Please see the new post on rankings of psychology departments that is based on all areas of psychology and covers the years from 2010 to 2015 with separate information for the years 2012-2015.
===========================================================================
Old post on rankings of social psychology research at 100 Psychology Departments
This post provides the first analysis of replicability for individual departments. The table focuses on social psychology and the results cannot be generalized to other research areas in the same department. An explanation of the rational and methodology of replicability rankings follows in the text below the table.
| Department | 2010-2014 |
|---|---|
| Macquarie University | 91 |
| New Mexico State University | 82 |
| The Australian National University | 81 |
| University of Western Australia | 74 |
| Maastricht University | 70 |
| Erasmus University Rotterdam | 70 |
| Boston University | 69 |
| KU Leuven | 67 |
| Brown University | 67 |
| University of Western Ontario | 67 |
| Carnegie Mellon | 67 |
| Ghent University | 66 |
| University of Tokyo | 64 |
| University of Zurich | 64 |
| Purdue University | 64 |
| University College London | 63 |
| Peking University | 63 |
| Tilburg University | 63 |
| University of California, Irvine | 63 |
| University of Birmingham | 62 |
| University of Leeds | 62 |
| Victoria University of Wellington | 62 |
| University of Kent | 62 |
| Princeton | 61 |
| University of Queensland | 61 |
| Pennsylvania State University | 61 |
| Cornell University | 59 |
| University of California at Los Angeles | 59 |
| University of Pennsylvania | 59 |
| University of New South Wales (UNSW) | 59 |
| Ohio State University | 58 |
| National University of Singapore | 58 |
| Vanderbilt University | 58 |
| Humboldt Universität Berlin | 58 |
| Radboud University | 58 |
| University of Oregon | 58 |
| Harvard University | 56 |
| University of California, San Diego | 56 |
| University of Washington | 56 |
| Stanford University | 55 |
| Dartmouth College | 55 |
| SUNY Albany | 55 |
| University of Amsterdam | 54 |
| University of Texas, Austin | 54 |
| University of Hong Kong | 54 |
| Chinese University of Hong Kong | 54 |
| Simone Fraser University | 54 |
| Ruprecht-Karls-Universitaet Heidelberg | 53 |
| University of Florida | 53 |
| Yale University | 52 |
| University of California, Berkeley | 52 |
| University of Wisconsin | 52 |
| University of Minnesota | 52 |
| Indiana University | 52 |
| University of Maryland | 52 |
| University of Toronto | 51 |
| Northwestern University | 51 |
| University of Illinois at Urbana-Champaign | 51 |
| Nanyang Technological University | 51 |
| University of Konstanz | 51 |
| Oxford University | 50 |
| York University | 50 |
| Freie Universität Berlin | 50 |
| University of Virginia | 50 |
| University of Melbourne | 49 |
| Leiden University | 49 |
| University of Colorado, Boulder | 49 |
| Univerität Würzburg | 49 |
| New York University | 48 |
| McGill University | 48 |
| University of Kansas | 48 |
| University of Exeter | 47 |
| Cardiff University | 46 |
| University of California, Davis | 46 |
| University of Groningen | 46 |
| University of Michigan | 45 |
| University of Kentucky | 44 |
| Columbia University | 44 |
| University of Chicago | 44 |
| Michigan State University | 44 |
| University of British Columbia | 43 |
| Arizona State University | 43 |
| University of Southern California | 41 |
| Utrecht University | 41 |
| University of Iowa | 41 |
| Northeastern University | 41 |
| University of Waterloo | 40 |
| University of Sydney | 40 |
| University of Bristol | 40 |
| University of North Carolina, Chapel Hill | 40 |
| University of California, Santa Barbara | 40 |
| University of Arizona | 40 |
| Cambridge University | 38 |
| SUNY Buffalo | 38 |
| Duke University | 37 |
| Florida State University | 37 |
| Washington University, St. Louis | 37 |
| Ludwig-Maximilians-Universität München | 36 |
| University of Missouri | 34 |
| London School of Economics | 33 |
Replicability scores of 50% and less are considered inadequate (grade F). The reason is that less than 50% of the published results are expected to produce a significant result in a replication study, and with less than 50% successful replications, the most rational approach is to treat all results as false because it is unclear which results would replicate and which results would not replicate.
RATIONALE AND METHODOLOGY
University rankings have become increasingly important in science. Top ranking universities use these rankings to advertise their status. The availability of a single number of quality and distinction creates pressures on scientists to meet criteria that are being used for these rankings. One key criterion is the number of scientific articles that are being published in top ranking scientific journals under the assumption that these impact factors of scientific journals track the quality of scientific research. However, top ranking journals place a heavy premium on novelty without ensuring that novel findings are actually true discoveries. Many of these high-profile discoveries fail to replicate in actual replication studies. The reason for the high rate of replication failures is that scientists are rewarded for successful studies, while there is no incentive to publish failures. The problem is that many of these successful studies are obtained with the help of luck or questionable research methods. For example, scientists do not report studies that fail to support their theories. The problem of bias in published results has been known for a long time (Sterling, 1959). However, few researchers were aware of the extent of the problem. New evidence suggests that more than half of published results provide false or extremely biased evidence. When more than half of published results are not credible, a science loses its credibility because it is not clear which results can be trusted and which results provide false information.
The credibility and replicability of published findings varies across scientific disciplines (Fanelli, 2010). More credible sciences are more willing to conduct replication studies and to revise original evidence. Thus, it is inappropriate to make generalized claims about the credibility of science. Even within a scientific discipline credibility and replicability can vary across sub-disciplines. For example, results from cognitive psychology are more replicable than results from social psychology. The replicability of social psychological findings is extremely low. Despite an increase in sample size, which makes it easier to obtain a significant result in a replication study, only 5 out of 38 replication studies produced a significant result. If the replication studies had used the same sample sizes as the original studies, only 3 out of 38 results would have replicated, that is, produced a significant result in the replication study. Thus, most published results in social psychology are not trustworthy.
There have been mixed reactions by social psychologists to the replication crisis in social psychology. On the one hand, prominent leaders of the field have defended the status quo with the following arguments.
1 – The experiments who conducted the replication studies are incompetent (Bargh, Schnall, Gilbert).
2 – A mysterious force makes effects disappear over time (Schooler).
3 – A statistical artifact (regression to the mean) will always make it harder to find significant results in a replication study (Fiedler).
4 – It is impossible to repeat social psychological studies exactly and a replication study is likely to produce different results than an original study (the hidden moderator) (Schwarz, Strack).
These arguments can be easily dismissed because they do not explain why cognitive psychologists and other scientific disciplines have more successful replications and more failed results. The real reason for the low replicability of social psychology is that social psychologists conduct many, relatively cheap studies that often fail to produce the expected results. They then conduct exploratory data analyses to find unexpected patterns in the data or they simply discard the study and publish only studies that support a theory that is consistent with the data (Bem). This hazardous approach to science can produce false positive results. For example, it allowed Bem (2011) to publish 9 significant results that seemed to show that humans can foresee unpredictable outcomes in the future. Some prominent social psychologists defend this approach to science.
“We did run multiple studies, some of which did not work, and some of which worked better than others. You may think that not reporting the less successful studies is wrong, but that is how the field works.” (Roy Baumeister,)
The lack of rigorous scientific standards also allowed Diederik Stapel, a prominent social psychologist to fabricate data, which led to over 50 retractions of scientific articles. The commission that investigated Stapel came to the conclusion that he was only able to publish so many fake articles because social psychology is a “sloppy science,” where cute findings and sexy stories count more than empirical facts.
Social psychology faces a crisis of confidence. While social psychology tried hard to convince the general public that it is a real science, it actually failed to follow standard norms of science to ensure that social psychological theories are based on objective replicable findings. Social psychology therefore needs to reform its practices if it wants to be taken serious as a scientific field that can provide valuable insights into important question about human nature and human behavior.
There are many social psychologists who want to improve scientific standards. For example, the head of the OSF-reproducibility project, Brian Nosek, is a trained social psychologist. Mickey Inzlicht published a courageous self-analysis that revealed problems in some of his most highly cited articles and changed the way his lab is conducting studies to improve social psychology. Incoming editors of social psychology journals are implementing policies to increase the credibility of results published in their journals (Simine Vazire; Roger Giner-Sorolla). One problem for social psychologists willing to improve their science is that the current incentive structure does not reward replicability. The reason is that it is possible to count number of articles and number of citations, but it seems difficult to quantify replicability and scientific integrity.
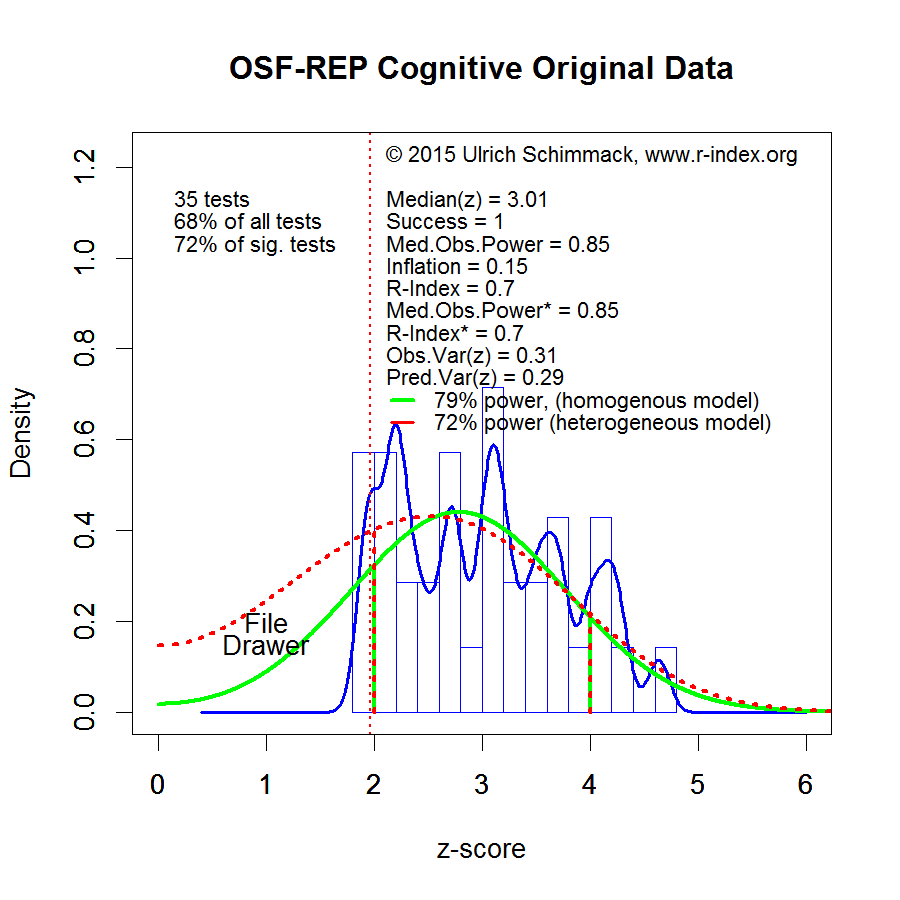
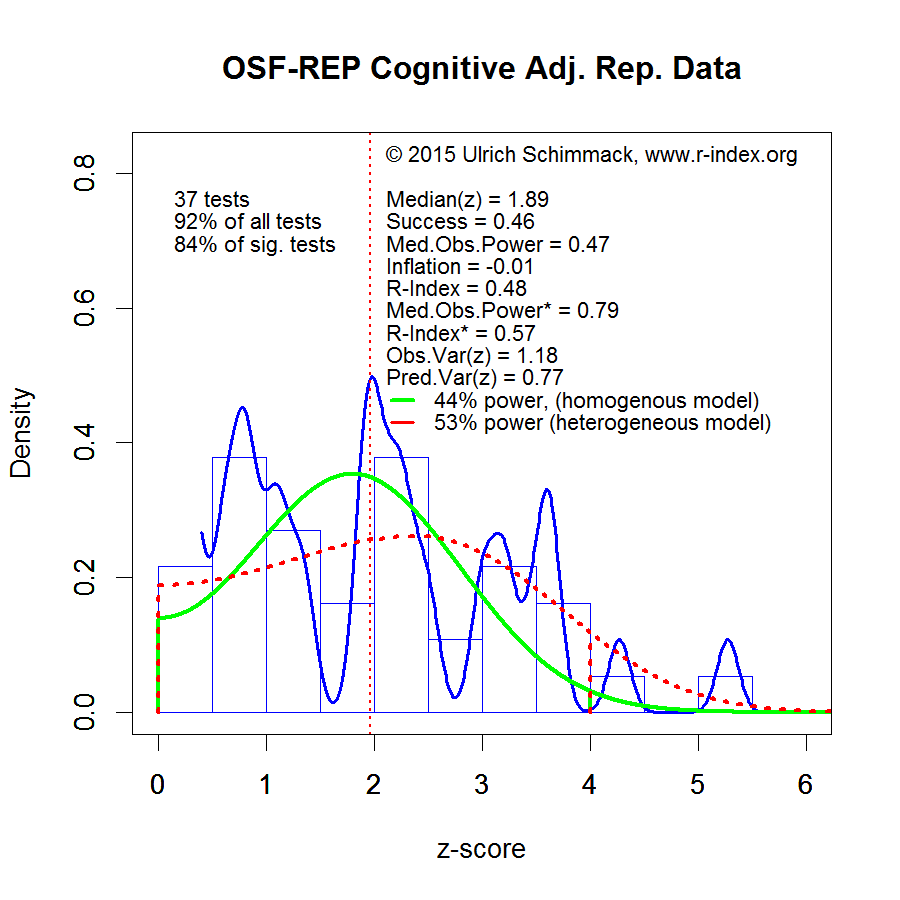
To address this problem, Jerry Brunner and I developed a quantitative measure of replicability. The replicability-score uses published statistical results (p-values) and transforms them into absolute z-scores. The distribution of z-scores provides information about the statistical power of a study given the sample size, design, and observed effect size. Most important, the method takes publication bias into account and can estimate the true typical power of published results. It also reveals the presence of a file-drawer of unpublished failed studies, if the published studies contain more significant results than the actual power of studies allows. The method is illustrated in the following figure that is based on t- and F-tests published in the most important journals that publish social psychology research.

The green curve in the figure illustrates the distribution of z-scores that would be expected if a set of studies had 53% power. That is, random sampling error will sometimes inflate the observed effect size and sometimes deflate the observed effect size in a sample relative to the population effect size. With 54% power, there would be 46% (1 – .54 = .46) non-significant results because the study had insufficient power to demonstrate an effect that actually exists. The graph shows that the green curve fails to describe the distribution of observed z-scores. On the one hand, there are more extremely high z-scores. This reveals that the set of studies is heterogeneous. Some studies had more than 54% power and others had less than 54% power. On the other hand, there are fewer non-significant results than the green curve predicts. This discrepancy reveals that non-significant results are omitted from the published reports.
Given the heterogeneity of true power, the red curve is more appropriate. It provides the best fit to the observed z-scores that are significant (z-scores > 2). It does not model the z-scores below 2 because non-significant z-scores are not reported. The red-curve gives a lower estimate of power and shows a much larger file-drawer.
I limit the power analysis to z-scores in the range from 2 to 4. The reason is that z-scores greater than 4 imply very high power (> 99%). In fact, many of these results tend to replicate well. However, many theoretically important findings are published with z-scores less than 4 as evidence. These z-scores do not replicate well. If social psychology wants to improve its replicability, social psychologists need to conduct fewer studies with more statistical power that yield stronger evidence and they need to publish all studies to reduce the file-drawer.
To provide an incentive to increase the scientific standards in social psychology, I computed the replicability-score (homogeneous model for z-scores between 2 and 4) for different journals. Journal editors can use the replicability rankings to demonstrate that their journal publishes replicable results. Here I report the first rankings of social psychology departments. To rank departments, I searched the database of articles published in social psychology journals for the affiliation of articles’ authors. The rankings are based on the z-scores of these articles published in the years 2010 to 2014. I also conducted an analysis for the year 2015. However, the replicability scores were uncorrelated with those in 2010-2014 (r = .01). This means that the 2015 results are unreliable because the analysis is based on too few observations. As a result, the replicability rankings of social psychology departments cannot reveal recent changes in scientific practices. Nevertheless, they provide a first benchmark to track replicability of psychology departments. This benchmark can be used by departments to monitor improvements in scientific practices and can serve as an incentive for departments to create policies and reward structures that reward scientific integrity over quantitative indicators of publication output and popularity. Replicabilty is only one aspect of high-quality research, but it is a necessary one. Without sound empirical evidence that supports a theoretical claim, discoveries are not real discoveries.