
Abstract: I predicted the replicability of 38 social psychology results in the OSF-Reproducibility Project. Based on post-hoc-power analysis I predicted a success rate of 35%. The actual success rate was 8% (3 out of 38) and post-hoc-power was estimated to be 3% for 36 out of 38 studies (5% power = type-I error rate, meaning the null-hypothesis is true).
The OSF-Reproducibility Project aimed to replicate 100 results published in original research articles in three psychology journals in 2008. The selected journals focus on publishing results from experimental psychology. The main paradigm of experimental psychology is to recruit samples of participants and to study their behaviors in controlled laboratory conditions. The results are then generalized to the typical behavior of the average person.
An important methodological distinction in experimental psychology is the research design. In a within-subject design, participants are exposed to several (a minimum of two) situations and the question of interest is whether responses to one situation differ from behavior in other situations. The advantage of this design is that individuals serve as their own controls and variation due to unobserved causes (mood, personality, etc.) does not influence the results. This design can produce high statistical power to study even small effects. The design is often used by cognitive psychologists because the actual behaviors are often simple behaviors (e.g., pressing a button) that can be repeated many times (e.g., to demonstrate interference in the Stroop paradigm).
In a between-subject design, participants are randomly assigned to different conditions. A mean difference between conditions reveals that the experimental manipulation influenced behavior. The advantage of this design is that behavior is not influenced by previous behaviors in the experiment (carry over effects). The disadvantage is that many uncontrolled factors (e..g, mood, personality) also influence behavior. As a result, it can be difficult to detect small effects of an experimental manipulation among all of the other variance that is caused by uncontrolled factors. As a result, between-subject designs require large samples to study small effects or they can only be used to study large effects.
One of the main findings of the OSF-Reproducibility Project was that results from within-subject designs used by cognitive psychology were more likely to replicate than results from between-subject designs used by social psychologists. There were two few between-subject studies by cognitive psychologists or within-subject designs by social psychologists to separate these factors. This result of the OSF-reproducibility project was predicted by PHP-curves of the actual articles as well as PHP-curves of cognitive and social journals (Replicability-Rankings).
Given the reliable difference between disciplines within psychology, it seems problematic to generalize the results of the OSF-reproducibility project to all areas of psychology. The Replicability-Rankings suggest that social psychology has a lower replicability than other areas of psychology. For this reason, I conducted separate analyses for social psychology and for cognitive psychology. Other areas of psychology had two few studies to conduct a meaningful analysis. Thus, the OSF-reproducibility results should not be generalized to all areas of psychology.
The master data file of the OSF-reproducibilty project contained 167 studies with replication results for 99 studies. 57 studies were classified as social studies. However, this classification used a broad definition of social psychology that included personality psychology and developmental psychology. It included six articles published in the personality section of the Journal of Personality and Social Psychology. As each section functions essentially like an independent journal, I excluded all studies from this section. The file also contained two independent replications of two experiments (experiment 5 and 7) in Albarracín et al. (2008; DOI: 10.1037/a0012833). As the main sampling strategy was to select the last study of each article, I only included Study 7 in the analysis (Study 5 did not replicate, p = .77). Thus, my selection did not lower the rate of successful replications. There were also two independent replications of the same result in Bressan and Stranieri (2008). Both replications produced non-significant results (p = .63, p = .75). I selected the replication study with the larger sample (N = 318 vs. 259). I also excluded two studies that were not independent replications. Rule and Ambady (2008) examined the correlation between facial features and success of CEOs. The replication study had new raters to rate the faces, but used the same faces. Heine, Buchtel, and Norenzayan (2008) examined correlates of conscientiousness across nations and the replication study examined the same relationship across the same set of nations. I also excluded replications of non-significant results because non-significant results provide ambiguous information and cannot be interpreted as evidence for the null-hypothesis. For this reason, it is not clear how the results of a replication study should be interpreted. Two underpowered studies could easily produce consistent results that are both type-II errors. For this reason, I excluded Ranganath and Nosek (2008) and Eastwick and Finkel (2008). The final sample consisted of 38 articles.
I first conducted a post-hoc-power analysis of the reported original results. Test statistics were first converted into two-tailed p-values and two-tailed p-values were converted into absolute z-scores using the formula (1 – norm.inverse(1-p/2). Post-hoc power was estimated by fitting the observed z-scores to predicted z-scores with a mixed-power model with three parameters (Brunner & Schimmack, in preparation).
Estimated power was 35%. This finding reflects the typical finding that reported results are a biased sample of studies that produced significant results, whereas non-significant results are not submitted for publication. Based on this estimate, one would expect that only 35% of the 38 findings (k = 13) would produce a significant result in an exact replication study with the same design and sample size.

The Figure visualizes the discrepancy between observed z-scores and the success rate in the original studies. Evidently, the distribution is truncated and the mode of the curve (it’s highest point) is projected to be on the left side of the significance criterion (z = 1.96, p = .05 (two-tailed)). Given the absence of reliable data in the range from 0 to 1.96, the data make it impossible to estimate the exact distribution in this region, but the step decline of z-scores on the right side of the significance criterion suggests that many of the significant results achieved significance only with the help of inflated observed effect sizes. As sampling error is random, these results will not replicate again in a replication study.
The replication studies had different sample sizes than the original studies. This makes it difficult to compare the prediction to the actual success rate because the actual success rate could be much higher if the replication studies had much larger samples and more power to replicate effects. For example, if all replication studies had sample sizes of N = 1,000, we would expect a much higher replication rate than 35%. The median sample size of the original studies was N = 86. This is representative of studies in social psychology. The median sample size of the replication studies was N = 120. Given this increase in power, the predicted success rate would increase to 50%. However, the increase in power was not uniform across studies. Therefore, I used the p-values and sample size of the replication study to compute the z-score that would have been obtained with the original sample size and I used these results to compare the predicted success rate to the actual success rate in the OSF-reproducibility project.
The depressing finding was that the actual success rate was much lower than the predicted success rate. Only 3 out of 38 results (8%) produced a significant result (without the correction of sample size 5 findings would have been significant). Even more depressing is the fact that a 5% criterion, implies that every 20 studies are expected to produce a significant result just by chance. Thus, the actual success rate is close to the success rate that would be expected if all of the original results were false positives. A success rate of 8% would imply that the actual power of the replication studies was only 8%, compared to the predicted power of 35%.
The next figure shows the post-hoc-power curve for the sample-size corrected z-scores.
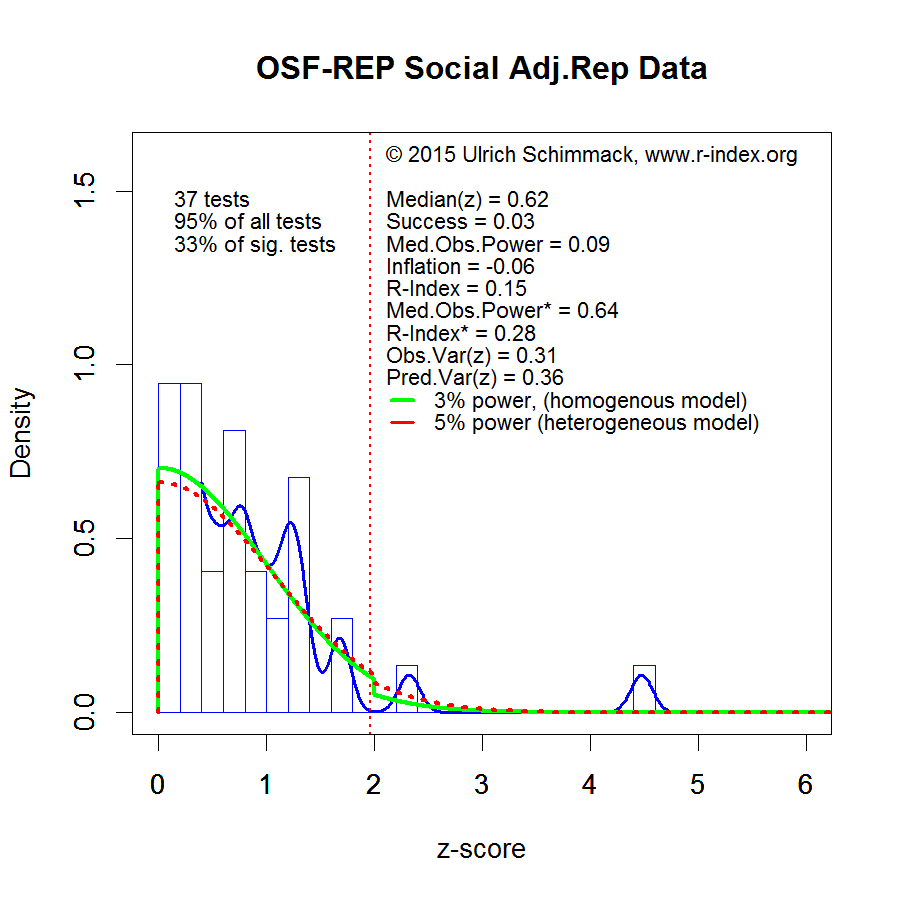
The PHP-Curve estimate of power for z-scores in the range from 0 to 4 is 3% for the homogeneous case. This finding means that the distribution of z-scores for 36 of the 38 results is consistent with the null-hypothesis that the true effect size for these effects is zero. Only two z-scores greater than 4 (one shown, the other greater than 6 not shown) appear to be replicable and robust effects.
One replicable finding was obtained in a study by Halevy, Bornstein, and Sagiv. The authors demonstrated that allocation of money to in-group and out-group members is influenced much more by favoring the in-group than by punishing the out-group. Given the strong effect in the original study (z > 4), I had predicted that this finding would replicate.
The other successful replication was a study by Lemay and Clark (DOI: 10.1037/0022-3514.94.4.647). The replicated finding was that participants’ projected their own responsiveness in a romantic relationship onto their partners’ responsiveness while controlling for partners’ actual responsiveness. Given the strong effect in the original study (z > 4), I had predicted that this finding would replicate.
Based on weak statistical evidence in the original studies, I had predicted failures of replication for 25 studies. Given the low success rate, it is not surprising that my success rate was 100.
I made the wrong prediction for 11 results. In all cases, I predicted a successful replication when the outcome was a failed replication. Thus, my overall success rate was 27/38 = 71%. Unfortunately, this success rate is easily beaten by a simple prediction rule that nothing in social psychology replicates, which is wrong in only 3 out of 38 predictions (89% success rate).
Below I briefly comment on the 11 failed predictions.
1 Based on strong statistics (z > 4), I had predicted a successful replication for Förster, Liberman, and Kuschel (DOI: 10.1037/0022-3514.94.4.579). However, even when I made this predictions based on the reported statistics, I had my doubts about this study because statisticians had discovered anomalies in Jens Förster’s studies that cast doubt on the validity of these reported results. Post-hoc power analysis can correct for publication bias, but it cannot correct for other sources of bias that lead to vastly inflated effect sizes.
2 I predicted a successful replication of Payne, MA Burkley, MB Stokes. The replication study actually produced a significant result, but it was no longer significant after correcting for the larger sample size in the replication study (180 vs. 70, p = .045 vs. .21). Although the p-value in the replication study is not very reassuring, it is possible that this is a real effect. However, the original result was probably still inflated by sampling error to produce a z-score of 2.97.
3 I predicted a successful replication of McCrae (DOI: 10.1037/0022-3514.95.2.274). This prediction was based on a transcription error. Whereas the z-score for the target effect was 1.80, I posted a z-score of 3.5. Ironically, the study did successfully replicate with a larger sample size, but the effect was no longer significant after adjusting the result for sample size (N = 61 vs. N = 28). This study demonstrates that marginally significant effects can reveal real effects, but it also shows that larger samples are needed in replication studies to demonstrate this.
4 I predicted a successful replication for EP Lemay, MS Clark (DOI: 10.1037/0022-3514.95.2.420). This prediction was based on a transcription error because EP Lemay and MS Clark had another study in the project. With the correct z-score of the original result (z = 2.27), I would have predicted correctly that the result would not replicate.
5 I predicted a successful replication of Monin, Sawyer, and Marquez (DOI: 10.1037/0022-3514.95.1.76) based on a strong result for the target effect (z = 3.8). The replication study produced a z-score of 1.45 with a sample size that was not much larger than the original study (N = 75 vs. 67).
6 I predicted a successful replication for Shnabel and Nadler (DOI: 10.1037/0022-3514.94.1.116). The replication study increased sample size by 50% (Ns = 141 vs. 94), but the effect in the replication study was modest (z = 1.19).
7 I predicted a successful replication for van Dijk, van Kleef, Steinel, van Beest (DOI: 10.1037/0022-3514.94.4.600). The sample size in the replication study was slightly smaller than in the original study (N = 83 vs. 103), but even with adjustment the effect was close to zero (z = 0.28).
8 I predicted a successful replication of V Purdie-Vaughns, CM Steele, PG Davies, R Ditlmann, JR Crosby (DOI: 10.1037/0022-3514.94.4.615). The original study had rather strong evidence (z = 3.35). In this case, the replication study had a much larger sample than the original study (N = 1,490 vs. 90) and still did not produce a significant result.
9 I predicted a successful replication of C Farris, TA Treat, RJ Viken, RM McFall (doi:10.1111/j.1467-9280.2008.02092.x). The replication study had a somewhat smaller sample (N = 144 vs. 280), but even with adjustment of sample size the effect in the replication study was close to zero (z = 0.03).
10 I predicted a successful replication of KD Vohs and JW Schooler (doi:10.1111/j.1467-9280.2008.02045.x)). I made this prediction of generally strong statistics, although the strength of the target effect was below 3 (z = 2.8) and the sample size was small (N = 30). The replication study doubled the sample size (N = 58), but produced weak evidence (z = 1.08). However, even the sample size of the replication study is modest and does not allow strong conclusions about the existence of the effect.
11 I predicted a successful replication of Blankenship and Wegener (DOI: 10.1037/0022-3514.94.2.94.2.196). The article reported strong statistics and the z-score for the target effect was greater than 3 (z = 3.36). The study also had a large sample size (N = 261). The replication study also had a similarly large sample size (N = 251), but the effect was much smaller than in the original study (z = 3.36 vs. 0.70).
In some of these failed predictions it is possible that the replication study failed to reproduce the same experimental conditions or that the population of the replication study differs from the population of the original study. However, there are twice as many studies where the failure of replication was predicted based on weak statistical evidence and the presence of publication bias in social psychology journals.
In conclusion, this set of results from a representative sample of articles in social psychology reported a 100% success rate. It is well known that this success rate can only be achieved with selective reporting of significant results. Even the inflated estimate of median observed power is only 71%, which shows that the success rate of 100% is inflated. A power estimate that corrects for inflation suggested that only 35% of results would replicate, and the actual success rate is only 8%. While mistakes by the replication experimenters may contribute to the discrepancy between the prediction of 35% and the actual success rate of 8%, it was predictable based on the results in the original studies that the majority of results would not replicate in replication studies with the same sample size as the original studies.
This low success rate is not characteristic of other sciences and other disciplines in psychology. As mentioned earlier, the success rate for cognitive psychology is higher and comparisons of psychological journals show that social psychology journals have lower replicability than other journals. Moreover, an analysis of time trends shows that replicability of social psychology journals has been low for decades and some journals even show a negative trend in the past decade.
The low replicability of social psychology has been known for over 50 years, when Cohen examined the replicability of results published in the Journal of Social and Abnormal Psychology (now Journal of Personality and Social Psychology), the flagship journal of social psychology. Cohen estimated a replicability of 60%. Social psychologists would rejoice if the reproducibility project had shown a replication rate of 60%. The depressing result is that the actual replication rate was 8%.
The main implication of this finding is that it is virtually impossible to trust any results that are being published in social psychology journals. Yes, two articles that posted strong statistics (z > 4) replicated, but several results with equally strong statistics did not replicate. Thus, it is reasonable to distrust all results with z-scores below 4 (4 sigma rule), but not all results with z-scores greater than 4 will replicate.
Given the low credibility of original research findings, it will be important to raise the quality of social psychology by increasing statistical power. It will also be important to allow publication of non-significant results to reduce the distortion that is created by a file-drawer filled with failed studies. Finally, it will be important to use stronger methods of bias-correction in meta-analysis because traditional meta-analysis seemed to show strong evidence even for incredible effects like premonition for erotic stimuli (Bem, 2011).
In conclusion, the OSF-project demonstrated convincingly that many published results in social psychology cannot be replicated. If social psychology wants to be taken seriously as a science, it has to change the way data are collected, analyzed, and reported and demonstrate replicability in a new test of reproducibility.
The silver lining is that a replication rate of 8% is likely to be an underestimation and that regression to the mean alone might lead to some improvement in the next evaluation of social psychology.
“regression to the mean alone might lead to some improvement in the next evaluation of social psychology”
You are assuming that the replication studies’ effect sizes are below the mean. What makes you think this?
Dear Richard Kunert,
I shouldn’t have written this sentence and I will remove it. It was intended as a joke because a prominent social psychologists tried to explain the OSF-results as a natural consequence of regression to the mean.
https://www.dgps.de/index.php?id=2000735
I don’t have any real reason to believe that the results of the OSF-project are biased and would increase other than the observation that it can only go up given that 2 out of 38 significant results would be expected by chance alone and 3 out of 38 is pretty much rock bottom.