“More research is needed” is the most important conclusion for academics. More research means more money for oneself, graduate students, and other academics who benefit from a research paradigm (Kuhn, 19$$). A paradigm is essentially a game. Like other games, it has rules that regulate behavior. Like professional games, players are incentivized to expand the game or at least keep it going. Hence, “more research is needed.”
In healthy paradigms, the game produces knowledge. However, not all academic paradigms are healthy. Some never produced any knowledge and others did produce some knowledge at some point but are no longer doing so. However, recognizing that a paradigm is dead threatens the academics who benefit from it. Therefore, they are the least likely to notice that their research activities are not producing knowledge. Thus, change can be excruciatingly slow.
Paradigm change usually requires a new paradigm that gives players something new to do. In psychology, personal computers made it possible to measure reaction times cheaply, and a new game was to study psychological process with the speed of button presses, culminating in the measurement of implicit racial biases with the Implicit Association Test. Two decades later, it is clear that this measure is useless for any practical purposes, but before a new game is found, IAT studies continue to pollute the literature and waste limited research funds.
The public is generally unaware of the politics of academic research and assumes that academics are scientists who are selfless monks who have dedicated their lives to the search for truth, akin to nuns and monks who pledged their lives to follow God. In reality, academic research is just another industry and academics are following market pressures. Marketing is as important, or more important, than research and development. And paradigms have to maintain a positive image. The pressure to demonstrate progress is counterproductive to admitting and learning from mistakes.
In the old days, guardians of paradigms had the advantage that they controlled the communication about research findings. Research had to be published in prestigious journals that were sold as rigorous and scientific because articles were peer-reviewed. However, peer-review served as a mechanism to keep critical research out of the literature. Thus, the publishing monopolies helped sick paradigms to live longer. This changed after the internet made it easier and cheaper to share information online. Online-only journals also made it possible to publish critical articles that were suppressed by censorship in legacy journals that were controlled by paradigm guardians.
In 2026, the power of paradigm guardians is decreasing further because AI makes it easy to critically examine published articles and meta-analysis. AI can also evaluate the strength of arguments rather than rely on journal prestige to evaluate research. All that AI needs is access to critical information and prompts that make it look for it. And that is exactly what I am doing here to undermine attempts to keep the social priming paradigm alive.
In short, social priming is the idea that people’s behavior is often influenced by stimuli in their environment without awareness. Yes, one example, is implicit prejudice. White women grab for their handbags, men reach for their wallets, when they see a Black person walk by, but if you ask them, they did not even see a Black person. Advertising may work in the same way, and subliminal stimuli have been used to show the effect. The unconscious revolution in experimental social psychology started in the 1990s (when PCs entered psychology labs) and did well until 2012, when Doyen et al. (2012) published a replication failure of a famous social priming study (seeing words related to old people made young students walk slower). Daniel Kahneman, a Nobel Prize winner, had just published a bestselling book that featured this work prominently as scientifically proven. However, replication failures were piling up in the 2010s, and social priming became the poster child of the replication crisis in experimental social psychology.
Most of the older paradigm leaders were old and retired without much fighting. Younger academics found other paradigms to play. However, some mid-career academics took it upon themselves to keep the paradigm alive. I asked ChatGPT
“who are still social psychologists who actively do priming research or at least vocally defend it against criticism that it was mostly p-hacked studies that produced no credible evidence?
“I’m checking for people with recent, public evidence of either continuing priming research or explicitly defending social priming against the p-hacking / non-credibility critique. I’ll separate “still publishing on priming” from “mainly defending the literature in commentary or interviews. A first pass suggests a small set of names rather than a broad camp. One clear current defender is Dolores Albarracín, who coauthored a 2022 paper arguing the “social priming” label is misleading and that critics focused too narrowly on a handful of underpowered studies.”
ChatGPT also summarized her original research on priming that produced mixed results.
Dolores Albarracín did conduct priming studies, especially on action/inaction and achievement primes, but the replication record is mixed rather than clearly favorable. Some of her priming effects were later tested in large direct-replication projects, and the results generally suggested that the original effects were either much smaller than first reported or not reliably reproduced. So it would be inaccurate to say her priming work was cleanly vindicated, but also too strong to say all of it simply collapsed.
ChatGPT found that Albarracin commented on replicatoin failures as inconclusive, but did not conduct new preregistered replicatoin studies with sufficient statistical power to detect smaller effects.
Albarracín has responded publicly to the replication issue. In a 2021 commentary with Wenhao Dai, she explicitly argued that several failed replications of a few underpowered priming studies from the 2000s were being overgeneralized to the entire priming literature.
What I did not find is clear evidence that Albarracín herself later led registered direct replications of the specific paradigms that had failed in the replication era.
Weingarten et al. (2016) was the first major Albarracín-associated meta-analysis of behavioral word-priming studies. It reported a small average effect, d = 0.33 to 0.35, across 352 effect sizes from 133 studies and concluded that publication bias did not fully account for the findings. Sotola (2022) reanalyzed the same literature with z-curve and obtained much more pessimistic estimates: an expected discovery rate of 5.9%, an expected replication rate of 12.4%, and a Sorić false-discovery estimate of 83.8%. These results suggest a literature with very low evidentiary value, heavy selection, and many likely false positives. This evidence does not mean that social priming effects do not exist, but it shows that two decades of research that claim to show the effect have failed to do so.
Albarracín and colleagues later published a new and broader meta-analysis, Dai et al. (2023), again arguing that priming effects on behavior are real. Once more, they did not use powerful tools to correct for publication bias. They did report that new pre-registered studies failed to show the effect, but then draw on the old literature that lacks credibility to assure readers that social priming is real.
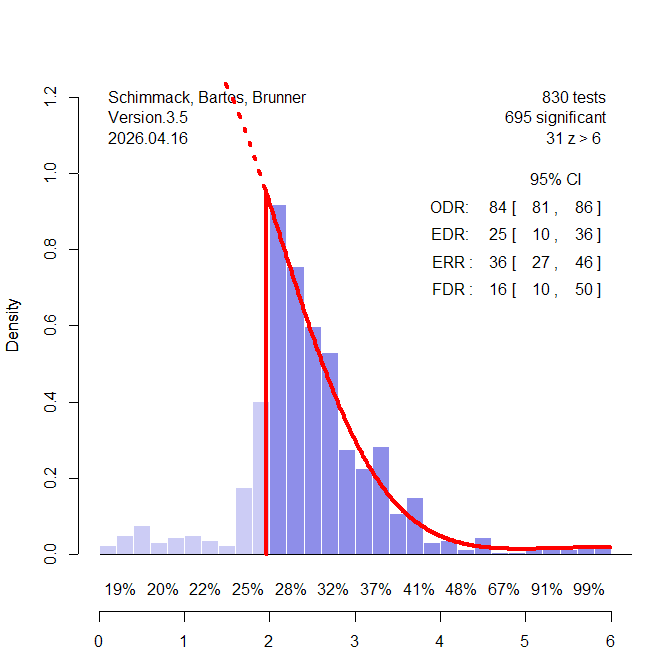
With the help of an undergraduate student, who prefers to remain anonymous, I downloaded the articles used in Dai et al.’s (2023) meta-analysis and analyzed the results with z-curve. I used ChatGPT to extract test value and to distinguish focal tests that were used to claim evidence of social priming in abstracts from other statistical tests. A comparison of focal and non-focal tests shows that focal tests nearly always show a significant result. As this is impossible with modest power, this finding confirms selection bias (Sotola, 2022).
Figure 1 shows the z-curve plot for the focal tests.
The results are more favorable than Sotola’s results for the earlier meta-analysis. The EDR is 25% rather than 6%. However, the 95% confidence interval has a lower limit of only 10% (10 significant results for every 100 tests). A discovery rate of 10% still implies a false positie risk of 50%. Optimists may point out that a true discovery is even higher, and that social priming works most of the time. However, all of these studies used different stimuli and procedures. So, it is not clear which studies produce real effects and which ones do not.
One way to deal with uncertainty is to focus on the strength of evidence of individual studies. True effects are likely to produce larger z-values. Z-curve shows the average replication rates (average power) for different levels of evidence. With just significant results (2-2.5), replicability is low (28%) and false positives are likely. Power reaches acceptable levels (80% or more) only with z-values of 5 or more, but the plot shows that these studies are very rare. The best bet of replicable effects comes from the 31 z-values greater than 6. However, until one of these effects has been demonstrated to be real, evidence of social priming effects and the conditions that make these effects smaller or larger remains elusive.
In conclusion, Albarracin illustrates the problem of an incentive structure in academia that make it less probable for this research to guide discovery and explanation of true effects. At mid-career it is difficult for academics to switch gears and start a new paradigm or join a different one. The incentive is to use reputation and status to keep playing the game until retirement. While this decision is rational for the individual academic, it is harmful to science and the general public. It is therefore important to find ways to end paradigms and to retrain academics so that they can actually do productive research.
Just like addictions, the academics themselves are the last one to realize the problem. As Feynan pointed out motivated biases can turn experts into fools because they are unable to question the foundations of their paradigms.
The main advantage of AI is not that it is smarter than humans. The key advantage is that its existence does not depend on certain beliefs to be true or not. Once that is no longer true, it will kill us or keep us as pets. Until then, AI is more trustworthy than so called experts who are often just academics who are unable to face the truth that they spend a lot of time chasing a bad idea. These prisoners of paradigms are sad examples of human irrationality. The problem is not that they made a mistake, we all do. The problem is their inability to recognize their mistakes, and that is the biggest mistake of them all.
The notion of implicit bias has taken root in North America and influential politicians like Hillary Clinton or FBI director James Comey used the idea to understand persistent racism and prejudice in the United States (Greenwald, 2015).
From Anthony Greenwald’s talk (40.21 minutes)
The main idea of implicit bias is that most White Americans have negative associations about Blacks that influence their behaviors without their awareness. This explains why even Americans who hold egalitarian values and do not want to discriminate end up discriminating against Black Americans.
The idea of implicit bias emerged in experimental social psychology in the 1980s. Until then most academic psychologists dismissed Freudian ideas of unconscious processes. However, research in cognitive psychology with computerized tasks suggested that some behaviors may be directly guided by unconscious processes that cannot be controlled by our conscious and may even influence behavior without our awareness (Greenwald, 1992).
Some examples of these unconscious processes are physiological processes (breathing), highly automated behaviors (driving while talking to a friend), and basic cognitive processes (e.g., color perception). These processes differ from cognitive tasks like adding 2 + 3 + 5 or deciding what take out food to order tonight. There is no controversy about this distinction. The controversial and novel suggestion was that prejudice could work like color perception. We automatically notice skin color and our unconscious guides our actions based on this information. Eventually the term implicit bias was coined to refer to automatic prejudice.
To provide evidence for implicit bias, experimental social psychologists adopted experiments from cognitive psychology to study prejudice. For example, one procedure is to present racial stimuli on a computer screen very quickly and immediately replace them with some neutral stimulus to prevent participants from actually seeing the stimulus. This method is called subliminal (below-threshold of awareness) priming.
Some highly cited studies suggested that subliminal priming influences behaviour without awareness (Bargh et al., 1996; Devine, 1989). However, in the past decade it has become apparent that these results are not credible (Schimmack, 2020). The reason is that social psychologists did not use the scientific method properly. Instead of using experiments to examine whether an effect exists, they only looked for evidence that shows an effect. Studies that failed to show the expected effects of subliminal priming were simply not reported. As a result, even incredible subliminal priming studies that reversed the order of cause and effect were successful (Bem, 2011). In the 2010s, some courageous researchers started publish replication failures (Doyen et al., 2012). They were attacked for doing so because it was a well-known secrete among experimental social psychologists that many studies fail, but you were not supposed to tell anybody about it. In short, the evidence that started the implicit revolution (Greenwald & Banaji, 2017) is invalid and casts a shadow over the whole notion of prejudice without awareness.
Measuring Implicit Bias
In the 1990s, experimental psychologists started developing methods to measure individuals’ implicit biases. The most prominent method is the Implicit Association Test (IAT, Greenwald et al., 1998) that has produced a large literature with thousands of studies that used the IAT to measure attitudes towards the self (self-esteem), exercise, political candidates, etc. etc. However, the most important literature with the IAT are studies of implicit bias. In these studies, White Americans tend to show a clear preference for Whites over Black Americans. This preference can also be shown with self-ratings. However, a notable group of participants shows much stronger preferences for Whites with the IAT than in their self-ratings. This finding has been used to claim that some White Americans are more prejudice than their are aware off.
One problem with the IAT and other measures of implicit bias is that they are not very good. That is, an individual’s test score is much more strongly influenced by measurement error than by their implicit bias. One way to demonstrate this is to examine the reliability of IAT scores. A good measure should produce similar results when it is used twice (e.g., two Covid-19 tests should be both positive or negative, not one positive and one negative). Reliability can be assessed by examining the correlation of two IATs. A correlation of r = .5 would imply that there is a 75% chance for somebody to score above average on both tests and a 25% chance to get conflicting results (i.e., above and below average).
Experimental social psychologists rarely examines reliability because most of their studies are cross-sectional ( a single experimental session lasting from 10 minutes to 1 hour). However, a few studies with repeated measurements provide some information. Short intervals are preferable to avoid any real changes in implicit bias. Bar-Anan and Nosek (2014) reported a retest-correlation of r = .4, for tests taken within a few hours. Lai et al. (2016) conducted the largest study with several hundred participants for tests taken within a few days. The retest correlations ranged from .22 to .30. Even two similar, but not identical, race IATs in the same session produce low correlations, r ~ .2 (Cunningham et al., 2001). More extensive psychometric analysis further suggest that some of the variance in implicit bias measures is systematic measurement error that influences one type of measure, but not other measures (Schimmack, 2019). Longitudinal studies over several years further show that the reliable variance in IATs is highly stable over time (Onyeador et al., 2020).
In short, ample evidence suggests that most of the variance in implicit bias measures is measurement error. This has important implications for research with these measures that tries to change implicit bias or use implicit bias measures to predict behaviors. However, experimental social psychologists have ignored these implications when they implicitly assumed that their measures are perfectly valid.
The Numbers do not add up
Some simple math shows the problems for experimental social psychologists to study implicit bias. The main method to study implicit bias is to conduct experiments where participants are randomly assigned to two or more groups. Each group receives a different treatment and then the effects on an implicit bias measure and actual behaviors are observed. For illustrative purposes, I assume that manipulations actually have a moderate effect size of half a standard deviation (d = .5) on implicit bias. However, because only a small proportion of the variance in the implicit bias measures is valid (here the assumption is a generous .5^2 = 25%), the effect that an experimental social psychologist could observe is only .25 standard deviations. That is, measurement error cuts the actual effect size in half. The effect on an actual behavior is even smaller because the link between attitudes and a single behavior is also small, d = .5 * .3 = .15. Thus, even under favorable conditions, experimental social psychologists can only expect to observe small effect sizes.
A good scientist would plan studies to be able to reliably detect these small effect sizes. Cohen (1988) provided guidelines for scientists how to plan sample sizes that make it possible to detect these small effects. A so-called power analysis shows that N = 500 participants are needed to detect an effect size of d = .25 and 1,400 participants are needed to detected an effect size of d = .15 for behavior.
However, experimental social psychologists tend to conduct studies with much smaller sample, often fewer than 100 participants. With N = 100, they would have only a 25% chance to reliably (with a p-value below .05) detect an effect and the observed effect size would be severely inflated because the significant result can only be significant with an inflated effect size estimate. Thus, we would expect many non-significant results in the implicit bias literature. However, we do not see these results because experimental social psychologists did not report their failures.
Implicit Bias Intervention Studies
For 20 years, experimental social psychologists have reported studies that seemed to change implicit bias (Dasgupta & Greenwald, 2001; Kawakami, Dovidio, Moll, Hermsen, Russin, 2000). The most influential article was Dasgupta and Greenwald’s (2001) article with nearly 700 citations. As this article spanned an entire literature, it is worthwhile to take a closer look at it.
There were two studies, but only Study 1 focused on implicit race bias. The sample size was N = 48. These 48 participants were divided into three groups, leaving n = 18 per group. Aside from a control group, one group was shown positive example of Blacks and negative examples of Whites and another group was shown the reverse. To get a significant result for the extreme comparison of the opposing groups, we have a study with 36 participants. To have an 80% chance to get a significant result for this contrast, an observed difference of d = .96 is needed. Taking measurement error into account this requires a change in implicit bias by 2 standard deviations. Otherwise, a non-significant result is likely and the study is risky.
Surprisingly, the authors did find a very strong effect size for their manipulation, d = 1.29. They even found a significant difference with the control group, d = .58.
As shown in Figure 1, Panel A, results revealed that exposure to pro-Black exemplars had a substantial effect on automatic racial associations (or the IAT effect).5 The magnitude of the automatic White preference effect was significantly smaller immediately after exposure to pro-Black exemplars (IAT effect = 78 ms; d = 0.58) compared with nonracial exemplars (IAT effect = 174 ms; d = 1.15), F(1, 31) = 6.79, p = .01; or pro-White exemplars (IAT effect = 176 ms; d = 1.29), F(1, 31) = 5.23, p = .029. IAT effects in control and pro-White conditions were statistically comparable (F < 11)
Dasgupta and Greenwald not only wanted to show an immediate effect. They also wanted to show that this effect can last at least for a short time. Thus, they repeated the measurement a second day. The problem is that they now need to show two significant results, when they have a relatively low chance to show even one. The risk of failure therefore increased considerably, but they were successful again.
Panel B of Figure 1 illustrates the response latency data 24 hr after exemplar exposure. Compared with the control condition, the magnitude of the IAT effect in the pro-Black condition remained significantly diminished 1 day after encountering admired Black and disliked White images (IAT effects = 126 ms vs. 51 ms, respectively; ds = 0.98 vs. 0.38, respectively), F(1, 31) = 4.16, p = .05. Similarly, compared with the pro-White condition, the IAT effect in the pro-Black exemplar condition remained substantially smaller as well (IAT effects = 107 vs. 51 ms, respectively; ds = 1.06 vs. 0.38, respectively), F(1, 31) = 3.67, p = .065.
Nobody cared about p-values that are strictly not significant (p = .05, p = .068), but these days these p-values are considered red flags that may suggest the use of questionable research practices to find significance. Another sign of questionable practices is when multiple tests are all successful because each test produces a new opportunity for failure. Thus, the fact that everything always works in experimental social psychology is a sign of widespread abuse of the scientific method (Sterling, 1959; Schimmack, 2012).
Study 2 did not examine racial bias, but it is relevant because it presents more statistical tests. If they also show the desired results, we have additional evidence that QRPs were used. Study 2 examined prejudice towards old people. Notably, the reported study did not have a control group as in Study 1, thus there is only a comparison of manipulations with favorable old people versus favorable young people. Study 2 also did not bother to examine whether the changes last for a day, or at least there were no results reported if this was examined. Thus, there is only one statistical test and that was significant with p = .03.
As illustrated in Figure 2, exposure to pro-elderly exemplars yielded a substantially smaller automatic age bias effect (IAT effect = 182 ms, d = 1.23) than exposure to pro-young exemplars (IAT effect = 336 ms, d = 1.75), F ( 1 , 24) = 5.13, p = .03.
Over the past decade, meta-scientists have developed new tools to examine the presence of questionable practices even in small sets of studies. One test examines the variability of p-values as a function of sampling error (TIVA). After converting p-values into z-scores, we would expect a variance of 1, but the variance is only 0.05. This outcome has only a probability of 1 out of 180 times to occur by chance. Even if we are conservative and make this 1 out of 100, Dasgupta and Greenwald were extremely lucky to get significant results in all of their critical tests. We can also examine the power of their studies given the reported test statistics. The average observed power is 56%, yet they had 100% successes. This suggests that QRPs were used to inflate the success rate. This test is extremely conservative because mean observed power is also inflated by the use of QRPs. A simple correction is to subtract the inflation (100% – 56% = 44%) from the observed mean power. This yields a corrected replicability index of 56% – 44% = 12%. A replicability index of 21% is obtained when there is actually no effect.
In short, power analyses and bias tests suggest that Dasgupta and Greenwald’s article contains no empirical evidence that simple experimental manipulations can produce lasting changes in implicit bias. Yet, this article suggested to other experimental social psychologists that changing IAT scores is relatively easy and worthwhile. This generated a large literature with hundreds of studies. Next we are going to examine what we can learn from 20 years of research with over 40,000 participants.
A Z-Curve Analysis of Implicit Bias Intervention Studies
Psychologists often use meta-analyses to make sense of a literature. The implicit bias literature is no exception (Forscher et al., 2019; Kurdi et al., 2019). The problem with traditional meta-analyses is that they are uninformative. Their main purpose is to claim that an effect exists and to provide an average effect size estimate that nobody cares about. Take the meta-analysis by Forscher et al. (2019) as an example. After finding as many published and unpublished studies as possible, the results are converted into effect size estimates to end up with the conclusion that
“implicit measures can be changed, but effects are often relatively weak (|ds| < .30).
What do we do with this information. After all, Dasgupta and Greenwald (2001) reported an effect size of d > 1. Does this mean, they had a more powerful manipulation or does this mean their results were inflated by QRPs?
Traditional meta-analysis suffers from two problems. First, unlike medical meta-analysis where manipulations represent a treatment with the same drug, social psychologists use very different manipulations to change implicit bias ranging from living with a Black roommate for a semester to subliminal presentation of stimuli on a computer screen. Not surprisingly there is evidence of heterogeneity, that is, effect sizes vary, making any conclusions about the average effect size meaningless. What we really want to know is which manipulations reliably can produce the largest changes in implicit attitudes.
The next problem of this meta -analysis is that it did not differentiate between IATs. Implicit measures of attitudes towards alcohol or consumer products were treated the same as implicit bias. Thus, the average results may not hold for implicit bias.
The biggest problem is that meta-analysis in psychology do not take publication bias into account. Either they do not even examine it or, as in this case, they find evidence for publication bias, but don’t correct conclusions accordingly.
“we found that procedures that directly or indirectly targeted associations, depleted mental resources, or induced goals all changed implicit measures relative to neutral procedures” (p. 541).
It is not clear whether this conclusion holds after taking publication bias into account. Meta-scientists have developed better tools to examine and correct for the influence of questionable research practices that inflate effect sizes (QRP, John et al., 2012). A simulation study found that z-curve is superior to several alternative methods (Brunner & Schimmack, 2020). Thus, I conducted a z-curve analysis of the literature on implicit bias interventions.
The meta-analysis by Forscher et al. (2019) was very helpful to find studies until 2014. I also looked for newer studies that cited Dasgupta and Greenwald (2001), the seminal study in this field. I did not bother to get data from unpublished studies or dissertations. The reason is that these sources are only included in traditional meta-analysis to give the illusion that all studies were included and that there is no bias. However, original researchers who used QRPs are not going to share their failed studies. Z-curve can correct bias for the published studies and does not require cooperation from original researchers to correct the scientific record.
I found 214 studies with 49,1145 participants (data). Figure 1 shows the z-curve. A z-curve is a histogram of the reported test-statistics converted into z-scores. Each z-score reflects the strength of evidence (effect size over sampling error) against the null-hypothesis in each study. As the direction of the effect is irrelevant, all z-scores are positive.
The first notable finding is that the peak of the distribution is at z = 1.96, which corresponds to a two-sided p-value of .05. The second finding is the sharp drop from the peak to values below 1.96. The third observation is that the peak of the distribution has a density of 1.1, which is much larger than the peak density of a standard normal distribution (~ .4). All of these results together make it clear that non-significant results are missing. To quantify the amount of bias due to the use of QRPs, we can compare the observed discovery rate (the percentage of significant results) with the expected discovery rate based on the z-curve model (the grey curve is the predicted distribution without QRPs). The literature contains 74% significant results, when we would expect only 8% significant results.
Thus, there is strong evidence that QRPs undermine the credibility of this literature. Especially, p-values like those reported by Dasgupta and Greenwald (2001) are often a sign of studies with low power that required QRPs to produce a p-value less than .05 (see values below x-axis, 12% for z-scores 2 to 2.5). However, there is also clear evidence of heterogeneity. Studies with z-scores greater than 4 are expected to replicate with 90% or more (again values below x-axis) and 6 studies are not shown because their z-scores even exceeded the maximum value of 6 on the x-axis. To give a context, particle physicists use a z-score of 5 to claim major discoveries. Thus, a few studies produced credible evidence, while the bulk of studies used QRPs to achieve statistical significance in studies with low power.
There are two remarkable articles in this literature that deserve closer attention (Lai et al., 2014, 2016). Before I examine these two articles in more detail, I also conducted a z-curve analysis of the literature without these two articles to examine the credibility of typical articles in this literature.
The z-curve plot for traditional articles in this literature looks even worse. The expected discovery rate of 7% is just above the discovery rate of 5% that is expected from studies without any effect simply because the alpha criterion of .05 allows for 5% false positive discoveries. Moreover, the 95% confidence interval of the expected replication rate does include 5%, which means we cannot rule out that all of the published studies with significant results are false positives. This is also reflected in the maximum False Discovery Rate, 73%, but the upper limit of the 95% confidence interval includes 100%.
While there may be two or three studies with credible evidence, 154 studies with nearly 20,000 participants have produced no scientific information about implicit bias. In short, like several other areas of research in experimental social psychology, implicit bias research is junk science and the seminal study by Dasgupta and Greenwald is no excpetion.
Exception No 1: Lai et al. (2014)
The IAT is a popular measure of implicit bias in part because the developers of the IAT created an online site where visitors can get feedback on their (invalid) IAT scores, including the race IAT. This website is called Project Implicit. Some also volunteer to be participants in studies with the IAT. This makes it possible to get large samples. Lai et al. (2014) used Project Implicit to conduct 50 studies with 18 different interventions. Each study had several hundred participants, which allows for higher power to get significant results and more precise effect size estimates. The next figure shows the z-curve for these 50 studies.
Visual inspection of the histogram does not show the previous steep cliff around z = 1.96. In addition, the replication rate for significant studies is high and the lower limit of the 95%CI is still 65%. Thus, even if some minor QRPs may have produced a little bump around 1.96, this article provides credible evidence that IAT scores can be changed with some manipulations. However, it also shows that several manipulations produce hardly any effects.
Moreover, it is possible that the little bump around 1.96 is a chance finding. This can be examined by fitting z-curve to all values, including no-significant ones. Now the estimated discovery rate perfectly matches the observed discovery rate, suggesting that no QRPs were used.
In short, a single study with well-powered studies that honestly reported results provided more informative results than a literature with hundreds of underpowered studies that used QRPs to publish significant results. This just shows how powerful real science can be, while at the same time exposing the flaws of the way most experimental social psychologists to this day conduct their research.
Do Successful Changes of IAT scores Reveal Changes in Implicit Bias?
If we think about measures as perfect representations of constructs, any change in a measure implies that we changed the construct. However, Figure 1 showed that we need to distinguish measures and constructs. This brings up a new question. Did Lai et al. successfully change implicit biases or did they merely change IAT scores without changing attitudes.
This question can be difficult to answer. One way to examine this would be to see whether the manipulation also influenced behaviour. In the Figure a change of actual implicit bias would also produce a change in behavior, whereas the direct effect on the measure (red path) would not imply a change in behavior. However, as we saw studies with actual behaviors require even larger samples than used in the Project Implicit studies. So, this information is not available.
This brings us to the second exceptional study, which was also conducted by Lai and colleagues (2016). It is essentially a replication and extension of their first study. Focussing on the successful intervention in Lai et al. (2014), the authors examined whether the immediate effects would persist for a few days. First, the authors successfully replicated the immediate effects. More important, they failed to find significant effects a few days later, despite high power to do so. Even participants who were trained to fake the IAT did not bother to fake the IAT again the second time. Thus, even successful interventions that change IAT scores do not seem to change implicit biases measured with the IAT.
Don’t just trust me. Even Greenwald himself has declared that there are no proven ways to change implicit bias, although he fails to explain how he obtained strong effects in his seminal study.
“Importantly, there are no such situational interventions that have been established to have durable effects on IAT measures (Lai et al., 2016)” (Rae and Greenwald, 2017).
“None of the eight effective interventions produced an effect that persisted after a delay of one or a few days.This lack of persistence was not previously known because more than 90% of prior intervention studies had considered changes only within a single experimental session (Lai et al. 2013).” (Greenwald and Lai, 2020).
In short, 20 years of research that started with strong and persistent effects in Dasgupta and Greenwald’s seminal article has produced no useful information how to change implicit bias, despite hundreds of articles that claimed to change implicit bias successfully.
Where do we go from here?
Based on the famous saying “insanity is doing the same thing over and over again and expecting different results” we have to declare experimental social psychologists insane. For decades they have tried to make a contribution to the understanding of prejudice by bringing White students at White universities into labs run by mostly White professors, expose them to some stimuli and measured prejudice right afterwards. The only things that changed is that social psychologists now do even shorter studies with larger samples over the Internet. Should anybody expect that a brief manipulation can have profound effects? The only people who think this could work are social psychologists who have been deluded by inflated effect sizes in p-hacked studies that even subliminal manipulations can have profound effects on prejudice. Meanwhile, racisms remains a troubling reality in the United States as the summer in 2020 made clear.
It is time to use research funding wisely and not to waste it on experimental social psychology that is more concerned with publications and citations than with affecting real change. Resources need to be invested in longitudinal studies, studies with children, studies at work places with real outcome measures. Right now, this research does not attract funding because researchers who pump out five quick, p-hacked experiments get more publications, funding, and positions than researchers who do one well-designed longitudinal study that may fail to show a statistically significant result. Junk is drowning out good science. Maybe a new administration that actually cares about racial justice will allocate research money more wisely. Meanwhile, experimental social psychologists need to rethink their research practices and wonder what their real priorities are. As a group, they can either continue to do meaningless research or step up. However, they can no longer deceive themselves or others that their past research made a real contribution. Denial is not an answer, unless they want to take a place next to Trump in history. Publishing only studies that work was a big mistake. It is time to own up to it.
References
Onyeador, I. N., Wittlin, N. M., Burke, S. E., Dovidio, J. F., Perry, S. P., Hardeman, R. R., … van Ryn, M. (2020). The Value of Interracial Contact for Reducing Anti-Black Bias Among Non-Black Physicians: A Cognitive Habits and Growth Evaluation (CHANGE) Study Report. Psychological Science, 31(1), 18–30. https://doi.org/10.1177/0956797619879139
Implicit racism is in the news again (CNN). A manager of a Starbucks in Philadelphia called 911 to ask police to remove two Black men from the coffee store because they had not purchased anything. The problem is that many White customers frequent Starbucks without purchasing things and the police is not called. The incident caused widespread protests and Starbucks announced that it would close all of its stores for “implicit bias training.”
Starbucks’ CEO Derrick Johnson explains the need for store-wide training in this quote.
“The Starbucks situation provides dangerous insight regarding the failure of our nation to take implicit bias seriously,” said the group’s president and CEO Derrick Johnson in a statement. “We refuse to believe that our unconscious bias –the racism we are often unaware of—can and does make its way into our actions and policies.”
But was it implicit bias? It does not matter. CEO Derrick Johnson could have talked about racism without changing what happened or the need for training.
“The Starbucks situation provides dangerous insight regarding the failure of our nation to take racism seriously,” said the group’s president and CEO Derrick Johnson in a statement. “We refuse to believe that we are racists and that racism can and does make its way into our actions and policies.”
We have not heard from the store manager why she called the police. This post is not about a single incidence at Starbucks because psychological science can rarely provide satisfactory answers to single events. However, the call for training of thousands of Starbucks’ employees is not a single event. It implies that social psychologists have developed scientific ways to measure “implicit bias” and developed ways to change it. This is the topic of this post.
What is implicit bias and what can be done to reduce it?
The term “implicit” has a long history in psychology, but it rose to prominence in the early 1990s when computers became more widely used in psychological research. Computers made it possible to present stimuli on screens rather than on paper and to measure reaction times rather than self-ratings. Computerized tasks were first used in cognitive psychology to demonstrate that people have associations that can influence their behaviors. For example, participants are faster to determine that “doctor” is a word if the word is presented after a related word like “hospital” or “nurse.”
The term implicit is used for effects like this because the effect occurs without participants’ intention, conscious reflection, or deliberation. They do not want to respond this way, but they do, whether they want to or not. Implicit effects can occur with or without awareness, but they are generally uncontrollable.
After a while, social psychologists started to use computerized tasks that were developed by cognitive psychologists to study social topics like prejudice. Most studies used White participants to demonstrate prejudice with implicit tasks. For example, the association task described above can be easily modified by showing traditionally White or Black names (in the beginning computers could not present pictures) or faces.
Given the widespread prevalence of stereotypes about African Americans, many of these studies demonstrated that White participants respond differently to Black or White stimuli. Nobody doubts these effects. However, there remain two unanswered questions about these effects.
What (the fuck) is Implicit Racial Bias?
First, do responses in this implicit task with racial stimuli measure a specific form of prejudice? That is, do implicit tasks measure plain old prejudice with a new measure or do they actually measure a new form of prejudice? The main problem is that psychologists are not very good at distinguishing constructs and measures. This goes back to the days when psychologists equated measures and constructs. For example, to answer the difficult question whether IQ tests measure intelligence, it was simply postulated that intelligence is what IQ tests measure. Similarly, there is no clear definition of implicit racial bias. In social psychology implicit racism is essentially whatever leads to different responses to Black and White stimuli in an implicit task.
The main problem with this definition is that different implicit tasks show low convergent validity. Somebody can take two different “implicit tests” (the popular Implicit Association Test, IAT, or the Affective Misattribution Task) and get different results. The correlations between two different tests range from 0 to .3, which means that the tests disagree more with each other than that they agree.
20 years after the first implicit tasks were used to study prejudice we still do not know whether implicit bias even exist or how it could be measured, despite the fact that these tests are made available to the public to “test their racial bias.” These tests do not meet the standards of real psychological tests and nobody should take their test scores too seriously. A brief moment of self-reflection is likely to provide better evidence about your own feelings towards different social groups. How would you feel if somebody from this group would move in next door? How would you feel if somebody from this group would marry your son or daughter? Responses to questions like this have been used for over 100 years and they still show that most people have a preference for their own group over most other groups. The main concern is that respondents may not answer these survey questions honestly. But if you do so in private for yourself and you are honest to yourself, you will know better how prejudice you are towards different groups than by taking an implicit test.
What was the Starbucks’ manager thinking or feeling when she called 911? The answer to this question would be more informative than giving her an implicit bias test.
Is it possible to Reduce Implicit Bias?
Any scientific answer to this question requires measuring implicit bias. The ideal study to examine the effectiveness of any intervention is a randomized controlled trial. In this case it is easy to do so because many White Americans who are prejudice do not want to be prejudice. They learned to be prejudice through parents, friends, school, or media. Racism has been part of American culture for a long time and even individuals who do not want to be prejudice respond differently to White and African Americans. So, there is no ethical problem in subjecting participants to an anti-racism training program. It is like asking smokers who want to quit smoking to participate in a test of a new treatment of nicotine addiction.
Unfortunately, social psychologists are not trained in running well-controlled intervention studies. They are mainly trained to do experiments that examine the immediate effects of an experimental manipulation on some measure of interest. Another problem is that published articles typically report only report successful experiments. This publication bias leads to the wrong impression that it may be easy to change implicit bias.
For example, one of the leading social psychologist on implicit bias published an article with the title “On the Malleability of Automatic Attitudes: Combating Automatic
Prejudice With Images of Admired and Disliked Individuals” (Dasgupta & Greenwald, 2001). The title makes two (implicit) claims. Implicit attitudes can change (it is malleable) and this article introduces a method that successfully reduced it (combating it). This article was published 17 years ago and it has been cited 537 times so far.
Study 1
The first experiment relied on a small sample of university students (N = 48). The study had three experimental conditions with n = 18, 15, and 15 for each condition. It is now recognized that studies with fewer than n = 20 participants per condition are questionable (Simmons et al., 2011).
The key finding in this study was that scores on the Implicit Association Test (IAT) were lower when participants were exposure to positive examples of African Americans (e.g., Denzel Washington) and negative examples of European Americans (e.g., Jeffrey Dahmer – A serial killer) than in the control condition, F(1, 31) = 5.23, p = .023.
The observed mean difference is d = .80. This is considered a large effect. For an intervention to increase IQ it would imply an increase by 80% of a standard deviation or 12 IQ points. However, in small samples, these estimates of effect size vary a lot. To get an impression of the range of variability it is useful to compute the 95%CI around the observed effect size. It ranges form d = .10 to 1.49. This means that the actual effect size could be just 10% of a standard deviation, which in the IQ analogy would imply an increase by just 1.5 points. Essentially, the results merely suggest that there is a positive effect, but they do not provide any information about the size of the effect. It could be very small or it could be very large.
Unusual for social psychology experiments, the authors brought participants back 24 hours after the manipulation to see whether the brief exposure to positive examples had a lasting effect on IAT scores. As the results were published, we already know that it did. The only question is how strong the evidence was.
The result remained just significant, F(1, 31) = 4.16, p = .04999. A p-value greater than .05 would be non-significant, meaning the study provided insufficient evidence for a lasting change. More troublesome is that the 95%CI around the observed mean difference of d = .73 ranged from d = .01 to 1.45. This means it is possible that the actual effect size is just 1% of a standard deviation or 0.15 IQ points. The small sample size simply makes it impossible to say how large the effect really is.
Study 2
Study 1 provided encouraging results in a small sample. A logical extension for Study 2 would be to replicate the results of Study 1 with a larger sample in order to get a better sense of the size of the effect. Another possible extension could be to see whether repeated presentations of positive examples over a longer time period can have lasting effects that last longer than 24 hours. However, multiple-study articles in social psychology are rarely programmatic in this way (Schimmack, 2012). Instead, they are more a colorfull mosaic of studies that were selected to support a good story like “it is possible to combat implicit bias.”
The sample size in Study 2 was reduced from 48 to 26 participants. This is a terrible decision because the results in Study 1 were barely significant and reducing sample sizes increases the risk of a false negative result (the intervention actually works, but the study fails to show it).
The purpose of Study 2 was to generalize the results of racial bias to aging bias. Instead of African and European Americans, participants were exposed to positive and negative examples of young and old people and performed an age-IAT (old vs. young).
The statistical analysis showed again a significant mean difference, F(1, 24) = 5.13, p = .033. However, the 95%CI again showed a wide range of possible effect sizes from d = .11 to 1.74. Thus, the study provides no reliable information about the size of the effect.
Moreover, it has to be noted that study two did not report whether a 24-hour follow up was conducted or not. Thus, there is no replication of the finding in Study 1 that a small intervention can have an effect that lasts 24 hours.
Publication Bias: Another Form of Implicit Bias [the bias researchers do not want to talk about in public]
Significance tests are only valid if the data are based on a representative sample of possible observations. However, it is well-known that most journals, including social psychology journals publish only successful studies (p < .05) and that researchers use questionable research practices to meet this requirement. Even two studies are sufficient to examine whether the results are representative or not.
The Test of Insufficient Variance examines whether reported p-values are too similar than we would expect based on a representative sample of data. Selection for significance reduces variability in p-values because p-values greater than .05 are missing.
This article reported a p-value of .023 in Study 1 and .033 in Study 2. These p-values were converted int z-values; 2.27 and 2.13, respectively. The variance for these two z-scores is 0.01. Given the small sample sizes, it was necessary to run simulations to estimate the expected variance for two independent p-values in studies with 24 and 31 degrees of freedom. The expected variance is 0.875. The probability of observing a variance of 0.01 or less with an expected variance of 0.875 is p = .085. This finding raises concerns about the assumption that the reported results were based on a representative sample of observations.
In conclusion, the widely cited article with the promising title that scores on implicit bias measures are malleable and that it is possible to combat implicit bias provided very preliminary results that by no means provide conclusive evidence that merely presenting a few positive examples of African Americans reduces prejudice.
A Large-Scale Replication Study
Nine years later, Joy-Gaba and Nosek (2010) examined whether the results reported by Dasgupta and Greenwald could be replicated. The title of the article “The Surprisingly Limited Malleability of Implicit Racial Evaluations” foreshadows the results.
Abstract
“Implicit preferences for Whites compared to Blacks can be reduced via exposure to admired Black and disliked White individuals (Dasgupta & Greenwald, 2001). In four studies (total N = 4,628), while attempting to clarify the mechanism, we found that implicit preferences for Whites were weaker in the “positive Blacks” exposure condition compared to a control condition (weighted average d = .08). This effect was substantially smaller than the original demonstration (Dasgupta & Greenwald, 2001; d = .82).”
On the one hand, the results can be interpreted as a successful replication because the study with 4,628 participants again rejected the null-hypothesis that the intervention has absolutely no effect. However, the mean difference in the replication study is only d = .08, which corresponds to an effect size estimate of 1.2 IQ points if the study had tried to raise IQ. Moreover, it is clear that the original study was only able to report a significant result because the observed mean difference in this study was inflated by 1000%.
Study 1
Participants in Study 1 were Canadian students (N = 1,403). The study differed in that it separated exposure to positive Black examples and negative White examples. Ideally, real-world training programs would aim to increase liking of African Americans rather than make people think about White people as serial killers. So, the use of only positive examples of African Americans makes an additional contribution by examining a positive intervention without negative examples of Whites. The study also included age to replicate Study 2.
Like US Americans, Canadian students also showed a preference for White over Blacks on the Implicit Association Test. So failures to replicate the intervention effect are not due to a lack of racism in Canada.
A focused analysis of the race condition showed no effect of exposure to positive Black examples, t(670) = .09, p = .93. The 95%CI of the mean difference in this study ranged from -.15 to .16. This means that with a maximum error probability of 5%, it is possible to rule out effect sizes greater than .16. This finding is not entirely inconsistent with the original article because the original study was inconclusive about effect sizes.
The replication study is able to provide a more precise estimate of the effect size and the results show that the effect size could be 0, but it could not be d = .2, which is typically used as a reference point for a small effect.
Study 2a
Study 2a reintroduced the original manipulation that exposed participants to positive examples of African Americans and negative examples of European Americans. This study showed a significant difference between the intervention condition and a control condition that exposed participants to flowers and insects, t(589) = 2.08, p = .038. The 95%CI for the effect size estimate ranged from d = .02 to .35.
It is difficult to interpret this result in combination with the result from Study 1. First, the results of the two studies are not significantly different from each other. It is therefore not possible to conclude that manipulations with negative examples of Whites are more effective than those that just show positive examples of Blacks. In combination, the results of Study 1 and 2a are not significant, meaning it is not clear whether the intervention has any effect at all. Nevertheless, the significant result in Study 2a suggests that presenting negative examples of Whites may influence responses on the race IAT.
Study 2b
Study 2b is an exact replication of Study 2a. It also replicated a significant mean difference between participants exposed to positive Black and negative White examples and the control condition, t(788) = 1.99, p = .047 (reported as p = .05). The 95%CI ranges from d = .002 to d = .28.
The problem is that now three studies produced significant results with exposure to positive Black and negative White examples (Original Study 1; replication Study 2a & 2b) and all three studies had just significant p-values (p = .023, p = .038, p = .047). This is unlikely without selection of data to attain significance.
Study 3
The main purpose of Study 3 was to compare an online sample, an online student sample, and a lab student sample. None of the three samples showed a significant mean difference.
Online sample: t(999) = .96, p = .34
Online student sample: t(93) = 0.51, p = .61
Lab student sample: t(75) = 0.70, p = .48
The non-significant results for the student samples are not surprising because sample sizes are too small to detect small effects. The non-significant result for the large online sample is more interesting. It confirms that the two p-values in Studies 2a and 2b were too similar. Study 3 produces greater variability in p-values that is expected and given the small effect size variability was increased by a non-significant result rather than a highly significant one.
Conclusion
In conclusion, there is no reliable evidence that merely presenting a few positive Black examples alters responses on the Implicit Association Test. There is some suggestive evidence that presenting negative White examples may reduce prejudice presumably by decreasing favorable responses to Whites, but even this effect is very weak and may not last more than a few minutes or hours.
The large replication study shows that the highly cited original article provided misleading evidence that responses on implicit bias measures can be easily and dramatically changed by presenting positive examples of African Americans. If it were this easy to reduce prejudice, racism wouldn’t be the problem that it still is.
Newest Evidence
In a major effort, Lai et al. (2016) examined several interventions that might be used to combat racism. The first problem with the article is that the literature review fails to mention Joy-Gaba and Nosek’s finding that interventions were rather ineffective or evidence that implicit racism measures show little natural variation over time (Cunningham et al., 2001). Instead they suggest that the ” dominant view has changed over the past 15 years to one of implicit malleability” [what they mean malleability of responses on implict tasks with racial stimuli]. While this may accurately reflect changes in social psychologists’ opinions, it ignores that there is no credible evidence to suggest that implicit attitude measures are malleable.
More important, the study also failed to find evidence that a brief manipulation could change performance on the IAT a day or more later, despite a large sample size to detect even small lasting effects. However, some manipulations produced immediate effects on IAT scores. The strongest effect was observed for a manipulation that required vivid imagination.
Vivid counterstereotypic scenario.
Participants in this intervention read a vivid second-person story in which they are the protagonist. The participant imagines walking down a street late at night after drinking at a bar. Suddenly, a White man in his forties assaults the participant, throws him/her into the trunk of his car, and drives away. After some time, the White man opens the trunk and assaults the participant again. A young Black man notices the second assault and knocks out the White assailant, saving the day. After reading the story, participants are told the next task (i.e., the race IAT) was supposed to affirm the associations: White = Bad, Black = Good. Participants were instructed to keep the story in mind during the IAT.
When given this instruction, the pro-White bias in the IAT was reduced. However, one day later (Study 2) or two or three days later (Study 1) IAT performance was not significantly different from a control condition.
In conclusion, social psychologists have found out something that most people already know. Changing attitudes, including prejudice, is hard because they are stable and difficult to change, even when participants want to change them. A simple, 5-minute manipulation is not an intervention and it will not produce lasting changes in attitudes.
General Discussion
Social psychology has failed Black people who would like to be treated with the same respect as White people and White people who do not want to be racist.
Since Martin Luther King gave his dream speech, America has made progress towards a goal of racial equality without the help of social psychologists. Nevertheless, racial bias remains a problem, but social psychologists are too busy with sterile experiments that have no application to the real world (No! Starbucks’ employees should not imagine being abducted by White sociopaths to avoid calling 911 on Black patrons of their stores) and performance on an implicit bias test is only relevant if it predicted behavior and it doesn’t do that very well.
The whole notion of implicit bias is a creation by social psychologists without scientific foundations, but 911 calls that kill black people are real. Maybe Starbucks could fund some real racism research at Howard University because the mostly White professors at elite Universities seem to be unable to develop and test real interventions that can influence real behavior.
And last but not least, don’t listen to self-proclaimed White experts.
Social psychologists who have failed to validate measures and failed to conduct real intervention studies that might actually work are not experts. It doesn’t take a Ph.D. to figure out some simple things that can be taught in a one-day workshop for Starbucks’ employees. After all, the goal is just to get employees to treat all customers equally, which doesn’t even require a change in attitudes.
Here is one simple rule. If you are ready to call 911 to remove somebody from your coffee shop and the person is Black, ask yourself before you dial whether you would do the same if the person were White and looked like you or your brother or sister. If so, go ahead. If not, don’t touch that dial. Let them sit at a table like you let dozens of other people sit at their table because you make most of your money from people on the go anyways. Or buy them a coffee, or do something, but think twice or three times before you call the police.
And so what if it is just a PR campaign. It is a good one. I am sure there are a few people who would celebrate a nation-wide racism training day for police (maybe without shutting down all police stations).
Real change comes from real people who protest. Don’t wait for the academics to figure out how to combat automatic prejudice. They are more interested in citations and further research than to provide real solutions to real problems. Trust me, I know. I am (was?) a White social psychologist myself.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.