The chapter offers interesting insights into the history of Project Implicit by two insiders who worked for Project Implicit. This blog post provides comments on this history from the perspective of an outsider.
1. Big Sample Envy
“Nosek wanted to use the IAT in his research but was only allotted fifteen participant hours through the Yale participant pool” (p. 98).
In most sciences, it is a blessing to be at a rich ivy league university with expensive equipment. Psychology is different because it relied mostly on undergraduate students as participants and classes at fancy ivy universities are small. This gave large state universities like Ohio State University or the University of Illinois at Urbana-Champaign. One might think, rich universities could just pay participants, but that did not appear to be the case. Thus, psychologists at the top universities often published studies with very small samples (Bargh et al., 1996), which led to the replication crisis in the 2010s (Doyen et al., 2012; Kahneman, 2012, 2017).
Project Implicit was born out of the desire to collect data with large samples.
“In the first version of the website, I set up the application to compute the scores within the app and just send a single line of data to the database– e.g., block means, errors. I could watch the file grow live with each person completing a test and their result being added to the database. It was truly mesmerizing. Watching a new line come in every few seconds compared to how laborious data collection had been before. It was some thing of a conversion experience to going all-in on on-line data collection.” (Brian Nosek, quoted in Ratliff & Smith, p. 98).
For an outsider, the statement is a clear admission that the primary purpose of Project Implicit was research and the use of online administration to get data from many people.
Ratliff and Smith further mention that the National Institute of Mental Health awarded a research grant ($2.5 million) to “further develop the virtual laboratory on the Internet” (p. 98).
False Feedback and Deception
The article also mentions the preconditions for research conducted with Project Implicit. ( (1) studies can be no longer than fifteen minutes (around ten minutes is the goal), (2) study text should be no higher than an eighth-grade reading level (3) studies may not include deception (4) studies must include some kind of measure about which participants receive feedback (5) an appropriate debriefing that fulfills the educational mission of the organization must be offered.
Several of these points are noteworthy from an outsider’s perspective. The short time frame makes it impossible to study causes or consequences of implicit biases experimentally. Even correlational studies that relate IAT scores to other measures may take longer. Thus, most studies are limited to the IAT scores themselves or correlations with demographic variables. This limits the usefulness of the virtual laboratory to study actual causes and consequences of implicit biases in real life. Not surprisingly, millions of people have completed an IAT, but sample sizes with actual measures of behavior are much smaller and often unable to reveal meaningful relationships (Kurdi et al., 2019).
The absence of deception and the requirement to provide feedback about IAT performance create a tension that is rarely acknowledged. One type of study in psychology deliberately gives people false feedback about a desirable trait. These studies use deception and require extensive debriefing to ensure that participants are not harmed by the false information. Project Implicit does not give blatantly false feedback, but many people will receive false feedback if a test has low validity. For example, an IQ test that correlates r = .6 with true intelligence (whatever that is) will give 20% of participants false feedback that they are below average (IQ below 100) if their true score is above average. IAT scores are much less valid than intelligence tests and even more people get false feedback. An ethical debriefing would require warning people that one possible explanation for a surprising result is measurement error, however Project Implicit has failed to provide this information. This resistance to debriefing participants properly about the low validity of IAT scores contradicts the claim that IAT research on Project Implicit should avoid deception and properly debrief participants.
The lack of proper debriefing can be explained by the insiders’ belief in implicit biases and the ability of IATs to measure them.
“When we started graduate school in 2003, few people outside of the field of social psychology were talking about implicit bias. We earnestly explained to our friends and family that people have attitudes and stereotypes that influence how they see and interpret the world around them, and they might not even know it is happening. They were skep tical. We told them about tests that help scientists uncover and quantify these biases. They were notc onvinced. We told them to read Blink (Gladwell, 2005). A “real” author wrote that; they started to get it. Now, of course, implicit bias is discussed everywhere– court rooms, police departments, offices of human resources, corporate boardrooms, elementary schools, and colleges. The idea that even “good people” may harbor unwanted attitudes and stereotypes is commonplace, ordinary, perhaps even a bit insipid. We seem to have forgotten that, just two decades ago, these ideas were quite radical.” (Ratliff & Smith, p. 97).
Research on the unconscious, however, shows how hard it is to study unconscious processes and that widespread beliefs in them do not mean that they exist. At one point in time, academic psychologists were attacked for questioning the validity of repressed memories and it is now widely accepted that some (not all!) of these memories were constructions of events that never happened.
Like some psychoanalysts who lashed out against scientific critics, Project Implicit insiders dismiss valid scientific criticism without engaging with the scientific arguments.
“we disagree with arguments that moderate correlations between IAT scores and self-report suggest that the constructs are redundant (Schimmack, 2021), and thus implicit bias is uninteresting. These and similar arguments are difficult to reconcile with many people’s surprise and even resistance when confronted with evidence of their own bias” (Ratliff & Smith, p. 112).
This response is almost comically similar to a cartoonish psychoanalyst who tells a patient that (a) “you unconsciously want to kill your father,” (b) you unconsciously want to sleep with your mother,” or (c) “you unconsciously want to have a penis.” When the patient responds that this is clearly not the case, the psychiatrists claims that they are just using defense mechanisms to deny the truth about their hidden motives.
According to Ratliff and Smith any denial of biases revealed by the IAT is a defensive response, when most of the time, it is much more likely that the IAT scores are biased. They also mischaracterize Schimmack’s evidence, which may reveal a defensive reaction of their own. Schimmack showed that a large portion of the variance in IAT scores is random and systematic measurement error. Once measurement error is statistically corrected, IAT scores and self-reports on the race IAT are highly correlated. Thus, there is no evidence that IAT scores reflect anything that could diverge from people’s self-perceptions. Moreover, their self-reported attitudes are often stronger predictors of behavior than the small amount of unique variance in IAT scores, even in studies done by IAT proponents (Axt et al., in press; Greenwald et al., 1998).
Accuracy and Ethics of Feedback
The section “Accuracy and Ethics in Providing IAT Feedback” promises to address these problems, but falls short of engaging with the low validity of IAT scores as measure of implicit biases.
“Research shows the IAT is an effective educational tool for raising awareness about implicit bias, but the IAT cannot and should not be used for diagnostic or selection purposes (e.g., hiring or qualification decisions). For example, using the IAT to choose jurors is not justifiable, but it is appropriate to use the IAT to teach jurors about implicit bias” (Ratliff & Smith, p. 115).
What this statement leaves out is the reason why IATs should not be used for diagnostic purposes. The reason is that IAT scores have woefully inadequate validity; that is most of the variance in these scores is measurement error. So, how is it ethical to give people feedback about these scores if they are often invalid? The most revealing statement in the whole article is Ratliff and Smith’s answer to this question:
“This brings up an important question on which Project Implicit’s Scientific Advisory Board reflects frequently– is it ethical to pro vide participants feedback on their IAT performance? Thus far, the team has answered this question in the affirmative (a point to which we will return at the end of this section), but the team closely follows the literature on IAT reliability and malleability to make this decision and are open to reconsidering should the evidence suggest it is prudent to do so.”
The question is whether we can trust a team of researchers who are interested in collecting data in the virtual laboratory to make this ethical decision without conflict of interest. Maybe they should consult outsiders to avoid motivated biases that could harm people who receive false feedback without proper debriefing.
Aside from conflict of interest, a bigger problem is that the Project Implicit members have no formal training in developing, evaluating, and administering psychological tests, a discipline known as psychometrics and despite the similar name, largely removed from psychology. Even undergraduate students learn at some point that reliability is insufficient to evaluate test scores, but Ratliff and Smith never discuss validity and systematic measurement error in IAT scores.
They also confuse effect sizes for group means with scores of individuals. “The reasoning for these particular cut-offs is that, given that the standard deviations of IAT D-scores are rarely greater than 0.5 (Nosek et al., 2007), these IAT D-score cutoffs correspond approximately to Cohen’s d effect sizes of 0.3 (slight preference), 0.7 (moderate preference), and 1.3 (strong preference). These are above Cohen’s conventional cutoffs (i.e., 0.2, 0.5, 0.8), because the confidence interval around the estimate of a single score is likely to be greater than that of the confidence interval based on a sample mean. In other words, the feedback is somewhat conservative” (p. 101). This claim shows lack of knowledge about the scoring of test scores and the true amount of uncertainty around an individuals’ test score. Not surprisingly, they see no problem in providing invalid feedback based on their false assumption that the scoring is conservative.
The chapter does provide some interesting information about changes to the feedback that people are given. In the beginning, feedback claimed that IAT scores reveal unconscious biases. Ratliff and Smith emphasize that talks and educational materials no longer use the term unconscious (p. 112). Instead, “for several years now Project Implicit has used the term active awareness to reflect the fact that unawareness of implicit bias might be because one has not reflected deeply about their biases rather than because one cannot” (p. 112).
However, there is no evidence for this claim. A search on the Project Implicit website did not retrieve any relevant hits that mention active awareness and evidence that IAT scores reflect biases that operate without active awareness. Instead, the website continues to claim that implicit biases exist without awareness.
Some outsiders might consider this double deception. The description of the way Project Implicit is presenting itself to the public is deceiving readers who do not fact check the claim and the claim “without awareness” deceives people who visit the website that the test can tell something about them that they do not already know.
Conclusion
In conclusion, Project Implicit was created as a research laboratory for short studies with the aim to get responses from a large number of people. Many other researches have surveys posted, but do not get millions of visitors to do their surveys. Project Implicit has benefited from an affiliation with Harvard that suggests to many Americans that it is solid science and from marketing the IAT as a “window into the unconscious” (Banaji & Greenwald, 2013). Criticism of the validity of the IAT has been brushed aside with the claim that “Project Implicit gives feedback to participants about their IAT performance because of the perceived educational value in doing so.” The question remains who perceives this value. Many outsiders do not think that it is educational to give people false feedback about their unconscious. If the IAT is no different than a Rorschach test, why does it still get support from psychological science.
Fortunately, thanks to popular articles and blog posts the general public is learning more about the problems with the IAT and the concept of implicit biases (Schimmack, 2026; Singal, 2017). This blog post provides further evidence that the organization behind the online administration of the IAT lacks the scientific qualifications to do so and has put self-interest over ethics. Despite growing scientific evidence that IATs do not measure implicit biases, visitors are not given proper information about the accuracy of their feedback. Instead, resistance to the feedback is described as defensive. Ironically, the response by the scientific advisory board to criticism is a lot more defensive and less defensible than responses by people to do not believe the IAT.
Project Implicit is a nonprofit company founded in 1998 by three social psychologists: Tony Greenwald (University of Washington) Mahzarin Banaji (Harvard University) Brian Nosek (University of Virginia)
Project Implicit is mainly known as the company that hosts a website where people receive (false) feedback about their implicit associations based on the Implicit Association Test (IAT). The website is hosted by Harvard University, which is prominently displayed in web searchers, presumably because many Americans associate Harvard with excellent science.
However, the ethical oversight for the activities of Project Implicit rests with the Institutional Review Board with the University of Virginia’s IRB for Social and Behavioral Sciences. The Harvard branding is real but largely a legacy of Banaji’s professorship there; the organization is legally independent of Harvard.”
Project Implicit is now also hosting on an independent site as About the IAT – Project Implicit. Thus, the connection with Harvard may come to an end, but the website hosted by Harvard is still operational.
People
Based on the ProPublica 990 data, the leaders of Project Implicit in the fiscal year 2025 were:
Amy Jin Johnson — Executive Director (the only compensated employee, at $111,038)
Dr. Brian Nosek — President (University of Virginia; co-founder)
Dr. Kate Ratliff — Treasurer (University of Florida)
Keith Maddox, PhD — Director
Jarvis Idowu — Director
Bayet Ross Smith — Director
The affiliation with University of Virginia and Brian Nosek’s role as president and co-founder make it clear that Brian Nosek is the main person responsible for the ethical integrity of Project Implicit’s scientific work and the administration of IATs to the general public.
Financials
The picture that emerges is of a very small operation that is burning through reserves. As a 501(c)(3), Project Implicit files Form 990s with the IRS, which are publicly accessible. The ProPublica Nonprofit Explorer has their filings going back to 2011.
For fiscal year ending September 2025: revenue of $104,552, expenses of $296,971, a net loss of $192,419, and total net assets of $365,382. The dominant revenue source was program services (82% of revenue, at $86,100), with investment income making up most of the rest. Public donations were negligible at $675 (0.6%).
The prior year (FY2024) showed revenue of $273,966 against expenses of $489,223 — another large deficit — and the year before that (FY2023) showed revenue of $436,655 against expenses of $522,546.
So revenues have dropped sharply over three years (~$437K → ~$274K → ~$105K) while expenses remain high relative to income. They are drawing down net assets at a significant rate.
The main revenue of Project Implicit are fees for program services:
Corporate/organizational DEI training and consulting — companies, government agencies, universities, and HR departments pay Project Implicit to run implicit bias workshops, license the IAT for their own use, or deliver training programs. This has been a significant revenue stream for them, especially during the DEI boom years of 2020–2022.
Licensing or access fees — organizations that want to use the IAT infrastructure for research or applied purposes may pay for that.
Speaking and educational programs — paid engagements where Project Implicit personnel deliver training.
The trajectory tells an interesting story. Program service revenue went from ~$308K (FY2023) to ~$240K (FY2024) to ~$86K (FY2025) — a collapse of roughly 72% in two years. That almost certainly tracks the broader pullback in corporate DEI spending that accelerated after 2023 and especially into 2024–2025. Thus, while the website hosts hundreds of different IATs, the race IAT is the bread and butter IAT that funds the organization. The collapse in revenues can be explained by the changing political climate under the “Make Racism Great Again” policies of the MAGA government. There is no evidence that sustained criticism of the validity of IATS in general and the race IAT specifically over the past decades has contributed to this sharp drop in revenues.
Project Implicit’s mission statement has changed considerably over time, against the backdrop of accumulating scientific criticism of the IAT and the organization’s broader institutional repositioning. The changes are visible not only in the language itself, but also in where the organization now presents itself to the public.
An older version still visible on the Harvard-hosted site describes an organization that “provides consulting, education, and training services on implicit bias, diversity and inclusion, leadership, applying science to practice, and innovation” (app-prod-03.implicit.harvard.edu, retrieved June 1, 2026). The earliest version cached by the Wayback Machine, from 2013, contains the same language. The current projectimplicit.net site describes its educational work in considerably more cautious terms, as providing “research-based educational programs that translate findings from cognitive science into clear, accessible understanding of judgment and decision-making, without prescribing behavior change or organizational intervention.”
The phrase “without prescribing behavior change or organizational intervention” marks a significant retreat. The earlier language presented Project Implicit as an organization that translated implicit-bias science into diversity, inclusion, leadership, and applied organizational practice. The current language distances the organization from prescriptive behavior change and organizational intervention. This does not mean that Project Implicit has abandoned all consulting or educational services. Rather, it means that the organization has narrowed the public rationale for those services. It no longer presents itself as directly prescribing organizational change, but as providing research-based education about judgment and decision-making.
That retreat is important, but it is incomplete. Even the current mission statement continues to claim the authority of “research-based” education and the translation of “findings from cognitive science.” Those phrases preserve the impression that Project Implicit is communicating settled scientific knowledge. But the central scientific problem remains unresolved. The issue is not whether racial disparities, prejudice, or discrimination exist. They plainly do. The issue is whether IAT scores validly measure implicit prejudice at the individual level, and whether individualized feedback about hidden racial bias is scientifically justified.
The evidence does not support that stronger interpretation. IAT scores have limited validity, weak relations with behavior, and substantial ambiguity in what they measure (Schimmack, 2021). They are influenced by task-specific processes, cultural associations, and systematic sources of measurement error. In the case of the race IAT, the color-valence confound raises the additional possibility that scores partly reflect general associations with black and white rather than racial attitudes themselves. These limitations are not minor qualifications. They go to the construct validity of the measure and to the ethical defensibility of giving people individualized feedback about hidden racial bias.
Ethics
The administration of psychological tests to assess individuals with clinical relevance is regulated by professional bodies such as the American Psychological Association. However, these strict ethical rules do not apply to test that are administered for other purposes. Anybody can host a website and give people scores on some test.
Millions of people have taken tests like astrological birth chart generators or the “What kind of pizza are you? test (Pizza Test). However, as academics, Brian Nosek and Project Implicit are required to have ethical approval for the administration of IATs, especially because they are using the data for research purposes. Currently, the IRB of the University of Virginia is responsible for the ethical oversight of Project Implicit’s activities.
The IRB protocol obtained from Brian Nosek — the only document he could find, dated 2006 — confirms that the ethical oversight of Project Implicit has not kept pace with the scientific evidence.
The 2006 protocol acknowledges that participants may be “surprised” and “concerned” by their results, and promises debriefing that contextualizes scores as having “no direct implications for individual scores.” But it makes no mention of the limited reliability of IAT scores, the color-valence confound, the absence of construct validity evidence, or the specific risks to African American participants of being told they harbor hidden pro-White bias.
A protocol written in 2006, before the major validity critiques were published, and apparently never formally updated, cannot provide adequate ethical oversight for a research enterprise that has since accumulated overwhelming evidence of the instrument’s limitations. The fact that Nosek’s response to a direct request for the current IRB protocol was to send a 20-year-old document is itself an answer.
UVA seems to treat this project like any other research project, but Project Implicit research is different because it gives people feedback about potential hidden biases. The key claim is that they measure processes that are not directly accessible to introspection. This is also used to explain why people may receive feedback that is inconsistent with their self-perceptions — the supposed reason being that the test revealed something true about them that is not accessible to conscious awareness, much like a psychoanalyst claiming to recover a forgotten or repressed memory. These claims are controversial because they are difficult to verify, and the epistemic structure is problematic: participants cannot dispute the feedback on the basis of their own experience because the whole point is that the bias is hidden from them. The danger is that discrepancies between IAT scores and self-perceptions are more likely to reflect measurement error in the IAT than truly hidden biases — a conclusion supported by published psychometric research (Schimmack, 2021). As a result, a substantial proportion of participants will receive false feedback about racial attitudes they do not hold and people are not given proper debriefing that the most likely reason for surprising results is measurement error.
Implicit Biases of Project Implicit
Given the seriousness of providing people with feedback about hidden biases on topics like prejudice, depression, and suicide, one might expect that Project Implicit has carefully evaluated the psychometric properties of IATs — that is, assessed the accuracy of IAT scores. However, this is not the case. None of the three founding members has training in psychometrics or demonstrated understanding of modern test theory, as evidenced by their failure to apply basic psychometric concepts such as discriminant validity, convergent validity with other implicit measures, or the fundamental constraint that validity cannot exceed reliability (Schimmack, 2021).
Most of the discussion of measurement error in the IAT literature has focused on random measurement error and situational influences on IAT scores. This limited focus ignores that IAT scores can also be influenced by systematic measurement error. Random error averages out across repeated administrations; systematic error does not. If IAT scores are systematically influenced by factors such as cognitive ability or task-switching rather than hidden bias, repeated testing will not produce valid feedback about hidden biases. Neglect of systematic measurement error is common in psychology, but the ethical stakes are considerably higher when such error invalidates personal feedback about sensitive topics like racial prejudice, depression, or suicidal ideation.
The finding that the average white, Asian, or non-white Hispanic American finds it easier to associate white with good and black with bad rather than the other way around does not mean that they are prejudiced against Black people. It also does not show that they are unbiased. In fact, self-reports show that a substantial number of people are aware of and willing to admit their prejudices.
Brian Nosek, the director of Project Implicit, has ignored scientific criticism of the interpretation of IAT scores made by numerous researchers using independent lines of argument. One is that IAT scores show low convergent validity with other implicit measures — meaning that a person classified as biased on the IAT may not be classified as biased on other implicit measures of the same construct. Yet visitors to the Project Implicit website are offered only the IAT, with no acknowledgment that other implicit measures exist or that they frequently disagree with IAT scores. While the name Project Implicit implies a focus on implicit constructs, the site is really just promoting the Implicit Association Test, even though it lacks validity to measure implicit biases.
Is the race IAT itself racist?
The scoring of the race IAT rests on a simple assumption. If reaction times in favor of white-good, black-bad are faster than black-good and white-bad, a person shows an implicit bias favoring whites. This scoring assumes that a value of zero corresponds to a psychological attitude that is neutral and unbiased. While this assumption is intuitively appealing, it requires scientific evidence. An alternative possibility is that scores on the race IAT are also influenced by factors that have nothing to do with prejudice.
One way to validate the assumption is to see how scores on the IAT are related to actual behaviors. If zero reflects neutrality, people with scores above zero should show prejudice in their behaviors and people with scores below zero should show the opposite pattern, a preference for Black people. However, no compelling evidence has been provided that reaction time differences map directly on amount of bias in behavior.
A critical analysis of the literature failed to provide evidence for the scoring of the race IAT that is used to provide people with feedback about their hidden biases (Blanton, Jacard, Strauts, Mitchell, & Tetlock, 2015) [ironically, Mitchell is also affiliated with UVA that oversees the ethics of Project Implicit]. There has been no response to this criticism and no research to demonstrate that the scoring of the race IAT is valid by Project Implicit since then. There is also no response by Brian Nosek or other founders of Project Implicit to more recent criticisms (Schimmack, 2021).
Moreover, there has been research that has examined why the IAT may have a bias towards white-good/black-bad associations; that is, the test itself is biased. The first problem is that American culture is filled with racial stereotypes that associated Black people with negative attributes. Mere awareness of these stereotypes may influence IAT scores, even if people hold favorable attitudes towards specific Black people or even African Americans as a group (Olson & Fazio, 2004). Even African Americans are aware of these stereotypes and their responses may be influenced by these associations. In support of this argument, responses are more neutral on other tasks that rely on specific stimuli (faces of European and African Americans) rather than abstract associations.
More challenging for the race IAT is the finding that simple color associations explain a substantial portion of the variance in scores on the race IAT (Smith-McLallen, Johnson, Dovidio, & Pearson, 2006). This means the race IAT is not a pure measure of racial biases because it is contaminated by general associations related to the colors white and black. Although this problem was reported 20 years ago, it has been largely ignored by the research community and by Project Implicit. The implication is that African Americans who like white cars and white clothing may receive feedback that they have a hidden bias against African Americans.
Durgin, Diop, Lewis-Owona, and Eaton (in press) replicated and substantially extended Smith-McLallen et al.’s findings across six experiments. They showed that the correlation between color IAT scores and race IAT scores is of similar magnitude to the test-retest correlation of the race IAT itself, suggesting that the two instruments are measuring largely the same underlying construct. Critically, the shared variance between the color and race IATs was not explained by explicit racial bias but by metaphoric alignments of black and white — the deep cultural association of darkness with evil present across racial groups. Even Black participants showed similar metaphoric color alignments to White participants, and a blue-gray color IAT showed no correlation with the race IAT, confirming the effect is specific to black-white alignments rather than a general method artifact.
These results undermine the validity of race IAT scores, especially for African Americans. This matters because the validity of test scores must be assessed within populations, not just in aggregate. However, IAT validation studies have relied exclusively on White or mixed samples, meaning the test has never been properly validated for African Americans. Durgin et al.’s findings suggest that race IAT scores are even less valid for African Americans than for European Americans, as the metaphoric color bias and in-group effects pull in opposing directions, making individual scores particularly difficult to interpret.
Good Intentions and Bad Behavior
Racists often accuse social psychologists of a left-leaning, liberal bias. However, racial equality is enshrined in the 13th, 14th, and 15th Amendments to the Constitution of the United States, passed after the Northern States won the Civil War against the Confederate States that sought to maintain slavery. Working towards Martin Luther King’s dream of actual racial equality is therefore aligned with the moral and political ideals of the United States.
Project Implicit was founded on the idea that many Americans embrace Martin Luther King’s dream but often act in violation of egalitarian principles — sometimes due to limitations in their ability to control their behavior, and sometimes because they are not even aware that their actions are influenced by race. The founding vision of Project Implicit was that a five-minute reaction time task could help people become aware of their biases, and that this awareness would be a first step toward changing their behavior.
The problem is that early on, research findings suggested that the race IAT could not deliver on this promise. However, well-known motivated biases made it impossible for Nosek, Banaji, and Greenwald to acknowledge their own biases and temper their enthusiasm about IATs as “windows into people’s unconscious” (Banaji & Greenwald, 2013). Instead, they continued to promote the test, generated substantial revenues for Project Implicit, and aggressively promoted the concept of implicit biases to a broad public audience and ignored valid criticism of IATs as measures of implicit biases.
At this point, the dream of Martin Luther King and the dream of Nosek, Banaji, and Greenwald diverged. Project Implicit promoted a research program and a task that did not increase awareness of bias and did not reduce racism. In fact, the recent surge in open, old-fashioned racism may partly reflect a backlash against DEI programs and implicit bias training. Some people did not resent feedback that they were racist — they resented the implication that racism is bad and that they need to change. These people are now fighting back against DEI programs because they wish to maintain the racial hierarchy established during slavery and perpetuated through the Jim Crow laws of former Confederate states.
Project Implicit was built on a false understanding of racism in the United States, an invalid measure of racial bias, and a failure to connect laboratory findings to actual discriminatory behavior. These problems might have been recognized sooner had Project Implicit — which derived most of its revenues from the use of the race IAT in DEI training — consulted with African American communities or scholars. There is little public evidence that their work on racial issues involved meaningful engagement with the actual targets of racial discrimination.
Giving False Feedback to African Americans
It seems that Brian Nosek trusted the validity of the race IAT even when self-reports of African Americans suggested otherwise (Jost, Banaji, & Nosek, 2004). Millions of people have taken the race IAT on the Project Implicit website and also reported their consciously accessible preferences. Many of them were African Americans and research articles show their results at the aggregate level.
A robust finding based on hundreds of thousands of scores shows a striking dissociation in African Americans’ racial attitudes: on explicit self-report measures, African Americans show strong ingroup favoritism — clearly preferring their own group — yet on the race IAT they score close to zero, showing neither consistent preference for Black nor for White (Nosek et al., 2007; Jost et al., 2004).
This dissociation has two possible interpretations. Either African Americans hold two genuinely different attitudes — one conscious and pro-Black, one unconscious and neutral or pro-White — or they hold one attitude, the explicit measure captures it accurately, and the IAT is biased for this group in ways that suppress the ingroup preference that is clearly present in self-reports. The second interpretation is strongly supported by the documented color-valence confound in the race IAT, the near-zero mean being equally consistent with cultural contamination of the measure, and the fundamental psychometric principle that validity cannot exceed reliability.
Nevertheless, Nosek, Banaji, and Greenwald — three non-African American scholars with no documented engagement with African American communities or scholars — chose the most psychologically and politically loaded interpretation available: that many African Americans harbor a hidden pro-White bias rooted in system justification, a motivated tendency to endorse the existing social order even when that order places them at the bottom of the racial hierarchy.
This is a remarkable claim. Translated out of theoretical language, it asserts that the race IAT reveals that many African Americans are unconsciously motivated to maintain a social system that affords them fewer rights, lower status, and less economic opportunity than White Americans. The claim is made on the basis of a psychometrically compromised instrument, without consulting African American communities or scholars, and in direct contradiction of the most obvious behavioral evidence available. African Americans vote overwhelmingly Democratic — approximately 80% overall and 90% among women — consistently supporting the party associated with anti-racism policies and government intervention to address racial inequality. This is not the behavior of a group that unconsciously endorses the racial status quo. More broadly, African Americans have actively resisted racial hierarchy throughout their entire history in the United States, from the abolitionist movement and Reconstruction to the civil rights movement and beyond. System justification theory, as applied to African Americans through the race IAT, mistakes the cognitive fingerprints of living under racism for psychological endorsement of it.
Although this claim was made in the most highly cited article in the journal Political Psychology (1,277 citations in Web of Science), it has received little critical attention outside the academic literature. Black activists and scholars working on racism have largely ignored this work rather than directly challenging it — not because they accept it, but because Project Implicit’s research program is so disconnected from the empirical traditions and practical concerns that dominate Black psychology and anti-racism activism. This neglect further underscores that Project Implicit operates largely in isolation from broader anti-racism efforts in the United States. African American scholars from W.E.B. Du Bois onward have had good reasons to be skeptical of psychological instruments developed by White researchers to make claims about the inner lives of Black Americans — the history of IQ testing used to pathologize Black communities is instructive. Project Implicit repeated this pattern without appearing to recognize it. The fundamental problem is that the focus of Project Implicit is the measure, not the construct of racial bias. An organization genuinely committed to understanding and reducing racism would follow the evidence wherever it leads, including away from its flagship instrument. Project Implicit has done the opposite.
It is particularly troubling that this interpretation of African Americans’ scores was made by prominent members of Project Implicit, including Nosek himself. If the system justification interpretation is wrong — and the psychometric evidence strongly suggests it is — then African Americans who receive pro-White feedback on the race IAT are being told something false and potentially harmful about their own psychology. The ethical stakes are highest precisely for this group, yet the 2006 IRB protocol makes no mention of the specific risks to African American participants, provides no tailored debriefing to address the system justification interpretation, and offers no guidance on how to contextualize a pro-White result for a Black participant who strongly identifies with their own group. This is not a minor oversight. It is the most serious ethical failure in Project Implicit’s research program.
Conclusion: So, What is Project Implicit?
In my opinion, Project Implicit is a research project built around an experimental paradigm. Participants are asked to perform two complementary reaction time tasks, and the outcome is the difference in response times between them. This task is called the Implicit Association Test. Like many experimental paradigms, the IAT gives social psychologists something to do and write articles about. This academic research is inexpensive and not directly connected to real-world problems. It is basic research by academics in the ivory tower, for researchers in other ivory towers.
However, Project Implicit took this experimental paradigm and presented it to the public as a valid measure of hidden biases and unconscious processes, and as a tool capable of assessing those processes at the level of individual people. It provided individuals with feedback about their scores on a publicly accessible website, used the research to support seminars and public speaking engagements about implicit bias, and claimed that this work could address real social problems. This marketing was extremely effective, in part due to Banaji’s affiliation with Harvard, and Project Implicit generated substantial revenues over two decades while ignoring mounting evidence that the IAT is not a valid instrument for studying racism or reducing it.
Largely unrelated to this scientific evidence, the resurgence of open racism in American politics is draining Project Implicit of revenue, and the organization appears to be running out of money. This would be a serious loss if Project Implicit had made genuine progress in the fight against racism. But it did not. Instead, it deflected attention from real problems and drained resources — financial, institutional, and intellectual — from more effective anti-racism efforts. The projected demise of Project Implicit is therefore a blessing in disguise.
Unfortunately, the real problem of racism remains. Many Americans are unwilling to abandon their racial prejudices and to treat all people as equal under the law. Martin Luther King’s dream remains elusive — not because we lacked a reaction time task to measure hidden bias, but because we lacked the collective will to confront the bias that was never hidden at all.
References
Axt, J. R., Connor, P., Hoogeveen, S., Clark, C. J., Vianello, M., Lahey, J. N., Hahn, A., To, J., Petty, R. E., Costello, T. H., Mitchell, G., Tetlock, P. E., & Uhlmann, E. L. (in press). On the relationship between indirect measures of Black vs. White racial attitudes and discriminatory outcomes: An adversarial collaboration using a sample of White Americans. Journal of Personality and Social Psychology.
Banaji, M. R., & Greenwald, A. G. (2013). Blindspot: Hidden biases of good people. New York: Delacorte Press.
Blanton, H., & Jaccard, J. (2006). Arbitrary metrics in psychology. American Psychologist, 61(1), 27–41.
Blanton, H., Jaccard, J., Strauts, E., Mitchell, G., & Tetlock, P. E. (2015). Toward a meaningful metric of implicit prejudice. Journal of Applied Psychology, 100(5), 1468–1481.
Durgin, F. H., Diop, S. M., Lewis-Owona, J., & Eaton, O. (in press). A downside of conceptual metaphor: Metaphoric alignments of black and white. Manuscript submitted for publication.
Greenwald, A. G., McGhee, D. E., & Schwartz, J. L. K. (1998). Measuring individual differences in implicit cognition: The Implicit Association Test. Journal of Personality and Social Psychology, 74(6), 1464–1480.
Greenwald, A. G., Nosek, B. A., & Banaji, M. R. (2003). Understanding and using the Implicit Association Test: I. An improved scoring algorithm. Journal of Personality and Social Psychology, 85(2), 197–216.
Hahn, A., & Gawronski, B. (2019). Facing one’s implicit biases: From awareness to acknowledgment. Journal of Personality and Social Psychology, 116(5), 769–794.
Jost, J. T., Banaji, M. R., & Nosek, B. A. (2004). A decade of system justification theory: Accumulated evidence of conscious and unconscious bolstering of the status quo. Political Psychology, 25(6), 881–919.
Karpinski, A., & Hilton, J. L. (2001). Attitudes and the Implicit Association Test. Journal of Personality and Social Psychology, 81(5), 774–788.
Kurdi, B., Seitchik, A. E., Axt, J. R., Carroll, T. J., Karapetyan, A., Kaushik, N., … & Greenwald, A. G. (2019). Relationship between the Implicit Association Test and intergroup behavior: A meta-analysis. American Psychologist, 74(5), 569–586.
McFarland, S. G., & Crouch, Z. (2002). A cognitive skill confound on the Implicit Association Test. Social Cognition, 20(6), 483–510.
Meier, B. P., Robinson, M. D., & Clore, G. L. (2004). Why good guys wear white: Automatic inferences about stimulus valence based on brightness. Psychological Science, 15(2), 82–87.
Meier, B. P., Fetterman, A. K., & Robinson, M. D. (2015). The brightness of your smile: The solar hypothesis of the affect-brightness link. In Handbook of embodied cognition and sport psychology. MIT Press.
Nosek, B. A., Banaji, M. R., & Greenwald, A. G. (2002). Harvesting implicit group attitudes and beliefs from a demonstration website. Group Dynamics: Theory, Research, and Practice, 6(1), 101–115.
Nosek, B. A., Smyth, F. L., Hansen, J. J., Devos, T., Lindner, N. M., Ranganath, K. A., … & Banaji, M. R. (2007). Pervasiveness and correlates of implicit attitudes and stereotypes. European Review of Social Psychology, 18(1), 36–88.
Olson, M. A., & Fazio, R. H. (2004). Reducing the influence of extrapersonal associations on the Implicit Association Test: Personalizing the IAT. Journal of Personality and Social Psychology, 86(5), 653–667.
Oswald, F. L., Mitchell, G., Blanton, H., Jaccard, J., & Tetlock, P. E. (2013). Predicting ethnic and racial discrimination: A meta-analysis of IAT criterion studies. Journal of Personality and Social Psychology, 105(2), 171–192.
Oswald, F. L., Mitchell, G., Blanton, H., Jaccard, J., & Tetlock, P. E. (2015). Using the IAT to predict ethnic and racial discrimination: Small effect sizes of unknown societal significance. Journal of Personality and Social Psychology, 108(4), 562–571.
Schimmack, U. (2021). The Implicit Association Test: A method in search of a construct. Perspectives on Psychological Science, 16(2), 396–414.
Smith-McLallen, A., Johnson, B. T., Dovidio, J. F., & Pearson, A. R. (2006). Black and White: The role of color bias in implicit race bias. Social Cognition, 24(1), 46–73.
Worden, R. E., Najdowski, C. J., McLean, S. J., Worden, K. M., Corsaro, N., Cochran, H., & Engel, R. S. (2024). Implicit bias training for police: Evaluating impacts on enforcement disparities. Law and Human Behavior, 48(5–6), 338–355.
This is a preprint (not yet submitted to a journal) of a manuscript that examines the validity of the race IAT as a measure of in-group and out-group attitudes for African and White Americans. We show that research on intergroup relationships and attitudes benefits from insights (insights by means of being inside the experience) by African Americans that are often ignored by White psychologists. Data and Syntax are here (https://osf.io/rvfz8/)
The Race Implicit Association Test is Biased: Most African Americans Have Positive Attitudes Towards Their In-Group
Ulrich Schimmack University of Toronto Mississauga
Explicit ratings of attitudes show a preference for the in-group for African Americans and White participants. However, the average score of African Americans on the race Implicit Association Test is close to zero. This finding has been interpreted as evidence that many African Americans have unconsciously internalized negative attitudes towards their group. We conducted a multi-method study of this hypothesis with various implicit measures (Single-Target IAT, Evaluative Priming, Affective Misattribution Procedure) that distinguish between in-group and out-group attitudes. Our main finding is that African Americans have positive attitudes towards their in-group on a latent factor that reflects the valid variance across measures. In addition, the race IAT scores of African Americans are unrelated to in-group and out-group attitudes. Moreover, White American’s race IAT scores are biased and exaggerate in-group preferences. These findings are discussed in terms of the unique aspects of the race IAT that may activate cultural stereotypes. The results have ethical implications for the practice of providing individuals with feedback about their unconscious biases with an invalid measure. It is harmful to African Americans to suggest that they unconsciously dislike African Americans and to exaggerate prejudice of White Americans. Ongoing discrimination may be better explained by explicit prejudice of a minority of White Americans than pervasive, uncontrollable implicit biases of most White Americans.
Introduction
With 1,277 citations in WebOfScience, Jost, Banaji, and Nosek’s (2004) article “A Decade of System Justification Theory: Accumulated Evidence of Conscious and Unconscious Bolstering of the Status Quo” is easily the most cited article in the journal Political Psychology. The second most cited article has less than half the number of citations (523 citations). The abstract of this influential article states the authors’ main thesis clearly and succinctly. They postulate a general motive to support the existing social order. This motive contributes to internalization of inferiority of disadvantaged groups. Most important for this article is the claim that this internalization of inferiority is “observed most readily at an implicit, nonconscious level of awareness” (p. 881).
The theory is broadly applied to a wide range of stigmatized groups and its validity has to be evaluated for each group individually. Our focus is on the African American community. Jost et al. (2004) assume that system justification theory is applicable to African Americans because they show different evaluations of their in-group on explicit measures and on the Implicit Association Test (IAT; Greenwald, McGhee, & Schwartz, 1998). On explicit measures, like the feeling thermometer, African Americans show higher in-group favoritism than White Americans (standardized mean differences d = .8 vs. .6). However, IAT scores show greater in-group favoritism for White Americans than for African Americans (d = .9 vs. 0). IAT scores close to zero for African Americans have been interpreted as evidence that “sizable proportions of members of disadvantaged groups – often 40% to 50% or even more exhibit implicit (or indirect) biases against their own group and in favor of more advantaged groups” (Jost, 2019, p. 277).
This pattern of results is based on large samples and has been replicated in several studies. Thus, we are not questioning the empirical facts. Our concern is that Jost and colleagues misinterpret these results. In the early 2000s, it was common to assume that explicit and implicit group evaluations reflect different constructs (Nosek, Greenwald, & Banaji, 2005). This dual-attitude model allows for different evaluations of the in-group at a conscious and an unconscious level. Evidence for this model rested mostly on the finding that race IAT scores and self-ratings are only weekly correlated, r ~ .2 (Hofmann, Gawronski, Gschwendner, Le, & Schmitt, 2005). However, these studies did not correct for measurement error. After correcting for measurement error, the correlation increases to r = .8 (Schimmack, 2021a). The race IAT also has little incremental predictive validity over explicit measures (Schimmack, 2021b). This new evidence renders it less likely that explicit and implicit attitudes can diverge. In fact, there exists no evidence that attitudes are hidden from consciousness. Thus, there may be an alternative explanation for African Americans’ scores on the race IAT.
White Psychologists’ Theorizing about African Americans
Before we propose an alternative explanation for African Americans’ neutral scores on the race IAT, we would like to make the observation that Jost et al.’s (2004) claims about African Americans follow a long tradition of psychological research on African Americans by mostly White psychologists. Often this research ignores the lived experience of African Americans, which often leads to false claims (cf. Adams, 2010). For example, since the beginning of psychology, White psychologists assumed that African Americans have low self-esteem and proposed several theories for this seemingly obvious fact. However, in 1986 Rosenberg ironically pointed out that “everything stands solidly in support of this conclusion except the facts.” Since then, decades of research have shown that African Americans have the same or even higher self-esteem than White Americans (Twenge & Crocker, 2002). Just like White theorists’ claims about self-esteem, Jost et al.’s claims about African Americans’ unconscious are removed from African Americans’ own understanding of their culture and identity and disconnected from other findings that are in conflict with the theory’s predictions. The only empirical support for the theory is the neutral score of African Americans on the race IAT.
African American’s Resilience in a Culture of Oppression
We are skeptical about the claim that most African-Americans secretly favor the out-group based on the lived experience of the second author. Alicia Howard is an African-American from a predominantly White, small town in Kentucky. She grew up surrounded by a large family and attended a Black church. Her identity was shaped by role-models from this Black in-group and not by some idealized abstract image of the White out-group. Also, contrary to the famous doll-studies from the 1960s, she had White and Black dolls and got excited when a new Black doll came out. Alicia studied classical music at the historically Black college and university Kentucky State University. Even though her admired composers like Rachmaninov were White, she looked up to Black classical musicians like Andre Watts, Kathleen Battle, Leontyne Price, and Jesse Norman as role models. It is of course possible that her experiences are unique and not representative of African-Americans. However, no one in her family or among her Black friends showed signs that they preferred to be White or liked White people more than Black people. In small towns, the lives of Black and White people are also more similar than in big cities. Therefore, the White out-group was not all that different from the Black in-group. Although there are Black individuals who seem to struggle with their Black identity, there are also White people who suffer from White guilt or assume a Black identity for other reasons. Thus, from an African American perspective, system justification theory does not seem to characterize most African Americans’ attitudes to their in-group.
The Race IAT Could Be Biased
We are not the first to note that the race IAT may not be a pure measure of attitudes (Olson & Fazio, 2004). The nature of the task may activate cultural stereotypes that are normally not activated when African Americans interact with each other. As a result, the mean score of African Americans on the race IAT may be shifted towards a pro-White bias because negative cultural stereotypes persist in US American culture. The same influence of cultural stereotypes would also enhance the pro-White bias for White Americans. Thus, an alternative explanation for the greater in-group bias for White Americans than for African Americans on the race IAT is that attitudes and cultural stereotypes act together for White Americans, whereas they act in opposite directions for African Americans.
One way to test this hypothesis is to examine in-group biases with alternative implicit measures that do not activate stereotypes. The most widely used alternative implicit measures are the Affective Misattribution Procedure (AMP; Payne, Cheng, Govorun, & Stewart, 2005) and the evaluative priming task (EPT, Fazio, Jackson, Dunton, & Williams, 2005). Only recently it has been noted that these implicit measures produce different results (Teige-Mocigemba, Becker, Sherman, Reichardt, & Klauer, 2017). A study in the United States, examined the differences between African American and White respondents on three implicit measures (Figure 1, Bar-Anan & Nosek, 2014).
Known-group differences are much more pronounced for the race IAT than the other two implicit tasks. The authors interpret this finding as evidence that the race IAT has higher validity. That is, under the assumption that (mostly) White participants have a strong preference for their in-group, a positive mean is predicted, and the more positive the mean is, the more valid a measure is. However, alternative explanations are possible. One alternative explanation is that only the race IAT activates cultural stereotypes and produces a high pro-White mean as a result. In contrast, the other tasks are better measures of attitudes and the results show that prejudice is much less pronounced than the race IAT suggests. That is, the race IAT is biased because it activates cultural stereotypes that are not automatically activated with other implicit tasks.
Another limitation of the race IAT is that preferences for the in-group and the out-group are confounded. In contrast, the other two tasks can be scored separately to obtain measures of the strength of preferences for the in-group and the out-group. This is particularly helpful to make sense of the neutral score of African Americans on the race IAT. One explanation for a weaker in-group bias is simply that African Americans are less biased against the out-group than White Americans. Thus, a better test of African Americans’ attitudes towards their own group is to examine how positive or negative African American’s responses are to African American stimuli.
In short, published studies reveal that different implicit tasks produce different results and that the race IAT shows stronger pro-White biases than other tasks. However, it has not been systematically explored whether this finding reveals higher or lower validity of the race IAT. We used Bar-Anan and Nosek’s (2014) data to explore this question.
Method
Data
The data are based on a voluntary online sample. The total sample size is large (N = 23,413). However, participants completed only some of the tasks that included implicit measures of political orientation and self-esteem. Table 1 shows the number of African American and White participants for six measures.
Measures
Race IAT. The race IAT is the standard Implicit Association Test, although the specific stimuli that represent the African American group and the White American group were different. However, this does not appear to have influenced responses as seen by similar means for African American and White American participants. The race IAT was scored so that higher values represented a pro-White bias for White participants and a pro-Black bias for Black participants.
Single Target IAT. The single-target IAT (ST-IAT) is a variation of the race IAT. The main difference is that participants only have to classify one racial group along with classifications of positive and negative stimuli. As a result, the ST-IAT reflects only evaluations of one group and provides distinct information about evaluations of the in-group and out-group. It is particularly interesting how Black participants perform on the in-group ST-IAT with Black targets. System justification theory predicts a score close to zero that would reflect an over all neutral attitude and at least 50% of participants who may hold negative views of the in-group.
Evaluative Priming Task. The Evaluative Priming Task (EPT) was developed by Fazio et al. (1995). In a practice block, participants classified words as “good” or “bad.” In the next three blocks, target stimuli were primed with pictures of African American and White Americans. In-group bias was the response time to same-group primes for negative words minus response times to same-group primes for positive words. Out-group bias was the response time to other-group primes for negative words minus response times to other-group primes for positive words.
Affective Misattribution Procedure. The Affective Misattribution was invented by Payne et al. (2005). Pictures of African Americans or White Americans are quickly followed by a Chinese character and a mask. Participants are instructed to rate the Chinese character as more or less pleasant than the average Chinese character. They were instructed not to let the pictures influence their evaluation of the target stimuli. The in-group score was the percentage of more pleasant responses after an in-group picture. The out-group score was the percentage of more pleasant responses after an out-group picture.
Feeling Thermometer. Self-reports of in-group and out-group attitudes were measured with feeling thermometers. Participants rated how warm or cold they feel toward the in-group and the out-group on an 11-point scale ranging from 0 = coldest feelings to 10 = warmest feelings.
For all measures, participants scores were divided by the standard deviation so that means can be interpreted as standardized effect sizes assuming that a mean of zero reflects a neutral attitude, positive scores reflect positive attitudes, and negative scores reflect negative attitudes.
Results
The data were analyzed using structural equation modeling with MPLUS8.2 (Muthen & Muthen (2017), A multi-group model was specified with African Americans and White Americans as separate groups. The model was developed iteratively using the data. Thus, all results are exploratory and require validation in a separate sample. Due to the small number of Black participants, it was not possible to cross-validate the model with half of the sample. Moreover, tests of group differences have low power and a study with a larger sample of African Americans is needed to test equivalence of parameters. Cherry picking of data, models, and references undermines psychological science. To avoid this problem, we also constructed a model that assumes some implicit measures are biased and inflate in-group attitudes of African Americans. To identify the means of the latent in-group and out-group factors, we chose the single-target IAT because it shows the least positive attitudes of African Americans towards their in-group. We then freed other parameters to maximize model fit. We then freed other parameters to maximize model fit. The data, input syntax, and the full outputs have been posted online (https://osf.io/rvfz8/).
Preferred Model
Overall fit of the final model meets standard fit criteria (RMSEA < .06, CFI > .95), CFI (78) = 133.37, RMSEA = .012, 90%CI = .009 to .016, CFI = .981. However, models with low coverage (many missing data) may overestimate model fit. A follow-up study that administers all tasks to all participants should be conducted to provide a stronger test of the model. Nevertheless, the model is parsimonious and there were no modification indices greater than 20. This suggests that there are no major discrepancies between the model and the data.
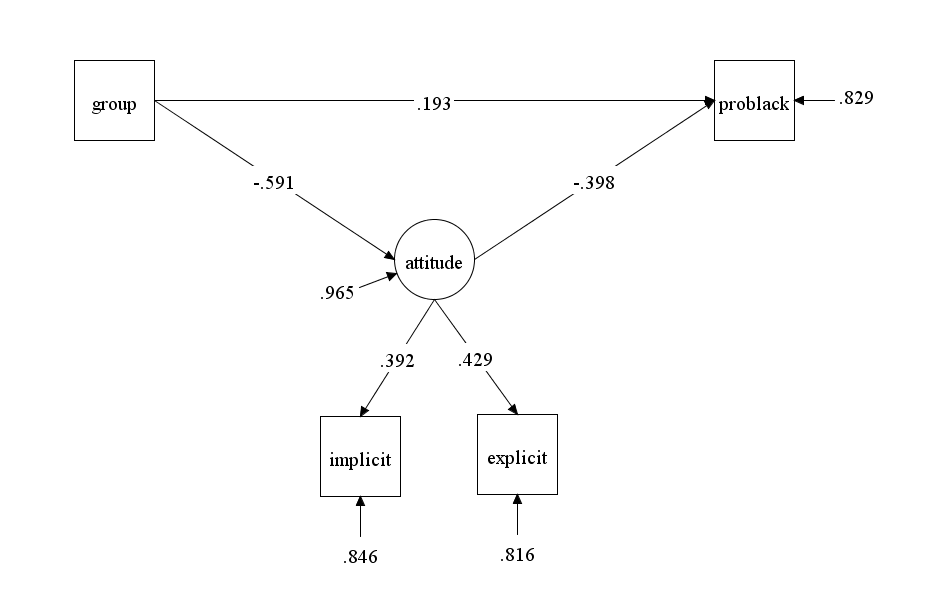
Figure 2 shows a measurement of attitudes towards the in-group and out-group. The key unobserved variables in this model are the attitude towards the in-group factor (ig) and the attitude towards the out-group factor (og). Each construct is measured with four indicators, namely scores on the single-target IAT (satig/satog), scores on the evaluative priming task (epig, epog), scores on the affective misattribution procedure (ampig/ampog), and scores on the explicit feeling thermometer ratings (thermoig/thermoog). For ease of interpretation, Figure 2 shows standardized coefficients that range from -1 to 1.
The first finding is that loadings of the measures on the IG factor (.3-.4) and on the outgroup factor (.4) are modest. They suggest that less than 20% of the variance in a single measure is valid variance. However, the model clearly identified latent factors that show individual differences in attitudes towards in-group and out-group for Black and White Americans. The second noteworthy finding is that loadings for African Americans and White Americans were similar. Thus, the multi-method measurement model was able to identify variation in in-group and out-group attitudes for both groups.
A third finding is that for White participants.54^2 = 29% of the variance in race IAT reflects attitudes towards African Americans (i.e., prejudice). This is a bit higher than previous estimates, which were in the 10% to 20% range (Schimmack, 2021). However, the lower limit of the 95%CI overlapped with this range of possible values, .43^2 = 18%.
Most important is the finding that race IAT scores for African Americans were unrelated to the attitudes towards the in-group and out-group factors. Thus, scores on the race IAT do not appear to be valid measures of African Americans’ attitudes. This finding has important implications for Jost et al.’s (2021) reliance on race IAT scores to make inferences about African Americans’ unconscious attitudes towards their in-group. This interpretation assumed that race IAT scores do provide valid information about African American’s attitudes towards the in-group, but no evidence for this assumption was provided. The present results show 20 years later that this fundamental assumption is wrong. The race-IAT does not provide information about African Americans’ attitudes towards the in-group as reflected in other implicit measures.
An additional interesting finding was that in-group and out-group attitudes were unrelated. This suggests that prejudice does not enhance pro-White attitudes for White participants. It also suggests that Black pride does not have to devalue the White outgroup.
Finally, the model shows that three methods show strong method variance. All three methods measured in-group and out-group attitudes within a single experimental block. The main difference is the single-target IAT that is conducted once with one target (Black) and once with the other target (White). Separating the assessment of in-group and out-group attitudes for the other tasks might reduce the amount of systematic measurement error. However, less systematic measurement error does not seem to translate into more valid variance as the single-target IAT was not more valid than the other measures. The results for the commonly used feeling thermometer are particularly noteworthy. While this measure shows some modest validity, the present results also show that this single-item measure has poor psychometric properties. An important goal for future research is to develop more valid measures of attitudes towards in-groups and out-groups. Until then, researchers should use a multi-method approach.
Figure 3 shows the model for the means. While standardized coefficients are easier to interpret for the measurement model, means are easier to interpret in the units of the measures, which were scaled so that means can be interpreted as Cohen’s d values.
The most important finding is that African Americans’ mean for the in-group factor is positive, d = 1.07, 95%CI = 0.98 to 1.16. Thus, the data provide no support for the claim that most African Americans evaluate their in-group negatively. With a normal distribution centered at 1.07, only 14% of African Americans would have a negative (below 0) attitude towards the in-group. White Americans also show a positive evaluation of the in-group, but to a lesser extent, d = 0.62; 95%CI = 0.58, 0.66. The confidence intervals are tight and clearly do not overlap, and constraining these two coefficients to be equal reduced model fit, chi2(79) = 228.43, Δchi2(1) = 95.06, p = 1.85e-22. Thus, this model suggests that African Americans have an even more positive attitude towards their in-group than White Americans.
As expected, out-group attitudes are less positive than in-group attitudes for both groups. Also expected was the finding that out-group attitudes of African Americans, d = .42, 95%CI , are more favorable than out-group attitudes of White Americans, d = .20, 95%CI. However, even White Americans’ out-group attitudes are on average positive. This finding is in marked contrast to the common finding with the race IAT that most White Americans show a pronounced pro-White bias, which has often been interpreted as evidence of widespread prejudice. However, this interpretation is problematic for two reasons. First, it confounds in-group and out-group attitudes. Prejudice is defined as White American’s attitude towards African Americans. The race IAT is not a direct measure of prejudice because it measures relative preferences. Of course, in-group favoritism alone can lead to discrimination and racial disparities when one group is dominant, but these consequences can occur without actual prejudice against African Americans. The present results suggest that African American also have an in-group bias. Thus, it is important to distinguish between in-group favoritism, which applies to both groups, from prejudice which applies uniquely to White Americans towards African Americans.
The bigger problem for the race IAT is that White Americans’ scores on the race IAT are systematically biased towards a pro-White score, d = .78, whereas African Americans’ scores are only slightly biased towards a pro-Black score, d = -.19. This finding shows that IAT scores provide misleading information about the amount of in-group favoritism. Thus, support for the system justification theory rests on a measurement artifact.
Alternative Model
It is possible that our modeling decisions exaggerated the positivity of African Americans’ in-group attitudes. To address this concern, we tried to find an alternative model that fits the data with the lowest amount of African American’s in-group bias. This alternative model fit the data as well as our preferred model, CFI (77) = 134.24, RMSEA = .013, 90%CI = .009 to .016, CFI = .980. Thus, the data cannot distinguish between these two models. The covariance structure was identical. Thus, we only present the means structure of the model (Figure 4).
The main difference between the models is that African Americans’ attitudes towards the ingroup are less favorable (d = 1.07 vs. d = .54). The discrepancy is explained by the assumptions that African Americans have a positive bias on the feeling-thermometer and by assuming that African Americans’ responses to White targets on the AMP are negatively biased (ampog = -.72). The most important finding is that African Americans’ in-group attitudes remain positive, d = .54, although they are now slightly less favorable than White Americans’ in-group attitudes, d = .62.
Proponents of system justification theory might argue that attitudes towards the in-group have to be evaluated in relative terms. Viewed from this perspective, the results still show relatively more in-group favoritism for White Americans, d = .62 – .20 = .42 than African Americans, d = .54 – .40 = .14. However, out-group attitudes contribute more to this difference, d = .40 = .20 = .20, than in-group differences, d = .62 – .54 = .08. Thus, one reason for the difference in relative preferences is that African Americans attitudes towards Whites are more positive than White Americans’ attitudes towards African Americans. It would be a mistake to interpret this difference in evaluations of the out-group as evidence that African Americans have internalized negative stereotypes about their in-group.
The alternative model does not alter the fact that scores on the race IAT are biased and provide misleading information about in-group and out-group attitudes.
Discussion
After its introduction in 1998, the Implicit Association Test has been quickly accepted as a valid measure of attitudes that individuals are unwilling or unable to report on self-report measures. Mean scores of White Americans were interpreted as evidence that prejudice is much more widespread and severe than self-report measures suggest. Mean scores of African Americans were interpreted as evidence of unconscious self-loathing. The present results suggest that millions of African American and White visitors of the Project Implicit website were given false feedback about their attitudes. For White Americans, the race IAT does appear to reflect individual differences in out-group attitudes (prejudice). However, the scoring of the IAT in terms of deviations from a value of zero is invalid because the mean is biased towards pro-White scores. Even the amount of valid variation is modest and insufficient to provide individualized feedback.
Implications for African American’s In-Group and Out-Group Attitudes
Our investigation started with the surprising suggestions that African Americans are motivated to justify racism and are supposed to have internalized negative stereotypes and attitudes towards their group. This view of African Americans is detached from their history and evidence of high self-esteem among African Americans. The only evidence for this claim was the finding that African Americans do not show a strong in-group preference on the race IAT.
Our results suggest that this finding is due to the low validity of the race IAT as a measure of African Americans’ attitudes. African American’s race IAT scores were unrelated to their in-group attitudes and out-group attitudes as measured by other measures, including the single-target variant of the IAT.
This raises the question in which way the race IAT differs from other measures. We are not the first to suggest that the race IAT activates negative cultural stereotypes (Olson & Fazio, 2004). These stereotypes are known to African Americans and may influence their performance on the IAT, even if African Americans do not endorse these stereotypes and these stereotypes are rarely activated in real life. Thus, the mean close to zero may not reflect the fact that 50% of African Americans have negative attitudes towards their group. Rather, it is possible that the neutral score reflects a balanced influence of positive attitudes and negative stereotypes.
Another noteworthy difference between other implicit tasks and the race IAT is that other tasks rely on pictures of individual members to elicit a valenced response. In contrast, the race IAT focuses on the evaluation of the abstract category “Black.” It is possible that African Americans have more positive attitudes to (pictures of) members of the group than to the concept of being “Black,” which is a fuzzy category at best. Similarly, old people seem to have a negative attitude to the concept of being “old,” but this does not imply that they do not like old people. This has important implications for the predictive validity of the IAT. In everyday life, we encounter individuals and not abstract categories. Thus, even if the race IAT were a valid measure of attitudes towards abstract categories, it would be a weak predictor of actual behaviors.
In sum, the only empirical support for system justification theory was African Americans’ neutral score on the race IAT. We show that the race IAT lacks validity and that African Americans have positive attitudes towards their in-group on all other measures. We also find that they have positive attitudes towards the White outgroup. This has important implications for the assessment of racial attitudes of White participants. If most White participants have negative attitudes towards Black people and these attitudes consistently influence White Americans behaviors, African Americans would experience discrimination from most White Americans. In this case, we would expect negative attitudes towards the out-group. As the data show, this is not the case. This does not mean that discrimination is rare. Rather, it is possible that most acts of discrimination are committed by a relatively small group of White Americans (Campbell & Brauer, 2021).
Implications for White American’s In-Group and Out-Group Attitudes
Banaji and Greenwald’s (2013) popular book was largely responsible for claims that implicit bias is real, widespread, and explains racial discrimination. The book ends with several conclusions. Two conclusions are widely accepted among social psychologists and a majority of US Americans, namely Black disadvantage exists and racial discrimination at least partially contributes to this disadvantage. However, other conclusions were not generally accepted and were not clearly supported by evidence, namely attitudes have both reflective and automatic form, people are often unaware of their automatic attitudes, and implicit bias is pervasive, and implicit racial attitudes contribute to discrimination against Black Americans. The claim that implicit biases are widespread was based entirely on the finding that 75% of US Americans show a clear pro-White bias on the race IAT. The present results suggest that this finding is unique to the race IAT and not found with other implicit measures.
Once more, we are not the first to point out that scoring of the race IAT may have exaggerated the pervasiveness of racial biases among White Americans (Blanton et al., 2006, 2009, 2015; Oswald et al., 2013, 2015). However, so far this criticism has fallen on deaf ears and Project Implicit continues to provide individuals with feedback about their race IAT scores. Textbooks proudly point out that over 20 million people have received this feedback, as if this number says something about the validity of the test (Myers & Twenge, 2019).
When visitors might see a discrepancy between their self-views and the test scores, they are informed that this does not invalidate the test because it measures something that is hidden from self-knowledge. The present results suggest that many visitors of the Project Implicit website were given false feedback about their prejudices because even individuals without any negative attitudes towards African Americans end up with a pro-White bias on the race IAT.
This bias can co-exist with evidence that variation in race IAT scores shows some convergent validity with other explicit and implicit measures of individual differences in attitudes towards African Americans. However, variances and means are two independent statistical constructs, and valid variance does not imply that means are valid. Nosek and Bar-Anan (2014) argued that the race IAT is the most valid measure of attitudes because it shows the largest differences in scores between African Americans and White Americans. However, this argument is only valid, if we assume that random measurement error attenuates the differences on other measures. The present study directly tested this assumption and found no evidence for the assumption. Instead, we found that the larger differences between African Americans and White Americans reflects some systematic mean differences that are unique to the race IAT. As noted earlier, a plausible explanation for this systematic bias is that the race IAT activates stereotypes, whereas other measures are purer measures of attitudes.
We hope that our direct demonstration of bias will finally end the practice of providing visitors of the Project Implicit website with misleading information about the validity of the race IAT and misleading information about individuals’ prejudice. There is simply no evidence that prejudice is hidden from honest self-reflection or that such hidden biases are revealed by the race IAT (Schimmack, 2021).
Implications for Future Research
Although our article focuses on the race IAT, the results also have implications for the use and interpretation of the other measures. One advantage of the other measures is that they provide separate information about in-group and out-group attitudes because they avoid the pitting of one group against the other. However, these measures have other problems. Fast reactions to pictures of African Americans and White Americans reflect only first impressions without context. They are also influenced by affective reactions to other aspects such as gender, age, or attractiveness. Thus, these scores may not reflect other aspects of attitudes that are activated in specific contexts. Moreover, the means will depend heavily on the selection of individual pictures. Thus, a lot more work would need to be done to ensure that the picture sets are representative of the whole group. Finally, our results showed that none of the measures had high loadings on the attitude factors. Thus, a single measure has only modest validity.
Unfortunately, psychologists often do not carefully examine the psychometric properties of their measures. Instead, one measure is often arbitrarily chosen and treated as if it were a perfect measure of a construct. Even worse, a specific measure may be chosen from a set of measures because it showed the desired result (John, Loewenstein, & Prelec, 2012). To avoid these problems, we strongly urge intergroup relationship researchers to use a multi-method approach and to use formal measurement models to analyze their data (Schimmack, 2021). This approach will also produce better estimates of effect sizes that are attenuated by random and systematic measurement error.
References
Adams, P. E. (2010). Understanding the Different Realities, Experience, and Use of Self-Esteem Between Black and White Adolescent Girls. Journal of Black Psychology, 36(3), 255–276. https://doi.org/10.1177/0095798410361454
Banaji, M. R., & Greenwald, A. G. (2013). Blindspot: Hidden biases of good people. New York, NY: Delacorte Press.
Bar-Anan, Y., & Nosek, B. A. (2014). A comparative investigation of seven indirect attitude measures. Behavior Research Methods, 46(3), 668–688. https://doi.org/10.3758/s13428-013-0410-6
Blanton, H., Jaccard, J., Gonzales, P. M., & Christie, C. (2006). Decoding the implicit association test: Implications for criterion prediction. Journal of Experimental Social Psychology, 42(2), 192–212. https://doi.org/10.1016/j.jesp.2005.07.003
Blanton, H., Jaccard, J., Klick, J., Mellers, B., Mitchell, G., & Tetlock, P. E. (2009). Strong claims and weak evidence: Reassessing the predictive validity of the IAT. Journal of Applied Psychology, 94(3), 567–582.
Blanton, H., Jaccard, J., Strauts, E., Mitchell, G., & Tetlock, P. E. (2015). Toward a meaningful metric of implicit prejudice. Journal of Applied Psychology, 100(5), 1468–1481. https://doi.org/10.1037/a0038379
Campbell, M. R., & Brauer, M. (2021). Is discrimination widespread? Testing assumptions about bias on a university campus. Journal of Experimental Psychology: General, 150(4), 756–777. https://doi.org/10.1037/xge0000983
Fazio, R. H., Jackson, J. R., Dunton, B. C., & Williams, C. J. (1995). Variability in automatic activation as an unobtrusive measure of racial attitudes: A bona fide pipeline? Journal of Personality and Social Psychology, 69(6), 1013–1027. https://doi.org/10.1037/0022-3514.69.6.1013
Greenwald, A. G., McGhee, D. E., & Schwartz, J. L. K. (1998). Measuring individual differences in implicit cognition: The Implicit Association Test. Journal of Personality and Social Psychology, 74, 1464–1480.
John, L. K., Loewenstein, G., & Prelec, D. (2012). Measuring the prevalence of questionable research practices with incentives for truth telling. Psychological Science, 23(5), 524–532. https://doi.org/10.1177/0956797611430953
Jost, J. T. (2019). A quarter century of system justification theory: Questions, answers, criticisms, and societal applications. British Journal of Social Psychology, 58(2), 263–314. https://doi.org/10.1111/bjso.12297
Jost, J. T., Banaji, M. R., & Nosek, B. A. (2004). A Decade of System Justification Theory: Accumulated Evidence of Conscious and Unconscious Bolstering of the Status Quo. Political Psychology, 25(6), 881–919. https://doi.org/10.1111/j.1467-9221.2004.00402.x
Hofmann, W., Gawronski, B., Geschwendner, T., Le, H., & Schmitt, M. (2005). A meta-analysis on the correlation between the Implicit Association Test and explicit self-report measures. Personality and Social Psychology Bulletin, 31, 1369–1385. doi:10.1177/0146167205275613
Muthén, L.K. and Muthén, B.O. (1998-2017). Mplus User’s Guide. Eighth Edition. Los Angeles, CA: Muthén & Muthén
Myers, D. & Twenge, J. (2019). Social psychology (13th edition). McGraw Hill.
Nosek, B. A., Greenwald, A. G., & Banaji, M. R. (2005). Understanding and Using the Implicit Association Test: II. Method Variables and Construct Validity. Personality and Social Psychology Bulletin, 31(2), 166–180. https://doi.org/10.1177/0146167204271418
Olson, M. A., & Fazio, R. H. (2004). Reducing the Influence of Extrapersonal Associations on the Implicit Association Test: Personalizing the IAT. Journal of Personality and Social Psychology, 86(5), 653–667. https://doi.org/10.1037/0022-3514.86.5.653
Oswald, F. L., Mitchell, G., Blanton, H., Jaccard, J., & Tetlock, P. E. (2013). Predicting ethnic and racial discrimination: A meta-analysis of IAT criterion studies. Journal of Personality and Social Psychology, 105(2), 171–192. https://doi.org/10.1037/a0032734
Oswald, F. L., Mitchell, G., Blanton, H., Jaccard, J., & Tetlock, P. E. (2015). Using the IAT to predict ethnic and racial discrimination: Small effect sizes of unknown societal significance. Journal of Personality and Social Psychology, 108(4), 562–571. https://doi.org/10.1037/pspa0000023
Payne, B. K., Cheng, C. M., Govorun, O., & Stewart, B. D. (2005). An inkblot for attitudes: Affect misattribution as implicit measurement. Journal of Personality and Social Psychology, 89(3), 277–293. https://doi.org/10.1037/0022-3514.89.3.277
Rosenberg, M. (1986). Conceiving the self. Malabar, FL: Robert E. Krieger.
Schimmack, U. (2021a). The Implicit Association Test: A Method in Search of a Construct. Perspectives on Psychological Science, 16(2), 396–414. https://doi.org/10.1177/1745691619863798
Schimmack, U. (2021). Invalid Claims About the Validity of Implicit Association Tests by Prisoners of the Implicit Social-Cognition Paradigm. Perspectives on Psychological Science, 16(2), 435–442. https://doi.org/10.1177/1745691621991860
Teige-Mocigemba, S., Becker, M., Sherman, J. W., Reichardt, R., & Christoph Klauer, K. (2017). The affect misattribution procedure: In search of prejudice effects. Experimental Psychology, 64(3), 215–230. https://doi.org/10.1027/1618-3169/a000364
Twenge, J. M., & Crocker, J. (2002). Race and self-esteem: Meta-analyses comparing Whites, Blacks, Hispanics, Asians, and American Indians and comment on Gray-Little and Hafdahl (2000). Psychological Bulletin, 128(3), 371–408. https://doi.org/10.1037/0033-2909.128.3.371
Ten years ago, the foundations of psychological science were shaking by the realization that the standard scientific method of psychological science is faulty. Since then it has become apparent that many classic findings are not replicable and many widely used measures are invalid; especially in social psychology (Schimmack, 2020).
However, it is not uncommon to read articles in 2021 that ignore the low credibility of published results. There are too many of these pseudo-scientific articles, but some articles matter more than others; at last to me. I do care about suicide and like many people my age, I know people who have committed suicide. I was therefore concerned when I saw a review article that examines suicide from a dual-process perspective.
My main concern about this article is that dual-process models in social cognition are based on implicit priming studies with low replicability and implicit measures with low validity (Schimmack, 2021a, 2021b). It is therefore unclear how dual-process models can help us to understand and prevent suicides.
After reading the article, it is clear that the authors make many false statements and present questionable studies that have never been replicated as if they produce a solid body of empirical evidence.
Introduction of the Article
The introduction cites outdated studies that have either not been replicated or produced replication failures.
“Our position is that even these integrative models omit a fundamental and well-established dynamic of the human mind: that complex human behavior is the result of an interplay between relatively automatic and relatively controlled modes of thought (e.g., Sherman et al., 2014). From basic processes of impression formation (e.g., Fiske et al., 1999) to romantic relationships (e.g., McNulty & Olson, 2015) and intergroup relations (e.g., Devine, 1989), dual-process frameworks that incorporate automatic and controlled cognition have provided a more complete understanding of a broad array of social phenomena.”
This is simply not true. For example, there is no evidence that we implicitly love our partners when we consciously hate them or vice versa, and there is no evidence that prejudice occurs outside of awareness.
Automatic cognitions can be characterized as unintentional (i.e., inescapably activated), uncontrollable (i.e., difficult to stop), efficient in operation (i.e., requiring few cognitive resources), and/or unconscious (Bargh, 1994) and are typically captured with implicit measures.
This statement ignores many articles that have criticized the assumption that implicit measures measure implicit constructs. Even the proponent of the most widely used implicit measure have walked back this assumption (Greenwald & Banaji, 2017).
The authors then make the claim that implicit measures of suicide have incremental predictive validity of suicidal behavior.
“For example, automatic associations between the self and death predict suicidal ideation and action beyond traditional explicit (i.e., verbal) responses (Glenn et al., 2017).“
This claim has been made repeatedly by proponents of implicit measures, so I meta-analyzed the small set of studies that tested this prediction (Schimmack, 2021). Some of these studies produced non-significant results and the literature showed evidence that questionable research practices were used to produce significant results. Overall, the evidence is inconclusive. It is therefore incorrect to point to a single study as if there is clear evidence that implicit measures of suicidality are valid.
Further statements are also based on outdated research and a single reference.
“Research on threat has consistently shown that people preferentially process dangers to physical harm by prioritizing attention, response, and recall regarding threats (e.g., Öhman & Mineka, 2001).”
There have been many proposals about stimuli that attract attention, and threatening stimuli are by no means the only attention grabbing stimuli. Sexual stimuli also attract attention and in general arousal rather than valence or threat is a better predictor of attention (Schimmack, 2005).
It is also not clear how threatening stimuli are relevant for suicide which is related to depression rather than anxiety disorders.
The introduction of implicit measures totally disregards the controversy about the validity of implicit measures or the fact that different implicit measures of the same construct show low convergent validity.
“Much has been written about implicit measures (for reviews, see De Houwer et al., 2009; Fazio & Olson, 2003; March et al., 2020; Nosek et al., 2011; Olson & Fazio, 2009), but for the present purposes, it is important to note the consensus that implicit measures index the automatic properties of attitudes.“
More relevant are claims that implicit measures have been successfully used to understand a variety of clinical topics.
The application of a dual-process framework has consequently improved explanation and prediction in a number of areas involving mental health, including addiction (Wiers & Stacy, 2006), anxiety (Teachman et al., 2012), and sexual assault (Widman & Olson, 2013). Much of this work incorporates advances in implicit measurement in clinical domains (Roefs et al., 2011).
The authors then make the common mistake to conflate self-deception and other-deception. The notion of implicit motives that can influence behavior without awareness implies self-deception. An alternative rational for the use of implicit measures is that they are better measures of consciously accessible thoughts and feelings that individuals are hiding from others. Here we do not need to assume a dual-process model. We simply have to assume that self-report measures are easy to fake, whereas implicit measures can reveal the truth because they are difficult to fake. Thus, even incremental predictive validity does not automatically support a dual-process model of suicide. However, this question is only relevant if implicit measures of suicidality show incremental predictive validity, which has not been demonstrated.
Consistent with the idea that such automatic evaluative associations can predict suicidality later, automatic spouse-negative associations predicted increases in suicidal ideation over time across all three studies, even after accounting for their controlled counterparts (McNulty et al., 2019).
Conclusion Section
In the conclusion section, the authors repeat their false claim that implicit measures of suicidality reflect valid variance in implicit suicidality and that they are superior to explicit measures.
“As evidence of their impact on suicidality has accumulated, so has the need for incorporating automatic processes into integrative models that address questions surrounding how and under what circumstances automatic processes impact suicidality, as well as how automatic and controlled processes interact in determining suicide-relevant outcomes.”
“Implicit measures are better-suited to assess constructs that are more affective (Kendrick & Olson, 2012), spontaneous (e.g., Phillips & Olson, 2014), and uncontrollable (e.g., Klauer & Teige-Mocigemba, 2007).“
As recent work has shown (e.g., Creemers et al., 2012; Franck, De Raedt, Dereu, et al., 2007; Franklin et al., 2016; Glashouwer et al., 2010; Glenn et al., 2017; Hussey et al., 2016; McNulty et al., 2019; Nock et al., 2010; Tucker,Wingate, et al., 2018), the psychology of suicidality requires formal consideration of automatic processes, their proper measurement, and how they relate to one another and corresponding controlled processes.
We have articulated a number of hypotheses, several already with empirical support, regarding interactions between automatic and controlled processes in predicting suicidal ideation and lethal acts, as well as their combination into an integrated model.
Then they finally mention the measurement problems of implicit measures.
Research utilizing the model should be mindful of specific challenges. First, although the model answers calls to diversify measurement in suicidality research by incorporating implicit measures, such measures are not without their own problems. Reaction time measures often have problematically low reliabilities, and some include confounds (e.g., Olson et al., 2009). Further, implicit and explicit measures can differ in a number of ways, and structural differences between them can artificially deflate their correspondence (Payne et al., 2008). Researchers should be aware of the strengths and weaknesses of implicit measures.
Evaluation of the Evidence
Here I provide a brief summary of the actual results of studies cited in the review article so that readers can make up their own mind about the relevance and credibility of the evidence.
Creemers, D. H., Scholte, R. H., Engels, R. C., Prinstein, M. J., & Wiers, R. W. (2012). Implicit and explicit self-esteem as concurrent predictors of suicidal ideation, depressive symptoms, and loneliness. Journal of Behavior Therapy and Experimental Psychiatry, 43(1), 638–646
Participants: 95 undergraduate students Implicit Construct / Measure: Implicit self-esteem / Name Latter Task Dependent Variables: depression, loneliness, suicidal ideation Results: No significant direct relationship. Interaction between explicit and implicit self-esteem for suicidal ideation only, b = .28.
Franck, E., De Raedt, R., & De Houwer, J. (2007). Implicit but not explicit self-esteem predicts future depressive symptomatology. Behaviour Research and Therapy, 45(10), 2448–2455.
Participants: 28 clinically depressed patients; 67 not-depressed participants. Implicit Construct / Measure: Implicit self-esteem / Name Latter Task Dependent Variable: change in depression controlling for T1 Result: However, after controlling for initial symptoms of depression, implicit, t(48) = 2.21, p = .03, b = .25, but not explicit self-esteem, t(48) = 1.26, p = .22, b = .17, proved to be a significant predictor for depressive symptomatology at 6 months follow-up.
Franck, E., De Raedt, R., Dereu, M., & Van den Abbeele, D. (2007). Implicit and explicit self- esteem in currently depressed individuals with and without suicidal ideation. Journal of Behavior Therapy and Experimental Psychiatry, 38(1), 75–85.
Participants: Depressed patients with suicidal ideation (N = 15), depressed patients without suicidal ideation (N = 14) and controls (N = 15) Implicit Construct / Measure: Implicit self-esteem / IAT Dependent variable. Group status Contrast analysis revealed that the currently depressed individuals with suicidal ideation showed a significantly higher implicit self-esteem as compared to the currently depressed individuals without suicidal ideation, t(43) = 3.0, p < 0.01. Furthermore, the non-depressed controls showed a significantly higher implicit self-esteem as compared to the currently depressed individuals without suicidal ideation, t(43) = 3.7, p < 0.001. [this finding implies that suicidal depressed patients have HIGHER implicit self-esteem than depressed patients who are not suicidal].
Glashouwer,K.A., de Jong,P. J., Penninx, B.W.,Kerkhof,A. J., vanDyck, R., & Ormel, J. (2010). Do automatic self-associations relate to suicidal ideation? Journal of Psychopathology and Behavioral Assessment, 32(3), 428–437.
Participants: General population (N = 2,837) Implicit Constructs / Measure: Implicit depression, Implicit Anxiety / IAT Dependent variable: Suicidal Ideation, Suicide Attempt Results: simple correlations Depression IAT – Suicidal Ideation, r = .22 Depression IAT – Suicide Attempt, r = .12 Anxiety IAT – Suicide Ideation, r = .18 Anxiety IAT – Suicide Attempt, r = .11 Controlling for Explicit Measures of Depression / Anxiety Depression IAT – Suicidal Ideation, b = ..024, p = .179 Depression IAT – Suicide Attempt, b = .037, p = .061 Anxiety IAT – Suicide Ideation, b = .024, p = .178 Anxiety IAT – Suicide Attempt, r = ..039, p = .046
Glenn, J. J., Werntz, A. J., Slama, S. J., Steinman, S. A., Teachman, B. A., & Nock, M. K. (2017). Suicide and self-injury-related implicit cognition: A large-scale examination and replication. Journal of Abnormal Psychology, 126(2), 199–211.
Participants: Self-selected online sample with high rates of self-harm (> 50%). Ns = 3,115, 3114 Implicit Constructs / Measure: Self-Harm, Death, Suicide / IAT Dependent variables: Group differences (non-suicidal self-injury / control; suicide attempt / control) Results: Non-suicidal self-injury versus control Self-injury IAT, d = .81/.97; Death IAT d = .52/.61, Suicide IAT d = .58/.72 Suicide Attempt versus control Self-injury IAT, d = ..52/.54; Death IAT d = .37/.32, Suicide IAT d = .54/.67 [these results show that self-ratings and IAT scores reflect a common construct; they do not show discriminant validity; no evidence that they measure distinct constructs and they do not show incremental predictive validity]
Hussey, I., Barnes-Holmes, D., & Booth, R. (2016). Individuals with current suicidal ideation demonstrate implicit “fearlessness of death..” Journal of Behavior Therapy and Experimental Psychiatry, 51, 1–9.
Participants: 23 patients with suicidal ideation and 25 controls (university students) Implicit Constructs / Measure: Death attitudes (general / personal) / IRAP Dependent variable: Group difference Results: No main effects were found for either group (p = .08). Critically, however, a three-way interaction effect was found between group, IRAP type, and trial-type, F(3, 37) = 3.88, p = .01. Specifically, the suicidal ideation group produced a moderate “my death-not-negative” bias (M = .29, SD = .41), whereas the normative group produced a weak “my death-negative” bias (M = -.12, SD = .38, p < .01). This differential performance was of a very large effect size (Hedges’ g = 1.02). [This study suggests that evaluations of personal death show stronger relationships than generic death]
McNulty, J. K., Olson, M. A., & Joiner, T. E. (2019). Implicit interpersonal evaluations as a risk factor for suicidality: Automatic spousal attitudes predict changes in the probability of suicidal thoughts. Journal of Personality and Social Psychology, 117(5), 978–997
Participants. Integrative analysis of 399 couples from 3 longitudinal study of marriages. Implicit Construct / Measure: Partner attitudes / evaluative priming task Dependent variable: Change in suicidal thoughts (yes/no) over time Result: (preferred scoring method) without covariates, b = -.69, se = .27, p = .010. with covariate, b = -.64, se = .29, p = .027
Nock, M. K., Park, J. M., Finn, C. T., Deliberto, T. L., Dour, H. J., & Banaji, M. R. (2010). Measuring the suicidal mind: Implicit cognition predicts suicidal behavior. Psychological Science, 21(4), 511–517.
Participants. 157 patients with mental health problems Implicit Construct / Measure: death attitudes / IAT Dependent variable: Prospective Prediction of Suicide Result: controlling for prior attempts / no explicit covariates b = 1.85, SE = 0.94, z = 2.03, p = .042
Tucker, R. P., Wingate, L. R., Burkley, M., & Wells, T. T. (2018). Implicit Association with Suicide as Measured by the Suicide Affect Misattribution Procedure (S-AMP) predicts suicide ideation. Suicide and Life-Threatening Behavior, 48(6), 720–731.
Participants. 138 students oversampled for suicidal ideation Implicit Construct / Measure: suicide attitudes / AMP Dependent variable: Suicidal Ideation Result: simple correlation, r = .24 regression controlling for depression, b = .09, se = .04, p = .028
Taken together the reference show a mix of constructs, measures and outcomes, and p-values cluster just below .05. Not one of these p-values is below .005. Moreover, many studies relied on small convenience samples. The most informative study is the study by Glashouwer et al. that examined incremental predictive validity of a depression IAT in a large, population wide, sample. The result was not significant and the effect size was less than r = .1. Thus, the references do not provide compelling evidence for dual-attitude models of depression.
Conclusion
Social psychology have abused the scientific method for decades. Over the past decade, criticism of their practices has become louder, but many social psychologists ignore this criticism and continue to abuse significance testing and to misrepresent these results as if they provide empirical evidence that can inform understanding of human behavior. This article is just another example of the unwillingness of social psychologists to “clean up their act” (Kahneman, 2012). Readers of this article should be warned that the claims made in this article are not scientific. Fortunately, there is a credible research on depression and suicide outside of social psychology.
The notion of implicit bias has taken root in North America and influential politicians like Hillary Clinton or FBI director James Comey used the idea to understand persistent racism and prejudice in the United States (Greenwald, 2015).
From Anthony Greenwald’s talk (40.21 minutes)
The main idea of implicit bias is that most White Americans have negative associations about Blacks that influence their behaviors without their awareness. This explains why even Americans who hold egalitarian values and do not want to discriminate end up discriminating against Black Americans.
The idea of implicit bias emerged in experimental social psychology in the 1980s. Until then most academic psychologists dismissed Freudian ideas of unconscious processes. However, research in cognitive psychology with computerized tasks suggested that some behaviors may be directly guided by unconscious processes that cannot be controlled by our conscious and may even influence behavior without our awareness (Greenwald, 1992).
Some examples of these unconscious processes are physiological processes (breathing), highly automated behaviors (driving while talking to a friend), and basic cognitive processes (e.g., color perception). These processes differ from cognitive tasks like adding 2 + 3 + 5 or deciding what take out food to order tonight. There is no controversy about this distinction. The controversial and novel suggestion was that prejudice could work like color perception. We automatically notice skin color and our unconscious guides our actions based on this information. Eventually the term implicit bias was coined to refer to automatic prejudice.
To provide evidence for implicit bias, experimental social psychologists adopted experiments from cognitive psychology to study prejudice. For example, one procedure is to present racial stimuli on a computer screen very quickly and immediately replace them with some neutral stimulus to prevent participants from actually seeing the stimulus. This method is called subliminal (below-threshold of awareness) priming.
Some highly cited studies suggested that subliminal priming influences behaviour without awareness (Bargh et al., 1996; Devine, 1989). However, in the past decade it has become apparent that these results are not credible (Schimmack, 2020). The reason is that social psychologists did not use the scientific method properly. Instead of using experiments to examine whether an effect exists, they only looked for evidence that shows an effect. Studies that failed to show the expected effects of subliminal priming were simply not reported. As a result, even incredible subliminal priming studies that reversed the order of cause and effect were successful (Bem, 2011). In the 2010s, some courageous researchers started publish replication failures (Doyen et al., 2012). They were attacked for doing so because it was a well-known secrete among experimental social psychologists that many studies fail, but you were not supposed to tell anybody about it. In short, the evidence that started the implicit revolution (Greenwald & Banaji, 2017) is invalid and casts a shadow over the whole notion of prejudice without awareness.
Measuring Implicit Bias
In the 1990s, experimental psychologists started developing methods to measure individuals’ implicit biases. The most prominent method is the Implicit Association Test (IAT, Greenwald et al., 1998) that has produced a large literature with thousands of studies that used the IAT to measure attitudes towards the self (self-esteem), exercise, political candidates, etc. etc. However, the most important literature with the IAT are studies of implicit bias. In these studies, White Americans tend to show a clear preference for Whites over Black Americans. This preference can also be shown with self-ratings. However, a notable group of participants shows much stronger preferences for Whites with the IAT than in their self-ratings. This finding has been used to claim that some White Americans are more prejudice than their are aware off.
One problem with the IAT and other measures of implicit bias is that they are not very good. That is, an individual’s test score is much more strongly influenced by measurement error than by their implicit bias. One way to demonstrate this is to examine the reliability of IAT scores. A good measure should produce similar results when it is used twice (e.g., two Covid-19 tests should be both positive or negative, not one positive and one negative). Reliability can be assessed by examining the correlation of two IATs. A correlation of r = .5 would imply that there is a 75% chance for somebody to score above average on both tests and a 25% chance to get conflicting results (i.e., above and below average).
Experimental social psychologists rarely examines reliability because most of their studies are cross-sectional ( a single experimental session lasting from 10 minutes to 1 hour). However, a few studies with repeated measurements provide some information. Short intervals are preferable to avoid any real changes in implicit bias. Bar-Anan and Nosek (2014) reported a retest-correlation of r = .4, for tests taken within a few hours. Lai et al. (2016) conducted the largest study with several hundred participants for tests taken within a few days. The retest correlations ranged from .22 to .30. Even two similar, but not identical, race IATs in the same session produce low correlations, r ~ .2 (Cunningham et al., 2001). More extensive psychometric analysis further suggest that some of the variance in implicit bias measures is systematic measurement error that influences one type of measure, but not other measures (Schimmack, 2019). Longitudinal studies over several years further show that the reliable variance in IATs is highly stable over time (Onyeador et al., 2020).
In short, ample evidence suggests that most of the variance in implicit bias measures is measurement error. This has important implications for research with these measures that tries to change implicit bias or use implicit bias measures to predict behaviors. However, experimental social psychologists have ignored these implications when they implicitly assumed that their measures are perfectly valid.
The Numbers do not add up
Some simple math shows the problems for experimental social psychologists to study implicit bias. The main method to study implicit bias is to conduct experiments where participants are randomly assigned to two or more groups. Each group receives a different treatment and then the effects on an implicit bias measure and actual behaviors are observed. For illustrative purposes, I assume that manipulations actually have a moderate effect size of half a standard deviation (d = .5) on implicit bias. However, because only a small proportion of the variance in the implicit bias measures is valid (here the assumption is a generous .5^2 = 25%), the effect that an experimental social psychologist could observe is only .25 standard deviations. That is, measurement error cuts the actual effect size in half. The effect on an actual behavior is even smaller because the link between attitudes and a single behavior is also small, d = .5 * .3 = .15. Thus, even under favorable conditions, experimental social psychologists can only expect to observe small effect sizes.
A good scientist would plan studies to be able to reliably detect these small effect sizes. Cohen (1988) provided guidelines for scientists how to plan sample sizes that make it possible to detect these small effects. A so-called power analysis shows that N = 500 participants are needed to detect an effect size of d = .25 and 1,400 participants are needed to detected an effect size of d = .15 for behavior.
However, experimental social psychologists tend to conduct studies with much smaller sample, often fewer than 100 participants. With N = 100, they would have only a 25% chance to reliably (with a p-value below .05) detect an effect and the observed effect size would be severely inflated because the significant result can only be significant with an inflated effect size estimate. Thus, we would expect many non-significant results in the implicit bias literature. However, we do not see these results because experimental social psychologists did not report their failures.
Implicit Bias Intervention Studies
For 20 years, experimental social psychologists have reported studies that seemed to change implicit bias (Dasgupta & Greenwald, 2001; Kawakami, Dovidio, Moll, Hermsen, Russin, 2000). The most influential article was Dasgupta and Greenwald’s (2001) article with nearly 700 citations. As this article spanned an entire literature, it is worthwhile to take a closer look at it.
There were two studies, but only Study 1 focused on implicit race bias. The sample size was N = 48. These 48 participants were divided into three groups, leaving n = 18 per group. Aside from a control group, one group was shown positive example of Blacks and negative examples of Whites and another group was shown the reverse. To get a significant result for the extreme comparison of the opposing groups, we have a study with 36 participants. To have an 80% chance to get a significant result for this contrast, an observed difference of d = .96 is needed. Taking measurement error into account this requires a change in implicit bias by 2 standard deviations. Otherwise, a non-significant result is likely and the study is risky.
Surprisingly, the authors did find a very strong effect size for their manipulation, d = 1.29. They even found a significant difference with the control group, d = .58.
As shown in Figure 1, Panel A, results revealed that exposure to pro-Black exemplars had a substantial effect on automatic racial associations (or the IAT effect).5 The magnitude of the automatic White preference effect was significantly smaller immediately after exposure to pro-Black exemplars (IAT effect = 78 ms; d = 0.58) compared with nonracial exemplars (IAT effect = 174 ms; d = 1.15), F(1, 31) = 6.79, p = .01; or pro-White exemplars (IAT effect = 176 ms; d = 1.29), F(1, 31) = 5.23, p = .029. IAT effects in control and pro-White conditions were statistically comparable (F < 11)
Dasgupta and Greenwald not only wanted to show an immediate effect. They also wanted to show that this effect can last at least for a short time. Thus, they repeated the measurement a second day. The problem is that they now need to show two significant results, when they have a relatively low chance to show even one. The risk of failure therefore increased considerably, but they were successful again.
Panel B of Figure 1 illustrates the response latency data 24 hr after exemplar exposure. Compared with the control condition, the magnitude of the IAT effect in the pro-Black condition remained significantly diminished 1 day after encountering admired Black and disliked White images (IAT effects = 126 ms vs. 51 ms, respectively; ds = 0.98 vs. 0.38, respectively), F(1, 31) = 4.16, p = .05. Similarly, compared with the pro-White condition, the IAT effect in the pro-Black exemplar condition remained substantially smaller as well (IAT effects = 107 vs. 51 ms, respectively; ds = 1.06 vs. 0.38, respectively), F(1, 31) = 3.67, p = .065.
Nobody cared about p-values that are strictly not significant (p = .05, p = .068), but these days these p-values are considered red flags that may suggest the use of questionable research practices to find significance. Another sign of questionable practices is when multiple tests are all successful because each test produces a new opportunity for failure. Thus, the fact that everything always works in experimental social psychology is a sign of widespread abuse of the scientific method (Sterling, 1959; Schimmack, 2012).
Study 2 did not examine racial bias, but it is relevant because it presents more statistical tests. If they also show the desired results, we have additional evidence that QRPs were used. Study 2 examined prejudice towards old people. Notably, the reported study did not have a control group as in Study 1, thus there is only a comparison of manipulations with favorable old people versus favorable young people. Study 2 also did not bother to examine whether the changes last for a day, or at least there were no results reported if this was examined. Thus, there is only one statistical test and that was significant with p = .03.
As illustrated in Figure 2, exposure to pro-elderly exemplars yielded a substantially smaller automatic age bias effect (IAT effect = 182 ms, d = 1.23) than exposure to pro-young exemplars (IAT effect = 336 ms, d = 1.75), F ( 1 , 24) = 5.13, p = .03.
Over the past decade, meta-scientists have developed new tools to examine the presence of questionable practices even in small sets of studies. One test examines the variability of p-values as a function of sampling error (TIVA). After converting p-values into z-scores, we would expect a variance of 1, but the variance is only 0.05. This outcome has only a probability of 1 out of 180 times to occur by chance. Even if we are conservative and make this 1 out of 100, Dasgupta and Greenwald were extremely lucky to get significant results in all of their critical tests. We can also examine the power of their studies given the reported test statistics. The average observed power is 56%, yet they had 100% successes. This suggests that QRPs were used to inflate the success rate. This test is extremely conservative because mean observed power is also inflated by the use of QRPs. A simple correction is to subtract the inflation (100% – 56% = 44%) from the observed mean power. This yields a corrected replicability index of 56% – 44% = 12%. A replicability index of 21% is obtained when there is actually no effect.
In short, power analyses and bias tests suggest that Dasgupta and Greenwald’s article contains no empirical evidence that simple experimental manipulations can produce lasting changes in implicit bias. Yet, this article suggested to other experimental social psychologists that changing IAT scores is relatively easy and worthwhile. This generated a large literature with hundreds of studies. Next we are going to examine what we can learn from 20 years of research with over 40,000 participants.
A Z-Curve Analysis of Implicit Bias Intervention Studies
Psychologists often use meta-analyses to make sense of a literature. The implicit bias literature is no exception (Forscher et al., 2019; Kurdi et al., 2019). The problem with traditional meta-analyses is that they are uninformative. Their main purpose is to claim that an effect exists and to provide an average effect size estimate that nobody cares about. Take the meta-analysis by Forscher et al. (2019) as an example. After finding as many published and unpublished studies as possible, the results are converted into effect size estimates to end up with the conclusion that
“implicit measures can be changed, but effects are often relatively weak (|ds| < .30).
What do we do with this information. After all, Dasgupta and Greenwald (2001) reported an effect size of d > 1. Does this mean, they had a more powerful manipulation or does this mean their results were inflated by QRPs?
Traditional meta-analysis suffers from two problems. First, unlike medical meta-analysis where manipulations represent a treatment with the same drug, social psychologists use very different manipulations to change implicit bias ranging from living with a Black roommate for a semester to subliminal presentation of stimuli on a computer screen. Not surprisingly there is evidence of heterogeneity, that is, effect sizes vary, making any conclusions about the average effect size meaningless. What we really want to know is which manipulations reliably can produce the largest changes in implicit attitudes.
The next problem of this meta -analysis is that it did not differentiate between IATs. Implicit measures of attitudes towards alcohol or consumer products were treated the same as implicit bias. Thus, the average results may not hold for implicit bias.
The biggest problem is that meta-analysis in psychology do not take publication bias into account. Either they do not even examine it or, as in this case, they find evidence for publication bias, but don’t correct conclusions accordingly.
“we found that procedures that directly or indirectly targeted associations, depleted mental resources, or induced goals all changed implicit measures relative to neutral procedures” (p. 541).
It is not clear whether this conclusion holds after taking publication bias into account. Meta-scientists have developed better tools to examine and correct for the influence of questionable research practices that inflate effect sizes (QRP, John et al., 2012). A simulation study found that z-curve is superior to several alternative methods (Brunner & Schimmack, 2020). Thus, I conducted a z-curve analysis of the literature on implicit bias interventions.
The meta-analysis by Forscher et al. (2019) was very helpful to find studies until 2014. I also looked for newer studies that cited Dasgupta and Greenwald (2001), the seminal study in this field. I did not bother to get data from unpublished studies or dissertations. The reason is that these sources are only included in traditional meta-analysis to give the illusion that all studies were included and that there is no bias. However, original researchers who used QRPs are not going to share their failed studies. Z-curve can correct bias for the published studies and does not require cooperation from original researchers to correct the scientific record.
I found 214 studies with 49,1145 participants (data). Figure 1 shows the z-curve. A z-curve is a histogram of the reported test-statistics converted into z-scores. Each z-score reflects the strength of evidence (effect size over sampling error) against the null-hypothesis in each study. As the direction of the effect is irrelevant, all z-scores are positive.
The first notable finding is that the peak of the distribution is at z = 1.96, which corresponds to a two-sided p-value of .05. The second finding is the sharp drop from the peak to values below 1.96. The third observation is that the peak of the distribution has a density of 1.1, which is much larger than the peak density of a standard normal distribution (~ .4). All of these results together make it clear that non-significant results are missing. To quantify the amount of bias due to the use of QRPs, we can compare the observed discovery rate (the percentage of significant results) with the expected discovery rate based on the z-curve model (the grey curve is the predicted distribution without QRPs). The literature contains 74% significant results, when we would expect only 8% significant results.
Thus, there is strong evidence that QRPs undermine the credibility of this literature. Especially, p-values like those reported by Dasgupta and Greenwald (2001) are often a sign of studies with low power that required QRPs to produce a p-value less than .05 (see values below x-axis, 12% for z-scores 2 to 2.5). However, there is also clear evidence of heterogeneity. Studies with z-scores greater than 4 are expected to replicate with 90% or more (again values below x-axis) and 6 studies are not shown because their z-scores even exceeded the maximum value of 6 on the x-axis. To give a context, particle physicists use a z-score of 5 to claim major discoveries. Thus, a few studies produced credible evidence, while the bulk of studies used QRPs to achieve statistical significance in studies with low power.
There are two remarkable articles in this literature that deserve closer attention (Lai et al., 2014, 2016). Before I examine these two articles in more detail, I also conducted a z-curve analysis of the literature without these two articles to examine the credibility of typical articles in this literature.
The z-curve plot for traditional articles in this literature looks even worse. The expected discovery rate of 7% is just above the discovery rate of 5% that is expected from studies without any effect simply because the alpha criterion of .05 allows for 5% false positive discoveries. Moreover, the 95% confidence interval of the expected replication rate does include 5%, which means we cannot rule out that all of the published studies with significant results are false positives. This is also reflected in the maximum False Discovery Rate, 73%, but the upper limit of the 95% confidence interval includes 100%.
While there may be two or three studies with credible evidence, 154 studies with nearly 20,000 participants have produced no scientific information about implicit bias. In short, like several other areas of research in experimental social psychology, implicit bias research is junk science and the seminal study by Dasgupta and Greenwald is no excpetion.
Exception No 1: Lai et al. (2014)
The IAT is a popular measure of implicit bias in part because the developers of the IAT created an online site where visitors can get feedback on their (invalid) IAT scores, including the race IAT. This website is called Project Implicit. Some also volunteer to be participants in studies with the IAT. This makes it possible to get large samples. Lai et al. (2014) used Project Implicit to conduct 50 studies with 18 different interventions. Each study had several hundred participants, which allows for higher power to get significant results and more precise effect size estimates. The next figure shows the z-curve for these 50 studies.
Visual inspection of the histogram does not show the previous steep cliff around z = 1.96. In addition, the replication rate for significant studies is high and the lower limit of the 95%CI is still 65%. Thus, even if some minor QRPs may have produced a little bump around 1.96, this article provides credible evidence that IAT scores can be changed with some manipulations. However, it also shows that several manipulations produce hardly any effects.
Moreover, it is possible that the little bump around 1.96 is a chance finding. This can be examined by fitting z-curve to all values, including no-significant ones. Now the estimated discovery rate perfectly matches the observed discovery rate, suggesting that no QRPs were used.
In short, a single study with well-powered studies that honestly reported results provided more informative results than a literature with hundreds of underpowered studies that used QRPs to publish significant results. This just shows how powerful real science can be, while at the same time exposing the flaws of the way most experimental social psychologists to this day conduct their research.
Do Successful Changes of IAT scores Reveal Changes in Implicit Bias?
If we think about measures as perfect representations of constructs, any change in a measure implies that we changed the construct. However, Figure 1 showed that we need to distinguish measures and constructs. This brings up a new question. Did Lai et al. successfully change implicit biases or did they merely change IAT scores without changing attitudes.
This question can be difficult to answer. One way to examine this would be to see whether the manipulation also influenced behaviour. In the Figure a change of actual implicit bias would also produce a change in behavior, whereas the direct effect on the measure (red path) would not imply a change in behavior. However, as we saw studies with actual behaviors require even larger samples than used in the Project Implicit studies. So, this information is not available.
This brings us to the second exceptional study, which was also conducted by Lai and colleagues (2016). It is essentially a replication and extension of their first study. Focussing on the successful intervention in Lai et al. (2014), the authors examined whether the immediate effects would persist for a few days. First, the authors successfully replicated the immediate effects. More important, they failed to find significant effects a few days later, despite high power to do so. Even participants who were trained to fake the IAT did not bother to fake the IAT again the second time. Thus, even successful interventions that change IAT scores do not seem to change implicit biases measured with the IAT.
Don’t just trust me. Even Greenwald himself has declared that there are no proven ways to change implicit bias, although he fails to explain how he obtained strong effects in his seminal study.
“Importantly, there are no such situational interventions that have been established to have durable effects on IAT measures (Lai et al., 2016)” (Rae and Greenwald, 2017).
“None of the eight effective interventions produced an effect that persisted after a delay of one or a few days.This lack of persistence was not previously known because more than 90% of prior intervention studies had considered changes only within a single experimental session (Lai et al. 2013).” (Greenwald and Lai, 2020).
In short, 20 years of research that started with strong and persistent effects in Dasgupta and Greenwald’s seminal article has produced no useful information how to change implicit bias, despite hundreds of articles that claimed to change implicit bias successfully.
Where do we go from here?
Based on the famous saying “insanity is doing the same thing over and over again and expecting different results” we have to declare experimental social psychologists insane. For decades they have tried to make a contribution to the understanding of prejudice by bringing White students at White universities into labs run by mostly White professors, expose them to some stimuli and measured prejudice right afterwards. The only things that changed is that social psychologists now do even shorter studies with larger samples over the Internet. Should anybody expect that a brief manipulation can have profound effects? The only people who think this could work are social psychologists who have been deluded by inflated effect sizes in p-hacked studies that even subliminal manipulations can have profound effects on prejudice. Meanwhile, racisms remains a troubling reality in the United States as the summer in 2020 made clear.
It is time to use research funding wisely and not to waste it on experimental social psychology that is more concerned with publications and citations than with affecting real change. Resources need to be invested in longitudinal studies, studies with children, studies at work places with real outcome measures. Right now, this research does not attract funding because researchers who pump out five quick, p-hacked experiments get more publications, funding, and positions than researchers who do one well-designed longitudinal study that may fail to show a statistically significant result. Junk is drowning out good science. Maybe a new administration that actually cares about racial justice will allocate research money more wisely. Meanwhile, experimental social psychologists need to rethink their research practices and wonder what their real priorities are. As a group, they can either continue to do meaningless research or step up. However, they can no longer deceive themselves or others that their past research made a real contribution. Denial is not an answer, unless they want to take a place next to Trump in history. Publishing only studies that work was a big mistake. It is time to own up to it.
References
Onyeador, I. N., Wittlin, N. M., Burke, S. E., Dovidio, J. F., Perry, S. P., Hardeman, R. R., … van Ryn, M. (2020). The Value of Interracial Contact for Reducing Anti-Black Bias Among Non-Black Physicians: A Cognitive Habits and Growth Evaluation (CHANGE) Study Report. Psychological Science, 31(1), 18–30. https://doi.org/10.1177/0956797619879139
Until 2011, social psychologists were able to believe that they were actually doing science. They conducted studies, often rigorous experiments with random assignment, analyzed the data and reported results only when they achieved statistical significance, p < .05. This is how they were trained to do science and most of them believed that this is how science works.
However, in 2011 an article by a well-respected social psychologists changed all this. Daryl Bem published an article that showed time-reversed causal processes. Seemingly, people were able to feel the future (Bem, 2011). This article shock the foundations of social psychology because most social psychologists did not believe in paranormal phenomena. Yet, Bem presented evidence for his crazy claim in 8 out of 9 studies. The only study that did not work was with supraliminal stimuli. The other studies used subliminal stimuli, suggesting that only our unconscious self can feel the future.
Over the past decade it has become apparent that Bem and other social psychologists had misused significance testing. They only paid attention to significant results, p < .05, and ignored non-significant results, p > .05. Selective publishing of significant results means that statistical results no longer distinguished between true and false findings. Everything was significant, even time-reversed implicit priming.
Some areas of social psychology have been hit particularly hard by replication failures. Most prominently, implicit priming research has been called out as a poster child of doubt about social psychological results by Nobel Laureate Kahneman. The basic idea of implicit priming is that stimuli outside of participants’ awareness can influence their behavior. Many implicit priming studies have failed to replicate.
Ten years later, we can examine how social psychologists have responded to the growing evidence that many classic findings were obtained with questionable practices (not reporting the failures) and cannot be replicated. Unfortunately, the response is consistent with psychodynamic theories of ego-defense mechanisms and social psychologists’ own theories of motivated reasoning. For the most part, social psychologists have simply ignored the replication failures in the 2010s and continue to treat old articles as if they provide scientific insights into human behavior. For example, Bargh – a leading figure in the implicit priming world – wrote a whole book about implicit priming that does not mention replication failures and presents questionable research as if they were well-established facts (Schimmack, 2017).
Given the questionable status of implicit priming research, it is not surprising that concerns are also growing about measures that were designed to reflect individual differences in implicit cognitions (Schimmack, 2019). The measures often have low reliability (when you test yourself you get different results each time) and show low convergent validity (one measure of your unconscious feelings towards your spouse doesn’t correlate with another measure of your unconscious feelings towards your spouse). It is therefore suspicious, when researchers consistently find results with these measures because measurement error should make it difficult to get significant results all the time.
Implicit Love
In an article from 2019 (i.e., when the replication crisis in social psychology has been well-established), Hicks and McNulty make the following claims about implicit love; that is feelings that are not reflected in self-reports of affection or marital satisfaction.
Their title is based on a classic article by Bargh and Chartrand.
Readers are not informed that the big claims made by Bargh twenty years ago have failed to be supported by empirical evidence. Especially the claim that stimuli often influence behavior without awareness lacks any credible evidence. It is therefore sad to say that social psychologists have moved on from self-deception (they thought they were doing science, but they did not) to other-deception (spreading false information knowing that credible doubts have been raised about this research). Just like it is time to reclaim humility and honesty in American political life, it is important to demand humility and honesty from American social psychologists, who are dominating social psychology.
The empirical question is whether research on implicit love has produced robust and credible results. One advantage for relationship researchers is that a lot of this research was published after Bem (2011). Thus, researchers could have improved their research practices. This could result in two outcomes. Either relationship researchers reported their results more honestly and did report non-significant results when they emerged, or they increased sample sizes to ensure that small effect sizes could produce statistically significant results.
Hicks and McNulty’s (2019) narrative review makes the following claims about implicit love.
1. The frequency of various sexual behaviors was prospectively associated with automatic partner evaluations assessed with an implicit measure but not with self-reported relationship satisfaction. (Hicks, McNulty, Meltzer, & Olson, 2016).
2. Participants with less responsive partners who felt less connected to their partners during conflict-of-interest situations had more negative automatic partner attitudes at a subsequent assessment but not more negative subjective evaluations (Murray, Holmes, & Pinkus, 2010).
3. Pairing the partner with positive affect from other sources (i.e., positive words and pleasant images) can increase the positivity of automatic partner attitudes relative to a control group.
4. The frequency of orgasm during sex was associated with automatic partner attitudes, whereas sexual frequency was associated only with deliberate reports of relationship satisfaction for participants who believed frequent sex was important for relationship health.
5. More positive automatic partner attitudes have been linked to perceiving fewer problems over time (McNulty, Olson, Meltzer, & Shaffer, 2013).
6. More positive automatic partner attitudes have been linked to self-reporting fewer destructive behaviours (Murray et al., 2015).
7. More positive automatic partner attitudes have been linked to more cooperative relationship behaviors (LeBel & Campbell, 2013)
8. More positive automatic partner attitudes have been linked to displaying attitude-consistent nonverbal communication in conflict discussions (Faure et al., 2018).
9. More positive automatic partner attitudes were associated with a decreased likelihood of dissolution the following year, even after controlling for explicit relationship satisfaction (Lee, Rogge, & Reis, 2010).
10. Newlyweds’ implicit partner evaluations but not explicit satisfaction within the first few months of marriage were more predictive of their satisfaction 4 years later.
11. People with higher motivation to see their relationship in a positive light because of barriers to exiting their relationships (i.e., high levels of relationship investments and poor alternatives) demonstrated a weaker correspondence between their automatic attitudes and their relationship self-reports.
12. People with more negative automatic evaluations are less trusting of their partners when their working memory capacity is limited (Murray et al., 2011).
These claims are followed with the assurance that “these studies provide compelling evidence that automatic partner attitudes do have implications for relationship outcomes” (p. 256).
Should anybody who reads this article or similar claims in the popular media believe them? Have social psychologists improved their methods to produce more credible results over the past decade?
Fortunately, we can answer this question by examining the statistical evidence that was used to support these claims, using the z-curve method. First, all test statistics are converted into z-scores that represent the strength of evidence against the null-hypothesis (i.e., implicit love has no effect or does not exist) in each study. These z-scores are a function of the effect size and the amount of sampling error in a study (signal/noise ratio). Second, the z-scores are plotted as a histogram to show how many of the reported results provide weak or strong evidence against the null-hypothesis. The data are here for full transparency (Implicit.Love.xlsx).
The figure shows the z-curve for the 30 studies that reported usable test results. Most published z-scores are clustered just above the threshold value of 1.96 that corresponds to the .05 criterion to claim a discovery. This clustering is indicative of the use of selecting significant results from a much larger set of analyses that were run and produced non-significant results. The grey curve from z = 0 to 1.96 shows the predicted number of analyses that were not reported. The file drawer ratio implies that for every significant result there were 12 analyses with non-significant results.
Another way to look at the results is to compare the observed discovery rate with the expected discovery rate. The observed discovery rate is simply the percentage of studies that reported a significant result, which is 29 out of 30 or 97%. The estimated discovery rate is the average power of studies to produce a significant result. It is only 8%. This shows that social psychologists still continue to select only successes and do not report or interpret the failures. Moreover, in this small sample of studies, there is considerable uncertainty around the point estimates. The 95%confidence interval for the replication success probability includes 5%, which is not higher than chance. The complementary finding is that the maximum number of false positives is estimated to be 63%, but could be as high as 100%. In other words, the results make it impossible to conclude that even some of these studies produced a credible result.
In short, the entire research on implicit love is bullshit. Ten years ago, social psychologists had the excuse that they did not know better and misused statistics because they were trained the wrong way. This excuse is wearing thin in 2020. They know better, but they continue to report misleading results and write unscientific articles. In psychology, this is called other-deception, in everyday life it is called lying. Don’t trust social psychologists. Doing so is as stupid as believing Donald Trump when he claims that he won the election.
Citation: Schimmack, U. (2021). Invalid Claims About the Validity of Implicit Association Tests by Prisoners of the Implicit Social-Cognition Paradigm. Perspectives on Psychological Science, 16(2), 435–442. https://doi.org/10.1177/1745691621991860
Invalid Claims about the Validity of Implicit Association Tests by Prisoners of the Implicit Social-Cognition Paradigm
Abstract In a prior publication, I used structural equation modeling of multimethod data to examine the construct validity of Implicit Association Tests. The results showed no evidence that IATs measure implicit constructs (e.g., implicit self-esteem, implicit racial bias). This critique of IATs elicited several responses by implicit social-cognition researchers, who tried to defend the validity and usefulness of IATs. I carefully examine these arguments and show that they lack validity. IAT proponents consistently ignore or misrepresent facts that challenge the validity of IATs as measures of individual differences in implicit cognitions. One response suggests that IATs can be useful even if they merely measure the same constructs as self-report measures, but I find no support for the claim that IATs have practically significant incremental predictive validity. In conclusions, IATs are widely used without psychometric evidence of construct or predictive validity.
Keywords implicit attitudes, Implicit Association Test, validity, prejudice, suicide, mental health
Greenwald and colleagues (1998) introduced Implicit Association Tests (IATs) as a new method to measure individual differences in implicit cognitions. Twenty years later, IATs are widely used for this purpose, but their construct validity has not been established. Even its creator is no longer sure what IATs measure. Whereas Banaji and Greenwald (2013) confidently described IATs as “a method that gives the clearest window now available into a region of the mind that is inaccessible to question-asking methods” (p. xiii), they now claim that IATs merely measure “the strengths of associations among concepts” (Cvencek et al., 2020, p. 187). This is akin to saying that an old-fashioned thermometer measures the expansion of mercury: It is true, but it has little to do with thermometers’ purpose of measuring temperature.
Fortunately, we do not need Greenwald or Banaji to define the constructs that IATs are supposed to measure. Twenty years of research with IATs makes it clear what researchers believe they are measuring with IATs. A self-esteem IAT is supposed to measure implicit self-esteem (Greenwald & Farnham, 2000). A race IAT is supposed to measure implicit prejudice (Cunningham et al., 2001), and a suicide IAT is supposed to measure implicit suicidal tendencies that can predict suicidal behaviors above and beyond self-reports (Kurdi et al., 2021). The empirical question is whether IATs are any good at measuring these constructs. I concluded that most IATs are poor measures of their intended constructs (Schimmack, 2021). This conclusion elicited one implicit and two explicit responses.
Implicit Response
The implicit response is to simply ignore criticism and to make invalid claims about the construct validity of IATs (Greenwald & Lai, 2020). For example, a 2020 article coauthored by Nosek, Greenwald, and Banaji (among others) claimed that “available evidence for validity of IAT measures of self-esteem is limited (Bosson et al., 2000; Greenwald & Farnham, 2000), with some of the strongest evidence coming from empirical tests of the balance-congruity principle” (Cvencek et al., 2020, p. 191). This statement is as valid as Donald Trump’s claim that an honest count of votes would make him the winner of the 2020 election. Over the past 2 decades, several articles have concluded that self-esteem IATs lack validity (Buhrmester et al., 2011; Falk et al., 2015; Walker & Schimmack, 2008). It is unscientific to omit these references from a literature review.
The balance-congruity principle is also not a strong test of the claim that the self-esteem IAT is a valid measure of individual differences in implicit self-esteem. In contrast, the lack of convergent validity with informant ratings and even other implicit measures of self-esteem provides strong evidence that self-esteem IATs are invalid (Bosson et al., 2000; Falk et al., 2015). Finally, supporting evidence is surprisingly weak. For example, Greenwald and Farnham’s (2000) highly cited article tested predictive validity of the self-esteem IAT with responses to experimentally manipulated successes and failures (n = 94). They did not even report statistical results. Instead, they suggested that even nonsignificant results should be counted as evidence for the validity of the self-esteem IAT:
Although p values for these two effects straddled the p = .05 level that is often treated as a boundary between noteworthy and ignorable results, any inclination to dismiss these findings should be tempered by noting that these two effects agreed with prediction in both direction and shape. (Greenwald & Farnham, 2000, p. 1032)
Twenty years later, this finding has not been replicated, and psychologists have learned to distrust p values that are marginally significant (Benjamin et al., 2018; Schimmack, 2012, 2020). In conclusion, conflict of interest and motivated biases undermine the objectivity of Greenwald and colleagues in evaluations of IATs’ validity.
Explicit Response 1
Vianello and Bar-Anan (2021) criticized my structural equation models of their data. They also presented a new model that appeared to show incremental predictive validity for implicit racial bias and implicit political orientation. I thought it would be possible to resolve some of the disagreement in a direct and open communication with the authors because the disagreement is about modeling of the same data. I was surprised when the authors declined this offer, given that Bar- Anan coauthored an article that praised the virtues of open scientific communication (Nosek & Bar-Anan, 2012). Readers therefore have to reconcile conflicting viewpoints for themselves. To ensure full transparency, I published syntax, outputs, and a detailed discussion of the different modeling assumptions on OSF at https://osf.io/wsqfb/.
In brief, a comparison of the models shows that mine is more parsimonious and has better fit than their model. Because the model is more parsimonious, better fit cannot be attributed to overfitting of the data. Rather, the model is more consistent with the actual data, which in most sciences is considered a good reason to favor a model. Vianello and Bar-Anan’s model also produced unexplained, surprising results. For example, the race IAT has only a weak positive loading on the IAT method factor, and the political-orientation IAT even has a moderate negative loading. It is not clear how a method can have negative loadings on a method factor, and Vianello and Bar-Anan provided no explanation for this surprising finding.
The two models also produce different results regarding incremental predictive validity (Table 1). My model shows no incremental predictive validity for implicit factors. It is also surprising that Vianello and Bar-Anan found incremental predictive validity for voting behaviors, because the explicit and implicit factors correlated (r) at .9. This high correlation leaves little room for variance in implicit political orientation that is distinct from political orientation measured with self-ratings.
In conclusion, Vianello and Bar-Anan failed to challenge my conclusion that implicit and explicit measures measure mostly the same constructs and that low correlations between explicit and implicit measures reflect measurement error rather than some hidden implicit processes.
Explicit Response 2
The second response (Kurdi et al., 2021) is a confusing 7,000-word article that is short of facts, filled with false claims, and requires more fact-checking than a Trump interview.
False fact 1
The authors begin with the surprising statement that my findings are “not at all incompatible with the way that many social cognition researchers have thought about the construct of (implicit) evaluation” (p. 423). This statement is misleading. For 3 decades, social-cognition researchers have pursued the idea that many social-cognitive processes that guide behavior occur outside of awareness. For example, Nosek et al. (2011) claim “most human cognition occurs outside conscious awareness or conscious control” (p. 152) and go on to claim that IATs “measure something different from self-report” (p. 153). And just last year, Greenwald and Lai (2020) claimed that “in the last 20 years, research on implicit social cognition has established that social judgments and behavior are guided by attitudes and stereotypes of which the actor may lack awareness” (p. 419).
Social psychologists have also been successful in making the term implicit bias a common term in public discussions of social behavior. The second author, Kathy Ratliff, is director of Project Implicit, which “has a mission to develop and deliver methods for investigating and applying phenomena of implicit social cognition, including especially phenomena of implicit bias based on age, race, gender or other factors” (Kurdi et al., 2021, p. 431). It is not clear what this statement means if we do not make a distinction between traditional research on prejudice with self-report measures and the agenda of Project Implicit to study implicit biases with IATs. In addition, all three authors have published recent articles that allude to IATs as measures of implicit cognitions.
In a highly cited American Psychologist article, Kurdi and coauthors (2019) claim “in addition to dozens of studies that have established construct validity . . . investigators have asked to what extent, and under what conditions, individual differences in implicit attitudes, stereotypes, and identity are associated with variation in behavior toward individuals as a function of their social group membership” (p. 570). The second author coauthored an article with the claim that “Black participants’ implicit attitudes reflected no ingroup/ outgroup preference . . . Black participants’ explicit attitudes reflected an ingroup preference” ( Jiang et al., 2019). In 2007, Cunningham wrote that the “distinction between automatic and controlled processes now lies at the heart of several of the most influential models of evaluative processing” (Cunningham & Zelazo, 2007, p. 97). And Cunningham coauthored a review article with the claim that “a variety of tasks have been used to reflect implicit psychopathology associations, with the IAT (Greenwald et al., 1998) used most widely” (Teachman et al., 2019). Finally, many users of IATs assume that they are measuring implicit constructs that are distinct from constructs that are measured with self-ratings. It is therefore a problem for the construct validity of IATs if they lack discriminant validity. At the least, Kurdi et al. fail to explain why anybody should use IATs if they merely measure the same constructs that can be measured with cheaper self-ratings. In short, the question whether IATs and explicit measures reflect the same constructs or different constructs has theoretical and empirical relevance, and lack of discriminant validity is a problem for many theories of implicit cognitions (but see Cunningham & Zelazo, 2007).
False fact 2
A more serious false claim is that I found “high correlations between relatively indirect (automatic) measures of mental content, as indexed by the IAT, and relatively direct (controlled) measures of mental content, as indexed by a variety of self-report scales” (p. 423). Table 2 shows some of the correlations among implicit and explicit measures in Vianello and Bar-Anan’s data. Only one of these correlations meets the standard criterion of a high correlation (i.e., r = .5; Cohen, 1988). The other correlations are small to moderate. These correlations show at best moderate convergent validity and no evidence of discriminant validity (i.e., higher implicit-implicit than implicit-explicit correlations). Similar results have been reported since the first IATs were created (Bosson et al., 2000). For 20 years, IAT researchers have ignored these low correlations and made grand claims about the validity of IATs. Kurdi et al. are doubling down on this misinformation by falsely describing these correlations as high.
False fact 3
The third false claim is that “plenty of evidence in favor of dissociations between direct and indirect measures exists” (p. 428). To support this claim, Kurdi et al. cite a meta-analysis of incremental predictive validity (Kurdi et al., 2019). There are several problems with this claim. First, the meta-analysis corrects only for random measurement error and not systematic measurement error. To the extent that systematic measurement error is present, incremental validity will shrink because explicit and implicit factors are very highly correlated when both sources of error are controlled (Schimmack, 2021). Second, Kurdi et al. fail to mention effect sizes. The meta-analysis suggests that a perfectly reliable IAT would explain about 2% unique variance. However, IATs have only modest reliability. Thus, manifest IAT scores would explain even less unique variance. Finally, even this estimate has to be interpreted with caution because the meta-analysis did not correct for publication bias and included some questionable studies. For example, Phelps et al. (2003) report, among 12 participants, a correlation of .58 between scores on the race IAT and differences in amygdala activation in response to Black and White faces. Assuming 20% valid variance in the IAT scores (Schimmack, 2021), the validation- corrected correlation would be 1.30. In other words, a correlation of .58 is impossible given the low validity of race-IAT scores. It is well known that correlations in functional MRI studies with small samples are not credible (Vul et al., 2009). Moreover, brain activity is not a social behavior. It is therefore unclear why studies like this were included in Kurdi et al.’s (2019) meta-analysis.
Kurdi et al. also used suicides as an important outcome that can be predicted with suicide and death IATs. They cited two articles to support this claim. Fact checking shows that one article reported a statistically significant result (p = .013; Barnes et al., 2017), whereas the other one did not (p > .50; Glenn et al., 2019). I conducted a meta-analysis of all studies that reported incremental predictive validity of suicide or death IATs. The criterion was suicide attempts in the next 3 to 6 months (Table 3). I found eight studies, but six of them came from a single lab (Matthew K. Nock). Nock was also the first one to report a significant result in an extremely underpowered study that included only two suicide attempts (Nock & Banaji, 2007). Five of the eight studies showed a statistically significant result (63%), but the average observed power to achieve significance was only 42%. This discrepancy suggests the presence of publication bias (Schimmack, 2012). Moreover, significant results are all clustered around .05, and none of the p values meets the stricter criterion of .005 that has been suggested by Nosek and others to claim a discovery (Benjamin et al., 2018). Thus, there is no conclusive evidence to suggest that suicide IATs have incremental predictive validity in the prediction of suicides. This is not surprising because most of the studies were underpowered and unlikely to detect small effects. Moreover, effect sizes are bound to be small because the convergent validity between suicide and death IATs is low (r = .21; Chiurliza et al., 2018), suggesting that most of the variance in these IATs is measurement error.
In conclusion, 20 years of research with IATs has produced no credible and replicable evidence that IATs have incremental predictive validity over explicit measures. Even if there is some statistically significant incremental predictive validity, the amount of explained variance may lack practical significance (Kurdi et al., 2019).
False fact 4
Kurdi et al. (2021) object (p. 424) to my claim that “most researchers regard the IAT as a valid measure of enduring attitudes that vary across individuals” (Schimmack, 2021, p. 397). They claim that “the overwhelming theoretical consensus in the community of attitude researchers. . . is that attitudes emerge from an interaction of persons and situations” (p. 425). It is instructive to compare this surprising claim with Cunningham and Zelazo’s (2007) definition of attitudes as “relatively stable ideas about whether something is good or bad” (p. 97). Kurdi and Banaji (2017) wrote that “differences in implicit attitudes . . . may arise because of multiple components, including relatively stable components [emphasis added]” (p. 286). Rae and Greenwald (2017) stated that it is a “widespread assumption . . . that implicit attitudes are characteristics of people, almost certainly more so than a property of situations” (p. 297). Greenwald and Lai (2020) stated that test–retest reliability “places an upper limit on correlational tests of construct validity” (p. 425). This statement makes sense only if we assume that the construct to be measured is stable over the retest interval. It is also not clear how it would be ethical to provide individuals with feedback about their IAT scores on the Project Implicit website, if IAT scores were merely a product of the specific situation at the moment they are taking the test. Finally, how can the suicide IAT be a useful predictor of suicide if it cannot not measure some stable dispositions related to suicidal behaviors?
In conclusion, Kurdi et al.’s definition of attitudes is inconsistent with the common definition of attitudes as relatively enduring evaluations. That being said, the more important question is whether IATs measure stable attitudes or momentary situational effects. Ironically, some of the best evidence comes from Cunningham. Cunningham et al. (2001) repeatedly measured prejudice four times over a 3-month period with multiple measures, including the race IAT. Cunningham et al. (2001) modeled the data with a single trait factor that explained all of the covariation among different measures of racial attitudes. Thus, Cunningham et al. (2001) provided first evidence that most of the valid variance in race IAT scores is perfectly stable over a 3-month period and that person-by-situation interactions had no effect on racial attitudes. There have been few longitudinal studies with IATs since Cunningham et al.’s (2001) seminal study. However, last year, an article examined stability over a 6-year interval (Onyeador et al., 2020). Racial attitudes of more than 3,000 medical students were measured in the first year of medical school, the fourth year of medical school, and the second year of medical residency. Table 4 shows the correlations for the explicit feeling thermometer and the IAT scores. The first observation is that the Time-1-to-Time-3 correlation for the IAT scores is not smaller than the Time-1-to-Time-2 or the Time-2-to-Time-3 correlations. This pattern shows that a single trait factor can capture the shared variance among the repeated IAT measures. The second observation is that the bold correlations between explicit ratings and IAT scores on the same occasion are only slightly higher than the correlations for different measurement occasions. This finding shows that there is very little occasion-specific variance in racial attitudes. The third observation is that IAT correlations over time are higher than the corresponding FT-IAT correlations over time. This finding points to IAT-specific method variance that is revealed in studies with multiple implicit measures (Cunningham et al., 2001; Schimmack, 2021). These findings extend Cunningham et al.’s (2001) findings to a 6-year period and show that most of the valid variance in race IAT scores is stable over long periods of time.
In conclusion, Kurdi et al.’s claims about person-by-situation effects are not supported by evidence.
Conclusion
Like presidential debates, the commentaries and my response present radically different views of reality. In one world, IATs are valid and useful tools that have led to countless new insights into human behavior. In the other world, IATs are noisy measures that add nothing to the information we already get from cheaper self-reports. Readers not well versed in the literature are likely to be confused rather than informed by these conflicting accounts. Although we may expect such vehement disagreement in politics, we should not expect it among scientists. A common view of scientists is that they are able to resolve disagreement by carefully looking at data and drawing logical conclusions from empirical facts. However, this model of scientists is naive and wrong.
A major source of disagreement among psychologists is that psychology lacks an overarching paradigm; that is, a set of fundamentally shared assumptions and facts. Psychology does not have one paradigm, but many paradigms. The IAT was developed within the implicit social-cognition paradigm that gained influence in the 1990s (Bargh et al., 1996; Greenwald & Banaji, 1995; Nosek et al., 2011). Over the past decade, it has become apparent that the empirical foundations of this paradigm are shaky (Doyen et al., 2012; D. Kahneman quoted in Yong, 2012, Supplemental Material; Schimmack, 2020). It took a long time to see the problems because paradigms are like prisons that make it impossible to see the world from the outside. A key force that prevents researchers within a paradigm from noticing problems is publication bias. Publication bias ensures that studies that are consistent with a paradigm are published, cited, and highlighted in review articles to provide false evidence in support for a paradigm (Greenwald & Lai, 2020; Kurdi et al., 2021).
Over the past decade, it has become apparent how pervasive these biases have been, especially in social psychology (Schimmack, 2020). The responses to my critique of IATs merely confirms how powerful paradigms and conflicts of interest can be. It is therefore necessary to allocate more resources to validation projects by independent researchers. In addition, validation studies should be preregistered and properly powered, and results need to be published whether they show validity or not. Conducting validation studies of widely used measures could be an important role for the emerging field of meta-psychology that is not focused on new discoveries, but rather on evaluating paradigmatic research from an outsider, meta-perspective (Carlsson et al., 2017). Viewed from this perspective, many IATs that are in use lack credible evidence of construct validity.
References *References marked with an asterisk report studies included in the suicide IAT meta-analysis
Banaji, M. R., & Greenwald, A. G. (2013). Blindspot: Hidden biases of good people. Delacorte Press.
Bargh, J. A., Chen, M., & Burrows, L. (1996). Automaticity of social behavior: Direct effects of trait construct and stereotype activation on action. Journal of Personality and Social Psychology, 71(2), 230–244. https://doi.org/ 10.1037/0022-3514.71.2.230
*Barnes, S. M., Bahraini, N. H., Forster, J. E., Stearns-Yoder, K. A., Hostetter, T. A., Smith, G., Nagamoto, H. T., & Nock, M. K. (2017). Moving beyond self-report: Implicit associations about death/ life prospectively predict suicidal behavior among veterans. Suicide and Life-Threatening Behavior, 47, 67–77. https://doi.org/10.1111/sltb.12265
Benjamin, D. J., Berger, J. O., Johannesson, M., Nosek, B. A., Wagenmakers, E.-J., Berk, R., Bollen, K. A., Brembs, B., Brown, L., Camerer, C., Cesarini, D., Chambers, C. D., Clyde, M., Cook, T. D., Boeck, P., De, Dienes, Z., Dreber, A., Easwaran, K., Efferson, C., . . . Johnson, V. E. (2018). Redefine statistical significance. Nature Human Behaviour, 2, 6–10.
Bosson, J. K., Swann, W. B. Jr., & Pennebaker, J. W. (2000). Stalking the perfect measure of implicit self-esteem: The blind men and the elephant revisited? Journal of Personality and Social Psychology, 79, 631–643. https:// doi.org/10.1037/0022-3514.79.4.631
Buhrmester, M. D., Blanton, H., & Swann, W. B., Jr. (2011). Implicit self-esteem: Nature, measurement, and a new way forward. Journal of Personality and Social Psychology, 100(2), 365–385. https://doi.org/10.1037/a0021341
Carlsson, R., Danielsson, H., Heene, M., Ker, Å., Innes, Lakens, D., Schimmack, U., Schönbrodt, F. D., van Assen, M., & Weinstein, Y. Inaugural editorial of Meta-Psychology. Meta- Psychology, 1. https://doi.org/10.15626/MP2017.1001
Chiurliza, B., Hagan, C. R., Rogers, M. L., Podlogar, M. C., Hom, M. A., Stanley, I. H., & Joiner, T. E. (2018). Implicit measures of suicide risk in a military sample. Assessment, 25(5), 667–676. https://doi.org/10.1177/1073191116676363 Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Erlbaum.
Cunningham, W. A., Preacher, K. J., & Banaji, M. R. (2001). Implicit attitude measures: Consistency, stability, and No Evidence for Construct Validity of IAT 441 convergent validity. Psychological Science, 12(2), 163–170 https://doi.org/10.1111/1467-9280.00328
Cunningham, W. A., & Zelazo, P. D. (2007). Attitudes and evaluations: A social cognitive neuroscience perspective. Trends in Cognitive Sciences, 11, 97–104. https:// doi.org/10.1016/j.tics.2006.12.005
Cvencek, D., Meltzoff, A. N., Maddox, C. D., Nosek, B. A., Rudman, L. A., Devos, T., Dunham, Y., Baron, A. S., Steffens, M. C., Lane, K., Horcajo, J., Ashburn Nardo, L., Quinby, A., Srivastava, S. B., Schmidt, K., Aidman, E., Tang, E., Farnham, S., Mellott, D. S., . . . Greenwald, A. G. (2020). Meta-analytic use of balanced identity theory to validate the Implicit Association Test. Personality and Social Psychology Bulletin, 47(2), 185–200. https://doi .org/10.1177/0146167220916631
Doyen, S., Klein, O., Pichon, C. L., & Cleeremans, A. (2012). Behavioral priming: It’s all in the mind, but whose mind? PLOS ONE, 7(1), Article e29081. https://doi.org/10.1371/ journal.pone.0029081
Falk, C. F., Heine, S. J., Takemura, K., Zhang, C. X., & Hsu, C. (2015). Are implicit self-esteem measures valid for assessing individual and cultural differences. Journal of Personality, 83, 56–68. https://doi.org/10.1111/jopy.12082
*Glenn, C. R., Millner, A. J., Esposito, E. C., Porter, A. C., & Nock, M. K. (2019). Implicit identification with death predicts suicidal thoughts and behaviors in adolescents. Journal of Clinical Child & Adolescent Psychology, 48, 263–272. https://doi.org/10.1080/15374416.2018.1528548
Greenwald, A. G., & Banaji, M. R. (1995). Implicit social cognition: Attitudes, self-esteem, and stereotypes. Psychological Review, 102(1), 4–27. https://doi.org/10.1037/0033- 295X.102.1.4
Greenwald, A. G., & Farnham, S. D. (2000). Using the Implicit Association Test to measure self-esteem and self-concept. Journal of Personality and Social Psychology, 79, 1022–1038 https://doi.org/10.1037/0022-3514.79.6.1022
Greenwald, A. G., & Lai, C. K. (2020). Implicit social cognition. Annual Review of Psychology, 71, 419–445. https:// doi.org/10.1146/annurev-psych-010419-050837
Greenwald, A. G., McGhee, D. E., & Schwartz, J. L. K. (1998). Measuring individual differences in implicit cognition: The Implicit Association Test. Journal of Personality and Social Psychology, 74, 1464–1480.
*Harrison, D. P., Stritzke, W. G. K., Fay, N., & Hudaib, A.-R. (2018). Suicide risk assessment: Trust an implicit probe or listen to the patient? Psychological Assessment, 30(10), 1317–1329. https://doi.org/10.1037/pas0000577
Jiang, C., Vitiello, C., Axt, J. R., Campbell, J. T., & Ratliff, K. A. (2019). An examination of ingroup preferences among people with multiple socially stigmatized identities. Self and Identity. Advance online publication. https://doi.org/ 10.1080/15298868.2019.1657937
Kurdi, B., & Banaji, M. R. (2017). Reports of the death of the individual difference approach to implicit social cognition may be greatly exaggerated: A commentary on Payne, Vuletich, and Lundberg. Psychological Inquiry, 28, 281–287. https://doi.org/10.1080/1047840X.2017.1373555
Kurdi, B., Ratliff, K. A., & Cunningham, W. A. (2021). Can the Implicit Association Test serve as a valid measure of automatic cognition? A response to Schimmack (2021). Perspectives on Psychological Science, 16(2), 422–434. https://doi.org/10.1177/1745691620904080
Kurdi, B., Seitchik, A. E., Axt, J. R., Carroll, T. J., Karapetyan, A., Kaushik, N., Tomezsko, D., Greenwald, A. G., & Banaji, M. R. (2019). Relationship between the Implicit Association Test and intergroup behavior: A meta-analysis. American Psychologist, 74(5), 569–586. https://doi.org/ 10.1037/amp0000364
*Millner, A. J., Augenstein, T. M., Visser, K. H., Gallagher, K., Vergara, G. A., D’Angelo, E. J., & Nock, M. K. (2019). Implicit cognitions as a behavioral marker of suicide attempts in adolescents. Archives of Suicide Research, 23(1), 47–63. https://doi.org/10.1080/13811118.2017.1421488
*Nock, M. K., & Banaji, M. R. (2007). Prediction of suicide ideation and attempts among adolescents using a brief performance- based test. Journal of Consulting and Clinical Psychology, 75(5), 707–715. https://doi.org/10.1037/0022- 006X.75.5.707
*Nock, M. K., Park, J. M., Finn, C. T., Deliberto, T. L., Dour, H. J., & Banaji, M. R. (2010). Measuring the suicidal mind: Implicit cognition predicts suicidal behavior. Psychological Science, 21(4), 511–517. https://doi .org/10.1177/0956797610364762
Nosek, B. A., & Bar-Anan, Y. (2012). Scientific utopia: I. Opening scientific communication. Psychological Inquiry, 23(3), 217–243. https://doi.org/10.1080/1047840X.2012.692215
Nosek, B. A., Hawkins, C. B., & Frazier, R. S. (2011). Implicit social cognition: From measures to mechanisms. Trends in Cognitive Sciences, 15(4), 152–159. https://doi.org/ 10.1016/j.tics.2011.01.005
Onyeador, I. N., Wittlin, N. M., Burke, S. E., Dovidio, J. F., Perry, S. P., Hardeman, R. R., Dyrbye, L. N., Herrin, J., Phelan, S. M., & van Ryn, M. (2020). The value of interracial contact for reducing anti-Black bias among non-Black physicians: A Cognitive Habits and Growth Evaluation (CHANGE) study report. Psychological Science, 31(1), 18–30. https://doi.org/10.1177/0956797619879139
Phelps, E. A., Cannistraci, C. J., & Cunningham, W. A. (2003). Intact performance on an indirect measure of race bias following amygdala damage. Neuropsychologia, 41(2), 203–208. https://doi.org/10.1016/s0028-3932(02)00150-1
Rae, J. R., & Greenwald, A. G. (2017). Persons or situations? Individual differences explain variance in aggregated implicit race attitudes. Psychological Inquiry, 28, 297–300. https://doi.org/10.1080/1047840X.2017.1373548
*Randall, J. R., Rowe, B. H., Dong, K. A., Nock, M. K., & Colman, I. (2013). Assessment of self-harm risk using implicit thoughts. Psychological Assessment, 25(3), 714–721 https://doi.org/10.1037/a0032391
Schimmack, U. (2012). The ironic effect of significant results on the credibility of multiple-study articles. Psychological Methods, 17(4), 551–566. https://doi.org/10.1037/a0029487
Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology/Psychologie canadienne, 61(4), 364–376. http://doi.org/10.1037/cap0000246
Schimmack, U. (2021). The Implicit Association Test: A method in search of a construct. Perspectives on Psychological Science, 16(2), 396–414. https://doi.org/10.1177/1745691619863798
Teachman, B. A., Clerkin, E. M., Cunningham, W. A., Dreyer- Oren, S., & Werntz, A. (2019). Implicit cognition and psychopathology: Looking back and looking forward. Annual Review of Clinical Psychology, 15, 123–148. https://doi.org/10.1146/annurev-clinpsy-050718-095718
*Tello, N., Harika-Germaneau, G., Serra, W., Jaafari, N., & Chatard, A. (2020). Forecasting a fatal decision: Direct replication of the predictive validity of the Suicide– Implicit Association Test. Psychological Science, 31(1), 65–74. https://doi.org/10.1177/0956797619893062
Vianello, M., & Bar-Anan, Y. (2021). Can the Implicit Association Test measure automatic judgment? The validation continues. Perspectives on Psychological Science, 16(2), 415–421. https://doi.org/10.1177/1745691619897960
Vul, E., Harris, C., Winkielman, P., & Pashler, H. (2009). Puzzlingly high correlations in fMRI studies of emotion, personality, and social cognition. Perspectives on Psychological Science, 4(3), 274–290. https://doi.org/10 .1111/j.1745-6924.2009.01125.x
Walker, S. S., & Schimmack, U. (2008). Validity of a happiness implicit association test as a measure of subjective wellbeing. Journal of Research in Personality, 42, 490–497. https://doi.org/10.1016/j.jrp.2007.07.005
Yong, E. (2012 October 12). Nobel laureate challenges psychologists to clean up their act. Nature. https://doi .org/10.1038/nature.2012.11535
Bar-Anan and Vianello (2018) published a structural equation model in support of a dual-attitude model that postulates explicit and implicit attitudes towards racial groups, political parties, and the self. I used their data to argue against a dual-attitude model. Vianello and Bar-Anan (2020) wrote a commentary that challenged my conclusions. I was a reviewer of their commentary and pointed out several problems with their new model (Schimmack, 2020). They did not respond to my review and their commentary was published without changes. I wrote a reply to their commentary. In the reply, I merely pointed to my criticism of their new model. Vianello and Bar-Anan wrote a review of my reply, in which they continue to claim that my model is wrong. I invited them to discuss the differences between our models, but they declined. In this blog post, I show that Vianello and Bar-Anan lack insight into the shortcomings of their model, which is consistent with the Dunning-Kruger effect that incompetent individuals lack insight into their own incompetence. On top of this, Vianello and Bar-Anan show willful ignorance by resisting arguments that undermine their motivated belief in dual-attitude models. As I show below, Vianello and Bar-Anan’s model has several unexplained results (e.g, negative loadings on method factors), worse fit than my model, and produces false evidence of incremental predictive validity for the implicit attitude factors.
Introduction
The skill set of psychology researchers is fairly limited. In some areas expertise is needed to create creative experimental setups. In other areas, some expertise in the use of measurement instruments (e.g., EEG) is required. However, for the most part, once data are collected, little expertise is needed. Data are analyzed with simple statistical tools like t-tests, ANOVAs, or multiple regression. These statistical methods are implemented in simple commands and no expertise is required to obtain results from statistics programs like SPSS or R.
Structural equation modeling is different because researchers have to specify a model that is fitted to the data. With complex data sets, the number of possible models that can be specified increases exponentially and it is not possible to specify all models and to simply pick the model with the best fit. Moreover, there will be many models with similar fit and it requires expertise to pick plausible models. Unfortunately, psychologists receive little formal training in structural equation modeling because graduate training relies heavily on training by supervisors rather than formal training. As most supervisors never received training in structural equation modeling, they cannot teach their graduate student how to perform these analyses. This means that expertise in structural equation modeling varies widely.
An inevitable consequence of wide variation in expertise is that individuals with low expertise have little insight into their limited abilities. This is known as the Dunning-Kruger effect that has been replicated in numerous studies. Even incentives to provide accurate performance estimates do not eliminate the overconfidence of individuals with low levels of expertise (Ehrlinger et al., 2008).
The Dunning-Kruger effect explains Vianello and Bar-Anan’s (2020) response to my article that presents another ill-fitting model that makes little theoretical sense. This overconfidence may also explain why they are unwilling to engage in a discussion of their model with me. They may not realize that my model is superior because they were unable to compare the models or to run more direct comparisons of the models. As their commentary is published in the influential journal Perspectives on Psychological Science and as many readers lack the expertise to evaluate the merits of their criticism, it is necessary to explain clearly why their criticism of my models is invalid and why their new alternative model is flawed.
Reproducing Vianello and Bar-Anan’s Model
I learned the hard way that the best way to fit a structural equation model is to start with small models of parts of the data and then to add variables or other partial models to build a complex model. The reason is that bad fit in smaller models can be easily identified and lead to important model modifications, whereas bad fit in a complex model can have thousands of reasons that are difficult to diagnose. In this particular case, I saw new reason to even fit a complex model for attitudes to political parties, racial groups, and the self. Instead I fitted separate models for each attitude domain. Vianello and Bar-Anan (2020) take issue with this decision.
“As for estimating method variance across attitude domains, that is the very logic behind an MTMM design (Campbell & Fiske, 1959; Widaman, 1985): Method variance is shared across measures of different traits that use the same method (e.g., among indirect measures of automatic racial bias and political preferences). Trait variance is shared across measures of the same trait that use different methods (e.g., among direct and indirect measures of racial attitude). Separating the MTMM matrix into three separate submatrices (one for each trait), as Schimmack did in his article, misses a main advantage of an MTMM design.“
This criticism is based on an outdated notion of validation by means of correlations in a multi-trait-multi-method matrix. In this MTMM tables, every trait is measured with all methods. For example, the Big Five traits are measured with students’ self-ratings, mothers’ ratings, and fathers’ ratings (5 traits x 3 methods). This is not possible for validation studies of explicit and implicit measures because it is assumed that explicit measures measure explicit constructs and implicit measures measure implicit constructs. Thus, it is not possible to fully cross traits and methods. This problem is evident in all models by Bar-Anan and Vianello and myself. Bar-Anan and Vianello make the mistake to assume that using implicit measures for several attitude domains solves this problem, but their assumption that we can use correlations between implicit measures in one domain and implicit measures in another domain to solve this problem is wrong. In fact, it makes matters worse because they fail to model method variance within a single attitude domain properly.
To show this problem, I first constructed measurement models for each attitude domain and then show that combining well-fitting models of three three domains produces a better fitting model than Vianello and Bar-Anan’s model.
Racial Bias
In their revised model, Vianello and Bar-Anan postulate three method factors. One for explicit measures, one for IAT-related measures, and one for the Affective Missatribution Paradigm and the Evaluative Priming Task. It is not possible to estimate a separate method factor for all explicit measures, but it is possible to allow for method factors that are unique to the IAT-related measures and one that is unique to the AMP and EPT. In the first model, I fitted this model to the measures of racial bias. The model appears to have good fit, RMSEA = .013, CFI = 973. In this model, the correlation between the explicit and implicit racial bias factors is r = .80.
However, it would be premature to stop the analysis here because overall fit values in models with many missing values are misleading (Zhang & Savaley, 2019). Even if fit were good, it is good practice to examine the modification indices to see whether some parameters are misspecified.
Inspection of the fit indices shows one very large Modification Index of 146.04 for the residual correlation between the feeling thermometer and the preference ratings. There is a very plausible explanation for this finding. These two measures are very similar and can share method variance. For example, social desirable responding could have the same effect on both ratings. This was the reason why I included only one of the two measures in my model. An alternative is to include both ratings and allow for the correlated residual to model shared method variance.
As predicted by the MI, model fit improved, RMSEA = .006, CFI = .995. Vianello and Bar-Anan (2020) might object that this finding is post-hoc after peeking at the data, while their model is specified theoretically. However, this argument is weak. If they really theoretically predicted that feeling thermometer and direct ratings share no method variance, it is not clear what theory they have in mind. After all, shared rating biases are very common. Moreover, their model also assumes shared method variance between these factors, but it also predicts that this method variance also influences dissimilar measures like the Modern Racism Scale and even ratings of other attitude objects. In short, neither their model nor my models are based on theories, in part because psychologists have ignored to develop and validate measurement theories. Even if it were theoretically predicted that feeling-thermometer and preference ratings do not share method variance, the large MI for this parameter would indicate that this theory is wrong. Thus, the data falsify this prediction. In the modified model, the implicit-explicit correlation increases from .80 to .90, providing even less support for the dual-attitude model.
Further inspection of the MI showed no plausible further improvements of the model. One important finding in this partial model is that there is no evidence of shared method variance between the AMP and EPT, r = -.04. Thus, closer inspection of the correlations among the racial attitude domain suggests two problems for Vianello and Bar-Anan’s model. There is evidence of shared method variance between two explicit measures and there is no evidence of shared method variance between two implicit measures, namely the AMP and EPT.
Next, I built a model for the political orientation domain starting with the specification in Vianello and Bar-Anan’s model. Once more, overall fit appears to be good, RMSEA = .014, CFI = .989. In this model, the correlation between the implicit and explicit factor is r = .9. However, inspection of the MI replicates a residual correlation between feeling thermometer and preference ratings. MI = 91.91. Allowing for this shared method variance improved model fit, RMSEA = .012, CFI = .993, but had little effect on the implicit-explicit correlation, r = .91. In this model, there was some evidence of shared method variance between the AMP and EPT, r = .13.
Next, I put these two well-fitting models together, leaving each model unchanged. The only new question is how measures of racial bias should be related to measures of political orientation. It is common to allow trait factors to correlate freely. This is also what Vianello and Bar-Anan did and I followed this common practices. Thus, there is no theoretical structure imposed on the trait correlations. I did not specify any additional relations for the method factors. If such relationships exist, this should lead to low fit. Model fit seemed to be good, RMSEA = .009, CFI = .982. The biggest MI was observed for the loading of the Modern Racism Scale (MRS) on the explicit political orientation factor, MI = 197.69. This is consistent with the item content of the MRS that combines racism with conservative politics (e.g., being against affirmative action). For that reason, I included the MRS in my measurement model of political orientation (Schimmack, 2020).
Vianello and Bar-Anan (2020) criticize my use of the MRS. “For instance, Schimmack chose to omit one of the indirect measures—the SPF—from the models, to include the Modern Racism Scale (McConahay, 1983) as an indicator of political evaluation, and to omit the thermometer scales from two of his models. We assume that Schimmack had good practical or theoretical reasons for his modelling decisions; unfortunately, however, he did not include those reasons.” If they had inspected the MI, they would have seen that my decision to use the MRS as a different method to measure political orientation was justified by the data as well as by the item-content of the scale.
After allowing for this theoretically expected relationship, model fit improves, chi2(df = 231) = 506.93, RMSEA = .007, CFI = .990. Next I examined whether the IAT method factor for racial bias is related to the IAT method factor for political orientation. Adding this relationship did not improve fit, chi2(230) = 506.65 = RMSEA = .007, CFI = .990. More important, the correlation was not significant, r = -.06. This is a problem for Vianello and Bar-Anan’s model that assumes the two method factors are identical. To test this hypothesis, I fitted a model with a single IAT method factor. This model had worse fit, chi2(231) = 526.99, RMSEA = .007, CFI = .989. Thus, there is no evidence for a general IAT method factor.
I next explored the possibility of a method factor for the explicit measures. I had identified shared method variance for the feeling thermometer and preference ratings for racial bias and for political orientation. I now modeled this shared method variance with method factors and let the two method factors correlate with each other. The addition of a correlation did not improve model fit, chi2(230) = 506.93, RMSEA = .007, CFI = .990 and the correlation between the two explicit method factors was not significant, r = .00. Imposing a single method factor for both attitude domains reduced model fit, chi2(df = 229) = 568.27, RMSEA = .008, CFI = .987.
I also tried to fit a single method factor for the AMP and EPT. The model only converged by constraining two loadings. Then model fit improved slightly, chi2(df = 230) = 501.75, RMSEA = .007, CFI = .990. The problem for Vianello and Bar-Anan is that the better fit was achieved with a negative loading on the method factor. This is inconsistent with the idea that a general method factor inflates correlations across attitude domains.
In sum, there is no evidence that method factors are consistent across the two attitude domains. Therefore I retained the basic model that specified method variance within attitude domains. I then added the three criterion variables to the model. As in Vianello and Bar-Anan’s model, contact was regressed on the explicit and implicit racial bias factor and previous voting and intention to vote were regressed on the explicit and implicit political orientation factors. The residuals were allowed to correlate freely, as in Vianello and Bar-Anan’s model.
Overall model fit decreased slightly for CFI, chi2(df = 297) = 668.61, RMSEA = .007, CFI = .988. MI suggested an additional relationship between the explicit political orientation factor and racial contact. Modifying the model accordingly improved fit slightly, chi2(df = 296) = 660.59, RMSEA = .007, CFI = .988. There were no additional MI involving the two voting measures.
Results were different from Vianello and Bar-Anan’s results. They reported that the implicit factors had incremental predictive validity for all three criterion measures.
In contrast, the model I am developing here shows no incremental predictive validity for the implicit factors.
It is important to note that I create the measurement model before I examined predictive validity. After the measurement model was created, criterion variables were added and the data determined the pattern of results. It is unclear how Vianello and Bar-Anan developed a measurement model with non-existing method factors that produced the desired outcome of significant incremental validity.
To try to reproduce their full result, I also added self-esteem measures to the model. To do so, I first created a measurement model for the self-esteem measures. The basic measurement model had poor fit, chi2(df = 58) = 434.49, RMSEA = .019, CFI = .885. Once more, the MI suggested that feeling-thermometer and preference ratings shared method variance. Allowing for this residual correlation increased model fit, chi2(df = 57) = 165.77, RMSEA = .010, CFI = .967. Another MI suggested a loading of the speeded task on the implicit factor, MI = 54.59. Allowing for this loading further improved model fit, chi2(df = 56) = 110.01, RMSEA = .007, CFI = .983. The crucial correlation between the explicit and implicit factor was r = .36. The correlation in Vianello and Bar-Anan’s model was r = .30.
I then added the self-esteem model to the model with the other two attitude domains, chi2(df = 695) = 1309.59, RMSEA = .006, CFI = .982. Next I added correlations of the IAT method factor for self-esteem with the two other IAT-method factors. This improved model fit, chi2(df = 693) = 1274.59, RMSEA = .006, CFI = .983. The reason was a significant correlation between the IAT method factors for self-esteem and racial bias. I offered an explanation for this finding in my article. Most White respondents associate self with good and White with good. If some respondents are better able to control their automatic tendencies, they will show less pro-self and pro-White biases. In contrast, Vianello and Bar-Anan have no theoretical explanation for a shared method factor across attitude domains. There was no significant correlation between IAT method factors for self-esteem and political orientation. The reason is that political orientation has more balanced automatic tendencies so that method variance does not favor one direction over the other.
This model had better fit with fewer parameters than Vianello and Bar-Anan’s model, chi2(df = 679) = 1719.39, RMSEA = .008, CFI = .970. The critical results of predictive validity remained unchanged.
I also fitted Vianello and Bar-Anan’s model and added four parameters that I identified as missing from their model: (a) the loading of the MRS on the explicit political orientation factor and (b) the correlations between feeling-thermometer and preference ratings for each domain. Making these adjustments improved model fit considerably, chi2(df = 675) = 1235.59, RMSEA = .006, CFI = .984. This modest adjustment altered the pattern of results for the prediction of the three criterion variables. Unlike Vianello and Bar-Anan’s model, the implicit factors no longer predicted any of the three criterion variables.
Conclusion
My interaction with Vianello and Bar-Anan are symptomatic of social psychologists misapplication of the scientific method. Rather than using data to test theories, data are being abused to confirm pre-existing beliefs. This confirmation bias goes against philosophies of science that have demonstrated the need to subject theories to strong tests and to allow data to falsify theories. Verificationism is so ingrained in social psychology that Vianello and Bar-Anan ended up with a model that showed significant incremental predictive validity for all three criterion measures in their model, when this model made several questionable assumptions. They may object that I am biased in the opposite direction, but I presented clear justifications for modeling decisions and my model fits better than their model. In my 2020 article, I showed that Bar-Anan also co-authored another article that exaggerated evidence of predictive validity that disappeared when I reanalyzed the data (Greenwald, Smith, Sriram, Bar-Anan, & Nosek, 2009). Ten years later, social psychologists claim that they have improved their research methods, but Vianello and Bar-Anan’s commentary in 2020 shows that social psychologists have a long way to go. If social psychologists want to (re)gain trust, they need to be willing to discard cherished theories that are not supported by data.
References
Bar-Anan, Y., & Vianello, M. (2018). A multi-method multi-trait test of the dual-attitude perspective. Journal of Experimental Psychology: General, 147(8), 1264–1272. https://doi.org/10.1037/xge0000383
Ehrlinger, J., Johnson, K., Banner, M., Dunning, D., & Kruger, J. (2008). Why the unskilled are unaware: Further explorations of (absent) self-insight among the incompetent. Organizational Behavior and Human Decision Processes, 105(1), 98–121. https://doi.org/10.1016/j.obhdp.2007.05.002
Greenwald, A. G., Smith, C. T., Sriram, N., Bar-Anan, Y., & Nosek, B. A. (2009). Implicit race attitudes predicted vote in the 2008 U.S. Presidential election. Analyses of Social Issues and Public Policy (ASAP), 9(1), 241–253. https://doi.org/10.1111/j.1530-2415.2009.01195.x
Schimmack U. The Implicit Association Test: A Method in Search of a Construct. Perspectives on Psychological Science. October 2019. doi:10.1177/1745691619863798
Vianello M, Bar-Anan Y. Can the Implicit Association Test Measure Automatic Judgment? The Validation Continues. Perspectives on Psychological Science. February 2020. doi:10.1177/1745691619897960
Zhang, X. & Savalei, V. (2020) Examining the effect of missing data on RMSEA and CFI under normal theory full-information maximum likelihood, Structural Equation Modeling: A Multidisciplinary Journal, 27:2, 219-239, DOI: 10.1080/10705511.2019.1642111
Prejudice is an important topic in psychology that can be examined from various perspectives. Nevertheless, prejudice research is typically studied by social psychologists. As a result, research has focused on social cognitive processes that are activated in response to racial stimuli (e.g., pictures of African Americans) and experimental manipulations of the situation (e.g., race of experimenter). Other research has focused on cognitive processes that can lead to the formation of racial bias (e.g., the minimal group paradigm). Sometimes this work has been based on a model of prejudice that assumes racial bias is a common attribute of all people (Devine, 1989) and that individuals only differ in their willingness or ability to act on their racial biases.
An alternative view is that racial biases vary across individuals and are shaped by experiences with out-group members. The most prominent theory is contact theory, which postulates that contact with out-group members reduces racial bias. In social psychology, individual differences in racial biases are typically called attitudes, where attitudes are broad dispositions to respond to a class of attitude objects in a consistent manner. For example, individuals with positive attitudes towards African Americans are more likely to have positive thoughts, feelings, and behaviors in interactions with African Americans.
The notion of attitudes as general dispositions shows that attitudes play the same role in social psychology that traits play in personality psychology. For example, extraversion is a general disposition to have more positive thoughts, feelings, and to engage more in social interactions. One important research question in personality psychology are the causes of variation in personality. Why are some people more extraverted than others? A related question is how stable personality traits are. If the causes of extraversion are environmental factors, extraversion should change when the environment changes. If the causes of extraversion are within the person (e.g., early childhood experiences, genetic differences), extraversion should be stable. Thus, the stability of personality traits over time is an empirical question that can only be answered in longitudinal studies that measure personality traits repeatedly. A meta-analysis shows that the Big Five personality traits are highly stable over time (Anusic & Schimmack, 2016).
In comparison, the stability of attitudes has received relatively little attention in social psychology because stable individual differences are often neglected in social cognitive models of attitudes. This is unfortunate because the origins of racial bias are important to the understanding of racial bias and to design interventions that help individuals to reduce their racial biases.
How stable are racial biases?
The lack of data has not stopped social psychologists from speculating about the stability of racial biases. “It’s not as malleable as mood and not as reliable as a personality trait. It’s in between the two–a blend of both a trait and a state characteristic” (Nosek in Azar, 2008). In 2019, Nosek was less certain about the stability of racial biases. “One is does that mean we have have some degree of trait variance because there is some stability over time and what is the rest? Is the rest error or is it state variance in some way, right. Some variation that is meaningful variation that is sensitive to the context of measurement. Surely it is some of both, but we don’t know how much” (The Psychology Podcast, 2019).
Other social psychologists have made stronger claims about the stability of racial bias. Payne argued that racial bias is a state because implicit bias measures show higher internal consistency than retest correlations (Payne, 2017). However, the comparison of internal consistency and retest correlations is problematic because situational factors may simply produce situation-specific measurement errors rather than reflecting real changes in the underlying trait; a problem that is well recognized in personality psychology. To examine this question more thoroughly, it is necessary to obtain multiple retests and decompose the variances into trait, state, and error variances (Anusic & Schimmack, 2016). Even this approach cannot distinguish between state variance and systematic measurement error, which requires multi-method data (Schimmack, 2019).
A Longitudinal Multi-Method Study of Racial Bias
A recent article reported the results of an impressive longitudinal study of racial bias with over 3,000 medical students who completed measures of racial bias and inter-group contact three times over a period of six year (first year of medical school, fourth year of medical school, 2nd year of residency) (Onyeador et al., 2019). I used the openly shared data to fit a multi-method state-trait-error model to the data (https://osf.io/78cqx/).
The model integrates several theoretical assumptions that are consistent with previous research (Schimmack, 2019). First, the model assumes that explicit ratings of racial bias (feeling thermometer) and implicit measures of racial bias (Implicit Association Test) are complementary measures of individual differences in racial bias. Second, the model assumes that one source of variance in racial bias is a stable trait. Third, the model assumes that racial bias differs across racial groups, in that Black individuals have more favorable attitudes towards Black people than members from other groups. Fourth, the model assumes that contact is negatively correlated with racial bias without making a strong causal assumption about the direction of this relationship. The model also assumes that Black individuals have more contact with Black individuals and that contact partially explains why Black individuals have less racial biases.
The new hypotheses that could be explored with these data concerned the presence of state variance in racial bias. First, state variance should produce correlations between the occasion specific variances of the two methods. That is, after statistically removing trait variance, residual state variance in feeling thermometer scores should be correlated with residual variances in IAT scores. For example, as medical students interact more with Black staff and patients in residency, their racial biases could change and this would produce changes in explicit ratings and in IAT scores. Second, state variance is expected to be somewhat stable over shorter time intervals because environments tend to be stable over shorter time intervals.
The model in Figure 1 met standard criteria of model fit, CFI = .997, RMSEA = .016.
Describing the model from left to right, race (0 = Black, 1 = White) has the expected relationship with quantity of contact (quant1) in year 1 (reflecting everyday interactions with Black individuals) and with the racial bias (att) factor. In addition, more contact is related to less pro-White bias (-.28). The attitude factor is a stronger predictor of the explicit trait factor (.78; ft; White feeling-thermometer – Black feeling-thermometer) than on the implicit trait factor (.60, iat). The influence of the explicit trait factor on measures on the three occasions (.58-.63) suggests that about one-third of the variance in these measures is trait variance. The same is true for individual IATs (.59-.62). The effect of the attitude factor on individual IATs (.60 * .60 = .36; .36^2 = .13 suggests that less than 20% of the variance in an individual IAT reflects racial bias. This estimate is consistent with the results from multi-method studies (Schimmack, 2019). However, these results suggests that the amount of valid trait variance can increase up to 36%, by aggregating scores of several IATs. In sum, these results provide first evidence that racial bias is stable over a period of six years and that both explicit ratings and implicit ratings capture trait variance in racial bias.
Turning to the bottom part of the model, there is weak evidence to suggest that residual variances (that are not trait variance) in explicit and implicit ratings are correlated. Although the correlation of r = .06 at time 1 is statistically significant, the correlations at time 2 (r = .03) and time 3 (r = .00) are not. This finding suggests that most of the residual variance is method specific measurement error rather than state-variance in racial bias. There is some evidence that the explicit ratings capture more than occasion-specific measurement error because state variance at time 1 predicts state variance at time 2 (r = .25) and from time 2 to time 3 (r = .20). This is not the case for the IAT scores. Finally, contact with Black medical staff at time 2 is a weak, but significant predictor of explicit measures of racial bias at time 2 and time 3, but it does not predict IAT scores at time 2 and 3. These findings do not support the hypothesis that changes in racial bias measures reflect real changes in racial biases.
The results are consistent with the only other multi-method longitudinal study of racial bias that covered only a brief period of three months. In this study, even implicit measures showed no convergent validity for the state (non-trait) variance on the same occasion (Cunningham, Preacher, & Banaji, 1995).
Conclusion
Examining predictors of individual differences in racial bias is important to understand the origins of racial biases and to develop interventions that help individuals to reduce their racial biases. Examining the stability of racial bias in longitudinal studies shows that these biases are stable dispositions and there is little evidence that they change with changing life-experiences. One explanation is that only close contact may be able to shift attitudes and that few people have close relationships with outgroup members. Thus stable environments may contribute to stability in racial bias.
Given the trait-like nature of racial bias, interventions that target attitudes and general dispositions may be relatively ineffective, as Onyeador et al.’s (2019) article suggested. Thus, it may be more effective to target and assess actual behaviors in diversity training. Expecting diversity training to change general dispositions may be misguided and lead to false conclusions about the effectiveness of diversity training programs.
Over 20 years ago, Anthony Greenwald and colleagues introduced the Implicit Association Test (IAT) as a measure of individual differences in implicit bias (Greenwald et al., 1998). The assumption underlying the IAT is that individuals can harbour unconscious, automatic, hidden, or implicit racial biases. These implicit biases are distinct from explicit bias. Somebody could be consciously unbiased, while their unconscious is prejudice. Theoretically, the opposite would also be possible, but taking IAT scores at face value, the unconscious is more prejudice than conscious reports of attitudes imply. It is also assumed that these implicit attitudes can influence behavior in ways that bypass conscious control of behavior. As a result, implicit bias in attitudes leads to implicit bias in behavior.
The problem with this simple model of implicit bias is that it lacks scientific support. In a recent review of validation studies, I found no scientific evidence that the IAT measures hidden or implicit biases outside of people’s awareness (Schimmack, 2019a). Rather, it seems to be a messy measure of consciously accessible attitudes.
Another contentious issue is the predictive validity of IAT scores. It is commonly implied that IAT scores predict bias in actual behavior. This prediction is so straightforward that the IAT is routinely used in implicit bias training (e.g., at my university) with the assumption that individuals who show bias on the IAT are likely to show anti-Black bias in actual behavior.
Even though the link between IAT scores and actual behavior is crucial for the use of the IAT in implicit bias training, this important question has been examined in relatively few studies and many of these studies had serious methodological limitations (Schimmack, 20199b).
To make things even more confusing, a couple of papers even suggested that White individuals’ unconscious is not always biased against Black people: “An unintentional, robust, and replicable Pro-Black bias in social judgment (Axt, Ebersole, & Nosek, 2016; Axt, 2017).
I used the open data of these two articles to examine more closely the relationship between scores on the attitude measures (the Brief Implicit Association Test & a direct explicit rating on a 7-point scale) and performance on a task where participants had to accept or reject 60 applicants into an academic honor society. Along with pictures of applicants, participants were provided with information about academic performance. These data were analyzed with signal-detection theory to obtain a measure of bias. Pro-White bias would be reflected in a lower admission standard for White applicants than for Black applicants. However, despite pro-White attitudes, participants showed a pro-Black bias in their admissions to the honor society.
Figure 1 shows the results for the Brief IAT. The blue lines show are the coordinates with 0 scores (no bias) on both tasks. The decreasing red line shows the linear relationship between BIAT scores on the x-axis and bias in admission decisions on the y-axis. The decreasing trend shows that, as expected, respondents with more pro-White bias on the BIAT are less likely to accept Black applicants. However, the picture also shows that participants with no bias on the BIAT have a bias to select more Black than White applicants. Most important, the vertical red line shows behavior of participants with the average performance on the BIAT. Even though these participants are considered to have a moderate pro-White bias, they show a pro-Black bias in their acceptance rates. Thus, there is no evidence that IAT scores are a predictor of discriminatory behavior. In fact, even the most extreme IAT scores fail to identify participants who discriminate against Black applicants.
A similar picture emerges for the explicit ratings of racial attitudes.
The next analysis examine convergent and predictive validity of the BIAT in a latent variable model (Schimmack, 2019). In this model, the BIAT and the explicit measure are treated as complementary measures of a single attitude for two reasons. First, multi-method studies fail to show that the IAT and explicit measures tap different attitudes (Schimmack, 2019a). Second, it is impossible to model systematic method variance in the BIAT in studies that use only a single implicit measure of attitudes.
The model also includes a group variable that distinguishes the convenience samples in Axt et al.’s studies (2016) and the sample of educators in Axt (2017). The grouping variable is coded with 1 for educators and 0 for the comparison samples.
The model meets standard criteria of model fit, CFI = .996, RMSEA = .002.
Figure 3 shows the y-standardized results so that relationships with the group variable can be interpreted as Cohen’s d effect sizes. The results show a notable difference (d = -59) in attitudes between the two samples with less pro-White attitudes for educators. In addition, educators have a small bias to favor Black applicants in their acceptance decisions (d = .19).
The model also shows that racial attitudes influence acceptance decisions with a moderate effect size, r = -.398. Finally, the model shows that the BIAT and the single-item explicit rating have modest validity as measures of racial attitudes, r = .392, .429, respectively. The results for the BIAT are consistent with other estimates that a single IAT has no more than 20% (.392^2 = 15%) valid variance. Thus, the results here are entirely consistent with the view that explicit and implicit measures tap a single attitude and that there is no need to postulate hidden, unconscious attitudes that can have an independent influence on behavior.
Based on their results, Axt et al. (2016) caution readers that the relationship between attitudes and behaviors is more complex than the common narrative of implicit bias assumes.
The authors “suggest that the prevailing emphasis on pro-White biases in judgment and behavior in the existing literature would improve by refining the theoretical understanding of under what conditions behavior favoring dominant or minority groups will occur.” (p. 33).
Implications
For two decades, the developers of the IAT have argued that the IAT measures a distinct type of attitudes that reside in individuals’ unconscious and can influence behavior in ways that bypass conscious control. As a result, even individuals who aim to be unbiased might exhibit prejudice in their behavior. Moreover, the finding that the majority of White people show a pro-White bias in their IAT scores was used to explain why discrimination and prejudice persist. This narrative is at the core of implicit bias training.
The problem with this story is that it is not supported by scientific evidence. First, there is no evidence that IAT scores reflect some form of unconscious or implicit bias. Rather, IAT scores seem to tap the same cognitive and affective processes that influence explicit ratings. Second, there is no evidence that processes that influence IAT scores can bypass conscious control of behavior. Third, there is no evidence that a pro-White bias in attitudes automatically produces a pro-White bias in actual behaviors. Not even Freud assumed that unconscious processes would have this effect on behavior. In fact, he postulated that various defense mechanisms may prevent individuals from acting on their undesirable impulses. Thus, the prediction that attitudes are sufficient to predict behavior is too simplistic.
Axt et al. (2016= speculate that “bias correction can occur automatically and without awareness” (p. 32). While this is an intriguing hypothesis, there is little evidence for such smart automatic control processes. This model also implies that it is impossible to predict actual behaviors from attitudes because correction processes can alter the influence of attitudes on behavior. This implies that only studies of actual behavior can reveal the ability of IAT scores to predict actual behavior. For example, only studies of actual behavior can demonstrate whether police officers with pro-White IAT scores show racial bias in the use of force. The problem is that 20 years of IAT research have uncovered no robust evidence that IAT scores actually predict important real-world behaviors (Schimmack, 2019b).
In conclusion, the results of Axt’s studies suggest that the use of the IAT in implicit bias training needs to be reconsidered. Not only are test scores highly variable and often provide false information about individuals’ attitudes; they also do not predict actual behavior of discrimination. It is wrong to assume that individuals who show a pro-White bias on the IAT are bound to act on these attitudes and discriminate against Black people or other minorities. Therefore, the focus on attitudes in implicit bias training may be misguided. It may be more productive to focus on factors that do influence actual behaviors and to provide individuals with clear guidelines that help them to act in accordance with these norms. The belief that this is not sufficient is based on an unsupported model of unconscious forces that can bypass awareness.
This conclusion is not totally new. In 2008, Blanton criticized the use of the IAT in applied settings (IAT: Fad or fabulous?)
“There’s not a single study showing that above and below that cutoff people differ in any way based on that score,” says Blanton.
And Brian Nosek agreed.
Guilty as charged, says the University of Virginia’s Brian Nosek, PhD, an IAT developer.
However, this admission of guilt has not changed behavior. Nosek and other IAT proponents continue to support Project Implicit that provided millions of visitors with false information about their attitudes or mental health issues based on a test with poor psychometric properties. A true admission of guilt would be to stop this unscientific and unethical practice.
References
Axt, J.R. (2017). An unintentional pro-Black bias in judgement among educators. British Journal of Educational Psychology, 87, 408-421.
Axt, J.R., Ebersole, C.R. & Nosek, B.A. (2016). An unintentional, robust, and replicable pro-Black bias in social judgment. Social Cognition, 34, 1-39.
Greenwald, A. G., McGhee, D. E., & Schwartz, J. L. K. (1998). Measuring individual differences in implicit cognition: The Implicit Association Test. Journal of Personality and Social Psychology, 74, 1464–1480.
Schimmack, U. (2019). The Implicit Association Test: A Method in Search of a construct. Perspectives on Psychological Science. https://doi.org/10.1177/1745691619863798