With close to 10,000 citations in WebofScience, Ed Diener’s article that introduced the “Satisfaction with Life Scale” (SWLS) is a citation classic in well-being science. While single-item measures are used in large national representative surveys (e.g., General Social Survey, German Socio-Economic Panel, World Value Survey), psychologists prefer multi-item scales because they have higher reliability and therewith also higher validity.
Study 1 in Diener et al. (1985) demonstrated that the SWLS shows convergent validity with single-item measures like Cantril’s ladder, r = .62, .66), and Andrews and Withey’s Delighted-Terrible scale, r = .68, .62. Attesting to the higher reliability of the 5-item SWLS is the finding that the internal consistency was .87 and the retest reliability was r = .82. These results suggest that the SWLS and single-item measures measure a single construct with different amounts of random measurement error.
The important question for well-being scientists who use the SWLS and other global well-being measures is whether these items measure what they are intended to measure. To answer this question, we need to know what life-satisfaction measures are intended to measure.
Diener et al. (1985) draw on Andrews and Withey’s (1976) model of well-being perceptions. Accordingly, life-satisfaction judgments are based on subjective evaluations of important concerns.
Judgments of satisfaction are dependent upon a comparison of one’s circumstances with what is thought to be an appropriate standard. It is important to point out that the judgment of how satisfied people are with their present state of affairs is based on a comparison with a standard which each individual sets for him· or herself; it is not externally imposed. It is a hallmark of the subjective well-being area that it centers on the person’s own judgments, not upon some criterion which is judged to be important by the researcher (Diener, 1984).
This definition of life-satisfaction makes two important points. First, it is assumed that respondents are thinking about their circumstances when they judge their life-satisfaction. That is, we we can think about life-satisfaction as an attitude with an individual’s life as the attitude object. Just like individuals are assumed to think about the important features of Coca Cola when they are asked to report their attitudes towards Coca Cola, respondents are assumed to think about the important features of their lives, when they report their attitudes towards their lives.
The second part of the definition makes it clear that attitudes towards lives are based on subjectively chosen criteria to evaluate lives. Just like individuals may like the taste of Coke or dislike the taste of Coke, the same life circumstance can be evaluated differently by different individuals. Some may be extremely satisfied with an income of $100,000 and some may be extremely dissatisfied with the same income. For students, some students may be happy with a GPA of 2.9, others may be unhappy with the same GPA. The reason is that the evaluation criteria or standards can very across individuals and that there is no objective criterion that is used to evaluate life circumstances. This makes life-satisfaction judgments an indicator of subjective well-being.
The reliance on subjective evaluation criteria also implies that individuals can give different weights to different life domains. For some people, family life may be the most important domain, for others it may be work (Andrews & Withey, 1976). The same point is made by Diener et al. (1985).
For example, although health, energy, and so forth may be desirable, particular individuals may place different values on them. It is for this reason that ,we need to ask the person for their overall evaluation of their life, rather than summing across their satisfaction with specific domains, to obtain a measure of overall life-satisfaction (p. 71).
This point makes sense. If life-satisfaction judgments on evaluations of life circumstances and individuals place different emphasis on different life domains, more important domains should have a stronger influence on global life-satisfaction judgments (Schimmack, Diener, & Oishi, 2002). However, starting with Andrews and Withey (1976), empirical tests of this prediction have failed to confirm it. When individuals are asked to rate the importance of life domains, and these weights are used to compute a weighted average, the weighted average is not a better predictor of global judgments than a simple unweighted average (Rohrer & Schmukle, 2018).
Although this fact has been known since 1974, its theoretical significance has been ignored. There are two possible interpretations of this finding. On the one hand, it could be that importance ratings are invalid. That is, people don’t really know what is important to them and the actual importance is best revealed by the regression weights when global life-satisfaction ratings are regressed on domain satisfaction either across participants or within-participants over time. The alternative explanation is more troubling. In this case, global life-satisfaction judgments are invalid. Maybe these judgments are not based on subjective evaluations of life-circumstances.
Schwarz and Strack (1999) made the point that global life-satisfaction judgments are based on quick heuristics that produce invalid information. The problem of their criticism is that they focused on unstable sources such as mood or temporarily accessible information as the main sources of life-satisfaction judgments. This model fails to explain the high temporal stability of life-satisfaction judgments. (Schimmack & Oishi, 2005).
However, it is possible that stable factors produce systematic method variance in life-satisfaction judgments. For example, Andrews and Withey (1976) suggested that halo bias could influence ratings of domain satisfaction and life-satisfaction. They used informant ratings to rule out this possibility, but their test of this hypothesis was statistically flawed (Schimmack, 2019). Thus, it is possible that a substantial portion of the reliable variance in SWLS scores is halo bias.
Diener et al. (1985) tried to address the problem of systematic measurement error in two ways. First, they included the Marlowe-Crowne Social Desirability (MCSD) scale to measure social desirable responding and found no correlation with SWLS scores, r = .02. The problem is that the MCSD is not a valid measure of socially desriable responding or halo bias, but rather a measure of agreeableness and conscientiousness. Thus, the correlation is better interpreted as evidence that life-satisfaction is fairly independent of these personality traits. Second, Study 3 with 53 elderly residents of Urbana-Champaign included an interview with two trained interviewers. Afterwards, the interviewers made ratings of the interviewees’ well-being. The averaged interviewer’ ratings correlated r = .43 with the self-ratings of well-being. The problem here is that individuals who are motivated to present a positive image in their SWLS ratings are also likely to present a positive image in an interview. Moreover, the conveyed sense of well-being could reflect individuals’ personality more than their life-circumstances. Thus, it is not clear how much of the agreement between self-ratings and interviewer-ratings reflects evaluations of actual life-circumstances.
The most recent review article by Ed Diener was published last year; “Advances and Open Questions in the Science of Subjective Well-Being” (Diener, Lucas, & Oishi, 2018). The article makes it clear that the construct has not changed since 1985.
“Subjective well-being (SWB) reflects an overall evaluation of the quality of a person’s life from her or his own perspective” (p. 1).
“As the term implies, SWB refers to the extent to which a person believes or feels that his or her life is going well. The descriptor “subjective” serves to define and limit the scope of the construct: SWB researchers are interested in evaluations of the quality of a person’s life from that person’s own perspective.” (p. 2)
The authors also explicitly state that subjective well-being measures are subjective because individuals can focus on different aspects of their lives depending on their importance to them.
“it is the subjective nature of the construct that gives it its power. This is due to the fact that different people likely weight different objective circumstances differently depending on their goals, their values, and even their culture” (p. 3).
The fact that global measures allow individuals to assign different weights to different domains is seen as a strength.
Presumably, subjective evaluations of quality of life reflect these idiosyncratic reactions to objective life circumstances in ways that alternative approaches (such as the objective list approach) cannot. Thus, when evaluating the impact of events, interventions, or public-policy decisions on quality of life, subjective evaluations may provide a better mechanism for assessment than alternative, objective approaches (p. 3).
The problem is that this claim requires empirical evidence to show that global life-satisfaction judgments are indeed more valid measures of subjective well-being than simple averages because they properly weigh information in accordance with individuals’ subjective preferences, and since 1976 this evidence has been lacking.
Diener et al.’s (2018) review glosses over this glaring problem for the construct validity of the SWLS and other global well-being measures.
Because most measures are simple self-reports, considerable research addresses the psychometric properties of these types of assessments. This research consistently shows that existing self-report measures exhibit strong psychometric properties including high internal consistency when multiple-item measures are used; moderately strong test-retest reliability, especially over short periods of time; reasonable convergence with alternative measures (especially those that have also been shown to have high levels of reliability and validity); and theoretically meaningful patterns of associations with other constructs and criteria (see Diener et al., 2009, and Diener, Inglehart, & Tay, 2013, for reviews). There is little debate about the quality of SWB measures when evaluated using these traditional criteria.
While it is true that there is little debate, this does not mean that there is strong evidence for the construct validity of the SWLS. The open question is how much respondents are really conducting a memory search for information about important life domains, evaluate these domains based on subjective criteria, and then report an overall summary of these evaluations. If so, subjective importance weights should improve predictions, but they often do not. Moreover, in regression models individual life domains often contribute small amounts of unique variance (Andrews & Withey, 1976), and some important aspects like health often account for close to zero percent of the variance in life-satisfaction judgments.
Convergent Validity
One key feature of construct validity is convergent validity between two independent methods that measure the same construct (Campbell & Fiske, 1959). Ideally, multiple methods are used and it is possible to examine whether the pattern of correlations matches theoretical predictions (Cronbach & Meehl, 1955; Schimmack, 2019). Diener et al. (2018) mention some evidence of convergent validity.
For example, Schneider and Schimmack (2009) conducted a meta-analysis of the correlation between self and informant reports, and they found that there is reasonable agreement (r = .42) between these two methods of assessing SWB.
The problem with this evidence is that the correlation between two measures only shows that both methods are valid, but it is not possible to quantify the amount of valid variance in self-ratings or informant ratings, which requires at least three methods (Andrews & Withey, 1976; Zou, Schimmack, & Gere, 2013). Theoretically, it would be possible that most of the variance in self-ratings is valid and that informant ratings are rather invalid. This is what Andrews and Withey (1976) claimed with estimates of 65% valid variance in self-ratings and 15% valid variance in informant ratings, with a correlation of r = .32. However, their model was incorrect and allowed for method variance in self-ratings to inflate the factor loading of self-ratings.
Zou et al. (2013) avoided this problem by using self-ratings and ratings by two informants as independent methods and found no evidence that self-ratings are more valid than informant ratings; a finding that is mirrored in ratings of personality traits (Anusic et al., 2009). Thus, a correlation of r = .3, implies that 30% of the variance in self-ratings is valid and 30% of the variance in informant ratings is valid.
While this evidence shows that self-ratings of life-satisfaction show convergent validity with informant ratings, it also shows that a substantial portion of the reliable variance in self-ratings is not shared with informants. Moreover, it is not clear what information produces agreement between self-ratings and informant ratings. This question has received surprisingly little attention, although it is critical for the construct validity of life-satisfaction judgments. Two articles have examined this question with opposite conclusions. Schneider and Schimmack (2010) found some evidence that satisfaction in important life domains contributed to self-informant agreement. This finding would support the bottom-up model of well-being judgments that raters are actually considering life circumstances when they make well-being judgments. In contrast, Dobewall, Realo, Allik, Esko, andMetspalu (2013) proposed that personality traits like depression and cheerfulness accounted for self-informant agreement. In this case, informants do not need ot know anything about life circumstances. All they need to know is whether an individual has a positive or negative lens to evaluate their lives. If informants are not using information about life circumstances, they cannot be used to validate self-ratings to show that self-ratings are based on evaluations of life circumstances.
Diener et al. (2018) cite a number of additional findings as evidence of convergent validity.
Physiological measures, including brain activity (Davidson, 2004) and hormones (Buchanan, al’Absi, & Lovallo, 1999), along with behavioral measures such as the amount of smiling (e.g., Oettingen & Seligman, 1990; Seder & Oishi, 2012) and patterns of online behaviors (Schwartz, Eichstaedt, Kern, Dziurzynski, Agrawal et al., 2013) have also been used to assess SWB. (p. 7).
This evidence has several limitations. First, hormones do not reflect evaluations and are at best indirectly related to life-evaluations. Asymmetries in prefrontal brain activity (Davidson, 2004) have been shown to reflect approach and avoidance motivation more than pleasure and displeasure, and brain activity is a better measure of momentary states than the evaluation of fairly stable life circumstances. Finally, they also may reflect individuals’ personality more than their life circumstances. The same is true for the behavioral measures. Most important, correlations with a single indicators do not provide information about the amount of valid variance in life-satisfaction judgments. To quantify validity it is necessary to examine these findings within a causal network (Schimmack, 2019).
Diener et al. (2019) agree with my assessment in their final conclusions about measurement of subjective well-being.
The first (and perhaps least controversial) is that many open questions remain regarding the associations among different SWB measures and the extent to which these measures map on to theoretical expectations; therefore, understanding how the measures relate and how they diverge will continue to be one of the most important goals of research in the area of SWB. Although different camps have emerged that advocate for one set of measures over others, we believe that such advocacy is premature. More research is needed about the strengths, weaknesses, and relative merits of the various approaches to measurement that we have documented in this review (p. 7).
The problem is that well-being scientists have made no progress on this front since Andrews and Withey (1976) conducted the first thorough construct validation studies. The reason is that social and personality psychology suffers from a validation crisis (Schimmack, 2019). Researchers simply assume that measures are valid rather than testing it or they use necessary, but insufficient criteria like internal consistency (alpha), retest reliability as evidence. Moreover, there is a tendency to ignore inconvenient findings. As a result, 40 years after Andrews and Withey’s (1976) seminal article was published, it remains unclear (a) whether respondents aggregate information about important life domains to make global judgments, (b) how much of the variance in life-satisfaction judgments is valid, and (c) which factors produce systematic biases in life-satisfaction judgments that may lead to false conclusions about the causes of life-satisfaction and to false policy recommendations.
Health is probably the best example to illustrate the importance of valid measurement of subjective well-being. It makes intuitive sense that health has an influence on well-being. Illness often disables individuals from pursuing their goals and enjoying life as everybody who had the flu knows. Diener et al. (2018) agree.
“One life circumstance that might play a prominent role in subjective well-being is a person’s health” (p. 15).
It is also difficult to see how there could be dramatic individual differences in the criteria that are used to evaluate health. Sure, fitness levels may be a matter of personal preference, but nobody is enjoying a stroke, heart attack, or cancer, or even having the flu.
Thus, it was a surprising finding that health seemed to have a small influence on global well-being judgments.
“Initial research on the topic of health conditions often concluded that health played only a minor role in wellbeing judgments (Diener et al., 1999; Okun, Stock, Haring, & Witter, 1984).”
More problematic was the finding that subjective evaluations of health seemed to play no role in these judgments in multivariate analyses that controlled for shared variance among ratings of several life domains. For example, in Andrews and Withey’s (1976) studies satisfaction with health contributed only 1% unique variance in the global measure.
In contrast, direct importance ratings show that health is rated as the second most important domain (Rohrer & Schmukle, 2018).
Thus, we have to conclude that health doesn’t seem to matter for people’s subjective well-being. Or we can conclude that global measures are (partially) invalid measures because respondents do not weigh life domains in accordance with their importance. This question clearly has policy relevance as health care costs are a large part of wealthy nations’ GDP and financing health care is a controversial political issue, especially in the United States. Why would this be the case, if health is actually not important for well-being. We could argue that it is important for life expectancy (Veenhoven’s happy life-years) or that it matters for objective well-being, but not for subjective well-being, but clearly the question why health satisfaction plays a small role in global measures of subjective well-being is an important one. The problem is that 40 years of well-being science have passed without addressing this important question. But as they say, better late than never. So, let’s get on with it and figure out how responses to global well-being questions are made and whether these cognitive processes are in line with the theoretical model of subjective well-being.
In 1976, Andrews and Withey published a groundbreaking book on the measurement of well-being. Although their book has been cited over 2,000 times, including influential articles like Diener’s 1984 and 1999 Psychological Bulletin articles on Subjective Well-Being, it is likely that many people are not familiar with the book because books are not as accessible as online articles. The aim of this blog post is to review and comment on the main points made by Andrews and Withey.
CHAPTER 1: Introduction
A&W (wink) believed that well-being indicators are useful because they reflect major societal forces that influence individuals’ well-being.
“In these days of growing interdependence and social complexity we need more adequate cues and indicators of the nature, meaning, pace, and course of social change” (p. 1).
Presumably, A&W would be pleasantly surprised about the widespread use of well-being surveys for this purpose. Well-being questions are included in the General Social Survey, The German Socio-Economic Panel Study, the World Value Survey, and Gallup’s World Poll and the daily survey of Americans’ well-being and health.
A&W saw themselves as part of a broader movement towards evidence based public policy.
The social indicator “movement” is gaining adherents all over the world. … Several facets of these definitions reflect the basic perspectives of the social indicator effort. The quest is for a limited yet comprehensive set of coherent and significant indicators, which can be monitored over time, and which can be disaggregated to the level of the relevant social unit (p. 4).
Objective and Subjective Indicators
A&W criticize the common distinction between objective and subjective indicators of well-being. Objective indicators such as hunger, pollution, or unemployment are factors that are universally considered bad for individuals are typically called objective indicators.
A&W propose to distinguish three features of indicators.
Thus, it may be more helpful and meaningful to consider the individualistic or consensual aspects of phenomena, the private or public accessibility of evidence, and the different forms and patterns of behavior needed to change something rather than to cling to the more simplistic notions of objective and subjective.
They propose to use “perceptions of well-being” as a social indicator. This indicator is individualistic, private, and may require personalized interventions to change them.
The work of engineers, industrialists, construction workers, technological innovators, foresters, and farmers who alter the physical and biological environment is matched by educators, therapists, advertisers, lovers, friends, ministers, politicians, and issue advocates who are all interested and active in constructing, tearing down, and remodeling subjective appreciations and experiences. (p. 6)
A&W argue that measuring “perceptions of well-being” is important because citizens of modern societies share the belief that societies should maximize well-being.
The promotion of individual well-being is a central goal of virtually all modern societies, and of many units within them. While there are real and important differences of opinion-both within societies and between them-about how individual well-being is to be maximized, there is nearly universal agreement that the goal itself is a worthy one and is to be actively pursued. (p. 7).
Research Goals
A&W’s goal was to develop a set of indicators (not just one) that fulfill several criteria that can be considered validation criteria.
1. Content validity. Their coverage should be sufficiently broad to include all the most important concerns of the population whose well-being is to be monitored. If the relevant population includes demographic or cultural subgroups that might be the targets of separate social policies, or that might be affected differentially by social policies, the indicators should have relevance for each of the subgroups as well as for the whole population.
2. Construct Validity. The validity (i.e., accuracy) with which the indicators are measured should be high, and known.
3. Parsimony and Efficiency: It should be possible to measure the indicators with a high degree of statistical and economic efficiency so that it is feasible to monitor them on a regular basis at reasonable cost.
4. Flexibility: The instrument used to measure the indicators should be flexible so that it can accommodate different trade-offs between resource input, accuracy of output, and degree of detail or specificity.
In short, the indicators should be measured with breadth, relevance, efficiency, validity, and flexibility. (p. 8).
A&W then list several specific research questions that they aimed to answer.
1. What are the more significant general concerns of the American people?
2. Which of these concerns are relevant to Americans’ sense of general wellbeing?
3. What is the relative potency of each concern vis-a.-vis well-being?
4. How do the relevant concerns relate to one another?
5. How do Americans arrive at their general sense of well-being?
6. To what extent can Americans easily identify and report their feelings about well-being?
7. To what extent will they bias their answers?
8. How stable are Americans’ evaluations of particular concerns?
9. How comparable are various subgroups within the American population with respect to each of the questions above?
Although some of these questions have been examined in great detail others have been neglected in the following decades of well-being research. In particular, very little attention has been paid to questions about the potency (strength of influence) of different concerns for global perceptions of well-being, and to the question how different concerns are related to each other. In contrast, the stability of well-being perceptions has been examined in numerous longitudinal studies (see Anusic & Schimmack, 2016, for the most recent meta-analysis).
Usefulness
A&W “propose six products of value to social scientists, to policymakers and implementers of policy, and to people who want to influence the course of society” (p. 9).
1. Repeated measurement of well-being perceptions can be used to see whether (humans’) lives are betting better or worse.
2. Comparison of groups (e.g., men vs. women, White vs. Black Americans) can be used to examine equity and inequity in well-being.
3. Positive or negative correlations among domains can be informative. For example, marital satisfaction may be positively or negatively correlated to each other, and this evidence has been used to study work-family or work-live balance.
4. It is possible to see how much well-being perceptions are based on more objective aspects of life (job, housing) versus more abstract aspects such as values or meaning.
5. It is informative to see what domains have a stronger influence on well-being perceptions, which shows people’s values and priorities.
6. It is important to know whether people appreciate actual improvement. For example, a drop in crime rates is more desirable if citizens also feel safer. “The appreciation of life’s conditions would often seem to be as important as what those conditions actually are” (p. 10).
One may justifiably claim, then, that people’s evaluations are terribly important: to those who would like to raise satisfactions by trying to meet people’s needs, to those who would like to raise dissatisfactions and stimulate new challenges, to those who would suppress or reduce feelings and public expressions of discontent, and above all, to the individuals themselves. It is their perceptions of their own well-being, or lack of well-being, that ultimately define the quality of their lives (p. 10).
BASIC CONCEPTS AND A CONCEPTUAL MODEL
The most important contribution of A&W is their conception of well-being as a broad evaluations of important life domains. We might think about a life as a pizza with several slices that have different toppings. Some are appealing (say ham and pineapple) and some are less appealing (say sardines and olives). Well-being is conceptualized as the sum or average of evaluations of the different slices. This view of well-being is now called the bottom-up model after Diener (1984).
We conceive of well-being indicators as occurring at several levels of specificity. The most global indicators are those that refer to life as a whole; they are not specific to anyone particular aspect of life (p. 11).
Mostly forgotten is A&W’s distinction between life domains and criteria.
Domains and Criteria
Domains are essentially different slices of the pizza of life such as work, family, health, recreation.
Criteria are values, standards, aspirations, goals, and-in general-ways of judging what the domains of life afford. In modern research, they are best represented by models of human values or motives, such as Schwartz’s model of human values. Thus, life domains or aspects can be desirable or undesirable because the foster or block fulfillment of universal needs for safety, freedom, pleasure, connectedness, and achievement to name a few.
The quality of life is not just a matter of the conditions of one’s physical, interpersonal and social setting but also a matter of how these are judged and evaluated by oneself and others. The values that one brings to bear on life are in themselves determinants of one’s assessed quality of life. Leave the situations of life stable and simply alter the standards of judgment and one’s assessed quality of life could go up or down according to the value framework. (p. 13).
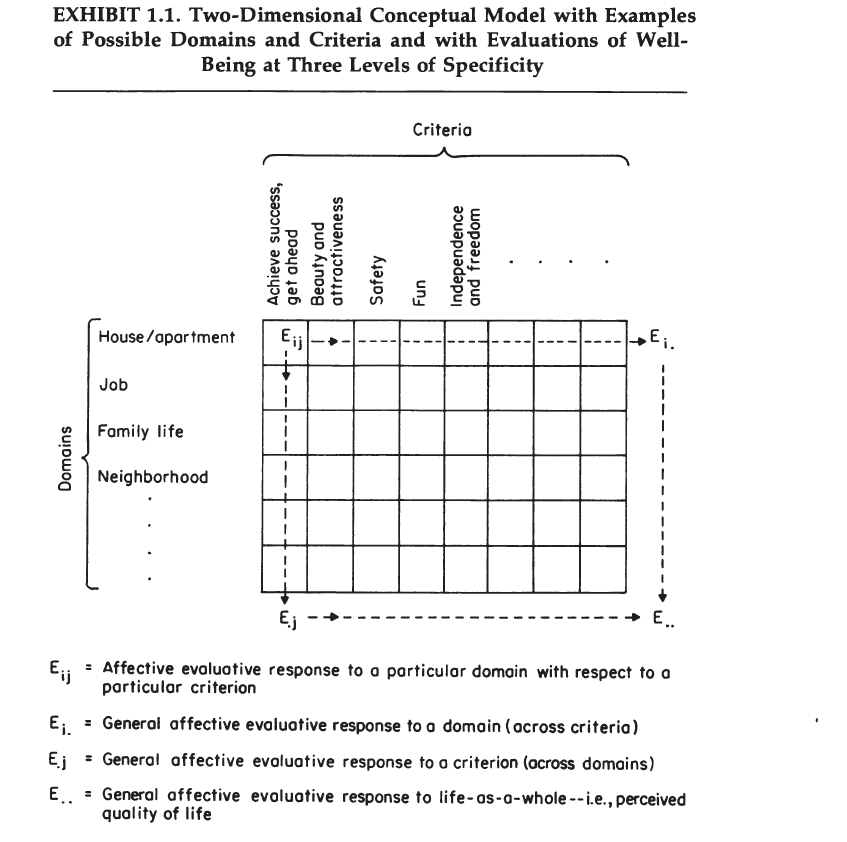
A Conceptual Model
A&W’s Exhibit 1.1 shows a grid of life domains and evaluation criteria (values). According to their bottom-up model, perceptions of well-being are an integrated summary of these lower-order evaluations of specific life domains.
“The diagram is also intended to imply that global evaluations-i.e., how a person feels about life as a whole-may be the result of combining the domain evaluations or the criterion evaluations” (p. 14)
METHODS AND DATA
The Measurement of Affective Evaluations
A&W proposed that perceptions of well-being are based on two modes of evaluation.
The basic entries in the model, just described, are what we designate as “affective evaluations.” The phrase suggests our hypothesis that a person’s assessment of life quality involves both a cognitive evaluation and some degree of positive and/or negative feeling, i.e., “affect.”
One mode is cognitive and could be performed by a computer. Once objective circumstances are known and there are clear criteria for evaluation, it is possible to compute the discrepancy. For example, if a person needs $40,000 a year to afford housing, food, and basic necessities, an income of $20,000 is clearly inadequate, whereas an income of $70,000 is more than adequate. However, A&W also propose that evaluations have a feeling or affective component. That is, the individual who earns only $20,000 may feel worse about their income, while the individual with a $70,000 income may feel good about their income.
Not much progress has been made in terms of distinguishing affective or cognitive evaluations, especially when it comes to evaluations of specific life domains. One problem is that it is difficult to measure affective reactions and that self-reports of feelings may simply be cognitive judgments. It is therefore easier to think about well-being “perceptions” as evaluations, without trying to distinguish between cognitive and affective evaluations.
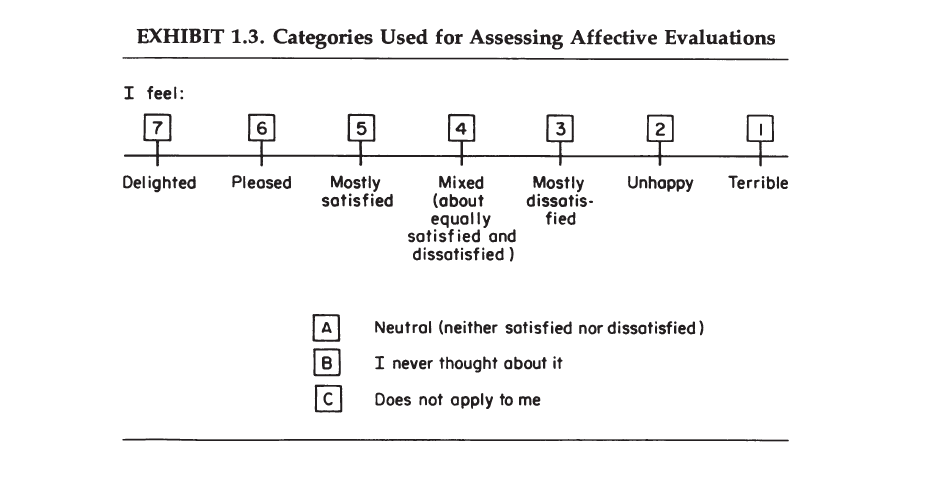
Both global and more specific evaluations are measured with rating scales. A&W favored the delighted-terrible scale, but it didn’t catch on. Much more commonly used is Cantril’s Ladder or life-satisfaction or happiness questions.
In the next section of this interview/questionnaire we want to find out how you feel about various parts of your life, and life in this country as you see it. Please tell me the feelings you have now-taking into account what has happened in the last year and what you expect in the near future.
A&W were concerned that a large proportion of respondents’ report high levels of satisfaction because they are merely satisfied, but not really happy or delighted. They also wanted a 7-point scale and suggested that more categories would not produce more sensitive responses, while a 7-point scale is clearly preferable to the 3-point happiness measure that is still used in the General Social Survey. They also wanted a scale where each response option is clearly labelled, while some scales like Cantril’s ladder only label the most extreme options (best possible life, worst possible life).
Data Sources
A&W conducted several cross-sectional surveys.
CHAPTER 2: Identifying and Mapping Concerns
Research Strategy
The basic strategy of our approach was first to assemble a very large number of possible life concerns and to write questionnaire items to tap people’s feelings, if any, about them. Then, having administered these items to broad samples of Americans, we used the resulting data to empirically explore how people’s feelings about these items are organized.
IDENTIFYING CONCERNS
The task of identifying concerns involved examining four different types of sources.
One source was previous surveys that had included open questions about people’s concerns. Two examples of such items are:
All of us want certain things out of life. When you think about what really matters in your own life, what are your wishes and hopes for the future? In other words, if you imagine your future in the best possible light, what would your life look like then, if you are to be happy? (Cantril, 1965)
In this study we are interested in people’s views about many different things. What things going on in the United States these days worry or concern you? (Blumenthal et aI., 1972)
In our search for expression of life concerns, we examined data from these very general unstructured questions in eight different surveys.
A second type of source was structured interviews, typically lasting an hour or two with about a dozen people of heterogeneous background.
A third type of source, particularly useful for expanding our list of criterion-type concerns, was previously published lists of values.
This information was used to create items that were administered in some of the surveys.
MAPPING THE CONCERNS
Given the list of 123 concern items, the next step was to explore how they fit together in people’s thinking.
Maps and the Mapping Process
Selecting and Clustering Concern-Level Measures
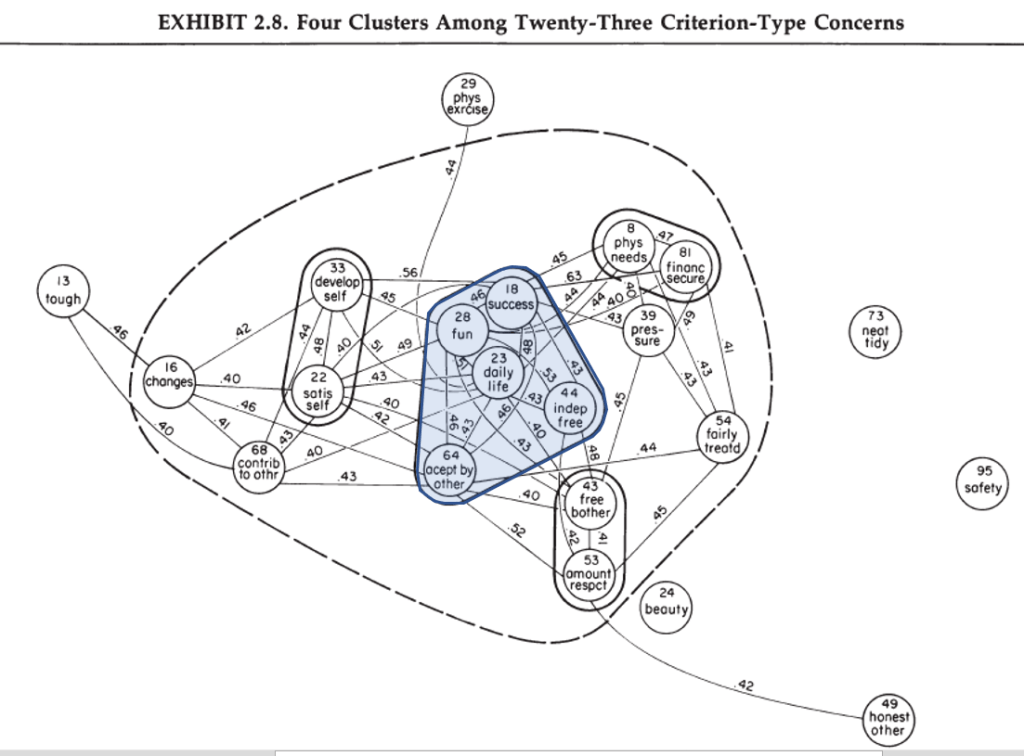
A&W’s work identified clusters of concerns that are often included in surveys of domain satisfaction such as work (green), recreation (orange), standard of living (purple), housing (light blue), health (red), and family (dark blue).
The map for criteria, shows that the most central values are hedonism (having fun), achievement, acceptance and affiliation (accept by other) and freedom.
These findings are consistent with modern conceptions of well-being as the freedom to seek pleasure and to avoid pain (Bentham).
CHAPTER 3: Measuring Global Well-Being
A&W compiled 68 items that had been used to measure global well-being.
Formal Structure of the Typology
A&W provided a taxonomy of the various global measures.
Accordingly, measures can differ in the perspective of the evaluation, the generality of the evaluation, and the range of the evaluation. For the measurement of global well-being general measures that cover the full-range from an absolute perspective are most widely used.
“We find that the Type A measures, involving a general evaluation of the respondent’s life-as-a-whole from an absolute perspective, tend to cluster together into what we shall call the core cluster” (p. 76).
A study of the retest stability for the same item in the same survey showed a retest correlation of r = .68. This estimate for the reliability of a single global well-being rating has been replicated in numerous studies (see Ansic & Schimmack, 2005; Schimmack & Oishi, 2005; for meta-analyses).
A&W also provided some evidence about measurement invariance across subgroups (gender, racial groups, age groups) and found very similar results.
“The results (not shown) indicated very substantial stabilities across the subgroups. In nearly all cases the correlations within the subgroups were within 0.1 of the correlations within the total population.” (p. 83).
The next results show that different global well-being measures tend to be highly correlated with each other. Exceptions are the 3-point happiness scale in the GSS, which lacks sensitivity, and the affect measure because affect measures show some discriminant validity from life evaluations (Zou, Schimmack, & Gere, 2013). That is, an individuals’ perception of well-being is not fully determined by their perception of how much pleasure versus displeasure they experienced.
A principal component analysis showed items with high loadings that best capture the shared variance among global well-being measures.
The results show that the 7-point delighted-terrible (Life 1, Life 2) or a 7-point happiness scale capture this variance well.
These results lead A&W to conclude that these measures are valid and useful indicators of well-being.
“We believe the Type A measures clearly deserve our primary attention. Thus, it is reassuring to find that the Type A measures provide a statistically defensible set of general evaluations of the level of current wellbeing” (p. 106).
CHAPTER 4: Predicting Global Well-Being: I
A&W argue that statistical predictors of global well-being ratings provide useful information about the cognitive processes (what is going on in the minds of respondents) underlying well-being ratings.
Finding a statistical model that fits the data has real substantive interest, as well as methodological, because in these data the statistical model can also be considered as a psychological model. Not only is the model that method of combining feelings that provides the best predictions, it is also our best indication of what may go on in the minds of the respondents when they themselves combine feelings about specific life concerns to arrive at global evaluations. Thus, our statistical model can also be considered as a simulation of psychological processes (p. 109).
This assumption is reasonable as ratings are clearly influenced by some information in memory that is activated during the formation of a response. However, the actual causal mechanism can be more complicated. For example, job satisfaction may be correlated with global well-being only because respondents’ think about income and income satisfaction is related with job satisfaction. Moreover, Diener (1984) pointed out that causality may flow from global well-being to domain satisfaction, which is now called a top-down process. Thus, rather than job satisfaction being used to make a global well-being judgment, respondents’ affective disposition may influence their job satisfaction.
A&W’s next finding has been replicated and emphasized in many review articles on well-being.
The prediction of global well-being from the demographic characteristics of the respondents produced straightforward results that have proved surprising to some observers: The demographic variables, either singly or jointly, account for very little of the variance in perceptions of global well-being (less than 10 percent), and they add nothing to what can be predicted (more accurately) from the concern measures (p. 109).
This finding has also been misinterpreted as evidence that objective life circumstances have a small influence on well-being. The problem with this interpretation is that demographic variables do not represent all environmental influences and many of them are not even environmental factors (e.g., sex, age, race). It is true, however, that there are relatively small differences in well-being perceptions across different groups. The main exception is a persistent gap in well-being of White and Black Americans (Iceland & Ludwig-Dehm, 2019).
A&W conducted numerous tests to look for non-linear relationships. For example, only very low income satisfaction or health satisfaction may be related to global well-being if moderate levels of income or health are sufficient to be satisfied with life. However, they found no notable non-linear relationships.
However, after examining many associations between feelings about specific life concerns and life-as-a-whole, we conclude that substantial curvilinearities do not occur when affective evaluations are assessed using the DelightedTerrible Scale (p. 110).
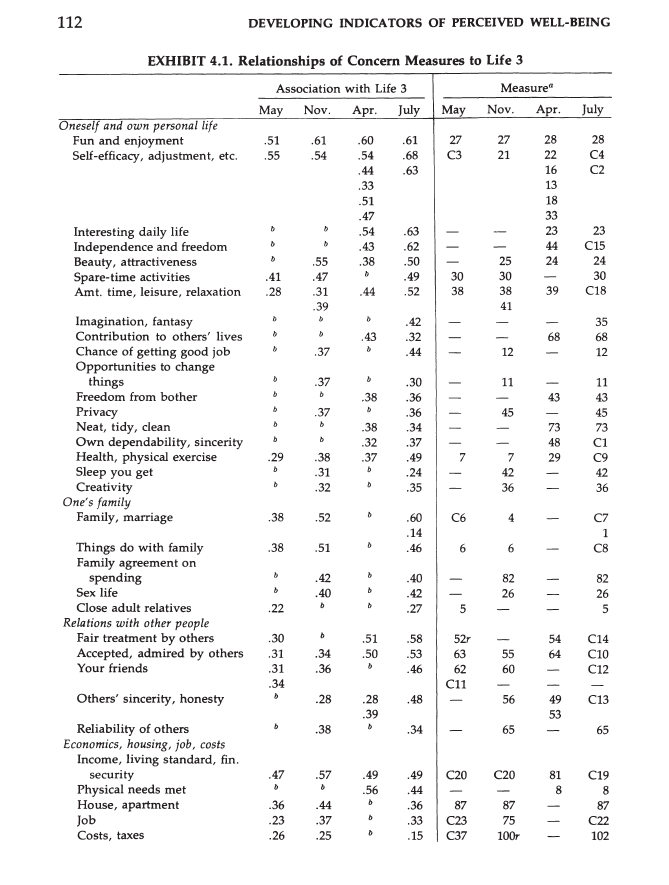
Exhibit 4.1 shows simple linear correlations of various life concerns with the averaged repeated ratings on the Delighted-Terrible scale (Life 3).
The main finding is that all correlations are positive, most are moderate, and some are substantial (r > .5), such as the correlations for fun/enjoyment, self-efficacy, income, and family/marriage.
It is important to interpret differences in the strength of correlations with caution because several factors influence how strong these correlations are. One factor is the amount of variability in a predictor variable. For example, while incomes can vary dramatically, the national government is the same for everybody. Thus, there is no variability in government that can produce variability in well-being across respondents; although perceptions of government can vary and could influence well-being perceptions. Keeping this caveat in mind, the results suggest that concerns about standard of living and family life seem to matter most. Interestingly, health is not a major factor, but once again, this might simply reflect relatively small variability in actual health, while health may become more of a concern later in life.
Nevertheless, while the causal processes that produce these correlations are unclear, any theory of well-being has to account for this robust pattern of correlations. between global well-being perceptions and concerns.
MULTIVARIATE PREDICTION OF LIFE 3
Regression analysis aims to identify variables that make a unique contribution to the prediction of an outcome. That is, they share variance with the outcome that is not shared by other predictor variables.
As mentioned before, there was no evidence of marked non-linearity, so all variables were entered as measured without transformation or quadratic terms. A&W also examined potential interaction effects, but did not find evidence for these either.
Weighting Schemes
One of the most important analyses was the exploration of different weighting schemes. Intuitively, it makes sense that some domains are more important than others (e.g., standard of living vs. weather). If this is the case, a predictor that weights standard of living more should be a better predictor of well-being than a predictor that weights all concerns equally.
A&W found that a simple average of 12 concerns was highly correlated with the global measure.
Several explorations provide consistent and clear answers to these questions. A simple summing of answers to any of certain alternative sets of concern items (coded from 1 to 7 on the Delighted-Terrible Scale) provides a prediction of feelings about life-as-a-whole that correlates rather well with the respondent’s actual scores on Life 3. Using twelve selected concerns12 (mainly domains) and data from the May respondents, this correlation was .67 (based on 1,278 cases); using eight selected concerns13 (all criteria) and data from the April respondents, the correlation was .77 (based on 1,070 cases). These relatively high values obtain in subgroups of the population as well as in the population as a whole: When the sum of answers to eight of the April concern items was correlated with Life 3 in twenty-one different subgroups of the national adult population, the correlation was never lower than .70 nor higher than .82. (p. 118).
However, more important is the question whether other weighing schemes produce higher correlations, and the important finding is that optimal weights (using regression coefficients) produced only a small improvement in the multiple correlation.
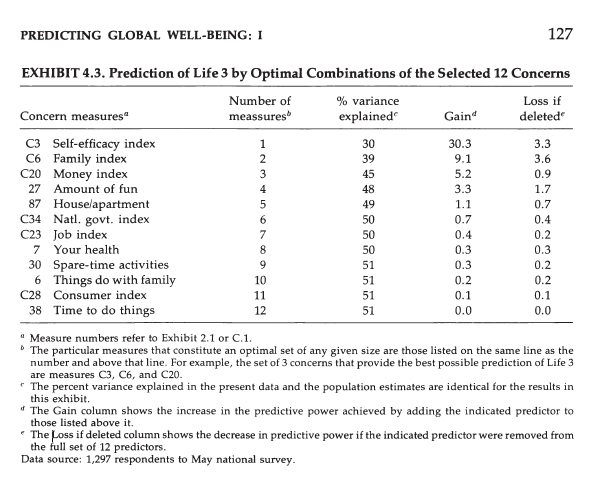
What is extremely interesting is that the optimally weighted combination of concern measures provides a prediction of Life 3 that is, at most, only modestly better than that provided by the simple sum. In the May data, the previous correlation of .67 could be increased to .71 by optimally weighting the twelve concern measures.
A&W conclude that a model with equal weights is a parsimonious and good model of well-being.
Our conclusion is that the introduction of weights when summing answers to the concern measures is likely to produce a modest improvement, but that even a simple sum of the answers provides a prediction that is remarkably close to the best that can be statistically derived.
However, the use of a fixed regression weight implies that all respondents attach the same importance of different domains. It is plausible that this is not the case. For example, some people live to work and others work to live. So, work would have different importance for different respondents. A&W tested this by asking respondents about the importance of several domains and used this information to weight concerns on a person by person basis. They found that this did not improve prediction.
The significant finding that emerged is that there was no possible use of these importance data that produced the slightest increase in the accuracy with which feelings about life-as-a-whole could be predicted over what could be achieved using an optimally weighted combination of answers to the concern measures alone.Although a number of questions remain with respect to the nature and meaning of the importance measures (some are explored in chap. 7), we have an unambiguous answer to our original question: Data about the importance people assign to concerns did not increase the accuracy with which feelings about life-as-a-whole could be predicted (p. 119).
This surprising result has been replicated numerous times (Rohrer & Schmukle, 2018). However, nobody has attempted to explain why importance weights do not improve prediction. After all, it is theoretically nonsensical within A&W’s theoretical framework to say that work, family, and health are very important, to be extremely dissatisfied in these domains, and then to report high global well-being. If global well-being judgments are, indeed, based on information about concerns and life domains, then important life domains should have a stronger relationship with global well-being ratings than unimportant domains (cf. Schimmack, Diener, & Oishi, 2002).
While I share A&W’s surprise, I am much less pleased by this finding.
Our results point to a simple linear additive one, in which an optimal set of weights is only modestly better than no weights (i.e. equal weights).19 We confess to both surprise and pleasure at these conclusions (p. 120).
A&W are pleased because a simple additive, linear model is simple and science favors simple models, when they fit actual data reasonably well, which seems to be the case here.
However, A&W are too quick to interpret their results as support for their bottom-up model of well-being, where everybody weights concerns equally and well-being perceptions depend only on the relative standing in life domains (good job, happy marriage, etc.).
Interpreted in this light, the linear additive model suggests that somehow individuals themselves “add up” their joys and sorrows about specific concerns to arrive at a feeling about general well-being. It appears that joys in one area of life may be able to compensate for sorrows in other areas; that multiple joys accumulate to raise the level of felt well-being; and that multiple sorrows also accumulate to lower it.
In discussing these findings with various colleagues and commentators, the question has sometimes been raised as to whether the model implies a policy of “give them bread and circuses.” The model does suggest that bread and circuses are likely to increase a population’s sense of general well-being. However, the model does not suggest that bread and circuses alone will ensure a high level of well-being. On the contrary, it is quite specific in noting that concerns that are evaluated more negatively than average (e.g., poor housing, poor government, poor health facilities, etc.) would be expected to pull down the general sense of well-being, and that multiple negative feelings about life would be expected to have a cumulative impact on general well-being.
At least at this stage of the investigation in Chapter 4 other, more troubling interpretations of the results are possible. Maybe most of the variance in these evaluative judgments are response biases and social desirable responding. This alone could produce strong correlations and they would be independent of the actual concerns that are being rated. Respondents could rate the weather on Mars and we would still see that those who are more satisfied with the weather on Mars have higher global well-being.
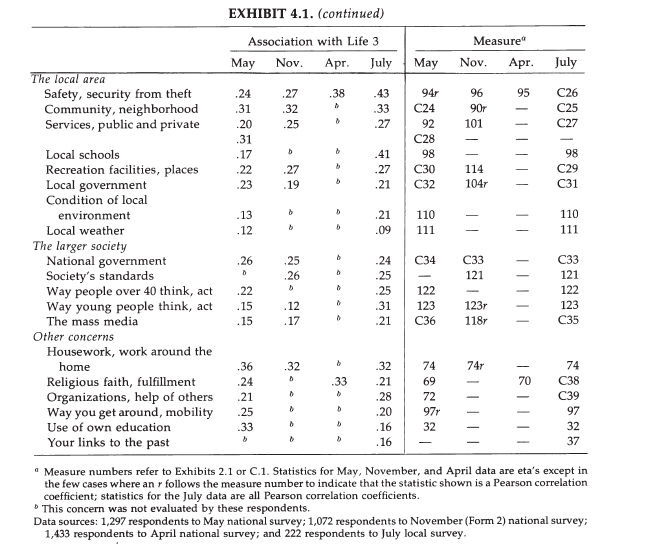
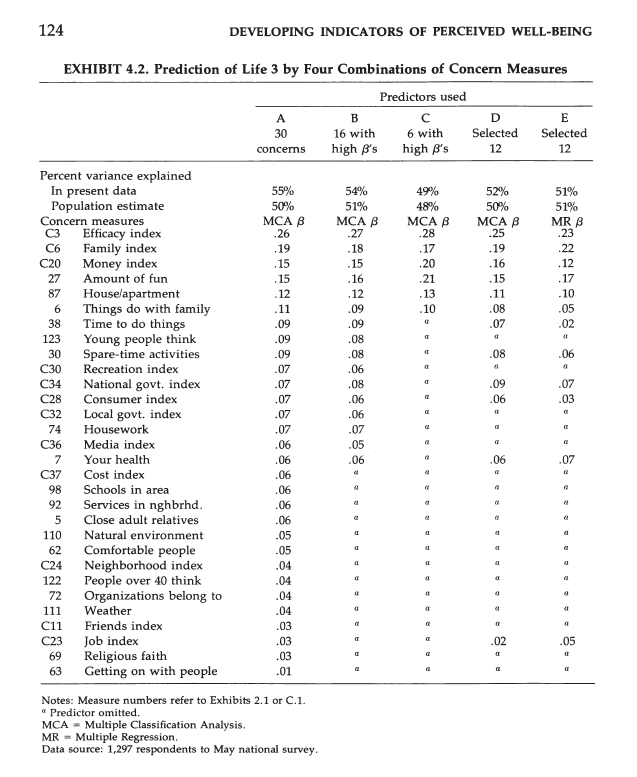
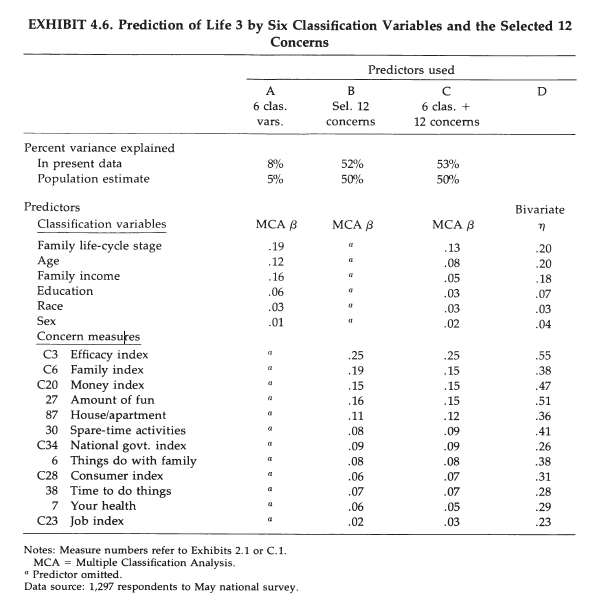
However, A&W’s subsequent analyses are inconsistent with their conclusions. Exhibit 4.2 shows the regression weights for various concerns that are sorted by the amount of unique contribution to the global impressions. It is clear that averaging the top 12 concerns would give a measure that is more strongly related to global well-being than averaging the last 12 concerns. Thus, domains do differ in importance. The results in the last column (E) are interesting because here 12 domains explain 51% of the total variance, but squaring the regression coefficients provides only 17% of variance, which implies that most of the explained variance stems from variance that is shared among the predictor variables. Thus, it is important to examine the nature of this shared variance more closely. In this mode, the first five domains account for 15 of the 17 percent in total. These domains are efficacy, family, money, fun, and housing. Thus, there is some support for the bottom-up model for some domains, but most of the explained variance may stem from shared method variance between concern ratings and well-being ratings.
Exhibit 4.3 confirms this with a stepwise regression analysis where concerns are entered according to their unique importance. Self-efficacy alone accounts for 30% of the explained variance. Then family adds 9%, money adds 5%, fun adds 3%, and housing 1%. The remaining variables add less than 1% individually.
Exhibit 4.4 shows that demongraphic variables are weak predictors of well-being ratings and that these relationships are weakened when concerns are added as predictors (column 3).
This suggests that effects of demongraphic variables are at least partially mediated by concerns (Schimmack, 2008). For example, the influence of income on well-being ratings could be explained by the effect of income on satisfaction with money, which is a unique predictor of well-being ratings (income -> money satisfaction-> life satisfaction). The limitation of regression analysis is that it does not show which of the concerns mediates the influence of income. A better way to examine mediation is to test mediation models with structural equation modeling (Baron & Kenny, 1986).
A&W draw the conclusion that there are no major differences in perceived well-being between social groups. As mentioned before, this is only partially correct. The GSS shows consistent racial differences in well-being.
“The conclusion seems inescapable that there is no strong and direct relationship between membership in these social subgroups and feelings about life-as-a-whole” (p. 142).
CHAPTER 5: Predicting Global Well-Being: II
Chapter 5 does not make a major novel contribution. It mainly explores how concerns are related to the broader set of global measures. The results show that the findings in Chapter 4 generalize to other global measures.
CHAPTER 6: Evaluating the Measures of Well-Being
Chapter 6 tackles the important question of construct validity. Do global measures measure individuals’ true evaluations of their lives?
How good are the measures of perceived well-being reported in previous chapters of this book? More specifically, to what extent do the data produced by the various measurement methods indicate a person’s true feelings about his life? (p. 175).
A&W note several reasons why global ratings may have low validity.
Unfortunately, evaluating measures of perceived well-being presents formidable problems. Feelings about one’s life are internal, subjective matters. While very real and important to the person concerned, these feelings are not necessarily manifested in any direct way. If people are asked about these feelings, most can and will speak about them, but a few may lie outright, others may shade their answers to some degree, and probably most are influenced to some extent by the framework in which the questions are put and the format in which the answers are expected. Thus, there is no assurance that the answers people give fully represent their true feelings. (p. 176)
ESTIMATION OF THE VALIDITY AND ERROR COMPONENTS OF THE MEASURES
Measurement Theory and Models
A&W are explicit in their ambition. They want to estimate the proportion of variance in global well-being measures that reflects respondents’ true evaluations of their lives. They want to separate this variance from random measurement error, which is relatively easy, and systematic measurement error, which is hard (Campbell & Fiske, 1959).
The analyses to be reported in this major section of the chapter begin from the fact that the variance of any measure can be partitioned into three parts: a valid component, a correlated (i.e., systematic) error component, and a random error (or “residual”) component. Our general analysis goal is to estimate, for measures of different types, from different surveys, and derived from different methods, how the total variance can be divided among these three components (p. 178).
A “validity coefficient,” as this term is commonly used by social scientists, is the correlation (Pearson’s product-moment r) between the true conditions and the obtained measure of those conditions. The square of the validity coefficient gives the proportion of observed variance that is true variance; e.g., a measure that has a validity coefficient of .8 contains 64 percent valid variance; similarly, a measure that contains 49 percent valid variance has a validity of .7. (p. 179; cf. Schimmack, 2010).
One source of systematic measurement error are response sets such as aquiescence bias. Another one is halo bias.
A special form of bias is what is sometimes known as “halo.” One would hope that a respondent, when answering a series of questions about different aspects of something-e.g., his own life, or someone else’s life-would distinguish clearly among those aspects. Sometimes, however, the answers are substantially affected by the respondent’s general impression and are not as distinct from one another as an external observer might think they should be. This is particularly likely to happen when the respondent is not well acquainted with the details of what is being investigated or when the questions and/or answer categories are themselves unclear. Of course, “halo,” which produces an undesired source of correlation among the measures, must be distinguished from the sources of true correlation among the measures. (p. 179).
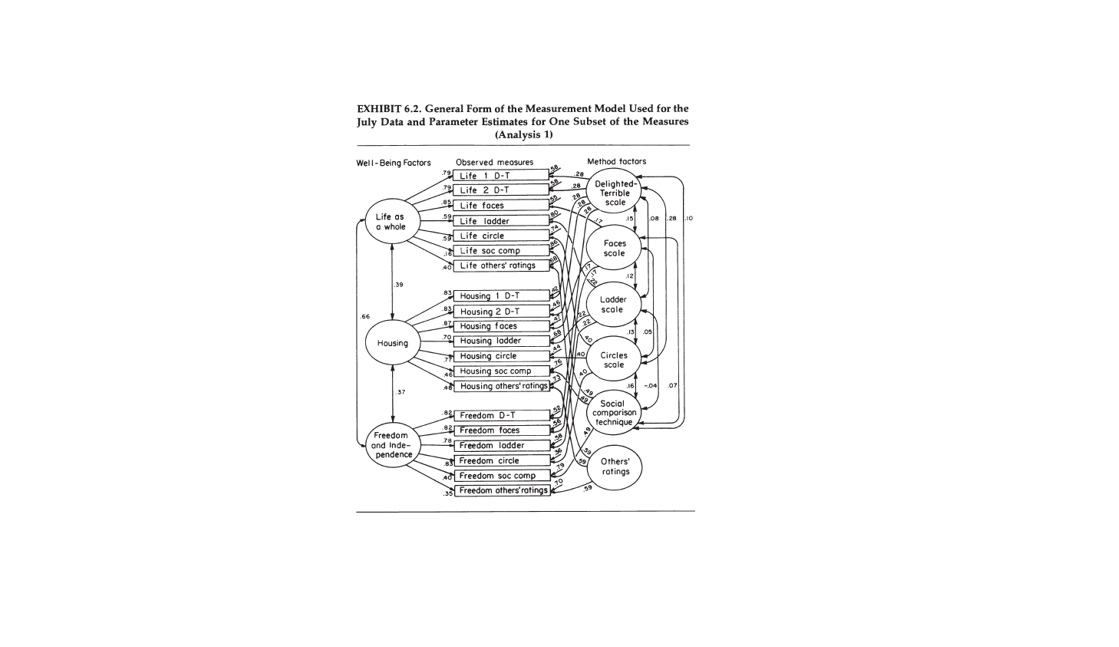
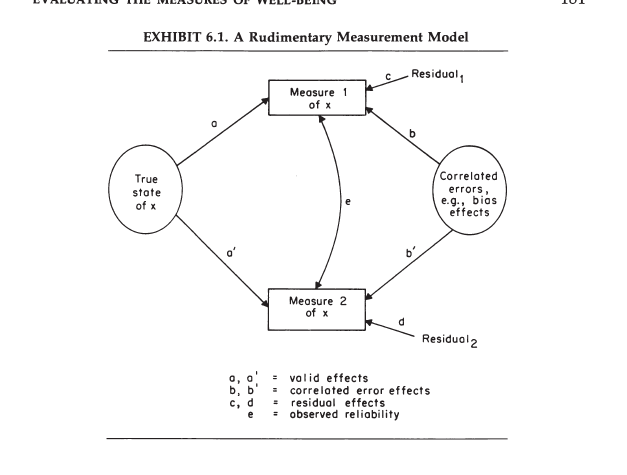
Exhibit 6.1 uses the graphical language of structural equation modelling to illustrate the measurement model. Here the oval on the left represents the true variation in well-being perceptions in a sample. The boxes in the middle represent two measures of well-being (e.g., two ratings on a delighted-terrible scale). The oval on the right reflects sources that produce systematic measurement error (e.g., halo bias). In this model, the observed correlation is the retest reliability of a single global measure and it is a function of the strength of the causal effects of the true variance (path a and a’) and the systematic measurement (b and b’) on the two measures.
The problem with this model is that there is only one observed correlation and two possible causal effects (assuming equal strength for a and a’, and b and b’). Thus, it is unclear how much of the reliable variance reflects actual variation in true well-being.
To make empirical claims about the validity of global well-being ratings, it is necessary to embed them in a network of variables that shows theoretically predicted relationships. Within a larger set of variables, the path from the construct to the observed measures may be identifiable (Cronbach & Meehl, 1955; Schimmack, 2019).
Estimates Derived from the July Data
Scattered throughout the July questionnaire was a set of thirty-seven items that, when brought together for the purposes of the present analysis, forms a nearly complete six-by-six multimethod-multitrait matrix; i.e., a matrix in which six different “traits” (aspects of well-being) are assessed by each of six different methods. (p. 183)
The concerns were chosen to be well spread in the perceptual structure (as shown in Exhibit 2.2) and to include both domains and criteria. The following six aspects of well-being are represented: Life-as-a-whole, House or apartment, Spare-time activities, National government, Standard of living, and Independence or Freedom. The six measurement methods involve: self-ratings on the Delighted-Terrible, Faces, Circles, and Ladder Scales, the Social Comparison technique, and Ratings by others. (The exact wording of each of the concern-level items appears in Exhibit 2.1; see items 3D, 44, 85, 87, and 105. For descriptions of the six methods used to assess life-as-a-whole, see Exhibit 3.1, measures G1, G5, G6, G7, G13, and G54, these same methods were also used to assess the concern-level aspects. (p. 184).
Exhibit 6.2 shows the partial structural equation model for the global ratings and two domains. The key finding is that the correlations between residuals of the same rating scale tend to be rather small, while the validity coefficients are high. This seems to suggest that most of the reliable variance in global and domain measures is valid variance rather than systematic measurement error.
As much as I like Andrews and Withey’s work and recognize their contribution to well-being science in its infancy, I am disappointed by their discussion of the model.
Because the model shown in Exhibit 6.2 incorporates our theoretical expectations about how various phenomena influenced the validity and error components of the observed measures, because serious alternative theories have not come to our attention, and because the model in fact fits the data rather well (as will be described shortly), it seems reasonable to use it to estimate the validity and error components of the measures (p. 187)
On the basis of these results we infer that single item measures using the D-T, Faces, or Circles Scales to assess any of a wide range of different aspects of perceived well-being contain approximately 65 percent valid variance (p. 189).
Their own discussion of halo bias suggests that their model fails to account for systematic measurement error that is shared by different rating formats (Schimmack, , Böckenholt, & Reisenzein, 2002). It is well known that response sets have a negligible influence on ratings, but halo bias has a stronger influence.
It is important that the model actually includes measures that are based on the aggregated ratings of three informants that knew the respondent well (others’ rating). This makes the study a multi-method study that not only varies the response format, but also the rater. Other research has shown that halo bias is rather unique to a single rater (Anusic et al., 2009). Thus, halo bias cannot inflate correlations between respondents’ self-ratings and ratings by others. The problem is that a model with two-methods is unstable. It is only identified here because there are multiple self-ratings. In this case, halo bias can be hidden in higher loadings of the self-ratings on the true well-being factor than the other’ ratings. This is clearly the case. The loading for the informant ratings , as ratings by others’ are typically called, for global well-being is only .40, despite the fact that it is an average of three ratings and averaging increases validity. Based on the factor loadings, we can infer that the self-informant correlations are .4 * .8 = .32, which is in line with meta-analytic results from other studies (Schneider & Schimmack, 2009). A&W’s model gives the false impression that self-ratings are much more valid than informant ratings, but models that can test this assumption by using each informant as a separate method show that this is not the case (Zou et al., 2013). Thus, A&W’s work may have given a false impression about the validity of global well-being ratings. While they claimed that two-thirds of the variance is valid variance, other studies suggest it is only one-third, after taking halo bias into account.
A&W’s model shows high residual correlations among the three others’ ratings of life, housing, and freedom. They interpret this finding as evidence that halo bias has a strong influence on informant ratings.
The relatively high method effects in measures obtained from Others’ ratings is notable, but not terribly surprising. Since other people have less direct access to the respondents’ feelings than do the respondents themselves, one would expect substantially more “halo” in the Others’ ratings than in the respondents’ own ratings. This would be a reasonable explanation for the large amount of correlated error in these scores. (p. 189).
However, if these concerns are related to global well-being, but informant ratings have low loadings on the true factors, the model has to find another way to relate informant ratings of related to domains. The model is unable to test whether these correlations reflect bias or valid relationships. In contrast, other studies find no evidence that halo bias is considerably less present in self-ratings than in informant ratings (Anusic et al., 2009; Kim, Schimmack, & Oishi, 2012).
It is unfortunate that A&W and many researchers after them aggregated informant ratings, instead of treating informants as separate methods. As a result, 30 years of research failed to provide information about the amount of valid variance in self-ratings and informant ratings, leaving A&W’s estimate of 65% and 15% unquestioned. It was only in 2013, when Zou et al. (2013) showed that family members are as valid as the self in ratings of global well-being and that the proportions of variance are more equal around 30-40% valid variance for both. Self-ratings are only more valid when informant ratings are obtained from recent friends with less than two years of acquaintance (Schneider et al., 2010).
The low validity of informant ratings in A&W’s model led them to suggest that people are rather private about their true feelings about live.
What is of interest is that even people who the respondents felt knew them pretty well were in fact relatively poor judges of the respondents’ perceptions. This suggests that perceptions of well-being may be rather private matters. While people can-and did-give reasonably reliable answers (and, we estimate reasonably valid answers) regarding their affective evaluations of a wide range of life concerns, it would seem that they do not communicate their perceptions even to their friends and neighbors with much precision (p. 191).
While this may be true for neighbors, it is not true for family members. Moreover, other studies have found stronger correlations when informant ratings were aggregated across more informants and when informants are family members rather than neighbors (Schneider & Schimmack, 2009), and these stronger correlations have been used as evidence for the validity of self-ratings (Diener, Lucas, Schimmack, & Helliwell, 2009). Based on the same logic, A&W results would undermine the use of informant ratings as evidence of convergent validity of self-ratings.
There are several reasons why the modes validity of global well-being ratings has been ignored. First, it seems plausible that self-ratings are more valid because individuals have access to all of the relevant information. They know how things are going in their lives and they know what is important to them. In contrast, it is virtually certain that informants do not have access to all of the relevant information. However, these differences in accessibility of relevant information do not automatically ensure that self-ratings are more valid. This would only be the case if respondents are motivated to engage in an exhaustive search that retrieves all of the relevant information. This assumption has been questioned (Schwarz & Strack, 1999). Thus, we cannot simply assume that self-ratings are valid. The aim of validation research is to test this assumption. A&W’s model was unable to test it because they had several self-ratings and only one aggregated other-rating as indicators.
The second reason may be self-serving interest. The assumption that a single-item happiness rating can be used to measures something as complex and important as an individuals’ well-being makes these ratings very appealing for social scientists. If the assessment of well-being would require a complex set of questions about 20 life-domains with 10 criteria, it would be impossible to survey the well-being of nations and populations. The reason well-being is one of the most widely studied social constructs across several disciplines is that a single happiness item was easy to add to a survey.
DISTRIBUTIONS PRODUCED BY THE MORE VALID METHODS
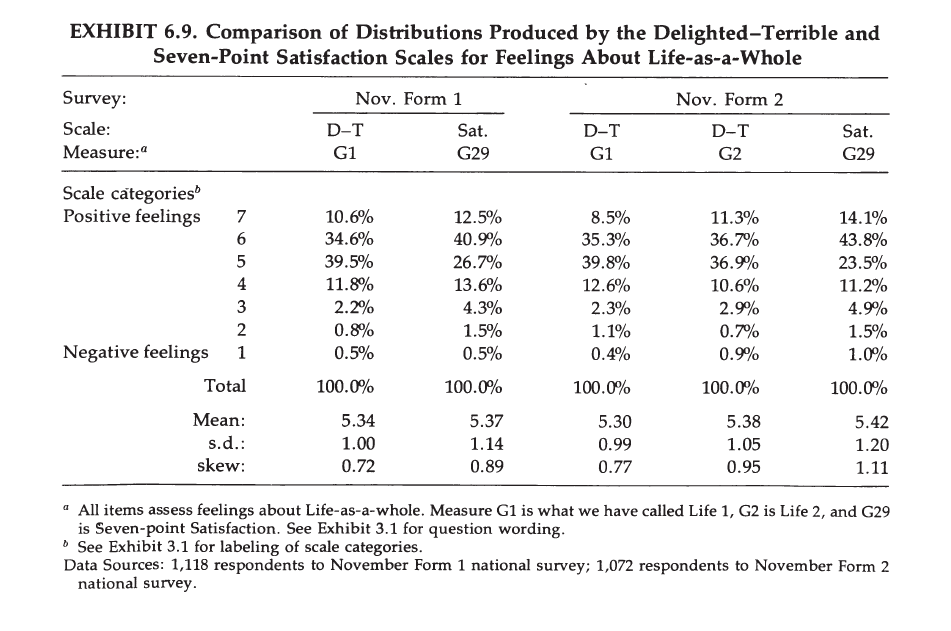
A&W also examine and care about the distribution of responses. They developed the delighted-terrible scale because they observed that even on a 7-point satisfaction scale responses clustered at the top.
Our data clearly show that the Delighted-Terrible Scale produces greater differentiation at the positive end of the scale than the seven-point Satisfaction Scale (p. 207).
However, the differences that they mention are rather small and both formats produce similar means.
RELATIONSHIPS BETWEEN MEASURES OF PERCEIVED WELL-BEING AND OTHER TYPES OF VARIABLES
a reasonably consistent and not very surprising pattern emerged. Nearly always, relationships were in the “expected” direction, and most were rather weak (p. 214).
However, these weak correlations were systematic and stronger when researchers expected stronger correlations.
“Where concerns had been judged relevant to the other items, the average correlation was .31; where staff members had been uncertain as to the concerns’ relevance, the average correlation was .25; and where concerns had been judged irrelevant the average correlation was .15″ (p. 214).
The problem is that A&W interpreted these results as evidence that perceived well-being is relatively independent of life conditions or actual behaviors.
Our general conclusion is that one will not usually find strong and direct relationships between measures of perceived well-being and reports of most life conditions or behaviors (p. 214).
This conclusion is partially based on the false inference that most of the variance in well-being ratings is valid variance. Another problem is that well-being is a broad construct and that a single behavior (e.g., sexual frequency; cf. Muise, Schimmack, & Impett, 2016) will only influence a small slice of the pizza of life. Other designs like twin studies or studies of spouses who are exposed to similar life circumstances are better suited to make claims about the importance of life conditions for well-being (Schimmack & Lucas, 2010). If differences in life circumstances do not explain variation in perceptions of well-being, what else could produce these differences? A&W do not address this question.
It would be naive to think that a person’s feelings about various aspects of life could be perfectly predicted by knowing only the characteristics of the person’s present environment. Developing adequate explanations for why people feel as they do about various life concerns would be a challenging undertaking in its own right. While we believe this could prove scientifically fruitful, such an investigation is not part of the work we are presently reporting.
This question became the focus of personality theories of well-being (Costa & McCrae, 1980; Diener, 1984) and it is now well-established that stable dispositions to experience more pleasure (positive affect) and less displeasure (negative affect) contribute to perceptions of well-being (Schimmack, Oishi, & Diener, 2002;
CHAPTER 7: Exploring the Dynamics of Evaluation
Explorations 1 and 2 examine how response categories of different formats correspond to each other.
EXPLORATION 3: HYPOTHETICAL FAMILY INCOMES AND AFFECTIVE EVALUATIONS ON THE D-T SCALE
This exploration examined response options on the delighted-terrible scale in relation to hypothetical income levels.
The dollar amounts would need to be translated into current dollar amounts to be meaningful. Nevertheless, it is surprising how small the gaps are even for the highest, delighted, category.
EXPLORATION 6: AN IMPLEMENTATION OF THE DOMAINS-BY-CRITERIA MODEL
Design of the Analysis and Measures Employed
A&W wrote items for each of the 48 cells in the 6 domains x 8 criteria matrix. They found that all items had small to moderate correlations with the global measure.
“The fortyeight correlations involved range from .13 to .41 with a mean of .20.”
Domain-criterion items were also more strongly correlated with judgments of the same domain than with other domains.
If the model is right, each concern-level variable should tend to have higher relationships with the cell variables that are assumed to influence it than with other cell variables. This expectation also proves to be supported by the data. For the domains, the average of the forty-eight correlations with “relevant” cell variables is .48 (as noted previously) while the average of the 240 correlations with “irrelevant” cell variables is .20 (p. 236).
For the criteria, a similar but somewhat smaller difference exists: The forty-eight correlations with “relevant” cell variables average .37, while the 320 correlations with “irrelevant” cell variables average .27. Furthermore, these differences are not reversed for any of the fourteen concern measures considered individually (p. 236).
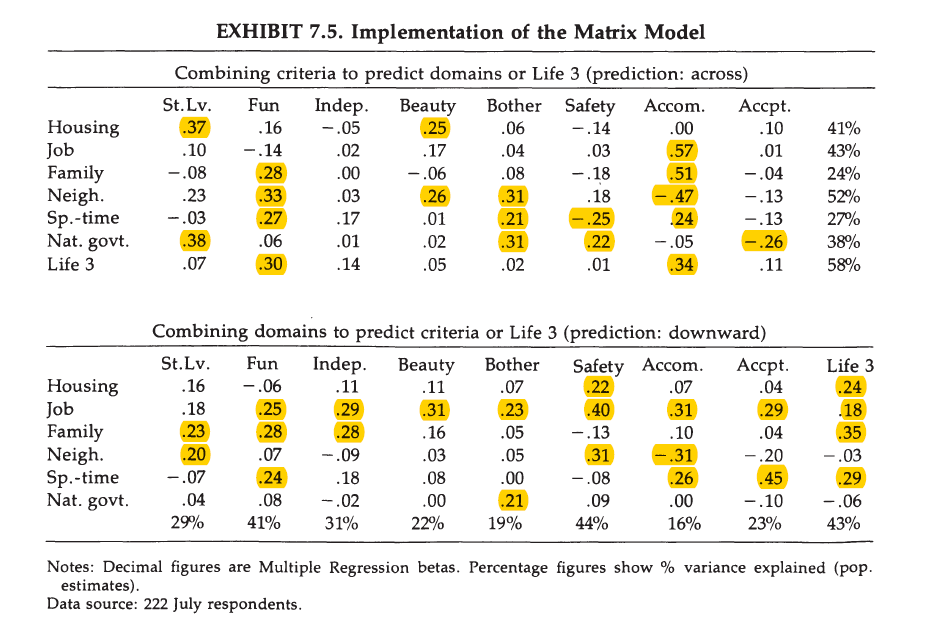
Exhibit 7.5 shows regression weights from a multiple regression with (a) criteria as predictors (top) and with domains as predictors (bottom). At the top, the key criteria are fun and accomplishments. Standard of living matters only for evaluations of housing and national government, beauty for housing and neighbourhood. At the bottom, housing family and free time contribute to fun, and job and free time contribute to accomplishments. Free time probably does so by means of hobbies or volunteering. For life in general, fun and accomplishment (top) and housing, family, free time, and job are the key predictors.
EXPLORATION 7: COMPARISONS BETWEEN ONE’S OWN WELL-BEING AND THAT OF OTHERS
When Life-as-a-whole is being assessed, the consistent finding is that most people think they are better off than either other people in general (“all the adults in the U.S.”) or their nearest same-sexed neighbor. (p. 240).
This finding is probably just the typical better-than-average effect that is obtained for desirable traits. One explanation for it is that people do not overestimate themselves, but rather underestimate others, and do not sufficiently adjust the comparison. After all, if A&W are right we do not know much about the well-being of others, especially when we do not know them well.
Interestingly, the results switch for national government, which receives low ratings. So, here the adjustment problem works in the opposite direction and respondents underestimate how dissatisfied others are with the government.
EXPLORATION 8: JUDGMENTS OF THE “IMPORTANCE” OF CONCERNS
“One of the hypotheses with which we started was that the relative importance a person assigned to various life concerns should be taken into account when combining concern-level evaluations to predict feelings about Life-as-awhole. The hypothesis is based on the expectation that when forming evaluations of overall well-being people would give greater “weight” to those concerns they felt were important, and less weight to those they regarded as less significant. As described in chapter 4, a careful examination of this hypothesis showed it to be untrue.”
In one analysis we looked to see whether the mean importance assigned to a given concern bore any relationship to its association with feelings about Life-as- a-whole. If our original hypothesis had been correct, one would have expected a high relationship here; feelings about Life-as-a-whole would have had more to do with feelings about the important concerns than with feelings about the others. Using the data from our colleagues’ survey the answer was essentially “no.” Over ten concerns, the rank correlation between mean importance and the size of the simple bivariate relationship (measured by the eta statistic) was – .39: There was a modest tendency for the concerns that had higher relationships to Life-as-a-whole to be judged less important: When we performed the same analysis using a more complex multivariate relationship derived by holding constant the effects of all other nine concerns (measured by the beta statistic from Multiple classification Analysis), the rank correlation was + .15. A similar analysis in the July data produced a rank correlation of + .30 between the importance of concerns and the size of their (bivariate) relationships to the Life 3 measure. It seems clear that the mean importance assigned to a concern has little to do with the relationship between that concern and feelings about Life-as-a-whole (p. 243).
This is a puzzling finding and seems to undermine A&W’s bottom-up model of well-being perceptions. One problem is that Pearson correlations are sensitive to the amount of variance and the distribution of variables. For example, health could be important, but because it is important it is at high levels for most respondents. As a result, the Pearson correlation with perceived well-being would be low, which it actually is. A different kind of correlation coefficient or analysis would be needed for a better test of the hypothesis that more important domains are stronger predictors of well-being perceptions.
Further insight about the meaning of importance judgments emerged when we checked to see whether the importance assigned to a concern has anything to do with the position of the concern in the psychological structure. We compared the importance data for the ten concerns as assessed in our colleagues’ survey with the position of those concerns in the structural maps derived from our own national sample of May respondents (see Exhibit 2.4). There was a distinct tendency for concerns that were closer to Self and Family to receive higher importance ratings than those that were more remote (rho = .52). When the analysis was repeated using the importance of the concerns as judged by our July respondents, a parallel result emerged (rho = .43). Still a third version of the analysis took the importance of the concerns as judged by the July respondents and checked the location of the concerns in the plot derived from these same respondents (Exhibit 2.2). Here the relationship was somewhat higher (rho = .59). We conclude that importance ratings are substantially linked to the position of the concern in the perceptual structure, and that concerns that are seen as being closely associated with oneself and one’s family tend to be ranked as more important than others. (p. 244)
This is an interesting observation, but A&W do not elaborate further on it. Thus, it remains a mystery why respondents’ rate some domains as more important, but variation in these domains is not a stronger predictor of well-being evaluations.
END OF PART I
Conclusion
A&W provided a groundbreaking and exemplary examination of the construct validity of global well-being ratings. They presented a coherent theory that assumes global well-being judgments are integrative, mostly additive, evaluations of several life domains based on several criteria. Surprisingly, they found that weighing domains by importance did not improve predictions. They also tested a multi-trait-multi-method model to separate valid variance from method variance in well-being ratings. They concluded that two-thirds of the variance in self-ratings is valid, but only 15% of the variance in informant ratings are valid. Based on these results, they concluded that even a single global well-being rating is a valid measure of individuals’ true feelings about their lives, which we would rather call attitudes towards their lives, these days.
It is unfortunate that few well-being researchers have tried to build on A&W’s seminal work. To my knowledge, I am the only one who has fitted MTMM models to self-ratings and informant ratings of well-being to separate valid variance from systematic measurement error. Ironically, A&W’s impressive results may be the reason why further validation research has been neglected. However, A&W made some mistakes in their MTMM model and never explained the inconsistency between the bottom-up theory and their finding that importance weights do not improve prediction. Unfortunately, it is possible that their model was wrong and that a much larger portion of the variance in single-item well-being measures is method variance and that bottom-up effects on these measures are relatively weak and do not reflect the true importance of life circumstances for individuals’ well-being. Health is a particularly relevant domain. According to A&W’s results, variation in health satisfaction has relatively little unique effect on global well-being ratings. Does this really mean that health is unimportant? Does this mean that the massive increase in health spending over the past years is a waste of money? Or does it mean, global life evaluations are not as valid as we think they are and they fail to capture the relative importance of life domains for individuals’ well-being?
Psychology has a measurement problem. Big claims about personality, self-esteem, or well-being are based on sum-scores of self-ratings; or sometimes a single rating. This would be a minor problem if thorough validation research had demonstrated that sum-scores of self-ratings are valid measures of the constructs they are intended to represent, but such validation research is often missing. As a result, the validity of widely used measures in psychology and claims based on these measures is unknown.
The well-being literature is an interesting example of the measurement crisis because two opposing views about the validity of well-being measures co-exist. On the one hand, experimental social psychologists argue that life-satisfaction ratings are invalid and useless (Schwarz & Strack, 1999); a view that has been popularized by Noble Laureate Daniel Kahneman in his book “Thinking: Fast and Slow” (cf. Schimmack, 2018). On the other hand, well-being scientists often assume that life-satisfaction ratings are near perfect indicators of individuals’ well-being.
An editor of JPSP, which presumably means he or she is an expert, has no problem to mention both positions in the same paragraph without noting the contradiction.
“There is a huge literature on well-being. Since Schwarz and Strack (1999), to take that arbitrary year as a starting point, there have been more than 11,000 empirical articles with “wellbeing” (or well-being or well being) in the title, according to PsychInfo. The vast majority of them, I submit, take the subjective evaluation of one’s own life as a perfectly valid and perhaps the best way to assess one’s own evaluation of one’s life. “
So, since Schwarz and Strack concluded that life-satisfaction judgments are practically useless, 11,000 articles have used life-satisfaction judgments as perfectly valid measures of life-satisfaction and nobody thinks this is a problem. No wonder, natural scientists don’t consider psychology a science.
The Validity of Well-Being Measures
Any attempt at validating well-being measures requires a definition of well-being that leads to testable predictions about correlations of well-being measures with other measures. Testing these predictions is called construct validation (Cronbach & Meehl, 1955; Schimmack, 2019).
The theory underlying the use of life-satisfaction judgments as measures of well-being assumes that well-being is subjective and that (healthy, adult) individuals are able to compare their actual lives to their ideal lives and to report the outcome of these comparison processes (Andrews & Whithey, 1973; Diener, Lucas, Schimmack, & Helliwell, 2009).
One prediction that follows from this model is that global life-satisfaction judgments should be correlated with judgments of satisfaction in important life domains, but not in unimportant life domains. The reason is that satisfaction with life as a whole should be related to satisfaction with (important) parts. It would make little sense for somebody to say that they are extremely satisfied with their life as a whole, but not satisfied with their family life, work, health, or anything else that matters to them. The whole point of asking a global question is the assumption that people will consider all important aspects of their lives and integrate this information into a global judgment (Andrews & Whithey, 1973). The main criticism of Schwarz and Strack (1999) was that this assumption does not describe the actual judgment process and that actual life-satisfaction judgments are based on transient and irrelevant information (e.g., current mood, Schwarz & Clore, 1983).
Top-Down vs. Bottom-Up Theories of Global and Domain Satisfaction
To muddy the waters, Diener (1984) proposed on the one hand that life-satisfaction judgments are, at least somewhat, valid indicators of life-satisfaction, while also proposing that correlations between satisfaction with life as a whole and satisfaction with domains might reflect a top-down effect.
A top-down effect implies that global life-satisfaction influences domain satisfaction. That is, health satisfaction is not a cause of life-satisfaction because good health is an important part of a good life. Instead, life-satisfaction is a content-free feeling of satisfaction that creates a halo in evaluations of specific life aspects independent of the specific evaluations of a life domain.
Diener overlooked that top-down processes invalidate life-satisfaction judgments as valid measures of wellbeing because a top-down model implies that global life-satisfaction judgments reflect only a general disposition to be satisfied without information about the actual satisfaction in important life domains. In the context of a measurement model, we can see that the top-down model implies that life-satisfaction judgments only capture the shared variance among specific life-satisfaction judgments, but fail to represent the part of satisfaction that reflects unique variance in satisfaction with specific life domains. In other words, top-down models imply that well-being does not encompass evaluations of the parts that make up an individuals entire life.
The problem that measurement models in psychology often consider unique or residual variances error variances that are often omitted from figures does not help. In the figure, the residual variances are shown and represent variation in life-aspects that are not shared across domains.
Some influential articles that examined top-down and bottom-up processes have argued in favor of top-down processes without noticing that this invalidates the use of life-satisfaction judgments as indicators of well-being or at least requires a radically different conception of well-being (well-being is being satisfied independent of how things are actually going in your life) (Heller, Watson, & Ilies, 2004).
An Integrative Top-Down vs. Bottom-Up Model
Brief et al. (1993) proposed an integrative model of top-down and bottom-up processes in life-satisfaction judgments. The main improvement of this model was to distinguish between a global disposition to be more satisfied and a global judgment of important aspects of life. As life-satisfaction judgments are meant to represent the latter, life-satisfaction judgments are the ultimate outcome of interest, not a measure of the global disposition. Brief et al. (1993) used neuroticism as an indicator for the global disposition to be less satisfied, but there are probably other factors that can contribute to a general disposition to be satisfied. The integrative model assumes that any influence of the general disposition is mediated by satisfaction with important life domains (e.g., health).
It is important to realize that the mediation model separates two variances in domain satisfaction judgments, namely the variance that is explained by dispositional satisfaction and the variance that is not explained by dispositional satisfaction (residual variance). Both variances contribute to life-satisfaction. Thus, objective aspects of health that contribute to health satisfaction can also influence life-satisfaction. This makes the model an integrative model that allows for top-down and bottom-up effects.
One limitation of Brief et al.’s (1993) model was the use of neuroticism as sole indicator of dispositional satisfaction. While it is plausible that neuroticism is linked to more negative perceptions of all kinds of life-aspects, it may not be the only trait that matters.
Another limitation was the use of a health satisfaction as a single life domain. If people also care about other life domains, other domain satisfactions should also contribute to life-satisfaction and they could be additional mediators of the influence of neuroticism on life-satisfaction. For example, neurotic individuals might also worry more about money and financial satisfaction could influence life-satisfaction, making financial satisfaction another mediator of the influence of neuroticism on life-satisfaction.
One advantage of structural equation modeling is the ability to study constructs that do not have a direct indicator. This makes it possible to examine top-down effects without “direct” indicators of dispositional satisfaction. The reason is that dispositional satisfaction should influence satisfaction with various life domains. Thus, dispositional satisfaction is reflected in the shared variance among different domain satisfaction judgments and domain satisfaction judgments serve as indicators that can be used to measure dispositional satisfaction (see Figure 2).
Domain Satisfactions in the SOEP
It is fortunate that the creators of the Socio-Economic Panel in the 1980s included domain satisfaction measures and that these measures have been included in every wave from 1984 to 2017. This makes it possible to test the integrative top-down bottom-up model with the SOEP data.
The five domains that have been included in all surveys are health, household income, recreation, housing, and job satisfaction. However, job satisfaction is only available for those participants who are employed. To maximize the number of domains, I used all five domains and limited the analysis to working participants. The model can be used to build a model with four domains for all participants.
One limitation of the SOEP is the use of single-item indicators. This makes sense for expensive panel studies, but creates some psychometric problems. Fortunately, it is possible to estimate the reliability of single-item indicators in panel data by using Heise’s (1969) model which estimates reliability based on the pattern of retest correlations for three waves of data.
REL = r12 * r23 / r13
More data would be better and are available, but the goal was to combine the well-being model with a model of personality ratings that are available for only three waves (2005, 2009, & 2013). Thus, the same three waves for used to create an integrative top-down bottom-up model that also examined how domain satisfaction is related to global life-satisfaction across time.
The data set consisted of 3 repeated measures of 5 domain satisfaction judgments and a single life-satisfaction judgments for a total of 18 variables. The data were analyzed with MPLUS (see OSF for syntax and detailed results https://osf.io/vpcfd/ ).
Results
Overall model fit was acceptable, CFI = .988, RMSEA = .023, SRMR = .029.
The first results are the reliability and stability estimates of the five domain satisfactions and global life satisfaction (Table 1). For comparison purposes, the last column shows the estimates based on a panel analyses with annual retests (Schimmack, Krause, Wagner, & Schupp, 2010). The results show fairly consistent stability across domains with the exception of job satisfaction. Job satisfaction is less stable than other domains. The four-year stability is high, but not as high as for personality traits (Schimmack, 2019). A comparison with the panel data shows higher stability, which indicates that some of the error variance in 4-year retest studies is reliable variance that fluctuates over the four-year retest period. However, the key finding is that there is high stability in domain satisfaction judgments and life-satisfaction judgments. which makes it theoretically interesting to examine the relationship between the stable variances in domain satisfaction and life-satisfaction.
Reliability
Stability
1Y-Stability
Panel
Job Satisfaction
0.62
0.62
0.89
Health Satisfaction
0.67
0.79
0.94
0.93
Financial Satisfaction
0.74
0.81
0.95
0.91
Housing Satisfaction
0.66
0.81
0.95
0.89
Leisure Satisfaction
0.67
0.80
0.95
0.92
Life Satisfaction
0.66
0.78
0.94
0.89
Table 2 examines the influence of top-down processes on domain satisfaction. Results show the factor loadings of domain satisfaction on a common factor that reflects dispositional satisfaction; that is, a general disposition to report higher levels of satisfaction. The results show that somewhere between 30% and 50% of the reliable variance in life-satisfaction judgments is explained by a general disposition factor. While this leaves ample room for domain-specific factors to influence domain satisfaction judgments, the results show a strong top-down influence.
T1
T2
T3
Job Satisfaction
0.69
0.68
0.68
Health Satisfaction
0.68
0.66
0.65
Financial Satisfaction
0.60
0.61
0.63
Housing Satisfaction
0.72
0.74
0.76
Leisure Satisfaction
0.61
0.61
0.61
Table 3 shows the unique contribution of the disposition and the five domains to life-satisfaction concurrently and longitudinally.
DS1-LS1
DS1-LS2
DS1-LS3
DS2-LS2
DS2-LS3
DS3-LS3
Disposition
0.56
0.59
0.57
0.61
0.59
0.60
Job
0.14
0.10
0.05
0.17
0.08
0.12
Health
0.23
0.22
0.21
0.28
0.27
0.33
Finances
0.34
0.20
0.14
0.24
0.18
0.22
Housing
0.04
0.03
0.03
0.04
0.04
0.06
Leisure
0.06
0.10
0.06
0.13
0.07
0.09
The first notable finding is that the disposition factor accounts for the lion share of the explained variance in life-satisfaction judgments. The second important finding is that the relationship is very stable over time. The disposition measured at time 1 is an equally good predictor of life-satisfaction at time 1 (r = .56), time 2 (r = .59), and at time 3 (r = .57). This suggests that about one-third of the reliable variance in life-satisfaction judgments reflects a stable disposition to report higher or lower levels of satisfaction.
Regarding domain satisfaction, health is the strongest predictor with correlations between .21 and .33. Finances is the second strongest predictor with correlations between .14 and .34. For health satisfaction there is high stability over time. That is, time 1 health satisfaction predicts time 1 life-satisfaction nearly as well (r = .23) as time 3 life-satisfaction (r = .21). In contrast, financial satisfactions shows a bit more change over time with concurrent correlations at time 1 of r = .34 and a drop to r = .14 for life-satisfaction at time 3. This suggests that changes in financial satisfaction produces changes in life-satisfaction.
Job satisfaction has a weak influence on life-satisfaction with correlations ranging from r = .14 to .05. Like financial satisfaction, there is some evidence that changes in job satisfaction predict changes in life-satisfaction.
Housing and leisure have hardly any influence on life-satisfaction judgments with most relationships being less than .10. There is also no evidence that changes in these domain produce changes in life-satisfaction judgments.
These results show that most of the reliable variance in global life-satisfaction judgments remains unexplained and that a stable disposition accounts for most of the explained variance in life-satisfaction judgments.
Implications for the Validity of Life-Satisfaction Judgments
There are two ways to interpret the results. One interpretation is that is common in the well-being literature and hundreds of studies with the SOEP data is that life-satisfaction judgments are valid measures of well-being. Accordingly, well-being in Germany is determined mostly by a stable disposition to be satisfied. Accordingly, changing actual life-circumstances will have negligible effects on well-being. For example, Nakazato et al. (2011) used the SOEP data to examine the influence of moving on well-being. They found that decreasing housing satisfaction triggered a decision to move and that moving produces lasting increases in housing satisfaction. However, moving had no effect on life-satisfaction. This is not surprising given the present results that housing satisfaction has a negligible influence on life-satisfaction judgments. Thus, we would conclude that people are irrational by investing money in a better house, if we assume that life-satisfaction judgments are a perfectly valid measure of well-being.
The alternative interpretation is that life-satisfaction judgments are not as good as well-being researchers think they are. Rather than reflecting a weighted summary of all important aspects of life, they are based on accessible information that does not include all relevant information. The difference to Schwarz and Strack’s (1999) criticism is that bias is not due to temporarily accessible information (e.g., mood) that makes life-satisfaction judgments unreliable. As demonstrated here and elsewhere, a large portion of the variance in life-satisfaction judgments is stable. The problem is that the stable factors may be biases in life-satisfaction ratings rather than real determinants of well-being.
It is unfortunate that psychologist and other social sciences have neglected proper validation research of a measure that has been used to make major empirical claims about the determinants of well-being, and that this research has been used to make policy recommendation (Diener, Lucas, Schimmack, & Helliwell, 2009). The present results suggest that any policy recommendations based on life-satisfaction ratings alone are premature. It is time to take measurement more seriously and to improve the validity of measuring well-being.
Here is a link to the manuscript, data, and MPLUS scripts for reproducibility. https://osf.io/mu7e6/
ABSTRACT
Greenwald et al. (1998) proposed that the IAT measures
individual differences in implicit social cognition. This claim requires evidence of construct validity.
I review the evidence and show that there is insufficient evidence for this
claim. Most important, I show that few
studies were able to test discriminant validity of the IAT as a measure of
implicit constructs. I examine discriminant validity in several multi-method
studies and find no or weak evidence for discriminant validity. I also show
that validity of the IAT as a measure of attitudes varies across constructs. Validity
of the self-esteem IAT is low, but estimates vary across studies. About 20% of the variance in the race IAT
reflects racial preferences. The highest validity is obtained for measuring
political orientation with the IAT (64% valid variance). Most of this valid variance stems from a
distinction between individuals with opposing attitudes, while reaction times
contribute less than 10% of variance in the prediction of explicit attitude
measures. In all domains, explicit
measures are more valid than the IAT, but the IAT can be used as a measure of
sensitive attitudes to reduce measurement error by using a multi-method
measurement model.
Despite its popularity, relatively little is known about the construct validity of the IAT.
As Cronbach (1989) pointed out, construct validation is better examined by independent experts than by authors of a test because “colleagues are especially able to refine the interpretation, as they compensate for blind spots and capitalize on their own distinctive experience” (p. 163).
It is of utmost importance to determine how much of the variance in IAT scores is valid variance and how much of the variance is due to measurement error, especially when IAT scores are used to provide individualized feedback.
There is also no consensus in the literature whether the IAT measures something different from explicit measures.
In conclusion, while there is general consensus to make a distinction between explicit measures and implicit measures, it is not clear what the IAT measures
To complicate matters further, the validity of the IAT may vary across attitude objects. After all the IAT is a method, just like Likert scales are a method, and it is impossible to say that a method is valid (Cronbach, 1971).
At present, relatively little is known about the contribution of these three parameters to observed correlations in hundreds of mono-method studies.
A Critical Review
of Greenwald et al.’s (1998) Original Article
In conclusion, the seminal IAT article introduced the IAT as a measure of implicit constructs that cannot be measured with explicit measures, but it did not really test this dual-attitude model.
Construct Validity in 2007
In conclusion, the 2007 review of construct validity revealed major psychometric challenges for the construct validity of the IAT, which explains why some researchers have concluded that the IAT cannot be used to measure individual differences (Payne et al., 2017). It also revealed that most studies were mono-method studies that could not examine convergent and discriminant validity
Cunningham, Preacher and Banaji (2001)
Another noteworthy finding is that a single factor accounted for correlations among all measures on the same occasion and across measurement occasions. This finding shows that there were no true changes in racial attitudes over the course of this two-month study. This finding is important because Cunningham et al.’s (2001) study is often cited as evidence that implicit attitudes are highly unstable and malleable (e.g., Payne et al., 2017). This interpretation is based on the failure to distinguish random measurement error and true change in the construct that is being measured (Anusic & Schimmack, 2016). While Cunningham et al.’s (2001) results suggest that the IAT is a highly unreliable measure, the results also suggest that the racial attitudes that are measured with the race IAT are highly stable over periods of weeks or months.
Bar-Anan & Vianello, 2018
this large study of construct validity also provides little evidence for the original claim that the IAT measures a new construct that cannot be measured with explicit measures, and confirms the estimate from Cunningham et al. (2001) that about 20% of the variance in IAT scores reflects variance in racial attitudes.
Greenwald et al. (2009)
“When entered after the self-report measures, the two implicit measures incrementally explained 2.1% of vote intention variance, p=.001, and when political conservativism was also included in the model, “the pair of implicit measures incrementally predicted only 0.6% of voting intention variance, p = .05.” (Greenwald et al., 2009, p. 247).
I tried to reproduce these results with the published correlation matrix and failed to do so. I contacted Anthony Greenwald, who provided the raw data, but I was unable to recreate the sample size of N = 1,057. Instead I obtained a similar sample size of N = 1,035. Performing the analysis on this sample also produced non-significant results (IAT: b = -.003, se = .044, t = .070, p = .944; AMP: b = -.014, se = .042, t = 0.344, p = .731). Thus, there is no evidence for incremental predictive validity in this study.
Axt (2018)
With N = 540,723 respondents, sampling error is very small, σ = .002, and parameter estimates can be interpreted as true scores in the population of Project Implicit visitors. A comparison of the factor loadings shows that explicit ratings are more valid than IAT scores. The factor loading of the race IAT on the attitude factor once more suggests that about 20% of the variance in IAT scores reflects racial attitudes
Falk, Heine, Zhang, and Hsu (2015)
Most important, the self-esteem IAT and the other implicit measures have low and non-significant loadings on the self-esteem factor.
Bar-Anan & Vianello (2018)
Thus, low validity contributes considerably to low observed correlations between IAT scores and explicit self-esteem measures.
Bar-Anan & Vianello (2018) – Political Orientation
More important, the factor loading of the IAT on the implicit factor is much higher than for self-esteem or racial attitudes, suggesting over 50% of the variance in political orientation IAT scores is valid variance, π = .79, σ = .016. The loading of the self-report on the explicit ratings was also higher, π = .90, σ = .010
Variation of Implicit – Explicit Correlations Across Domains
This suggests that the IAT is good in classifying individuals into opposing groups, but it has low validity of individual differences in the strength of attitudes.
What Do IATs Measure?
The present results suggest that measurement error alone is often sufficient to explain these low correlations. Thus, there is little empirical support for the claim that the IAT measures implicit attitudes that are not accessible to introspection and that cannot be measured with self-report measures.
For 21 years the lack of discriminant validity has been overlooked because psychologists often fail to take measurement error into account and do not clearly distinguish between measures and constructs.
In the future, researchers need to be more careful when they make claims about constructs based on a single measure like the IAT because measurement error can produce misleading results.
Researchers should avoid terms like implicit attitude or implicit preferences that make claims about constructs simply because attitudes were measured with an implicit measure
Recently, Greenwald and Banaji (2017) also expressed concerns about their earlier assumption that IAT scores reflect unconscious processes. “Even though the present authors find themselves occasionally lapsing to use implicit and explicit as if they had conceptual meaning, they strongly endorse the empirical understanding of the implicit– explicit distinction” (p. 862).
How
Well Does the IAT Measure What it Measures?
Studies with the IAT can be divided into applied studies (A-studies) and basic studies (B-studies). B-studies employ the IAT to study basic psychological processes. In contrast, A-studies use the IAT as a measure of individual differences. Whereas B-studies contribute to the understanding of the IAT, A-studies require that IAT scores have construct validity. Thus, B-studies should provide quantitative information about the psychometric properties for researchers who are conducting A-studies. Unfortunately, 21 years of B-studies have failed to do so. For example, after an exhaustive review of the IAT literature, de Houwer et al. (2009) conclude that “IAT effects are reliable enough to be used as a measure of individual differences” (p. 363). This conclusion is not helpful for the use of the IAT in A-studies because (a) no quantitative information about reliability is given, and (b) reliability is necessary but not sufficient for validity. Height can be measured reliably, but it is not a valid measure of happiness.
This article provides the first quantitative information about validity of three IATs. The evidence suggests that the self-esteem IAT has no clear evidence of construct validity (Falk et al., 2015). The race-IAT has about 20% valid variance and even less valid variance in studies that focus on attitudes of members from a single group. The political orientation IAT has over 40% valid variance, but most of this variance is explained by group-differences and overlaps with explicit measures of political orientation. Although validity of the IAT needs to be examined on a case by case basis, the results suggest that the IAT has limited utility as a measurement method in A-studies. It is either invalid or the construct can be measured more easily with direct ratings.
Implications for the Use of IAT scores in Personality Assessment
I suggest to replace the reliability coefficient with the validity coefficient. For example, if we assume that 20% of the variance in scores on the race IAT is valid variance, the 95%CI for IAT scores from Project Implicit (Axt, 2018), using the D-scoring method, with a mean of .30 and a standard deviation of.46 ranges from -.51 to 1.11. Thus, participants who score at the mean level could have an extreme pro-White bias (Cohen’s d = 1.11/.46 = 2.41), but also an extreme pro-Black Bias (Cohen’s d = -.51/.46 = -1.10). Thus, it seems problematic to provide individuals with feedback that their IAT score may reveal something about their attitudes that is more valid than their beliefs.
Conclusion
Social psychologists have always distrusted self-report, especially for the measurement of sensitive topics like prejudice. Many attempts were made to measure attitudes and other constructs with indirect methods. The IAT was a major breakthrough because it has relatively high reliability compared to other methods. Thus, creating the IAT was a major achievement that should not be underestimated because the IAT lacks construct validity as a measure of implicit constructs. Even creating an indirect measure of attitudes is a formidable feat. However, in the early 1990s, social psychologists were enthralled by work in cognitive psychology that demonstrated unconscious or uncontrollable processes (Greenwald & Banaji, 1995). Implicit measures were based on this work and it seemed reasonable to assume that they might provide a window into the unconscious (Banaji & Greenwald, 2013). However, the processes that are involved in the measurement of attitudes with implicit measures are not the personality characteristics that are being measured. There is nothing implicit about being a Republican or Democrat, gay or straight, or having low self-esteem. Conflating implicit processes in the measurement of attitudes with implicit personality constructs has created a lot of confusion. It is time to end this confusion. The IAT is an implicit measure of attitudes with varying validity. It is not a window into people’s unconscious feelings, cognitions, or attitudes.
Most published psychological measures are unvalid. (subtitle) *unvalid = the validity of the measure is un-known.
2022/01/01 UPDATE This blog post attracted a lot of attention when it was first posted and served as a first draft for a manuscript that is now published in Meta-Psychology. You can find the published article here. (Meta-Psychology).
2025/01/11 UPDATE The article has attracted much less attention and most psychologists continue to ignore the problem that their measures have an unknown amount of measurement error and probably only modest construct validity. Thanks to AI, it is now possible to provide quick summaries of articles. Here is a summary that I find accurate and snappy that takes only a minute or two to read.
ChatGPT summary of my article.
Core Argument Schimmack argues that psychology faces a validation crisis, in addition to its replication crisis, due to widespread neglect of rigorous construct validation practices. Construct validity, introduced by Cronbach and Meehl (1955), is critical for ensuring that measures accurately reflect the theoretical constructs they are meant to assess. Without valid measures, even replicable findings can lead to false or misleading conclusions.
Key Points
Importance of Construct Validity – Construct validity ensures that variations in test scores reflect variations in the intended construct (e.g., anxiety or intelligence). – Validity is essential for meaningful theory testing and avoiding false inferences (e.g., correlating irrelevant variables like hair length with intelligence).
Current Problems in Psychological Measurement – Many widely used psychological measures lack proper validation. – Researchers often conflate reliability with validity, though reliability is necessary but insufficient for construct validity. – Claims about construct validity are often unsupported or vague, leading to a proliferation of questionable constructs and measures.
Cronbach and Meehl’s Recommendations (1955) – Nomological Networks: Valid measures should fit into a theoretical framework (relationships between constructs and observables). – Multi-Method Approach: Validation requires using multiple independent methods (e.g., self-reports, informant ratings, behavioral observations). – Quantification of Validity: Construct validity should be measured quantitatively, such as estimating the proportion of variance attributable to the construct. – Convergent and Discriminant Validity – Convergent Validity: Measures of the same construct using different methods should correlate. – Discriminant Validity: Measures of different constructs should not correlate highly unless theoretically expected.
Structural Equation Modeling (SEM) – SEM extends factor analysis, allowing researchers to test and refine models of constructs. – Construct validation should be an iterative process, where empirical data inform both measures and theoretical models.
Criticism of Current Practices – Over-reliance on single-method correlations and inadequate use of multi-method designs. – Lack of transparency and skepticism in evaluating claims of construct validity. – Resistance to updating or replacing outdated measures due to institutional inertia and bias.
Proposed Solutions – Embrace systematic, multi-method validation studies with clear standards for quantifying validity. – Critically evaluate existing measures and replace low-validity measures with improved ones. – Adopt structural equation modeling and other advanced techniques to refine the nomological networks of constructs.
Network Models vs. Nomological Networks – Network models focus on direct relationships among observables, neglecting the role of latent constructs and proper measurement.
Call to Action – Schimmack emphasizes the need for psychology to address its validation crisis with the same vigor as its replication crisis. – He advocates for making the 2020s the “decade of validation,” pushing for rigorous standards and better measures.
—————————- ———————————- —————————-
Here is the original blog post.
Introduction
8 years ago, psychologists started to realize that they have a replication crisis. Many published results do not replicate in honest replication attempts that allow the data to decide whether a hypothesis is true or false.
The replication crisis is sometimes attributed to the lack of replication studies before 2011. However, this is not the case. Most published results were replicated successfully. However, these successes were entirely predictable from the fact that only successful replications would be published (Sterling, 1959). These sham replication studies provided illusory evidence for theories that have been discredited over the past eight years by credible replication studies.
New initiatives that are called open science are likely to improve the replicability of psychological science in the future, although progress towards this goal is painfully slow.
This blog post addresses another problem in psychological science. I call it the validation crisis. Replicability is only one necessary feature of a healthy science. Another necessary feature of a healthy science is the use of valid measures. This feature of a healthy science is as obvious as the need for replicability. To test theories that relate theoretical constructs to each other (e.g., construct A influences construct B for individuals drawn from population P under conditions C), it is necessary to have valid measures of constructs. However, it is unclear which criteria a measure has to fulfill to have construct validity. Thus, even successful and replicable tests of a theory may be false because the measures that were used lacked construct validity.
Construct Validity
The classic article on “Construct Validity” was written by two giants in psychology; Cronbach and Meehl (1955). Every graduate student of psychology and surely every psychologists who published a psychological measure should be familiar with this article.
The article was the result of an APA task force that tried to establish criteria, now called psychometric properties, for tests to be published. The result of this project was the creation of the construct “Construct validity”
The chief innovation in the Committee’s report was the term construct validity. (p. 281).
Cronbach and Meehl provide their own definition of this construct.
Construct validation is involved whenever a test is to be interpreted as a measure of some attribute or quality which is not “operationally defined” (p. 282).
In modern language, construct validity is the relationship between variation in observed test scores and a latent variable that reflects corresponding variation in a theoretical construct (Schimmack, 2010).
Thinking about construct validity in this way makes it immediately obvious why it is much easier to demonstrate predictive validity, which is the relationship between observed tests scores and observed criterion scores than to establish construct validity, which is the relationship between observed test scores and a latent, unobserved variable. To demonstrate predictive validity, one can simply obtain scores on a measure and a criterion and compute the correlation between the two variables. The correlation coefficient shows the amount of predictive validity of the measure. However, because constructs are not observable, it is impossible to use simple correlations to examine construct validity.
The problem of construct validation can be illustrated with the development of IQ scores. IQ scores can have predictive validity (e.g., performance in graduate school) without making any claims about the construct that is being measured (IQ tests measure whatever they measure and what they measure predicts important outcomes). However, IQ tests are often treated as measures of intelligence. For IQ tests to be valid measures of intelligence, it is necessary to define the construct of intelligence and to demonstrate that observed IQ scores are related to unobserved variation in intelligence. Thus, construct validation requires clear definitions of constructs that are independent of the measure that is being validated. Without clear definition of constructs, the meaning of a measure reverts essentially to “whatever the measure is measuring,” as in the old saying “Intelligence is whatever IQ tests are measuring. This saying shows the problem of research with measures that have no clear construct and no construct validity.
In conclusion, the challenge in construct validation research is to relate a specific measure to a well-defined construct and to establish that variation in test scores are related to variation in the construct.
What are Constructs
Construct validation starts with an assumption. Individuals are assumed to have an attribute, today we may say personality trait. Personality traits are typically not directly observable (e.g., kindness rather than height), but systematic observation suggests that the attribute exists (some people are kinder than others across time and situations). The first step is to develop a measure of this attribute (e.g., a self-report measure “How kind are you?”). If the test is valid, variation in the observed scores on the measure should be related to the personality trait.
A construct is some postulated attribute of people, assumed to be reflected in test performance (p. 283).
The term “reflected” is consistent with a latent variable model, where unobserved traits are reflected in observable indicators. In fact, Cronbach and Meehl argue that factor analysis (not principle component analysis!) provides very important information for construct validity.
We depart from Anastasi at two points. She writes, “The validity of a psychological test should not be confused with an analysis of the factors which determine the behavior under consideration.” We, however, regard such analysis as a most important type of validation. (p. 286).
Factor analysis is useful because factors are unobserved variables and factor loadings show how strongly an observed measure is related to variation in a an unobserved variable; the factor. If multiple measures of a construct are available, they should be positively correlated with each other and factor analysis will extract a common factor. For example, if multiple independent raters agree in their ratings of individuals’ kindness, the common factor in these ratings may correspond to the personality trait kindness, and the factor loadings provide evidence about the degree of construct validity of each measure (Schimmack, 2010).
In conclusion, factor analysis provides useful information about construct validity of measures because factors represent the construct and factor loadings show how strongly an observed measure is related to the construct.
It is clear that factors here function as constructs (p. 287).
Convergent Validity
The term convergent validity was introduced a few years later in another seminal article on validation research by Campbell and Fiske (1959). However, the basic idea of convergent validity was specified by Cronbach and Meehl (1955) in the section “Correlation matrices and factor analysis”
If two tests are presumed to measure the same construct, a correlation between them is predicted (p. 287).
If a trait such as dominance is hypothesized, and the items inquire about behaviors subsumed under this label, then the hypothesis appears to require that these items be generally intercorrelated (p. 288)
Cronbach and Meehl realize the problem of using just two observed measures to examine convergent validity. For example, self-informant correlations are often used in personality psychology to demonstrate validity of self-ratings. However, a correlation of r = .4 between self-ratings and informant ratings is open to very different interpretations. The correlation could reflect very high validity of self-ratings and modest validity of informant ratings or the opposite could be true.
If the obtained correlation departs from the expectation, however, there is no way to know whether the fault lies in test A, test B, or the formulation of the construct. A matrix of intercorrelations often points out profitable ways of dividing the construct into more meaningful parts, factor analysis being a useful computational method in such studies. (p. 300)
A multi-method approach avoids this problem and factor loadings on a common factor can be interpreted as validity coefficients. More valid measures should have higher loadings than less valid measures. Factor analysis requires a minimum of three observed variables, but more is better. Thus, construct validation requires a multi-method assessment.
Discriminant Validity
The term discriminant validity was also introduced later by Campbell and Fiske (1959). However, Cronbach and Meehl already point out that high or low correlations can support construct validity. Crucial for construct validity is that the correlations are consistent with theoretical expectations.
For example, low correlations between intelligence and happiness do not undermine the validity of an intelligence measure because there is no theoretical expectation that intelligence is related to happiness. In contrast, low correlations between intelligence and job performance would be a problem if the jobs require problem solving skills and intelligence is an ability to solve problems faster or better.
Only if the underlying theory of the trait being measured calls for high item intercorrelations do the correlations support construct validity (p. 288).
Quantifying Construct Validity
It is rare to see quantitative claims about construct validity. Most articles that claim construct validity of a measure simply state that the measure has demonstrated construct validity as if a test is either valid or invalid. However, the previous discussion already made it clear that construct validity is a quantitative construct because construct validity is the relation between variation in a measure and variation in the construct and this relation can vary . If we use standardized coefficients like factor loadings to assess the construct validity of a measure, construct validity can range from -1 to 1.
Contrary to the current practices, Cronbach and Meehl assumed that most users of measures would be interested in a “construct validity coefficient.”
There is an understandable tendency to seek a “construct validity coefficient. A numerical statement of the degree of construct validity would be a statement of the proportion of the test score variance that is attributable to the construct variable. This numerical estimate can sometimes be arrived at by a factor analysis” (p. 289).
Cronbach and Meehl are well-aware that it is difficult to quantify validity precisely, even if multiple measures of a construct are available because the factor may not be perfectly corresponding with the construct.
Rarely will it be possible to estimate definite “construct saturations,” because no factor corresponding closely to the construct will be available (p. 289).
And nobody today seems to remember Cronbach and Meehl’s (1955) warning that rejection of the null-hypothesis, the test has zero validity, is not the end goal of validation research.
It should be particularly noted that rejecting the null hypothesis does not finish the job of construct validation (p. 290)
The problem is not to conclude that the test “is valid” for measuring- the construct variable. The task is to state as definitely as possible the degree of validity the test is presumed to have (p. 290).
One reason why psychologists may not follow this sensible advice is that estimates of construct validity for many tests are likely to be low (Schimmack, 2010).
The Nomological Net – A Structural Equation Model
Some readers may be familiar with the term “nomological net” that was popularized by Cronbach and Meehl. In modern language a nomological net is essentially a structural equation model.
The laws in a nomological network may relate (a) observable properties or quantities to each other; or (b) theoretical constructs to observables; or (c) different theoretical constructs to one another. These “laws” may be statistical or deterministic.
It is probably no accident that at the same time as Cronbach and Mehl started to think about constructs as separate from observed measures, structural equation model was developed as a combination of factor analysis that made it possible to relate observed variables to variation in unobserved constructs and path analysis that made it possible to relate variation in constructs to each other. Although laws in a nomological network can take on more complex forms than linear relationships, a structural equation model is a nomological network (but a nomological network is not necessarily a structural equation model).
As proper construct validation requires a multi-method approach and demonstration of convergent and discriminant validity, SEM is ideally suited to examine whether the observed correlations among measures in a mulit-trait-multi-method matrix are consistent with theoretical expectations. In this regard, SEM is superior to factor analysis. For example, it is possible to model shared method variance, which is impossible with factor analysis.
Cronbach and Meehl also realize that constructs can change as more information becomes available. It may also occur that the data fail to provide evidence for a construct. In this sense, construct validiation is an ongoing process of improved understanding of unobserved constructs and how they are related to observable measures.
Ideally this iterative process would start with a simple structural equation model that is fitted to some data. If the model does not fit, the model can be modified and tested with new data. Over time, the model would become more complex and more stable because core measures of constructs would establish the construct validity, while peripheral relationships may be modified if new data suggest that theoretical assumptions need to be changed.
When observations will not fit into the network as it stands, the scientist has a certain freedom in selecting where to modify the network (p. 290).
Too often psychologists use SEM only to confirm an assumed nomological network and it is often considered inappropriate to change a nomological network to fit observed data. However, SEM is as much testing of an existing construct as exploration of a new construct.
The example from the natural sciences was the initial definition of gold as having a golden color. However, later it was discovered that the pure metal gold is actually silver or white and that the typical yellow color comes from copper impurities. In the same way, scientific constructs of intelligence can change depending on the data that are observed. For example, the original theory may assume that intelligence is a unidimensional construct (g), but empirical data could show that intelligence is multi-faceted with specific intelligences for specific domains.
However, given the lack of construct validation research in psychology, psychology has seen little progress in the understanding of such basic constructs such as extraversion, self-esteem, or wellbeing. Often these constructs are still assessed with measures that were originally proposed as measures of these constructs, as if divine intervention led to the creation of the best measure of these constructs and future research only confirmed their superiority.
Instead many claims about construct validity are based on conjectures than empirical support by means of nomological networks. This was true in 1955. Unfortunately, it is still true over 50 years later.
For most tests intended to measure constructs, adequate criteria do not exist. This being the case, many such tests have been left unvalidated, or a finespun network of rationalizations has been offered as if it were validation. Rationalization is not construct validation. One who claims that his test reflects a construct cannot maintain his claim in the face of recurrent negative results because these results show that his construct is too loosely defined to yield verifiable inferences (p. 291).
Given the difficulty of defining constructs and finding measures for it, even measures that show promise in the beginning might fail to demonstrate construct validity later and new measures should show higher construct validity than the early measures. However, psychology shows no development in measures of the same construct. The most widely used measure of self-esteem is still Rosenberg’s scale from 1965 and the most widely used measure of wellbieng is still Diener et al.’s scale from 1984. It is not clear how psychology can make progress, if it doesn’t make progress in the development of nomological networks that provide information about constructs and about the construct validity of measures.
Cronbach and Meehl are clear that nomological networks are needed to claim construct validity.
To validate a claim that a test measures a construct, a nomological net surrounding the concept must exist (p. 291).
However, there are few attempts to examine construct validity with structural equation models (Connelly & Ones, 2010; Zou, Schimmack, & Gere, 2013). [please share more if you know some]
One possible reason is that construct validation research may reveal that authors initial constructs need to be modified or their measures have modest validity. For example, McCrae, Zonderman, Costa, Bond, and Paunonen (1996) dismissed structural equation modeling as a useful method to examine the construct validity of Big Five measures because it failed to support their conception of the Big Five as orthogonal dimensions with simple structure.
Recommendations for Users of Psychological Measures
The consumer can accept a test as a measure of a construct only when there is a strong positive fit between predictions and subsequent data. When the evidence from a proper investigation of a published test is essentially negative, it should be reported as a stop sign to discourage use of the test pending a reconciliation of test and construct, or final abandonment of the test (p. 296).
It is very unlikely that all hunches by psychologists lead to the discovery of useful constructs and development of valid tests of these constructs. Given the lack of knowledge about the mind, it is rather more likely that many constructs turn out to be non-existent and that measures have low construct validity.
However, the history of psychological measurement has only seen development of more and more constructs and more and more measures to measure this increasing universe of constructs. Since the 1990s, constructs have doubled because every construct has been split into an explicit and an implicit version of the construct. Presumably, there is even implicit political orientation or gender identity.
The proliferation of constructs and measures is not a sign of a healthy science. Rather it shows the inability of empirical studies to demonstrate that a measure is not valid or that a construct may not exist. This is mostly due to self-serving biases and motivated reasoning of test developers. The gains from a measure that is widely used are immense. Thus, weak evidence is used to claim that a measure is valid and consumers are complicit because they can use these measures to make new discoveries. Even when evidence shows that a measure may not work as intended (e.g., Bosson et al., 2000), it is often ignored (Greenwald & Farnham, 2001).
Conclusion
Just like psychologist have started to appreciate replication failures in the past years, they need to embrace validation failures. Some of the measures that are currently used in psychology are likely to have insufficient construct validity. If this was the decade of replication, the 2020s may become the decade of validation, and maybe the 2030s may produce the first replicable studies with valid measures. Maybe this is overly optimistic, given the lack of improvement in validation research since Cronbach and Meehl (1955) outlined a program of construct validation research. Ample citations show that they were successful in introducing the term, but they failed in establishing rigorous criteria of construct validity. The time to change this is now.
Cookie Consent
We use cookies to improve your experience on our site. By using our site, you consent to cookies.