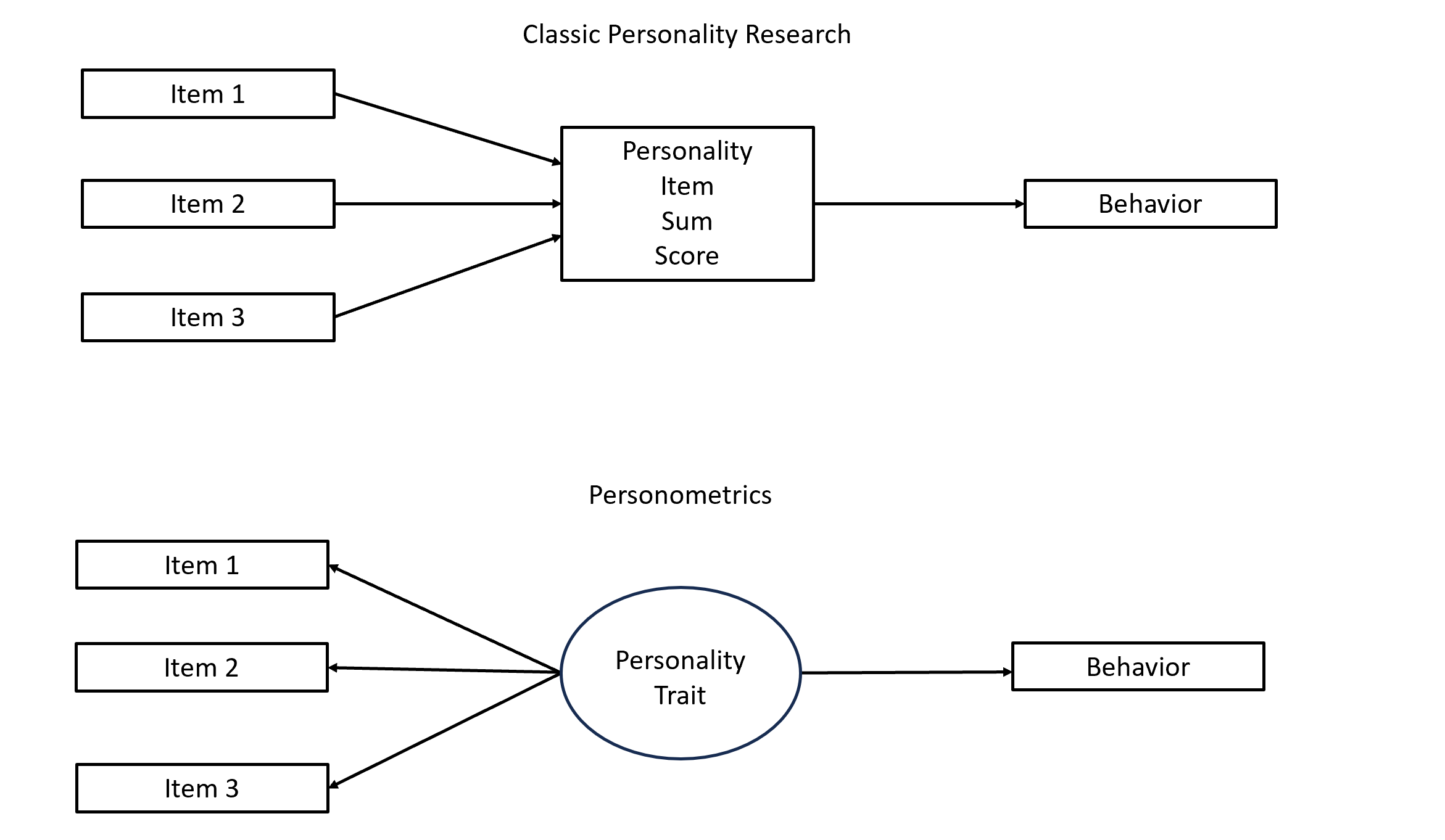
Last update: 10/16/2025
[Please suggest additional references in the comment section or email me
ulrich.schimmack@utoronto.ca]
Aldhous, P. (2011). Journal rejects studies contradicting precognition. New Scientist. Retrieve January 6, 2020, from https://www.newscientist.com/article/ dn20447-journal-rejects-studies-contradicting-precognition
Bakker, M., van Dijk, A., & Wicherts, J. M. (2012). The Rules of the Game Called Psychological Science. Perspectives on Psychological Science, 7(6), 543–554. https://doi.org/10.1177/1745691612459060
Barrett, L. F. (2015). Psychology is not in crisis. New York Times. Retrieved January 8, 2020, from https://www.nytimes.com/2015/09/01/ opinion/psychology-is-not-in-crisis.html
Bartlett, T. (2013). Power of suggestion: The amazing influence of uncon- scious cues is among the most fascinating discoveries of our time—That is, if it’s true. The Chronicle of Higher Education. Retrieved from https://www.chronicle.com/article/Power-of-Suggestion/136907
Bartoš, F., & Schimmack, U. (2022). Z-curve 2.0: Estimating replication rates and discovery rates. Meta-Psychology, 6, Article e0000130. https://doi.org/10.15626/MP.2022.2981
Baumeister, R. F. (2016, March). Email response posted in Psychological Methods Discussion Group. Retrieved from https://www.facebook.com/ groups/853552931365745/permalink/985757694811934/
Baumeister, R. F., & Vohs, K. D. (2016). Misguided effort with elusive implications. Perspectives on Psychological Science, 11(4), 574–575. https://doi.org/10.1177/1745691616652878
Bem, D. J. (2000). Writing an empirical article. In R. J. Sternberg (Ed.), Guide to publishing in psychological journals (pp. 3–16). Cambridge, UK: Cambridge University Press. http://dx.doi.org/10.1017/ CBO9780511807862.002
Bem, D. J. (2011). Feeling the future: Experimental evidence for anoma- lous retroactive influences on cognition and affect. Journal of Personality and Social Psychology, 100, 407– 425. http://dx.doi.org/10.1037/ a0021524
Bem, D. J., Utts, J., & Johnson, W. O. (2011). Must psychologists change the way they analyze their data? Journal of Personality and Social Psychology, 101, 716 –719. http://dx.doi.org/10.1037/a0024777
Benjamin, D.J., Berger, J.O., Johannesson, M. et al. (2018) Redefine statistical significance. Nature Human Behaviour 2, 6–10. https://doi.org/10.1038/s41562-017-0189-z
Brunner, J. (2018). An even better p-curve. Retrieved January 8, 2020, from https://replicationindex.com/2018/05/10/an-even-better-p-curve
Brunner, J., & Schimmack, U. (2020). Estimating population mean power  under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
under conditions of heterogeneity and selection for significance. Meta- Psychology. MP.2018.874, https://doi.org/10.15626/MP.2018.874
Bryan, C. J., Yeager, D. S., & O’Brien, J. M. (2019). Replicator degrees of freedom allow publication of misleading failures to replicate. Proceedings of the National Academy of Sciences USA, 116, 25535–25545. http://dx.doi.org/10.1073/pnas.1910951116
[Rating 2/10, review]
Cacioppo, J. T., Petty, R. E., & Morris, K. (1983). Effects of need for cognition on message evaluation, recall, and persuasion. Journal of Personality and Social Psychology, 45, 805– 818. http://dx.doi.org/10.1037/0022-3514.45.4.805
Cairo, A. H., Green, J. D., Forsyth, D. R., Behler, A. M. C., & Raldiris, T. L. (2020). Gray (literature) mattes: Evidence of selective hypothesis reporting in social psychological research. Personality and Social Psy- chology Bulletin. Advance online publication. http://dx.doi.org/10.1177/ 0146167220903896
Carpenter, S. (2012). Psychology’s bold initiative. Science, 335, 1558 – 1560. http://dx.doi.org/10.1126/science.335.6076.1558
Carter, E. C., Kofler, L. M., Forster, D. E., & McCullough, M. E. (2015). A series of meta-analytic tests of the depletion effect: Self-control does not seem to rely on a limited resource. Journal of Experimental Psy- chology: General, 144, 796 – 815. http://dx.doi.org/10.1037/xge0000083
Carter EC, Schönbrodt FD, Gervais WM, Hilgard J. (2019). Correcting for Bias in Psychology: A Comparison of Meta-Analytic Methods. Advances in Methods and Practices in Psychological Science. 2019;2(2):115-144. doi:10.1177/2515245919847196
[ChatGPT review, rating 9/10]
Carter, E. C., & McCullough, M. E. (2013). Is ego depletion too incredible? Evidence for the overestimation of the depletion effect. Behavioral and Brain Sciences, 36, 683– 684. http://dx.doi.org/10.1017/ S0140525X13000952
Carter, E. C., & McCullough, M. E. (2014). Publication bias and the limited strength model of self-control: Has the evidence for ego depletion been overestimated? Frontiers in Psychology, 5, 823.http://dx.doi.org/10.3389/fpsyg.2014.00823
Chambers, C. D. (2013). Registered reports: A new publishing initiative at Cortex. Cortex, 49, 609 – 610. http://dx.doi.org/10.1016/j.cortex.2012.12.016
Cohen, J. (1962). The statistical power of abnormal-social psychological research: A review. Journal of Abnormal and Social Psychology, 65, 145–153. http://dx.doi.org/10.1037/h0045186
Cohen, J. (1994). The earth is round (p <. 05). American Psychologist, 49, 997–1003. http://dx.doi.org/10.1037/0003-066X.49.12.997
Crandall, C. S., & Sherman, J. W. (2016). On the scientific superiority of conceptual replications for scientific progress. Journal of Experimental Social Psychology, 66, 93–99. http://dx.doi.org/10.1016/j.jesp.2015.10.002
Cunningham, M. R., & Baumeister, R. F. (2016). How to make nothing out of something: Analyses of the impact of study sampling and statistical interpretation in misleading meta-analytic conclusions. Frontiers in Psy- chology, 7, 1639. http://dx.doi.org/10.3389/fpsyg.2016.01639
Ebersole, C. R., Atherton, O. E., Belanger, A. L., Skulborstad, H. M., Allen, J. M., Banks, J. B., . . . Nosek, B. A. (2016). Many Labs 3: Evaluating participant pool quality across the academic semester via replication. Journal of Experimental Social Psychology, 67, 68 – 82. http://dx.doi.org/10.1016/j.jesp.2015.10.012
Elkins-Brown, N., Saunders, B., & Inzlicht, M. (2018). The misattribution of emotions and the error-related negativity: A registered report. Cortex, 109, 124 –140. http://dx.doi.org/10.1016/j.cortex.2018.08.017
Engel, C. (2015). Scientific disintegrity as a public bad. Perspectives on Psychological Science, 10, 361–379. http://dx.doi.org/10.1177/1745691615577865
Ferguson, C. J., & Heene, M. (2012). A vast graveyard of undead theories: Publication bias and psychological science’s aversion to the null. Per- spectives on Psychological Science, 7, 555–561. http://dx.doi.org/10.1177/1745691612459059
Fiedler, K. (2015). Regression to the mean. Retrieved January 6, 2020, from https://brettbuttliere.wordpress.com/2018/03/10/fiedler-on-the- replicability-project
Fiedler, K., & Schwarz, N. (2016). Questionable research practices revis- ited. Social Psychological & Personality Science, 7, 45–52. http://dx.doi.org/10.1177/1948550615612150
Fisher, R. A. (1926). The arrangement of field experiments. Journal of the Ministry of Agriculture, 33, 503–513.
Fiske, S. T. (2016). How to publish rigorous experiments in the 21st century. Journal of Experimental Social Psychology, 66, 145–147. http://dx.doi.org/10.1016/j.jesp.2016.01.006
Fiske, S. T. (2017). Going in many right directions, all at once. Perspectives on Psychological Science, 12, 652– 655. http://dx.doi.org/10.1177/1745691617706506
Francis, G. (2012). Too good to be true: Publication bias in two prominent studies from experimental psychology. Psychonomic Bulletin & Review, 19, 151–156. http://dx.doi.org/10.3758/s13423-012-0227-9
Galak, J., LeBoeuf, R. A., Nelson, L. D., & Simmons, J. P. (2012). Correcting the past: Failures to replicate. Journal of Personality and Social Psychology, 103, 933–948. http://dx.doi.org/10.1037/a0029709
Gilbert, D. T., King, G., Pettigrew, S., & Wilson, T. D. (2016). Comment on “Estimating the reproducibility of psychological science.” Science, 351, 1037–1103. http://dx.doi.org/10.1126/science.aad7243
Gronau, Q. F., Duizer, M., Bakker, M., & Wagenmakers, E.-J. (2017). Bayesian mixture modeling of significant p values: A meta-analytic method to estimate the degree of contamination from Ho. Journal of Experimental Psychology: General, 146, 1223–1233. http://dx.doi.org/ 10.1037/xge0000324
Hagger, M. S., Chatzisarantis, N. L. D., Alberts, H., Anggono, C. O., Batailler, C., Birt, A. R., . Zwienenberg, M. (2016). A multilab preregistered replication of the ego-depletion effect. Perspectives on Psychological Science, 11, 546 –573. http://dx.doi.org/10.1177/1745691616652873
Hagger, M. S., Wood, C., Stiff, C., & Chatzisarantis, N. L. D. (2010). Ego depletion and the strength model of self-control: A meta-analysis. Psychological Bulletin, 136, 495–525. http://dx.doi.org/10.1037/a0019486
Hoenig, J. M., & Heisey, D. M. (2001). The abuse of power: The pervasive fallacy of power calculations for data analysis. The American Statistician, 55(1), 19–24. https://doi.org/10.1198/000313001300339897
Review: The Abuse of Hoenig and Heisey: A Justification of Power Calculations with Observed Effect Sizes – Replicability-Index
Inbar, Y. (2016). Association between contextual dependence and replicability in psychology may be spurious. Proceedings of the National Academy of Sciences, 113(34):E4933-9334, doi.org/10.1073/pnas.1608676113
Ioannidis, J. P. A. (2005). Why most published research findings are false. PLoS Medicine, 2, e124. http://dx.doi.org/10.1371/journal.pmed.0020124
John, L. K., Loewenstein, G., & Prelec, D. (2012). Measuring the Prevalence of Questionable Research Practices With Incentives for Truth Telling. Psychological Science, 23(5), 524–532. https://doi.org/10.1177/0956797611430953
Kahneman, D. (2003). Experiences of collaborative research. American Psychologist, 58, 723–730. http://dx.doi.org/10.1037/0003-066X.58.9.723
Kerr, N. L. (1998). HARKing: Hypothesizing After the Results are Known. Personality and Social Psychology Review, 2(3), 196–217. https://doi.org/10.1207/s15327957pspr0203_4
Kitayama, S. (2018). Response to request to retract Bem’s (2011) JPSP article. Retrieved January 9, 2020, from https://replicationindex.files. wordpress.com/2020/01/kitayama.response.docx
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian new statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25, 178 –206. http://dx.doi.org/10.3758/s13423-016-1221-4
Kvarven, A., Strømland, E. & Johannesson, M. (2020). Comparing meta-analyses and preregistered multiple-laboratory replication projects. Nature Human Behaviour 4, 423–434 (2020). https://doi.org/10.1038/s41562-019-0787-z
Lakens, D., Scheel, A. M., & Isager, P. M. (2018). Equivalence testing for psychological research: A tutorial. Advances in Methods and Practices in Psychological Science, 1, 259 –269. http://dx.doi.org/10.1177/2515245918770963
Lehrer, J. (2010). The truth wears off. https://www.newyorker.com/magazine/2010/12/13/the-truth-wears-off (downloaded 7/2/2020)
Lengersdorff LL, Lamm C. With Low Power Comes Low Credibility? Toward a Principled Critique of Results From Underpowered Tests. Advances in Methods and Practices in Psychological Science. 2025;8(1). doi:10.1177/25152459241296397
[Rating 4/10, review]
Lin, H., Saunders, B., Friese, M., Evans, N. J., & Inzlicht, M. (2020). Strong effort manipulations reduce response caution: A preregistered reinvention of the ego-depletion paradigm. Psychological Science, 31, 531–547. http://dx.doi.org/10.1177/0956797620904990
Lindsay, D. S. (2019). Swan song editorial. Psychological Science, 30, 1669 –1673. http://dx.doi.org/10.1177/0956797619893653
Luttrell, A., Petty, R. E., & Xu, M. (2017). Replicating and fixing failed replications: The case of need for cognition and argument quality. Journal of Experimental Social Psychology, 69, 178 –183. http://dx.doi.org/10.1016/j.jesp.2016.09.006
Maxwell, S. E., Lau, M. Y., & Howard, G. S. (2015). Is psychology suffering from a replication crisis? What does “failure to replicate” really mean? American Psychologist, 70, 487– 498. http://dx.doi.org/10.1037/a0039400
McShane BB, Böckenholt U, Hansen KT. Average Power: A Cautionary Note. Advances in Methods and Practices in Psychological Science. 2020;3(2):185-199. doi:10.1177/2515245920902370
Morewedge, C. K., Gilbert, D., & Wilson, T. D. (2014). Reply to Francis. Retrieved June 7, 2019, from https://www.semanticscholar.org/paper/ REPLY-TO-FRANCIS-Morewedge-Gilbert/019dae0b9cbb3904a671 bfb5b2a25521b69ff2cc
Morey, R. D., & Davis-Stober, C. P. (2025). On the poor statistical properties of the P-curve meta-analytic procedure. Journal of the American Statistical Association. Advance online publication. https://doi.org/10.1080/01621459.2025.2544397
[see Blog post for info]
Motyl, M., Demos, A. P., Carsel, T. S., Hanson, B. E., Melton, Z. J., Mueller, A. B., . . . Skitka, L. J. (2017). The state of social and personality science: Rotten to the core, not so bad, getting better, or getting worse? Journal of Personality and Social Psychology, 113, 34 –58. http://dx.doi.org/10.1037/pspa0000084
Murayama, K., Pekrun, R., & Fiedler, K. (2014). Research practices that can prevent an inflation of false-positive rates. Personality and Social Psychology Review, 18, 107–118. http://dx.doi.org/10.1177/1088868313496330
Nelson, L. D., Simmons, J., & Simonsohn, U. (2018). Psychology’s Re- naissance. Annual Review of Psychology, 69, 511–534. http://dx.doi.org/ 10.1146/annurev-psych-122216-011836
Noah, T., Schul, Y., & Mayo, R. (2018). When both the original study and its failed replication are correct: Feeling observed eliminates the facial- feedback effect. Journal of Personality and Social Psychology, 114, 657– 664. http://dx.doi.org/10.1037/pspa0000121
Nosek, B. A., Ebersole, C. R., DeHaven, A. C., & Mellor, D. T. (2018). The preregistration revolution. Proceedings of the National Academy of Sciences USA, 115, 2600 –2606. http://dx.doi.org/10.1073/pnas.1708274114
Open Science Collaboration (OSC). (2015). Estimating the reproducibility of psychological science. Science, 349, aac4716. http://dx.doi.org/10.1126/science.aac4716
Pashler, H., & Harris, C. R. (2012). Is the replicability crisis overblown? Three arguments examined. Perspectives on Psychological Science, 7, 531–536. http://dx.doi.org/10.1177/1745691612463401
Patil, P., Peng, R. D., & Leek, J. T. (2016). What Should Researchers Expect When They Replicate Studies? A Statistical View of Replicability in Psychological Science. Perspectives on Psychological Science, 11(4), 539-544. https://doi-org.myaccess.library.utoronto.ca/10.1177/1745691616646366
[Rating 3/10, review]
Pek, J., Hoisington-Shaw, K. J., & Wegener, D. T. (2024). Uses of uncertain statistical power: Designing future studies, not evaluating completed studies.. Psychological Methods. Advance online publication. https://dx.doi.org/10.1037/met0000577
[Rating 1/10, review]
Pettigrew, T. F. (2018). The e`mergence of contextual social psychology. Personality and Social Psychology Bulletin, 44, 963–971. http://dx.doi.org/10.1177/0146167218756033
Renkewitz, F., & Keiner, M. (2019). How to detect publication bias in psychological research: A comparative evaluation of six statistical methods. Zeitschrift für Psychologie, 227(4), 261-279. http://dx.doi.org/10.1027/2151-2604/a000386
Ritchie, S. J., Wiseman, R., & French, C. C. (2012). Failing the future: Three unsuccessful attempts to replicate Bem’s ‘retroactive facilitation of recall’ effect. PLoS One, 7, e33423. http://dx.doi.org/10.1371/journal.pone.0033423
Rosenthal, R. (1979). The file drawer problem and tolerance for null results. Psychological Bulletin, 86, 638 – 641. http://dx.doi.org/10.1037/0033-2909.86.3.638
Scheel, A. M., Schijen, M., & Lakens, D. (2020). An excess of positive results: Comparing the standard psychology literature with registered reports. Retrieved from https://psyarxiv.com/p6e9c
Schimmack, U. (2012). The ironic effect of significant results on the credibility of multiple-study articles. Psychological Methods, 17, 551– 566. http://dx.doi.org/10.1037/a0029487
Schimmack, U. (2020). A meta-psychological perspective on the decade of replication failures in social psychology. Canadian Psychology / Psychologie canadienne, 61(4), 364–376. https://doi.org/10.1037/cap0000246
Schimmack, U. (2018a). Fritz Strack asks “Have I done something wrong?” Retrieved January 8, 2020, from https://replicationindex.com/ 2018/04/29/fritz-strack-response
Schimmack, U. (2018b). Why the Journal of Personality and Social Psychology Should Retract Article DOI:10.1037/a0021524 “Feeling the future: Experimental evidence for anomalous retroactive influences on cognition and affect” by Daryl J. Bem. Retrieved January 6, 2020, from https://replicationindex.com/2018/01/05/bem-retraction
Schimmack, U. (2020). Estimating the replicability of results in “Journal of Experimental Social Psychology.” Retrieved February 17, 2020, from https://replicationindex.com/2020/02/15/est-rep-jesp
Schimmack, U., & Bartoš, F. (2023). Estimating the false discovery risk of (randomized) clinical trials in medical journals based on published p-values. PLOS ONE, 18(7), e0290084. https://doi.org/10.1371/journal.pone.0290084
Schimmack, U., & Brunner, J. (2019). The Bayesian mixture model for p-curves is fundamentally flawed. Retrieved January 8, 2020, from https://replicationindex.com/2019/04/01/the-bayesian-mixture-model- is-fundamentally-flawed
Schimmack, U., Schultz, L., Carlsson, R., & Schmukle, S.C., (2018). Letter to Kitayama regarding Bem’s article in JPSP. Retrieved January 9, 2020, from https://replicationindex.com/wp-content/uploads/2018/01/letter-2- kitayama-002.doc
Schooler, J. W. (2014). Turning the lens of science on itself: Verbal overshadowing, replication, and metascience. Perspectives on Psycho- logical Science, 9, 579 –584. http://dx.doi.org/10.1177/1745691614547878
Schooler, J. W., & Engstler-Schooler, T. Y. (1990). Verbal overshadowing of visual memories: Some things are better left unsaid. Cognitive Psy- chology, 22, 36 –71. http://dx.doi.org/10.1016/0010-0285(90)90003-M
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22, 1359 –1366. http://dx.doi.org/10.1177/0956797611417632
Simonsohn, U. (2013). It does not follow: Evaluating the one-off publication bias critiques by Francis (2012a, 2012b, 2012c, 2012d, 2012e, in press). Perspective on Psychological Science, 7, 597–599. http://dx.doi.org/10.1177/1745691612463399
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014). P-curve and effect size: Correcting for publication bias using only significant results. Perspectives on Psychological Science, 9, 666 – 681. http://dx.doi.org/10.1177/1745691614553988
Skibba, R. (2016). Psychologists argue about whether smiling makes cartoons funnier. Nature. https://www.nature.com/news/psychologists-argue-about-whether-smiling-makes-cartoons-funnier-1.20929
Sorić, B. (1989). Statistical “Discoveries” and Effect-Size Estimation. Journal of the American Statistical Association, 84(406), 608-610. doi:10.2307/2289950
Soto, M. D., & Schimmack, U. (2024). Credibility of results in emotion science: A Z-curve analysis of results in the journals Cognition & Emotion and Emotion. Cognition & Emotion. Advance online publication. https://doi.org/10.1080/02699931.2024.244301
Soto, M. D., & Schimmack, U. (2025). Credibility of results in psychological science: A z-curve analysis across journals and time [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/6ybeu
Sotola, L. (2023). How Can I Study from Below, that which Is Above? : Comparing Replicability Estimated by Z-Curve to Real Large-Scale Replication Attempts. Meta-Psychology, 7. https://doi.org/10.15626/MP.2022.3299
[ChatGPT review and rating, 8.5]
Sterling, T. D. (1959). Publication decision and the possible effects on inferences drawn from tests of significance— or vice versa. Journal of the American Statistical Association, 54, 30 –34.
Sterling, T. D., Rosenbaum, W. L., & Weinkam, J. J. (1995). Publication decisions revisited: The effect of the outcome of statistical tests on the decision to publish and vice versa. The American Statistician, 49, 108 –112.
Strack, F. (2016). Reflection on the smiling registered replication report. Perspectives on Psychological Science, 11, 929 –930. http://dx.doi.org/ 10.1177/1745691616674460
Stroebe, W., & Strack, F. (2014). The alleged crisis and the illusion of exact replication. Perspectives on Psychological Science, 9, 59 –71. http://dx.doi.org/10.1177/1745691613514450
Tendeiro, J. N., & Kiers, H. A. L. (2019). A review of issues about null hypothesis Bayesian testing. Psychological Methods, 24, 774 –795. http://dx.doi.org/10.1037/met0000221
Trafimow, D. (2003). Hypothesis testing and theory evaluation at the boundaries: Surprising insights from Bayes’s theorem. Psychological Review, 110, 526 –535. http://dx.doi.org/10.1037/0033-295X.110.3.526
Trafimow, D., & Marks, M. (2015). Editorial. Basic and Applied Social Psychology, 37, 1–2. http://dx.doi.org/10.1080/01973533.2015.1012991
Ulrich, R., & Miller, J. (2018). Some properties of p-curves, with an application to gradual publication bias. Psychological Methods, 23, 546 –560. http://dx.doi.org/10.1037/met0000125
Van Bavel, J. J., Mende-Siedlecki, P., Brady, W. J., & Reinero, D. A. (2016). Contextual sensitivity in scientific reproducibility. Proceedings of the National Academy of Sciences USA, 113, 6454 – 6459. http://dx.doi.org/10.1073/pnas.1521897113
Vohs, K. D., Schmeichel, B. J., Lohmann, S., Gronau, Q. F., Finley, A. J., Ainsworth, S. E., Alquist, J. L., Baker, M. D., Brizi, A., Bunyi, A., Butschek, G. J., Campbell, C., Capaldi, J., Cau, C., Chambers, H., Chatzisarantis, N. L. D., Christensen, W. J., Clay, S. L., Curtis, J., De Cristofaro, V., … Albarracín, D. (2021). A Multisite Preregistered Paradigmatic Test of the Ego-Depletion Effect. Psychological science, 32(10), 1566–1581. https://doi.org/10.1177/0956797621989733
Wagenmakers, E. J., Wetzels, R., Borsboom, D., & van der Maas, H. L. (2011). Why psychologists must change the way they analyze their data: The case of psi: Comment on Bem (2011). Journal of Personality and Social Psychology, 100, 426 – 432. http://dx.doi.org/10.1037/a0022790
Wagenmakers, E.-J., Beek, T., Dijkhoff, L., Gronau, Q. F., Acosta, A., Adams, R. B., … Zwaan, R. A. (2016). Registered Replication Report: Strack, Martin, & Stepper (1988). Perspectives on Psychological Science, 11(6), 917–928. https://doi.org/10.1177/1745691616674458
Wegner, D. M. (1992). The premature demise of the solo experiment. Personality and Social Psychology Bulletin, 18, 504 –508. http://dx.doi.org/10.1177/0146167292184017
Wegener, D. T., Fabrigar, L. R., Pek, J., & Hoisington-Shaw, K. (2021). Evaluating Research in Personality and Social Psychology: Considerations of Statistical Power and Concerns About False Findings. Personality and Social Psychology Bulletin, 48(7), 1105-1117. https://doi-org.myaccess.library.utoronto.ca/10.1177/01461672211030811
Wicherts, J. M., Veldkamp, C. L. S., Augusteijn, H. E. M., Bakker, M., van Aert, R. C. M., & van Assen, M. A. L. M. (2016). Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Frontiers in Psychology, 7, 1832.http://dx.doi.org/10.3389/fpsyg.2016.01832
Wilson, B. M., & Wixted, J. T. (2018). The prior odds of testing a true effect in cognitive and social psychology. Advances in Methods and Practices in Psychological Science, 1, 186 –197. http://dx.doi.org/10.1177/2515245918767122
Yamada, Y. (2018). How to crack pre-registration: Toward transparent and open science. Frontiers in Psychology, 9, 1831.http://dx.doi.org/10.3389/fpsyg.2018.01831
Yong, E. (2012). Nobel laureate challenges psychologists to clean up their act: Social-priming research needs “daisy chain” of replication. Nature. Retrieved from https://www.nature.com/news/nobel-laureate-challenges- psychologists-to-clean-up-their-act-1.11535
Yuan, K.-H., & Maxwell, S. (2005). On the Post Hoc Power in Testing Mean Differences. Journal of Educational and Behavioral Statistics, 30(2), 141–167. https://doi.org/10.3102/10769986030002141
Zwaan, R. A., Etz, A., Lucas, R. E., & Donnellan, M. B. (2018). Improving social and behavioral science by making replication mainstream: A response to commentaries. Behavioral and Brain Sciences, 41, e157. http://dx.doi.org/10.1017/S0140525X18000961