Power Failure, False Positives, and The Replication Crisis
Scientists have become increasingly skeptical about the credibility of published results (Baker, 2016). The main concern is that scientists were presenting results as objective facts, while the results were often influenced by undisclosed subjective decisions that increased the chances of presenting a desirable result. These degrees of freedom in analyses are now called questionable research practices or p-hacking.
Ioannidis (2005) showed with hypothetical scenarios that questionable research practices combined with low statistical power and testing of many false hypotheses could lead to more false than true discoveries of statistical regularities (i.e., a statistically significant result).
Awareness of this problem has produced thousands of new articles that discuss this problem. It has even created its own new science called meta-science; the scientific study of science. Some articles have gained prominent status and are foundational to meta-science.
For example, the Reproducibility Project in psychology replicated 100 studies. While 97 of these studies reported a statistically significant result, only 36% of the replication studies showed a significant result. The drop in the success rate can be attributed to questionable research practices that inflated effect size estimates to achieve significance. Honest replications did not have this advantage, and the true population effect sizes were often too small to produce significant results.
The true probability of obtaining a statistically significant result is called statistical power (Cohen, 1988; Neyman & Pearson, 1933). In the long run, a set of studies with average true power of 50% are expected to produce 50% significant results, even if all studies test different hypotheses (Brunner & Schimmack, 2020l). Thus, the success rate of the Reproducibility Project implies that the replication studies had about 40% average power. As these studies replicated original studies as closely as possible (and similar sample sizes), this suggests that the average power of the original studies was also around 40%.
This estimate is in line with Cohen’s (1962) seminal estimate of power. Average power around 40% has two implications. First, many attempts to demonstrate an effect in a single study will fail to reject a false null hypothesis that there is no relationship; a false negative result (Cohen, 1988). Concerns about false negatives were the focus of meta-scientific discussions about significance testing in the 1990s (Cohen, 1994).
This shifted, when meta-scientists pointed out the consequences of selection for significance and low power (Ioannidis, 2005; Rosenthal, 1979; Sterling et al., 1995). Low statistical power combined with questionable research practices could result in many false discoveries (i.e., statistically significant results without a real effect). In some scenarios, literatures could be entirely made up of false discoveries (Rosenthal, 1979) or at least more false than true discoveries (Ioannidis, 2005).
Theoretical articles and simulation studies suggested that false positive rates might be uncomfortably high and replication failures seemed to support this suspicion, although replication failures could also just be false negative results (Maxwell, 2016). Thus, actual replication studies often do not settle conflicting interpretations of the evidence. While some researchers see replication failures as evidence that original results cannot be trusted, others point towards the difficulty of replicating actual studies and false negatives as reasons why original results could not be replicated (Gilbert et al., 2016).
An alternative approach examines false positives for sets of studies rather than a single study. The statistical results of original articles are used to estimate the average power of studies and to use power to evaluate the risk of false positive results. One of the first attempts to do so was Button, Ioannidis, Mokrysz, Nosek, Flint, Robinson, and Munafò’s (2013) article “Power failure: why small sample size undermines the reliability of neuroscience.” The key empirical finding was that median power of 730 studies from 49 meta-analysis was 21%. The article did not provide an empirical estimate of the false positive rate, but it did illustrate implications of the power estimate for false positive rates in various scenarios. The authors suggested that “a major implication is that the likelihood that any nominally significant finding actually reflects a true effect is small” (p. 371). This claim has contribute to concerns that many published significant results are unreliable.
Reexamining The Power Failure
More than ten years later, it is possible to revisit the seminal article with the benefit of hindsight. Advances in the estimation of true power have revealed important conceptual problems that are different from the computation of hypothetical power for the purpose of sample size planning (Brunner & Schimmack, 2020; Soto & Schimmack, 2026).
Cohen defined statistical power as the probability of obtaining a significant result (1988). In the context of sample size planning, however, power is defined as the probability of obtaining a significant result given a hypothetical population effect size greater than zero. This conditional definition of power given a true hypothesis is widely used in the power literature and was also used by Ioannidis (2005) in his calculations of false positive rates.
Assuming only true hypothesis to compute power is reasonable for hypothetical scenarios, but not for the estimation of true power of completed studies. As the population effect size remains unknown after a study produced an effect size estimate, it is not possible to assume an effect size greater than zero. Thus, the true probability of a completed study to produce a significant result is unconditional and independent of the distinction between H0 and H1. Any estimate of average true power is therefore an estimate of the unconditional probability to produce a significant result. This average can contain tests of true null-hypothesis.
The distinction between conditional and unconditional probabilities has important implications for Button’s calculations of false positive rates. The median power of 21% is unconditional, but the false positive calculations assume conditional power. This can lead to inflated estimates of false positive rates. For example, mean power of 20% could be made up of 50% true H0 with a 5% probability to produce a (false) significant results and 50% tests of H1 with 35% power. In this scenario, the false positive rate is 2.5% / (2.5% + 17.5) = 12.5%. Increasing the proportion of true hypothesis that were tested to a 4:1 ratio would increase the conditional power of tests of H1 to 80% to maintain 20% average power. The false positive rate would increase to .04 / (.04 + .15) = 20%. As noted by Soric (1989), we can even compute the maximum false positive rate that is consistent with unconditional mean power assuming conditional power of 1. With mean power of 21%, the maximum ratio of H0 over H1 is 5.25:1 and the maximum false discovery rate is 20%.
Table 1
Maximum False Discovery Rate for 20% Unconditional Power (Soric, 1989)
| Not Significant | Significant | Total | |
| H₁ True | .000 | .160 | .160 |
| H₀ True | .798 | .042 | .840 |
| Total | .798 | .202 | 1.000 |
| H₀ : H₁ Ratio | 5.25 : 1 | ||
| False Discovery Rate | .208 |
Note. The table shows the maximum false discovery rate when average unconditional power equals 20%. This maximum occurs when conditional power for true hypotheses (H₁) equals 100%. The false discovery rate equals the proportion of significant results that are false positives: .042 / .202 = .208. Any lower conditional power with the same unconditional power of 20% produces a lower false discovery rate.
Soric’s formula: max.FDR = (1/Mean.Power – 1)*(alpha/(1-alpha))
The 21% false positive rate overestimates the true false positive rate with 21% median power for two reasons. Soric’s formula assumes that H1 are tested with 100% power. Assuming that many tests of small true effect sizes in small samples have low conditional power, the true false positive rate is below 21%. The second reason is that unconditional power has a skewed distribution with many low power studies and a few high power studies. As a result, mean power will be higher than median power. Button et al.’s provide information about mean power based on their analyses of publication bias that uses mean power. This analysis suggested that 254 of the 730 studies were expected to produce a significant result and the expected percentage of significant results is equivalent to mean power (Brunner & Schimmack, 2020). Thus, mean power was estimated to be 254 / 730 = 35%. Based on Soric’s formula, the maximum false discovery rate with 35% significant results is 10%.
In conclusion, Button et al.’s estimate of unconditional mean power can be used to draw inferences about false positives in the meta-analyses that they examined that do not rely on unknown ratios of true and false hypotheses being tested in neuroscience. Using their data and Soric’s formula suggests that the false positive risk is fairly small.
A Z-Curve Analyses of Button et al.’s Data
Button et al.’s article contribute to a culture of open sharing of data, but that was not the norm when the article was published. Fortunately, Nord et al. (2017) conducted further analyses of the data and shared power estimates for the 730 studies in an Open Science Foundation (OSC) project. The power estimates do not use the effect sizes of individual studies. Rather they use the sample sizes and the meta-analytic effect size to estimate power. This approach corrects for effect size inflation in smaller studies and reduces bias in power estimates. The following analyses used these data. Power estimates based on individual studies are likely to be inflated by publication bias.
Based on these data, 28% of the studies were statistically significant. Mean power was 35%, matching Button et al.’s estimate of mean power, suggesting that Nord et al.’s power values are based on meta-analytic effect sizes.
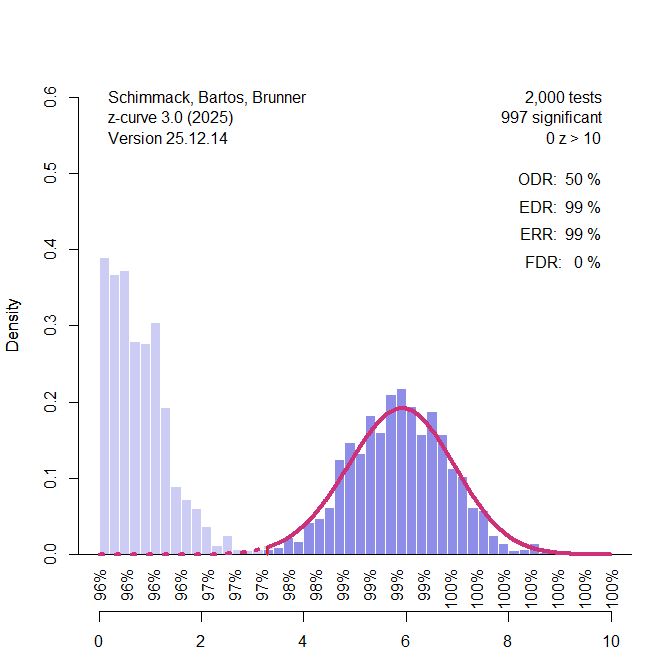
I converted power values into z-values and analyzed the z-values with z-curve.3.0 using the default model (Figure 1).
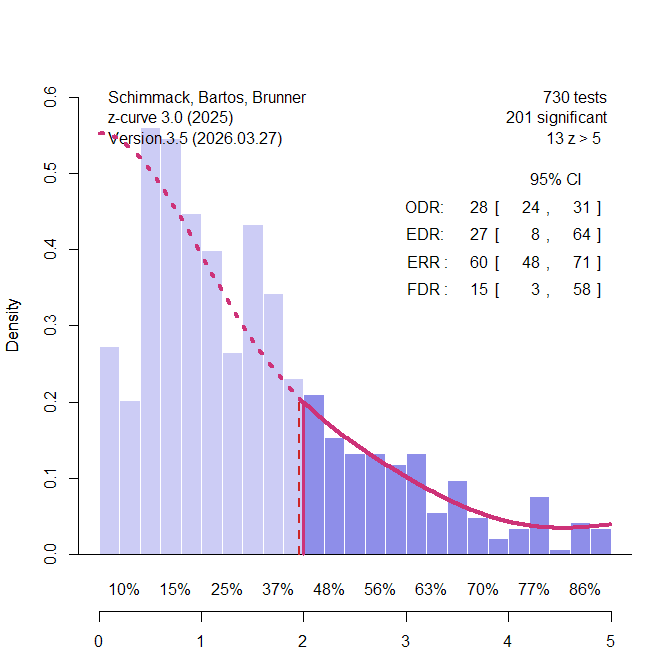
The observed discovery rate (ODR) is simply the percentage of significant results. More important is the bias-corrected estimate of unconditional mean power for all 730 z-values. Z-curve uses the observed distribution of significant z-values and projects the fitted model into the range of unobserved significant results. As shown in Figure 1, the model predicts the actual distribution of non-significant results fairly well. This suggests that the use of meta-analytic effect sizes adjusted inflated effect size estimates and removed publication bias. The estimated mean power for all studies is called the expected discovery rate (EDR). The EDR estimate is close to the ODR, suggesting further that the data are unbiased.
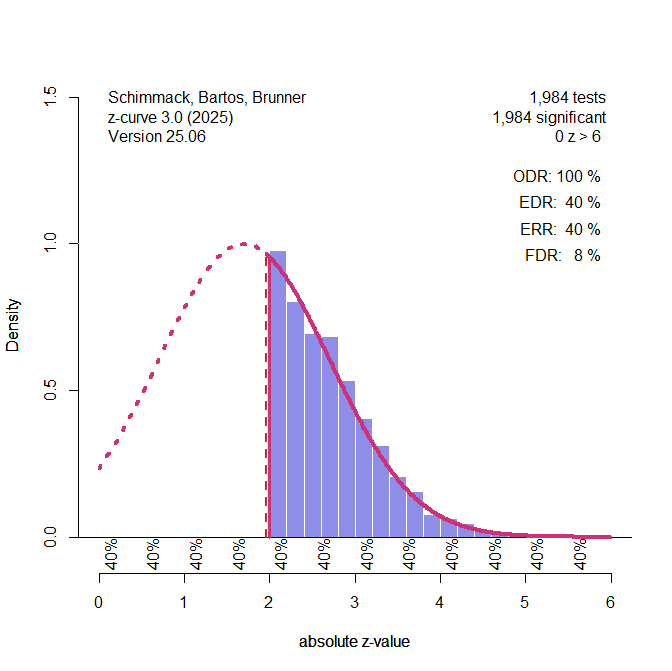
A key problem of estimating the EDR based on the significant results only is that the confidence interval around the point estimate is very wide. When the data show no major bias, more precise estimates can be obtained by fitting the model to all 730 data (Figure 2).
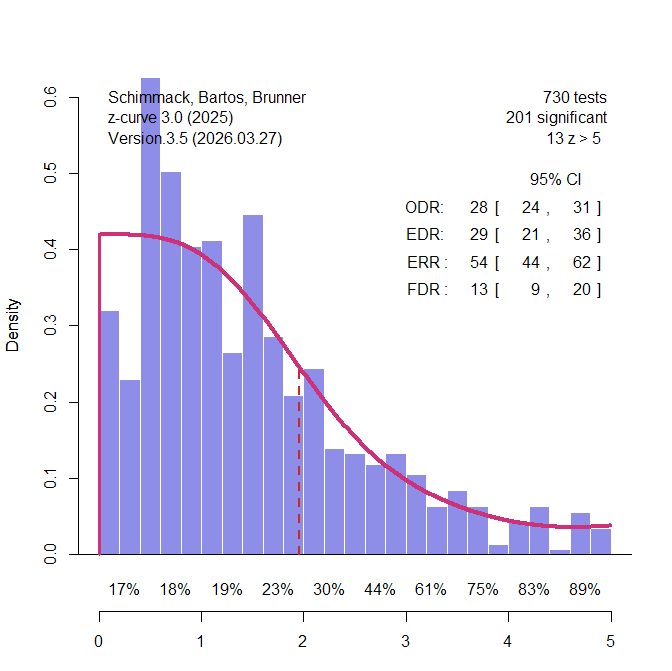
The key finding is that the point estimate of the false positive risk, FDR = 13% is in line with calculations based on Button’s estimate of mean power. The confidence interval around this estimate limits the FDR at 20%. This is an upper limit because conditional power of studies with significant results is likely to be less than 100%.
In fact, z-curve makes it possible to estimate conditional power of significant studies. First, z-curve estimates unconditional average power of significant studies. This parameter is called the expected replication rate (ERR) because it predicts how many studies would produce a significant result again in a hypothetical replication project that reproduces the original studies exactly with new samples. The ERR is 54% with an upper limit of 60% for the 95% confidence interval. We also know that no more than 20% of these studies are false positives. Assuming 80% true hypotheses, the average conditional power can not be higher than (.60 – .20*.05) / .8 = 74%. Thus, Soric’s assumption of 100% power is conservative, and the false positive rate is likely to be lower.
In conclusion, a z-curve analysis of Nord et al.’s power estimates for Button et al.’s meta-analyses confirms estimates that could have been obtained by applying Soric’s formula to Button et al.’s estimate of mean power. The true rate of false positive results remains unknown, but it is unlikely to be more than 20%.
Heterogeneity Across Research Areas
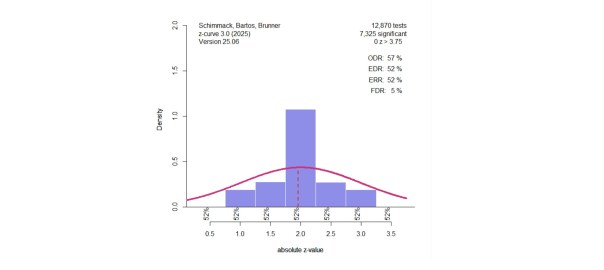
Nord et al. (2017) demonstrated that power varies across different research areas that were included in Button et al.’s sample of meta-analyses. Some of these areas had enough studies to conduct z-curve analyses for these specific areas. The most interesting area are candidate-gene studies that relate genotypic variation in single genes to phenotypes across participants With the benefit of hindsight, it is known that variation in a single gene has trivial effects on complex traits and that many of the significant results in these studies were practically false positive results (Duncan & Keller, 2011). 234 of the 730 studies were from this research area. Figure 3 shows the results. Interestingly, only 11% of the results were statistically significant. Thus, the low average power can be explained by many studies that reported non-significant results. There is no evidence of publication bias in these meta-analyses.
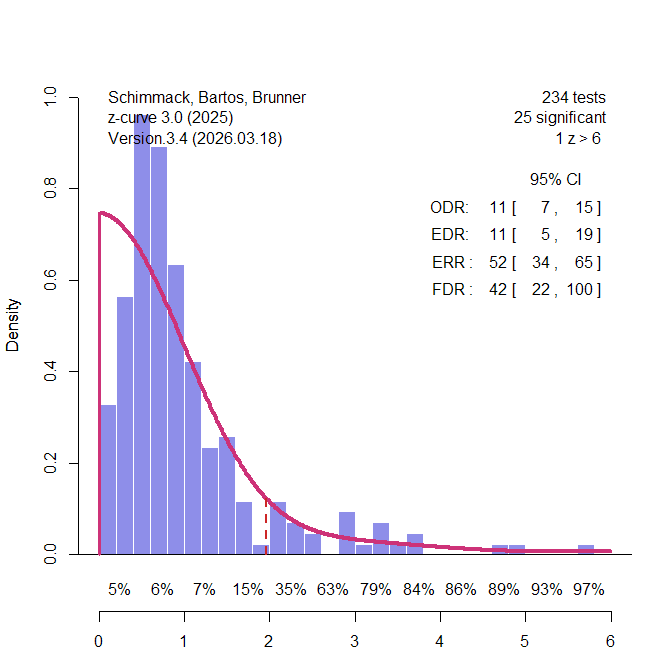
Using Soric’s formula, the low EDR translates into a high false positive risk, 42% and the upper limit of the 95% confidence interval includes 100%. Thus, z-curve confirms that the rare significant results in this literature could be false positive results. Most significant results also are just significant. There are hardly any results that show strong evidence (z > 4) against the null-hypothesis.
In short, a large portion of the 730 studies came from a research area that is known to have produced few significant results. This finding implies that other research areas are producing more credible significant results (Nord et al., 2017).
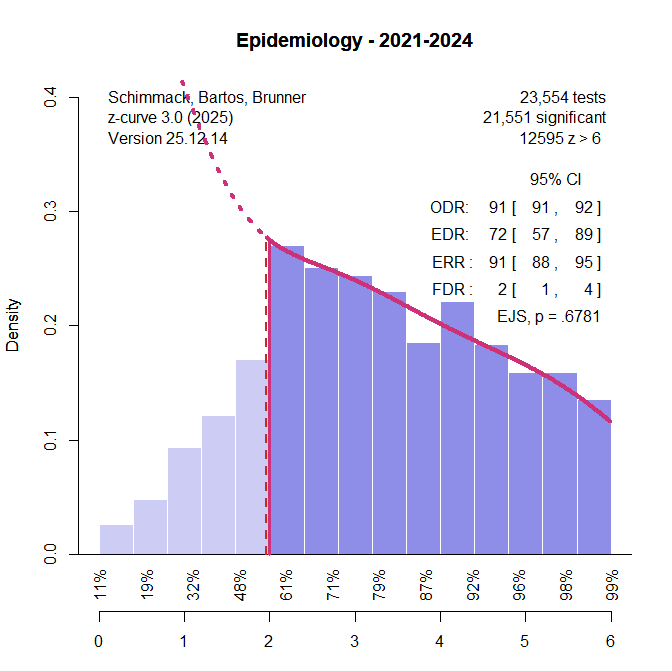
A second set of meta-analyses were clinical trials. Clinical trials have received considerable attention using Cochrane meta-analyses and abstracts in original articles that often report the key statistical result ( (Jager & Leek, 2013; Schimmack & Bartos, 2023, van Zwet et al., 2024). The results suggest that unconditional mean power is around 30% and the false positive risk is between 10% and 20%. These results serve as benchmarks for the z-curve analysis of the 145 clinical trials in Button et al.’s study (Figure 4).
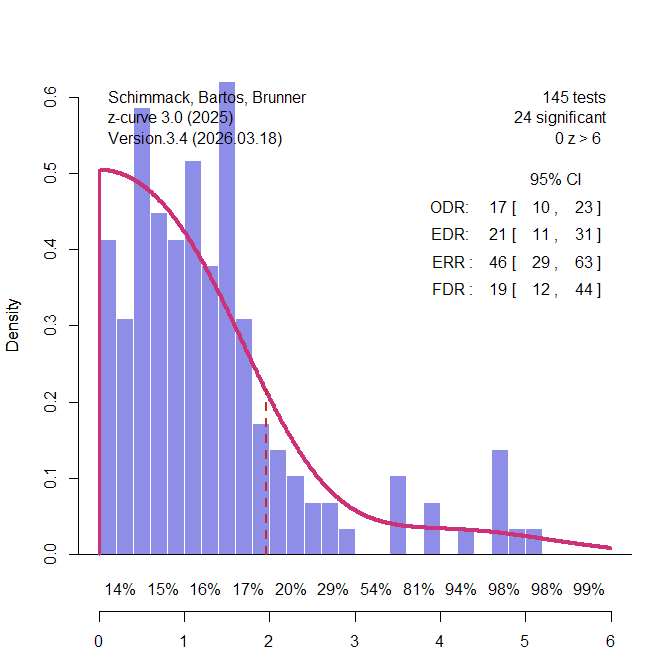
The EDR is somewhat lower, 21%, but the 95% confidence interval includes 30%. The FDR is 19%, but the lower limit of the confidence interval includes 13%. Thus, the results are a bit lower, but mostly consistent with evidence from estimates based on thousands of results. These estimates of the FDR are notably lower than the false positive rates that were predicted by Ioannidis’s scenarios that assumed high rates of true null-hypotheses.
The third domain were studies from psychology. Psychological scientists have examined the credibility of their research in the wake of replication failures (Open Science Collaboration, 2015). Suddenly, only significant results in multiple studies within a single study were no longer attributed to reliable effects, but seen as signs of selection for significance (Schimmack, 2012). Francis (2014) found that over 80% of these multi-study articles showed statistically significant evidence of bias. Large scale multi-lab replication studies failed also showed that effect sizes estimates in these studies could be inflated by a factor of 1,000, shrinking effect sizes from d = .6 to d = .06 (Vohs et al., 2019). A z-curve analysis of a representative sample of studies in social psychology estimated that average unconditional power before selection for significance, EDR = 19%, FDR = 22%. Cohen (1962) already found similar estimates are similar for focal and non-focal results. This was also the case in a survey of emotion research (Soto & Schimmack, 2024). Soto and Schimmack (2024) reported an EDR of 30% and a corresponding FDR = 12% (k sig = 21,628) for all automatically extracted tests, and an EDR of 27%, FDR = 14%, for hand-coded focal tests (k sig = 227). These results serve as a comparison standard for the z-curve of 145 studies classified as psychological research by Nord et al. (2017). The EDR is 49%, FDR = 5%. Even the lower limit of the EDR confidence interval, 39%, implies only 8% false positives. among the significant results.
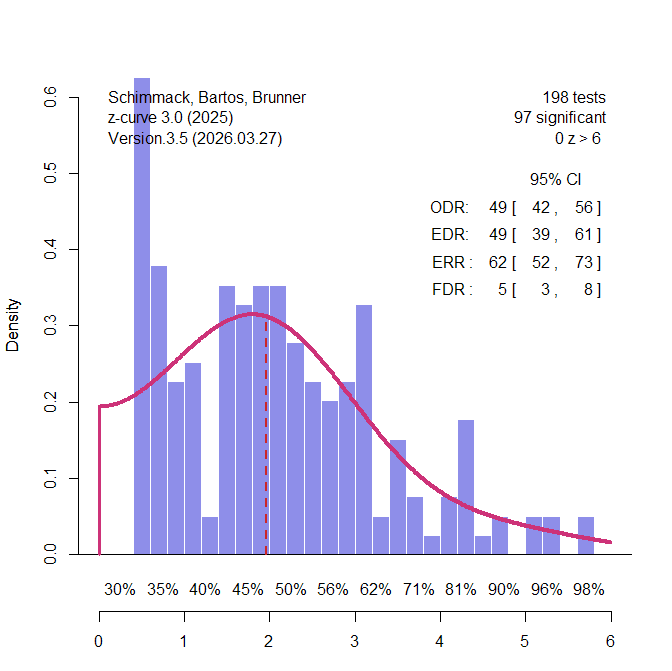
There are several reasons why these results differ from other findings. First, the focus on meta-analyses leads to an unrepresentative sample of the entire literature. Meta-analyses often include a lot more non-significant results and have less bias than original articles. Second, the specific set of meta-analyses was not representative of the broader literature in psychology. Thus, the results cannot be generalized from the specific studies in Button et al.’s sample to psychology or neuroscience. That would require representative sampling or collecting data from all studies using automatic extraction of test statistics.
Discussion
Button et al.’s (2013) was a first attempt to assess the credibility of empirical results with empirical estimates of power based on meta-analytic effect sizes and sample sizes. The median power was low (21%). The key implications of these finding was that researchers often fail to reject null-hypotheses and may use questionable research practices to report significant results in published articles. Low power and bias could lead to many false positive results. This article added to other concerns about the reliability of findings in neuroscience (Vul et al., 2019).
Most citations took Button et al.’s findings and implications at face value. Nord et al. (2017) pointed out that power and false positive rates varied across research areas. Most notably, candidate gene studies have lower power and a much higher false positive risk. Including these studies in the calculation of median power may have led to false perceptions of other research areas.
Here I presented the first serious critical examination of Button et al.’s methodology and inferences and found several problems that undermine their pessimistic assessment of neuroscience. First, they estimated unconditional power, but their false positive calculations require estimates of conditional power. Second, false positives rates depend on mean power and not median power. Mean power was 35% which is close to the estimate for psychology based on actual replication studies (OSC, 2015). Third, they made unnecessary assumptions about ratios of true and false hypotheses being tested, when unconditional power alone is sufficient to estimate false positive rates (Soric, 1989). Fourth, they relied on meta-analysis to correct for publication bias, but meta-analyses are not representative of the broader literature.
Meta-science is like other sciences. Ideally, critical analyses reveal problems and new innovations address these problems. Power estimation started in the 1960s with Cohen’s seminal article. Cohen (1962) worked with plausible effect sizes, but did not aim to estimate studies true power. Moreover, his work and statistical power were largely ignored (Cohen, 1990; Sedlmeier & Gigenzer, 1989).
Conclusion
The replication crisis stimulated renewed interest in methods that use observed results to draw inferences about the power of actual studies (Ioannidis & Trikalinos, 2007; Francis, 2014; Schimmack, 2012; Simonsohn, Nelson, & Simmons, 2014). This work shifted attention from prospective power calculations to the retrospective assessment of evidential strength in published literatures. Two challenges emerged as central. First, selection bias inflates the observed rate of significant results, requiring methods that correct for selection. Second, power varies across studies, requiring models that allow for heterogeneity rather than assuming a single common effect size or power level. Early approaches addressed selection under simplifying assumptions, typically treating power as homogeneous across studies. As a result, their inferences become unreliable when studies differ in sample size, effect size, or both (Brunner & Schimmack, 2020; Schimmack, 2026).
Z-curve extends this line of work by explicitly modeling both selection and heterogeneity, estimating a distribution of power across studies rather than a single average. This provides a framework for quantifying key properties of the literature, including expected discovery and replication rates, and for linking these quantities to false discovery risk (Sorić, 1989). In this sense, z-curve represents a substantive advance in the empirical assessment of the credibility of published findings. Like earlier contributions such as Button et al., it is unlikely to be the final word, but it is currently the most advanced method to estimate true power for sets of studies with heterogeneity in power and selection bias.