Prejudice is an important topic in psychology that can be examined from various perspectives. Nevertheless, prejudice research is typically studied by social psychologists. As a result, research has focused on social cognitive processes that are activated in response to racial stimuli (e.g., pictures of African Americans) and experimental manipulations of the situation (e.g., race of experimenter). Other research has focused on cognitive processes that can lead to the formation of racial bias (e.g., the minimal group paradigm). Sometimes this work has been based on a model of prejudice that assumes racial bias is a common attribute of all people (Devine, 1989) and that individuals only differ in their willingness or ability to act on their racial biases.
An alternative view is that racial biases vary across individuals and are shaped by experiences with out-group members. The most prominent theory is contact theory, which postulates that contact with out-group members reduces racial bias. In social psychology, individual differences in racial biases are typically called attitudes, where attitudes are broad dispositions to respond to a class of attitude objects in a consistent manner. For example, individuals with positive attitudes towards African Americans are more likely to have positive thoughts, feelings, and behaviors in interactions with African Americans.
The notion of attitudes as general dispositions shows that attitudes play the same role in social psychology that traits play in personality psychology. For example, extraversion is a general disposition to have more positive thoughts, feelings, and to engage more in social interactions. One important research question in personality psychology are the causes of variation in personality. Why are some people more extraverted than others? A related question is how stable personality traits are. If the causes of extraversion are environmental factors, extraversion should change when the environment changes. If the causes of extraversion are within the person (e.g., early childhood experiences, genetic differences), extraversion should be stable. Thus, the stability of personality traits over time is an empirical question that can only be answered in longitudinal studies that measure personality traits repeatedly. A meta-analysis shows that the Big Five personality traits are highly stable over time (Anusic & Schimmack, 2016).
In comparison, the stability of attitudes has received relatively little attention in social psychology because stable individual differences are often neglected in social cognitive models of attitudes. This is unfortunate because the origins of racial bias are important to the understanding of racial bias and to design interventions that help individuals to reduce their racial biases.
How stable are racial biases?
The lack of data has not stopped social psychologists from speculating about the stability of racial biases. “It’s not as malleable as mood and not as reliable as a personality trait. It’s in between the two–a blend of both a trait and a state characteristic” (Nosek in Azar, 2008). In 2019, Nosek was less certain about the stability of racial biases. “One is does that mean we have have some degree of trait variance because there is some stability over time and what is the rest? Is the rest error or is it state variance in some way, right. Some variation that is meaningful variation that is sensitive to the context of measurement. Surely it is some of both, but we don’t know how much” (The Psychology Podcast, 2019).
Other social psychologists have made stronger claims about the stability of racial bias. Payne argued that racial bias is a state because implicit bias measures show higher internal consistency than retest correlations (Payne, 2017). However, the comparison of internal consistency and retest correlations is problematic because situational factors may simply produce situation-specific measurement errors rather than reflecting real changes in the underlying trait; a problem that is well recognized in personality psychology. To examine this question more thoroughly, it is necessary to obtain multiple retests and decompose the variances into trait, state, and error variances (Anusic & Schimmack, 2016). Even this approach cannot distinguish between state variance and systematic measurement error, which requires multi-method data (Schimmack, 2019).
A Longitudinal Multi-Method Study of Racial Bias
A recent article reported the results of an impressive longitudinal study of racial bias with over 3,000 medical students who completed measures of racial bias and inter-group contact three times over a period of six year (first year of medical school, fourth year of medical school, 2nd year of residency) (Onyeador et al., 2019). I used the openly shared data to fit a multi-method state-trait-error model to the data (https://osf.io/78cqx/).
The model integrates several theoretical assumptions that are consistent with previous research (Schimmack, 2019). First, the model assumes that explicit ratings of racial bias (feeling thermometer) and implicit measures of racial bias (Implicit Association Test) are complementary measures of individual differences in racial bias. Second, the model assumes that one source of variance in racial bias is a stable trait. Third, the model assumes that racial bias differs across racial groups, in that Black individuals have more favorable attitudes towards Black people than members from other groups. Fourth, the model assumes that contact is negatively correlated with racial bias without making a strong causal assumption about the direction of this relationship. The model also assumes that Black individuals have more contact with Black individuals and that contact partially explains why Black individuals have less racial biases.
The new hypotheses that could be explored with these data concerned the presence of state variance in racial bias. First, state variance should produce correlations between the occasion specific variances of the two methods. That is, after statistically removing trait variance, residual state variance in feeling thermometer scores should be correlated with residual variances in IAT scores. For example, as medical students interact more with Black staff and patients in residency, their racial biases could change and this would produce changes in explicit ratings and in IAT scores. Second, state variance is expected to be somewhat stable over shorter time intervals because environments tend to be stable over shorter time intervals.
The model in Figure 1 met standard criteria of model fit, CFI = .997, RMSEA = .016.
Describing the model from left to right, race (0 = Black, 1 = White) has the expected relationship with quantity of contact (quant1) in year 1 (reflecting everyday interactions with Black individuals) and with the racial bias (att) factor. In addition, more contact is related to less pro-White bias (-.28). The attitude factor is a stronger predictor of the explicit trait factor (.78; ft; White feeling-thermometer – Black feeling-thermometer) than on the implicit trait factor (.60, iat). The influence of the explicit trait factor on measures on the three occasions (.58-.63) suggests that about one-third of the variance in these measures is trait variance. The same is true for individual IATs (.59-.62). The effect of the attitude factor on individual IATs (.60 * .60 = .36; .36^2 = .13 suggests that less than 20% of the variance in an individual IAT reflects racial bias. This estimate is consistent with the results from multi-method studies (Schimmack, 2019). However, these results suggests that the amount of valid trait variance can increase up to 36%, by aggregating scores of several IATs. In sum, these results provide first evidence that racial bias is stable over a period of six years and that both explicit ratings and implicit ratings capture trait variance in racial bias.
Turning to the bottom part of the model, there is weak evidence to suggest that residual variances (that are not trait variance) in explicit and implicit ratings are correlated. Although the correlation of r = .06 at time 1 is statistically significant, the correlations at time 2 (r = .03) and time 3 (r = .00) are not. This finding suggests that most of the residual variance is method specific measurement error rather than state-variance in racial bias. There is some evidence that the explicit ratings capture more than occasion-specific measurement error because state variance at time 1 predicts state variance at time 2 (r = .25) and from time 2 to time 3 (r = .20). This is not the case for the IAT scores. Finally, contact with Black medical staff at time 2 is a weak, but significant predictor of explicit measures of racial bias at time 2 and time 3, but it does not predict IAT scores at time 2 and 3. These findings do not support the hypothesis that changes in racial bias measures reflect real changes in racial biases.
The results are consistent with the only other multi-method longitudinal study of racial bias that covered only a brief period of three months. In this study, even implicit measures showed no convergent validity for the state (non-trait) variance on the same occasion (Cunningham, Preacher, & Banaji, 1995).
Conclusion
Examining predictors of individual differences in racial bias is important to understand the origins of racial biases and to develop interventions that help individuals to reduce their racial biases. Examining the stability of racial bias in longitudinal studies shows that these biases are stable dispositions and there is little evidence that they change with changing life-experiences. One explanation is that only close contact may be able to shift attitudes and that few people have close relationships with outgroup members. Thus stable environments may contribute to stability in racial bias.
Given the trait-like nature of racial bias, interventions that target attitudes and general dispositions may be relatively ineffective, as Onyeador et al.’s (2019) article suggested. Thus, it may be more effective to target and assess actual behaviors in diversity training. Expecting diversity training to change general dispositions may be misguided and lead to false conclusions about the effectiveness of diversity training programs.
In the old days, most scientific communication occured behind closed doors, when reviewers provide anonymous peer-reviews that determine the fate of manuscripts. In the old days, rejected manuscripts would not be able to contribute to scientific communications because nobody would know about them.
All of this has changed with the birth of open science. Now authors can share manuscripts on pre-print servers and researchers can discuss merits of these manuscripts on social media. The benefit of this open scientific communication is that more people can join in and contribute to the communication.
I have criticized their model in an in press article in Perspectives of Psychological Science (Schimmack, 2019). In a commentary, Yoav and Michelangelo argue that their model is “compatible with the logic of an MTMM investigation (Campbell & Fiske, 1959). They argue that it is important to have multiple traits to identify method variance in a matrix with multiple measures of multiple traits. They then propose that I lost the ability to identify method variance by examining one attitude (i.e., race, self-esteem, political orientation) at a time. They then point out that I did not include all measures and included the Modern Racism Scale as an indicator of political orientation to note that I did not provide a reason for these choices. While this is true, Yoav and Michelangelo had access to the data and could have tested whether these choices made any differences. They do not. This is obvious for the modern racism scale that can be eliminated from the measurement model without any changes in the overall model.
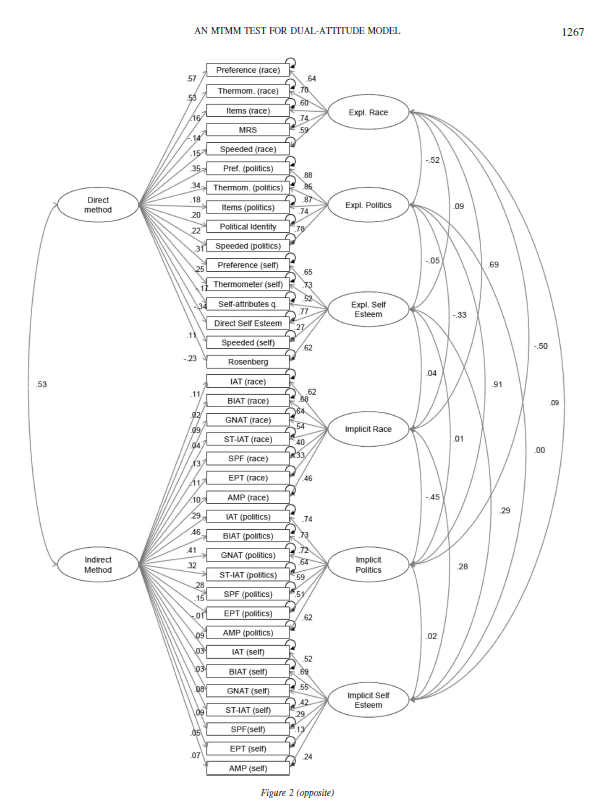
To cut to the chase, the main source of disagreement is the modelling of method variance in the multi-trait-multi-method data set. The issue is clear when we examine the original model published in Bar-Anan and Vianello (2018).
In this model, method variance in IATs and related tasks like the Brief IAT is modelled with the INDIRECT METHOD factor. The model assumes that all of the method variance that is present in implicit measures is shared across attitude domains and across all implicit measures. The only way for this model to allow for different amounts of method variance in different implicit measures is by assigning different loadings to the various methods. Moreover, the loadings provide information about the nature of the shared variance and the amount of method variance in the various methods. Although this is valuable and important information, the authors never discuss this information and its implications.
Many of these loadings are very small. For example, the loading of the race IAT and the brief race IAT are .11 and .02. In other words, the correlation between these two measures is inflated by .11 * .02 = .0022 points. This means that the correlation of r = .52 between these two measures is r = .5178 after we remove the influence of method variance.
It makes absolutely no sense to accuse me of separating the models, when there is no evidence of implicit method variance that is shared across attitudes. The remaining parameter estimates are not affected if a factor with low loadings is removed from a model.
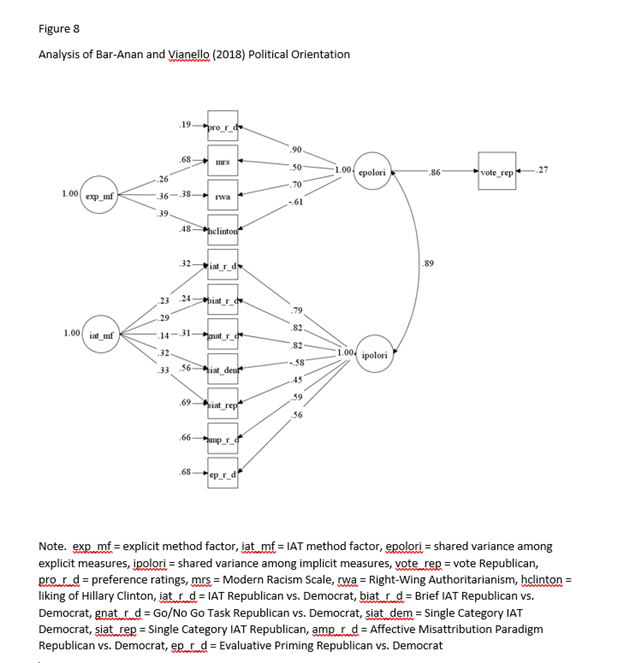
Here I show that examining one attitude at a time produces exactly the same results as the full model. I focus on the most controversial IAT; the race IAT. After all, there is general agreement that there is little evidence of discriminant validity for political orientation (r = .91, in the Figure above), and there is little evidence for any validity in the self-esteem IAT based on several other investigations of this topic with a multi-method approach (Bosson et al., 2000; Falk et al., 2015).
Model 1 is based on Yoav and Michelangelo’s model that assumes that there is practically no method variance in IAT-variants. Thus, we can fit a simple dual-attitude model to the data. In this model, contact is regressed onto implicit and explicit attitude factors to see the unique contribution of the two factors without making causal assumptions. The model has acceptable fit, CFI = .952, RMSEA = .013.
The correlation between the two factors is .66, while it is r = .69 in the full model in Figure 1. The loading of the race IAT on the implicit factor is .66, while it is .62 in the full model in Figure 1. Thus, as expected based on the low loadings on the IMPLICIT METHOD factor, the results are no different when the model is fitted only to the measure of racial attitudes.
Model 2 makes the assumption that IAT-variants share method variance. Adding the method factor to the model increased model fit, CFI = .973, RMSEA = .010. As the models are nested, it is also possible to compare model fit with a chi-square test. With five degrees of freedom difference, chi-square changed from 167. 19 to 112.32. Thus, the model comparison favours the model with a method factor.
The main difference between the models is that there the evidence is less supportive of a dual attitude model and that the amount of valid variance in the race IAT decreases from .66^2 = 43% to r = .47^2 = 22%.
In sum, the 2018 article made strong claims about the race IAT. These claims were based on a model that implied that there is no systematic measurement error in IAT scores. I showed that this assumption is false and that a model with a method factor for IATs and IAT-variants fits the data better than a model without such a factor. It also makes no theoretical sense to postulate that there is no systematic method variance in IATs, when several previous studies have demonstrated that attitudes are only one source of variance in IAT scores (Klauer, Voss, Schmitz, & Teige-Mocigemba, 2007).
How is it possible that the race IAT and other IATs are widely used in psychological research and on public websites to provide individuals with false feedback about their hidden attitudes without any evidence of its validity as an individual difference measure of hidden attitudes that influence behaviour outside of awareness?
The answer is that most of these studies assumed that the IAT is valid rather than testing its validity. Another reason is that psychological research is focused on providing evidence that confirms theories rather than subjecting theories to empirical tests that they may fail. Finally, psychologists ignore effect sizes. As a result, the finding that IAT scores have incremental predictive validity of less than 4% variance in a criterion is celebrated as evidence for the validity of IATs, but even this small estimate is based on underpowered studies and may shrink in replication studies (cf. Kurdi et al., 2019).
It is understandable that proponents of the IAT respond with defiant defensiveness to my critique of the IAT. However, I am not the first to question the validity of the IAT, but these criticisms were ignored. At least Banaji and Greenwald recognized in 2013 that they do “not have the luxury of believing that what appears true and valid now will always appear so” (p. xv). It is time to face the facts. It may be painful to accept that the IAT is not what it was promised to be 21 years ago, but that is what the current evidence suggests. There is nothing wrong with my models and their interpretation, and it is time to tell visitors of the Project Implicit website that they should not attach any meaning to their IAT scores. A more productive way to counter my criticism of the IAT would be to conduct a proper validation study with multiple methods and validation criteria that are predicted to be uniquely related to IAT scores in a preregistered study.
Here is a link to the manuscript, data, and MPLUS scripts for reproducibility. https://osf.io/mu7e6/
ABSTRACT
Greenwald et al. (1998) proposed that the IAT measures
individual differences in implicit social cognition. This claim requires evidence of construct validity.
I review the evidence and show that there is insufficient evidence for this
claim. Most important, I show that few
studies were able to test discriminant validity of the IAT as a measure of
implicit constructs. I examine discriminant validity in several multi-method
studies and find no or weak evidence for discriminant validity. I also show
that validity of the IAT as a measure of attitudes varies across constructs. Validity
of the self-esteem IAT is low, but estimates vary across studies. About 20% of the variance in the race IAT
reflects racial preferences. The highest validity is obtained for measuring
political orientation with the IAT (64% valid variance). Most of this valid variance stems from a
distinction between individuals with opposing attitudes, while reaction times
contribute less than 10% of variance in the prediction of explicit attitude
measures. In all domains, explicit
measures are more valid than the IAT, but the IAT can be used as a measure of
sensitive attitudes to reduce measurement error by using a multi-method
measurement model.
Despite its popularity, relatively little is known about the construct validity of the IAT.
As Cronbach (1989) pointed out, construct validation is better examined by independent experts than by authors of a test because “colleagues are especially able to refine the interpretation, as they compensate for blind spots and capitalize on their own distinctive experience” (p. 163).
It is of utmost importance to determine how much of the variance in IAT scores is valid variance and how much of the variance is due to measurement error, especially when IAT scores are used to provide individualized feedback.
There is also no consensus in the literature whether the IAT measures something different from explicit measures.
In conclusion, while there is general consensus to make a distinction between explicit measures and implicit measures, it is not clear what the IAT measures
To complicate matters further, the validity of the IAT may vary across attitude objects. After all the IAT is a method, just like Likert scales are a method, and it is impossible to say that a method is valid (Cronbach, 1971).
At present, relatively little is known about the contribution of these three parameters to observed correlations in hundreds of mono-method studies.
A Critical Review
of Greenwald et al.’s (1998) Original Article
In conclusion, the seminal IAT article introduced the IAT as a measure of implicit constructs that cannot be measured with explicit measures, but it did not really test this dual-attitude model.
Construct Validity in 2007
In conclusion, the 2007 review of construct validity revealed major psychometric challenges for the construct validity of the IAT, which explains why some researchers have concluded that the IAT cannot be used to measure individual differences (Payne et al., 2017). It also revealed that most studies were mono-method studies that could not examine convergent and discriminant validity
Cunningham, Preacher and Banaji (2001)
Another noteworthy finding is that a single factor accounted for correlations among all measures on the same occasion and across measurement occasions. This finding shows that there were no true changes in racial attitudes over the course of this two-month study. This finding is important because Cunningham et al.’s (2001) study is often cited as evidence that implicit attitudes are highly unstable and malleable (e.g., Payne et al., 2017). This interpretation is based on the failure to distinguish random measurement error and true change in the construct that is being measured (Anusic & Schimmack, 2016). While Cunningham et al.’s (2001) results suggest that the IAT is a highly unreliable measure, the results also suggest that the racial attitudes that are measured with the race IAT are highly stable over periods of weeks or months.
Bar-Anan & Vianello, 2018
this large study of construct validity also provides little evidence for the original claim that the IAT measures a new construct that cannot be measured with explicit measures, and confirms the estimate from Cunningham et al. (2001) that about 20% of the variance in IAT scores reflects variance in racial attitudes.
Greenwald et al. (2009)
“When entered after the self-report measures, the two implicit measures incrementally explained 2.1% of vote intention variance, p=.001, and when political conservativism was also included in the model, “the pair of implicit measures incrementally predicted only 0.6% of voting intention variance, p = .05.” (Greenwald et al., 2009, p. 247).
I tried to reproduce these results with the published correlation matrix and failed to do so. I contacted Anthony Greenwald, who provided the raw data, but I was unable to recreate the sample size of N = 1,057. Instead I obtained a similar sample size of N = 1,035. Performing the analysis on this sample also produced non-significant results (IAT: b = -.003, se = .044, t = .070, p = .944; AMP: b = -.014, se = .042, t = 0.344, p = .731). Thus, there is no evidence for incremental predictive validity in this study.
Axt (2018)
With N = 540,723 respondents, sampling error is very small, σ = .002, and parameter estimates can be interpreted as true scores in the population of Project Implicit visitors. A comparison of the factor loadings shows that explicit ratings are more valid than IAT scores. The factor loading of the race IAT on the attitude factor once more suggests that about 20% of the variance in IAT scores reflects racial attitudes
Falk, Heine, Zhang, and Hsu (2015)
Most important, the self-esteem IAT and the other implicit measures have low and non-significant loadings on the self-esteem factor.
Bar-Anan & Vianello (2018)
Thus, low validity contributes considerably to low observed correlations between IAT scores and explicit self-esteem measures.
Bar-Anan & Vianello (2018) – Political Orientation
More important, the factor loading of the IAT on the implicit factor is much higher than for self-esteem or racial attitudes, suggesting over 50% of the variance in political orientation IAT scores is valid variance, π = .79, σ = .016. The loading of the self-report on the explicit ratings was also higher, π = .90, σ = .010
Variation of Implicit – Explicit Correlations Across Domains
This suggests that the IAT is good in classifying individuals into opposing groups, but it has low validity of individual differences in the strength of attitudes.
What Do IATs Measure?
The present results suggest that measurement error alone is often sufficient to explain these low correlations. Thus, there is little empirical support for the claim that the IAT measures implicit attitudes that are not accessible to introspection and that cannot be measured with self-report measures.
For 21 years the lack of discriminant validity has been overlooked because psychologists often fail to take measurement error into account and do not clearly distinguish between measures and constructs.
In the future, researchers need to be more careful when they make claims about constructs based on a single measure like the IAT because measurement error can produce misleading results.
Researchers should avoid terms like implicit attitude or implicit preferences that make claims about constructs simply because attitudes were measured with an implicit measure
Recently, Greenwald and Banaji (2017) also expressed concerns about their earlier assumption that IAT scores reflect unconscious processes. “Even though the present authors find themselves occasionally lapsing to use implicit and explicit as if they had conceptual meaning, they strongly endorse the empirical understanding of the implicit– explicit distinction” (p. 862).
How
Well Does the IAT Measure What it Measures?
Studies with the IAT can be divided into applied studies (A-studies) and basic studies (B-studies). B-studies employ the IAT to study basic psychological processes. In contrast, A-studies use the IAT as a measure of individual differences. Whereas B-studies contribute to the understanding of the IAT, A-studies require that IAT scores have construct validity. Thus, B-studies should provide quantitative information about the psychometric properties for researchers who are conducting A-studies. Unfortunately, 21 years of B-studies have failed to do so. For example, after an exhaustive review of the IAT literature, de Houwer et al. (2009) conclude that “IAT effects are reliable enough to be used as a measure of individual differences” (p. 363). This conclusion is not helpful for the use of the IAT in A-studies because (a) no quantitative information about reliability is given, and (b) reliability is necessary but not sufficient for validity. Height can be measured reliably, but it is not a valid measure of happiness.
This article provides the first quantitative information about validity of three IATs. The evidence suggests that the self-esteem IAT has no clear evidence of construct validity (Falk et al., 2015). The race-IAT has about 20% valid variance and even less valid variance in studies that focus on attitudes of members from a single group. The political orientation IAT has over 40% valid variance, but most of this variance is explained by group-differences and overlaps with explicit measures of political orientation. Although validity of the IAT needs to be examined on a case by case basis, the results suggest that the IAT has limited utility as a measurement method in A-studies. It is either invalid or the construct can be measured more easily with direct ratings.
Implications for the Use of IAT scores in Personality Assessment
I suggest to replace the reliability coefficient with the validity coefficient. For example, if we assume that 20% of the variance in scores on the race IAT is valid variance, the 95%CI for IAT scores from Project Implicit (Axt, 2018), using the D-scoring method, with a mean of .30 and a standard deviation of.46 ranges from -.51 to 1.11. Thus, participants who score at the mean level could have an extreme pro-White bias (Cohen’s d = 1.11/.46 = 2.41), but also an extreme pro-Black Bias (Cohen’s d = -.51/.46 = -1.10). Thus, it seems problematic to provide individuals with feedback that their IAT score may reveal something about their attitudes that is more valid than their beliefs.
Conclusion
Social psychologists have always distrusted self-report, especially for the measurement of sensitive topics like prejudice. Many attempts were made to measure attitudes and other constructs with indirect methods. The IAT was a major breakthrough because it has relatively high reliability compared to other methods. Thus, creating the IAT was a major achievement that should not be underestimated because the IAT lacks construct validity as a measure of implicit constructs. Even creating an indirect measure of attitudes is a formidable feat. However, in the early 1990s, social psychologists were enthralled by work in cognitive psychology that demonstrated unconscious or uncontrollable processes (Greenwald & Banaji, 1995). Implicit measures were based on this work and it seemed reasonable to assume that they might provide a window into the unconscious (Banaji & Greenwald, 2013). However, the processes that are involved in the measurement of attitudes with implicit measures are not the personality characteristics that are being measured. There is nothing implicit about being a Republican or Democrat, gay or straight, or having low self-esteem. Conflating implicit processes in the measurement of attitudes with implicit personality constructs has created a lot of confusion. It is time to end this confusion. The IAT is an implicit measure of attitudes with varying validity. It is not a window into people’s unconscious feelings, cognitions, or attitudes.
Most published psychological measures are unvalid. (subtitle) *unvalid = the validity of the measure is un-known.
2022/01/01 UPDATE This blog post attracted a lot of attention when it was first posted and served as a first draft for a manuscript that is now published in Meta-Psychology. You can find the published article here. (Meta-Psychology).
2025/01/11 UPDATE The article has attracted much less attention and most psychologists continue to ignore the problem that their measures have an unknown amount of measurement error and probably only modest construct validity. Thanks to AI, it is now possible to provide quick summaries of articles. Here is a summary that I find accurate and snappy that takes only a minute or two to read.
ChatGPT summary of my article.
Core Argument Schimmack argues that psychology faces a validation crisis, in addition to its replication crisis, due to widespread neglect of rigorous construct validation practices. Construct validity, introduced by Cronbach and Meehl (1955), is critical for ensuring that measures accurately reflect the theoretical constructs they are meant to assess. Without valid measures, even replicable findings can lead to false or misleading conclusions.
Key Points
Importance of Construct Validity – Construct validity ensures that variations in test scores reflect variations in the intended construct (e.g., anxiety or intelligence). – Validity is essential for meaningful theory testing and avoiding false inferences (e.g., correlating irrelevant variables like hair length with intelligence).
Current Problems in Psychological Measurement – Many widely used psychological measures lack proper validation. – Researchers often conflate reliability with validity, though reliability is necessary but insufficient for construct validity. – Claims about construct validity are often unsupported or vague, leading to a proliferation of questionable constructs and measures.
Cronbach and Meehl’s Recommendations (1955) – Nomological Networks: Valid measures should fit into a theoretical framework (relationships between constructs and observables). – Multi-Method Approach: Validation requires using multiple independent methods (e.g., self-reports, informant ratings, behavioral observations). – Quantification of Validity: Construct validity should be measured quantitatively, such as estimating the proportion of variance attributable to the construct. – Convergent and Discriminant Validity – Convergent Validity: Measures of the same construct using different methods should correlate. – Discriminant Validity: Measures of different constructs should not correlate highly unless theoretically expected.
Structural Equation Modeling (SEM) – SEM extends factor analysis, allowing researchers to test and refine models of constructs. – Construct validation should be an iterative process, where empirical data inform both measures and theoretical models.
Criticism of Current Practices – Over-reliance on single-method correlations and inadequate use of multi-method designs. – Lack of transparency and skepticism in evaluating claims of construct validity. – Resistance to updating or replacing outdated measures due to institutional inertia and bias.
Proposed Solutions – Embrace systematic, multi-method validation studies with clear standards for quantifying validity. – Critically evaluate existing measures and replace low-validity measures with improved ones. – Adopt structural equation modeling and other advanced techniques to refine the nomological networks of constructs.
Network Models vs. Nomological Networks – Network models focus on direct relationships among observables, neglecting the role of latent constructs and proper measurement.
Call to Action – Schimmack emphasizes the need for psychology to address its validation crisis with the same vigor as its replication crisis. – He advocates for making the 2020s the “decade of validation,” pushing for rigorous standards and better measures.
—————————- ———————————- —————————-
Here is the original blog post.
Introduction
8 years ago, psychologists started to realize that they have a replication crisis. Many published results do not replicate in honest replication attempts that allow the data to decide whether a hypothesis is true or false.
The replication crisis is sometimes attributed to the lack of replication studies before 2011. However, this is not the case. Most published results were replicated successfully. However, these successes were entirely predictable from the fact that only successful replications would be published (Sterling, 1959). These sham replication studies provided illusory evidence for theories that have been discredited over the past eight years by credible replication studies.
New initiatives that are called open science are likely to improve the replicability of psychological science in the future, although progress towards this goal is painfully slow.
This blog post addresses another problem in psychological science. I call it the validation crisis. Replicability is only one necessary feature of a healthy science. Another necessary feature of a healthy science is the use of valid measures. This feature of a healthy science is as obvious as the need for replicability. To test theories that relate theoretical constructs to each other (e.g., construct A influences construct B for individuals drawn from population P under conditions C), it is necessary to have valid measures of constructs. However, it is unclear which criteria a measure has to fulfill to have construct validity. Thus, even successful and replicable tests of a theory may be false because the measures that were used lacked construct validity.
Construct Validity
The classic article on “Construct Validity” was written by two giants in psychology; Cronbach and Meehl (1955). Every graduate student of psychology and surely every psychologists who published a psychological measure should be familiar with this article.
The article was the result of an APA task force that tried to establish criteria, now called psychometric properties, for tests to be published. The result of this project was the creation of the construct “Construct validity”
The chief innovation in the Committee’s report was the term construct validity. (p. 281).
Cronbach and Meehl provide their own definition of this construct.
Construct validation is involved whenever a test is to be interpreted as a measure of some attribute or quality which is not “operationally defined” (p. 282).
In modern language, construct validity is the relationship between variation in observed test scores and a latent variable that reflects corresponding variation in a theoretical construct (Schimmack, 2010).
Thinking about construct validity in this way makes it immediately obvious why it is much easier to demonstrate predictive validity, which is the relationship between observed tests scores and observed criterion scores than to establish construct validity, which is the relationship between observed test scores and a latent, unobserved variable. To demonstrate predictive validity, one can simply obtain scores on a measure and a criterion and compute the correlation between the two variables. The correlation coefficient shows the amount of predictive validity of the measure. However, because constructs are not observable, it is impossible to use simple correlations to examine construct validity.
The problem of construct validation can be illustrated with the development of IQ scores. IQ scores can have predictive validity (e.g., performance in graduate school) without making any claims about the construct that is being measured (IQ tests measure whatever they measure and what they measure predicts important outcomes). However, IQ tests are often treated as measures of intelligence. For IQ tests to be valid measures of intelligence, it is necessary to define the construct of intelligence and to demonstrate that observed IQ scores are related to unobserved variation in intelligence. Thus, construct validation requires clear definitions of constructs that are independent of the measure that is being validated. Without clear definition of constructs, the meaning of a measure reverts essentially to “whatever the measure is measuring,” as in the old saying “Intelligence is whatever IQ tests are measuring. This saying shows the problem of research with measures that have no clear construct and no construct validity.
In conclusion, the challenge in construct validation research is to relate a specific measure to a well-defined construct and to establish that variation in test scores are related to variation in the construct.
What are Constructs
Construct validation starts with an assumption. Individuals are assumed to have an attribute, today we may say personality trait. Personality traits are typically not directly observable (e.g., kindness rather than height), but systematic observation suggests that the attribute exists (some people are kinder than others across time and situations). The first step is to develop a measure of this attribute (e.g., a self-report measure “How kind are you?”). If the test is valid, variation in the observed scores on the measure should be related to the personality trait.
A construct is some postulated attribute of people, assumed to be reflected in test performance (p. 283).
The term “reflected” is consistent with a latent variable model, where unobserved traits are reflected in observable indicators. In fact, Cronbach and Meehl argue that factor analysis (not principle component analysis!) provides very important information for construct validity.
We depart from Anastasi at two points. She writes, “The validity of a psychological test should not be confused with an analysis of the factors which determine the behavior under consideration.” We, however, regard such analysis as a most important type of validation. (p. 286).
Factor analysis is useful because factors are unobserved variables and factor loadings show how strongly an observed measure is related to variation in a an unobserved variable; the factor. If multiple measures of a construct are available, they should be positively correlated with each other and factor analysis will extract a common factor. For example, if multiple independent raters agree in their ratings of individuals’ kindness, the common factor in these ratings may correspond to the personality trait kindness, and the factor loadings provide evidence about the degree of construct validity of each measure (Schimmack, 2010).
In conclusion, factor analysis provides useful information about construct validity of measures because factors represent the construct and factor loadings show how strongly an observed measure is related to the construct.
It is clear that factors here function as constructs (p. 287).
Convergent Validity
The term convergent validity was introduced a few years later in another seminal article on validation research by Campbell and Fiske (1959). However, the basic idea of convergent validity was specified by Cronbach and Meehl (1955) in the section “Correlation matrices and factor analysis”
If two tests are presumed to measure the same construct, a correlation between them is predicted (p. 287).
If a trait such as dominance is hypothesized, and the items inquire about behaviors subsumed under this label, then the hypothesis appears to require that these items be generally intercorrelated (p. 288)
Cronbach and Meehl realize the problem of using just two observed measures to examine convergent validity. For example, self-informant correlations are often used in personality psychology to demonstrate validity of self-ratings. However, a correlation of r = .4 between self-ratings and informant ratings is open to very different interpretations. The correlation could reflect very high validity of self-ratings and modest validity of informant ratings or the opposite could be true.
If the obtained correlation departs from the expectation, however, there is no way to know whether the fault lies in test A, test B, or the formulation of the construct. A matrix of intercorrelations often points out profitable ways of dividing the construct into more meaningful parts, factor analysis being a useful computational method in such studies. (p. 300)
A multi-method approach avoids this problem and factor loadings on a common factor can be interpreted as validity coefficients. More valid measures should have higher loadings than less valid measures. Factor analysis requires a minimum of three observed variables, but more is better. Thus, construct validation requires a multi-method assessment.
Discriminant Validity
The term discriminant validity was also introduced later by Campbell and Fiske (1959). However, Cronbach and Meehl already point out that high or low correlations can support construct validity. Crucial for construct validity is that the correlations are consistent with theoretical expectations.
For example, low correlations between intelligence and happiness do not undermine the validity of an intelligence measure because there is no theoretical expectation that intelligence is related to happiness. In contrast, low correlations between intelligence and job performance would be a problem if the jobs require problem solving skills and intelligence is an ability to solve problems faster or better.
Only if the underlying theory of the trait being measured calls for high item intercorrelations do the correlations support construct validity (p. 288).
Quantifying Construct Validity
It is rare to see quantitative claims about construct validity. Most articles that claim construct validity of a measure simply state that the measure has demonstrated construct validity as if a test is either valid or invalid. However, the previous discussion already made it clear that construct validity is a quantitative construct because construct validity is the relation between variation in a measure and variation in the construct and this relation can vary . If we use standardized coefficients like factor loadings to assess the construct validity of a measure, construct validity can range from -1 to 1.
Contrary to the current practices, Cronbach and Meehl assumed that most users of measures would be interested in a “construct validity coefficient.”
There is an understandable tendency to seek a “construct validity coefficient. A numerical statement of the degree of construct validity would be a statement of the proportion of the test score variance that is attributable to the construct variable. This numerical estimate can sometimes be arrived at by a factor analysis” (p. 289).
Cronbach and Meehl are well-aware that it is difficult to quantify validity precisely, even if multiple measures of a construct are available because the factor may not be perfectly corresponding with the construct.
Rarely will it be possible to estimate definite “construct saturations,” because no factor corresponding closely to the construct will be available (p. 289).
And nobody today seems to remember Cronbach and Meehl’s (1955) warning that rejection of the null-hypothesis, the test has zero validity, is not the end goal of validation research.
It should be particularly noted that rejecting the null hypothesis does not finish the job of construct validation (p. 290)
The problem is not to conclude that the test “is valid” for measuring- the construct variable. The task is to state as definitely as possible the degree of validity the test is presumed to have (p. 290).
One reason why psychologists may not follow this sensible advice is that estimates of construct validity for many tests are likely to be low (Schimmack, 2010).
The Nomological Net – A Structural Equation Model
Some readers may be familiar with the term “nomological net” that was popularized by Cronbach and Meehl. In modern language a nomological net is essentially a structural equation model.
The laws in a nomological network may relate (a) observable properties or quantities to each other; or (b) theoretical constructs to observables; or (c) different theoretical constructs to one another. These “laws” may be statistical or deterministic.
It is probably no accident that at the same time as Cronbach and Mehl started to think about constructs as separate from observed measures, structural equation model was developed as a combination of factor analysis that made it possible to relate observed variables to variation in unobserved constructs and path analysis that made it possible to relate variation in constructs to each other. Although laws in a nomological network can take on more complex forms than linear relationships, a structural equation model is a nomological network (but a nomological network is not necessarily a structural equation model).
As proper construct validation requires a multi-method approach and demonstration of convergent and discriminant validity, SEM is ideally suited to examine whether the observed correlations among measures in a mulit-trait-multi-method matrix are consistent with theoretical expectations. In this regard, SEM is superior to factor analysis. For example, it is possible to model shared method variance, which is impossible with factor analysis.
Cronbach and Meehl also realize that constructs can change as more information becomes available. It may also occur that the data fail to provide evidence for a construct. In this sense, construct validiation is an ongoing process of improved understanding of unobserved constructs and how they are related to observable measures.
Ideally this iterative process would start with a simple structural equation model that is fitted to some data. If the model does not fit, the model can be modified and tested with new data. Over time, the model would become more complex and more stable because core measures of constructs would establish the construct validity, while peripheral relationships may be modified if new data suggest that theoretical assumptions need to be changed.
When observations will not fit into the network as it stands, the scientist has a certain freedom in selecting where to modify the network (p. 290).
Too often psychologists use SEM only to confirm an assumed nomological network and it is often considered inappropriate to change a nomological network to fit observed data. However, SEM is as much testing of an existing construct as exploration of a new construct.
The example from the natural sciences was the initial definition of gold as having a golden color. However, later it was discovered that the pure metal gold is actually silver or white and that the typical yellow color comes from copper impurities. In the same way, scientific constructs of intelligence can change depending on the data that are observed. For example, the original theory may assume that intelligence is a unidimensional construct (g), but empirical data could show that intelligence is multi-faceted with specific intelligences for specific domains.
However, given the lack of construct validation research in psychology, psychology has seen little progress in the understanding of such basic constructs such as extraversion, self-esteem, or wellbeing. Often these constructs are still assessed with measures that were originally proposed as measures of these constructs, as if divine intervention led to the creation of the best measure of these constructs and future research only confirmed their superiority.
Instead many claims about construct validity are based on conjectures than empirical support by means of nomological networks. This was true in 1955. Unfortunately, it is still true over 50 years later.
For most tests intended to measure constructs, adequate criteria do not exist. This being the case, many such tests have been left unvalidated, or a finespun network of rationalizations has been offered as if it were validation. Rationalization is not construct validation. One who claims that his test reflects a construct cannot maintain his claim in the face of recurrent negative results because these results show that his construct is too loosely defined to yield verifiable inferences (p. 291).
Given the difficulty of defining constructs and finding measures for it, even measures that show promise in the beginning might fail to demonstrate construct validity later and new measures should show higher construct validity than the early measures. However, psychology shows no development in measures of the same construct. The most widely used measure of self-esteem is still Rosenberg’s scale from 1965 and the most widely used measure of wellbieng is still Diener et al.’s scale from 1984. It is not clear how psychology can make progress, if it doesn’t make progress in the development of nomological networks that provide information about constructs and about the construct validity of measures.
Cronbach and Meehl are clear that nomological networks are needed to claim construct validity.
To validate a claim that a test measures a construct, a nomological net surrounding the concept must exist (p. 291).
However, there are few attempts to examine construct validity with structural equation models (Connelly & Ones, 2010; Zou, Schimmack, & Gere, 2013). [please share more if you know some]
One possible reason is that construct validation research may reveal that authors initial constructs need to be modified or their measures have modest validity. For example, McCrae, Zonderman, Costa, Bond, and Paunonen (1996) dismissed structural equation modeling as a useful method to examine the construct validity of Big Five measures because it failed to support their conception of the Big Five as orthogonal dimensions with simple structure.
Recommendations for Users of Psychological Measures
The consumer can accept a test as a measure of a construct only when there is a strong positive fit between predictions and subsequent data. When the evidence from a proper investigation of a published test is essentially negative, it should be reported as a stop sign to discourage use of the test pending a reconciliation of test and construct, or final abandonment of the test (p. 296).
It is very unlikely that all hunches by psychologists lead to the discovery of useful constructs and development of valid tests of these constructs. Given the lack of knowledge about the mind, it is rather more likely that many constructs turn out to be non-existent and that measures have low construct validity.
However, the history of psychological measurement has only seen development of more and more constructs and more and more measures to measure this increasing universe of constructs. Since the 1990s, constructs have doubled because every construct has been split into an explicit and an implicit version of the construct. Presumably, there is even implicit political orientation or gender identity.
The proliferation of constructs and measures is not a sign of a healthy science. Rather it shows the inability of empirical studies to demonstrate that a measure is not valid or that a construct may not exist. This is mostly due to self-serving biases and motivated reasoning of test developers. The gains from a measure that is widely used are immense. Thus, weak evidence is used to claim that a measure is valid and consumers are complicit because they can use these measures to make new discoveries. Even when evidence shows that a measure may not work as intended (e.g., Bosson et al., 2000), it is often ignored (Greenwald & Farnham, 2001).
Conclusion
Just like psychologist have started to appreciate replication failures in the past years, they need to embrace validation failures. Some of the measures that are currently used in psychology are likely to have insufficient construct validity. If this was the decade of replication, the 2020s may become the decade of validation, and maybe the 2030s may produce the first replicable studies with valid measures. Maybe this is overly optimistic, given the lack of improvement in validation research since Cronbach and Meehl (1955) outlined a program of construct validation research. Ample citations show that they were successful in introducing the term, but they failed in establishing rigorous criteria of construct validity. The time to change this is now.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.