Thanks to social media, geography is no longer a barrier for scientific discourse. However, language is still a barrier. Fortunately, I understand German and I can respond to the official statement of the board of the German Psychological Association (DGPs), which was posted on the DGPs website (in German).
BACKGROUND
On September 1, 2015, Prof. Dr. Andrea Abele-Brehm, Prof. Dr. Mario Gollwitzer, and Prof. Dr. Fritz Strack published an official response to the results of the OSF-Replication Project – Psychology (in German) that was distributed to public media in order to correct potentially negative impressions about psychology as a science.
Numerous members of DGPs felt that this official statement did not express their views and noticed that members were not consulted about the official response of their organization. In response to this criticism, DGfP opened a moderated discussion page, where members could post their personal views (mostly in German).
On October 6, 2015, the board closed the discussion page and posted some final words (Schlussbeitrag). In this blog, I provide a critical commentary on these final words.
BOARD’S RESPONSE TO COMMENTS
The board members provide a summary of the core insights and arguments of the discussion from their (personal/official) perspective.
„Wir möchten nun die aus unserer Sicht zentralen Erkenntnisse und Argumente der unterschiedlichen Forumsbeiträge im Folgenden zusammenfassen und deutlich machen, welche vorläufigen Erkenntnisse wir im Vorstand aus ihnen ziehen.“
1. 68% success rate?
The first official statement suggested that the replication project showed that 68% of studies. This number is based on significance in a meta-analysis of the original and replication study. Critics pointed out that this approach is problematic because the replication project showed clearly that the original effect sizes were inflated (on average by 100%). Thus, the meta-analysis is biased and the 68% number is inflated.
In response to this criticism, the DGPs board states that “68% is the maximum [größtmöglich] optimistic estimate.” I think the term “biased and statistically flawed estimate” is a more accurate description of this estimate. It is common practice to consider fail-safe-N or to correct meta-analysis for publication bias. When there is clear evidence of bias, it is unscientific to report the biased estimate. This would be like saying that the maximum optimistic estimate of global warming is that global warming does not exist. This is probably a true statement about the most optimistic estimate, but not a scientific estimate of the actual global warming that has been taking place. There is no place for optimism in science. Optimism is a bias and the aim of science is to remove bias. If DGPs wants to represent scientific psychology, the board should post what they consider the most accurate estimate of replicability in the OSF-project.
2. The widely cited 36% estimate is negative.
The board members then justify the publication of the maximally optimistic estimate as a strategy to counteract negative perceptions of psychology as a science in response to the finding that only 36% of results were replicated. The board members felt that these negative responses misrepresent the OSF-project and psychology as a scientific discipline.
„Dies wird weder dem Projekt der Open Science Collaboration noch unserer Disziplin insgesamt gerecht. Wir sollten jedoch bei der konstruktiven Bewältigung der Krise Vorreiter innerhalb der betroffenen Wissenschaften sein.“
However, reporting the dismal 36% replication rate of the OSF-replication project is not a criticism of the OSF-project. Rather, it assumes that the OSF-replication project was a rigorous and successful attempt to provide an estimate of the typical replicability of results published in top psychology journals. The outcome could have been 70% or 35%. The quality of the project does not depend on the result. The result is also not a negatively biased perception of psychology as a science. It is an objective scientific estimate of the probability that a reported significant result in a journal would produce a significant result again in a replication study. Whether 36% is acceptable or not can be debated, but it seems problematic to post a maximally optimistic estimate to counteract negative implications of an objective estimate.
3. Is 36% replicability good or bad?
Next, the board ponders the implications of the 36% success rate. “How should we evaluate this number?” The board members do not know. According to their official conclusion, this question is complex as divergent contributions on the discussion page suggest.
„Im Science-Artikel wurde die relative Häufigkeit der in den Replikationsstudien statistisch bedeutsamen Effekte mit 36% angegeben. Wie ist diese Zahl zu bewerten? Wie komplex die Antwort auf diese Frage ist, machen die Forumsbeiträge von Roland Deutsch, Klaus Fiedler, Moritz Heene (s.a. Heene & Schimmack) und Frank Renkewitz deutlich.“
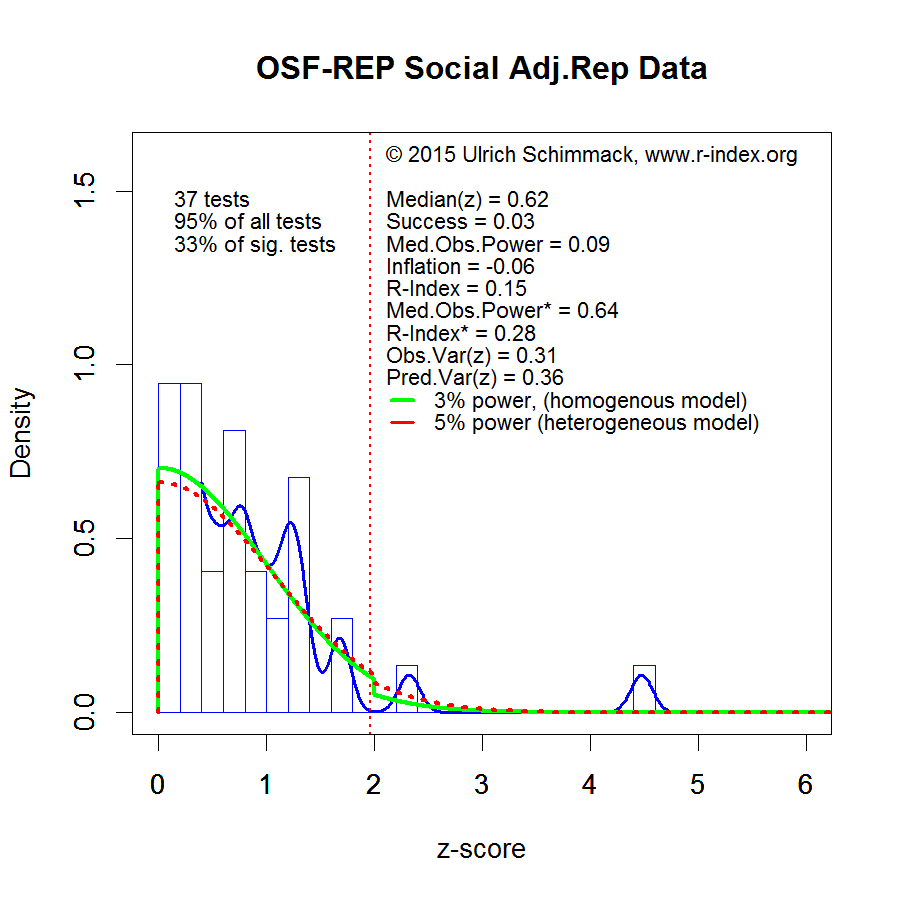
To help the board members to understand the number, I can give a brief explanation of replicability. Although there are several ways to define replicability, one plausible definition of replicability is to equate it with statistical power. Statistical power is the probability that a study will produce a significant result. A study with 80% power has an 80% probability to produce a significant result. For a set of 100 studies, one would expect roughly 80 significant results and 20 non-significant results. For 100 studies with 36% power, one would expect roughly 36 significant results and 64 non-significant results. If researchers would publish all studies, the percentage of published significant results would provide an unbiased estimate of the typical power of studies. However, it is well known that significant results are more likely to be written up, submitted for publication, and accepted for publication. These reporting biases explain why psychology journals report over 90% significant results, although the actual power of studies is less than 90%.
In 1962, Jacob Cohen provided the first attempt to estimate replicability of psychological results. His analysis suggested that psychological studies have approximately 50% power. He suggested that psychologists should increase power to 80% to provide robust evidence for effects and to avoid wasting resources on studies that cannot detect small, but practically important effects. For the next 50 years, psychologists have ignored Cohen’s warning that most studies are underpowered, despite repeated reminders that there are no signs of improvement, including reminders by prominent German psychologists like Gerg Giegerenzer, director of a Max Planck Institute (Sedlmeier & Giegerenzer, 1989; Maxwell, 2004; Schimmack, 2012).
The 36% success rate for an unbiased set of 100 replication studies, suggest that the actual power of published studies in psychology journals is 36%. The power of all studies conducted is even lower because the p < .05 selection criterion favors studies with higher power. Does the board think 36% power is an acceptable amount of power?
4. Psychologists should improve replicability in the future
On a positive note, the board members suggest that, after careful deliberation, psychologists need to improve replicability so that it can be demonstrated in a few years that replicability has increased.
„Wir müssen nach sorgfältiger Diskussion unter unseren Mitgliedern Maßnahmen ergreifen (bei Zeitschriften, in den Instituten, bei Förderorganisationen, etc.), die die Replikationsquote im temporalen Vergleich erhöhen können.“
The board members do not mention a simple solution to the replicabilty problem that was advocated over 50 years ago by Jacob Cohen. To increase replicability, psychologists have to think about the strength of the effects that they are investigating and they have to conduct studies that have a realistic chance to distinguish these effects from variation due to random error. This often means investing more resources (larger samples, repeated trials, etc.) in a single study. Unfortunately, the leaders of German psychologists appear to be unaware of this important and simple solution to the replication crisis. They neither mention power as a cause of the problem, nor do they recommend increasing power to increase replicability in the future.
5. Do the Results Reveal Fraud?
The DGPs board members then discuss the possibility that the OSF-reproducibilty results reveal fraud, like the fraud committed by Stapel. The board points out that the OSF-results do not imply that psychologists commit fraud because failed replications can occur for various reasons.
„Viele Medien (und auch einige Kolleginnen und Kollegen aus unserem Fach) nennen die Befunde der Science-Studie im gleichen Atemzug mit den Betrugsskandalen, die unser Fach in den letzten Jahren erschüttert haben. Diese Assoziation ist unserer Meinung nach problematisch: sie suggeriert, die geringe Replikationsrate sei auf methodisch fragwürdiges Verhalten der Autor(inn)en der Originalstudien zurückzuführen.“
It is true that the OSF-results do not reveal fraud. However, the board members confuse fraud with questionable research practices. Fraud is defined as fabricating data that were never collected. Only one of the 100 studies in the OSF-replication project (by Jens Förster, a former student of Fritz Strack, one of the board members) is currently being investigated for fraud by the University of Amsterdam. Despite very strong results in the original study, it failed to replicate.
The more relevant question is how much questionable research practices contributed to the results. Questionable research practices are practices where data are being collected, but statistical results are only being reported if they produce a significant result (studies, conditions, dependent variables, data points that do not produce significant results are excluded from the results that are being submitted for publication. It has been known for over 50 years that these practices produce a discrepancy between the actual power of studies and the rate of significant results that are published in psychology journals (Sterling, 1959).
Recent statistical developments have made it possible to estimate the true power of studies after correcting for publication bias. Based on these calculations, the true power of the original studies in the OSF-project was only 50%. Thus a large portion of the discrepancy between nearly 100% reported significant results and a replication success rate of 36% is explained by publication bias (see R-Index blogs for social psychology and cognitive psychology).
Other factors may contribute to the discrepancy between the statistical prediction that the replication success rate would be 50% and the actual success rate of 36%. Nevertheless, the lion share of the discrepancy can be explained by the questionable practice to report only evidence that supports a hypothesis that a researcher wants to support. This motivated bias undermines the very foundations of science. Unfortunately, the board ignores this implication of the OSF results.
6. What can we do?
The board members have no answer to this important question. In the past four years, numerous articles have been published that have made suggestions how psychology can improve its credibility as a science. Yet, the DPfP board seems to be unaware of these suggestions or unable to comment on these proposals.
„Damit wären wir bei der Frage, die uns als Fachgesellschaft am stärksten beschäftigt und weiter beschäftigen wird. Zum einen brauchen wir eine sorgfältige Selbstreflexion über die Bedeutung von Replikationen in unserem Fach, über die Bedeutung der neuesten Science-Studie sowie der weiteren, zurzeit noch im Druck oder in der Phase der Auswertung befindlichen Projekte des Center for Open Science (wie etwa die Many Labs-Studien) und über die Grenzen unserer Methoden und Paradigmen“
The time for more discussion has passed. After 50 years of ignoring Jacob Cohen’s recommendation to increase statistical power it is time for action. If psychologists are serious about replicability, they have to increase the power of their studies.
The board then discusses the possibility of measuring and publishing replication rates at the level of departments or individual scientists. They are not in favor of such initiatives, but they provide no argument for their position.
„Datenbanken über erfolgreiche und gescheiterte Replikationen lassen sich natürlich auch auf der Ebene von Instituten oder sogar Personen auswerten (wer hat die höchste Replikationsrate, wer die niedrigste?). Sinnvoller als solche Auswertungen sind Initiativen, wie sie zurzeit (unter anderem) an der LMU an der LMU München implementiert wurden (siehe den Beitrag von Schönbrodt und Kollegen).“
The question is why replicability should not be measured and used to evaluate researchers. If the board really valued replicability and wanted to increase replicability in a few years, wouldn’t it be helpful to have a measure of replicability and to reward departments or researchers who invest more resources in high powered studies that can produce significant results without the need to hide disconfirming evidence in file-drawers? A measure of replicability is also needed because current quantitative measures of scientific success are one of the reasons for the replicability crisis. The most successful researchers are those who publish the most significant results, no matter how these results were obtained (with the exception of fraud). To change this unscientific practice of significance chasing, it is necessary to have an alternative indicator of scientific quality that reflects how significant results were obtained.
Conclusion
The board makes some vague concluding remarks that are not worthwhile repeating here. So let me conclude with my own remarks.
The response of the DGPs board is superficial and does not engage with the actual arguments that were exchanged on the discussion page. Moreover, it ignores some solid scientific insights into the causes of the replicability crisis and it makes no concrete suggestions how German psychologists should change their behaviors to improve the credibility of psychology as a science. Not once do they point out that the results of the OSF-project were predictable based on the well-known fact that psychological studies are underpowered and that failed studies are hidden in file-drawers.
I received my education in Germany all the way to the Ph.D at the Free University in Berlin. I had several important professors and mentors that educated me about philosophy of science and research methods (Rainer Reisenzein, Hubert Feger, Hans Westmeyer, Wolfgang Schönpflug). I was a member of DGPs for many years. I do not believe that the opinion of the board members represent a general consensus among German psychologists. I hope that many German psychologists recognize the importance of replicability and are motivated to make changes to the way psychologists conduct research. As I am no longer a member of DGfP, I have no direct influence on it, but I hope that the next election will elect a candidate that will promote open science, transparency, and above all scientific integrity.