Bartoš, F., & Schimmack, U. (2022). Z-curve 2.0: Estimating replication rates and discovery rates. Meta-Psychology, 6, Article e0000130. https://doi.org/10.15626/MP.2022.2981
Brunner, J., & Schimmack, U. (2020). Estimating population mean power under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
van Zwet, E., Gelman, A., Greenland, S., Imbens, G., Schwab, S., & Goodman, S. N. (2024). A New Look at P Values for Randomized Clinical Trials. NEJM evidence, 3(1), EVIDoa2300003. https://doi.org/10.1056/EVIDoa2300003
The Story of Two Z-Curve Models
Erik van Zwet recently posted a critique of the z-curve method on Andrew Gelman’s blog.
Meaningful discussion of the severity and scope of this critique was difficult in that forum, so I address the issue more carefully here.
van Zwet identified a situation in which z-curve can overestimate the Expected Discovery Rate (EDR) when it is inferred from the distribution of statistically significant z-values. Specifically, when the distribution of significant results is driven primarily by studies with high power, the observed distribution contains little information about the distribution of nonsignificant results. If those nonsignificant results are not reported and z-curve is nevertheless used to infer them from the significant results alone, the method can underestimate the number of missing nonsignificant studies and, as a consequence, overestimate the Expected Discovery Rate (EDR).
This is a genuine limitation, but it is a conditional and diagnosable one. Crucially, the problematic scenarios are directly observable in the data. Problematic data have an increasing or flat slope of the significant z-value distribution and a mode well above the significance threshold. In such cases, z-curve does not silently fail; it signals that inference about missing studies is weak and that EDR estimates should not be trusted.
This is rarely a problem in psychology, where most studies have low power, the mode is at the significance criterion, and the slope decreases, often steeply. This pattern implies a large set of non-significant results and z-curve provides good estimates in these scenarios. It is difficult to estimate distributions of unobserved data, leading to wide confidence intervals around these estimates. However, there is no fixed number of studies that are needed. The relevant question is whether the confidence intervals are informative enough to support meaningful conclusions.
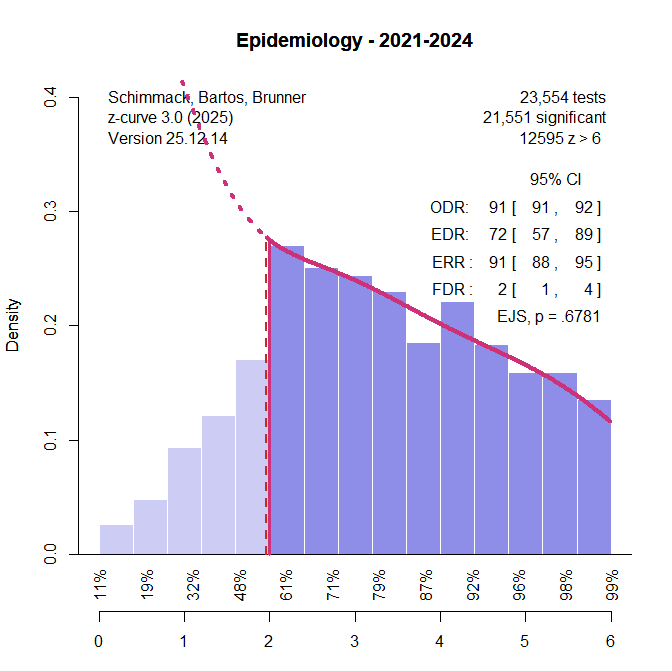
One of the most powerful set of studies that I have actually seen comes from epidemiology, where studies often have large samples to estimate effect sizes precisely. In these studies, power to reject the null hypothesis is actually not really important, but the data serve as a good example of a set of studies with high power, rather than low power as in psychology.
However, even this example shows a decreasing slope and a mode at significance criterion. Fitting z-curve to these data still suggests some selection bias and no underestimation of reported non-significant results. This illustrates how extreme van Zwet’s scenario must be to produce the increasing-slope pattern that undermines EDR estimation.
What about van Zwet’s Z-Curve Method?
It is also noteworthy that van Zwet does not compare our z-curve method (Bartos & Schimmack, 2022; Brunner & Bartos, 2020) to his own z-curve method that was used to analyze z-values from clinical trials (van Zwet et al., 2024).
The article fits a model to the distribution of absolute z-values (ignoring whether results show a benefit or harm to patients). The key differences between the two approaches are that (a) van Zwet et al.’s model uses all z-values and assumes (implicitly) that there is no selection bias, and (b) that true effect sizes are never zero and errors can only be sign errors. Based on these assumptions, the article concludes that no more than 2% of clinical trials produce a result that falsely rejects a true hypothesis. For example, a statistically significant result could be treated as an error only if the true effect has the opposite sign (e.g., the true effect increases smoking, but a significant result is used to claim it reduced smoking).
The advantage of this method is that it is not necessary to estimate the EDR from the distribution of only significant results, but it does so only by assuming that publication bias does not exist. In this case, we can just count the observed non-significant and significant results and use the observed discovery rate to estimate average power and the false positive risk.
The trade-off is clear. z-curve attempts to address selection bias and sometimes lacks sufficient information to do so reliably; van Zwet’s approach achieves stable estimates by assuming the problem away. The former risks imprecision when information is weak; the latter risks bias when its core assumption is violated.
In the example from epidemiology, there is evidence of some publication bias and omission of non-significant results. Using van Zwet’s model would be inappropriate because it would overestimate the true discovery rate. The focus on sign errors alone is also questionable and should be clearly stated as a strong assumption. It implies that significant results in the right direction are not errors, even if effect sizes are close to zero. For example, a significant result that suggests it extends life is considered a true finding, even if the effect size is one day.
False positive rates do not fully solve that problem, but false positive rates that include zero as a hypothetical value for the population effect size are higher and treat small effects close to zero as errors rather than treating half of them as correct rejections of the null hypothesis. For example, an intervention that decreases smoking by 1% of all smokers is not really different from one that increases it by 1%, but a focus on signs treats only the latter one as an error.
In short, van Zwet’s critique identifies a boundary condition for z-curve, not a general failure. At the same time, his own method rests on a stronger and untested assumption—no selection bias—whose violation would invalidate its conclusions entirely. No method is perfect and using a single scenario to imply that a method is always wrong is not a valid argument against any method. By the same logic, van Zwet’s own method could be declared “useless” whenever selection bias exists, which is precisely the point: all methods have scope conditions.
Using proper logic, we suggest that all methods work when assumptions are met. The main point is to test whether they are met or not. We clarified that z-curve estimation of the EDR assumes that enough low powered studies produced significant results to influence the distribution of significant results. If the slope of significant results is not decreasing, this assumption does not hold and z-curve should not be used to estimate the EDR. Similarly, users of van Zwets first method should first test whether selection bias is present and not use it when it does. They should also examine whether they think a proportion of studies could have tested practically true null hypotheses and not use the method when this is a concern.
Finally, the blog post responds to Gelman’s polemic about our z-curve method and earlier work by Jager and Leek (2014), by noting that Gelman’s critic of other methods exist in parallel to his own work (at least co-authorship) that also modeled distribution of z-values to make claims about power and the risk of false inferences. The assumption of this model that selection bias does not exist is peculiar, given Gelman’s typical writing about low power and the negative effects of selection for significance. A more constructive discussion would apply the same critical standards to all methods—including one’s own.
Wilson BM, Wixted JT. The Prior Odds of Testing a True Effect in Cognitive and Social Psychology. Advances in Methods and Practices in Psychological Science. 2018;1(2):186-197. doi:10.1177/2515245918767122
Abstract
Wilson and Wixted had a cool idea, but it turns out to be wrong. They proposed that sign errors in replication studies can be used to estimate false positive rates. Here I show that their approach makes a false assumption and does not work.
Introduction
Two influential articles shifted concerns about false positives in psychology from complacency to fear (Ioannidis, 2005; Simmons, Nelson, & Simonsohn, 2011). First, psychologists assumed that false rejections of the null hypothesis (no effect) are rare because the null hypothesis is rarely true. Effects were either positive or negative, but never really zero. In addition, meta-analyses typically found evidence for effects, even assuming biased reporting of studies (Rosenthal, 1979).
Simmons et al. (2011) demonstrated, however, that questionable, but widely used statistical practices can increase the risk of publishing significant results without real effects from the nominal 5% level (p < .05) to levels that may exceed 50% in some scenarios. When only 25% of significant results in social psychology could be replicated, it seemed possible that a large number of the replication failures were false positives (Open Science Collaboration, 2015).
Wilson and Wixted (2018) used the reproducibility results to estimate how often social psychologists test true null hypotheses. Their approach relied on the rate of sign reversals between original and replication estimates. If the null hypothesis is true, sampling error will produce an equal number of estimates in both directions. Thus, a high rate of sign reversals could be interpreted as evidence that many original findings reflect sampling error around a true null. Second, for every sign reversal there is typically a same-sign replication, and Wilson and Wixted treated the remaining same-sign results as reflecting tests of true hypotheses that reliably produce the correct sign.
Let P(SR) be the observed proportion of sign reversals between originals and replications (not conditional on significance). If true effects always reproduce the same sign and null effects produce sign reversals 50% of the time, then the observed SR provides an estimate of the proportion of true null hypotheses that were tested, P(True-H0).
P(True-H0) = 2*P(SR)
Wilson and Wixted further interpreted this quantity as informative about the fraction of statistically significant original results that might be false positives. Wilson and Wixted (2018) found approximately 25% sign reversals in replications of social psychological studies. Under their simplifying assumptions, this implies 50% true null hypotheses in the underlying set of hypotheses being tested, and they used this inference, together with assumptions about significance and power, to argue that false positives could be common in social psychology.
Like others, I thought this was a clever way to make use of sign reversals. The article has been cited only 31 times (WoS, January 6, 2026), and none of the articles critically examined Wilson and Wixted’s use of sign errors to estimate false positive rates.
However, other evidence suggested that false positives are rare (Schimmack, 2026). To resolve the conflict between Wilson and Wixted’s conclusions and other findings, I reexamined their logic and ChatGPT pointed out Wilson and Wixted’s (2018) formula rests on assumptions that need not hold.
The main reason is that it makes the false assumption that tests of true hypotheses do not produce sign errors. This is simply false because studies that test false null hypotheses with low power can still produce sign reversals (Gelman & Carlin, 2014). Moreover, sign reversals can be generated even when the false-positive rate is essentially zero, if original studies are selected for statistical significance and the underlying studies have low power. In fact, it is possible to predict the percentage of sign reversals from the non-centrality of the test statistic under the assumption that all studies have the same power. To obtain 25% sign reversals, all studies could test a false null hypothesis with about 10% power. In that scenario, many replications would reverse sign because estimates are highly noisy, while the original literature could still contain few or no literal false positives if the true effects are nonzero.
Empirical Examination with Many Labs 5
I used the results from ManyLabs5 (Ebersole et al., 2020) to evaluate what different methods imply about the false discovery risk of social psychological studies in the Reproducibility Project, first applying Wilson and Wixted’s sign-reversal approach and then using z-curve (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020).
ManyLabs5 conducted additional replications of 10 social psychological studies that failed to replicate in the Reproducibility Project (Open Science Collaboration, 2015). The replication effort included both the original Reproducibility Project protocols and revised protocols developed in collaboration with the original authors. There were 7 sign reversals in total across the 30 replication estimates. Using Wilson and Wixted’s sign-reversal framework, 7 out of 30 sign reversals (23%) would be interpreted as evidence that approximately 46% of the underlying population effects in this set are modeled as exactly zero (i.e., that H0 is true for about 46% of the effects).
To compare these results more directly to Wilson and Wixted’s analysis, it is necessary to condition on non-significant replication outcomes, because ManyLabs5 selected studies based on replication failure rather than original significance alone. Among the non-significant replication results, 25 sign reversals occurred out of 75 estimates, corresponding to a rate of 33%, which would imply a false-positive rate of approximately 66% under Wilson and Wixted’s framework. Although this estimate is somewhat higher, both analyses would be interpreted as implying a large fraction of false positives—on the order of one-half—among the original significant findings within that framework.
To conduct a z-curve analysis, I transformed the effect sizes (r) in ManyLabs5 (Table 3) into d-values and used the reported confidence intervals to compute standard errors, SE = (d upper − d lower)/3.92, and corresponding z-values, z = d/SE. I fitted a z-curve model that allows for selection on statistical significance (Bartos & Schimmack, 2022; Brunner & Schimmack, 2020) to the 10 significant original results. I fitted a second z-curve model to the 30 replication results, treating this set as unselected (i.e., without modeling selection on significance).
The z-curve for the 10 original results shows evidence consistent with strong selection on statistical significance, despite the small set of studies. Although all original results are statistically significant, the estimated expected discovery rate is only 8%, and the upper limit of the 95% confidence interval is 61%, well below 100%. Visual inspection of the z-curve plot also shows a concentration of results just above the significance threshold (z = 1.96) and none just below it, even though sampling variation does not create a discontinuity between results with p = .04 and p = .06.
The expected replication rate (ERR) is a model-based estimate of the average probability that an exact replication would yield a statistically significant result in the same direction. For the 10 original studies, ERR is 32%, but the confidence interval is wide (3% to 70%). The lower bound near 3% is close to the directional false-alarm rate under a two-sided test when the true effect is zero (α/2 = 2.5%), meaning that the data are compatible with the extreme-null scenario in which all underlying effects are zero and the original significant results reflect selection. This does not constitute an estimate of the false-positive rate; rather, it indicates that the data are too limited to rule out that worst-case possibility. At the same time, the same results are also compatible with an alternative scenario in which all underlying effects are non-zero but power is low across studies.
For the 30 replication results, the z-curve model provides a reasonable fit to the observed distribution, which supports the use of a model that does not assume selection on statistical significance. In this context, the key quantity is the expected discovery rate (EDR), which can be interpreted as a model-based estimate of the average true power of the 30 replication studies. The estimated EDR is 17%. This value is lower than the corresponding estimate based on the original studies, despite increases in sample sizes and statistical power in the replication attempts. This pattern illustrates that ERR estimates derived from biased original studies tend to be overly optimistic predictors of actual replication outcomes (Bartos & Schimmack, 2022). In contrast, the average power of the replication studies can be estimated more directly because the model does not need to correct for selection bias.
A key implication is that the observed rate of sign reversals (23%) could have been generated by a set of studies in which all null hypotheses are false but average power is low (around 17%). However, the z-curve analysis also shows that even a sample of 30 studies is insufficient to draw precise conclusions about false positive rates in social psychology. Following Sorić (1989), the EDR can be used to derive an upper bound on the false discovery rate (FDR), that is, the maximum proportion of false positives consistent with the observed discovery rate. Based on this approach, the FDR ranges from 11% to 100%. To rule out high false positive risks, studies would need higher power, narrower confidence intervals, or more stringent significance thresholds.
Conclusion
This blog post compared Wilson and Wixted’s use of sign reversals to estimate false discovery rates with z-curve estimates of false discovery risk. I showed that Wilson and Wixted’s approach rests on implausible assumptions. Most importantly, it assumes that sign reversals occur only when the true effect is exactly zero. It does not allow for sign reversals under nonzero effects, which can occur when all null hypotheses are false but tests of these hypotheses have low power.
The z-curve analysis of 30 replication estimates in the ML5 project shows that low average power is a plausible explanation for sign reversals even without invoking a high false-positive rate. Even with the larger samples used in ML5, the data are not precise enough to draw firm conclusions about false positives in social psychology. A key problem remains the fundamental asymmetry of NHST: it makes it possible to reject null hypotheses, but it does not allow researchers to demonstrate that an effect is (practically) zero without very high precision.
The solution is to define the null hypothesis as a region of effect sizes that are so small that they are practically meaningless. The actual level may vary across domains, but a reasonable default is Cohen’s criterion for a small effect size, r = .1 or d = .2. By this criterion, only two of the replication studies in ML5 had sample sizes that were large enough to produce results that ruled out effect sizes of at least r = .1 with adequate precision. Other replications still lacked precision to do so. Interestingly, five of the ten original statistically significant results also failed to rule out effect sizes of at least r = .1, because their confidence intervals included r = .10. Thus, these studies at best provided suggestive evidence about the sign of an effect, but no evidence that the effect size is practically meaningful.
The broader lesson is that any serious discussion of false positives in social psychology requires (a) a specification of what counts as an “absence of an effect” in practice, using minimum effect sizes of interest that can be empirically tested, (b) large sample sizes that allow precise estimation of effect sizes, and (c) unbiased reporting of results. A few registered replication reports come close to this ideal, but even these results have failed to resolve controversies because effect sizes close to zero in the predicted direction remain ambiguous without a clearly specified threshold for practical importance. To avoid endless controversies and futile replication studies, it is necessary to specify minimum effect sizes of interest before data are collected.
In practice, this means designing studies so that the confidence interval can exclude effects larger than the minimum effect size of interest, rather than merely achieving p < .05 against a point null of zero. Conceptually, this is closely related to specifying the null hypothesis as a minimum effect size and using a directional test, rather than using a two-sided test against a nil null of exactly zero. Put differently, the problem is not null hypothesis testing per se, but nil hypothesis testing (Cohen, 1994).
Citation: Soto, M. & Schimmack, U. (2024, July 4/08/13). 2024 Replicability Report for the Journal of Experimental Social Psychology. Replicability Index.
https://replicationindex.com/2024/07/04/rr24-jesp/
Introduction
In the 2010s, it became apparent that empirical psychology had a replication problem. When psychologists tested the replicability of 100 results, they found that only 36% of the 97 significant results in original studies could be reproduced (Open Science Collaboration, 2015). In addition, several prominent cases of research fraud further undermined trust in published results. Over the past decade, several proposals were made to improve the credibility of psychology as a science. Replicability Reports aim to improve the credibility of psychological science by examining the amount of publication bias and the strength of evidence for empirical claims in psychology journals.
The main problem in psychological science is the selective publishing of statistically significant results and the blind trust in statistically significant results as evidence for researchers’ theoretical claims. Unfortunately, psychologists have been unable to self-regulate their behaviour and continue to use unscientific practices to hide evidence that disconfirms their predictions. Moreover, ethical researchers who do not use unscientific practices are at a disadvantage in a game that rewards publishing many articles without concern about these findings’ replicability. Replicability reports aim to reward journals that publish credible results and use open science practices that encourage honest reporting of results like preregistration or registered reports.
My colleagues and I have developed a statistical tools that can reveal the use of unscientific practices and predict the outcome of replication studies (Brunner & Schimmack, 2021; Bartos & Schimmack, 2022). This method is called z-curve. Z-curve cannot be used to evaluate the credibility of a single study. However, it can provide valuable information about the research practices in a particular research domain. Replicability-Reports (RR) analyze the statistical results reported in a journal with z-curve to estimate the replicability of published results, the amount of publication bias, and the risk that significant results are false positive results (i.e, the sign of a mean difference or correlation of a significant result does not match the sign in the population).
Journal of Experimental Social Psychology
The Journal of Experimental Social Psychology (JESP) was established in 1965. It is the oldest journal that specializes on experimental studies of social cognitions and behaviors. A replicability analysis of this journal is particularly interesting for several reasons. First, the long history of the journal makes it possible to examine historic trends in research practices in this field over a long time period. Second, experimental social psychology has triggered the crisis of confidence in psychological science with studies on extrasensory perception (Bem, 2011), implicit priming (Bargh et al., 1996), and ego depletion (Baumeister et al., 1996) that failed to replicate. At the same time, social psychology has responded to these replication failures by increasing sample sizes and rewarding open science practices like preregistration of analyses plans that limit researchers’ degrees of freedom to fish for significance or change hypotheses after examining the data.
On average, JESP publishes about 150 articles in 6 annual issues. According to Web of Science, the impact factor of JESP ranks 15th in the Psychology, Social category (Clarivate, 2024). The journal has an H-Index of 196 (i.e., 196 articles have received 196 or more citations).
In its lifetime, Journal of Experimental Social Psychology (JESP) has published over 4,200 articles with an average citation rate of 56.01 citations. So far, the journal has published 10 articles with more than 1,000 citations. Most of these have been published before the 2000s. The three most cited articles in the 2000s focus on improving methods used in social psychology research (Oppenheimer et al., 2009; Leys et al., 2013; Peer et al., 2017).
The Open Science Collaboration observed how only 14 out of 55 (25%) social psychology effects were replicated. A similar replicability estimate of 16% to 44% was measured for social psychology by Bartoš & Schimmack (2022). In response, many journals have implemented multiple strategies to improve the replicability and credibility of their published findings. Similarly, JESP introduced the “JESP’s 10-Item Submission Checklist” in 2022. The list entails a series of requirements that authors must fulfill to have their manuscripts reviewed. This checklist requires that authors provide their priori power analysis, sample size determination, and full reporting of all statistics including non-significant ones, among other items that aim to improve the quality of the submitted manuscripts. JESP’s focus on social psychology allows this report to highlight whether the proposed strategies to reform social psychology research meet their expectations.
The current Editor-in-Chief is Professor Nicholas Rule. Professor Kristin Laurin serves as the Senior Associate Editor. The associate editors are Professor Rachel Barkan, Professor Pamela K Smith, Professor Fiona Barlow, Professor Paul Conway, Professor Jarret Crawford, Professor Sarah Gaither, Professor Shlomo Hareli, Professor Edward Hirt, Professor Rachael Jack, Professor Joris Lammers, Professor Pranjal H. Mehta, Professor Kristin Pauker, Professor Brett Peters, Professor Evava Pietr, and Professor Karina Schumann.
Extraction Method
Replication reports are based on automatically extracted test statistics such as F-tests, t-tests, z-tests, and chi2-tests. Additionally, we extracted 95% confidence intervals of odds ratios and regression coefficients. The test statistics were extracted from collected PDF files using a custom R-code. The code relies on the pdftools R package (Ooms, 2024) to render all textboxes from a PDF file into character strings. Once converted the code proceeds to systematically extract the test statistics of interest (Soto & Schimmack, 2024). PDF files identified as editorials, review papers and meta-analyses were excluded. Meta-analyses were excluded to avoid the inclusion of test statistics that were not originally published in the Journal of Experimental Social Psychology. Following extraction, the test statistics are converted into absolute z-scores.
Results For All Years
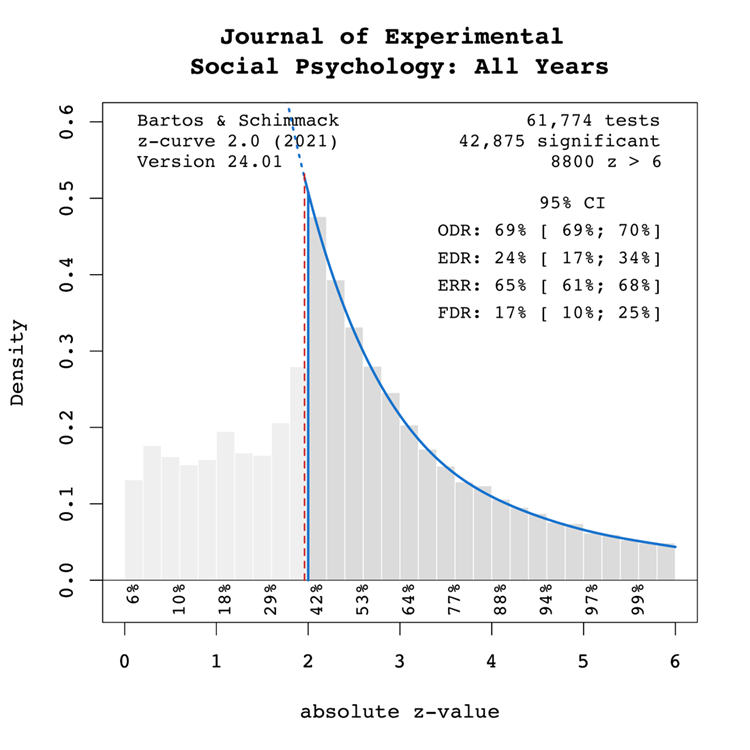
Figure 1 shows a z-curve plot for all articles from 2000-2023 (see Schimmack, 2023, for a detailed description of z-curve plots). The plot is essentially a histogram of all test statistics converted into absolute z-scores (i.e., the direction of an effect is ignored). Z-scores can be interpreted as the strength of evidence against the null hypothesis that there is no statistical relationship between two variables (i.e., the effect size is zero and the expected z-score is zero). A z-curve plot shows the standard criterion of statistical significance (alpha = .05, z = 1.96) as a vertical red dotted line.
Figure 1
Z-curve plots are limited to values less than z = 6. The reason is that values greater than 6 are so extreme that a successful replication is all but certain unless the value is a computational error or based on fraudulent data. The extreme values are still used for the computation of z-curve statistics but omitted from the plot to highlight the shape of the distribution for diagnostic z-scores in the range from 2 to 6. Using the expectation maximization (EM) algorithm, Z-curve estimates the optimal weights for seven components located at z-values of 0, 1, …. 6 to fit the observed statistically significant z-scores. The predicted distribution is shown as a blue curve. Importantly, the model is fitted to the significant z-scores, but the model predicts the distribution of non-significant results. This makes it possible to examine publication bias (i.e., selective publishing of significant results). Using the estimated distribution of non-significant and significant results, z-curve provides an estimate of the expected discovery rate (EDR); that is, the percentage of significant results that were actually obtained without selection for significance. Using Soric’s (1989) formula the EDR is used to estimate the false discovery risk; that is, the maximum number of significant results that are false positives (i.e., the null-hypothesis is true).
Selection for Significance
The extent of selection bias in a journal can be quantified by comparing the Observed Discovery Rate (ODR) of 69%, 95%CI = 69% to 70% with the Expected Discovery Rate (EDR) of 24%, 95%CI = 17%-34%. The ODR is notably higher than the upper confidence interval limit for the EDR, indicating statistically significant publication bias. Furthermore, there is clear evidence of selection for significance given that the ODR estimate is more than double the point estimate of the EDR.
It is also noteworthy that the present results probably underestimate severity of selection bias for focal hypothesis test. The present results do no distinguish between theoretically important and complementary analyses. It is known that focal hypothesis tests in psychology before the replication crisis have an observed success rate over 90% (Sterling, 1959; Sterling et al., 1995; Motyl et al., 2017). While it is possible that focal tests also have higher power, it is likely that the differences in the ODR larger than the differences in the EDR.
In conclusion, the present results are consistent with the finding that replication studies are more likely to produce non-significant results than reported original findings because selection for significance inflates the percentage of significant results in published articles (OSC, 2015).
Expected Replication Rate
The Expected Replication Rate (ERR) estimates the percentage of studies that would produce a significant result again if exact replications with the same sample size were conducted. A comparison of the ERR with the outcome of actual replication studies shows that the ERR is higher than the actual replication rate (Schimmack, 2020). Several factors can explain this discrepancy, including the difficulty of conducting exact replication studies. Thus, the ERR is an optimist estimate. A conservative estimate is the EDR. The EDR predicts replication outcomes if significance testing does not favour studies with higher power (larger effects and smaller sampling error) because statistical tricks make it just as likely that studies with low power are published. We suggest using the EDR and ERR in combination to estimate the actual replication rate.
The Expected Replication Rate (ERR) estimates the percentage of studies that would produce a significant result again if exact replications with the same sample size were conducted. A comparison of the ERR with the outcome of actual replication studies shows that the ERR is higher than the actual replication rate (Schimmack, 2020). Several factors can explain this discrepancy, such as the difficulty of conducting exact replication studies. Thus, the ERR is an optimist estimate. A conservative estimate is the EDR. The EDR predicts replication outcomes if significance testing does not favour studies with higher power (larger effects and smaller sampling error) because statistical tricks make it just as likely that studies with low power are published. We suggest using the EDR and ERR in combination to estimate the actual replication rate.
The ERR estimate of 65%, 95%CI = 61% to 68%, suggests that most results should produce a statistically significant, p < .05, result again in exact replication studies. However, the EDR of 24% implies considerable uncertainty about the actual replication rate for studies in this journal and that the success rate can be between 24% and 65%. These estimates can be compared with the actual success rate of replications of social psychological experiments in the Reproducibility Project of 25% (OSC, 2015). While this estimate is based on a small, unrepresentative sample, it does confirm that the replication rate of social psychological experiments can be as low as 1 out of 4 studies. This justifies concerns about the credibility of results published in JESP (see also Schimmack, 2020).
False Positive Risk
The replication crisis has led to concerns that many or even most published results are false positives (i.e., the true effect size is zero or in the opposite direction). The high rate of replication failures, however, may simply reflect low power to produce significant results for true positives and does not tell us how many published results are false positives. We can provide some information about the false positive risk based on the EDR. Using Soric’s formula (1989), the EDR can be used to calculate the maximum false discovery rate.
The EDR of 24% implies a False Discovery Risk (FDR) of 17%, 95%CI = 10% to 25%, but the 95%CI of the FDR allows for up to 25% false positive results. This estimate contradicts claims that most published results are false (Ioannidis, 2005), but the results also create uncertainty about the credibility of results with statistically significant results, if up to 1 out of 4 results can be false positives. For readers it may be difficult to decide whether a published results can be trusted.
Time Trends
One advantage of automatically extracted test-statistics is that the large number of test statistics makes it possible to examine changes in publication practices over time. We were particularly interested in changes in response to awareness about the replication crisis in recent years.
Z-curve plots for every publication year were calculated to examine time trends through regression analysis. Additionally, the degrees of freedom used in F-tests and t-tests were used as a metric of sample size to observe if these changed over time. Both linear and quadratic trends were considered. The quadratic term was included to observe if any changes occurred in response to the replication crisis. That is, there may have been no changes from 2000 to 2015, but increases in EDR and ERR after 2015.
Degrees of Freedom
Figure 2 shows the median and mean degrees of freedom used in F-tests and t-tests reported in the Journal of Experimental Social Psychology. The mean results are highly variable due to a few studies with extremely large sample sizes. Thus, we focus on the median to examine time trends. The median degree of freedom over time was 82.25, ranging from 60 to 302. Regression analyses of the median showed a significant linear increase by about 9 degrees of freedom per year, b = 9.13, SE = 0.62, p < 0.0001. Furthermore, there was a statistically significant non-linear increase, b = 0.94, SE = 0.10, p < 0.0001, suggesting that the replication crisis led to an increase in sample sizes. As larger samples increase power, we would expect an increase in the ERR and EDR.
Figure 2
Observed and Expected Discovery Rates
Figure 3 shows the changes in the ODR and EDR estimates over time. There was a significant linear decrease to the ODR estimate by 0.44 percentage points per year, b = -0.44, SE = 0.08, p < 0.0001. No significant non-linear, b = 0.01 (SE = 0.01, p = 0.27) trend was observed in the ODR estimate. These results show that researchers have published more non-significant results over time, leading to a decrease in selection bias.
The regression results for the EDR estimate showed significant linear, b = 1.14 (SE = 0.25 p < 0.001) and non-linear, b = 0.17 (SE = 0.04 p < 0.001) changes over time. The non-linear trend is consistent with the results for the degrees of freedom and confirms that power has increased after the replication crisis due to the use of larger samples. This also reduces selection bias. The trends for the ODR and EDR have narrowed the gap between the ODR and the EDR as seen in Figure 3. However, it remains to be seen whether this trend also applies to focal hypothesis tests.
Figure 3
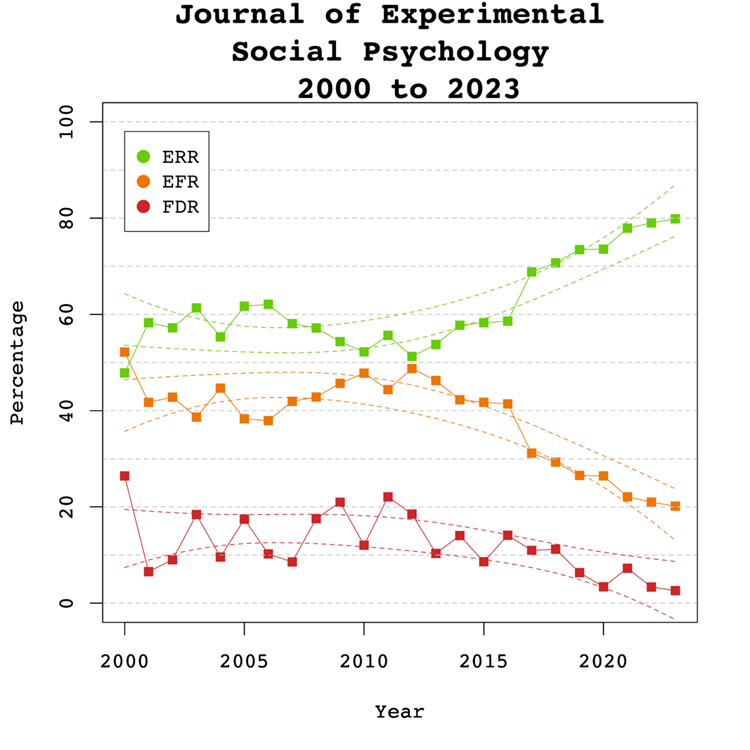
Expected Replicability Rates and False Discovery Risks
Figure 4 depicts the false discovery risk (FDR) and the Estimated Replication Rate (ERR). It also shows the Expected Replication Failure rate (EFR = 1 – ERR). A comparison of the EFR with the FDR provides information for the interpretation of replication failures. If the FDR is close to the EFR, many replication failures may be due to false positive results in original studies. In contrast, if the FDR is low, most replication failures will likely be false negative results in underpowered replication studies.
There were no significant linear, b = 0.13, SE = 0.10, p = 0.204 or non-linear, b = 0.01, SE = 0.16, p = 0.392 trends observed in the ERR estimate. These findings are inconsistent with the observed significant increase in sample sizes as the reduction in sampling error often increases the likelihood that an effect will replicate. One possible explanation for this is that the type of studies has changed. If a journal publishes more studies from disciplines with large samples and small effect sizes, sample sizes go up without increasing power. Thus, analysis of sample size alone provide insufficient information about the credibility of published results.
Visual inspection of Figure 4 depicts the EFR consistently around 30% and the FDR around 10%, suggesting that about one-third of replication failures are false positive results in original studies. The larger decrease for the EFR than the FDR suggests that larger samples have mainly reduced false negative results and increasing the probability that a replication failure reveals a false positive result in the original study.
Figure 4
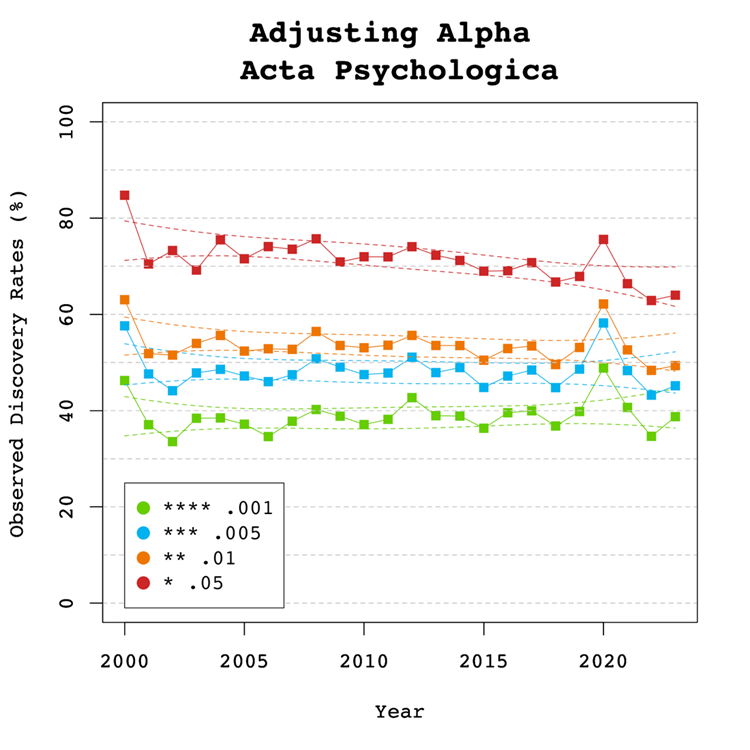
Adjusting Alpha
A simple solution to a crisis of confidence in published results is to adjust the criterion to reject the null-hypothesis. For example, some researchers have proposed to set alpha to .005 to avoid too many false positive results. With z-curve we can calibrate alpha to keep the false discovery risk at an acceptable level without discarding too many true positive results. To do so, we set alpha to .05, .01, .005, and .001 and examined the false discovery risk.
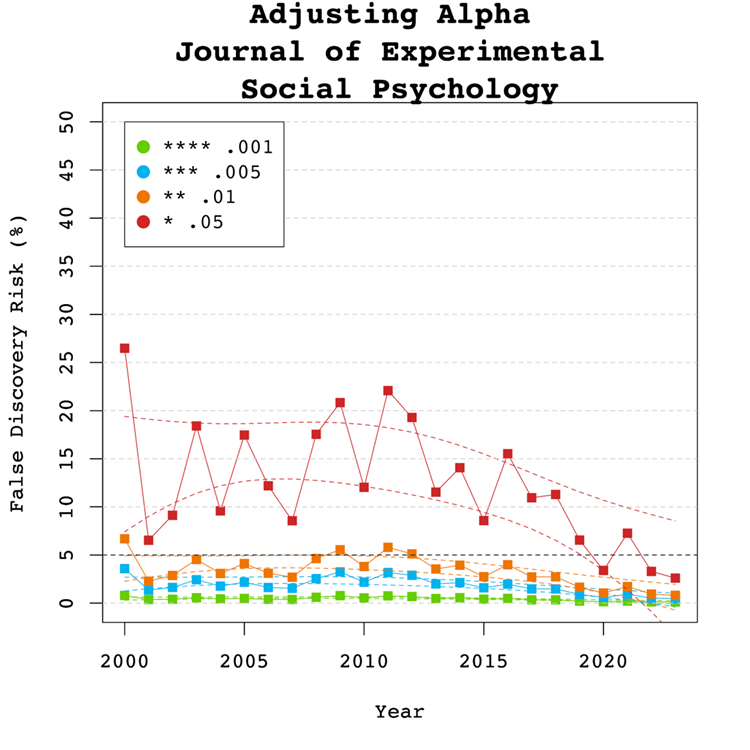
Figure 5
Figure 5 shows that the conventional criterion of p < .05 produces false discovery risks above 5%. The high variability in annual estimates also makes it difficult to provide precise estimates of the FDR. However, adjusting alpha to .01 is sufficient to produce an FDR with tight confidence intervals below 5%. More conservative readers might adjust to p < 0.005 for results published between 2007 and 2013. Overall, the benefits of reducing alpha further to .005 or .001 are minimal.
Figure 6
Figure 6 shows the impact of lowering the significance criterion, alpha, on the discovery rate (lower alpha implies fewer significant results). In the Journal of Experimental Social Psychology lowering alpha to .01 reduces the observed discovery rate considerably in the years before the replication crisis from about 70-80% to just 40-50% of reported results. The reason is that statistical tricks are more likely to produce just significant results between .05 and .01 than lower p-values (Simmons et al., 2011). Therese results are also much less likely to replicate (OSC, 2015). Thus, it is reasonable to treat these results as not significant and to require a credible replication study. In recent years, more p-values are below .01 and using alpha = .01 as significance criterion has relatively little impact on the discovery rate. Lowering alpha further has relatively little effect on the discovery rate. While these results should not be interpreted as a call for official changes to the alpha criterion, they help readers to evaluate the costs and benefits of using a specific alpha level. We believe that alpha = .01 provides an optimal trade-off for results published in JESP.
Limitations
One concern about the publication of our results is that it merely creates a new criterion to game publications. Rather than trying to get p-values below .05, researchers may use tricks to get p-values below .01. However, this argument ignores that it becomes increasingly harder to produce lower p-values with tricks (Simmons et al., 2011). Moreover, z-curve analysis makes it easy to see selection bias for different levels of significance. Thus, a more plausible response to these results is that researchers will increase sample sizes or use other methods to reduce sampling error to increase power. Our trend analyses show that this has already happened and that results published after 2015 are more credible.
A bigger concern is that our results underestimate the severity of the problem because they do not distinguish between theoretically important (focal) and additional (non-focal) hypothesis tests. To address this concern it is necessary to identify focal hypothesis tests and to hand-code results of these tests. For JESP, we were able to use hand-coded data from Motyl et al.’s (2017) article that randomly selected focal hypothesis tests from several journals, including JESP. The data are based on the years 2003, 2004, 2013, and 2014 and are representative for the years before reforms increased replicability (see Figures 3 & 4).
Figure 7
The ODR is similar to the ODR for all test statistics (70% vs. 69%, but non-significant results are clustered just below the significance level of .05 and are often used to reject the null-hypothesis with “marginal significance” (p < .10, z > 1.65). If these results are counted as ‘significant’, the ODR is 87%, which is close to Sterling et al.’s (1995) findings that over 90% of hypothesis tests in psychology reject the null-hypothesis. In contrast, the estimate of the expected discovery rate is only 14%, which is lower than the estimate for all hypothesis tests (Figure 1, 24%). Although the small number of studies leads to wide confidence intervals, the results suggest that focal tests have even lower power than other tests. The confidence interval for the EDR even includes 5%, which would imply that power equals alpha, which is the case when the population effect sizes are zero. This also implies that the confidence interval for the FDR includes 100%, suggesting that all focal hypothesis are false. Of course, it is unlikely that social psychologists only reported false results for decades, but the evidence is so weak that it is impossible to know which of these results are true and which ones are false. In this case, adjusting alpha does not help because the upper limit of the FDR confidence interval remains at 100% because the lower bound of the confidence interval for the EDR remains at 5%. Until more evidence for focal tests is obtained, it may be justified to use the results for all tests, but the false discovery risk for focal tests with p-values below .01 may be higher than 5%. Given so much uncertainty about results published in JESP before 2015, single studies should not be interpreted and important studies should be replicated with larger samples and preregistration.
Conclusion
The replicability report for the Journal of Experimental Social Psychology suggests that the power to obtain a significant result to report a significant result (i.e., a discovery) ranges from 24% to 65%, and may be even lower for focal hypothesis tests. This finding suggests that many studies are underpowered and require luck to get a significant result. The false positive risk is considerable but can be controlled by setting alpha to .01 during most years. However, an analysis of a small set of focal tests suggests that this criterion is too liberal for focal tests, but it is impossible to quantify the false discovery risk for focal tests.
Our results show clear evidence of improvement in response to the replication crisis. Power has increased with the help of larger samples and selection bias has decreased. This is a welcome development. It also means that our recommendation to use alpha of .01 penalizes only a smaller set of studies with p-values between .05 and .01. Of course, these results can occur by chance and can be false negatives, but in this case researchers should conduct additional studies to strengthen evidence for their hypothesis.
Hand-coding of focal tests after 2015 would provide important information about the credibility of focal tests in recent years. One important question is whether the journal publishes studies with non-significant results in large samples that suggest a hypothesis was false. These results would best be reported with 95%CI that limit plausible effect sizes to values close to zero. After all, risky hypotheses are bound to be false sometimes.
In conclusion, our results provide some valuable empirical evidence about the credibility of results published in JESP. The main finding is that results before the replication crisis had low credibility and were often obtained by selectively reporting confirmatory evidence. This has changed and results in recent years have much less selection bias and are more credible.
In the 2010s, it became apparent that empirical psychology had a replication problem. When psychologists tested the replicability of 100 results, they found that only 36% of the 97 significant results in original studies could be reproduced (Open Science Collaboration, 2015). In addition, several prominent cases of research fraud further undermined trust in published results. Over the past decade, several proposals were made to improve the credibility of psychology as a science. Replicability Reports aim to improve the credibility of psychological science by examining the amount of publication bias and the strength of evidence for empirical claims in psychology journals.
The main problem in psychological science is the selective publishing of statistically significant results and the blind trust in statistically significant results as evidence for researchers’ theoretical claims. Unfortunately, psychologists have been unable to self-regulate their behavior and continue to use unscientific practices to hide evidence that disconfirms their predictions. Moreover, ethical researchers who do not use unscientific practices are at a disadvantage in a game that rewards publishing many articles without any concern about the replicability of these findings.
My colleagues and I have developed a statistical tools that can reveal the use of unscientific practices and predict the outcome of replication studies (Brunner & Schimmack, 2021; Bartos & Schimmack, 2022). This method is called z-curve. Z-curve cannot be used to evaluate the credibility of a single study. However, it can provide valuable information about the research practices in a particular research domain. Replicability-Reports (RR) analyze the statistical results reported in a journal with z-curve to estimate the replicability of published results, the amount of publication bias, and the risk that significant results are false positive results (i.e, the sign of a mean difference or correlation of a significant result does not match the sign in the population).
Acta Psychologica
Acta Psychologica is an old psychological journal that was founded in 1936. The journal publishes articles from various areas of psychology, but cognitive psychological research seems to be the most common area. Since 2021, the journal is a Gold Open Access journal that charges authors a $2,000 publication fee.
On average, Acta Psychologica publishes about 150 articles a year in 9 annual issues.
According to Web of Science, the impact factor of Acta Psychologica ranks 44th in the Experimental Psychology category (Clarivate, 2024). The journal has an H-Index of 140 (i.e., 140 articles have received 140 or more citations).
In its lifetime, Acta Psychologica has published over 6,000 articles with an average citation rate of 21.5 citations. So far, the journal has published 5 articles with more than 1,000 citations. However, most of these articles were published in the 1960s and 1970s. The most highly cited article published in the 2000s examined the influence of response categories on the psychometric properties of survey items (Preston & Colman, 2000; 1055 citations).
Psychology literature has faced difficult realizations in the last decade. Acta Psychologica is a broad-scope journal that offers us the possibility to observe changes in the robustness of psychological research practices and results. The current report serves as a glimpse into overall trends in psychology literature as it considers research from multiple subfields.
Given the multidisciplinary nature of the journal, the journal has a team of editors. The current editors are Dr. Muhammad Abbas, Dr. Mohamed Alansari, Dr. Colin Cooper, Dr. Valerie De Cristofaro, Dr. Nerelie Freeman, Professor, Alessandro Gabbiadini, Professor Matthieu Guitton, Dr. Nhung T Hendy, Dr. Amanpreet Kaur, Dr. Shengjie Lin, Dr. Hui Jing Lu, Professor Robrecht Van Der Wel and Dr. Olvier Weigelt.
Extraction Method
Replication reports are based on automatically extracted test statistics such as F-tests, t-tests, z-tests, and chi2-tests. Additionally, we extracted 95% confidence intervals of odds ratios and regression coefficients. The test statistics were extracted from collected PDF files using a custom R-code. The code relies on the pdftools R package (Ooms, 2024) to render all textboxes from a PDF file into character strings. Once converted the code proceeds to systematically extract the test statistics of interest (Soto & Schimmack, 2024). PDF files identified as editorials, review papers and meta-analyses were excluded. Meta-analyses were excluded to avoid the inclusion of test statistics that were not originally published in Acta Psychologica Following extraction, the test statistics are converted into absolute z-scores.
Results For All Years
Figure 1 shows a z-curve plot for all articles from 2000-2023 (see Schimmack, 2022a, 2022b, for a detailed description of z-curve plots). The plot is essentially a histogram of all test statistics converted into absolute z-scores (i.e., the direction of an effect is ignored). Z-scores can be interpreted as the strength of evidence against the null hypothesis that there is no statistical relationship between two variables (i.e., the effect size is zero and the expected z-score is zero). A z-curve plot shows the standard criterion of statistical significance (alpha = .05, z = 1.96) as a vertical red dotted line.
Figure 1
Z-curve plots are limited to values less than z = 6. The reason is that values greater than 6 are so extreme that a successful replication is all but certain unless the value is a computational error or based on fraudulent data. The extreme values are still used for the computation of z-curve statistics but omitted from the plot to highlight the shape of the distribution for diagnostic z-scores in the range from 2 to 6. Using the expectation maximization (EM) algorithm, Z-curve estimates the optimal weights for seven components located at z-values of 0, 1, …. 6 to fit the observed statistically significant z-scores. The predicted distribution is shown as a blue curve. Importantly, the model is fitted to the significant z-scores, but the model predicts the distribution of non-significant results. This makes it possible to examine publication bias (i.e., selective publishing of significant results). Using the estimated distribution of non-significant and significant results, z-curve provides an estimate of the expected discovery rate (EDR); that is, the percentage of significant results that were actually obtained without selection for significance. Using Soric’s (1989) formula the EDR is used to estimate the false discovery risk; that is, the maximum number of significant results that are false positives (i.e., the null-hypothesis is true).
Selection for Significance
The extent of selection bias in a journal can be quantified by comparing the Observed Discovery Rate (ODR) of 70%, 95%CI = 70% to 71% with the Expected Discovery Rate (EDR) of 38%, 95%CI = 27%-54%. The ODR is notably higher than the upper limit of the confidence interval for the EDR, indicating statistically significant publication bias. It is noteworthy that the present results may underestimate the severity of the problem because the analysis is based on all statistical results. Selection bias is even more problematic for focal hypothesis tests and the ODR for focal tests in psychology journals is often higher than the ODR for all tests. Thus, the current results are a conservative estimate of bias for critical hypothesis tests.
Expected Replication Rate
The Expected Replication Rate (ERR) estimates the percentage of studies that would produce a significant result again if exact replications with the same sample size were conducted. A comparison of the ERR with the outcome of actual replication studies shows that the ERR is higher than the actual replication rate (Schimmack, 2020). Several factors can explain this discrepancy, including the difficulty of conducting exact replication studies. Thus, the ERR is an optimist estimate. A conservative estimate is the EDR. The EDR predicts replication outcomes if significance testing does not favour studies with higher power (larger effects and smaller sampling error) because statistical tricks make it just as likely that studies with low power are published. We suggest using the EDR and ERR in combination to estimate the actual replication rate.
The ERR estimate of 73%, 95%CI = 69% to 77%, suggests that the majority of results should produce a statistically significant, p < .05, result again in exact replication studies. However, the EDR of 38% implies that there is considerable uncertainty about the actual replication rate for studies in this journal and that the success rate can be anywhere between 27% and 77%.
False Positive Risk
The replication crisis has led to concerns that many or even most published results are false positives (i.e., the true effect size is zero or in the opposite direction). The high rate of replication failures, however, may simply reflect low power to produce significant results for true positives and does not tell us how many published results are false positives. We can provide some information about the false positive risk based on the EDR. Using Soric’s formula (1989), the EDR can be used to calculate the maximum false discovery rate.
The EDR of 38% for Acta Psychologica implies a False Discovery Risk (FDR) of 9%, 95%CI = 5% to 15%, but the 95%CI of the FDR allows for up to 15% false positive results. This estimate contradicts claims that most published results are false (Ioannidis, 2005), but is probably a bit higher than many readers of this journal would like.
Time Trends
One advantage of automatically extracted test-statistics is that the large number of test statistics makes it possible to examine changes in publication practices over time. We were particularly interested in changes in response to awareness about the replication crisis in recent years.
Z-curve plots for every publication year were calculated to examine time trends through regression analysis. Additionally, the degrees of freedom used in F-tests and t-tests were used as a metric of sample size to observe if these changed over time. Both linear and quadratic trends were considered. The quadratic term was included to observe if any changes occurred in response to the replication crisis. That is, there may have been no changes from 2000 to 2015 but increases in EDR and ERR after 2015.
Degrees of Freedom
Figure 2 shows the median and mean degrees of freedom used in F-tests and t-tests reported in Acta Psychologica. The mean results are highly variable due to a few studies with extremely large sample sizes. Thus, we focus on the median to examine time trends. The median degrees of freedom over time was 38, ranging from 22 to 74. Regression analyses of the median showed a significant linear increase of a 1.4 degrees of freedom per year, b = 1.39, SE = 3.00, p < 0.0001. Furthermore, the results suggest the replication crisis influenced a significant increase in sample sizes noted by the significant non-linear trend, b = 0.09, SE = 0.03, p = 0.007.
Figure 2
Observed and Expected Discovery Rates
Figure 3 shows the changes in the ODR and EDR estimates over time. The ODR estimate showed a significant linear decrease of about b = -0.42 (SE = 0.10 p = 0.001) percentage points per year. The results did not show a significant non-linear trend in the ODR estimate, b = -0.10 (SE = 0.02, p = 0.563. The regression results for the EDR estimate showed no significant trends, linear, b = 0.04, SE = 0.37, p = 0.903, non-linear, b = 0.01, SE = 0.06, p = 0.906.
These findings indicate the journal has increased the publication of non-significant results. However, there is no evidence that this change occurred in response to the replicability crisis. Even with this change, the ODR and EDR estimates do not overlap, indicating that selection bias is still present. Furthermore, the lack of changes to the EDR suggests that many studies continue to be statistically underpowered to detect true effects.
Figure 3
Expected Replicability Rates and False Discovery Risks
Figure 4 depicts the false discovery risk (FDR) and the Estimated Replication Rate (ERR). It also shows the Expected Replication Failure rate (EFR = 1 – ERR). A comparison of the EFR with the FDR provides information for the interpretation of replication failures. If the FDR is close to the EFR, many replication failures may be due to false positive results in original studies. In contrast, if the FDR is low, most replication failures will likely be false negative results in underpowered replication studies.
There were no significant linear, b = 0.13, SE = 0.10, p = 0.204 or non-linear, b = 0.01, SE = 0.16, p = 0.392 trends observed in the ERR estimate. These findings are inconsistent with the observed significant increase in sample sizes as the reduction in sampling error often increases the likelihood that an effect will replicate. One possible explanation for this is that the type of studies has changed. If a journal publishes more studies from disciplines with large samples and small effect sizes, sample sizes go up without increasing power.
Given the lack of change in the EDR and ERR estimate over time, many published significant results are based on underpowered studies that are difficult to replicate.
Figure 4
Visual inspection of Figure 4 depicts the EFR consistently around 30% and the FDR around 10%, suggesting that about 30% of replication failures are false positives.
Adjusting Alpha
A simple solution to a crisis of confidence in published results is to adjust the criterion to reject the null-hypothesis. For example, some researchers have proposed to set alpha to .005 to avoid too many false positive results. With z-curve, we can calibrate alpha to keep the false discovery risk at an acceptable level without discarding too many true positive results. To do so, we set alpha to .05, .01, .005, and .001 and examined the false discovery risk.
Figure 5
Figure 5 shows that the conventional criterion of p < .05 produces false discovery risks above 5%. The high variability in annual estimates also makes it difficult to provide precise estimates of the FDR. However, adjusting alpha to .01 is sufficient to produce an FDR with tight confidence intervals below 5%. The benefits of reducing alpha further to .005 or .001 are minimal.
Figure 6
Figure 6 shows the impact of lowering the significance criterion, alpha, on the discovery rate (lower alpha implies fewer significant results). In Acta Psychologica lowering alpha to .01 reduces the observed discovery rate by about 20 percentage points. This implies that 20% of results reported p-values between .05 and .01. These results often have low success rates in actual replication studies (OSC, 2015). Thus, our recommendation is to set alpha to .01 to reduce the false positive risk to 5% and to disregard studies with weak evidence against the null-hypothesis. These studies require actual successful replications with larger samples to provide credible evidence for an evolutionary hypothesis. There are relatively few studies with p-values between .01 and .005. Thus, more conservative researchers can use alpha = .005 without losing too many additional results.
Limitations
The main limitation of these results is the use of automatically extracted test statistics. This approach cannot distinguish between theoretically important statistical results and other results that are often reported but do not test focal hypotheses (e.g., testing the statistical significance of a manipulation check, reporting a non-significant result for a factor in a complex statistical design that was not expected to produce a significant result).
Hand-coding of 81 studies in 2010 and 112 studies from 2020 showed ODRs of 98%, 95%CI = 94%-100% and 91%, 95%CI = 86%-96%, suggesting a slight increase in reporting of non-significant focal tests. However, ODRs over 90% suggest that publication bias is still present in this journal. ERR estimates were similar and the small sample size made it impossible to obtain reliable estimates of the EDR and FDR.
One concern about the publication of our results is that it merely creates a new criterion to game publications. Rather than trying to get p-values below .05, researchers may use tricks to get p-values below .01. However, this argument ignores that it becomes increasingly harder to produce lower p-values with tricks (Simmons et al., 2011). Moreover, z-curve analysis makes it easy to see selection bias for different levels of significance. Thus, a more plausible response to these results is that researchers will increase sample sizes or use other methods to reduce sampling error to increase power.
Conclusion
The replicability report for Acta Psychologica shows clear evidence of selection bias, although there is a trend that selection bias has decreased due to reporting of more non-significant results, but not necessarily focal ones. The power to obtain a significant result to report a significant result (i.e., a discovery) ranges from 38% to 73%. This finding suggests that many studies are underpowered and require luck to get a significant result. The false positive risk is modest and can be controlled by setting alpha to .01. Replication attempts of original findings with p-values above .01 should increase sample sizes to produce more conclusive evidence.
There are several ways, the current or future editors of this journal can improve credibility of results published in this journal. First, results with weak evidence (p-values between .05 and .01) should only be reported as suggestive results that require replication or even request a replication before publication. Second, editors should try to reduce publication bias by prioritizing research questions over results. A well-conducted study with an important question should be published even if the results are not statistically significant. Pre-registration and registered reports can help to reduce publication bias. Editors may also ask for follow-up studies with higher power to follow up on a non-significant result.
Publication bias also implies that point estimates of effect sizes are inflated. It is therefore important to take uncertainty in these estimates into account. Small samples with large sampling errors are usually unable to provide meaningful information about effect sizes and conclusions should be limited to the direction of an effect.
We hope that these results provide readers of this journal with useful informatoin to evaluate the credibility of results reported in this journal. The results also provide a benchmark to evaluate the influence of reforms on the credibility of psychological science. We hope that reform initiatives will increase power and decrease publication bias and false positive risks.
The z-curve analysis of results in this journal shows (a) that many published results are based on studies with low to modest power, (b) selection for significance inflates effect size estimates and the discovery rate of reported results, and (c) there is no evidence that research practices have changed over the past decade. Readers should be careful when they interpret results and recognize that reported effect sizes are likely to overestimate real effect sizes, and that replication studies with the same sample size may fail to produce a significant result again. To avoid misleading inferences, I suggest using alpha = .005 as a criterion for valid rejections of the null-hypothesis. Using this criterion, the risk of a false positive result is below 2%. I also recommend computing a 99% confidence interval rather than the traditional 95% confidence interval for the interpretation of effect size estimates.
Given the low power of many studies, readers also need to avoid the fallacy to report non-significant results as evidence for the absence of an effect. With 50% power, the results can easily switch in a replication study so that a significant result becomes non-significant and a non-significant result becomes significant. However, selection for significance will make it more likely that significant results become non-significant than observing a change in the opposite direction.
The average power of studies in a heterogeneous journal like Frontiers of Psychology provides only circumstantial evidence for the evaluation of results. When other information is available (e.g., z-curve analysis of a discipline, author, or topic, it may be more appropriate to use this information).
Report
Frontiers of Psychology was created in 2010 as a new online-only journal for psychology. It covers many different areas of psychology, although some areas have specialized Frontiers journals like Frontiers in Behavioral Neuroscience.
The business model of Frontiers journals relies on publishing fees of authors, while published articles are freely available to readers.
The number of articles in Frontiers of Psychology has increased quickly from 131 articles in 2010 to 8,072 articles in 2022 (source Web of Science). With over 8,000 published articles Frontiers of Psychology is an important outlet for psychological researchers to publish their work. Many specialized, print-journals publish fewer than 100 articles a year. Thus, Frontiers of Psychology offers a broad and large sample of psychological research that is equivalent to a composite of 80 or more specialized journals.
Another advantage of Frontiers of Psychology is that it has a relatively low rejection rate compared to specialized journals that have limited journal space. While high rejection rates may allow journals to prioritize exceptionally good research, articles published in Frontiers of Psychology are more likely to reflect the common research practices of psychologists.
To examine the replicability of research published in Frontiers of Psychology, I downloaded all published articles as PDF files, converted PDF files to text files, and extracted test-statistics (F, t, and z-tests) from published articles. Although this method does not capture all published results, there is no a priori reason that results reported in this format differ from other results. More importantly, changes in research practices such as higher power due to larger samples would be reflected in all statistical tests.
As Frontiers of Psychology only started shortly before the replication crisis in psychology increased awareness about the problem of low statistical power and selection for significance (publication bias), I was not able to examine replicability before 2011. I also found little evidence of changes in the years from 2010 to 2015. Therefore, I use this time period as the starting point and benchmark for future years.
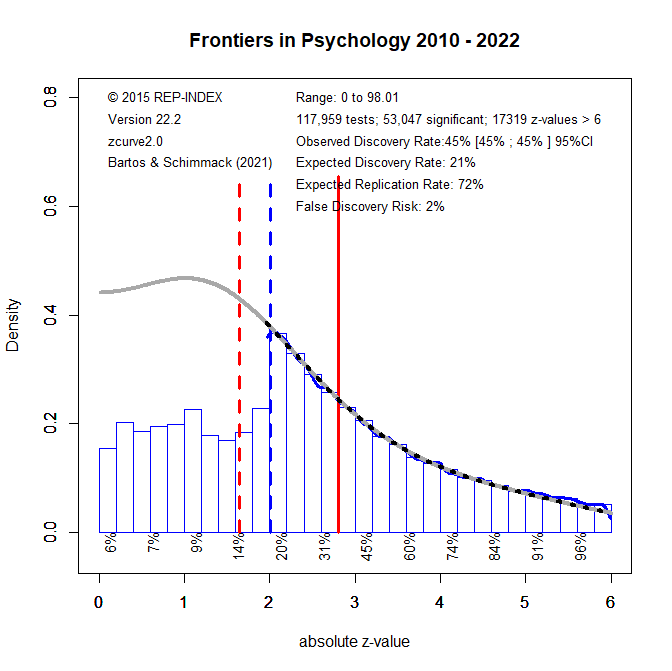
Figure 1 shows a z-curve plot of results published from 2010 to 2014. All test-statistics are converted into z-scores. Z-scores greater than 1.96 (the solid red line) are statistically significant at alpha = .05 (two-sided) and typically used to claim a discovery (rejection of the null-hypothesis). Sometimes even z-scores between 1.65 (the dotted red line) and 1.96 are used to reject the null-hypothesis either as a one-sided test or as marginal significance. Using alpha = .05, the plot shows 71% significant results, which is called the observed discovery rate (ODR).
Visual inspection of the plot shows a peak of the distribution right at the significance criterion. It also shows that z-scores drop sharply on the left side of the peak when the results do not reach the criterion for significance. This wonky distribution cannot be explained with sampling error. Rather it shows a selective bias to publish significant results by means of questionable practices such as not reporting failed replication studies or inflating effect sizes by means of statistical tricks. To quantify the amount of selection bias, z-curve fits a model to the distribution of significant results and estimates the distribution of non-significant (i.e., the grey curve in the range of non-significant results). The discrepancy between the observed distribution and the expected distribution shows the file-drawer of missing non-significant results. Z-curve estimates that the reported significant results are only 31% of the estimated distribution. This is called the expected discovery rate (EDR). Thus, there are more than twice as many significant results as the statistical power of studies justifies (71% vs. 31%). Confidence intervals around these estimates show that the discrepancy is not just due to chance, but active selection for significance.
Using a formula developed by Soric (1989), it is possible to estimate the false discovery risk (FDR). That is, the probability that a significant result was obtained without a real effect (a type-I error). The estimated FDR is 12%. This may not be alarming, but the risk varies as a function of the strength of evidence (the magnitude of the z-score). Z-scores that correspond to p-values close to p =.05 have a higher false positive risk and large z-scores have a smaller false positive risk. Moreover, even true results are unlikely to replicate when significance was obtained with inflated effect sizes. The most optimistic estimate of replicability is the expected replication rate (ERR) of 69%. This estimate, however, assumes that a study can be replicated exactly, including the same sample size. Actual replication rates are often lower than the ERR and tend to fall between the EDR and ERR. Thus, the predicted replication rate is around 50%. This is slightly higher than the replication rate in the Open Science Collaboration replication of 100 studies which was 37%.
Figure 2 examines how things have changed in the next five years.
The observed discovery rate decreased slightly, but statistically significantly, from 71% to 66%. This shows that researchers reported more non-significant results. The expected discovery rate increased from 31% to 40%, but the overlapping confidence intervals imply that this is not a statistically significant increase at the alpha = .01 level. (if two 95%CI do not overlap, the difference is significant at around alpha = .01). Although smaller, the difference between the ODR of 60% and the EDR of 40% is statistically significant and shows that selection for significance continues. The ERR estimate did not change, indicating that significant results are not obtained with more power. Overall, these results show only modest improvements, suggesting that most researchers who publish in Frontiers in Psychology continue to conduct research in the same way as they did before, despite ample discussions about the need for methodological reforms such as a priori power analysis and reporting of non-significant results.
The results for 2020 show that the increase in the EDR was a statistical fluke rather than a trend. The EDR returned to the level of 2010-2015 (29% vs. 31), but the ODR remained lower than in the beginning, showing slightly more reporting of non-significant results. The size of the file drawer remains large with an ODR of 66% and an EDR of 72%.
The EDR results for 2021 look again better, but the difference to 2020 is not statistically significant. Moreover, the results in 2022 show a lower EDR that matches the EDR in the beginning.
Overall, these results show that results published in Frontiers in Psychology are selected for significance. While the observed discovery rate is in the upper 60%s, the expected discovery rate is around 35%. Thus, the ODR is nearly twice the rate of the power of studies to produce these results. Most concerning is that a decade of meta-psychological discussions about research practices has not produced any notable changes in the amount of selection bias or the power of studies to produce replicable results.
How should readers of Frontiers in Psychology articles deal with this evidence that some published results were obtained with low power and inflated effect sizes that will not replicate? One solution is to retrospectively change the significance criterion. Comparisons of the evidence in original studies and replication outcomes suggest that studies with a p-value below .005 tend to replicate at a rate of 80%, whereas studies with just significant p-values (.050 to .005) replicate at a much lower rate (Schimmack, 2022). Demanding stronger evidence also reduces the false positive risk. This is illustrated in the last figure that uses results from all years, given the lack of any time trend.
In the Figure the red solid line moved to z = 2.8; the value that corresponds to p = .005, two-sided. Using this more stringent criterion for significance, only 45% of the z-scores are significant. Another 25% were significant with alpha = .05, but are no longer significant with alpha = .005. As power decreases when alpha is set to more stringent, lower, levels, the EDR is also reduced to only 21%. Thus, there is still selection for significance. However, the more effective significance filter also selects for more studies with high power and the ERR remains at 72%, even with alpha = .005 for the replication study. If the replication study used the traditional alpha level of .05, the ERR would be even higher, which explains the finding that the actual replication rate for studies with p < .005 is about 80%.
The lower alpha also reduces the risk of false positive results, even though the EDR is reduced. The FDR is only 2%. Thus, the null-hypothesis is unlikely to be true. The caveat is that the standard null-hypothesis in psychology is the nil-hypothesis and that the population effect size might be too small to be of practical significance. Thus, readers who interpret results with p-values below .005 should also evaluate the confidence interval around the reported effect size, using the more conservative 99% confidence interval that correspondence to alpha = .005 rather than the traditional 95% confidence interval. In many cases, this confidence interval is likely to be wide and provide insufficient information about the strength of an effect.
Original Post: 11/26/2018 Modification: 4/15/2021 The z-curve analysis was updated using the latest version of z-curve
“Trust is good, but control is better”
I asked Fritz Strack to comment on this post, but he did not respond to my request.
INTRODUCTION
Information about the replicability of published results is important because empirical results can only be used as evidence if the results can be replicated. However, the replicability of published results in social psychology is doubtful.
Brunner and Schimmack (2018) developed a statistical method called z-curve to estimate how replicable a set of significant results are, if the studies were replicated exactly. In a replicability audit, I am applying z-curve to the most cited articles of psychologists to estimate the replicability of their studies.
Fritz Strack
Fritz Strack is an eminent social psychologist (H-Index in WebofScience = 51).
Fritz Strack also made two contributions to meta-psychology.
First, he volunteered his facial-feedback study for a registered replication report; a major effort to replicate a published result across many labs. The study failed to replicate the original finding. In response, Fritz Strack argued that the replication study introduced cameras as a confound or that the replication team actively tried to find no effect (reverse p-hacking).
Second, Strack co-authored an article that tried to explain replication failures as a result of problems with direct replication studies (Strack & Stroebe, 2014). This is a concern, when replicability is examined with actual replication studies. However, this concern does not apply when replicability is examined on the basis of test statistics published in original articles. Using z-curve, we can estimate how replicable these studies are, if they could be replicated exactly, even if this is not possible.
Given Fritz Strack’s skepticism about the value of actual replication studies, he may be particularly interested in estimates based on his own published results.
Data
I used WebofScience to identify the most cited articles by Fritz Strack (datafile). I then selected empirical articles until the number of coded articles matched the number of citations, resulting in 42 empirical articles (H-Index = 42). The 42 articles reported 117 studies (average 2.8 studies per article). The total number of participants was 8,029 with a median of 55 participants per study. For each study, I identified the most focal hypothesis test (MFHT). The result of the test was converted into an exact p-value and the p-value was then converted into a z-score. The z-scores were submitted to a z-curve analysis to estimate mean power of the 114 results that were significant at p < .05 (two-tailed). Three studies did not test a hypothesis or predicted a non-significant result. The remaining 11 results were interpreted as evidence with lower standards of significance. Thus, the success rate for 114 reported hypothesis tests was 100%.
The z-curve estimate of replicability is 38% with a 95%CI ranging from 23% to 54%. The complementary interpretation of this result is that the actual type-II error rate is 62% compared to the 0% failure rate in the published articles.
The histogram of z-values shows the distribution of observed z-scores (blue line) and the predicted density distribution (grey line). The predicted density distribution is also projected into the range of non-significant results. The area under the grey curve is an estimate of the file drawer of studies that need to be conducted to achieve 100% successes with 28% average power. Although this is just a projection, the figure makes it clear that Strack and collaborators used questionable research practices to report only significant results.
Z-curve.2.0 also estimates the actual discovery rate in a laboratory. The EDR estimate is 24% with a 95%CI ranging from 5% to 44%. The actual observed discovery rate is well outside this confidence interval. Thus, there is strong evidence that questionable research practices had to be used to produce significant results. The estimated discovery rate can also be used to estimate the risk of false positive results (Soric, 1989). With an EDR of 24%, the false positive risk is 16%. This suggests that most of Strack’s results may show the correct sign of an effect, but that the effect sizes are inflated and that it is often unclear whether the population effect sizes would have practical significance.
The false discovery risk decreases for more stringent criteria of statistical significance. A reasonable criterion for the false discovery risk is 5%. This criterion can be achieved by lowering alpha to .005. This is in line with suggestions to treat only p-values less than .005 as statistically significant (Benjamin et al., 2017). This leaves 35 significant results.
CONCLUSION
The analysis of Fritz Strack’s published results provides clear evidence that questionable research practices were used and that published significant results have a higher type-I error risk than 5%. More important, the actual discovery rate is low and implies that 16% of published results could be false positives. This explains some replication failures in large samples for Strack’s item-order and facial feedback studies. I recommend to use alpha = .005 to evaluate Strack’s empirical findings. This leaves about a third of his discoveries as statistically significant results.
It is important to emphasize that Fritz Strack and colleagues followed accepted practices in social psychology and did nothing unethical by the lax standards of research ethics in psychology. That is, he did not commit research fraud.
DISCLAIMER
It is nearly certain that I made some mistakes in the coding of Fritz Strack’s articles. However, it is important to distinguish consequential and inconsequential mistakes. I am confident that I did not make consequential errors that would alter the main conclusions of this audit. However, control is better than trust and everybody can audit this audit. The data are openly available and the z-curve results can be reproduced with the z-curve package in R. Thus, this replicability audit is fully transparent and open to revision.
If you found this audit interesting, you might also be interested in other replicability audits.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.