Meta-Analysis of Observed Power
Citation: Dr. R (2015). Meta-analysis of observed power. R-Index Bulletin, Vol(1), A2.
In a previous blog post, I presented an introduction to the concept of observed power. Observed power is an estimate of the true power on the basis of observed effect size, sampling error, and significance criterion of a study. Yuan and Maxwell (2005) concluded that observed power is a useless construct when it is applied to a single study, mainly because sampling error in a single study is too large to obtain useful estimates of true power. However, sampling error decreases as the number of studies increases and observed power in a set of studies can provide useful information about the true power in a set of studies.
This blog post introduces various methods that can be used to estimate power on the basis of a set of studies (meta-analysis). I then present simulation studies that compare the various estimation methods in terms of their ability to estimate true power under a variety of conditions. In this blog post, I examine only unbiased sets of studies. That is, the sample of studies in a meta-analysis is a representative sample from the population of studies with specific characteristics. The first simulation assumes that samples are drawn from a population of studies with fixed effect size and fixed sampling error. As a result, all studies have the same true power (homogeneous). The second simulation assumes that all studies have a fixed effect size, but that sampling error varies across studies. As power is a function of effect size and sampling error, this simulation models heterogeneity in true power. The next simulations assume heterogeneity in population effect sizes. One simulation uses a normal distribution of effect sizes. Importantly, a normal distribution has no influence on the mean because effect sizes are symmetrically distributed around the mean effect size. The next simulations use skewed normal distributions. This simulation provides a realistic scenario for meta-analysis of heterogeneous sets of studies such as a meta-analysis of articles in a specific journal or articles on different topics published by the same author.
Observed Power Estimation Method 1: The Percentage of Significant Results
The simplest method to determine observed power is to compute the percentage of significant results. As power is defined as the long-range percentage of significant results, the percentage of significant results in a set of studies is an unbiased estimate of the long-term percentage. The main limitation of this method is that the dichotomous measure (significant versus insignificant) is likely to be imprecise when the number of studies is small. For example, two studies can only show observed power values of 0, 25%, 50%, or 100%, even if true power were 75%. However, the percentage of significant results plays an important role in bias tests that examine whether a set of studies is representative. When researchers hide non-significant results or use questionable research methods to produce significant results, the percentage of significant results will be higher than the percentage of significant results that could have been obtained on the basis of the actual power to produce significant results.
Observed Power Estimation Method 2: The Median
Schimmack (2012) proposed to average observed power of individual studies to estimate observed power. Yuan and Maxwell (2005) demonstrated that the average of observed power is a biased estimator of true power. It overestimates power when power is less than 50% and it underestimates true power when power is above 50%. Although the bias is not large (no more than 10 percentage points), Yuan and Maxwell (2005) proposed a method that produces an unbiased estimate of power in a meta-analysis of studies with the same true power (exact replication studies). Unlike the average that is sensitive to skewed distributions, the median provides an unbiased estimate of true power because sampling error is equally likely (50:50 probability) to inflate or deflate the observed power estimate. To avoid the bias of averaging observed power, Schimmack (2014) used median observed power to estimate the replicability of a set of studies.
Observed Power Estimation Method 3: P-Curve’s KS Test
Another method is implemented in Simonsohn’s (2014) pcurve. Pcurve was developed to obtain an unbiased estimate of a population effect size from a biased sample of studies. To achieve this goal, it is necessary to determine the power of studies because bias is a function of power. The pcurve estimation uses an iterative approach that tries out different values of true power. For each potential value of true power, it computes the location (quantile) of observed test statistics relative to a potential non-centrality parameter. The best fitting non-centrality parameter is located in the middle of the observed test statistics. Once a non-central distribution has been found, it is possible to assign each observed test-value a cumulative percentile of the non-central distribution. For the actual non-centrality parameter, these percentiles have a uniform distribution. To find the best fitting non-centrality parameter from a set of possible parameters, pcurve tests whether the distribution of observed percentiles follows a uniform distribution using the Kolmogorov-Smirnov test. The non-centrality parameter with the smallest test statistics is then used to estimate true power.
Observed Power Estimation Method 4: P-Uniform
van Assen, van Aert, and Wicherts (2014) developed another method to estimate observed power. Their method is based on the use of the gamma distribution. Like the pcurve method, this method relies on the fact that observed test-statistics should follow a uniform distribution when a potential non-centrality parameter matches the true non-centrality parameter. P-uniform transforms the probabilities given a potential non-centrality parameter with a negative log-function (-log[x]). These values are summed. When probabilities form a uniform distribution, the sum of the log-transformed probabilities matches the number of studies. Thus, the value with the smallest absolute discrepancy between the sum of negative log-transformed percentages and the number of studies provides the estimate of observed power.
Observed Power Estimation Method 5: Averaging Standard Normal Non-Centrality Parameter
In addition to these existing methods, I introduce to novel estimation methods. The first new method converts observed test statistics into one-sided p-values. These p-values are then transformed into z-scores. This approach has a long tradition in meta-analysis that was developed by Stouffer et al. (1949). It was popularized by Rosenthal during the early days of meta-analysis (Rosenthal, 1979). Transformation of probabilities into z-scores makes it easy to aggregate probabilities because z-scores follow a symmetrical distribution. The average of these z-scores can be used as an estimate of the actual non-centrality parameter. The average z-score can then be used to estimate true power. This approach avoids the problem of averaging power estimates that power has a skewed distribution. Thus, it should provide an unbiased estimate of true power when power is homogenous across studies.
Observed Power Estimation Method 6: Yuan-Maxwell Correction of Average Observed Power
Yuan and Maxwell (2005) demonstrated a simple average of observed power is systematically biased. However, a simple average avoids the problems of transforming the data and can produce tighter estimates than the median method. Therefore I explored whether it is possible to apply a correction to the simple average. The correction is based on Yuan and Maxwell’s (2005) mathematically derived formula for systematic bias. After averaging observed power, Yuan and Maxwell’s formula for bias is used to correct the estimate for systematic bias. The only problem with this approach is that bias is a function of true power. However, as observed power becomes an increasingly good estimator of true power in the long run, the bias correction will also become increasingly better at correcting the right amount of bias.
The Yuan-Maxwell correction approach is particularly promising for meta-analysis of heterogeneous sets of studies such as sets of diverse studies in a journal. The main advantage of this method is that averaging of power makes no assumptions about the distribution of power across different studies (Schimmack, 2012). The main limitation of averaging power was the systematic bias, but Yuan and Maxwell’s formula makes it possible to reduce this systematic bias, while maintaining the advantage of having a method that can be applied to heterogeneous sets of studies.
RESULTS
Homogeneous Effect Sizes and Sample Sizes
The first simulation used 100 effect sizes ranging from .01 to 1.00 and 50 sample sizes ranging from 11 to 60 participants per condition (Ns = 22 to 120), yielding 5000 different populations of studies. The true power of these studies was determined on the basis of the effect size, sample size, and the criterion p < .025 (one-tailed), which is equivalent to .05 (two-tailed). Sample sizes were chosen so that average power across the 5,000 studies was 50%. The simulation drew 10 random samples from each of the 5,000 populations of studies. Each sample of a study simulated a between-subject design with the given population effect size and sample size. The results were stored as one-tailed p-values. For the meta-analysis p-values were converted into z-scores. To avoid biases due to extreme outliers, z-scores greater than 5 were set to 5 (observed power = .999).
The six estimation methods were then used to compute observed power on the basis of samples of 10 studies. The following figures show observed power as a function of true power. The green lines show the 95% confidence interval for different levels of true power. The figure also includes red dashed lines for a value of 50% power. Studies with more than 50% observed power would be significant. Studies with less than 50% observed power would be non-significant. The figures also include a blue line for 80% true power. Cohen (1988) recommended that researchers should aim for a minimum of 80% power. It is instructive how accurate estimation methods are in evaluating whether a set of studies met this criterion.
The histogram shows the distribution of true power across the 5,000 populations of studies.
The histogram shows 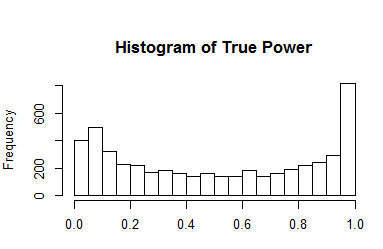 that the simulation covers the full range of power. It also shows that high-powered studies are overrepresented because moderate to large effect sizes can achieve high power for a wide range of sample sizes. The distribution is not important for the evaluation of different estimation methods and benefits all estimation methods equally because observed power is a good estimator of true power when true power is close to the maximum (Yuan & Maxwell, 2005).
that the simulation covers the full range of power. It also shows that high-powered studies are overrepresented because moderate to large effect sizes can achieve high power for a wide range of sample sizes. The distribution is not important for the evaluation of different estimation methods and benefits all estimation methods equally because observed power is a good estimator of true power when true power is close to the maximum (Yuan & Maxwell, 2005).
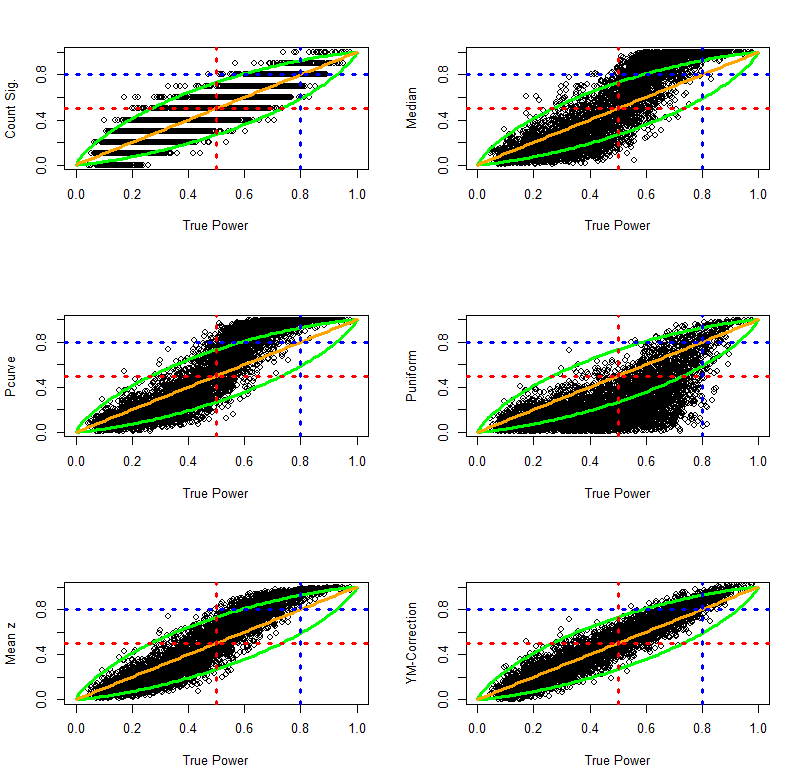
The next figure shows scatterplots of observed power as a function of true power. Values above the diagonal indicate that observed power overestimates true power. Values below the diagonal show that observed power underestimates true power.
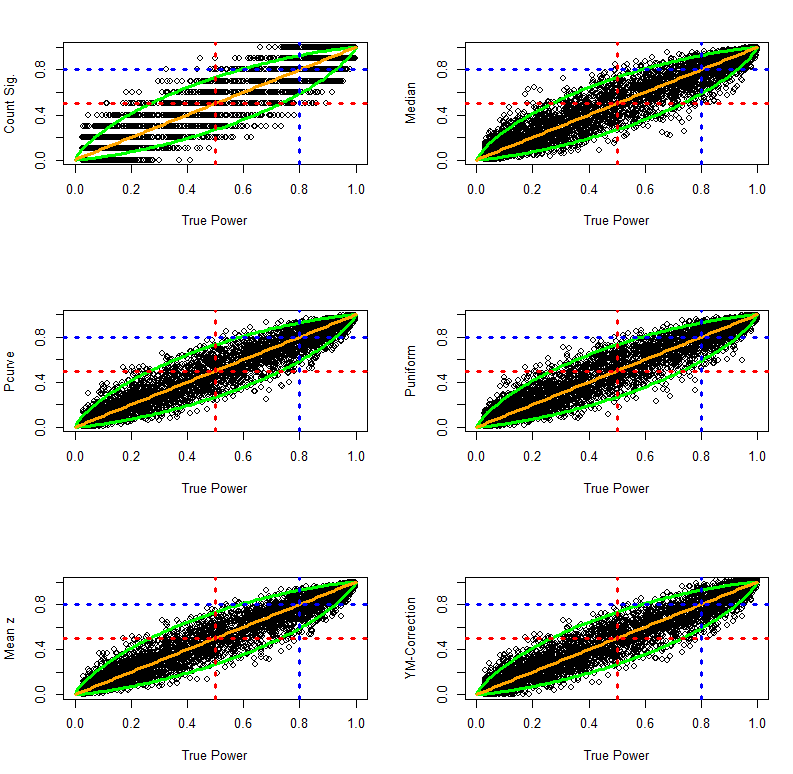
Visual inspection of the plots suggests that all methods provide unbiased estimates of true power. Another observation is that the count of significant results provides the least accurate estimates of true power. The reason is simply that aggregation of dichotomous variables requires a large number of observations to approximate true power. The third observation is that visual inspection provides little information about the relative accuracy of the other methods. Finally, the plots show how accurate observed power estimates are in meta-analysis of 10 studies. When true power is 50%, estimates very rarely exceed 80%. Similarly, when true power is above 80%, observed power is never below 50%. Thus, observed power can be used to examine whether a set of studies met Cohen’s recommended guidelines to conduct studies with a minimum of 80% power. If observed power is 50%, it is nearly certain that the studies did not have the recommended 80% power.
To examine the relative accuracy of different estimation methods quantitatively, I computed bias scores (observed power – true power). As bias can overestimate and underestimate true power, the standard deviation of these bias scores can be used to quantify the precision of various estimation methods. In addition, I present the mean to examine whether a method has large sample accuracy (i.e. the bias approaches zero as the number of simulations increases). I also present the percentage of studies with no more than 20% points bias. Although 20% bias may seem large, it is not important to estimate power with very high precision. When observed power is below 50%, it suggests that a set of studies was underpowered even if the observed power estimate is an underestimation.
The quantitati ve analysis also shows no meaningful differences among the estimation methods. The more interesting question is how these methods perform under more challenging conditions when the set of studies are no longer exact replication studies with fixed power.
ve analysis also shows no meaningful differences among the estimation methods. The more interesting question is how these methods perform under more challenging conditions when the set of studies are no longer exact replication studies with fixed power.
Homogeneous Effect Size, Heterogeneous Sample Sizes
The next simulation simulated variation in sample sizes. For each population of studies, sample sizes were varied by multiplying a particular sample size by factors of 1 to 5.5 (1.0, 1.5,2.0…,5.5). Thus, a base-sample-size of 40 created a range of sample sizes from 40 to 220. A base-sample size of 100 created a range of sample sizes from 100 to 2,200. As variation in sample sizes increases the average sample size, the range of effect sizes was limited to a range from .004 to .4 and effect sizes were increased in steps of d = .004. The histogram shows the distribution of power in the 5,000 population of studies.

The simulation covers the full range of true power, although studies with low and very high power are overrepresented.
The results are visually not distinguishable from those in the previous simulation.
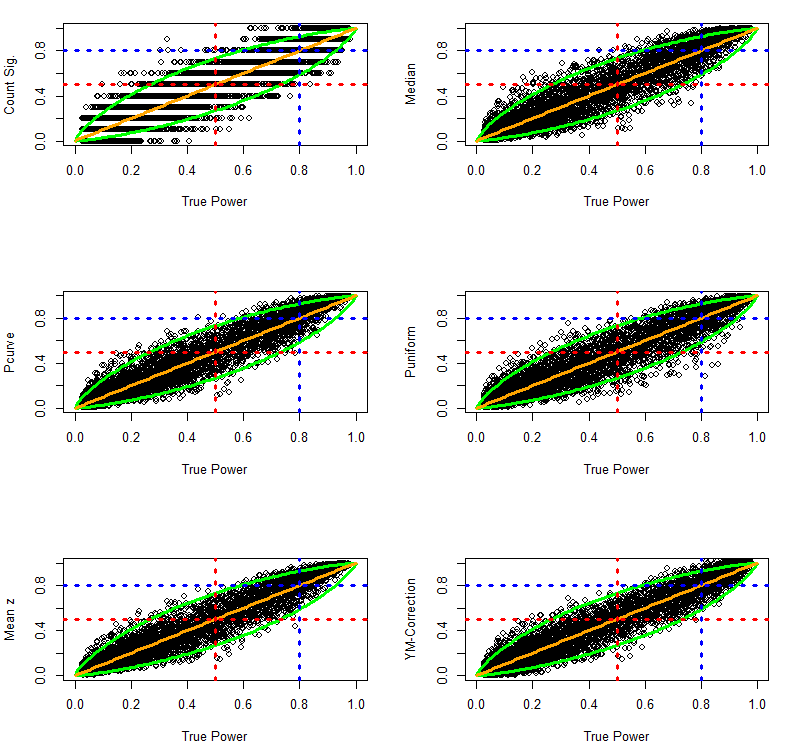
The quantitative comparison of the estimation methods also shows very similar results.

In sum, all methods perform well even when true power varies as a function of variation in sample sizes. This conclusion may not generalize to more extreme simulations of variation in sample sizes, but more extreme variations in sample sizes would further increase the average power of a set of studies because the average sample size would increase as well. Thus, variation in effect sizes poses a more realistic challenge for the different estimation methods.
Heterogeneous, Normally Distributed Effect Sizes
The next simulation used a random normal distribution of true effect sizes. Effect sizes were simulated to have a reasonable but large variation. Starting effect sizes ranged from .208 to 1.000 and increased in increments of .008. Sample sizes ranged from 10 to 60 and increased in increments of 2 to create 5,000 populations of studies. For each population of studies, effect sizes were sampled randomly from a normal distribution with a standard deviation of SD = .2. Extreme effect sizes below d = -.05 were set to -.05 and extreme effect sizes above d = 1.20 were set to 1.20. The first histogram of effect sizes shows the 50,000 population effect sizes. The histogram on the right shows the distribution of true power for the 5,000 sets of 10 studies.

The plots of observed and true power show that the estimation methods continue to perform rather well even when population effect sizes are heterogeneous and normally distributed.

The quantitative comparison suggests that puniform has some problems with heterogeneity. More detailed studies are needed to examine whether this is a persistent problem for puniform, but given the good performance of the other methods it seems easier to use these methods.

Heterogeneous, Skewed Normal Effect Sizes
The next simulation puts the estimation methods to a stronger challenge by introducing skewed distributions of population effect sizes. For example, a set of studies may contain mostly small to moderate effect sizes, but a few studies examined large effect sizes. To simulated skewed effect size distributions, I used the rsnorm function of the fGarch package. The function creates a random distribution with a specified mean, standard deviation, and skew. I set the mean to d = .2, the standard deviation to SD = .2, and skew to 2. The histograms show the distribution of effect sizes and the distribution of true power for the 5,000 sets of studies (k = 10).
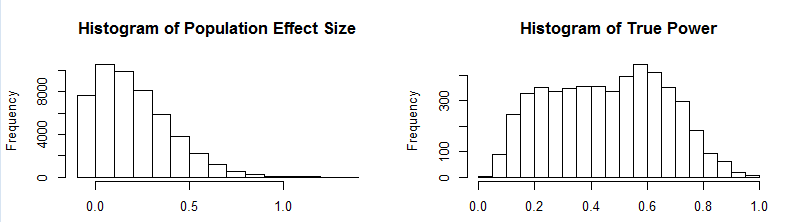
This time the results show differences between estimation methods in the ability of various estimation methods to deal with skewed heterogeneity. The percentage of significant results is unbiased, but is imprecise due to the problem of averaging dichotomous variables. The other methods show systematic deviations from the 95% confidence interval around the true parameter. Visual inspection suggests that the Yuan-Maxwell correction method has the best fit.
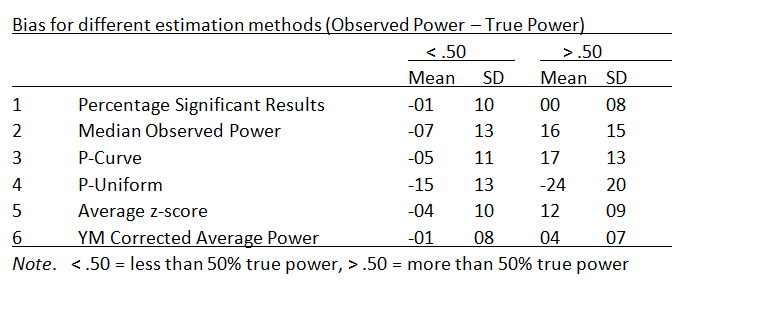
This impression is confirmed in quantitative analyses of bias. The quantitative comparison confirms major problems with the puniform estimation method. It also shows that the median, p-curve, and the average z-score method have the same slight positive bias. Only the Yuan-Maxwell corrected average power shows little systematic bias.
To examine biases in more detail, the following graphs plot bias as a function of true power. These plots can reveal that a method may have little average bias, but has different types of bias for different levels of power. The results show little evidence of systematic bias for the Yuan-Maxwell corrected average of power.
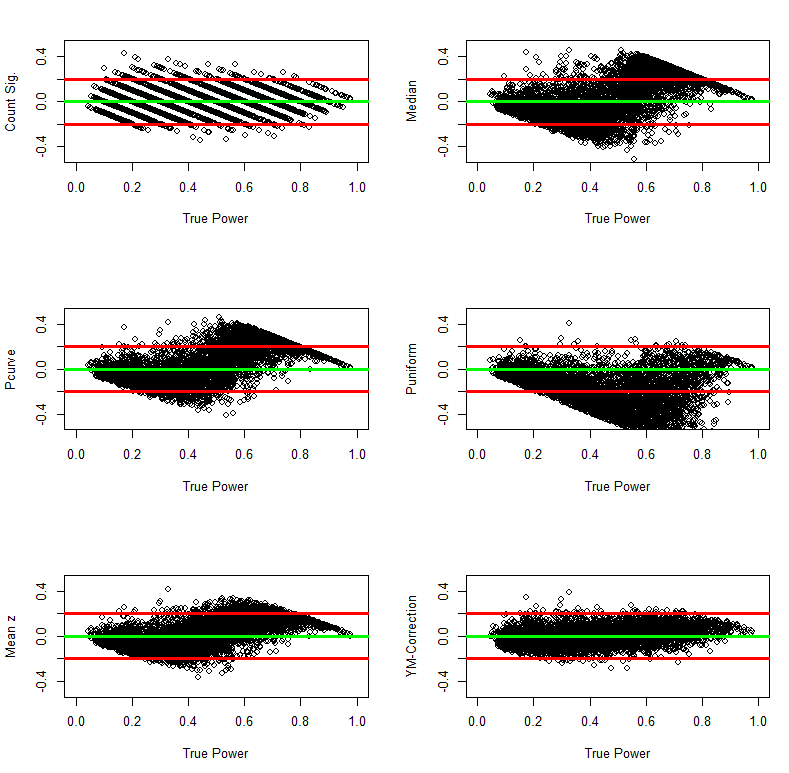
The following analyses examined bias separately for simulation with less or more than 50% true power. The results confirm that all methods except the Yuan-Maxwell correction underestimate power when true power is below 50%. In contrast, most estimation methods overestimate true power when true power is above 50%. The exception is puniform which still underestimated true power. More research needs to be done to understand the strange performance of puniform in this simulation. However, even if p-uniform could perform better, it is likely to be biased with skewed distributions of effect sizes because it assumes a fixed population effect size.
Conclusion
This investigation introduced and compared different methods to estimate true power for a set of studies. All estimation methods performed well when a set of studies had the same true power (exact replication studies), when effect sizes were homogenous and sample sizes varied, and when effect sizes were normally distributed and sample sizes were fixed. However, most estimation methods were systematically biased when the distribution of effect sizes was skewed. In this situation, most methods run into problems because the percentage of significant results is a function of the power of individual studies rather than the average power.
The results of these analyses suggest that the R-Index (Schimmack, 2014) can be improved by simply averaging power and then applying the Yuan-Maxwell correction. However, it is important to realize that the median method tends to overestimate power when power is greater than 50%. This makes it even more difficult for the R-Index to produce an estimate of low power when power is actually high. The next step in the investigation of observed power is to examine how different methods perform in unrepresentative (biased) sets of studies. In this case, the percentage of significant results is highly misleading. For example, Sterling et al. (1995) found percentages of 95% power, which would suggest that studies had 95% power. However, publication bias and questionable research practices create a bias in the sample of studies that are being published in journals. The question is whether other observed power estimates can reveal bias and can produce accurate estimates of the true power in a set of studies.