
It is well-known that scientific journals favor statistically significant results (Sterling, 1959). This phenomenon is known as publication bias. Publication bias can be easily detected by comparing the observed statistical power of studies with the success rate in journals. Success rates of 90% or more would only be expected if most theoretical predictions are true and empirical studies have over 90% statistical power to produce significant results. Estimates of statistical power range from 20% to 50% (Button et al., 2015, Cohen, 1962). It follows that for every published significant result an unknown number of non-significant results has occurred that remained unpublished. These results linger in researchers proverbial file-drawer or more literally in unpublished data sets on researchers’ computers.
The selection of significant results also creates an incentive for researchers to produce significant results. In rare cases, researchers simply fabricate data to produce significant results. However, scientific fraud is rare. A more serious threat to the integrity of science is the use of questionable research practices. Questionable research practices are all research activities that create a systematic bias in empirical results. Although systematic bias can produce too many or too few significant results, the incentive to publish significant results suggests that questionable research practices are typically used to produce significant results.
In sum, publication bias and questionable research practices contribute to an inflated success rate in scientific journals. So far, it has been difficult to examine the prevalence of questionable research practices in science. One reason is that publication bias and questionable research practices are conceptually overlapping. For example, a research article may report the results of a 2 x 2 x 2 ANOVA or a regression analysis with 5 predictor variables. The article may only report the significant results and omit detailed reporting of the non-significant results. For example, researchers may state that none of the gender effects were significant and not report the results for main effects or interaction with gender. I classify these cases as publication bias because each result tests a different hypothesis., even if the statistical tests are not independent.
Questionable research practices are practices that change the probability of obtaining a specific significant result. An example would be a study with multiple outcome measures that would support the same theoretical hypothesis. For example, a clinical trial of an anti-depressant might include several depression measures. In this case, a researcher can increase the chances of a significant result by conducting tests for each measure. Other questionable research practices would be optional stopping once a significant result is obtained, selective deletion of cases based on the results after deletion. A common consequence of these questionable practices is that they will produce results that meet the significance criterion, but deviate from the distribution that is expected simply on the basis of random sampling error.
A number of articles have tried to examine the prevalence of questionable research practices by comparing the frequency of p-values above and below the typical criterion of statistical significance, namely a p-value less than .05. The logic is that random error would produce a nearly equal amount of p-values just above .05 (e.g., p = .06) and below .05 (e.g., p = .04). According to this logic, questionable research practices are present, if there are more p-values just below the criterion than p-values just above the criterion (Masicampo & Lalande, 2012).
Daniel Lakens has pointed out some problems with this approach. The most crucial problem is that publication bias alone is sufficient to predict a lower frequency of p-values below the significance criterion. After all, these p-values imply a non-significant result and non-significant results are subject to publication bias. The only reason why p-values of .06 are reported with higher frequency than p-values of .11 is that p-values between .05 and .10 are sometimes reported as marginally significant evidence for a hypothesis. Another problem is that many p-values of .04 are not reported as p = .04, but are reported as p < .05. Thus, the distribution of p-values close to the criterion value provides unreliable information about the prevalence of questionable research practices.
In this blog post, I introduce an alternative approach to the detection of questionable research practices that produce just significant results. Questionable research practices and publication bias have different effects on the distribution of p-values (or corresponding measures of strength of evidence). Whereas publication bias will produce a distribution that is consistent with the average power of studies, questionable research practice will produce an abnormal distribution with a peak just below the significance criterion. In other words, questionable research practices produce a distribution with too few non-significant results and too few highly significant results.
I illustrate this test of questionable research practices with post-hoc-power analysis of three journals. One journal shows neither signs of publication bias, nor significant signs of questionable research practices. The second journal shows clear evidence of publication bias, but no evidence of questionable research practices. The third journal illustrates the influence of publication bias and questionable research practices.
Example 1: A Relatively Unbiased Z-Curve
The first example is based on results published during the years 2010-2014 in the Journal of Experimental Psychology: Learning, Memory, and Cognition. A text-mining program searched all articles for publications of F-tests, t-tests, correlation coefficients, regression coefficients, odds-ratios, confidence intervals, and z-tests. Due to the inconsistent and imprecise reporting of p-values (p = .02 or p < .05), p-values were not used. All statistical tests were converted into absolute z-scores.
The program found 14,800 tests. 8,423 tests were in the critical interval between z = 2 and z = 6 that is used for estimation of 4 non-centrality parameters and 4 weights that are used to model the distribution of z-values between 2 and 6 and to estimate the distribution in the range from 0 to 2. Z-values greater than 6 are not used because they correspond to Power close to 1. 11% of all tests fall into this region of z-scores that are not shown.
 The histogram and the blue density distribution show the observed data. The green curve shows the predicted distribution based on the post-hoc power analysis. Post-hoc power analysis suggests that the average power of significant results is 67%. Power for all statistical tests is estimated to be 58% (including 11% of z-scores greater than 6, power is .58*.89 + .11 = 63%). More important is the predicted distribution of z-scores. The predicted distribution on the left side of the criterion value matches the observed distribution rather well. This shows that there are not a lot of missing non-significant results. In other words, there does not appear to be a file-drawer of studies with non-significant results. There is also only a very small blip in the observed data just at the level of statistical significance. The close match between the observed and predicted distributions suggests that results in this journal are relatively free of systematic bias due to publication bias or questionable research practices.
The histogram and the blue density distribution show the observed data. The green curve shows the predicted distribution based on the post-hoc power analysis. Post-hoc power analysis suggests that the average power of significant results is 67%. Power for all statistical tests is estimated to be 58% (including 11% of z-scores greater than 6, power is .58*.89 + .11 = 63%). More important is the predicted distribution of z-scores. The predicted distribution on the left side of the criterion value matches the observed distribution rather well. This shows that there are not a lot of missing non-significant results. In other words, there does not appear to be a file-drawer of studies with non-significant results. There is also only a very small blip in the observed data just at the level of statistical significance. The close match between the observed and predicted distributions suggests that results in this journal are relatively free of systematic bias due to publication bias or questionable research practices.
Example 2: A Z-Curve with Publication Bias
The second example is based on results published in the Attitudes & Social Cognition Section of the Journal of Personality and Social Psychology. The text-mining program retrieved 5,919 tests from articles published between 2010 and 2014. 3,584 tests provided z-scores in the range from 2 to 6 that is being used for model fitting.

The average power of significant results in JPSP-ASC is 55%. This is significantly less than the average power in JEP-LMC, which was used for the first example. The estimated power for all statistical tests, including those in the estimated file drawer, is 35%. More important is the estimated distribution of z-values. On the right side of the significance criterion the estimated curve shows relatively close fit to the observed distribution. This finding shows that random sampling error alone is sufficient to explain the observed distribution. However, on the left side of the distribution, the observed z-scores drop off steeply. This drop is consistent with the effect of publication bias that researchers do not report all non-significant results. There is only a slight hint that questionable research practices are also present because observed z-scores just above the criterion value are a bit more frequent than the model predicts. However, this discrepancy is not conclusive because the model could increase the file drawer, which would produce a steeper slope. The most important characteristic of this z-curve is the steep cliff on the left side of the criterion value and the gentle slope on the right side of the criterion value.
Example 3: A Z-Curve with Questionable Research Practices.
Example 3 uses results published in the journal Aggressive Behavior during the years 2010 to 2014. The text mining program found 1,429 results and 863 z-scores in the range from 2 to 6 that were used for the post-hoc-power analysis.
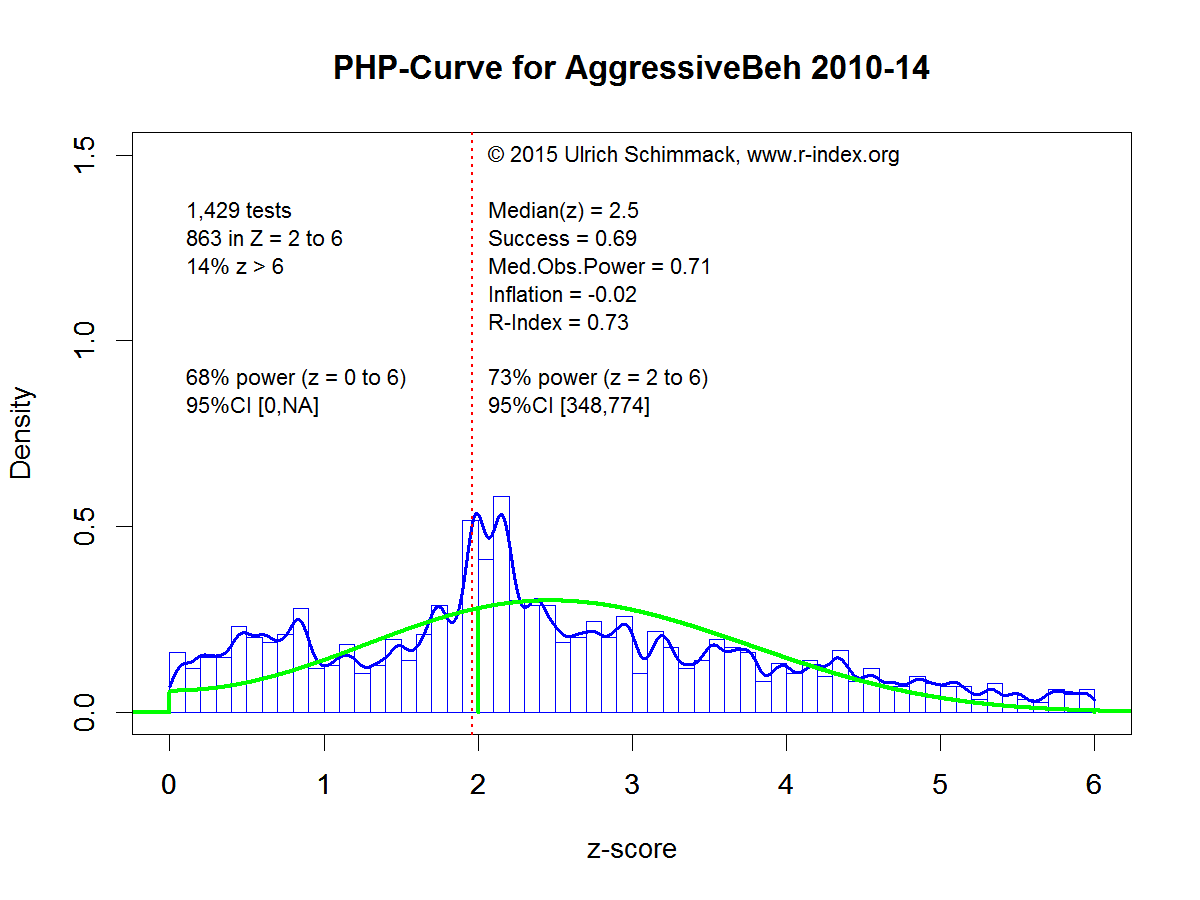
The average power for significant results in the range from 2 to 6 is 73%, which is similar to the power estimate in the first example. The power estimate that includes non-significant results is 68%. The power estimate is similar because there is no evidence of a file drawer with many underpowered studies. In fact, there are more observed non-significant results than predicted non-significant results, especially for z-scores close to zero. This outcome shows some problems of estimating the frequency of non-significant results based on the distribution of significant results. More important, the graph shows a cluster of z-scores just above and below the significance criterion. The step cliff to the left of the criterion might suggest publication bias, but the whole distribution does not show evidence of publication bias. Moreover, the steep cliff on the right side of the cluster cannot be explained with publication bias. Only questionable research practices can produce this cliff because publication bias relies on random sampling error which leads to a gentle slope of z-scores as shown in the second example.
Prevalence of Questionable Research Practices
The examples suggest that the distribution of z-scores can be used to distinguish publication bias and questionable research practices. Based on this approach, the prevalence of questionable research practices would be rare. The journal Aggressive Behavior is exceptional. Most journals show a pattern similar to Example 2, with varying sizes of the file drawer. However, this does not mean that questionable research practices are rare because it is most likely that the pattern observed in Example 2 is a combination of questionable research practices and publication bias. As shown in Example 2, the typical power of statistical tests that produce a significant result is about 60%. However, researchers do not know which experiments will produce significant results. Slight modifications in experimental procedures, so-called hidden moderators, can easily change an experiment with 60% power into an experiment with 30% power. Thus, the probability of obtaining a significant result in a replication study is less than the nominal power of 60% that is implied by post-hoc-power analysis. With only 30% to 60% power, researchers will frequently encounter results that fail to produce an expected significant result. In this case, researchers have two choices to avoid reporting a non-significant result. They can put the study in the file-drawer or they can try to salvage the study with the help of questionable research practices. It is likely that researchers will do both and that the course of action depends on the results. If the data show a trend in the right direction, questionable research practices seem an attractive alternative. If the data show a trend in the opposite direction, it is more likely that the study will be terminated and the results remain unreported.
Simons et al. (2011) conducted some simulation studies and found that even extreme use of multiple questionable research practices (p-hacking) will produce a significant result in at most 60% of cases, when the null-hypothesis is true. If such extreme use of questionable research practices were widespread, z-curve would produce corrected power estimates well-below 50%. There is no evidence that extreme use of questionable research practices is prevalent. In contrast, there is strong evidence that researchers conduct many more studies than they actually report and that many of these studies have a low probability of success.
Implications of File-Drawers for Science
First, it is clear that researchers could be more effective if they would use existing resources more effectively. An fMRI study with 20 participants costs about $10,000. Conducting a study that costs $10,000 that has only a 50% probability of producing a significant result is wasteful and should not be funded by taxpayers. Just publishing the non-significant result does not fix this problem because a non-significant result in a study with 50% power is inconclusive. Even if the predicted effect exists, one would expect a non-significant result in ever second study. Instead of wasting $10,000 on studies with 50% power, researchers should invest $20,000 in studies with higher power (unfortunately, power does not increase proportional to resources). With the same research budget, more money would contribute to results that are being published. Thus, without spending more money, science could progress faster.
Second, higher powered studies make non-significant results more relevant. If a study had 80% power, there is only a 20% chance to get a non-significant result if an effect is present. If a study had 95% power, the chance of a non-significant result would be just as low as the chance of a false positive result. In this case, it is noteworthy that a theoretical prediction was not confirmed. In a set of high-powered studies, a post-hoc power analysis would show a bimodal distribution with clusters of z-scores around 0 for true null-hypothesis and a cluster of z-scores of 3 or higher for clear effects. Type-I and Type-II errors would be rare.
Third, Example 3 shows that the use of questionable research practices becomes detectable in the absence of a file drawer and that it would be harder to publish results that were obtained with questionable research practices.
Finally, the ability to estimate the size of file-drawers may encourage researchers to plan studies more carefully and to invest more resources into studies to keep their file drawers small because a large file-drawer may harm reputation or decrease funding.
In conclusion, post-hoc power analysis of large sets of data can be used to estimate the size of the file drawer based on the distribution of z-scores on the right side of a significance criterion. As file-drawers harm science, this tool can be used as an incentive to conduct studies that produce credible results and thus reducing the need for dishonest research practices. In this regard, the use of post-hoc power analysis complements other efforts towards open science such as preregistration and data sharing.
“A text-mining program searched all articles for publications of F-tests, t-tests, correlation coefficients, regression coefficients, odds-ratios, confidence intervals, and z-tests.” Would you be willing to publish the code for this program? Or the logic and/or search terms you used to create it? Thank you!
sorry, at this moment I am not sharing the code. A similar software is available for free. I think it is called p-checker, but I couldn’t find a link.