For years, psychologists interested in their ‘impact’ could check their citation counts in Web of Science and see an increase. The main reason for this increase was the creation of more journals, including online journals without page limitations. The positive illusion of increasing importance came to a halt in 2021.

Figure 1. Citation count for the journal Psychological Science
The reason is probably that WebOfScience became more selective and delisted some low quality and possibly predatory journals. The end of exponential increases in citations is an interesting phenomenon in itself, but it is not the key focus of this blog post. The main question is whether the popping of the citation bubble also reflects concerns about the credibility of published articles in the wake of the replication crisis.
A useful analogy are stock market bubbles, like the valuation of new internet companies in the late 1990s. A bubble is created because investors buy stocks independent of the true value of a stock. Famous value-investor Warren Buffet quipped “Only when the tide goes out do you discover who’s been swimming naked” (not there is anything wrong with it).

After the crash of the dot.com bubble, companies like Pets.com lost all of their value. In contrast, (for better or worse) companies like Amazon.com became very valuable because they actually generated revenues and profits.
This blog post examines whether the citation-crash in 2021 affected all researchers equally or whether it discriminated between credible researchers that advanced science and researchers who produced articles with incredible results that are difficult to replicate and do not advance psychological science. The list of researchers is not meant to be representative in any way, but based on their significance during the replication crisis. My personal focus is on personality and social psychology. Readers interested in other research areas with access to WebOfScience can compare results for researchers they are interested in on their own.
Citations of Journals
To create a benchmark, i picked a small set of journals that represent social and personality research. For each journal, I recorded the peak (highest number of citations in a year), and the citations in 2023 and 2024. 2024 citations will still increase a bit over the next couple of month. So, a difference between 2023 and 2024 cannot be interpreted as a further decrease, yet. (I may update the numbers in a couple of months).
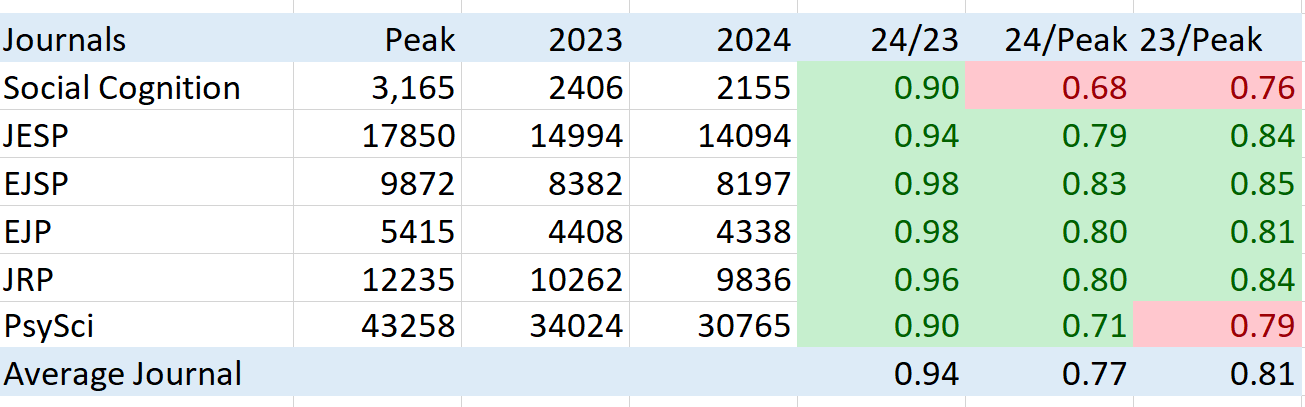
Note. JESP = Journal of Experimental Social Psychology, EJSP = European Journal of Social Psychology, EJP = European Journal of Personality, JRP = Journal of Research in Personality, PsySci = Psychological Science
The results are fairly consistent across journals. So far, the citation rates in 2024 are 90% or more of those in 2024. Thus, there is no evidence that citations are decreasing notably. The comparison of citations in 24 with the peak show that citations are now 20% to 30% below the peak (bear market territory in stock market language). The most notable drop is observed for Social Cognition, which may reflect the loss of trust or interest in social cognition research, which was hit hard by the replication crisis. The comparison of peak and citations in 2023, shows a similar pattern with a higher average because 2024 citations are not yet complete. Again, social cognition has the biggest drop. Psychological science which also published a lot of questionable research shows the second biggest drop, but there is no notable difference between social and personality journals in general. The averages provide a benchmark to examine trends for specific researchers. A loss in trust (or value in stock market language) would be revealed by bigger drops from the peak to recent years than the average drop for personality and social psychology journals.
Citation Counts of Prominent Social and Personality Psychologists
To provide context, i am presenting the results in order of the 24/Peak values that reflect the biggest drop in confidence.
1. Diderick Stapel
Diderick Stapel contributed to the loss of confidence in (social) psychology in 2011, when it emerged that he had faked data for numerous articles. After an investigation, 58 of his articles were retracted. It is remarkable that Stapel’s peak citation count is a meager 367, a number that pales in comparison to some of the citation counts below.

Citations have decreased to 27% of the peak in 2024 and 32% in 2023. The comparison of 24 and 23 suggests that citations are still decreasing (85% vs. 94% for the journal average). Evidently, awareness of fraud and retractions have produced a strong signal to neglect Stapel’s articles. However, this decrease is unrelated to the bust of the bubble in 2021. The correction appeared rather quickly after the discovery of fraud in 2011.
2. John A Bargh
John A Bargh is best known for his articles on priming without awareness, like his famous claim that reading a few words related to the elderly makes young students walk slower. This work was featured in the popular book of Nobel Laureate Daniel Kahneman along with other social priming studies. After a failed replication study, Kahneman wrote a letter to Bargh expressing his concerns about the replicability of social priming results. In the following years many of these results could not be replicated, confirming suspicion that these results were obtained with questionable research practices, including hiding of studies that did not show the predicted results (cf. Schimmack et al., 2017).
Citations for Bargh are now only 49% of the peak citations in 2014. Thus, it does not take fraud and retractions to correct citation bubbles based on questionable research. Bargh did not make up data like Stapel. Rather, he used unscientific ways to analyze data that increase the chances of obtaining a statistically significant and publishable result or simply conducting many studies and reporting only those that ‘worked.’
The bubble burst in 2014. While there was a slight uptick in citations in 2019, citations increased notably in the following years. With over 800 citations a year, the absolute number of citations is still high for psychology and suggests that many researchers still cite this work without awareness that social priming results are questionable.
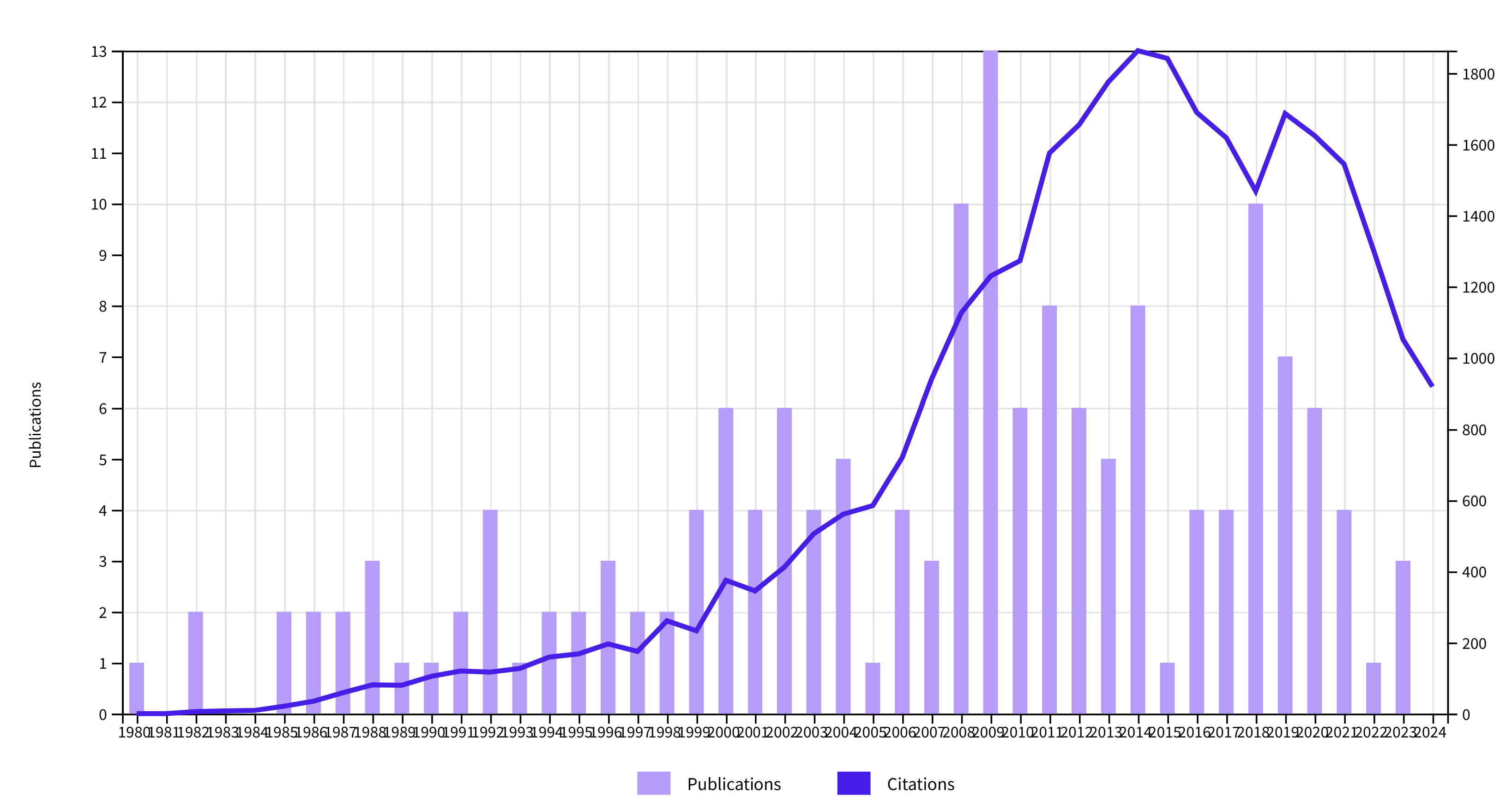
On a positive note, the decrease in citations is notably bigger than the average decrease from peak to 2024, 49% vs. 77%.

3. Fritz Strack
Fritz Strack is another social cognition researcher with a notable presence during the replication crisis in social psychology. For example, he wrote a meta-scientific article in defense of social psychology in the face of replicability problems (Strobe & Strack, 2014). Moreover, he is the author of an article that used a deceptive manipulation of facial muscles to provide evidence for the facial feedback theory of emotions. In 2019, he was awarded the IG Nobel Prize for this work. The results could not be replicated in one large replication attempts. is study failed to replicate in a big replication attempt, but he attributed this to problems with the replication study. However, another replication attempt in a project that he was actively involved in also failed. Another line of work suggested that item-order influences the correlation between life-satisfaction and domain satisfaction (e.g., marital satisfaction) judgments. This result was featured in Daniel Kahneman’s book and also failed to replicate. it is now generally accepted that life-satisfaction judgments are rather stable and based on chronically accessible information about important life domains. He is also a co-author on an article about an experimental manipulation of ease of retrieval that also failed to replicate (Schwarz et al., 1991).
The citation count peaked in 2021 and then decreased notably.
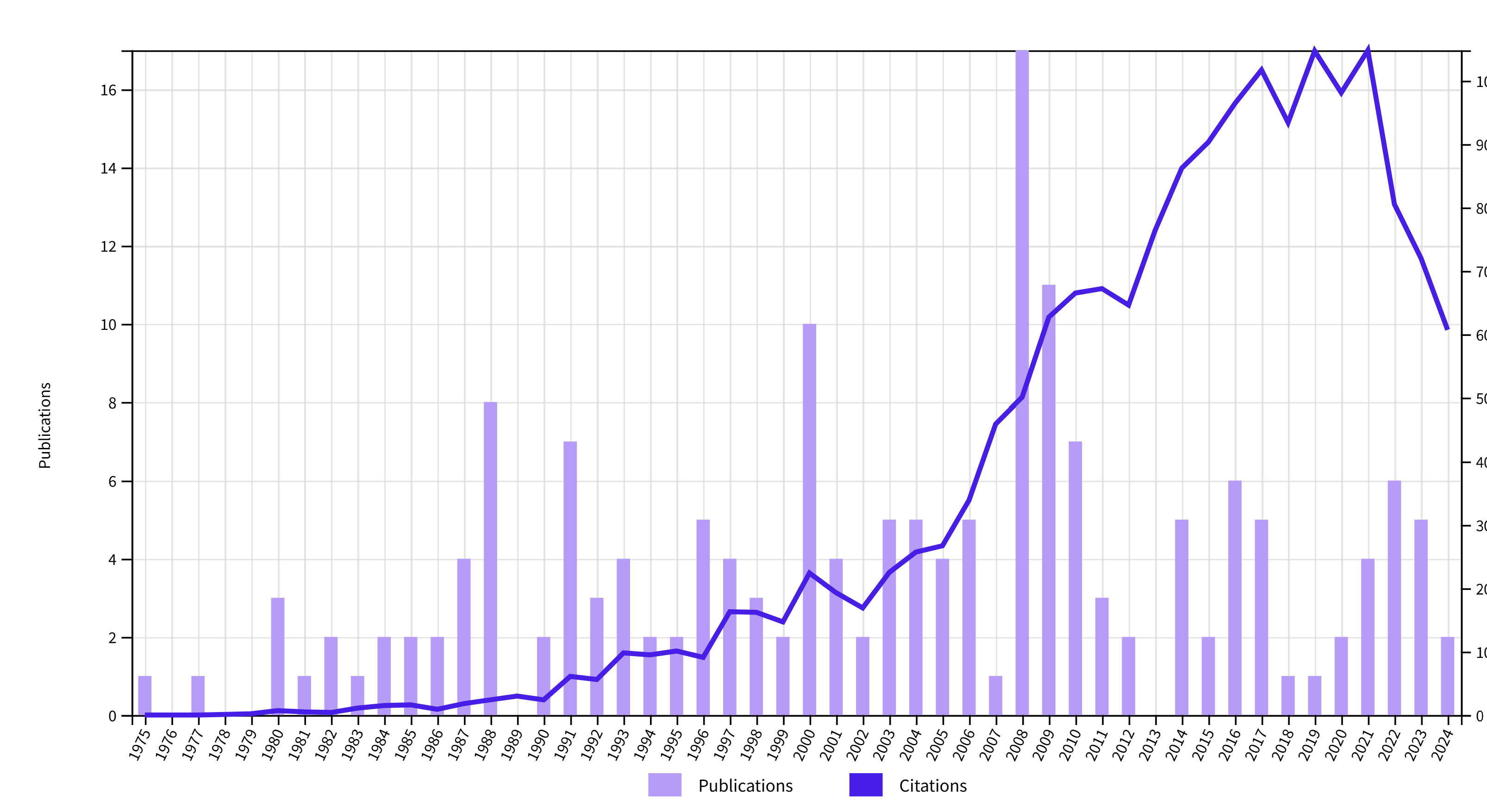
Importantly, the decrease is more pronounced that the average decrease of articles in social and personality psychology (

Given the recency of the peak, it is possible that citations continue to fall faster than the average in the coming years.
4. Dan Ariely
Dan Ariely’s research practices were scrutinized after it was discovered that data in one study of an article with him as author were manipulated. The data were provided by him, but he maintains that the manipulation was carried out by somebody else. Dan Ariely also co-authored article with another researcher, Francesca Gino, who is under investigation for data manipulation.
Ariely may not care much about citation counts, as he is one of those psychologists who have broken out of academia into pop culture. His popular book “Predictably Irrational” about his life and research was turned into a TV show that premiered in 2023 on NBC.

Citations peaked in 2021, when the citation bubble burst. Since then, citations have decreased somewhat faster than the average (62% vs. 77%).

Given the recency of the peak and the ongoing investigation of articles co-authored with Gino, it is possible that citation counts will decrease more than the average article in the coming years.
5. Anthony Greenwald*
* tied with Danna Carney who was involved in power-posing research, but distanced herself from this work. Her other work has not been a topic in the replication crisis and her overall citation count is low compared to the famous authors listed here .

Anthony Greenwald is famous for the invention of the Implicit Association Test (IAT). Millions of people have used IATs to obtain feedback about their unconscious/implicit/automatic associations. The most famous IAT is the race IAT that has been used to claim that the vast majority are more prejudiced against African Americans than they would admit in self-ratings. The test has also been used to suggest that African Americans often hold more favorable attitudes of White people than Black people even if they would state the opposite. A famous example is Malcolm Gladwell.
Numerous authors, including myself, have criticized the interpretation of IAT scores and pointed out that they lack evidence of validity (they may not measure racial attitudes) and are poor predictors of actual behavior. For example, the race IAT failed to predict racial bias in the 2008 US presidential election (Obama vs. McCain). That is, there was racial bias and self-report measures showed it, but IAT scores did not. Even proponents of implicit biases are now critical about the use of the IAT to study these biases. Even Greenwald has walked back unsupported claims in his popular book “Blindspots” and suggests IAT scores should simply be interpreted as scores produced by a method that does not rely on self-reports without specific claims about the meaning of these scores (i.e., it is a method without a clear construct).

Citations peaked in 2021, when the citation bubble burst. The decline in citations is somewhat steeper than the journal average (66% vs. 77%), but the number of citations in 2024 is still likely to break the 2,000 mark. The hype about the IAT is far from over and Project Implicit continues to hide the fact that the test is often invalid and provides false feedback.

6. Francesca Gino
The discovery of data anomalies (lawyer speak for funky data) in an article by Francesca Gino was big news on social media in 2023 (Datacolada, 2023). The accusation of fraud led to an investigation by Gino’s employer (Harvard) and a lawsuit by Gino against Harvard and the Datacolada team. The lawsuit against the investigators was recently dropped (Science, 2024) and the four flagged articles have been retracted. The investigation and law suit have drawn a lot of attention to Gino’s work. Collaborators have tried to separate credible studies from studies tainted by data from Gino’s lab, but this effort has not resulted in a clear separation of articles with and without tainted data. This may have affected citation of articles co-authored by Gino.
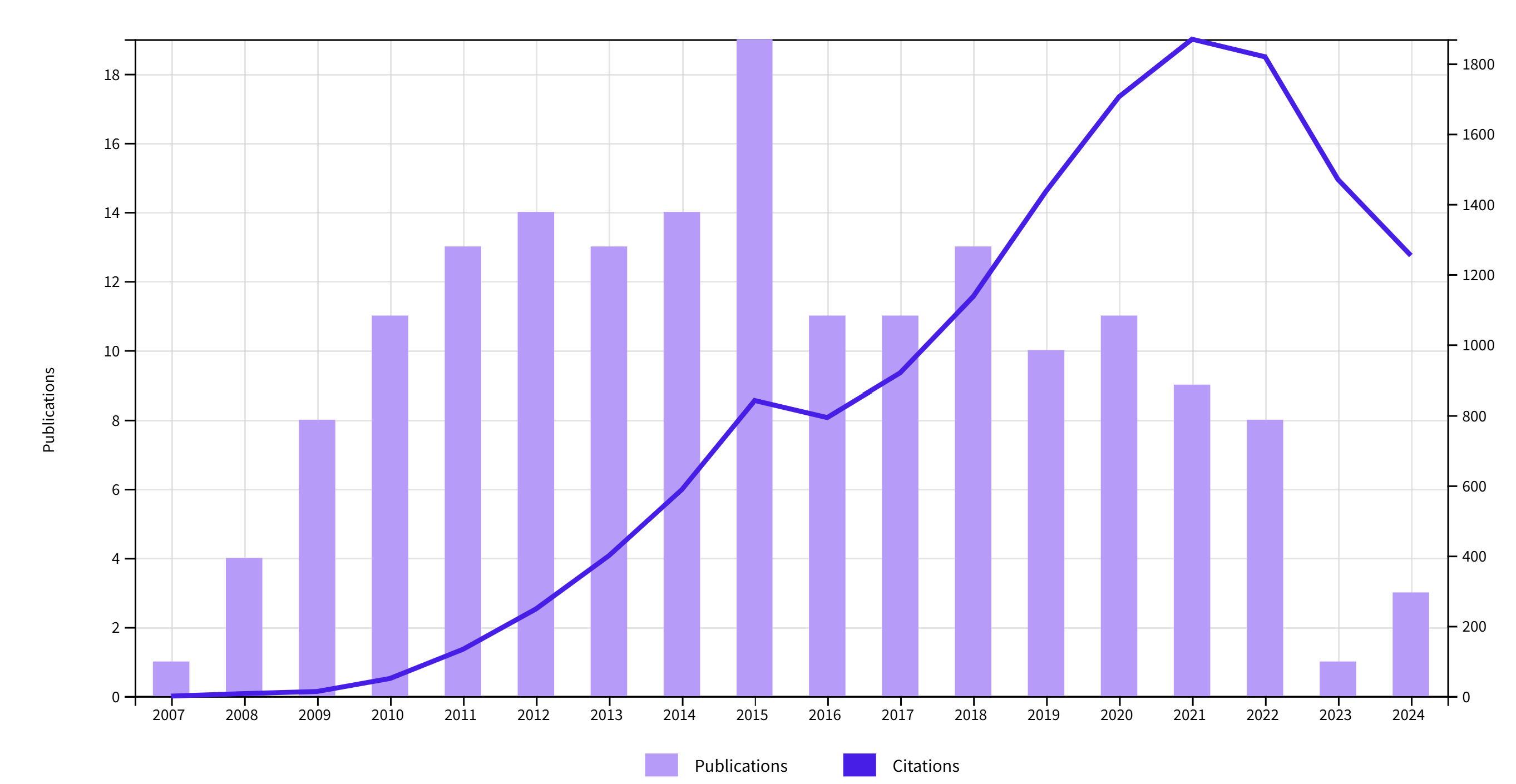
Note. Only articles from 2007 or later are used because WebOfScience only uses full first names in those years and using the initial would retrieve too many articles by other authors.
Citation counts peaked in 2021. The decrease from 2021 to 2024 is steeper than the average decrease for social psychology journals (67% vs. 77%). If more articles are retracted, the decrease is likely to accelerate in the coming years.

7. Tom Pyszczynski
IT was easier to search for citations for Tom Pyszczynski than his collaborators Jeff Greenberg and Sheldon Solomon, who invented Terror Management Theory (TMT) because his name is more unique. Terror management theory postulates that reminders of death alter people’s priorities and behaviors. Replicability varies depending on the methods that were used to study TMT. Many influential studies used priming without awareness. These results are difficult to replicate as are other priming studies (see Bargh above). TMT studies were highly influential in the early 2000s, but the topic attracted less attention recently, although TMT studies were not a major focus of discussion during the replication crisis.
Pyszczynski’s citation count peaked in 2021 when the citation bubble burst.
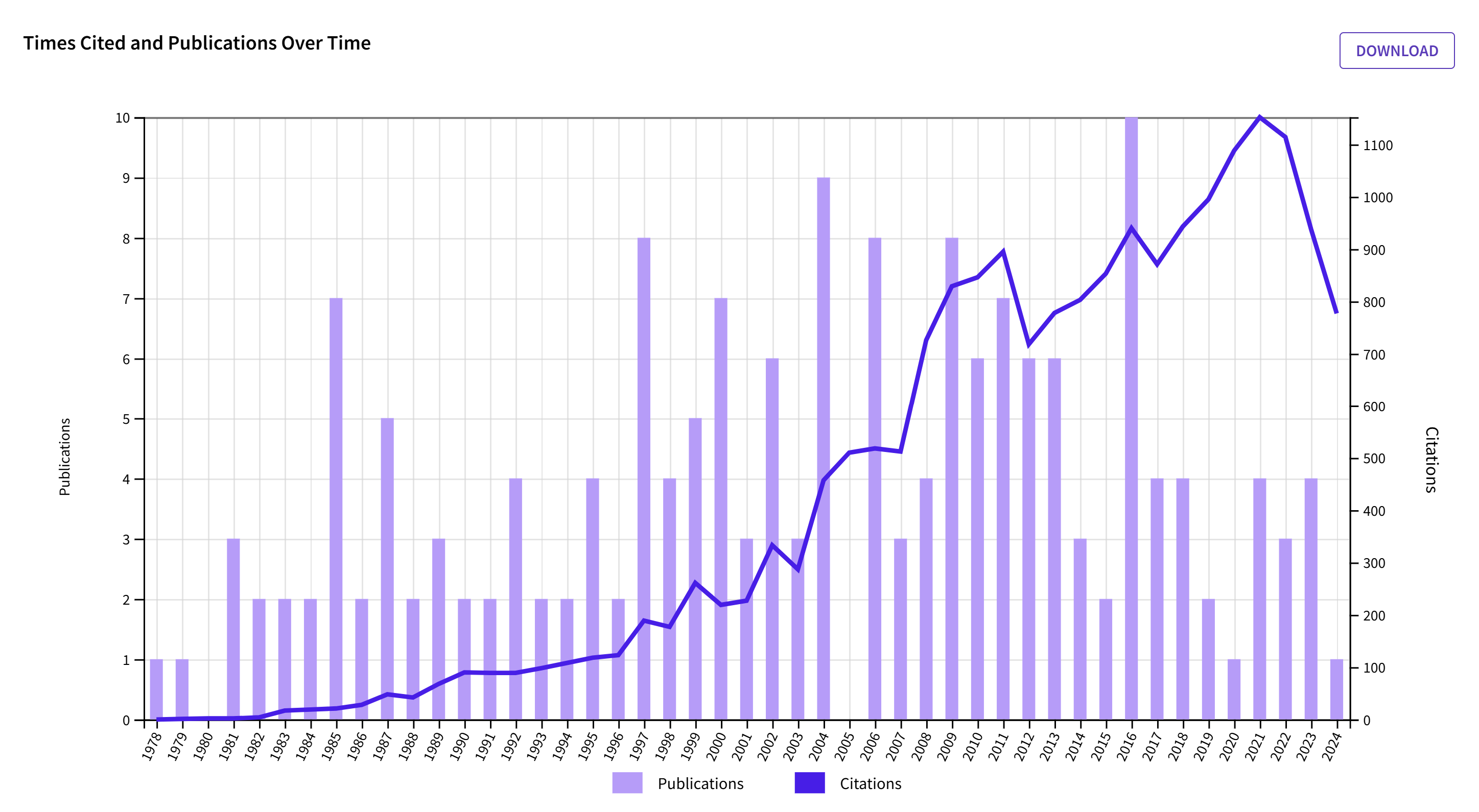
Citations decreased a little bit more than the journal average. However, with nearly 800 citations in 2024, TMT is likely to outlive its creators.

8. Kathleen D. Vohs
Kathleen Vohs’ has two lines of research related to the replication crisis. Her work on money priming is just a variation of priming without awareness studies with money as primes. These studies lack credibility and there is good evidence that published results were obtained with questionable research practices (Schimmack, 2024). The more important work was conducted in collaboration with Roy F. Baumeister on ego-depletion. Ego-depletion research has become another posterchild of replication failures. After a large replication project failed to show the effect, Vohs and colleague conducted another large replication project to demonstrate that the first attempt was flawed. However, even she could not replicate the finding with over 2,000 participants. Meta-analyses of published studies also find clear evidence of bias and little evidence of a real effect after controlling for bias. The general consensus among meta-psychologists is that the large ego-depletion literature has produced little insights into willpower and self-regulation failures (e.g., publishing only significant results although this violates scientific principles). Only a few people, still insist that ego-depletion effects are real. It is not clear where Vohs stands on this issue.

Vohs’ citation count peaked in 2021, the year the citation bubble burst. The decrease is a bit steeper than the journal average, down by 29 percentage points from the peak (71% vs. 77). However, with over 1,700 citations in 2024, there is still a lot of room for a correction that reflects the value of her money-priming and ego-depletion articles.

9. Dan Gilbert
Dan Gilbert made a contribution to the replication debate with some snarky online comments (e.g., calling replication researchers “shameless little bullies”) and an attempt to discredit the embarrassing finding of the reproducibility project that only 25% of social psychology studies could be replicated. The key argument was that replication studies were underpowered, but this argument does not explain how similarly powered studies could have a success rate of over 90% in the published articles.
His own research is often co-authord by Timothy Wilson, who is equally known for disparaging comments about replication researchers (Bartlett, 2014). It was easier to look up citations for Gilbet than for Wilson. Their work covers many topics, but they are probably best known for their studies on affective forecasting. The idea is that we overestimate the effects of negative events on our moods. The effect is replicable, but there is disagreement about the interpretation of the finding (Levine et al., 2012).
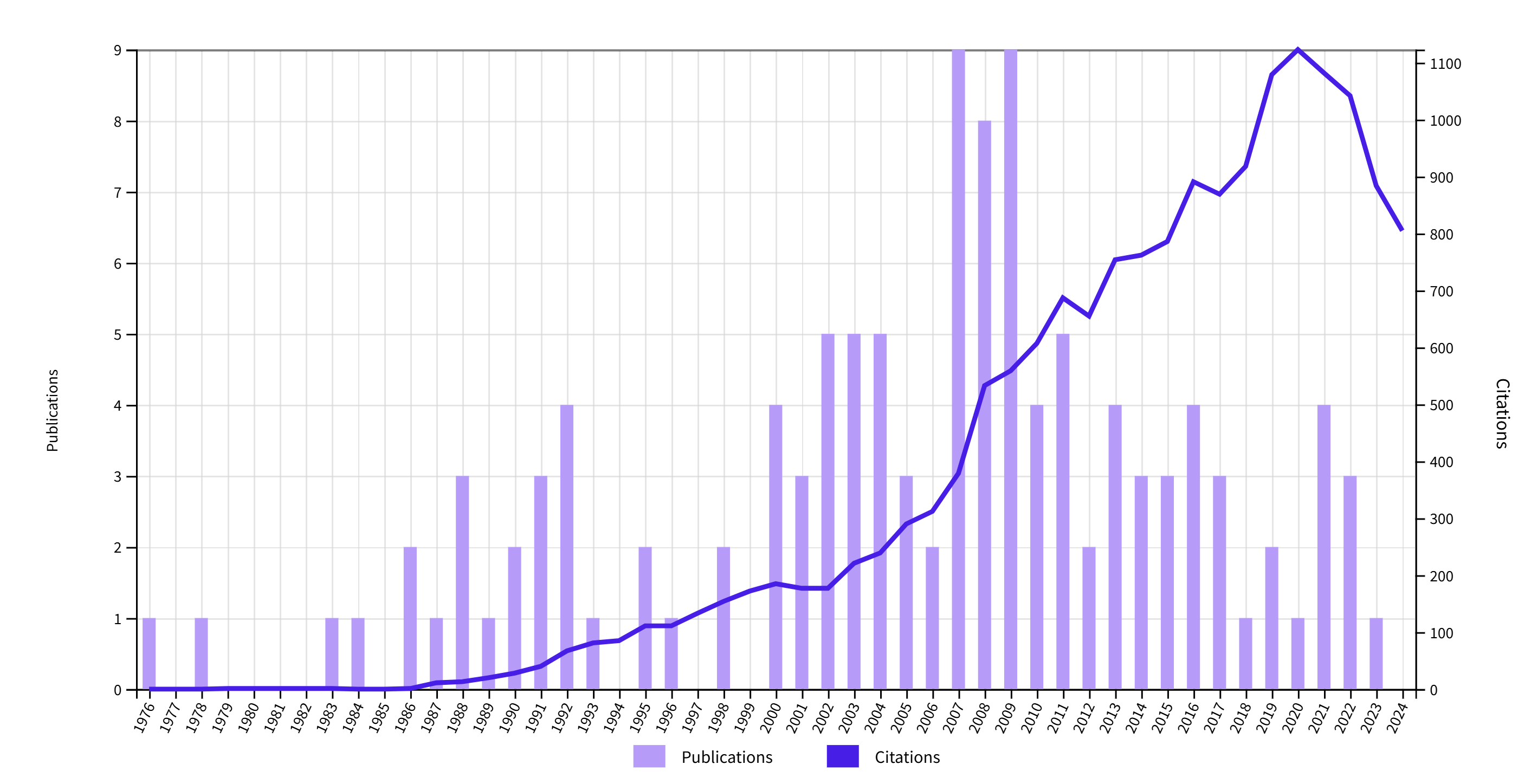
The peak citation count was in 2020, a year before the bubble burst. Citation counts decreased a bit faster than the journal average down to 71% versus 77%.
10. Roy F. Baumeister
And last, but not least, is Roy F. Baumeister, the inventor of ego-depletion (with Kathleen Vohs). At some point, Baumeister proposed that will-power is related to blood glucose levels and this claim was of course supported by statistically significant results, no less than 9 to be exact. When I wrote an article that pointed out that it is unlikely to get so many significant results without a non-significant effect even if an effect is real, Baumeister was a reviewer of the manuscript and simply noted that they of course had more studies and didn’t publish the weaker ones. That is just how the field works. At this point, ego-depletion was still accepted as a phenomenon, even if it didn’t rely on glucose levels. Now, even ego-depletion has been debunked and hundreds of significant results provide no insight into self-regulation. Nevertheless, Roy Baumeister continues to write articles that claim ego-depletion is real and all the critics are wrong. Roy F. Baumeister has also written on many other topics with influential review articles. For example, he reviewed credible evidence that men have a stronger sex drive than women.
Roy F. Baumeister has an impressive citation record with a peak citation rate of 7192 citations in 2021. He may be relieved that the decline in the following years is partially due to a general decline.
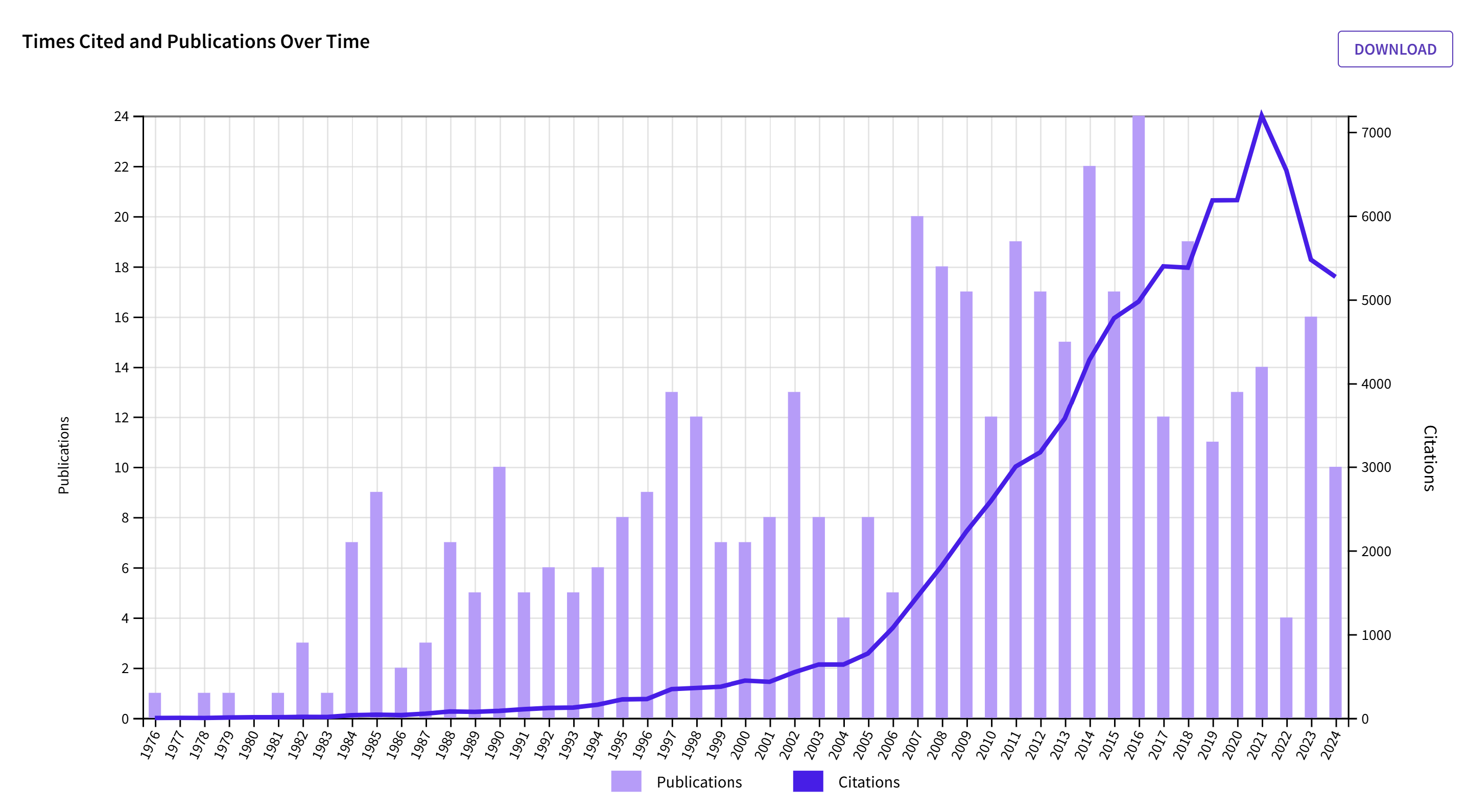
However, the decline is a bit steeper than the decline for the average journal (73% vs. 77%). To examine whether the results would be different, I also examined only articles that mention ego-depletion as a search term in any field. The key finding was hardly different (71% vs 73%). With nearly 900 ego-depletion related citations, psychology still has a long time to find out that Baumeister was swimming naked.
And here you have it. The most interesting result is that Bargh is the most notable victim of the replication crisis, whereas equally questionable research like the work on ego-depletion has been affected much less by demonstration of bias and major replication failures. While the citation bubble has burst, researchers are not as savvy as value investors to spot junk stocks. The following years will show whether awareness about replication failures spreads.
Some People Can be Better than Average
Some notable researchers have trends above the journal average. Here are three examples.
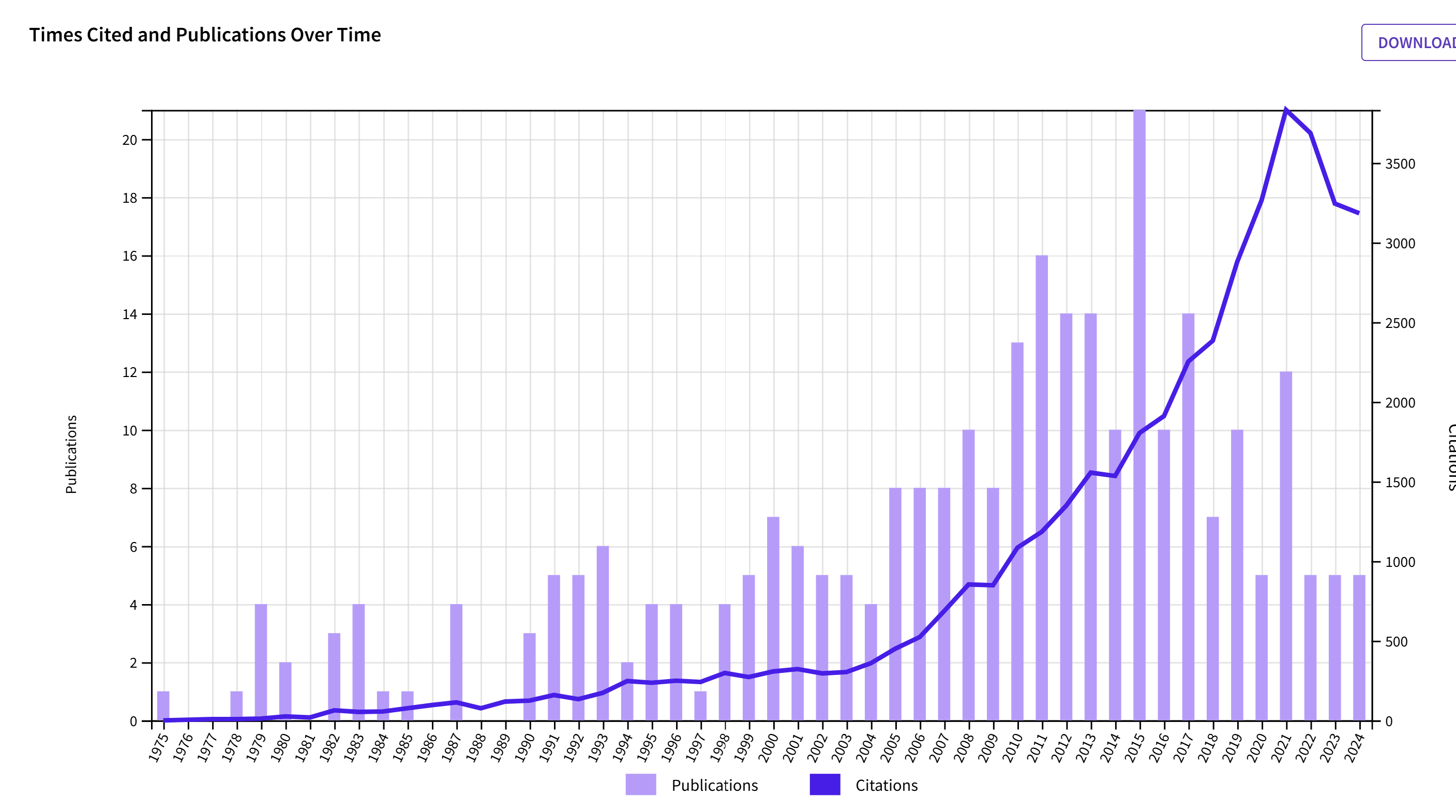
1. Susan Fiske
Susan Fiske became famous during the replication crisis when she called investigators of research bias “method terrorists.” Her own research has not been the focus of method terrorists. This may explain why her citation count decreased less than the journal average (83% vs. 77%).

2. Ed Diener
Ed Diener is one of the most influential psychologists of his generation, akin to Roy F. Baumeister. His main research has been on life-satisfaction and subjective well-being. This research has flourished since Diener published his seminal review paper in 1984. His Satisfaction with Life Scale (Diener et al., 1985) is still the most widely used multi–item measure of SWB. Many results have been replicated with large, nationally representative samples.
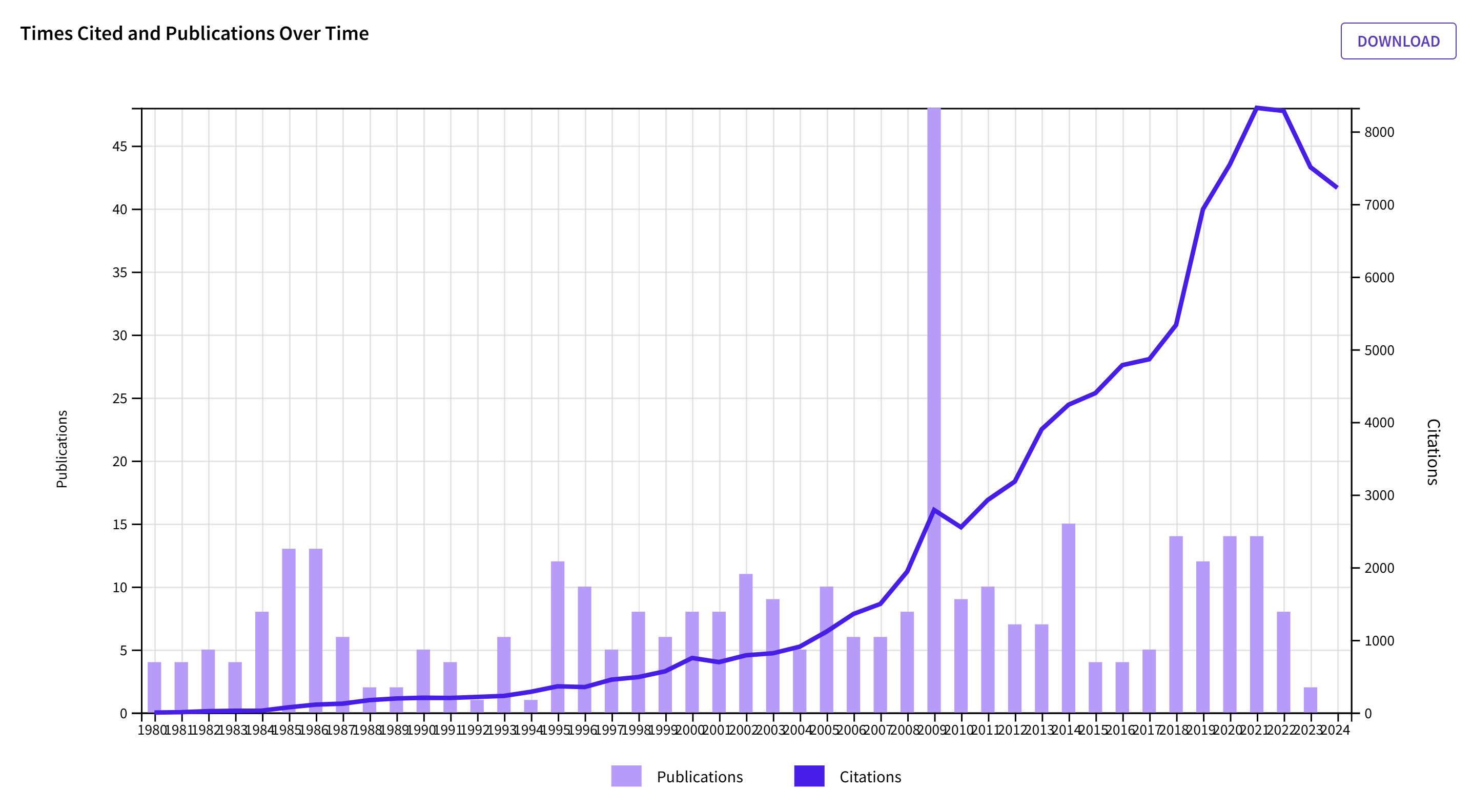
Citation counts peaked once again in 2021, the year the citation bubble burst. However, the decrease is relatively small and less than the journal average (87% vs. 77%).

A Positive Response to the Replication Crisis
My UofT colleague Michael Inzlicht also played a part in the replication crisis. In contrast to many social psychologists, he acknowledged that some of his early work was based on shoddy practices that produced results that cannot be replicated. Just recently, he commented on the demise of stereotype threat, another popular literature that turned out to be junk science (Inzlicht, 2024). After being unable to replicate his earlier findings at UofT, he started work on ego-depletion. After he joined a large replication project that failed to show the effect, he gave up on ego-depletion as well (Inzlicht, 2020). Since then, he started over and has already gathered a citation record that stands on its own without the previous publications.
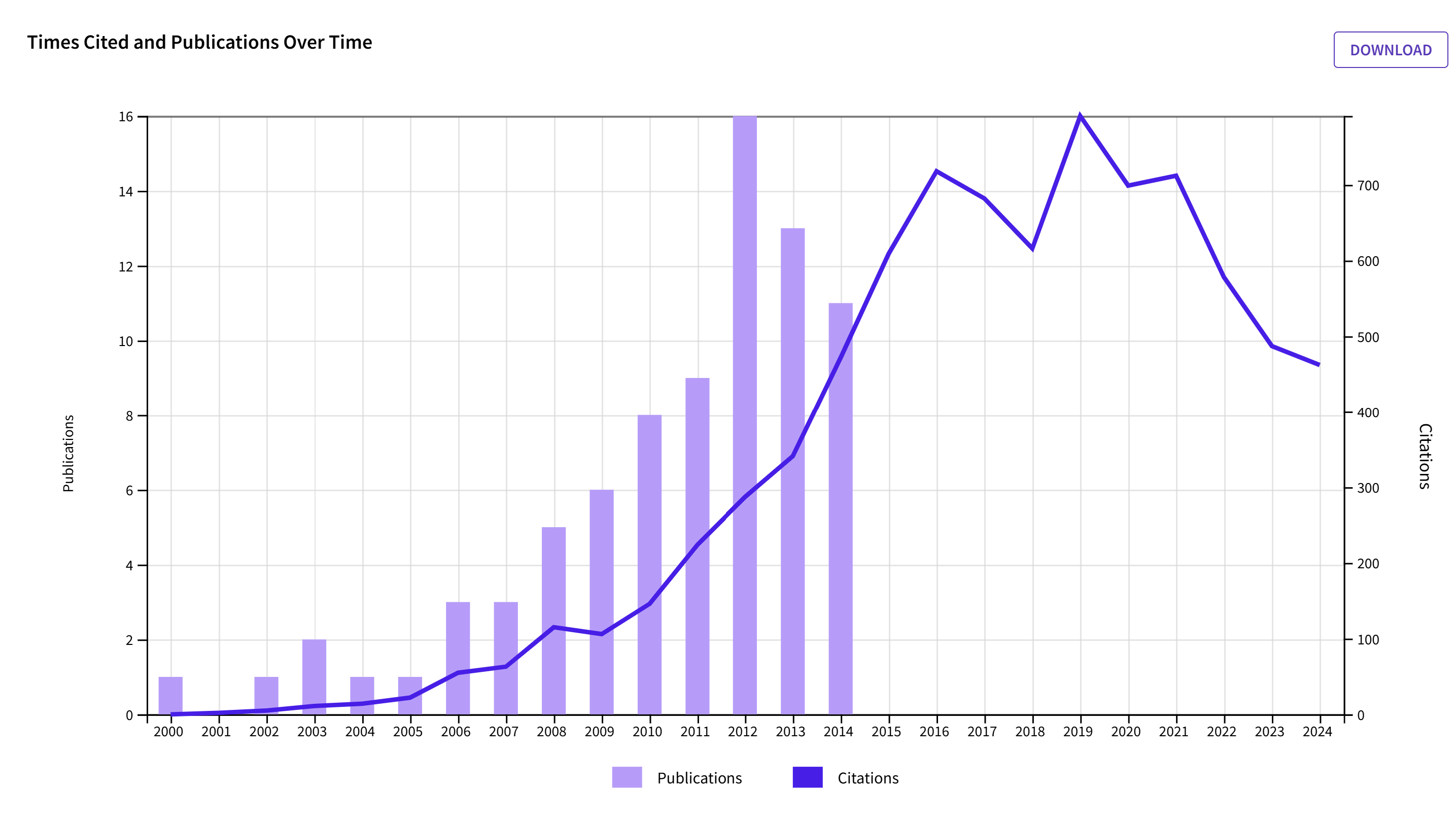
Citation counts for publications (k = 80) from 2000 to 2014 peaked in 2019 and then decreased sharply. The decrease matches the decrease for the third place (Strack).

However, over the past 10 years, Inzlicht published already over 100 new articles that have a higher peak than his old publications.
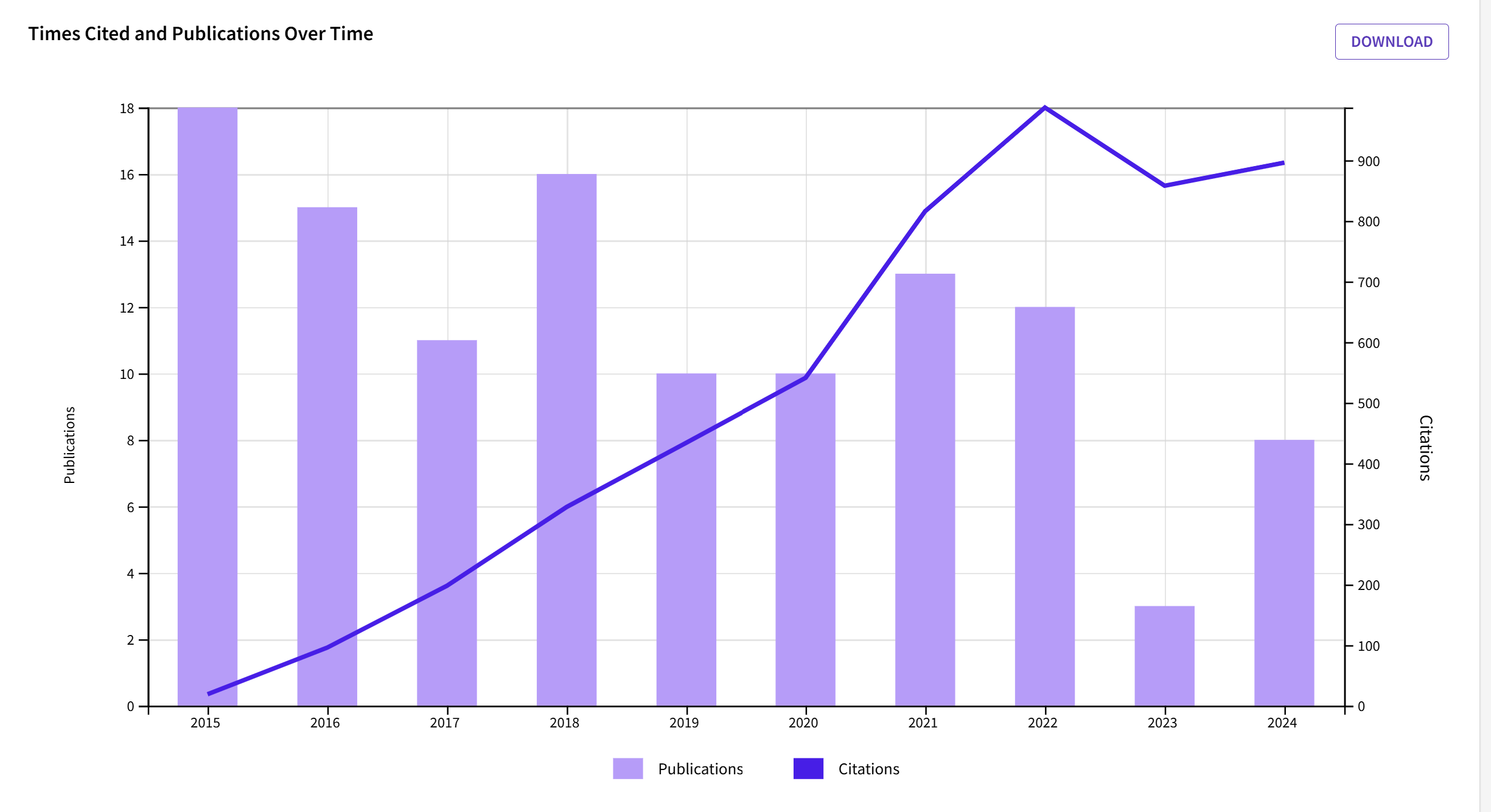
Moreover, the decrease is shallow and above the journal average (91% vs. 77%).

There you have it. When you invested in a bubble, it is best to sell and invest again in some new enterprise rather than sticking to your guns and hoping this will turn around.
Your’s Truly
Of course, I also looked up myself. In fact, the post is based on my investigation of the disappointing decrease in my own citations. It is comforting that the decrease is general and not specific to my publications.
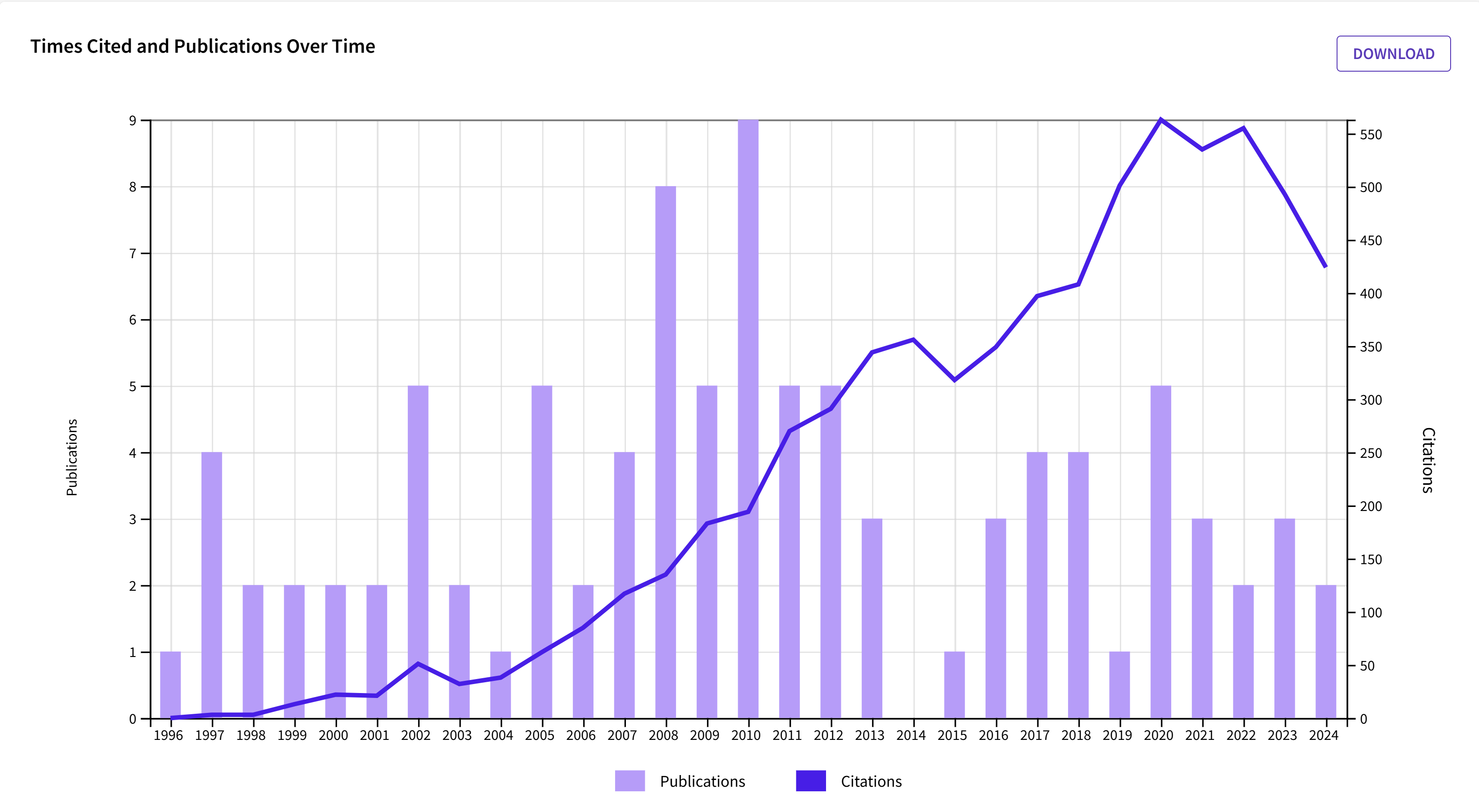
Rather the decrease is just slightly below the journal average (75% vs. 77%).

Conclusion
Citation counts matter even if they are only a poor reflection of research quality. They show what people are studying or reading and they are used to allocate resources for future research. The availability of citation counts makes it easy to conduct some meta-scientific studies on the popularity of topics and researchers. Whether the average number of citations goes up or down is a matter of journal space and the tracking of articles in an index. In WebOfScience citation counts have decreased. Researchers who look up themselves should be aware that the decrease is not a reflection of their popularity. More important is the relative increase compared to some benchmark or other researchers. Here we see some interesting differences. Most notably, citation counts of people who used fraud (Stapel) or questionable research practices (Bargh) to produce results that cannot be replicated have decreased notably. This is probably more important than the absolute number of citations or the H-Index of a researcher. The H-Index does not track whether a researcher made a positive contribution to science. It merely shows that a researcher was popular at some point in time. The hallmark of science is that it is self-correcting. This means that bubbles will be deflated eventually and popular but false claims will stop being citated. It is good to see some science that psychology acts like a science, but there is still a lot of room for further corrections in the future. So, do not be disappointed if your citation count pales in comparison to some of the giants in the field or decreased this year. No need for imposter syndrome. Not everybody can be better than average and some of the giants did more harm than good. Better to be just average.
Happy New Year
Ulrich Schimmack