
Any mature science classifies the objects that it studies. Chemists classify atoms. Biologists classify organisms. It is therefore not surprising that personalty psychologists have spent a lot of their effort on classifying personality traits; that is psychological attributes that distinguish individuals from each other.
[It is more surprising that social psychologists have spent very little effort on classifying situations; a task that is now being carried out by personality psychologists (Rauthmann et al., 2014)]
After decades of analyzing correlations among self-ratings of personality items, personality psychologists came to a consensus that five broad factors can be reliably identified. Since the 1980s, the so-called Big Five have dominated theories and measurement of personality. However, most theories of personality also recognize that the Big Five are not a comprehensive description of personality. That is, unlike colors that can be produced by mixing three basic colors, specific personality traits are not just a mixture of the Big Five. Rather, the Big Five represent an abstract level in a hierarchy of personality traits. It is possible to compare the Big Five to the distinction of five classes of vertebrate animals: mammals, birds, reptiles, fish, and amphibians. Although there are important distinctions between these groups, there are also important distinctions among the animals within each class; cats are not dogs.
Although the Big Five are a major achievement in personality psychology, it also has some drawbacks. As early as 1995, personality psychologists warned that focusing on the Big Five would be a mistake because the Big Five are too broad to be good predictors of important life outcomes (Block, 1995). However, this criticism has been ignored and many researchers seem to assume that they measure personality when they administer a Big Five questionnaire. To warrant the reliance on the Big Five would require that the Big Five capture most of the meaningful variation in personality. In this blog post, I use open data to test this implicit assumption that is prevalent in contemporary personality science.
Confirmatory Factor Analysis
In 1996, McCrae et al. (1995) published an article that may have contributed to the stagnation in research on the structure of personality. In this article, the authors argued that structural equation modeling (SEM), specifically confirmatory factor analysis (CFA), is not suitable for personality researchers. However, CFA is the only method that can be used to test structural theories and to falsify structural theories that are wrong. Even worse, McCrae et al. (1995) demonstrated that a simple-structure model did not fit their data. However, rather than concluding that personality structure is not simple, they concluded that CFA is the wrong method to study personality traits. The problem with this line of reasoning is self-evident and was harshly criticized by Borsboom (2006). If we dismiss methods because they do not show a theoretically predicted pattern, we loose the ability to test theories empirically.
To understand McCrae et al.’s (1995) reaction to CFA, it is necessary to understand the development of CFA and how it was used in psychology. In theory, CFA is a very flexible method that can fit any dataset. The main empirical challenge is to find plausible models and to find data that can distinguish between competing plausible models. However, when CFA was introduced, certain restrictions were imposed on models that could be tested. The most restrictive model imposed that a measurement model should have only primary loadings and no correlated residuals. Imposing these restrictions led to the foregone conclusions that the data are inconsistent with the model. At this point, researchers were supposed to give up, create a new questionnaire with better items, retest it with CFA and find out that there were still secondary loadings that produced poor fit to the data. The idea that actual data could have a perfect structure must have been invented by an anal-retentive statistician who never analyzed real data. Thus, CFA was doomed to be useless because it could only show that data do not fit a model.
It took some time and courage to decide that the straight-jacket of simple structure has to go. Rather than giving up after a simple-structure model was rejected, the finding should encourage further exploration of the data to find models that actually fit the data. Maybe biologists initially classified whales as fish, but so what. Over time, further testing suggested that they are mammals. However, if we never get started in the first place, we will never be able to develop a structure of personality traits. So, here I present a reflective measurement model of personality traits. I don’t call it CFA, because I am not confirming anything. I also don’t call it EFA because this term is used for a different statistical technique that imposes other restrictions (e.g., no correlated residuals, local independence). We might call it exploratory modeling (EM) or because it relies on structural equation modeling, we could call it ESEM. However, ESEM is already been used for a blind computer-based version of CFA. Thus, the term EM seems appropriate.
The Big Five and the 30 Facets
Costa and McCrae developed a personality questionnaire that assesses personality at two levels. One level are the Big Five. The other level are 30 more specific personality traits.

The 30 facets are often presented as if they are members of a domain, just like dogs, cats, pigs, horses, elephants, and tigers are mammals and have nothing to do with reptiles or bird. However, this is an oversimplification. Actual empirical data show that personality structure is more complex and that specific facets can be related to more than one Big Five factor. In fact, McCrae et al. (1996) published the correlations of the 30 facets with the Big Five factors and the table shows many, and a few substantial, secondary loadings; that is, correlations with a factor other than the main domain. For example, Impulsive is not just positively related to Neuroticism. It is also positively related to extraversion, and negatively related to conscientiousness.

Thus, McCrae et al.’s (1996) results show that Big Five data do not have a simple structure. It is therefore not clear what model a CONFIRMATORY factor analysis tries to confirm, when the CFA model imposes a simple structure. McCrae et al. (1995) agree: “If, however, small loadings are in fact meaningful, CFA with a simple structure model may not fit well” (p. 553). In other words, if an exploratory factor analysis shows a secondary loading of Anger/Hostility on Agreeableness (r = -.40), indicating that agreeable people are less likely to get angry, it makes no sense to confirm a model that sets this parameter to zero. McCrae et al. also point out that simple structure makes no theoretical sense for personality traits. “There is no theoretical reason why traits should not have meaningful loadings on three, four, or five factors:” (p. 553). The logical consequence of this insight is to fit models that allow for meaningful secondary loadings; not to dismiss modeling personality data with structural equations.
However, McCrae et al. (1996) were wrong about the correct way of modeling secondary loadings. “It is possible to make allowances for secondary loadings in CFA by fixing the loadings at a priori values other than zero” (p. 553). Of course, it is possible to fix loadings to a non-zero value, but even for primary loadings, the actual magnitude of a loading is estimated by the data. It is not clear why this approach could not be used for secondary loadings. It is only impossible to let all secondary loadings to be freely estimated, but there is no need to fix the loading of anger/hostilty on the agreeableness factor to a fixed value to model the structure of personality.
Personality psychologists in the 1990s also seemed to not fully understand how sensitive SEM is to deviations between model parameters and actual data. McCrae et al. (1996) critically discuss a model by Church and Burke (1994) because it “regarded loadings as small as ± .20 as salient secondaries” (p. 553). However, fixing a loading of .20 to a value of 0, introduces a large discrepancy that will hurt overall fit. One either has to free parameters or lower the criterion for acceptable fit. However, fixing loadings greater than .10 to zero and hoping to met standard criteria of acceptable fit is impossible. Effect sizes of r = .2 (d = .4) are not zero, and treating them as such will hurt model fit.
In short, exploratory studies of the relationship between the Big Five and facets show a complex pattern with many non-trivial (r > .1) secondary loadings. Any attempt to model these data with SEM needs to be able to account for this finding. As many of these secondary loadings are theoretically expected and replicable, allowing for these secondary loadings makes theoretical sense and cannot be dismissed as overfitting of data. Rather, imposing a simple structure that makes no theoretical sense should be considered underfiting of the data, which of course results in bad fit.
Correlated Residuals are not Correlated Errors
Another confusion in the use of structural equation modeling is the interpretation of residual variances. In the present context, residuals represent the variance in a facet scale that is not explained by the Big Five factors. Residuals are interesting for two reasons. First, they provide information about unique aspects of personality that are not explained by the Big Five. To use the analogy of animals, although cats and dogs are both animals, they also have distinct features. Residuals are analogous to these distinct features, and we would think that personality psychologists would be very interested in exploring this question. However, statistics textbooks tend to present residual variances as error variance in the context of measurement models where items are artifacts that were created to measure a specific construct. As the only purpose of the item is to measure a construct, any variance that does not reflect the intended construct is error variance. If we were only interested in measuring the Big Five, we would think about residual facet-variance as error variance. It does not matter how depressed people are. We only care about their neuroticism. However, the notion of a hierarchy implies that we do care about the valid variance in facets that is not explained by the Big Five. Thus, residual variance is not error variance.
The mistake of treating residual variance as error variance becomes especially problematic when residual variance in one facet is related to residual variance in another facet. For example, how angry people get (the residual variance in anger) could be related to how compliant people are (the residual variance in compliance). After all, anger could be elicit by a request to comply to some silly norms (e.g., no secondary loadings) that make no sense. There is no theoretical reason, why facets could only be linked by means of the Big Five. In fact, a group of researchers has attempted to explain all relations among personality facet without the Big Five because they don’t belief in broader factors (cf. Schimmack, 2019b). However, this approach has difficulties explaining the constistent primary loadings of facets on their predicted Big Five factor.
The confusion of residuals with errors accounts at least partially for McCrae et al.’s (1996) failure to fit a measurement model to the correlations among the 30 facets.
“It would be possible to specify a correlated error term between these two scales, but the interpretation of such a term is unclear. Correlated error usually refers to a nonsubstantive
source of variance. If Activity and Achievement Striving were, say, observer ratings, whereas all other variables were self-reports, it would make sense to control for this difference in method by introducing a correlated error term. But there are no obvious sources of correlated error among the NEO-PI-R facet scales in the present study” (p. 555).
The Big Five Are Independent Factors, but Evaluative Bias produces correlations among Big Five Scales
Another decision researchers have to make is whether they specify models with independent factors or whether they allow factors to be correlated. That is, are extraversion and openness independent factors or are extraversion and openness correlated. A model with correlated Big Five factors has 10 additional free parameters to fit the data. Thus, the model will is likely to fit better than a model with independent factors. However, the Big Five were discovered using a method that imposed independence (EFA and Varimax rotation). Thus, allowing for correlations among the factors seems atheoretical, unless an explanation for these correlations can be found. On this front, personality researchers have made some progress by using multi-method data (self-ratings and ratings by informants). As it turns out, correlations among the Big Five are only found in ratings by a single rater, but not in correlations across raters (e.g., self-rated Extraversion and informant-rated Agreeableness). Additional research has further validated that most of this variance reflects response styles in ratings by a single rater. These biases can be modeled with two method factors. One factor is an acquiescence factor that leads to higher or lower ratings independent of item content. The other factor is an evaluative bias (halo) factor. It represent responses to the desirability of items. I have demonstrated in several datasets that it is possible to model the Big Five as independent factors and that correlations among Big Five Scales are mostly due to the contamination of scale scores with evaluative bias. As a result, neuroticism scales tend to be negatively related to the other scales because neuroticism is undesirable and the other traits are desirable (see Schimmack, 2019a). Although the presence of evaluative biases in personality ratings has been known for decades, previous attempts at modeling Big Five data with SEM often failed to specify method factors; not surprisingly they failed to find good fit (McCrae et al., 1996. In contrast, models with method factors can have good fit (Schimmack, 2019a).
Other Problems in McCrae et al.’s Attempt
There are other problems with McCrae et al.’s (1996) conclusion that CFA cannot be used to test personality structure. First, the sample size was small for a rigorous study of personality structure with 30 observed variables (N = 229). Second, the evaluation of model fit was still evolving and some of the fit indices that they reported would be considered acceptable fit today. Most importantly, an exploratory Maximum Likelihood model produced reasonable fit, chi2/df = 1.57, RMS = .04, TLI = .92, CFI = .92. Their best fitting CFA model, however, did not fit the data. This merely shows a lack of effort and not the inability of fitting a CFA model to the 30 facets. In fact, McCrae et al. (1996) note “a long list of problems with the technique [SEM], ranging from technical difficulties in estimation
of some models to the cost in time and effort involved.” However, no science has made progress by choosing cheap and quick methods over costly and time-consuming methods simply because researchers lack the patients to learn a more complex method. I have been working on developing measurement models of personality for over a decade (Anusic et al., 2009). I am happy to demonstrate that it is possible to fit an SEM model to the Big Five data, to separate content variance from method variance, and to examine how big the Big Five factors really are.
The Data
One new development in psychology is that data are becoming more accessible and are openly shared. Low Goldberg has collected an amazing dataset of personality data with a sample from Oregon (the Eugene-Springfield community sample). The data are now publicly available at the Harvard Dataverse. With N = 857 participants the dataset is nearly four times larger than the dataset used by McCrae et al. (1996), and the ratio 857 observations and 30 variables (28:1) is considered good for structural equation modeling.
It is often advised to use different samples for exploration and then for cross-validation. However, I used the full sample for a mix of confirmation and exploration. The reason is that there is little doubt about the robustness of the data structure (the covariance/correlation matrix). The bigger issue is that a well-fitting model does not mean that it is the right model. Alternative models could also account for the same pattern of correlations. Cross-validation does not help with this bigger problem. The only way to address this is a systematic program of research that develops and tests different models. I see the present model as the beginning of such a line of research. Other researchers can use the same data to fit alternative models and they can use new data to test model assumptions. The goal is merely to boot a new era of research on the structure of personality with structural equation modeling, which could have started 20 years ago, if McCrae et al. (1996) had been more positive about the benefits of testing models and being able to falsify them (a.k.a. doing science).
Results
I started with a simple model that had five independent personality factors (the Big Five) and an evaluative bias factor. I did not include an acquiescence factor because facets are measured with scales that include reverse scored items. As a result, acquiescence bias is negligible (Schimmack, 2019a).
In the initial model facet loadings on the evaluative bias factor were fixed at 1 or -1 depending on the direction or desirability of a facet. This model had poor fit. I then modified the model by adding secondary loadings and by freeing loadings on the evaluative bias factor to allow for variation in desirability of facets. For example, although agreeableness is desirable, the loading for the modesty facet actually turned out to be negative. I finally added some correlated residuals to the model. The model was modified until it reached criteria of acceptable fit, CFI = .951, RMSEA = .044, SRMR = .034. The syntax and the complete results can be found on OSF (https://osf.io/23k8v/).
Table 3 shows the standardized loadings of the 30 facets on the Big Five and the two method factors.
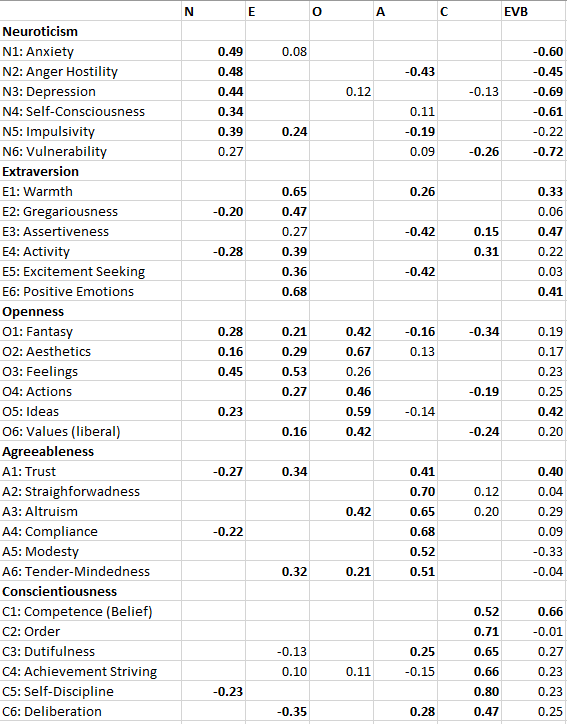
There are several notable findings that challenge prevalent conceptions of personality.
The Big Five are not so big
First, the loadings of facets on the Big Five factors are notably weaker than in McCrae et al.’s Table 4 reproduced above (Table 2). There are two reasons for this discrepancy. First, often evaluative bias is shared between facets that belong to the same factor. For example, anxiety and depression have strong negative loadings on the evaluative bias factor. This shared bias will push up the correlation between the two facets and inflate factor loadings in a model without an evaluative bias factor. Another reason can be correlated residuals. If this extra shared variance is not modeled it pushes up loadings of these facets on the shared factor. The new and more accurate estimates in Table 3 suggest that the Big Five are not as big as the name implies. The loading of anxiety on neuroticism (r = .49) implies that only 25% of the variance in anxiety is captured by the neuroticism factor. Loadings greater than .71 are needed for a Big Five factor to explain more than 50% of the variance in a facet. There are only two facets where the majority of the variance in a facet is explained by a Big Five factor (order, self-discipline).
Secondary loadings can explain additional variance in some facets. For example, for anger/hostility neuroticism explains .48^2 = 23% of the variance and agreeableness explains another -.43^2 = 18% of the variance for a total of 23+18 = 41% explained variance. However, even with secondary loadings many facets have substantial residual variance. This is of course predicted by a hierarchical model of personality traits with more specific factors underneath the global Big Five traits. However, it also implies that Big Five measures fail to capture substantial personality variance. It is therefore not surprising that facet measures often predict additional variance in outcomes that it is not predicted by the Big Five (e.g., Schimmack, Oishi, Furr, & Funder, 2004). Personality researchers need to use facet level or other more specific measures of personality in addition to Big Five measures to capture all of the personality variance in outcomes.
What are the Big Five?
Factor loadings are often used to explore the constructs underlying factors. The terms neuroticism, extraversion, or openness are mere labels for the shared variance among facets with primary loadings on a factor. There has been some discussion about the Big Five factors and there meaning is still far from clear. For example, there has been a debate about the extraversion factor. Lucas, Diener, Grob, Suh, and Shao (2000) argued that extraversion is the disposition to respond strongly to rewards. Ashton, Lee, and Paunonen disagreed and argued that social attention underlies extraversion. Empirically it would be easy to answer these questions if one facet would show a very high loading on a Big Five factor. The more loadings approach one, the more a factor corresponds to a facet or is highly related to a facet. However, the loading pattern does not suggest that a single facet captures the meaning of a Big Five factor. The strongest relationship is found for self-discipline and conscientiousness. Thus, good self-regulation may be the core aspect of conscientiousness that also influences achievement striving or orderliness. However, more generally the results suggest that the nature of the Big Five factors is not obvious. It requires more work to uncover the glue that ties facets belonging to a single factor together. Theories range from linguistic structures to shared neurotransmitters.
Evaluative Bias
The results for evaluative bias are novel because previous studies failed to model evaluative bias in responses to the NEO-PI-R. It would be interesting to validate the variation in loadings on the evaluative bias factor with ratings of item- or facet-desirability. However, intuitively the variation makes sense. It is more desirable to be competent (C1, r = .66) and not depressed (N3, r = -69) than to be an excitement seeker (E5: r = .03) or compliant (A4: r = .09). The negative loading for modesty also makes sense and validates self-ratings of modesty (A5,r = -.33). Modest individuals are not supposed to exaggerate their desirable attributes and apparently they refrain from doing so also when they complete the NEO-PI-R.
Recently, McCrae (2018) acknowledged the presence of evaluative biases in NEO scores, but presented calculations that suggested the influence is relatively small. He suggested that facet-facet correlations might be inflated by .10 due to evaluative bias. However, this average is uninformative. It could imply that all facets have a loading of .33 or -.33 on the evaluative bias factor, which introduces a bias of .33*.33 = .10 or .33*-.33 = -.10 in facet-facet correlations. In fact, the average absolute loading on the evaluative bias factor is .30. However, this masks the fact that some facets have no evaluative bias and others have much more evaluative bias. For example, the measure of competence beliefs (self-effacy) C1 has a loading of .66 on the evaluative bias factor, which is higher than the loading on conscientiousness (.52). It should be noted that the NEO-PI-R is a commercial instrument and that it is in the interest of McCrae to claim that the NEO-PI-R is a valid measure for personalty assessment. In contrast, I have no commercial interest in finding more or less evaluative bias in the NEO-PI-R. This may explain the different conclusions about the practical significance of evaluative bias in NEO-PI-R scores.
In short, the present analysis suggests that the amount of evaluative bias varies across facet scales. While the influence of evaluative bias tends to be modest for many scales, scales with highly desirable traits show rather strong influence of evaluative bias. In the future it would be interesting to use multi-method data to separate evaluative bias from content variance (Anusic et al., 2009).
Measurement of the Big Five
Structural equation modeling can be used to test substantive theories with a measurement model or to develop and evaluate measurement models. Unfortunately, personality psychologists have not taken advantage of structural equation modeling to improve personality questionnaires. The present study highlights two ways in which SEM analysis of personality ratings is beneficial. First, it is possible to model evaluative bias and to search for items with low evaluative bias. Minimizing the influence of evaluative bias increases the validity of personality scales. Second, the present results can be used to create better measures of the Big Five. Many short Big Five scales focus exclusively on a single facet. As a result, these measures do not actually capture the Big Five. To measure the Big Five efficiently, a measure requires several facets with high loadings on the Big Five factor. Three facets are sufficient to create a latent variable model that separates the facet-specific residual variance from the shared variance that reflects the Big Five. Based on the present results, the following facets seem good candidates for the measurement of the Big Five.
Neuroticism: Anxiety, Anger, and Depression. The shared variance reflects a general tendency to respond with negative emotions.
Extraversion: Warmth, Gregariousness, Positive Emotions: The shared variance reflects a mix of sciability and cheerfulness.
Openness: Aesthetics, Action, Ideas. The shared variance reflects an interest in a broad range of activities that includes arts, intellectual stimulation, as well as travel.
Agreeableness: Straightforwardness, Altruism, Complicance: The shared variance represents respecting others.
Conscientiousness: Order, Self-Discipline, Dutifulness. I do not include achievement striving because it may be less consistent across the life span. The shared variance represents following a fixed set of rules.
This is of course just a suggestion. More research is needed. What is novel is the use of reflective measurement models to examine this question. McCrae et al. (1996) and some others before them tried and failed. Here I show that it is possible and useful to fit facet corelations with a structural equation model. Thus, twenty years after McCrae et al. suggested we should not use SEM/CFA, it is time to reconsider this claim and to reject it. Most personality theories are reflective models. It is time to test these models with the proper statistical method.
You write, “As it turns out, correlations among the Big Five are only found in ratings by a single rater, but not in correlations across raters (e.g., self-rated Extraversion and informant-rated Agreeableness).” This is not true, and in your previous post you even acknowledged that it is not true. Here is a meta-analysis showing that even when the Big Five are modeled as the shared variance among multiple raters, there remain correlations among them: Chang, L., Connelly, B. S., & Geeza, A. A. (2012). Separating method factors and higher order traits of the Big Five: A meta-analytic multitrait–multimethod approach. Journal of personality and social psychology, 102(2), 408.
Did they use Big Five scales as indicators of the Big Five factors? If so, the results are inconclusive because secondary loadings will produce spurious correlations among scale scores that do not represent the factor structure. This is the reason, proper tests have to use hierarchical models with a measurement model at the item level.
https://replicationindex.com/2019/08/23/a-psychometric-study-of-the-neo-pi-r/