
In the old days, most scientific communication occured behind closed doors, when reviewers provide anonymous peer-reviews that determine the fate of manuscripts. In the old days, rejected manuscripts would not be able to contribute to scientific communications because nobody would know about them.
All of this has changed with the birth of open science. Now authors can share manuscripts on pre-print servers and researchers can discuss merits of these manuscripts on social media. The benefit of this open scientific communication is that more people can join in and contribute to the communication.
Yoav Bar-Anan co-authored an article with Brian Nosek titled “Scientific Utopia: I. Opening Scientific Communication.” In this spirit of openness, I would like to have an open scientific communication with Yoav and his co-author Michelangelo Vianello about their 2018 article “A Multi-Method Multi-Trait Test of the Dual-Attitude Perspective”
I have criticized their model in an in press article in Perspectives of Psychological Science (Schimmack, 2019). In a commentary, Yoav and Michelangelo argue that their model is “compatible with the logic of an MTMM investigation (Campbell & Fiske, 1959). They argue that it is important to have multiple traits to identify method variance in a matrix with multiple measures of multiple traits. They then propose that I lost the ability to identify method variance by examining one attitude (i.e., race, self-esteem, political orientation) at a time. They then point out that I did not include all measures and included the Modern Racism Scale as an indicator of political orientation to note that I did not provide a reason for these choices. While this is true, Yoav and Michelangelo had access to the data and could have tested whether these choices made any differences. They do not. This is obvious for the modern racism scale that can be eliminated from the measurement model without any changes in the overall model.
To cut to the chase, the main source of disagreement is the modelling of method variance in the multi-trait-multi-method data set. The issue is clear when we examine the original model published in Bar-Anan and Vianello (2018).
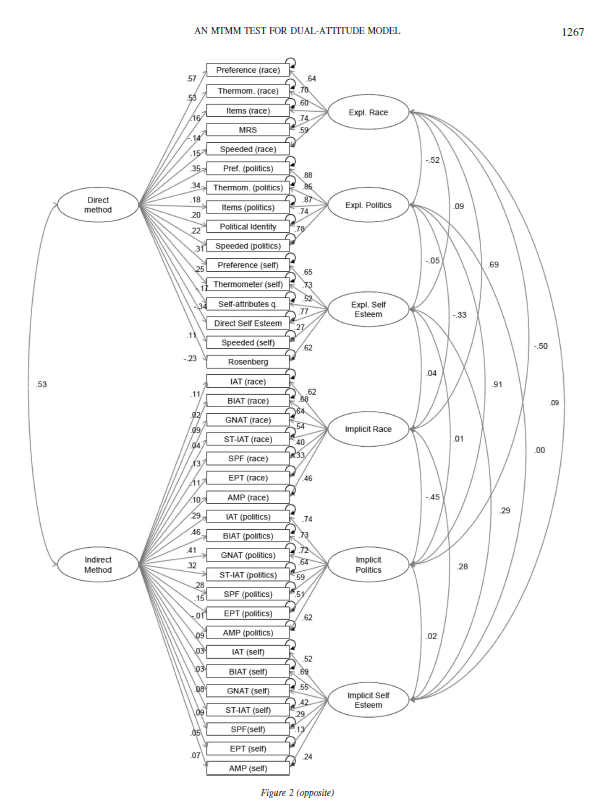
In this model, method variance in IATs and related tasks like the Brief IAT is modelled with the INDIRECT METHOD factor. The model assumes that all of the method variance that is present in implicit measures is shared across attitude domains and across all implicit measures. The only way for this model to allow for different amounts of method variance in different implicit measures is by assigning different loadings to the various methods. Moreover, the loadings provide information about the nature of the shared variance and the amount of method variance in the various methods. Although this is valuable and important information, the authors never discuss this information and its implications.
Many of these loadings are very small. For example, the loading of the race IAT and the brief race IAT are .11 and .02. In other words, the correlation between these two measures is inflated by .11 * .02 = .0022 points. This means that the correlation of r = .52 between these two measures is r = .5178 after we remove the influence of method variance.
It makes absolutely no sense to accuse me of separating the models, when there is no evidence of implicit method variance that is shared across attitudes. The remaining parameter estimates are not affected if a factor with low loadings is removed from a model.
Here I show that examining one attitude at a time produces exactly the same results as the full model. I focus on the most controversial IAT; the race IAT. After all, there is general agreement that there is little evidence of discriminant validity for political orientation (r = .91, in the Figure above), and there is little evidence for any validity in the self-esteem IAT based on several other investigations of this topic with a multi-method approach (Bosson et al., 2000; Falk et al., 2015).
Model 1 is based on Yoav and Michelangelo’s model that assumes that there is practically no method variance in IAT-variants. Thus, we can fit a simple dual-attitude model to the data. In this model, contact is regressed onto implicit and explicit attitude factors to see the unique contribution of the two factors without making causal assumptions. The model has acceptable fit, CFI = .952, RMSEA = .013.

The correlation between the two factors is .66, while it is r = .69 in the full model in Figure 1. The loading of the race IAT on the implicit factor is .66, while it is .62 in the full model in Figure 1. Thus, as expected based on the low loadings on the IMPLICIT METHOD factor, the results are no different when the model is fitted only to the measure of racial attitudes.
Model 2 makes the assumption that IAT-variants share method variance. Adding the method factor to the model increased model fit, CFI = .973, RMSEA = .010. As the models are nested, it is also possible to compare model fit with a chi-square test. With five degrees of freedom difference, chi-square changed from 167. 19 to 112.32. Thus, the model comparison favours the model with a method factor.

The main difference between the models is that there the evidence is less supportive of a dual attitude model and that the amount of valid variance in the race IAT decreases from .66^2 = 43% to r = .47^2 = 22%.
In sum, the 2018 article made strong claims about the race IAT. These claims were based on a model that implied that there is no systematic measurement error in IAT scores. I showed that this assumption is false and that a model with a method factor for IATs and IAT-variants fits the data better than a model without such a factor. It also makes no theoretical sense to postulate that there is no systematic method variance in IATs, when several previous studies have demonstrated that attitudes are only one source of variance in IAT scores (Klauer, Voss, Schmitz, & Teige-Mocigemba, 2007).
How is it possible that the race IAT and other IATs are widely used in psychological research and on public websites to provide individuals with false feedback about their hidden attitudes without any evidence of its validity as an individual difference measure of hidden attitudes that influence behaviour outside of awareness?
The answer is that most of these studies assumed that the IAT is valid rather than testing its validity. Another reason is that psychological research is focused on providing evidence that confirms theories rather than subjecting theories to empirical tests that they may fail. Finally, psychologists ignore effect sizes. As a result, the finding that IAT scores have incremental predictive validity of less than 4% variance in a criterion is celebrated as evidence for the validity of IATs, but even this small estimate is based on underpowered studies and may shrink in replication studies (cf. Kurdi et al., 2019).
It is understandable that proponents of the IAT respond with defiant defensiveness to my critique of the IAT. However, I am not the first to question the validity of the IAT, but these criticisms were ignored. At least Banaji and Greenwald recognized in 2013 that they do “not have the luxury of believing that what appears true and valid now will always appear so” (p. xv). It is time to face the facts. It may be painful to accept that the IAT is not what it was promised to be 21 years ago, but that is what the current evidence suggests. There is nothing wrong with my models and their interpretation, and it is time to tell visitors of the Project Implicit website that they should not attach any meaning to their IAT scores. A more productive way to counter my criticism of the IAT would be to conduct a proper validation study with multiple methods and validation criteria that are predicted to be uniquely related to IAT scores in a preregistered study.
I invited Yoav Bar Anan to comment on this blog post, but he declined this invitation. So much for “Scientific Utopia” and post-publication peer-review. I give the original article by Bar-Anan and Vianello one star out of five (*0000).
Dear Uli,
I appreciate your efforts and respect your devotion. For your sake, I hope you’re enjoying this.
I’m thankful you’re making use of our dataset, and that you’re making an effort to correct what you believe we got wrong. Nevertheless, I really hope I will not have to devote more time to this. So, please accept that I will not join this debate online or in emails. I am swamped with work, and the time devoted to the commentary was enough of a setback for me.
All the best,
Yoav
#Open_Science_Communication
I also was asked by the editor to review the commentary. I recommended to reject it because I showed in this blog post that the authors do not understand the implications of their model and that my model fits the data better than their model. Thus, I see now value in publishing this misguided commentary, but I want to be fully transparent about it. I think the authors should share their commentary so that everybody interested in this topic can see all the arguments, but I don’t think we need an old-fashioned printed commentary in PoPS to do so.
Here is my review
Dear Yoav,
I tried to have a conversation about the structural equation models with you, but you were not interested in a discussion. This is unfortunate because you seem to misunderstand your model and what it shows. As I already pointed out in my article and explained in more detail in a blog post, your assumption that a single method factor can account for all method variance in all implicit measures across the three attitude objects is unreasonable. However, what is more your unreasonable assumption can be tested by comparing a model that makes this assumption against a model that makes the assumption that the IAT-variants of the race IAT share some method variance that they do not share with other IAT variants for other attitude objects. On my blog, I show that this model comparison favors my model over your model. Thus, we can settle this debate empirically and your claims about my models are simply false. Thus, your commentary does not make a contribution that qualifies my claims. As a result, I recommend to the editor to reject your ms. This recommendation should not be seen as a move to silence critics. I have already mentioned and addressed your criticism in public and I still invite you to comment in public on our different models. I just don’t see a reason to bother readers of PoPS with this debate.
Best, Uli
Excellent post and yes, common method variance is the key issue. Followng the initial publication of the IAT, the authors of the IAT choose not to focus their time testing whether construct-unrelated sources of variance contrbute to IAT scores but rather choose softer targets for research (“Look, it’s reliable” etc). However, contruct validation is the exact problem that many cognitive psychologists had with the IAT – how is it any differnt from priming/task-switching etc? I wish people using the IAT would read Klauer, Voss, Schmitz, and Teige-Mocigemba 2007 and your research.
Your posts on the race IAT resonate with me because when I was designing an IAT test as a master student, I had to explain to my supervisor why doing pilots to check test validity was important and not justify the design off of the classical meta-analysis from the original authors. Your posts now reassured me that intuition was right. Pushing for the pilot studies (that became my thesis work) probably saved my lab a lot of time and money.