In the old days, most scientific communication occured behind closed doors, when reviewers provide anonymous peer-reviews that determine the fate of manuscripts. In the old days, rejected manuscripts would not be able to contribute to scientific communications because nobody would know about them.
All of this has changed with the birth of open science. Now authors can share manuscripts on pre-print servers and researchers can discuss merits of these manuscripts on social media. The benefit of this open scientific communication is that more people can join in and contribute to the communication.
I have criticized their model in an in press article in Perspectives of Psychological Science (Schimmack, 2019). In a commentary, Yoav and Michelangelo argue that their model is “compatible with the logic of an MTMM investigation (Campbell & Fiske, 1959). They argue that it is important to have multiple traits to identify method variance in a matrix with multiple measures of multiple traits. They then propose that I lost the ability to identify method variance by examining one attitude (i.e., race, self-esteem, political orientation) at a time. They then point out that I did not include all measures and included the Modern Racism Scale as an indicator of political orientation to note that I did not provide a reason for these choices. While this is true, Yoav and Michelangelo had access to the data and could have tested whether these choices made any differences. They do not. This is obvious for the modern racism scale that can be eliminated from the measurement model without any changes in the overall model.
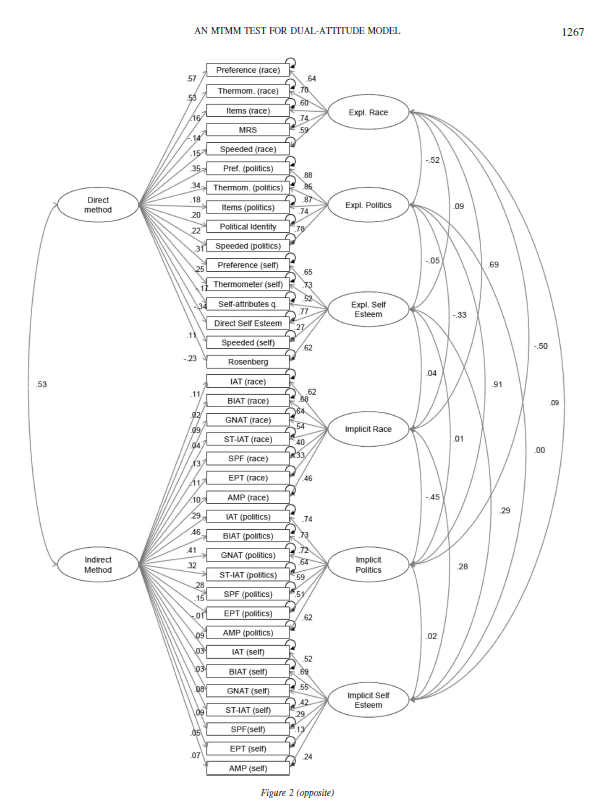
To cut to the chase, the main source of disagreement is the modelling of method variance in the multi-trait-multi-method data set. The issue is clear when we examine the original model published in Bar-Anan and Vianello (2018).
In this model, method variance in IATs and related tasks like the Brief IAT is modelled with the INDIRECT METHOD factor. The model assumes that all of the method variance that is present in implicit measures is shared across attitude domains and across all implicit measures. The only way for this model to allow for different amounts of method variance in different implicit measures is by assigning different loadings to the various methods. Moreover, the loadings provide information about the nature of the shared variance and the amount of method variance in the various methods. Although this is valuable and important information, the authors never discuss this information and its implications.
Many of these loadings are very small. For example, the loading of the race IAT and the brief race IAT are .11 and .02. In other words, the correlation between these two measures is inflated by .11 * .02 = .0022 points. This means that the correlation of r = .52 between these two measures is r = .5178 after we remove the influence of method variance.
It makes absolutely no sense to accuse me of separating the models, when there is no evidence of implicit method variance that is shared across attitudes. The remaining parameter estimates are not affected if a factor with low loadings is removed from a model.
Here I show that examining one attitude at a time produces exactly the same results as the full model. I focus on the most controversial IAT; the race IAT. After all, there is general agreement that there is little evidence of discriminant validity for political orientation (r = .91, in the Figure above), and there is little evidence for any validity in the self-esteem IAT based on several other investigations of this topic with a multi-method approach (Bosson et al., 2000; Falk et al., 2015).
Model 1 is based on Yoav and Michelangelo’s model that assumes that there is practically no method variance in IAT-variants. Thus, we can fit a simple dual-attitude model to the data. In this model, contact is regressed onto implicit and explicit attitude factors to see the unique contribution of the two factors without making causal assumptions. The model has acceptable fit, CFI = .952, RMSEA = .013.
The correlation between the two factors is .66, while it is r = .69 in the full model in Figure 1. The loading of the race IAT on the implicit factor is .66, while it is .62 in the full model in Figure 1. Thus, as expected based on the low loadings on the IMPLICIT METHOD factor, the results are no different when the model is fitted only to the measure of racial attitudes.
Model 2 makes the assumption that IAT-variants share method variance. Adding the method factor to the model increased model fit, CFI = .973, RMSEA = .010. As the models are nested, it is also possible to compare model fit with a chi-square test. With five degrees of freedom difference, chi-square changed from 167. 19 to 112.32. Thus, the model comparison favours the model with a method factor.
The main difference between the models is that there the evidence is less supportive of a dual attitude model and that the amount of valid variance in the race IAT decreases from .66^2 = 43% to r = .47^2 = 22%.
In sum, the 2018 article made strong claims about the race IAT. These claims were based on a model that implied that there is no systematic measurement error in IAT scores. I showed that this assumption is false and that a model with a method factor for IATs and IAT-variants fits the data better than a model without such a factor. It also makes no theoretical sense to postulate that there is no systematic method variance in IATs, when several previous studies have demonstrated that attitudes are only one source of variance in IAT scores (Klauer, Voss, Schmitz, & Teige-Mocigemba, 2007).
How is it possible that the race IAT and other IATs are widely used in psychological research and on public websites to provide individuals with false feedback about their hidden attitudes without any evidence of its validity as an individual difference measure of hidden attitudes that influence behaviour outside of awareness?
The answer is that most of these studies assumed that the IAT is valid rather than testing its validity. Another reason is that psychological research is focused on providing evidence that confirms theories rather than subjecting theories to empirical tests that they may fail. Finally, psychologists ignore effect sizes. As a result, the finding that IAT scores have incremental predictive validity of less than 4% variance in a criterion is celebrated as evidence for the validity of IATs, but even this small estimate is based on underpowered studies and may shrink in replication studies (cf. Kurdi et al., 2019).
It is understandable that proponents of the IAT respond with defiant defensiveness to my critique of the IAT. However, I am not the first to question the validity of the IAT, but these criticisms were ignored. At least Banaji and Greenwald recognized in 2013 that they do “not have the luxury of believing that what appears true and valid now will always appear so” (p. xv). It is time to face the facts. It may be painful to accept that the IAT is not what it was promised to be 21 years ago, but that is what the current evidence suggests. There is nothing wrong with my models and their interpretation, and it is time to tell visitors of the Project Implicit website that they should not attach any meaning to their IAT scores. A more productive way to counter my criticism of the IAT would be to conduct a proper validation study with multiple methods and validation criteria that are predicted to be uniquely related to IAT scores in a preregistered study.
Here is a link to the manuscript, data, and MPLUS scripts for reproducibility. https://osf.io/mu7e6/
ABSTRACT
Greenwald et al. (1998) proposed that the IAT measures
individual differences in implicit social cognition. This claim requires evidence of construct validity.
I review the evidence and show that there is insufficient evidence for this
claim. Most important, I show that few
studies were able to test discriminant validity of the IAT as a measure of
implicit constructs. I examine discriminant validity in several multi-method
studies and find no or weak evidence for discriminant validity. I also show
that validity of the IAT as a measure of attitudes varies across constructs. Validity
of the self-esteem IAT is low, but estimates vary across studies. About 20% of the variance in the race IAT
reflects racial preferences. The highest validity is obtained for measuring
political orientation with the IAT (64% valid variance). Most of this valid variance stems from a
distinction between individuals with opposing attitudes, while reaction times
contribute less than 10% of variance in the prediction of explicit attitude
measures. In all domains, explicit
measures are more valid than the IAT, but the IAT can be used as a measure of
sensitive attitudes to reduce measurement error by using a multi-method
measurement model.
Despite its popularity, relatively little is known about the construct validity of the IAT.
As Cronbach (1989) pointed out, construct validation is better examined by independent experts than by authors of a test because “colleagues are especially able to refine the interpretation, as they compensate for blind spots and capitalize on their own distinctive experience” (p. 163).
It is of utmost importance to determine how much of the variance in IAT scores is valid variance and how much of the variance is due to measurement error, especially when IAT scores are used to provide individualized feedback.
There is also no consensus in the literature whether the IAT measures something different from explicit measures.
In conclusion, while there is general consensus to make a distinction between explicit measures and implicit measures, it is not clear what the IAT measures
To complicate matters further, the validity of the IAT may vary across attitude objects. After all the IAT is a method, just like Likert scales are a method, and it is impossible to say that a method is valid (Cronbach, 1971).
At present, relatively little is known about the contribution of these three parameters to observed correlations in hundreds of mono-method studies.
A Critical Review
of Greenwald et al.’s (1998) Original Article
In conclusion, the seminal IAT article introduced the IAT as a measure of implicit constructs that cannot be measured with explicit measures, but it did not really test this dual-attitude model.
Construct Validity in 2007
In conclusion, the 2007 review of construct validity revealed major psychometric challenges for the construct validity of the IAT, which explains why some researchers have concluded that the IAT cannot be used to measure individual differences (Payne et al., 2017). It also revealed that most studies were mono-method studies that could not examine convergent and discriminant validity
Cunningham, Preacher and Banaji (2001)
Another noteworthy finding is that a single factor accounted for correlations among all measures on the same occasion and across measurement occasions. This finding shows that there were no true changes in racial attitudes over the course of this two-month study. This finding is important because Cunningham et al.’s (2001) study is often cited as evidence that implicit attitudes are highly unstable and malleable (e.g., Payne et al., 2017). This interpretation is based on the failure to distinguish random measurement error and true change in the construct that is being measured (Anusic & Schimmack, 2016). While Cunningham et al.’s (2001) results suggest that the IAT is a highly unreliable measure, the results also suggest that the racial attitudes that are measured with the race IAT are highly stable over periods of weeks or months.
Bar-Anan & Vianello, 2018
this large study of construct validity also provides little evidence for the original claim that the IAT measures a new construct that cannot be measured with explicit measures, and confirms the estimate from Cunningham et al. (2001) that about 20% of the variance in IAT scores reflects variance in racial attitudes.
Greenwald et al. (2009)
“When entered after the self-report measures, the two implicit measures incrementally explained 2.1% of vote intention variance, p=.001, and when political conservativism was also included in the model, “the pair of implicit measures incrementally predicted only 0.6% of voting intention variance, p = .05.” (Greenwald et al., 2009, p. 247).
I tried to reproduce these results with the published correlation matrix and failed to do so. I contacted Anthony Greenwald, who provided the raw data, but I was unable to recreate the sample size of N = 1,057. Instead I obtained a similar sample size of N = 1,035. Performing the analysis on this sample also produced non-significant results (IAT: b = -.003, se = .044, t = .070, p = .944; AMP: b = -.014, se = .042, t = 0.344, p = .731). Thus, there is no evidence for incremental predictive validity in this study.
Axt (2018)
With N = 540,723 respondents, sampling error is very small, σ = .002, and parameter estimates can be interpreted as true scores in the population of Project Implicit visitors. A comparison of the factor loadings shows that explicit ratings are more valid than IAT scores. The factor loading of the race IAT on the attitude factor once more suggests that about 20% of the variance in IAT scores reflects racial attitudes
Falk, Heine, Zhang, and Hsu (2015)
Most important, the self-esteem IAT and the other implicit measures have low and non-significant loadings on the self-esteem factor.
Bar-Anan & Vianello (2018)
Thus, low validity contributes considerably to low observed correlations between IAT scores and explicit self-esteem measures.
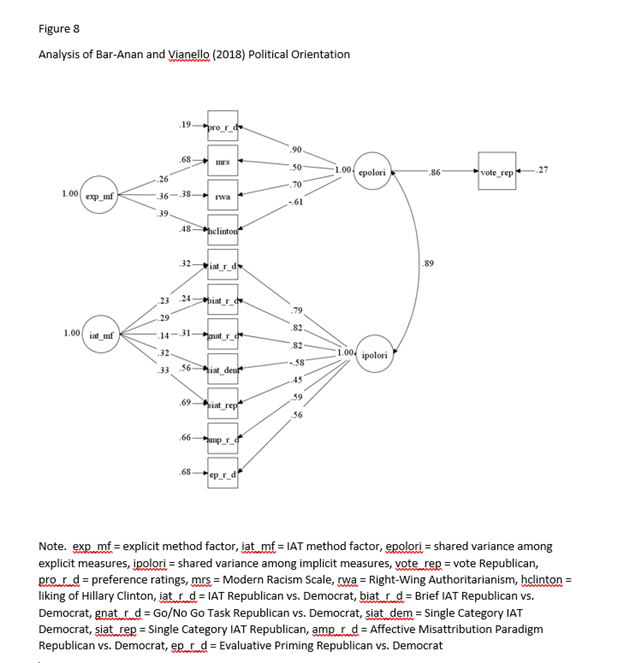
Bar-Anan & Vianello (2018) – Political Orientation
More important, the factor loading of the IAT on the implicit factor is much higher than for self-esteem or racial attitudes, suggesting over 50% of the variance in political orientation IAT scores is valid variance, π = .79, σ = .016. The loading of the self-report on the explicit ratings was also higher, π = .90, σ = .010
Variation of Implicit – Explicit Correlations Across Domains
This suggests that the IAT is good in classifying individuals into opposing groups, but it has low validity of individual differences in the strength of attitudes.
What Do IATs Measure?
The present results suggest that measurement error alone is often sufficient to explain these low correlations. Thus, there is little empirical support for the claim that the IAT measures implicit attitudes that are not accessible to introspection and that cannot be measured with self-report measures.
For 21 years the lack of discriminant validity has been overlooked because psychologists often fail to take measurement error into account and do not clearly distinguish between measures and constructs.
In the future, researchers need to be more careful when they make claims about constructs based on a single measure like the IAT because measurement error can produce misleading results.
Researchers should avoid terms like implicit attitude or implicit preferences that make claims about constructs simply because attitudes were measured with an implicit measure
Recently, Greenwald and Banaji (2017) also expressed concerns about their earlier assumption that IAT scores reflect unconscious processes. “Even though the present authors find themselves occasionally lapsing to use implicit and explicit as if they had conceptual meaning, they strongly endorse the empirical understanding of the implicit– explicit distinction” (p. 862).
How
Well Does the IAT Measure What it Measures?
Studies with the IAT can be divided into applied studies (A-studies) and basic studies (B-studies). B-studies employ the IAT to study basic psychological processes. In contrast, A-studies use the IAT as a measure of individual differences. Whereas B-studies contribute to the understanding of the IAT, A-studies require that IAT scores have construct validity. Thus, B-studies should provide quantitative information about the psychometric properties for researchers who are conducting A-studies. Unfortunately, 21 years of B-studies have failed to do so. For example, after an exhaustive review of the IAT literature, de Houwer et al. (2009) conclude that “IAT effects are reliable enough to be used as a measure of individual differences” (p. 363). This conclusion is not helpful for the use of the IAT in A-studies because (a) no quantitative information about reliability is given, and (b) reliability is necessary but not sufficient for validity. Height can be measured reliably, but it is not a valid measure of happiness.
This article provides the first quantitative information about validity of three IATs. The evidence suggests that the self-esteem IAT has no clear evidence of construct validity (Falk et al., 2015). The race-IAT has about 20% valid variance and even less valid variance in studies that focus on attitudes of members from a single group. The political orientation IAT has over 40% valid variance, but most of this variance is explained by group-differences and overlaps with explicit measures of political orientation. Although validity of the IAT needs to be examined on a case by case basis, the results suggest that the IAT has limited utility as a measurement method in A-studies. It is either invalid or the construct can be measured more easily with direct ratings.
Implications for the Use of IAT scores in Personality Assessment
I suggest to replace the reliability coefficient with the validity coefficient. For example, if we assume that 20% of the variance in scores on the race IAT is valid variance, the 95%CI for IAT scores from Project Implicit (Axt, 2018), using the D-scoring method, with a mean of .30 and a standard deviation of.46 ranges from -.51 to 1.11. Thus, participants who score at the mean level could have an extreme pro-White bias (Cohen’s d = 1.11/.46 = 2.41), but also an extreme pro-Black Bias (Cohen’s d = -.51/.46 = -1.10). Thus, it seems problematic to provide individuals with feedback that their IAT score may reveal something about their attitudes that is more valid than their beliefs.
Conclusion
Social psychologists have always distrusted self-report, especially for the measurement of sensitive topics like prejudice. Many attempts were made to measure attitudes and other constructs with indirect methods. The IAT was a major breakthrough because it has relatively high reliability compared to other methods. Thus, creating the IAT was a major achievement that should not be underestimated because the IAT lacks construct validity as a measure of implicit constructs. Even creating an indirect measure of attitudes is a formidable feat. However, in the early 1990s, social psychologists were enthralled by work in cognitive psychology that demonstrated unconscious or uncontrollable processes (Greenwald & Banaji, 1995). Implicit measures were based on this work and it seemed reasonable to assume that they might provide a window into the unconscious (Banaji & Greenwald, 2013). However, the processes that are involved in the measurement of attitudes with implicit measures are not the personality characteristics that are being measured. There is nothing implicit about being a Republican or Democrat, gay or straight, or having low self-esteem. Conflating implicit processes in the measurement of attitudes with implicit personality constructs has created a lot of confusion. It is time to end this confusion. The IAT is an implicit measure of attitudes with varying validity. It is not a window into people’s unconscious feelings, cognitions, or attitudes.
Good science requires valid measures. This statement is hardly controversial. Not surprisingly, all authors of some psychological measure claim that their measure is valid. However, validation research is expensive and difficult to publish in prestigious journals. As a result, psychological science has a validity crisis. Many measures are used in hundreds of articles without clear definitions of constructs and without quantitative information about their validity (Schimmack, 2010).
The Implicit Association Test (AT) is no exception. The IAT was introduced in 1998 with strong and highly replicable evidence that average attitudes towards objects pairs (e.g., flowers vs. spiders) can be measured with reaction times in a classification task (Greenwald et al., 1998). Although the title of the article promised a measure of individual differences, the main evidence in the article were mean differences between groups. Thus, the original article provided little evidence that the IAT is a valid measure of individual differences.
The use of the IAT as a measure of individual differences in attitudes requires scientific evidence that tests scores are linked to variation in attitudes. Key evidence for the validity of a test are reliability, convergent validity, discriminant validity, and incremental predictive validity (Campbell & Fiske, 1959).
The validity of the IAT as a measure of attitudes has to be examined on a case by case basis because the link between associations and attitudes can vary depending on the attitude object. For attitude objects like pop drinks, Coke vs. Pepsi, associations may be strongly related to attitudes. In fact, the IAT has good predictive validity for choices between two pop drinks (Hofmann, Gawronski, Gschwendner, & Schmitt, 2005). However, it lacks convergent validity when it is used to measure self-esteem (Bosson & Swan, & Pennebaker, 2000).
The IAT is best known as a measure of prejudice, racial bias, or attitudes of White Americans towards African Americans. On the one hand, the inventor of the IAT, Greenwald, argues that the race IAT has predictive validity (Greenwald et al., 2009). Others take issue with the evidence: “Implicit Association Test scores did not permit prediction of individual-level behaviors” (Blanton et al., 2009, p. 567); “the IAT provides little insight into who will discriminate against whom, and provides no more insight than explicit measures of bias” (Oswald et al., 2013).
Nine years later, Greenwald and colleagues present a new meta-analysis of predictive validity of the IAT (Kurdi et al., 2018) based on 217 research reports and a total sample size of N = 36,071 participants. The results of this meta-analysis are reported in the abstract.
We found significant implicit– criterion correlations (ICCs) and explicit– criterion correlations (ECCs), with unique contributions of implicit (beta = .14) and explicit measures (beta = .11) revealed by structural equation modeling.
The problem with meta-analyses is that they aggregate information with diverse methods, measures, and criterion variables, and the meta-analysis showed high variability in predictive validity. Thus, the headline finding does not provide information about the predictive validity of the race IAT. As noted by the authors, “Statistically, the high degree of heterogeneity suggests that any single point estimate of the implicit– criterion relationship would be misleading” (p. 7).
Another problem of meta-analysis is that it is difficult to find reliable moderator variables if original studies have small samples and large sampling error. As a result, a non-significant moderator effect cannot be interpreted as evidence that results are homogeneous. Thus, a better way to examine the predictive validity of the race IAT is to limit the meta-analysis to studies that used the race IAT.
Another problem of small studies is that they introduce a lot of noise because point estimates are biased by sampling error. Stanley, Jarrell, and Doucouliagos (2010) made the ingenious suggestion to limit meta-analysis to the top 10% of studies with the largest sample sizes. As these studies have small sampling error to begin with, aggregating them will produce estimates with even smaller sampling error and inclusion of many small studies with high heterogeneity is not necessary. A smaller number of studies also makes it easier to evaluate the quality of studies and to examine sources of heterogeneity across studies. I used this approach to examine the predictive validity of the race IAT using the studies included in Kurdi et al.’s (2018) meta-analysis (data).
Description of the Data
The datafile contained the variable groupStemCat2 that coded the groups compared in the IAT. Only studies classified as groupStemCat2 == “African American and Africans” were selected, leaving 1328 entries (rows). Next, I selected only studies with an IAT-criterion correlation, leaving 1004 entries. Next, I selected only entries with a minimum sample size of N = 100, leaving 235 entries (more than 10%).
The 235 entries were based on 21 studies, indicating that the meta-analysis coded, on average, more than 10 different effects for each study.
The median IAT-criterion correlation across all 235 studies was r = .070. In comparison, the median r for the 769 studies with N < 100 was r = .044. Thus, selecting for studies with large N did not reduce the effect size estimate.
When I first computed the median for each study and then the median across studies, I obtained a similar median correlation of r = .065. There was no significant correlation between sample size and median ICC-criterion correlation across the 21 studies, r = .12. Thus, there is no evidence of publication bias.
I now review the 21 studies in decreasing order of the median IAT-criterion correlation. I evaluate the quality of the studies with 1 to 5 stars ranging from lowest to highest quality. As some studies were not intended to be validation studies, this evaluation does not reflect the quality of a study per se. The evaluation is based on the ability of a study to validate the IAT as a measure of racial bias.
1. * Ma et al. (Study 2), N = 303, r = .34
Ma et al. (2012) used several IATs to predict voting intentions in the 2012 US presidential election. Importantly, Study 2 did not include the race IAT that was used in Study 1 (#15, median r = .03). Instead, the race IAT was modified to include pictures of the two candidates Obama and Romney. Although it is interesting that an IAT that requires race classifications of candidates predicted voting intentions, this study cannot be used to claim that the race IAT as a measure of racial bias has predictive validity because the IAT measures specific attitudes towards candidates rather than attitudes towards African Americans in general.
2. *** Knowles et al., N = 285, r = .26
This study used the race IAT to predict voting intentions and endorsement of Obama’s health care reforms. The main finding was that the race IAT was a significant predictor of voting intentions (Odds Ratio = .61; r = .20) and that this relationship remained significant after including the Modern Racism scale as predictor (Odds Ratio = .67, effect size r = .15). The correlation is similar to the result obtained in the next study with a larger sample.
3. ***** Greenwald et al. (2009), N = 1,057, r = .17
The most conclusive results come from Greenwald et al.’s (2009) study with the largest sample size of all studies. In a sample of N = 1,057 participants, the race IAT predicted voting intentions in the 2008 US election (Obama vs. McCain), r = .17. However, in a model that included political orientation as predictor of voting intentions, only explicit attitude measures added incremental predictive validity, b = .10, SE = .03, t = 3.98, but the IAT did not, b = .00, SE = .02, t = 0.18.
4. * Cooper et al., N = 178, r = .12
The sample size in the meta-analysis does not match the sample size of the original study. Although 269 patients were involved, the race IAT was administered to 40 primary care clinicians. Thus, predictive validity can only be assessed on a small sample of N = 40 physicians who provided independent IAT scores. Table 3 lists seven dependent variables and shows two significant results (p = .02, p = .02) for Black patients.
5. * Biernat et al. (Study 1), N = 136, r = .10
Study 1 included the race IAT and donations to a Black vs. other student organizations as the criterion variable. The negative relationship was not significant (effect size r = .05). The meta-analysis also included the shifting standard variable (effect size r = .14). Shifting standards refers to the extent to which participants shifted standards in their judgments of Black versus White targets’ academic ability. The main point of the article was that shifting standards rather than implicit attitude measures predict racial bias in actual behavior. “In three studies, the tendency to shift standards was uncorrelated with other measures of prejudice but predicted reduced allocation of funds to a Black student organization.” Thus, it seems debatable to use shifting standards as a validation criterion for the race IAT because the key criterion variable were the donations, while shifting standards were a competing indirect measure of prejudice.
6. ** Zhang et al. (Study 2), N = 196, r = .10
This study examined thought listings after participants watched a crime committed by a Black offender on Law and Order. “Across two programs, no statistically significant relations between the nature of the thoughts and the scores on IAT were found, F(2, 85) = 2.4, p < .11 for program 1, and F(2, 84) = 1.98, p < .53 for program 2.” The main limitation of this study is that thought listings are not a real social behavior. As the effect size for this study is close to the median, excluding it has no notable effect on the final result.
7. * Ashburn et al., N = 300, r = .09
The title of this article is “Race and the psychological health of African Americans.” The sample consists of 300 African American participants. Although it is interesting to examine racial attitudes of African Americans, this study does not address the question whether the race IAT is a valid measure of prejudice against African Americans.
8. *** Eno et al. (Study 1), N = 105, r = .09
This article examines responses to a movie set during the Civil Rights Era; “Remember the Titans.” After watching the movie, participants made several ratings about interpretations of events. Only one event, attributing Emma’s actions to an accident, showed a significant correlation with the IAT, r = .20, but attributions to racism also showed a correlation in the same direction, r = .10. For the other events, attributions had the same non-significant effect size, Girls interests r = .12, Girls race, r = .07; Brick racism, r = -.10, Brick Black coach’s actions, r = -.10.
9. *** Aberson & Haag, N = 153, r = .07
Abserson and Haag administered the race IAT to 153 participants and asked questions about quantity and quality of contact with African Americans. They found non-significant correlations with quantity, r = -.12 and quality, r = -.10, and a significant positive correlation with the interaction, r = .17. The positive interaction effect suggests that individuals with low contact, which implies low quality contact as well, are not different from individuals with frequent high quality contact.
10. *Hagiwara et al., N = 106, r = .07
This study is another study of Black patients and non-Black physician. The main limitation is that there were only 14 physicians and only 2 were White.
11. **** Bar-Anan & Nosek, N = 397, r = .06
This study used contact as a validation criterion. The race IAT showed a correlation of r = -.14 with group contact. , N in the range from 492-647. The Brief IAT showed practically the same relationship, r = -.13. The appendix reports that contact was more strongly correlated with the explicit measures; thermometer r = .27, preference r = .31. Using structural equation modeling, as recommended by Greenwald and colleagues, I found no evidence that the IAT has unique predictive validity in the prediction of contact when explicit measures were included as predictors, b = .03, SE = .07, t = 0.37.
12. *** Aberson & Gaffney, N = 386, median r = .05
This study related the race IAT to measures of positive and negative contact, r = .10, r = -.01, respectively. Correlations with an explicit measure were considerably stronger, r = .38, r = -.35, respectively. These results mirror the results presented above.
13. * Orey et al., N = 386, median r = .04
This study examined racial attitudes among Black respondents. Although this is an interesting question, the data cannot be used to examine the predictive validity of the race IAT as a measure of prejudice.
14. * Krieger et al., N = 708, median r = .04
This study used the race IAT with 442 Black participants and criterion measures of perceived discrimination and health. Although this is a worthwhile research topic, the results cannot be used to evaluate the validity of the race IAT as a measure of prejudice.
15. *** Ma et al. (Study 1), N = 335, median r = .03
This study used the race IAT to predict voter intentions in the 2012 presidential election. The study found no significant relationship. “However, neither category-level measures were related to intention to vote for Obama (rs ≤ .06, ps ≥ .26)” (p. 31). The meta-analysis recorded a correlation of r = .045, based on email correspondence with the authors. It is not clear why the race IAT would not predict voting intentions in 2012, when it did predict voting intentions in 2008. One possibility is that Obama was now seen as a an individual rather than as a member of a particular group so that general attitudes towards African Americans no longer influenced voting intentions. No matter what the reason is, this study does not provide evidence for the predictive validity of the race IAT.
16. **** Oliver et al., N = 105, median r = .02
This study was on online study of 543 family and internal medicine physicians. They completed the race IAT and gave treatment recommendations for a hypothetical case. Race of the patient was experimentally manipulated. The abstract states that “physicians possessed explicit and implicit racial biases, but those biases did not predict treatment recommendations” (p. 177). The sample size in the meta-analysis is smaller because the total sample was broken down into smaller subgroups.
17. * Nosek & Hansen, N = 207, median r = .01
This study did not include a clear validation criterion. The aim was to examine the relationship between the race IAT and cultural knowledge about stereoetypes. “In seven studies (158 samples, N = 107,709), the IAT was reliably and variably related to explicit attitudes, and explicit attitudes accounted for the relationship between the IAT and cultural knowledge.” The cultural knowledge measures were used as criterion variables. A positive relation, r = .10, was obtained for the item “If given the choice, who would most employers choose to hire, a Black American or a White American? (1 definitely White to 7 definitely Black).” A negative relation, r = -.09, was obtained for the item “Who is more likely to be a target of discrimination, a Black American or a White American? (1 definitely White to 7 definitely Black).”
18. *Plant et al., N = 229, median r = .00
This article examined voting intentions in a sample of 229 students. The results are not reported in the article. The meta-analysis reported a positive r = .04 and a negative r = -.04 for two separate entries with different explicit measures, which must be a coding mistake. As voting behavior has been examined in larger and more representative samples (#3, #15), these results can be ignored.
19. *Krieger et al. (2011), N = 503, r = .00
This study recruited 504 African Americans and 501 White Americans. All participants completed the race IAT. However, the study did not include clear validation criteria. The meta-analysis used self-reported experiences of discrimination as validation criterion. However, the important question is whether the race IAT predicts behaviors of people who discriminate, not the experience of victims of discrimination.
20. *Fiedorowicz, N = 257, r = -.01
This study is a dissertation and the validation criterion was religious fundamentalism.
21. *Heider & Skowronski, N = 140, r = -.02
This study separated the measurement of prejudice with the race IAT and the measurement of the criterion variables by several weeks. The criterion was cooperative behavior in a prisoner dilemma game. The results showed that “both the IAT (b = -.21, t = -2.51, p = .013) and the Pro-Black subscore (b = .17, t = 2.10, p = .037) were significant predictors of more cooperation with the Black confederate. However, these results were false and have been corrected (see Carlsson et al., 2018, for a detailed discussion).
Heider, J. D., & Skowronski, J.J. (2011). Addendum to Heider and Skowronski (2007): Improving the predictive validity of the Implicit Association Test. North American Journal of Psychology, 13, 17-20
Discussion
In summary, a detailed examination of the race IAT studies included in the meta-analysis shows considerable heterogeneity in the quality of the studies and their ability to examine the predictive validity of the race IAT. The best study is Greenwald et al.’s (2009) study with a large sample and voting in the Obama vs. McCain race as the criterion variable. However, another voting study failed to replicate these findings in 2012. The second best study was BarAnan and Nosek’s study with intergroup contact as a validation criterion, but it failed to show incremental predictive validity of the IAT.
Studies with physicians show no clear evidence of racial bias. This could be due to the professionalism of physicians and the results should not be generalized to the general population. The remaining studies were considered unsuitable to examine predictive validity. For example, some studies with African American participants did not use the IAT to measure prejudice.
Based on this limited evidence it is impossible to draw strong conclusions about the predictive validity of the race IAT. My assessment of the evidence is rather consistent with the authors of the meta-analysis, who found that “out of the 2,240 ICCs included in this metaanalysis, there were only 24 effect sizes from 13 studies that (a) had the relationship between implicit cognition and behavior as their primary focus” (p. 13).
This confirms my observation in the introduction that psychological science has a validation crisis because researchers rarely conduct validation studies. In fact, despite all the concerns about replicability, the lack of replication studies are much more numerous than validation studies. The consequences of the validation crisis is that psychologists routinely make theoretical claims based on measures with unknown validity. As shown here, this is also true for the IAT. At present, it is impossible to make evidence-based claims about the validity of the IAT because it is unknown what the IAT measures and how well it measures what it measures.
Theoretical Confusion about Implicit Measures
The lack of theoretical understanding of the IAT is evident in Greenwald and Banaji’s (2017) recent article, where they suggest that “implicit cognition influences explicit cognition that, in turn, drives behavior” (Kurdi et al., p. 13). This model would imply that implicit measures like the IAT do not have a direct link to behavior because conscious processes ultimately determine actions. This speculative model is illustrated with Bar-Anan and Nosek’s (#11) data that showed no incremental predictive validity on contact. The model can be transformed into a causal chain by changing the bidiretional path into an assumed causal relationship between implicit and explicit attitudes.
However, it is also possible to change the model into a single factor model, that considers unique variance in implicit and explicit measures as mere method variance.
Thus, any claims about implicit bias and explicit bias is premature because the existing data are consistent with various theoretical models. To make scientific claims about implicit forms of racial bias, it would be necessary to obtain data that can distinguish empirically between single construct and dual-construct models.
Conclusion
The race IAT is 20 years old. It has been used in hundreds of articles to make empirical claims about prejudice. The confusion between measures and constructs has created a public discourse about implicit racial bias that may occur outside of awareness. However, this discourse is removed from the empirical facts. The most important finding of the recent meta-analysis is that a careful search of the literature uncovered only a handful of serious validation studies and that the results of these studies are suggestive at best. Even if future studies would provide more conclusive evidence of incremental predictive validity, this finding would be insufficient to claim that the IAT is a valid measure of implicit bias. The IAT could have incremental predictive validity even if it were just a complementary measure of consciously accessible prejudice that does not share method variance with explicit measures. A multi-method approach is needed to examine the construct validity of the IAT as a measure of implicit race bias. Such evidence simply does not exist. Greenwald and colleagues had 20 years and ample funding to conduct such validation studies, but they failed to do so. In contrast, their articles consistently confuse measures and constructs and give the impression that the IAT measures unconscious processes that are hidden from introspection (“conscious experience provides only a small window into how the mind works”, “click here to discover your hidden thoughts”).
Greenwald and Banaji are well aware that their claims matter. “Research on implicit social cognition has witnessed higher levels of attention both from the general public and from governmental and commercial entities, making regular reporting of what is known an added responsibility” (Kurdi et al., 2018, p. 3). I concur. However, I do not believe that their meta-analysis fulfills this promise. An unbiased assessment of the evidence shows no compelling evidence that the race IAT is a valid measure of implicit racial bias; and without a valid measure of implicit racial bias it is impossible to make scientific statements about implicit racial bias. I think the general public deserves to know this. Unfortunately, there is no need for scientific evidence that prejudice and discrimination still exists. Ideally, psychologists will spend more effort in developing valid measures of racism that can provide trustworthy information about variation across individuals, geographic regions, groups, and time. Many people believe that psychologists are already doing it, but this review of the literature shows that this is not the case. It is high time to actually do what the general public expects from us.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.