
The OSF-Reproducibility Project (Psychology) aimed to replicate 100 results published in original research articles in three psychology journals in 2008. The selected journals focus on publishing results from experimental psychology. The main paradigm of experimental psychology is to recruit samples of participants and to study their behaviors in controlled laboratory conditions. The results are then generalized to the typical behavior of the average person.
An important methodological distinction in experimental psychology is the research design. In a within-subject design, participants are exposed to several (a minimum of two) situations and the question of interest is whether responses to one situation differ from behavior in other situations. The advantage of this design is that individuals serve as their own controls and variation due to unobserved causes (mood, personality, etc.) does not influence the results. This design can produce high statistical power to study even small effects. The design is often used by cognitive psychologists because the actual behaviors are often simple behaviors (e.g., pressing a button) that can be repeated many times (e.g., to demonstrate interference in the Stroop paradigm).
In a between-subject design, participants are randomly assigned to different conditions. A mean difference between conditions reveals that the experimental manipulation influenced behavior. The advantage of this design is that behavior is not influenced by previous behaviors in the experiment (carry over effects). The disadvantage is that many uncontrolled factors (e..g, mood, personality) also influence behavior. As a result, it can be difficult to detect small effects of an experimental manipulation among all of the other variance that is caused by uncontrolled factors. As a result, between-subject designs require large samples to study small effects or they can only be used to study large effects.
One of the main findings of the OSF-Reproducibility Project was that results from within-subject designs used by cognitive psychology were more likely to replicate than results from between-subject designs used by social psychologists. There were two few between-subject studies by cognitive psychologists or within-subject designs by social psychologists to separate these factors. This result of the OSF-reproducibility project was predicted by PHP-curves of the actual articles as well as PHP-curves of cognitive and social journals (Replicability-Rankings).
Given the reliable difference between disciplines within psychology, it seems problematic to generalize the results of the OSF-reproducibility project across all areas of psychology. For this reason, I conducted separate analyses for social psychology and for cognitive psychology. This post examines the replicability of results in cognitive psychology. The results for social psychology are posted here.
The master data file of the OSF-reproducibilty project contained 167 studies with replication results for 99 studies. 42 replications were classified as cognitive studies. I excluded Reynolds and Bresner was excluded because the original finding was not significant. I excluded C Janiszewski, D Uy (doi:10.1111/j.1467-9280.2008.02057.x) because it examined the anchor effect, which I consider to be social psychology. Finally, I excluded two studies with children as participants because this research falls into developmental psychology (E Nurmsoo, P Bloom; V Lobue, JS DeLoache).
I first conducted a post-hoc-power analysis of the reported original results. Test statistics were first converted into two-tailed p-values and two-tailed p-values were converted into absolute z-scores using the formula (1 – norm.inverse(1-p/2). Post-hoc power was estimated by fitting the observed z-scores to predicted z-scores with a mixed-power model with three parameters (Brunner & Schimmack, in preparation).
Estimated power was 75%. This finding reveals the typical presence of publication bias because the actual success rate of 100% is too high given the power of the studies. Based on this estimate, one would expect that only 75% of the 38 findings (k = 29) would produce a significant result in a set of 38 exact replication studies with the same design and sample size.
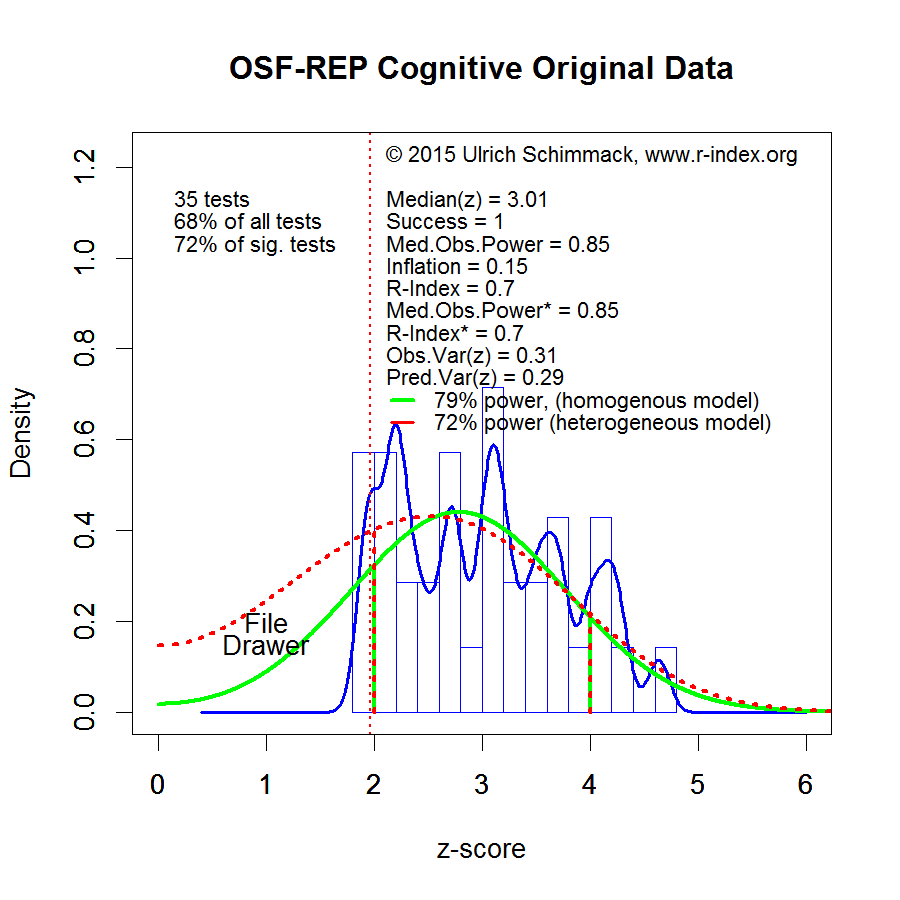
The Figure visualizes the discrepancy between observed z-scores and the success rate in the original studies. Evidently, the distribution is truncated and suggests a file-drawer of missing studies with non-significant results. However, the mode of the curve (it’s highest point) is projected to be on the right side of the significance criterion (z = 1.96, p = .05 (two-tailed)), which suggests that more than 50% of results should replicate. Given the absence of reliable data in the range from 0 to 1.96, the data make it impossible to estimate the exact distribution in this region, but the gentle decline of z-scores on the right side of the significance criterion suggests that the file-drawer is relatively small.
Sample sizes of the replication studies were based on power analysis with the reported effect sizes. The problem with this approach is that the reported effect sizes are inflated and provide an inflated estimate of true power. With a true power estimate of 75%, the inflated power estimates were above 80% and often over 90%. As a result, many replication studies used the same sample size and some even used a smaller sample size because the original study appeared to be overpowered (the sample size was much larger than needed). The median sample size for the original studies was 32. The median sample size for the replication studies was N = 32. Changes in sample sizes make it difficult to compare the replication rate of the original studies with those of the replication study. Therefore, I adjusted the z-scores of the replication study to match z-scores that would have been obtained with the original sample size. Based on the post-hoc-power analysis above, I predicted that 75% of the replication studies would produce a significant result (k = 29). I also had posted predictions for individual studies based on a more comprehensive assessment of each article. The success rate for my a priori predictions was 69% (k = 27).
The actual replication rate based on adjusted z-scores was 63% (k = 22), although 3 studies produced only p-values between .05 and .06 after the adjustment was applied. If these studies were not counted, the success rate would have been 50% (19/38). This finding suggests that post-hoc power analysis overestimates true power by 10% to 25%. However, it is also possible that some of the replication studies failed to reproduce the exact experimental conditions of the original studies, which would lower the probability of obtaining a significant result. Moreover, the number of studies is very small and the discrepancy may simply be due to random sampling error. The important result is that post-hoc power curves correctly predict that the success rate in a replication study will be lower than the actual success rate because it corrects for the effect of publication bias. It also correctly predicts that a substantial number of studies will be successfully replicated, which they were. In comparison, post-hoc power analysis of social psychology predicted only 35% of successful replications and only 8% successfully replicated. Thus, post-hoc power analysis correctly predicts that results in cognitive psychology are more replicable than results in social psychology.
The next figure shows the post-hoc-power curve for the sample-size corrected z-scores of the replication studies.
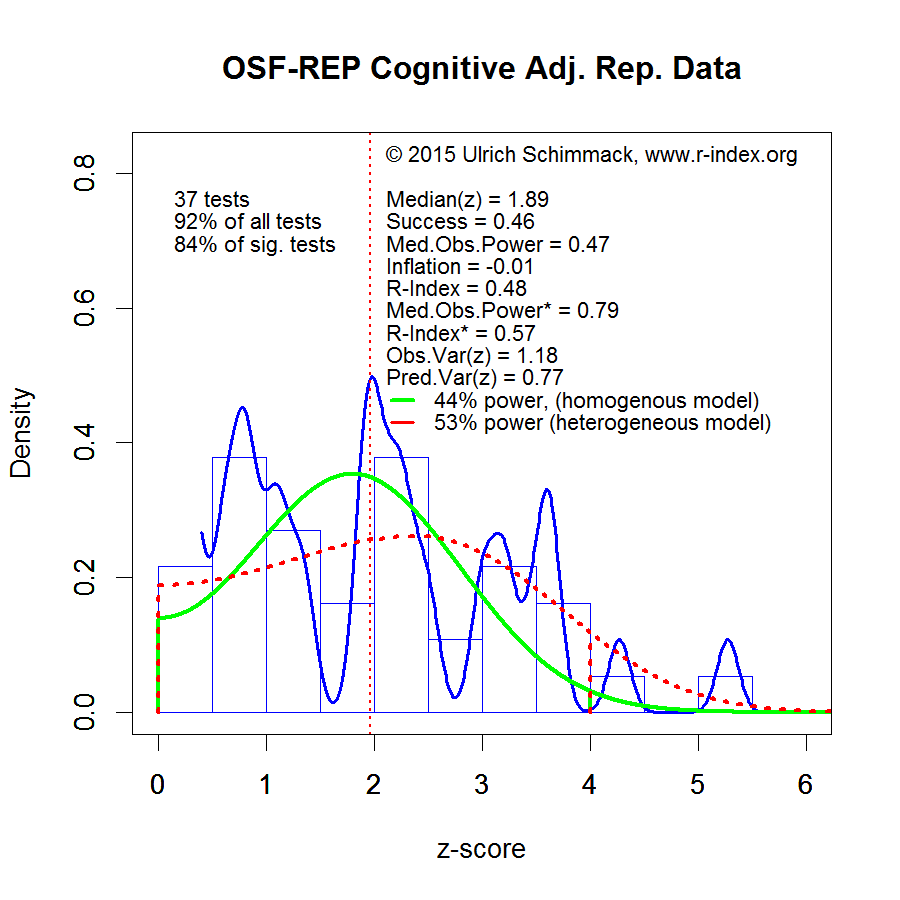
The PHP-Curve estimate of power for z-scores in the range from 0 to 4 is 53% for the heterogeneous model that fits the data better than a homogeneous model. The shape of the distribution suggests that several of the non-significant results are type-II errors; that is, the studies had insufficient statistical power to demonstrate a real effect.
I also conducted a power analysis that was limited to the non-significant results. The estimated average power was 22%. This power is a mixture of true power in different studies and may contain some cases of true false positives (power = .05), but the existing data are insufficient to determine whether results are true false positives or whether a small effect is present and sample sizes were too small to detect it. Again, it is noteworthy that the same analysis for social psychology produced an estimate of 5%, which suggests that most of the non-significant results in social psychology are true false positives (the null-effect is true).
Below I discuss my predictions of individual studies.
Eight studies reported an effect with a z-score greater than 4 (4 sigma), and I predicted that all of the 4-sigma effects would replicate. 7 out of 8 effects were successfully replicated (D Ganor-Stern, J Tzelgov; JI Campbell, ND Robert; M Bassok, SF Pedigo, AT Oskarsson; PA White; E Vul, H Pashler; E Vul, M Nieuwenstein, N Kanwisher; J Winawer, AC Huk, L Boroditsky). The only exception was CP Beaman, I Neath, AM Surprenant (DOI: 10.1037/0278-7393.34.1.219). It is noteworthy that the sample size of the original study was N = 99 and the sample size of the replication study was N = 14. Even with an adjusted z-score the study produced a non-significant result (p = .19). However, small samples produce less reliable results and it would be interesting to examine whether the result would become significant with an actual sample of 99 participants.
Based on more detailed analysis of individual articles, I predicted that an additional 19 studies would replicate. However, 9 out these 19 studies were not successfully replicated. Thus, my predictions of additional successful replications are just at chance level, given the overall success rate of 50%.
Based on more detailed analysis of individual articles, I predicted that 11 studies would not replicate. However, 5 out these 11 studies were successfully replicated. Thus, my predictions of failed replications are just at chance level, given the overall success rate of 50%.
In short, my only rule that successfully predicted replicability of individual studies was the 4-sigma rule that predicts that all findings with a z-score greater than 4 will replicate.
In conclusion, a replicability of 50-60% is consistent with Cohen’s (1962) suggestion that typical studies in psychology have 60% power. Post-hoc power analysis slightly overestimated the replicability of published findings despite its ability to correct for publication bias. Future research needs to examine the sources that lead to a discrepancy between predicted and realized success rate. It is possible that some of this discrepancy is due to moderating factors. Although a replicability of 50-60% is not as catastrophic as the results for social psychology with estimates in the range from 8-35%, cognitive psychologists should aim to increase the replicability of published results. Given the widespread use of powerful within-subject designs, this is easily achieved by a modest increase in sample sizes from currently 30 participants to 50 participants, which would increase power from 60% to 80%.