Citation:
Schimmack, U. (2021). Invalid Claims About the Validity of Implicit Association Tests by Prisoners of the Implicit Social-Cognition Paradigm. Perspectives on Psychological Science, 16(2), 435–442. https://doi.org/10.1177/1745691621991860
This post has been revised on March 12, 2021 to make it consistent with the published version (https://doi.org/10.1177/1745691621991860) of my response to commentaries by Vianello and Bar-Anan and Kurdi, Ratliff, and Cunningham in response to my target article about the lack of construct validity of IATs (Schimmack, 2021).
Invalid Claims about the Validity of Implicit Association Tests by Prisoners of the Implicit Social-Cognition Paradigm
Abstract
In a prior publication, I used structural equation modeling of multimethod data to examine the construct validity of Implicit Association Tests. The results showed no evidence that IATs measure implicit constructs (e.g., implicit self-esteem, implicit racial bias). This critique of IATs elicited several responses by implicit social-cognition researchers, who tried to defend the validity and usefulness of IATs. I carefully examine these arguments and show that they lack validity. IAT proponents consistently ignore or misrepresent facts that challenge the validity of IATs as measures of individual differences in implicit cognitions. One response suggests that IATs can be useful even if they merely measure the same constructs as self-report measures, but I find no support for the claim that IATs have practically significant incremental predictive validity. In conclusions, IATs are widely used without psychometric evidence of construct or predictive validity.
Keywords
implicit attitudes, Implicit Association Test, validity, prejudice, suicide, mental health
Greenwald and colleagues (1998) introduced Implicit Association Tests (IATs) as a new method to measure individual differences in implicit cognitions. Twenty years later, IATs are widely used for this purpose, but their construct validity has not been established. Even its creator is no longer sure what IATs measure. Whereas Banaji and Greenwald (2013) confidently described
IATs as “a method that gives the clearest window now available into a region of the mind that is inaccessible to question-asking methods” (p. xiii), they now claim that IATs merely measure “the strengths of associations among concepts” (Cvencek et al., 2020, p. 187). This is akin to saying that an old-fashioned thermometer measures the expansion of mercury: It is true, but it has little to do with thermometers’ purpose of measuring temperature.
Fortunately, we do not need Greenwald or Banaji to define the constructs that IATs are supposed to measure. Twenty years of research with IATs makes it clear what researchers believe they are measuring with IATs. A self-esteem IAT is supposed to measure implicit self-esteem (Greenwald & Farnham, 2000). A race IAT is supposed to measure implicit prejudice (Cunningham et al., 2001), and a suicide IAT is supposed to measure implicit suicidal tendencies that can predict suicidal behaviors above and beyond self-reports (Kurdi et al.,
2021). The empirical question is whether IATs are any good at measuring these constructs. I concluded that most IATs are poor measures of their intended constructs (Schimmack, 2021). This conclusion elicited one implicit and two explicit responses.
Implicit Response
The implicit response is to simply ignore criticism and to make invalid claims about the construct validity of IATs (Greenwald & Lai, 2020). For example, a 2020 article coauthored by Nosek, Greenwald, and Banaji (among others) claimed that “available evidence for validity of
IAT measures of self-esteem is limited (Bosson et al., 2000; Greenwald & Farnham, 2000), with some of the strongest evidence coming from empirical tests of the balance-congruity principle” (Cvencek et al., 2020, p. 191). This statement is as valid as Donald Trump’s claim that an honest count of votes would make him the winner of the 2020 election. Over the past 2 decades, several articles have concluded that self-esteem IATs lack validity (Buhrmester et al., 2011; Falk et al., 2015; Walker & Schimmack, 2008). It is unscientific to omit these references from a literature review.
The balance-congruity principle is also not a strong test of the claim that the self-esteem IAT is a valid measure of individual differences in implicit self-esteem. In contrast, the lack of convergent validity with informant ratings and even other implicit measures of
self-esteem provides strong evidence that self-esteem IATs are invalid (Bosson et al., 2000; Falk et al., 2015). Finally, supporting evidence is surprisingly weak. For example, Greenwald and Farnham’s (2000) highly cited article tested predictive validity of the self-esteem IAT with responses to experimentally manipulated successes and failures (n = 94). They did not even report statistical results. Instead, they suggested that even nonsignificant results should be counted as evidence for the validity of the self-esteem IAT:
Although p values for these two effects straddled the p = .05 level that is often treated as a boundary between noteworthy and ignorable results, any inclination to dismiss these findings should be tempered by noting that these two effects agreed with prediction in both direction and shape. (Greenwald & Farnham, 2000, p. 1032)
Twenty years later, this finding has not been replicated, and psychologists have learned to distrust p values that are marginally significant (Benjamin et al., 2018; Schimmack, 2012, 2020). In conclusion, conflict of interest and motivated biases undermine the objectivity of Greenwald and colleagues in evaluations of IATs’ validity.
Explicit Response 1
Vianello and Bar-Anan (2021) criticized my structural equation models of their data. They also presented a new model that appeared to show incremental predictive validity for implicit racial bias and implicit political orientation. I thought it would be possible to resolve some of the disagreement in a direct and open communication with the authors because the disagreement
is about modeling of the same data. I was surprised when the authors declined this offer, given that Bar- Anan coauthored an article that praised the virtues of open scientific communication (Nosek & Bar-Anan, 2012). Readers therefore have to reconcile conflicting viewpoints for themselves. To ensure full transparency, I published syntax, outputs, and a detailed discussion
of the different modeling assumptions on OSF at https://osf.io/wsqfb/.
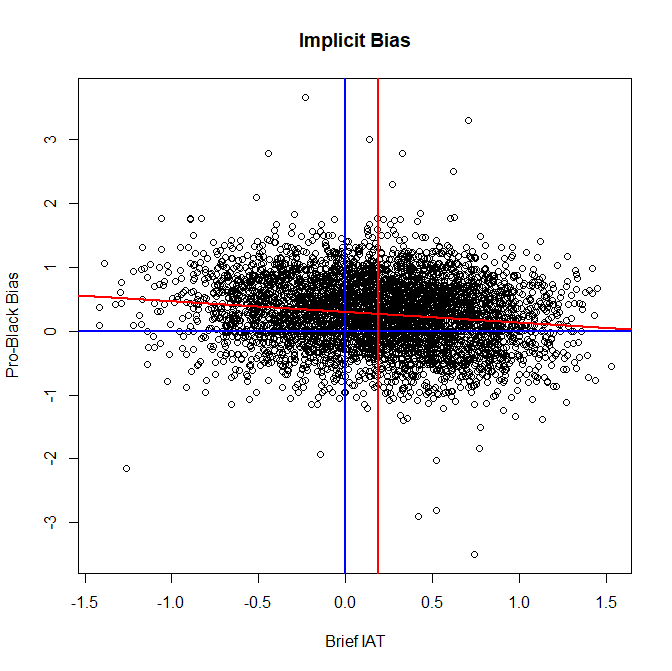
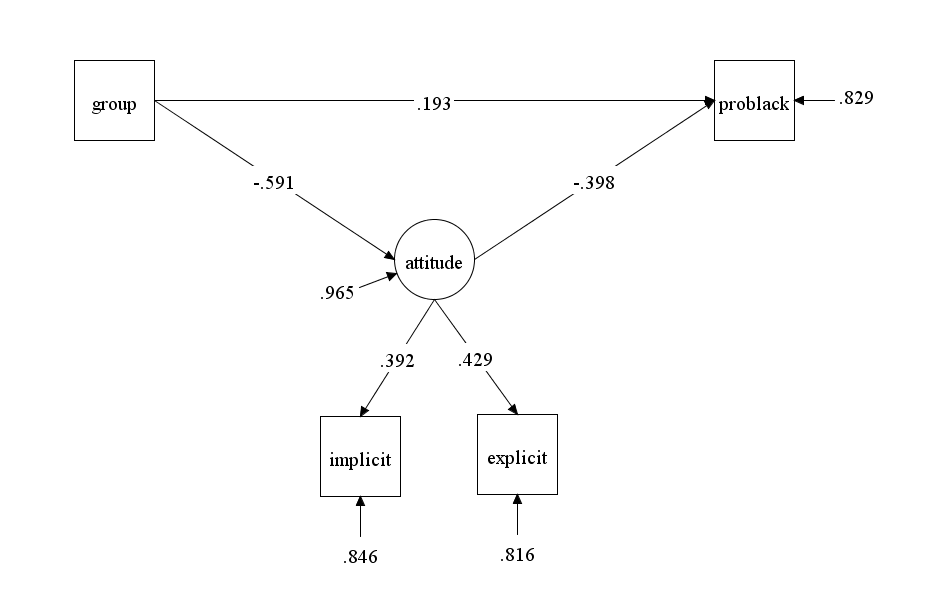
In brief, a comparison of the models shows that mine is more parsimonious and has better fit than their model. Because the model is more parsimonious, better fit cannot be attributed to overfitting of the data. Rather, the model is more consistent with the actual data, which in most sciences is considered a good reason to favor a model. Vianello and Bar-Anan’s model also produced unexplained, surprising results. For example, the race IAT has only a weak positive loading on the IAT method factor, and the political-orientation IAT even has a moderate negative loading. It is not clear how a method can have negative loadings on a method factor,
and Vianello and Bar-Anan provided no explanation for this surprising finding.
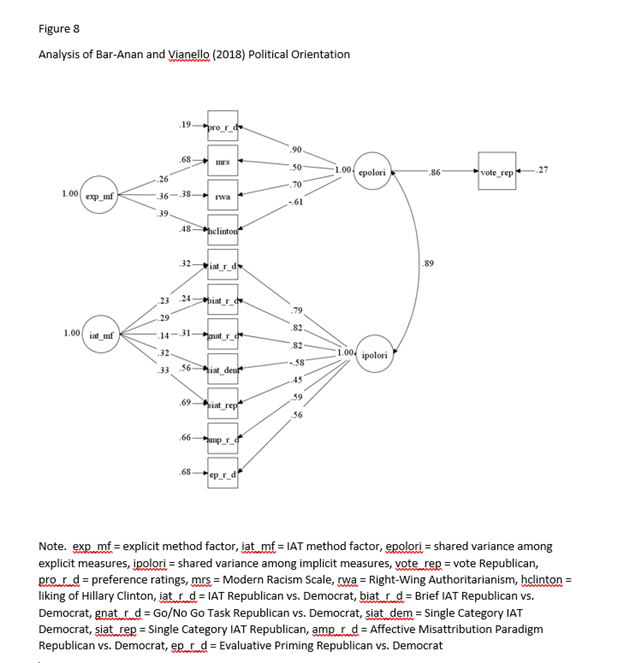
The two models also produce different results regarding incremental predictive validity (Table 1). My model shows no incremental predictive validity for implicit factors. It is also surprising that Vianello and Bar-Anan found incremental predictive validity for voting behaviors,
because the explicit and implicit factors correlated (r) at .9. This high correlation leaves little room for variance in implicit political orientation that is distinct from political orientation measured with self-ratings.
In conclusion, Vianello and Bar-Anan failed to challenge my conclusion that implicit and explicit measures measure mostly the same constructs and that low correlations between explicit and implicit measures reflect measurement error rather than some hidden implicit processes.

Explicit Response 2
The second response (Kurdi et al., 2021) is a confusing 7,000-word article that is short of facts, filled with false claims, and requires more fact-checking than a Trump interview.
False fact 1
The authors begin with the surprising statement that my findings are “not at all incompatible with the way that many social cognition researchers have thought about the construct of (implicit) evaluation” (p. 423). This statement is misleading. For 3 decades, social-cognition
researchers have pursued the idea that many social-cognitive processes that guide behavior occur outside of awareness. For example, Nosek et al. (2011) claim “most human cognition occurs outside conscious awareness or conscious control” (p. 152) and go on to claim that IATs “measure something different from self-report” (p. 153). And just last year, Greenwald and Lai
(2020) claimed that “in the last 20 years, research on implicit social cognition has established that social judgments and behavior are guided by attitudes and stereotypes of which the actor may lack awareness” (p. 419).
Social psychologists have also been successful in making the term implicit bias a common term in public discussions of social behavior. The second author, Kathy Ratliff, is director of Project Implicit, which “has a mission to develop and deliver methods for investigating and applying phenomena of implicit social cognition, including especially phenomena of implicit bias based on age, race, gender or other factors” (Kurdi et al., 2021, p. 431). It is not clear what this statement means if we do not make a distinction between traditional research on prejudice with self-report measures and the agenda of Project Implicit to study implicit biases with IATs.
In addition, all three authors have published recent articles that allude to IATs as measures of implicit cognitions.
In a highly cited American Psychologist article, Kurdi and coauthors (2019) claim “in addition to dozens of studies that have established construct validity . . . investigators have asked to what extent, and under what conditions, individual differences in implicit attitudes, stereotypes, and identity are associated with variation in behavior toward individuals as a function of their social group membership” (p. 570). The second author coauthored an article with the claim that “Black participants’ implicit attitudes reflected no ingroup/ outgroup preference . . . Black participants’ explicit attitudes reflected an ingroup preference” ( Jiang et al.,
2019). In 2007, Cunningham wrote that the “distinction between automatic and controlled processes now lies at the heart of several of the most influential models of evaluative processing” (Cunningham & Zelazo, 2007, p. 97). And Cunningham coauthored a review article with the claim that “a variety of tasks have been used to reflect implicit psychopathology associations, with the IAT (Greenwald et al., 1998) used most widely” (Teachman
et al., 2019). Finally, many users of IATs assume that they are measuring implicit constructs that are distinct from constructs that are measured with self-ratings. It is therefore a problem for the construct validity of IATs if they lack discriminant validity. At the least, Kurdi et al. fail to explain why anybody should use IATs if they merely measure the same constructs that can be
measured with cheaper self-ratings. In short, the question whether IATs and explicit measures reflect the same constructs or different constructs has theoretical and empirical relevance, and lack of discriminant validity is a problem for many theories of implicit cognitions (but see Cunningham & Zelazo, 2007).
False fact 2
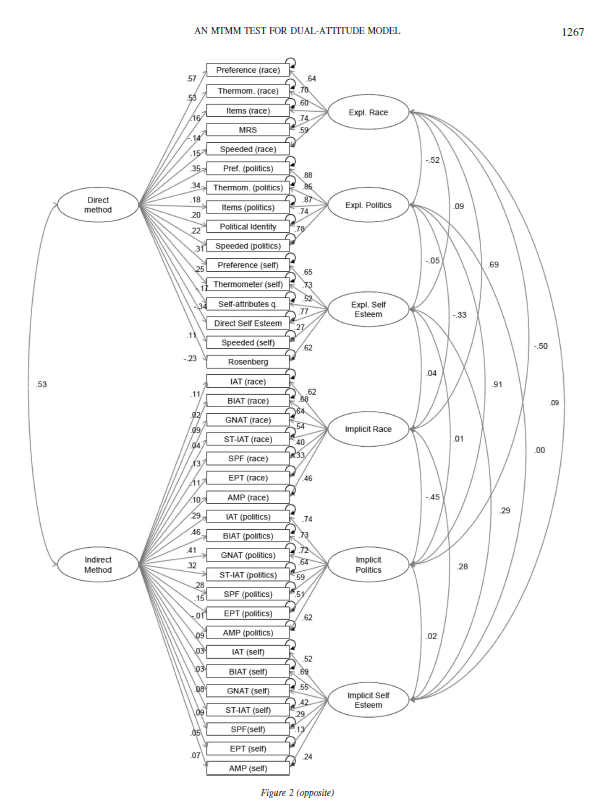
A more serious false claim is that I found “high correlations between relatively indirect (automatic) measures of mental content, as indexed by the IAT, and relatively direct (controlled) measures of mental content, as indexed by a variety of self-report scales” (p. 423). Table 2 shows some of the correlations among implicit and explicit measures in Vianello and Bar-Anan’s data. Only one of these correlations meets the standard criterion of a high correlation (i.e., r = .5; Cohen, 1988). The other correlations are small to moderate. These correlations show at best moderate convergent validity and no evidence of discriminant validity (i.e., higher implicit-implicit than implicit-explicit correlations). Similar results have been reported since the first IATs were created (Bosson et al., 2000). For 20 years, IAT researchers have ignored these low correlations and made grand claims about the validity of IATs. Kurdi et al. are doubling
down on this misinformation by falsely describing these correlations as high.

False fact 3
The third false claim is that “plenty of evidence in favor of dissociations between direct and indirect measures exists” (p. 428). To support this claim, Kurdi et al. cite a meta-analysis of incremental predictive validity (Kurdi et al., 2019). There are several problems with this claim.
First, the meta-analysis corrects only for random measurement error and not systematic measurement error. To the extent that systematic measurement error is present, incremental validity will shrink because explicit and implicit factors are very highly correlated when both sources of error are controlled (Schimmack, 2021). Second, Kurdi et al. fail to mention effect sizes. The meta-analysis suggests that a perfectly reliable IAT would explain about 2% unique variance. However, IATs have only modest reliability. Thus, manifest IAT scores would explain even less unique variance. Finally, even this estimate has to be interpreted with caution because the meta-analysis did not correct for publication bias and included some questionable studies. For example, Phelps et al. (2003) report, among 12 participants, a correlation of .58 between scores on the race IAT and differences in amygdala activation in response to Black and White faces. Assuming 20% valid variance in the IAT scores (Schimmack, 2021), the validation- corrected correlation would be 1.30. In other words, a correlation of .58 is impossible given the low validity of race-IAT scores. It is well known that correlations in functional MRI studies with small samples are not credible (Vul et al., 2009). Moreover, brain activity is not a social behavior. It is therefore unclear why studies like this were included in Kurdi et al.’s (2019) meta-analysis.
Kurdi et al. also used suicides as an important outcome that can be predicted with suicide and death IATs. They cited two articles to support this claim. Fact checking shows that one article reported a statistically significant result (p = .013; Barnes et al., 2017), whereas the other one did not (p > .50; Glenn et al., 2019). I conducted a meta-analysis of all studies that reported incremental predictive validity of suicide or death IATs. The criterion was suicide attempts in the next 3 to 6 months (Table 3). I found eight studies, but six of them came from a single lab (Matthew K. Nock). Nock was also the first one to report a significant result in an extremely underpowered study that included only two suicide attempts (Nock & Banaji, 2007). Five of the eight studies showed a statistically significant result (63%), but the average observed power to achieve significance was only 42%. This discrepancy suggests the presence of publication bias (Schimmack, 2012). Moreover, significant results are all clustered around .05, and none
of the p values meets the stricter criterion of .005 that has been suggested by Nosek and others to claim a discovery (Benjamin et al., 2018). Thus, there is no conclusive evidence to suggest that suicide IATs have incremental predictive validity in the prediction of suicides. This is not surprising because most of the studies were underpowered and unlikely to detect small effects.
Moreover, effect sizes are bound to be small because the convergent validity between suicide and death IATs is low (r = .21; Chiurliza et al., 2018), suggesting that most of the variance in these IATs is measurement error.
In conclusion, 20 years of research with IATs has produced no credible and replicable evidence that IATs have incremental predictive validity over explicit measures. Even if there is some statistically significant incremental predictive validity, the amount of explained
variance may lack practical significance (Kurdi et al., 2019).

False fact 4
Kurdi et al. (2021) object (p. 424) to my claim that “most researchers regard the IAT as a valid measure of enduring attitudes that vary across individuals” (Schimmack, 2021, p. 397). They claim that “the overwhelming theoretical consensus in the community of attitude researchers.
. . is that attitudes emerge from an interaction of persons and situations” (p. 425). It is instructive to compare this surprising claim with Cunningham and Zelazo’s (2007) definition of attitudes as “relatively stable ideas about whether something is good or bad” (p. 97). Kurdi and Banaji (2017) wrote that “differences in implicit attitudes . . . may arise because of multiple components, including relatively stable components [emphasis added]” (p. 286). Rae and Greenwald (2017) stated that it is a “widespread assumption . . . that implicit attitudes are characteristics of people, almost certainly more so than a property of situations” (p. 297).
Greenwald and Lai (2020) stated that test–retest reliability “places an upper limit on correlational tests of construct validity” (p. 425). This statement makes sense only if we assume that the construct to be measured is stable over the retest interval. It is also not clear how it would be ethical to provide individuals with feedback about their IAT scores on the Project Implicit website, if IAT scores were merely a product of the specific situation at the moment they are taking the test. Finally, how can the suicide IAT be a useful predictor of suicide if it cannot not measure some stable dispositions related to suicidal behaviors?
In conclusion, Kurdi et al.’s definition of attitudes is inconsistent with the common definition of attitudes as relatively enduring evaluations. That being said, the more important question is
whether IATs measure stable attitudes or momentary situational effects. Ironically, some of the best evidence comes from Cunningham. Cunningham et al. (2001) repeatedly measured prejudice four times over a 3-month period with multiple measures, including the race IAT. Cunningham et al. (2001) modeled the data with a single trait factor that explained all of the covariation among different measures of racial attitudes. Thus, Cunningham et al. (2001) provided first evidence that most of the valid variance in race IAT scores is perfectly stable over a 3-month period and that person-by-situation interactions had no effect on racial attitudes. There have been few longitudinal studies with IATs since Cunningham et al.’s (2001) seminal study. However, last year, an article examined stability over a 6-year interval (Onyeador et al., 2020). Racial attitudes of more than 3,000 medical students were measured in the first year of medical school, the fourth year of medical school, and the second year of medical residency.
Table 4 shows the correlations for the explicit feeling thermometer and the IAT scores. The first observation is that the Time-1-to-Time-3 correlation for the IAT scores is not smaller than the Time-1-to-Time-2 or the Time-2-to-Time-3 correlations. This pattern shows that a single trait factor can capture the shared variance among the repeated IAT measures. The second observation is that the bold correlations between explicit ratings and IAT scores on the same occasion are only slightly higher than the correlations for different measurement
occasions. This finding shows that there is very little occasion-specific variance in racial attitudes. The third observation is that IAT correlations over time are higher than the corresponding FT-IAT correlations over time. This finding points to IAT-specific method variance that is revealed in studies with multiple implicit measures (Cunningham et al., 2001; Schimmack, 2021). These findings extend Cunningham et al.’s (2001) findings to
a 6-year period and show that most of the valid variance in race IAT scores is stable over long periods of time.

In conclusion, Kurdi et al.’s claims about person-by-situation effects are not supported by evidence.
Conclusion
Like presidential debates, the commentaries and my response present radically different views of reality. In one world, IATs are valid and useful tools that have led to countless new insights into human behavior. In the other world, IATs are noisy measures that add nothing to the information we already get from cheaper self-reports. Readers not well versed in the literature are likely to be confused rather than informed by these conflicting accounts. Although we may expect such vehement disagreement in politics, we should not expect it among scientists.
A common view of scientists is that they are able to resolve disagreement by carefully looking at data and drawing logical conclusions from empirical facts. However, this model of scientists is naive and wrong.
A major source of disagreement among psychologists is that psychology lacks an overarching paradigm; that is, a set of fundamentally shared assumptions and facts. Psychology does not have one paradigm, but many paradigms. The IAT was developed within the implicit social-cognition paradigm that gained influence in the 1990s (Bargh et al., 1996; Greenwald & Banaji, 1995; Nosek et al., 2011). Over the past decade, it has become apparent that the empirical foundations of this paradigm are shaky (Doyen et al., 2012; D. Kahneman quoted in Yong, 2012, Supplemental Material; Schimmack, 2020). It took a long time to see the problems because paradigms are like prisons that make it impossible to see the world from the outside. A key force that prevents researchers within a paradigm from noticing problems is publication bias. Publication bias ensures that studies that are consistent with a paradigm are published, cited, and highlighted in review articles to provide false evidence in support for a paradigm
(Greenwald & Lai, 2020; Kurdi et al., 2021).
Over the past decade, it has become apparent how pervasive these biases have been, especially in social psychology (Schimmack, 2020). The responses to my critique of IATs merely confirms how powerful paradigms and conflicts of interest can be. It is therefore necessary to allocate more resources to validation projects by independent researchers. In addition, validation studies should be preregistered and properly powered, and results need to be published whether they show validity or not. Conducting validation studies of widely used measures could be an important role for the emerging field of meta-psychology that is not focused on new discoveries, but rather on evaluating paradigmatic research from an outsider, meta-perspective (Carlsson et al., 2017). Viewed from this perspective, many IATs that are in use lack credible evidence of construct validity.
References
*References marked with an asterisk report studies included in
the suicide IAT meta-analysis
Banaji, M. R., & Greenwald, A. G. (2013). Blindspot: Hidden
biases of good people. Delacorte Press.
Bargh, J. A., Chen, M., & Burrows, L. (1996). Automaticity
of social behavior: Direct effects of trait construct and
stereotype activation on action. Journal of Personality
and Social Psychology, 71(2), 230–244. https://doi.org/
10.1037/0022-3514.71.2.230
*Barnes, S. M., Bahraini, N. H., Forster, J. E., Stearns-Yoder, K. A.,
Hostetter, T. A., Smith, G., Nagamoto, H. T., & Nock,
M. K. (2017). Moving beyond self-report: Implicit associations
about death/ life prospectively predict suicidal
behavior among veterans. Suicide and Life-Threatening
Behavior, 47, 67–77. https://doi.org/10.1111/sltb.12265
Benjamin, D. J., Berger, J. O., Johannesson, M., Nosek, B. A.,
Wagenmakers, E.-J., Berk, R., Bollen, K. A., Brembs, B.,
Brown, L., Camerer, C., Cesarini, D., Chambers, C. D.,
Clyde, M., Cook, T. D., Boeck, P., De, Dienes, Z., Dreber,
A., Easwaran, K., Efferson, C., . . . Johnson, V. E. (2018).
Redefine statistical significance. Nature Human Behaviour,
2, 6–10.
Bosson, J. K., Swann, W. B. Jr., & Pennebaker, J. W. (2000).
Stalking the perfect measure of implicit self-esteem:
The blind men and the elephant revisited? Journal of
Personality and Social Psychology, 79, 631–643. https://
doi.org/10.1037/0022-3514.79.4.631
Buhrmester, M. D., Blanton, H., & Swann, W. B., Jr. (2011).
Implicit self-esteem: Nature, measurement, and a new way
forward. Journal of Personality and Social Psychology,
100(2), 365–385. https://doi.org/10.1037/a0021341
Carlsson, R., Danielsson, H., Heene, M., Ker, Å., Innes, Lakens,
D., Schimmack, U., Schönbrodt, F. D., van Assen, M., &
Weinstein, Y. Inaugural editorial of Meta-Psychology. Meta-
Psychology, 1. https://doi.org/10.15626/MP2017.1001
Chiurliza, B., Hagan, C. R., Rogers, M. L., Podlogar, M. C., Hom,
M. A., Stanley, I. H., & Joiner, T. E. (2018). Implicit measures
of suicide risk in a military sample. Assessment, 25(5),
667–676. https://doi.org/10.1177/1073191116676363
Cohen, J. (1988). Statistical power analysis for the behavioral
sciences (2nd ed.). Erlbaum.
Cunningham, W. A., Preacher, K. J., & Banaji, M. R. (2001).
Implicit attitude measures: Consistency, stability, and
No Evidence for Construct Validity of IAT 441
convergent validity. Psychological Science, 12(2), 163–170
https://doi.org/10.1111/1467-9280.00328
Cunningham, W. A., & Zelazo, P. D. (2007). Attitudes and
evaluations: A social cognitive neuroscience perspective.
Trends in Cognitive Sciences, 11, 97–104. https://
doi.org/10.1016/j.tics.2006.12.005
Cvencek, D., Meltzoff, A. N., Maddox, C. D., Nosek, B. A.,
Rudman, L. A., Devos, T., Dunham, Y., Baron, A. S.,
Steffens, M. C., Lane, K., Horcajo, J., Ashburn Nardo, L.,
Quinby, A., Srivastava, S. B., Schmidt, K., Aidman, E.,
Tang, E., Farnham, S., Mellott, D. S., . . . Greenwald, A. G.
(2020). Meta-analytic use of balanced identity theory to
validate the Implicit Association Test. Personality and
Social Psychology Bulletin, 47(2), 185–200. https://doi
.org/10.1177/0146167220916631
Doyen, S., Klein, O., Pichon, C. L., & Cleeremans, A. (2012).
Behavioral priming: It’s all in the mind, but whose mind?
PLOS ONE, 7(1), Article e29081. https://doi.org/10.1371/
journal.pone.0029081
Falk, C. F., Heine, S. J., Takemura, K., Zhang, C. X., & Hsu,
C. (2015). Are implicit self-esteem measures valid for
assessing individual and cultural differences. Journal of
Personality, 83, 56–68. https://doi.org/10.1111/jopy.12082
*Glenn, C. R., Millner, A. J., Esposito, E. C., Porter, A. C.,
& Nock, M. K. (2019). Implicit identification with death
predicts suicidal thoughts and behaviors in adolescents.
Journal of Clinical Child & Adolescent Psychology, 48,
263–272. https://doi.org/10.1080/15374416.2018.1528548
Greenwald, A. G., & Banaji, M. R. (1995). Implicit social cognition:
Attitudes, self-esteem, and stereotypes. Psychological
Review, 102(1), 4–27. https://doi.org/10.1037/0033-
295X.102.1.4
Greenwald, A. G., & Farnham, S. D. (2000). Using the Implicit
Association Test to measure self-esteem and self-concept.
Journal of Personality and Social Psychology, 79, 1022–1038
https://doi.org/10.1037/0022-3514.79.6.1022
Greenwald, A. G., & Lai, C. K. (2020). Implicit social cognition.
Annual Review of Psychology, 71, 419–445. https://
doi.org/10.1146/annurev-psych-010419-050837
Greenwald, A. G., McGhee, D. E., & Schwartz, J. L. K. (1998).
Measuring individual differences in implicit cognition:
The Implicit Association Test. Journal of Personality and
Social Psychology, 74, 1464–1480.
*Harrison, D. P., Stritzke, W. G. K., Fay, N., & Hudaib, A.-R.
(2018). Suicide risk assessment: Trust an implicit probe
or listen to the patient? Psychological Assessment, 30(10),
1317–1329. https://doi.org/10.1037/pas0000577
Jiang, C., Vitiello, C., Axt, J. R., Campbell, J. T., & Ratliff, K. A.
(2019). An examination of ingroup preferences among
people with multiple socially stigmatized identities. Self
and Identity. Advance online publication. https://doi.org/
10.1080/15298868.2019.1657937
Kurdi, B., & Banaji, M. R. (2017). Reports of the death of
the individual difference approach to implicit social cognition
may be greatly exaggerated: A commentary on Payne,
Vuletich, and Lundberg. Psychological Inquiry, 28,
281–287. https://doi.org/10.1080/1047840X.2017.1373555
Kurdi, B., Ratliff, K. A., & Cunningham, W. A. (2021). Can
the Implicit Association Test serve as a valid measure of
automatic cognition? A response to Schimmack (2021).
Perspectives on Psychological Science, 16(2), 422–434.
https://doi.org/10.1177/1745691620904080
Kurdi, B., Seitchik, A. E., Axt, J. R., Carroll, T. J., Karapetyan,
A., Kaushik, N., Tomezsko, D., Greenwald, A. G., &
Banaji, M. R. (2019). Relationship between the Implicit
Association Test and intergroup behavior: A meta-analysis.
American Psychologist, 74(5), 569–586. https://doi.org/
10.1037/amp0000364
*Millner, A. J., Augenstein, T. M., Visser, K. H., Gallagher, K.,
Vergara, G. A., D’Angelo, E. J., & Nock, M. K. (2019). Implicit
cognitions as a behavioral marker of suicide attempts in
adolescents. Archives of Suicide Research, 23(1), 47–63.
https://doi.org/10.1080/13811118.2017.1421488
*Nock, M. K., & Banaji, M. R. (2007). Prediction of suicide ideation
and attempts among adolescents using a brief performance-
based test. Journal of Consulting and Clinical
Psychology, 75(5), 707–715. https://doi.org/10.1037/0022-
006X.75.5.707
*Nock, M. K., Park, J. M., Finn, C. T., Deliberto, T. L.,
Dour, H. J., & Banaji, M. R. (2010). Measuring the suicidal
mind: Implicit cognition predicts suicidal behavior.
Psychological Science, 21(4), 511–517. https://doi
.org/10.1177/0956797610364762
Nosek, B. A., & Bar-Anan, Y. (2012). Scientific utopia: I. Opening
scientific communication. Psychological Inquiry, 23(3),
217–243. https://doi.org/10.1080/1047840X.2012.692215
Nosek, B. A., Hawkins, C. B., & Frazier, R. S. (2011). Implicit
social cognition: From measures to mechanisms. Trends
in Cognitive Sciences, 15(4), 152–159. https://doi.org/
10.1016/j.tics.2011.01.005
Onyeador, I. N., Wittlin, N. M., Burke, S. E., Dovidio, J. F.,
Perry, S. P., Hardeman, R. R., Dyrbye, L. N., Herrin, J.,
Phelan, S. M., & van Ryn, M. (2020). The value of interracial
contact for reducing anti-Black bias among non-Black
physicians: A Cognitive Habits and Growth Evaluation
(CHANGE) study report. Psychological Science, 31(1),
18–30. https://doi.org/10.1177/0956797619879139
Phelps, E. A., Cannistraci, C. J., & Cunningham, W. A. (2003).
Intact performance on an indirect measure of race bias
following amygdala damage. Neuropsychologia, 41(2),
203–208. https://doi.org/10.1016/s0028-3932(02)00150-1
Rae, J. R., & Greenwald, A. G. (2017). Persons or situations?
Individual differences explain variance in aggregated
implicit race attitudes. Psychological Inquiry, 28, 297–300.
https://doi.org/10.1080/1047840X.2017.1373548
*Randall, J. R., Rowe, B. H., Dong, K. A., Nock, M. K., &
Colman, I. (2013). Assessment of self-harm risk using
implicit thoughts. Psychological Assessment, 25(3), 714–721
https://doi.org/10.1037/a0032391
Schimmack, U. (2012). The ironic effect of significant results
on the credibility of multiple-study articles. Psychological
Methods, 17(4), 551–566. https://doi.org/10.1037/a0029487
Schimmack, U. (2020). A meta-psychological perspective on
the decade of replication failures in social psychology.
Canadian Psychology/Psychologie canadienne, 61(4),
364–376. http://doi.org/10.1037/cap0000246
Schimmack, U. (2021). The Implicit Association Test: A method
in search of a construct. Perspectives on Psychological Science, 16(2), 396–414. https://doi.org/10.1177/1745691619863798
Teachman, B. A., Clerkin, E. M., Cunningham, W. A., Dreyer-
Oren, S., & Werntz, A. (2019). Implicit cognition and
psychopathology: Looking back and looking forward.
Annual Review of Clinical Psychology, 15, 123–148.
https://doi.org/10.1146/annurev-clinpsy-050718-095718
*Tello, N., Harika-Germaneau, G., Serra, W., Jaafari, N., &
Chatard, A. (2020). Forecasting a fatal decision: Direct
replication of the predictive validity of the Suicide–
Implicit Association Test. Psychological Science, 31(1),
65–74. https://doi.org/10.1177/0956797619893062
Vianello, M., & Bar-Anan, Y. (2021). Can the Implicit Association
Test measure automatic judgment? The validation continues.
Perspectives on Psychological Science, 16(2), 415–421.
https://doi.org/10.1177/1745691619897960
Vul, E., Harris, C., Winkielman, P., & Pashler, H. (2009).
Puzzlingly high correlations in fMRI studies of emotion,
personality, and social cognition. Perspectives on
Psychological Science, 4(3), 274–290. https://doi.org/10
.1111/j.1745-6924.2009.01125.x
Walker, S. S., & Schimmack, U. (2008). Validity of a happiness
implicit association test as a measure of subjective wellbeing.
Journal of Research in Personality, 42, 490–497.
https://doi.org/10.1016/j.jrp.2007.07.005
Yong, E. (2012 October 12). Nobel laureate challenges
psychologists to clean up their act. Nature. https://doi
.org/10.1038/nature.2012.11535