable, whereas post-hoc power is treated as suspect. This contrast is unwarranted whenever both calculations rely on empirical effect-size estimates from completed studies. In that case, both calculations inherit the same uncertainty about the population effect size, but the uncertainty about true power in a priori power analyses has been neglected, leading to the imbalanced perception that power analysis is useful to plan studies, but not to evaluate the outcome of studies.
True A Priori and Post-Hoc Power are Identical
Sometimes the same authors recommend the use of effect sizes from past studies to plan future studies and warn against the computation of post-hoc power of completed studies (McShane & Böckenholt, 2016; McShane & Böckenholt, 2019). This is paradoxical because the true power of a study does not depend on the timing or the purpose of a power analysis. Moreover, when researchers plan a direct replication of a previous study, the population effect size of the completed study and the planed study are the same. If the replication study has the same sample size as the original study, and uses the same significance criterion, the two studies also have the same power. So, how can it be possible to use the effect size estimate of a completed study to ensure that a replication study has adequate power, while it is impossible to use the same effect size estimate to estimate the true power of the completed study? This is what we might call the McShane/Böckenholt paradox. The same information is used to calculate a power estimate, but we cannot use this information retrospectively, and only use it prospectively.
The Ontological Error
A common objection to post-hoc power calculations is that power is the probability of a future event and therefore loses its meaning once a study has been completed. After all, the study either produced a significant result or it did not. Once the outcome is known, there is no longer any uncertainty about that particular event.
This objection is valid only if the purpose of a power calculation is to predict the already-observed outcome. But that is not the purpose of post-hoc evaluations of power. The aim is not to ask whether the observed result occurred; it did. The aim is to evaluate the observed result in relation to the probability model that generated it. A significant result in a high-powered study is expected. A significant result in a low-powered study is surprising. A long series of significant results from studies with low power is not merely surprising but statistically incredible (Schimmack, 2012).
The occurrence of an event does not change its prior probability. A near accident remains a near accident even if disaster was avoided. A lottery win remains remarkable because it was unlikely before it happened and is unlikely to happen again. The same logic applies to statistical power. If a study had only a 10% probability of producing a significant result, a researcher who obtains a significant result was lucky. Observing the lucky outcome does not make it any less lucky.
In statistical terms, events must be distinguished from probabilities. Events are observed outcomes; probabilities are properties of the data-generating process. If 10 coin flips produce 10 heads and zero tails, this does not imply that the probability of heads was 100%. The observed outcome is evidence that can be evaluated against alternative probability models. Indeed, this is the logic of many statistical tests, including chi-square tests, which compare observed frequencies to theoretically expected frequencies. The real ontological error is therefore not the use of probability after an event has occurred. It is the conflation of the observed event with the probability that produced it.
For this reason, the strongest version of the ontological objection to post-hoc power is untenable. Meaningful debate remains about how post-hoc power should be estimated, whether observed-effect-size power is too noisy, and whether aggregated power estimates are biased or imprecise. These are statistical and methodological concerns, not ontological ones. Recent discussions of post-hoc power and z-curve have largely shifted toward these issues rather than defending the claim that power becomes meaningless once a study has been completed (Giner-Sorolla et al., 2024; Pek et al., 2026; Soto & Schimmack, 2026; Schimmack & Soto, 2026).
Uncertainty in A Priori Power Calculations
A second criticism of post-hoc power calculations is that they provide unreliable information about the true power of a study. This criticism is valid in one respect: the power of a study depends on the population effect size, which is unknown. A power estimate based on an observed effect size can therefore be highly uncertain. However, this problem is not unique to post-hoc power analysis. The same uncertainty arises whenever an empirical effect-size estimate is used to plan a future study.
Consider an example from McShane and Böckenholt. In their example, the standardized effect-size estimate was d = .40 / .92 = .43. With sample sizes of 52 and 74 participants in the two groups, the standard error of the effect-size estimate was approximately .18. The corresponding 95% confidence interval ranged from d = .07 to d = .80.
We can use these values to ask how lucky the researcher was to obtain a significant result. If the point estimate of d = .43 is used as the assumed population effect size, the estimated power of the study is 65%. However, this is not the true power of the study. It is only an estimate based on an uncertain estimate of the population effect size. If the lower bound of the confidence interval is used instead, d = .07, the estimated power is only 6%. If the upper bound is used, d = .80, the estimated power is 99%. Thus, the implied power of the completed study ranges from 6% to 99%. This wide interval has been used to argue that post-hoc power calculations based on a single observed effect size are uninformative, even if they are not conceptually wrong (McShane & Böckenholt, 2019).
The problem is that the same argument also applies to a priori power analyses. McShane and Böckenholt (2016) proposed a method for planning future sample sizes from the result of a single prior study with d = .40 and SE = .18. Their method applies a downward correction to the original effect-size estimate, yielding an assumed planning effect of approximately d = .36. On this basis, they recommend a replication study with n = 95 participants per condition to achieve 80% power in a one-sided test. Under a conventional two-sided test, however, the same study would have only about 65% power, no more than the completed study. They conclude that their procedure “yields the desired level of power on average and strikes a balance between the point estimate approach that uses too few subjects and thus has too little power on average and the safeguard power approach that uses too many subjects and thus has too much power on average” (p. 52).
This conclusion obscures the central issue. The true power of both the original study and the proposed replication study remains highly uncertain because the population effect size remains unknown. Even if the planned replication study produced the assumed effect size of d = .36 with n = 95 participants per condition, the standard error of d would still be approximately .15. The resulting 95% confidence interval would range from about d = .07 to d = .65. In McShane and Böckenholt’s one-sided framework, this interval implies a power range from roughly 14% to nearly 100%. Under a two-sided test, the corresponding range is approximately 7% to 99%. Thus, even under their own planning assumptions, the power of the proposed replication study would remain highly uncertain.
The broader point is that uncertainty about power follows from uncertainty about the population effect size. This uncertainty does not disappear simply because the calculation is performed before the study rather than after it. If an observed effect-size estimate is too uncertain to evaluate the power of a completed study, the same estimate is equally uncertain when used to plan the power of a future study. It is therefore inconsistent to reject post-hoc power estimates because they are uncertain while endorsing a priori power analyses based on the same uncertain empirical estimates.
The correct conclusion is not that all power calculations are useless. A priori power analyses can be useful for planning studies, just as post-hoc power analyses can be useful for evaluating the evidential value of completed research. But neither type of calculation reveals the true power of a study unless the population effect size is known. In practice, it rarely is. All empirical power calculations are conditional on assumptions about the effect size, model, design, and analysis. The relevant question is therefore not whether a power estimate is uncertain, but whether the assumptions behind it are explicit, plausible, and appropriate for the inferential purpose.
This point is especially important for critiques of post-hoc power. Uncertainty is a valid reason to reject naïve point estimates of power based on a single noisy study. It is not a valid reason to declare post-hoc power uniquely defective. The same uncertainty affects a priori power calculations whenever they rely on uncertain empirical effect-size estimates. McShane and Böckenholt’s argument therefore cuts both ways: if uncertainty invalidates post-hoc power, it also invalidates the empirical a priori power calculations they recommend.
The Abuse of Power Calculations
The most influential criticism of post-hoc power calculations was made by Hoenig and Heisey (2001). Their argument addressed a common misuse of post-hoc power: researchers sometimes calculated observed power after obtaining a nonsignificant result in order to decide whether the result supported the null hypothesis or merely reflected insufficient power. In this setting, a nonsignificant result could have two explanations. The null hypothesis may be true, or the null hypothesis may be false but the study failed to reject it because power was low.
Hoenig and Heisey correctly pointed out that observed power cannot solve this problem. When power is computed from the observed effect size, it is largely a transformation of the same information contained in the test statistic or p-value. Results below the critical value are nonsignificant and tend to yield low observed power. Results above the critical value are significant and tend to yield high observed power. Thus, observed power cannot reveal a pattern in which the study had high power but failed to reject the null, nor can it independently show that a nonsignificant result was a false negative. The calculation recycles the observed result rather than adding independent evidence about the population effect size.
This criticism is valid, but its scope is limited. It shows that naïve observed-power calculations should not be used to interpret a single nonsignificant result. It does not show that post-hoc power is meaningless, false, or conceptually incoherent. The actual problem is that the observed effect size is an uncertain estimate of the population effect size. Because true power is defined by the population effect size, any power calculation based on the observed effect size inherits this uncertainty.
The proper lesson is therefore not that power cannot be evaluated after a study has been completed. The proper lesson is that point estimates of power should not be confused with true power. Confidence intervals make this clear. A point estimate of 80% power may be compatible with a lower bound below 10%, and a point estimate of 20% power may be compatible with an upper bound above 90%. These wide intervals do not show that power is meaningless. They show that a single study often provides insufficient information to estimate its true power with useful precision.
Hoenig and Heisey’s critique is therefore best understood as a warning against overinterpreting noisy point estimates. It is not a categorical argument against post-hoc power analysis. Once uncertainty is acknowledged, the issue becomes the same as in any empirical power calculation: how much information do the data provide about the population effect size, and how precisely can the corresponding power be estimated?
Asymmetrical Uncertainty for Low and High Power
Discussions of post-hoc power usually focus on studies with low or modest power. This focus is understandable. Many researchers work with small samples, noisy measures, and between-subject designs where high power is difficult to achieve. However, this emphasis can create a misleading impression: that post-hoc power calculations are always uninformative. They are not. A single study can provide strong evidence that its true power was high when the observed evidence is very strong.
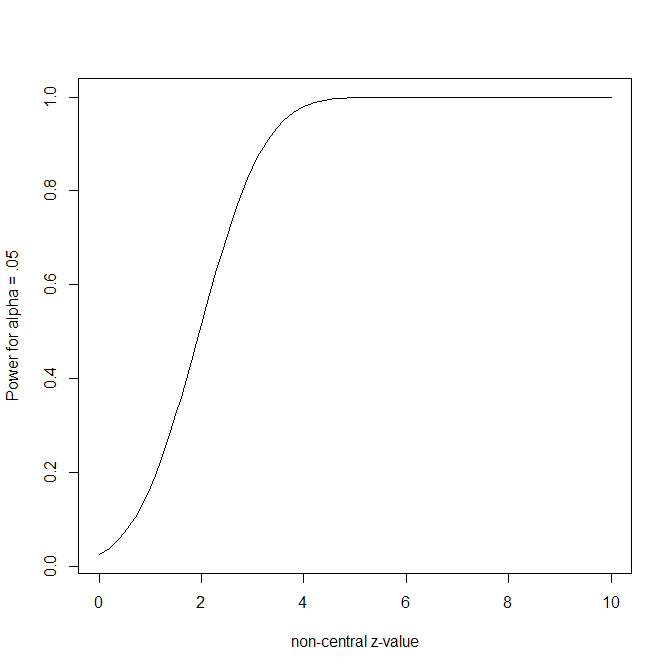
The reason is that power approaches 1 as the noncentrality parameter increases. For a two-sided test with α = .05, a noncentrality parameter of 2 implies roughly 50% power, a value of 4 implies roughly 98% power, and a value of 6 implies power greater than 99.9%. Thus, if a study produces an observed z-value of 6, the point estimate of power is practically 100%. More importantly, even the lower bound of the confidence interval around the effect size still implies very high power. Because the lower 95% confidence limit is approximately z = 6 − 1.96 = 4.04, the corresponding lower-bound power estimate is still about 98%.
This illustrates an important asymmetry. Low or moderate observed power in a single study is highly uncertain. A point estimate of 20% or 50% power may be compatible with a wide range of true power values. But very high observed power is different. A result with z = 6 is not easily explained by a study with only 50% true power. Under 50% power, the expected z-value is near the significance threshold, not three standard errors above it. Such an extreme result could occur by chance, but it is rare.
This matters because z-values greater than 6 are not uncommon in some areas of research, especially when studies use large samples, precise measures, strong manipulations, or repeated observations. These results are not merely statistically significant. They are highly replicable under the same design and population assumptions. If a replication study fails to reproduce such a finding, the most plausible explanation is often not ordinary sampling error but some substantive difference between the original and replication studies, such as a weaker manipulation, a different population, a changed measurement procedure, or a failure to reproduce the relevant conditions.
The real difficulty concerns low power in literatures with many studies. A single borderline-significant result cannot demonstrate that a study truly had low power, because the effect-size estimate is too uncertain. But a series of significant results from studies that all appear to have low or modest power is informative in a different way. The problem is not that any one study proves low power with precision. The problem is that repeated success becomes increasingly implausible when the studies, taken together, imply low probabilities of success.
In short, post-hoc power estimates from a single study are not uniformly uninformative. They are often weak for borderline results, but they can be informative when observed evidence is very strong. High power can sometimes be demonstrated from a single study. Low power is usually harder to establish from one study and is better diagnosed from patterns across multiple studies.
Average “Post-Hoc Power” As Bias Test
Power analyses of single studies are often uninformative because the population effect size is unknown and the observed effect-size estimate is noisy. This limitation, however, does not generalize to sets of studies. Post-hoc power analyses of multiple studies can be informative because they allow researchers to compare the expected number of significant results with the number of significant results that was actually observed. This comparison is the basis of several bias tests, including tests proposed by Ioannidis and Trikalinos (2007), Francis (2014), Schimmack (2012), and the z-curve selection model (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020).
Before discussing these tests, it is important to distinguish statistical power from the unconditional probability of obtaining a significant result. In the Neyman-Pearson framework, power is the probability of rejecting a false null hypothesis. It is therefore conditional on H0 being false. After a study has been completed, however, we usually do not know whether the tested null hypothesis was true or false. A set of studies may contain some true effects and some true null hypotheses. Consequently, the expected rate of significant results in such a set is not identical to average power in the strict Neyman-Pearson sense. It is the unconditional probability that a study produces a significant result.
Bartoš and Schimmack introduced the term expected discovery rate (EDR) for this unconditional probability. The EDR is related to power, but it is also influenced by the proportion of true null hypotheses that were tested. If all tested hypotheses are false, the EDR corresponds to average power. If some tested hypotheses are true, the EDR is lower because true null hypotheses can produce significant results only as Type I errors (Sterling et al., 1995).
The EDR is useful because it can be compared with the observed discovery rate (ODR), that is, the actual proportion of significant results in a set of studies. When the ODR is much higher than the EDR, the literature contains more significant results than the population effect sizes and sample sizes of the studies could have produced. This discrepancy provides evidence of selection bias, questionable research practices, or other reporting processes that favor significant results.
This use of post-hoc power is especially important because it addresses a problem that conventional publication-bias methods often handle poorly. Funnel plots and regression-based methods can be difficult to interpret when studies are heterogeneous. A relation between sampling error and effect size may reflect publication bias, but it may also reflect real heterogeneity, differences in study design, or differences in the populations and measures used across studies. Power-based bias tests do not require effect sizes to be homogeneous in the same way. They ask a different question: given the estimated probability that each study would produce a significant result, is the observed number of significant results credible? This makes power-based bias tests a valuable complement to funnel-plot and regression-based methods.
The logic is simple. If five studies each had only a 30% probability of producing a significant result, the probability that all five would be significant is .30⁵ = .0024. A set of five significant results is therefore not impossible, but it is statistically surprising. The problem becomes even more severe in literatures with success rates above 90%, which were common in psychology before the replication crisis. In such literatures, the question is not whether a single significant result was lucky. The question is whether the entire pattern of significant results is plausible under the estimated EDR.
Publication bias also creates a problem for a priori power analyses based on completed studies. When studies are selected for significance, their effect-size estimates are inflated. Sample-size planning based on those inflated estimates will therefore overestimate the power of future replication studies. This is precisely what happened in the Reproducibility Project. The replication studies were planned to have high power based on the original published effect sizes, yet the actual success rate was much lower. This discrepancy has often been treated as puzzling, but it is exactly what should be expected when original effect sizes are inflated by selection for significance.
The more important fact is not simply that the replication success rate was 36%. A low replication rate can have many explanations. The more diagnostic fact is that the original journals had success rates above 90%, whereas the expected discovery rate was much lower. This discrepancy reveals that the published literature contained too many significant results. It also explains why the original effect-size estimates were larger than the replication effect-size estimates and why a priori power analyses based on the original studies overstated the true power of the replications.
In short, “post-hoc power” of a set of studies (i.e., the expected discovery rate) has become an important application for power analyses of completed studies. The results of this application of power analysis also have implications for a priori power analyses. A priori power analysis based on meta-analyses of previous studies with publication bias will produce inflated estimates of power and suggest sample sizes that are too small. Estimating and correction biases in these meta-analyses is therefore important to avoid high type-II error rates in replication studies.
Conclusion
After the cognitive revolution of the 1970s, the affective revolution of the 1980s, the implicit revolution of the 1990s, and the neuroscience revolution of the 2000s, psychology underwent a methodological revolution in the 2010s. This revolution revealed serious defects in how psychologists designed studies, analyzed data, and reported results. It also vindicated Cohen’s long-standing warnings about low statistical power. The replication crisis was therefore not a surprise. It was the predictable consequence of a discipline that had embraced small samples despite Cohen’s reminder that “less is more except for sample size.”
Psychological science is now more attentive to statistical power, but misconceptions about power continue to impede progress. Power analysis is increasingly accepted as a tool for planning better studies, yet researchers still disagree about how to choose the population effect size needed for a meaningful a priori power analysis. At the same time, the focus on a priori planning has encouraged the mistaken belief that power becomes irrelevant once a study has been completed. This belief has led to overly broad claims that post-hoc power calculations should not be conducted.
Giner-Sorolla et al. (2024) already recognized legitimate uses of power calculations for completed studies, especially for evaluating the sensitivity of focal tests rather than relying on sample size alone. However, they remained skeptical of observed-power calculations that use the effect-size estimate from the same completed study, because such estimates often add little beyond the p-value and remain highly uncertain.
Here, I marshal a stronger defense of power calculations based on completed studies. First, I argue that uncertainty about the population effect size is not unique to post-hoc power. Sampling error in effect-size estimates affects a priori power calculations just as much as post-hoc power calculations when both rely on empirical estimates from completed studies. Second, I argue that power calculations based on actual results are essential for evaluating the credibility of published literatures. Only the observed results of completed studies can be used to estimate the expected discovery rate and compare it with the observed discovery rate. This comparison is the basis of power-based tests of publication bias. As long as power calculations are restricted to hypothetical effect sizes, they remain planning exercises; they cannot evaluate whether a published literature contains too many significant results. In this sense, a priori power analyses have limited diagnostic consequences because they are not based on the actual pattern of published findings. By contrast, bias tests that estimate expected discovery rates can challenge the credibility of entire literatures with hundreds of statistically significant results (Chen et al., 2025).
The central problem is not whether a power calculation is conducted before or after data are collected. The central problem is uncertainty. All empirical power calculations are affected by random error, and all calculations based on published findings may be affected by systematic error, especially selection bias. A priori power analyses are not exempt from this problem. If they rely on inflated effect-size estimates from selected literatures, they will overestimate the power of future studies. Conversely, post-hoc power analyses can be informative when they are used to evaluate whether published success rates are credible given the estimated probability of significant results.
Thus, the familiar objections to “post-hoc power” identify real problems, but they misdiagnose their source. The problem is not that power is calculated after the study. The problem is that point estimates are often confused with population quantities. Terms such as “effect size” and “power” are frequently used as shorthand for noisy estimates, while the uncertainty around those estimates is ignored. Clearer language would help: researchers should distinguish effect-size estimates from population effect sizes and power estimates from actual power, and they should report point estimates together with confidence intervals whenever possible.
The future of power analysis should therefore not be limited to a priori sample-size planning. Power estimates also have an important diagnostic function. They can reveal when published literatures contain too many significant results, when effect-size estimates are likely to be inflated, and when a priori power analyses based on those estimates are misleading. Properly understood, post-hoc power analysis is not an abuse of power. It is one tool for correcting the very biases that made the replication crisis possible.
The open science movement has made remarkable progress. Data sharing policies are now standard at top journals. Pre-registration is common. Reproducibility checks are increasingly required. In a recent survey, 97% of social scientists supported posting data and code online (Swanson et al., 2020). Open data is the one reform that enjoys near-universal support.
But open data without open results is performative transparency. If researchers share their data but journals refuse to publish reanalyses that challenge the original conclusions, the data sit in a repository like evidence in a courthouse that never opens.
I recently experienced this firsthand. Dai et al. (2023) published a meta-analysis of implicit priming studies in Psychological Bulletin. The article explicitly states that it “carefully followed the Transparency and Openness Promotion Guidelines.” The data are available. I reanalyzed them using z-curve and a step-function selection model.
The reanalysis reveals a more complex and more concerning picture than the original meta-analysis suggested. A step-function selection model estimates a seemingly robust unobserved average effect size — implicit priming likely produces a real but modest effect. However, the z-curve analysis of the published test statistics tells a different story about the evidence base: ERR ≈ 49%, EDR ≈ 14%, and the false discovery rate could be as high as 69%. Most published studies were too underpowered to provide evidence for the effect, and a substantial proportion of significant results may be false positives. For subliminal priming specifically, the estimated false discovery rate was 100% — none of the significant results can be trusted. The literature points to a real phenomenon but fails to provide credible evidence for it. This changes the interpretation of an entire research literature — from one with heterogeneous but broadly supportive evidence to one where a plausible effect exists but the published record cannot be trusted to distinguish signal from noise.
I submitted this reanalysis to Psychological Bulletin — the same journal that published the original meta-analysis and that endorsed the transparency framework that made the reanalysis possible. It was rejected on procedural grounds, without evaluation of its scientific merit.
The journal’s own policy explains why. Psychological Bulletin “traditionally publishes commentaries that are requested by the action editor in light of issues that arise during the review.” Unsolicited commentaries are accepted only during the brief window before an article appears in print. After that, requests are “rarely granted.” In other words, corrections are reserved for insiders who saw the paper during closed peer review. Once the article is published — and the open data become available to the wider scientific community — the journal closes the door to the very corrections that open data make possible.
This is not a quirk of one journal or one editor. It is a structural feature of the publication system. The journal promoted transparency. The data are available. The reanalysis was conducted. The system worked exactly as designed — until the last step, where the journal declined to publish what transparency revealed.
The evidence that the publication system resists self-correction is growing. Failed replications do not reduce citations of the original studies (Serra-Garcia & Gneezy, 2021; von Hippel, 2022). Replication and reproduction studies are infrequently cited and do not affect the citation trends of original papers (Ankel-Peters et al., 2023; Coupé & Reed, 2022). Now we can add a third category: reanalyses of open data that reach different conclusions cannot find publication outlets — not because they are wrong, but because the policies that govern commentary and correction were designed for a closed system and have not adapted to the open one.
Meta-analyses are precisely the category of paper where reanalysis matters most. The same data analyzed with different statistical methods or different assumptions about selection can support fundamentally different conclusions. Yet Psychological Bulletin does not even award open science badges for meta-analyses, as if transparency is less relevant when the product is a synthesis.
Open science reformers have focused on making inputs transparent — data, code, pre-registration, materials. This is necessary but not sufficient. The bottleneck was never access to data. It is access to readers. A correction on a blog reaches a fraction of the audience that the original paper reached through a top journal.
If open science is to fulfill its promise, “open” must apply not just to data but to results — open to revision when reanalysis warrants it, and open to be seen by the same audience that read the original. Journals that mandate data sharing should commit to considering reanalyses of the data they helped make available. A journal that publishes a meta-analysis under the Transparency and Openness Promotion Guidelines but refuses to publish a reanalysis of the same data is not practicing open science. It is performing it.
In a blog post on Andrew Gelman’s blog, Erik van Zwet voiced serious concerns about the performance of z-curve, a meta-analytic method to detect selection bias. The main concern was that z-curve failed to detect selection bias in a scenario where most observed data come from high-powered studies (noncentrality parameter z = 4) but some come from tests of true H0 (effect size is zero, z = 0). In some cases, there may only be a couple of false positive results and that provides too little information about the file drawer of missing tests of H0).
The first problem that I already addressed is that EvZ’s criticism was invalid because it generalized from a single unrealistic scenario to all other situations and did not mention that z-curve had been validated and performed well in these situations (Schimmack, 2026).
Another selection bias in EvZ’s criticism of z-curve is that he only examined the performance of z-curve and did not compare it to the performance of other models. One advantage of z-curve is that it works even if there is little or no variation in sample sizes, which is a requirement for all regression based methods like Funnel plots, Eggert regression, or PET/PEESE. Thus, the most relevant competitor for z-curve are selection models like Vevea and Wood’s (2005) random-effects, step-function model implemented in the r-package weightr.
I tested the model using the same simulation design that was used to examine the performance of z-curve with identical data. Here I focus on the EvZ scenario where most statistically significant results come tests with high power (d = .6, N = 200, z ~ 4.24, power ~ 98%). Thus, there are few non-significant results that can be suppressed by publication bias.
All simulations had 70% selection bias. That is only 30% of the non-significant results were reported and the distribution was flat. First I examined the performance of weightr with k = 100 significant results. All 100 simulations failed to provide estimates of the selection weight for non-significant results. With k = 300 significant results, bias was detected 92% of the time. With k = 1,000, bias was detected in all 100 simulations.
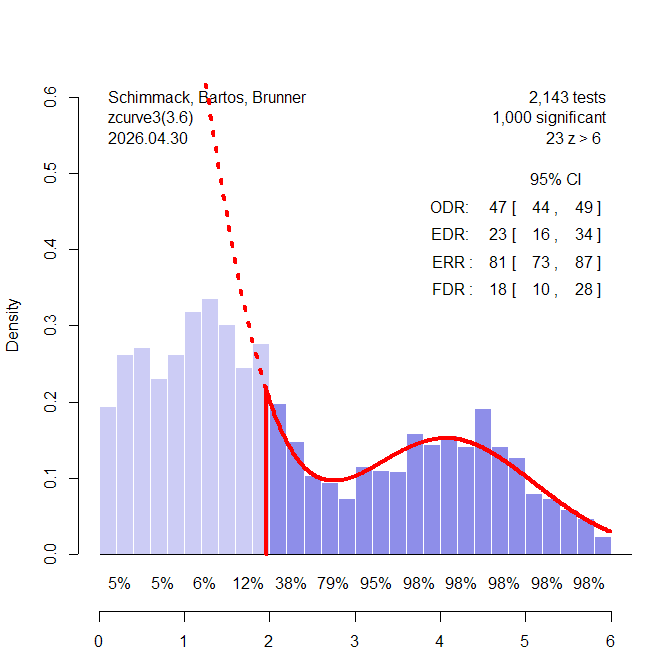
I then examined performance when 20% of the significant results are false positives – and the other 80% come from the same high-powered distribution as before. Figure 1 shows results for a run with k = 1,000 significant results for z-curve. With k = 1,000 z-curve has no problem detecting the selection bias because the distribution of the significant results is clearly bimodal with the mode for the studies with weak power in the non-significant range. Z-curve shows that there are more observed significant results, observed discover rate ODR = 47% than z-curve predicts based on the distribution of the significant results, expected discovery rate, EDR = 23%. The difference is highly significant, p < .000001.
In contrast, the step-function model falsely interprets the higher percentage of non-significant results as evidence that significant results are missing, w(p-value in .025 to .5 range) = 2.24, 95% 2.05 to 2.43. The reason is that the model does not allow for bimodal distributions and assumes a normal distribution of effect sizes, which also implies a normal distribution of z-values when sample sizes are fixed. This problem with the step-function selection model was already reported by Hedges & Vevea (1995). When the simulated data matched the assumed normal distribution, the model worked well. When the distribution did not match the assumed distribution, the model produced bias estimates. The advantage of z-curve is that it does not make a strong distribution assumption and allows for bimodal distributions like the one in Figure 1.
Conclusion
This blog post shows further evidence that EvZ’ expression of concerns about z-curve are biased and do not provide a balanced account of the strengths and weaknesses of z-curve. It is unreasonable to expect a model to perform well in an edge case that also provides problems for other models. In fact, z-curve handles the problem of bimodal distributions better than other models that assume unimodal distributions. If a heterogeneous literature contains a mixture of studies that tested true and false hypotheses, z-curve is actually the superior method and there are no alternatives because most meta-analytic methods were designed to analyze data where all studies are fairly similar and variation in population effect sizes is small. However, many meta-analyses in psychology show evidence of large heterogeneity and the true distribution of effect sizes across studies is unknown. For these kind of data, z-curve is currently the most appropriate statistical tool.
What is open science? Isn’t open science a tautology like “new innovation.” If there is open science, what is closed science? The need for open science arises from the fact that many academic practices are unscientific. They benefit academics without advancing or even hurting science. For example, conducting experiments and not reporting the results when they do not show a favorable outcome is a common academic practice that many people would recognize as undermining science. In psychology, this academic practice is widespread and explains why psychology journals have success rates over 90% (Sterling et al., 1995). Aside from just not publishing unfavorable results, academics also use a number of questionable statistical practices to turn failures into successes (John et al., 2012). All of these practices are well known and accepted among academics who understand the pressure to publish, while the general public focuses on the outcome and not the personal consequences of individual researchers.
Open science is basically the idea of an utopia where academic work produces scientific progress and creates incentive structures that reward honest attempts to advance science rather than meeting invalid indicators like publication and citation counts that can be gamed and can waste millions of dollars without any real progress.
In psychology, Brian Nosek spearheaded the Open Science movement and founded the Open Science Foundation (OSF). He also wrote several influential articles to promote Open Science practices in psychology (e.g., Nosek & Bar-Anan, 2012; Nosek, Spies, & Motyl, 2012).
These articles laid out a comprehensive vision to reform unscientific and counterproductive practices and incentive structures in psychology. Key elements focussed on (a) aligning incentives so truth-seeking wins over career advancement, (b) restructuring the unit of research itself from small teams to distributed collaborations, and (III) promoting a culture of transparency, openness to criticism, and willingness to find out you were wrong.
The Open Science movement has changed psychology in ways that nobody in 2010 could have imagined. Helped by empirical evidence that many results in Brian Nosek’s field of social psychology could not be replicated (a replication rate of 25% in the Open Science Reproducibility Project, 2015), journals now often demand assurances that results are reported honestly and reward practices that limit researchers’ abilities to change hypotheses or results when the original results are disappointing.
However, in other ways, progress has been limited. The main problem is that open admission of mistakes is still rare and researchers fear that any admission of mistakes harms their reputation. Thus, the incentive structure continues to reward promoting false claims. This problem is exacerbated by psychological mechanisms that have been documented in psychological research for decades and are highly robust. Motivated biases make it easier for people to see mistakes in others’ work than in their own work. The Bible calls this “seeing a splinter in others’ eyes, but missing the beam in one’s own eye.” The Nobel Laureate Feynman warned fellow scientists, “The first principle is that you must not fool yourself — and you are the easiest person to fool.”
Motivated Blindness
Ironically Brian Nosek’s work on the IAT provides an example of motivated blindness. All his knowledge and intelligence that helped him to spot the problem in colleague’s work with small samples that does not replicate, does not help him to see the problems in his own work on implicit biases. Originally invented by Anthony Greenwald, Brian Nosek helped to promote the Implicit Association Test (IAT) as a measure of associations that are sometimes called implicit, automatic, or unconscious. The IAT is a reaction time task, but modern technology made it possible to administer it on a website, hosted by Project Implicit and backed by Harvard University.
The IAT was never validated to the psychometric standards required for individual assessment. In practice, it functions like a distorting mirror — reflecting back what people largely already know about their attitudes, buried under substantial measurement error. If it were presented that way, no one would object, and no one would need a warning. But Project Implicit does not present it that way. Instead, visitors are warned that the test may reveal something undesirable about themselves. That warning only makes sense if the results are trustworthy. A distorting mirror does not come with a warning — it comes with a laugh. By framing the IAT as capable of revealing uncomfortable truths, Project Implicit treats an unvalidated research tool as a diagnostic instrument.
The problem is that even in 2024, Brian Nosek is still unable to openly admit that the IAT does not measure implicit biases (reference) and that his own studies, which convinced him the IAT is valid, were flawed. For example, in one study he claimed that a weak correlation of r = .2 between racial bias on the IAT and self-reported racial attitudes demonstrated convergent validity (reference). This is false. A correlation of r = .5 between self-reported height and self-reported weight does not validate either measure — it simply shows that two different constructs share a common method. Convergent validity requires measuring the same construct with different methods, not different constructs with the same method. When the IAT is compared to other implicit measures, the correlations are equally weak and, more importantly, no higher than the correlations with self-report measures (Schimmack, 2021). The IAT therefore provides no evidence that it reveals something about individuals that they do not already know. If somebody is biased against a particular group, they know it. The IAT does not uncover hidden biases — it merely repackages what people can already report about themselves.
While Brian Nosek is no longer actively involved in IAT research, he is still associated with Project Implicit and has made no attempt to correct the misinformation about the IAT given to visitors of the website that even administers mental health IATs without proven validity. Moreover, his students continue to publish misleading articles that make false claims about the IAT. These articles are published in journals that claim to promote open science, but do not allow for open criticism of statistical errors in their publications.
The article “On the Relationship Between Indirect Measures of Black Versus White Racial Attitudes and Discriminatory Outcomes: An Adversarial Collaboration Using a Sample of White Americans” by Axt et al. (2026) seems to meet the latest standards of open science. The research team is diverse with different opinions about the IAT. Hypotheses are preregistered with a clear criterion to claim validity. Brain Nosek was not a collaborator, but strongly endorsed this article on social media as a posterchild of open science practices.
Yet, the paper had a major limitations. It totally ignored the criticism of earlier structural equation modeling studies that failed to take shared method variance into account (Schimmack, 2021) and it made the same mistake again. By including two IATs, the published model treated all shared variance between the two IATs as valid variance, ignoring the well known evidence that IAT scores are also influenced by factors unrelated to the associations being measured. The authors could have avoided this mistake because they inspected Modification Indeces that show problem with a theoretically specified model They used these modification indices to adjust the measurement model for self-ratings, but not for the two IATs.
This mistake itself is not the main problem. Even a large team of scientists can make mistakes, especially if they are not trained in psychometrics and are working with measurement models. The real problem is that the editor of the journal that published the article is unwilling to correct it (Schimmack, 2026). This decision does not meet Open Science standards of open admission of mistakes or even engagement with criticism. Open science requires open discussion and responding to scientific criticism. I emailed Dr. Axt on December 2nd about my concerns and reanalysis of his data, but did not receive a response. This reaction highlights how far we still have to come before we can reach Brian Nosek’s utopia of open criticism and open admission of mistakes. Marketing the IAT as a “window into the unconscious” (Banaji & Greenwald’s, 2013, words, not mine) was a mistake, but Greenwald, Banaji, and Nosek have yet to admit so openly. Instead, Project Implicit continues to give people invalid feedback and Harvard does not care. This is not Open Science. This is naked self-interest to preserve a reputation that was earned with the false promise of addressing racial bias in the United States of America.
Why Do I care?
After cognitive performance tests, the IAT is arguably the most influential psychological test. Implicit bias was a major topic during the 2016 presidential campaign. Hillary Clinton made implicit bias a campaign issue, claiming that many Americans still harbor implicit racial biases. Asked for comment, Greenwald relied on IAT results for the two candidates to “go out on a limb to predict that Clinton’s vote margin on November 8 will exceed the prediction of the final pre-election polls.” The opposite happened. Trump became president and created a new culture that made open expression of racial bias “great again.”
Greenwald’s trust in the IAT was not justified. The IAT had already failed to predict racial bias in the 2008 election that Barack Obama won despite widespread racial prejudice. The IAT did not predict this outcome, but self-reports showed that some people openly admitted to biases that predicted their voting intentions over and above party affiliation (Greenwald et al., 2009).
Hillary Clinton’s endorsement of implicit bias may have cost her votes. The notion of implicit bias is that white people no longer endorse racist ideology, are motivated to avoid racial biases, but are still unconsciously influenced by them. That narrative has not aged well. A decade later, a presidential candidate can stand on a debate stage and say “they’re eating the cats and dogs” to applause, and win. The problem America faces is not hidden bias operating below the threshold of awareness. It is open prejudice, stated plainly, rewarded electorally, and entirely accessible to self-report.
The implicit bias framework misjudged the landscape. It assumed that the social norm against racism was strong and stable, and that the remaining work was to address what operated beneath it. Instead, the norm itself collapsed. Many white Americans are fully aware of their racial biases, are not motivated to change them, and are willing to vote for a candidate who hesitated to distance himself from the KKK. These voters were probably more offended by the suggestion that they are motivated to be unbiased than by the accusation that they have racial biases. Implicit bias training — which cost organizations millions — failed to address the real problem because it was designed for a world in which people wanted to be fair but couldn’t help themselves. That is not the world we live in.
Conclusion
Open science promises to align academic structures, incentives, and practices with the scientific aim of discovering the truth. To do so, science needs to check itself, notice mistakes, and correct them. However, the incentive structure continues to work against this goal. It is telling that Brian Nosek, the most visible proponent of open science in psychology, is unable to follow his own open science principles and admit that his work on the IAT did not produce a valid measure of implicit biases.
One might think that Nosek is in an enviable position to admit past mistakes given his achievements in making psychology more open. He is the Executive Director of the Center for Open Science and has a legacy that does not depend on the IAT. Other psychologists, like John Bargh, built their careers on a single line of research. When social priming failed to replicate, there was little else to fall back on. Walking away from the IAT should be easier by comparison. The fact that Nosek is unable to acknowledge the problems of the IAT shows even more the power of motivated blindness. It also highlights the most important change that is needed to make psychology a science. We need to normalize failure and see it as the inevitable outcome of exploration. Every failure that is openly acknowledged is a learning opportunity that makes success more likely the next time. Daniel Kahneman is a rare example of a psychologist who admitted mistakes in public and gained in recognition as a result. Maybe we should give Brian Nosek a Nobel Prize for his open science work so that he can admit his mistakes about the IAT.
References
Axt, J. R., Connor, P., Hoogeveen, S., Clark, C. J., Vianello, M., Lahey, J. N., Hahn, A., To, J., Petty, R. E., Costello, T. H., Mitchell, G., Tetlock, P. E., & Uhlmann, E. L. (2026). On the relationship between indirect measures of Black versus White racial attitudes and discriminatory outcomes: An adversarial collaboration using a sample of White Americans. Journal of Personality and Social Psychology. Advance online publication. https://dx.doi.org/10.1037/pspa0000480
Greenwald, A. G., Smith, C. T., Sriram, N., Bar-Anan, Y., & Nosek, B. A. (2009). Implicit race attitudes predicted vote in the 2008 U.S. presidential election. Analyses of Social Issues and Public Policy, 9(1), 241–253.
Nosek, B. A., & Bar-Anan, Y. (2012). Scientific Utopia I: Opening Scientific Communication Psychological Inquiry, 23(3), 217–243. DOI: 10.1080/1047840X.2012.692215
Nosek, B. A., Spies, J. R., & Motyl, M. (2012). Scientific Utopia II: Restructuring Incentives and Practices to Promote Truth Over Publishability. Perspectives on Psychological Science, 7(6), 615–631. DOI: 10.1177/1745691612459058
Nosek, B. A. (2024, November 8). Highs and lows on the road out of the replication crisis [Interview]. Clearer Thinking with Spencer Greenberg, Episode 235.
Schimmack, U. (2021). The Implicit Association Test: A method in search of a construct. Perspectives on Psychological Science, 16(2), 396–414. https://doi.org/10.1177/1745691619863798
Schimmack, U. (2021). Invalid claims about the validity of Implicit Association Tests by prisoners of the implicit social-cognition paradigm. Perspectives on Psychological Science, 16(2), 435–442. DOI: 10.1177/1745691621991860
Statistical power is widely known as a tool for planning sample sizes before studies are conducted. Less well known is the use of statistical power after publication to evaluate the credibility of published results in sets of studies, such as meta-analyses.
The basic idea is simple. Statistical power is the probability of obtaining a statistically significant result, typically p < .05. When the null hypothesis is true, this probability equals the alpha criterion, usually 5%. When the null hypothesis is false, power depends on the true population effect size, the sample size, and the significance criterion.
Several publication-bias tests estimate the average power of completed studies and compare it to the actual number of significant results in those studies (Ioannidis & Trikalinos, 2007; Schimmack, 2012). If the observed frequency of significant results is greater than the expected frequency based on average power, this suggests that non-significant results are missing from the published record. This reduces the credibility of the published results. The published literature is less robust than it appears, effect sizes are inflated, and the false-positive risk is higher than the observed success rate suggests.
The negative effects of publication bias on the credibility of published findings are well known and not controversial. Although publication bias is common, there is broad agreement that it is a problem. Publication-bias tests make it possible to detect this problem empirically.
The main challenge for power-based bias tests is estimating the true average power of completed studies. Developing and comparing different estimation methods is an active area of research, but these methods rely on the same basic principle: a set of studies cannot honestly produce substantially more significant results than its average power predicts. With reported success rates above 90% in many psychology journals, power-based tests typically show clear evidence of selection bias.
A few critical articles and blog posts have raised concerns about estimating average true power. However, these criticisms often do not engage with the actual goal of methods that use average power to detect publication bias. For example, McShane et al. acknowledge that average power says “something about replicability if we were able to replicate in the purely hypothetical repeated sampling sense and if we defined success in terms of statistical significance.” McShane objects that this is not useful because new replication studies can differ from original studies. But the purpose of computing average power in meta-analyses of completed studies is not to plan future studies or predict their exact outcomes. The purpose is to examine the credibility of the completed studies.
If a published literature reports 90% significant results but the completed studies had only 20% average power, the published record does not provide credible evidence for the claim, even if it contains hundreds of significant results. Critics of average-statistical power calculations often ignore this important information. Average power is not merely a planning tool. It is also a diagnostic tool for evaluating whether a published body of evidence is too successful to be credible.
An Average Power Primer: Clarifying Misconceptions about Average Power and Replicability
Cohen (1988) introduced power analysis for the planning of studies to reduce false negative (type-II error) rates in psychological science. After the replication crisis, the importance of a priori power analyses has gained increasing attention. However, the estimation of actual power of studies remains neglected. This article clarifies important differences between power analyses with hypothetical effect sizes to plan studies and power analyses of actual studies that have been completed. Knowing the actual power of completed studies is important because it can be used to assess publication bias. Sets of studies that have high success rates, but low power do not provide credible evidence for a hypothesis.
Chapter 8 examines whether major life events produce lasting changes in subjective well-being. It begins with adaptation theory, especially the “hedonic treadmill” idea, which claims that people quickly return to their baseline level of happiness after good or bad events. The chapter argues that this view is too pessimistic. People do adapt to some changes, but not all. Life circumstances can have lasting effects, especially when they affect important goals, daily experiences, income, status, relationships, or health.
The chapter distinguishes two mechanisms that can make gains fade over time. First, aspirations can rise. As people get better housing, higher income, or newer products, their standards also increase, so satisfaction may not rise much. Second, emotional reactions are often strongest when circumstances change. A new house or improved condition may feel exciting at first, but the emotional boost fades as the new situation becomes normal. These mechanisms differ across life domains. They may be strong for income or housing, but weaker for close relationships, where ongoing engagement continues to matter.
The chapter then reviews evidence on unemployment. Unemployment is one of the clearest examples of a life event with a strong and persistent negative effect on well-being. It reduces income, status, structure, purpose, and social contact. Panel studies show that people do not simply adapt to long-term unemployment. Their well-being remains lower while they are unemployed and improves when they find new work. Much of the effect appears to operate through income and financial satisfaction, but unemployment also affects status and purpose.
Housing shows a different pattern. Moving to a better home increases housing satisfaction, and this improvement can last. However, global life satisfaction often changes little. This does not mean housing is unimportant. Rather, housing may fade into the background of daily life and may be underweighted when people make global life evaluations. Domain-specific measures show that housing conditions matter, especially when they affect daily life through noise, crowding, poor physical conditions, safety, or comfort. The chapter uses housing to show why domain satisfaction is essential for understanding well-being.
Disability provides a more complex case. Early claims that people adapt almost completely to disability were based on weak evidence. Better panel studies show that acquired disability often produces lasting declines in life satisfaction, especially when it involves broader health deterioration. However, people born with disabilities often report higher well-being than those who acquire disabilities later. This supports the ideal-based framework: people born with a disability form their goals and identity around that condition, whereas people who acquire a disability must revise previously formed ideals. Adaptation depends less on time alone than on whether people can build new goals compatible with their changed circumstances.
The chapter gives special attention to relationships. Cross-sectional studies show that partnered people are generally happier than singles, but earlier research underestimated the effect because it focused on marriage rather than partnership. Weddings may produce only temporary increases in well-being, but having a stable partner appears to have a lasting positive effect for most people. Cohabitation and committed partnership matter more than legal marital status. Most people want a partner, and those without one tend to report lower well-being. Happy lifelong singles exist, but they appear to be the exception rather than the rule.
Partnership improves well-being partly through material advantages, because couples often share income and expenses. However, income explains only a small part of the partnership effect. Family satisfaction and relationship quality explain more. Partnership provides emotional support, shared life management, intimacy, and companionship. Sexual satisfaction contributes somewhat, but relationship satisfaction is much more important. Thus, the benefits of partnership are not reducible to money or sex.
The chapter also discusses spousal similarity in well-being. Spouses are more similar in well-being than would be expected from genetics alone, and their well-being tends to change in the same direction over time. This suggests that shared environments, such as household income, housing, relationship quality, and common life events, influence both partners. Some similarity may reflect assortative mating or stable shared conditions, but the evidence points strongly to environmental influences within couples.
The conclusion is that adaptation is real but not automatic. Some changes, such as improvements in housing, may produce lasting domain-specific satisfaction without strongly affecting global life satisfaction. Other events, such as unemployment, divorce, and disability, can reduce well-being until circumstances or goals change. Pursuing happiness through life changes is not futile, but people need to consider how changes will affect everyday life, goal progress, and long-term priorities. Novelty can be exciting, but lasting well-being depends more on stable fit between actual life, personal ideals, and daily experience.