Introduction
A naive model of science assumes that scientists are objective. That is, they derive hypotheses from theories, collect data to test these theories, and then report the results. In reality, scientists are passionate about theories and often want to confirm that their own theories are right. This leads to conformation bias and the use of questionable research practices (QRPs, John et al., 2012; Schimmack, 2015). QRPs are defined as practices that increase the chances of the desired outcome (typically a statistically significant result) while at the same time inflating the risk of a false positive discovery. A simple QRP is to conduct multiple studies and to report only the results that support the theory.
The use of QRPs explains the astonishingly high rate of statistically significant results in psychology journals that is over 90% (Sterling, 1959; Sterling et al., 1995). While it is clear that this rate of significant results is too high, it is unclear how much it is inflated by QRPs. Given the lack of quantitative information about the extent of QRPs, motivated biases also produce divergent opinions about the use of QRPs by social psychologists. John et al. (2012) conducted a survey and concluded that QRPs are widespread. Fiedler and Schwarz (2016) criticized the methodology and their own survey of German psychologists suggested that QRPs are not used frequently. Neither of these studies is ideal because they relied on self-report data. Scientists who heavily use QRPs may simply not participate in surveys of QRPs or underreport the use of QRPs. It has also been suggested that many QRPs happen automatically and are not accessible to self-reports. Thus, it is necessary to study the use of QRPs with objective methods that reflect the actual behavior of scientists. One approach is to compare dissertations with published articles (Cairo et al., 2020). This method provided clear evidence for the use of QRPs, even though a published document could reveal their use. It is possible that this approach underestimates the use of QRPs because even the dissertation results could be influenced by QRPs and the supervision of dissertations by outsiders may reduce the use of QRPs.
With my colleagues, I developed a statistical method that can detect and quantify the use of QRPs (Bartos & Schimmack, 2020; Brunner & Schimmack, 2020). Z-curve uses the distribution of statistically significant p-values to estimate the mean power of studies before selection for significance. This estimate predicts how many non-significant results were obtained in the serach for the significant ones. This makes it possible to compute the estimated discovery rate (EDR). The EDR can then be compared to the observed discovery rate, which is simply the percentage of published results that are statistically significant. The bigger the difference between the ODR and the EDR is, the more questionable research practices were used (see Schimmack, 2021, for a more detailed introduction).
I merely focus on social psychology because (a) I am a social/personality psychologists, who is interested in the credibility of results in my field, and (b) because social psychology has a large number of replication failures (Schimmack, 2020). Similar analyses are planned for other areas of psychology and other disciplines. I also focus on social psychology more than personality psychology because personality psychology is often more exploratory than confirmatory.
Method
I illustrate the use of z-curve to quantify the use of QRPs with the most extreme examples in the credibility rankings of social/personality psychologists (Schimmack, 2021). Figure 1 shows the z-value plot (ZVP) of David Matsumoto. To generate this plot, the tests statistics from t-tests and F-tests were transformed into exact p-values and then transformed into the corresponding values on the standard normal distribution. As two-sided p-values are used, all z-scores are positive. However, because the curve is centered over the z-score that corresponds to the median power before selection for significance (and not zero, when the null-hypothesis is true), the distribution can look relatively normal. The variance of the distribution will be greater than 1 when studies vary in statistical power.
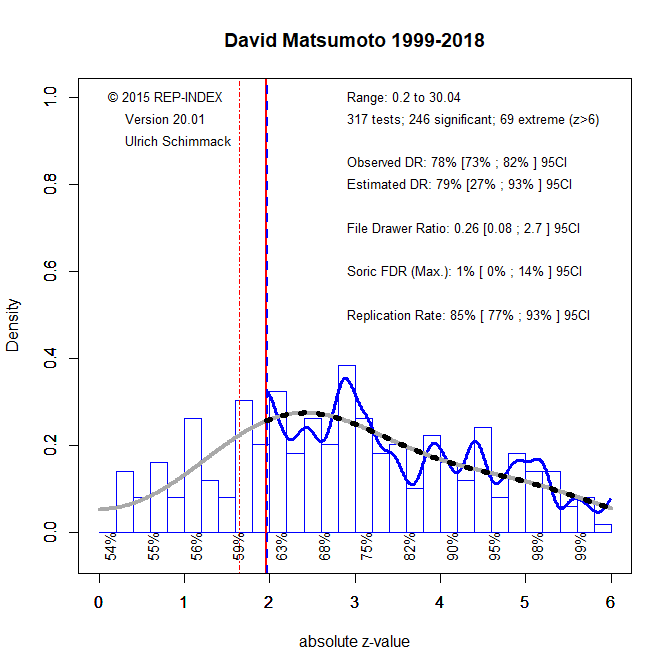
The grey curve in Figure 1 shows the predicted distribution based on the observed distribution of z-scores that are significant (z > 1.96). In this case, the observed number of non-significant results is similar to the predicted number of significant results. As a result, the ODR of 78% closely matches the EDR of 79%.
Figure 2 shows the results for Shelly Chaiken. The first notable observation is that the ODR of 75% is very similar to Matsumoto’s EDR of 78%. Thus, if we simply count the number of significant and non-significant p-values, there is no difference between these two researchers. However, the z-value plot (ZVP) shows a dramatically different picture. The peak density is 0.3 for Matsoumoto and 1.0 for Chaiken. As the maximum density of the standard normal distribution is .4, it is clear that the results in Chaiken’s articles are not from an actual sampling distribution. In other words, QRPs must have been used to produce too many just significant results with p-values just below .05.
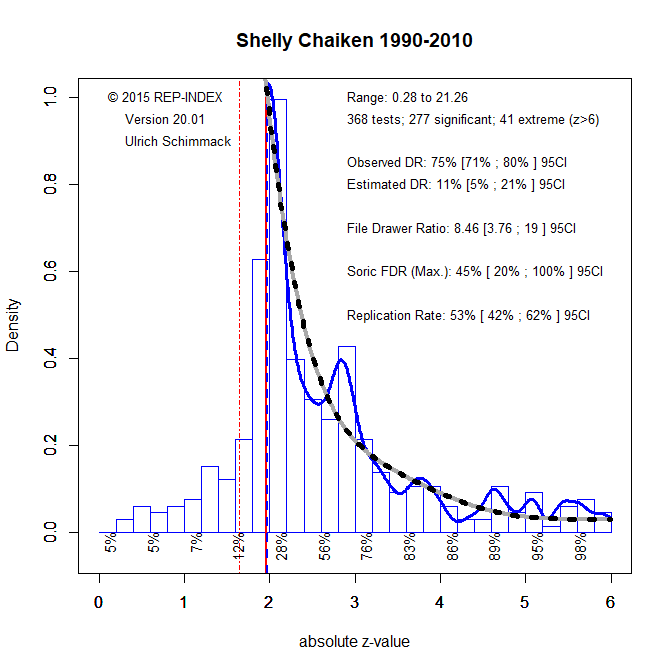
The comparison of the ODR and EDR shows a large discrepancy of 64 percentage points too many significant results (ODR = 75% minus EDR = 11%). This is clearly not a chance finding because the ODR falls well outside the 95% confidence interval of the EDR, 5% to 21%.
To examine the use of QPSs in social psychology, I computed the EDR and ORDR for over 200 social/personality psychologists. Personality psychologists were excluded if they reported too few t-values and F-values. The actual values can be found and additional statistics can be found in the credibility rankings (Schimmack, 2021). Here I used these data to examine the use of QRPs in social psychology.
Average Use of QRPs
The average ODR is 73.48 with a 95% confidence interval ranging from 72.67 to 74.29. The average EDR is 35.28 with a 95% confidence interval ranging from 33.14 to 37.43. the inflation due to QRPs is 38.20 percentage points, 95%CI = 36.10 to 40.30. This difference is highly significant, t(221) = 35.89, p < too many zeros behind the decimal for R to give an exact value.
It is of course not surprising that QRPs have been used. More important is the effect size estimate. The results suggest that QRPs inflate the discovery rate by over 100%. This explains why unbiased replication studies in social psychology have only a 25% chance of being significant (Open Science Collaboration, 2015). In fact, we can use the EDR as a conservative predictor of replication outcomes (Bartos & Schimmack, 2020). While the EDR of 35% is a bit higher than the actual replication rate, this may be due to the inclusion of non-focal hypothesis tests in these analyses. Z-curve analyses of focal hypothesis tests typically produce lower EDRs. In contrast, Fiedler and Schwarz failed to comment on the low replicability of social psychology. If social psychologists would not have used QRPs, it remains a mystery why their results are so hard to replicate.
In sum, the present results confirm that, on average, social psychologists heavily used QRPs to produce significant results that support their predictions. However, these averages masks differences between researchers like Matsumoto and Chaiken. The next analyses explore these individual differences between researchers.
Cohort Effects
I had no predictions about the effect of cohort on the use of QRPs. I conducted a twitter poll that suggested a general intuition that the use of QRPs may not have changed over time, but there was a lot of uncertainty in these answers. Similar results were obtained in a Facebook poll in the Psychological Methods Discussion Group. Thus, the a priori hypothesis is a vague prior of no change.

The dataset includes different generations of researchers. I used the first publication listed in WebofScience to date researchers. The earliest date was 1964 (Robert S. Wyer). The latest date was 2012 (Kurt Gray). The histogram shows that researchers from the 1970s to 2000s were well-represented in the dataset.
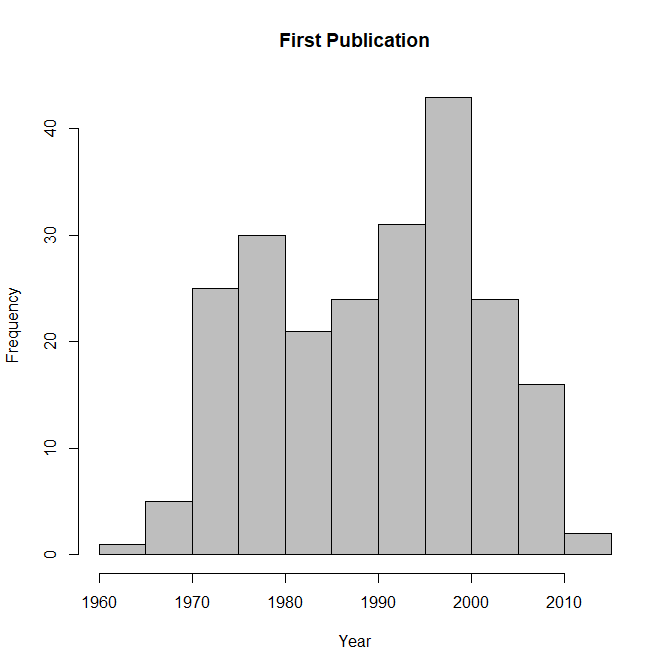
There was a significant negative correlation between the ODR and cohort, r(N = 222) = -.25, 95%CI = -.12 to -.37, t(220) = 3.83, p = .0002. This finding suggests that over time the proportion of non-significant results increased. For researchers with the first publication in the 1970s, the average ODR was 76%, whereas it was 72% for researchers with the first publication in the 2000s. This is a modest trend. There are various explanations for this trend.
One possibility is that power decreased as researchers started looking for weaker effects. In this case, the EDR should also show a decrease. However, the EDR showed no relationship with cohort, r(N = 222) = -.03, 95%CI = -.16 to .10, t(220) = 0.48, p = .63. Thus, less power does not seem to explain the decrease in the ODR. At the same time, the finding that EDR does not show a notable, abs(r) < .2, relationship with cohort suggests that power has remained constant over time. This is consistent with previous examinations of statistical power in social psychology (Sedlmeier & Gigerenzer, 1989).
Although the ODR decreased significantly and the EDR did not decrease significantly, bias (ODR – EDR) did not show a significant relationship with cohort, r(N = 222) = -.06, 95%CI = -19 to .07, t(220) = -0.94, p = .35, but the 95%CI allows for a slight decrease in bias that would be consistent with the significant decrease in the ODR.
In conclusion, there is a small, statistically significant decrease in the ODR, but the effect over the past 40 decades is too small to have practical significance. The EDR and bias are not even statistically significantly related to cohort. These results suggest that research practices and the use of questionable ones has not changed notably since the beginning of empirical social psychology (Cohen, 1961; Sterling, 1959).
Achievement Motivation
Another possibility is that in each generation, QRPs are used more by researches who are more achievement motivated (Janke et al., 2019). After all, the reward structure in science is based on number of publications and significant results are often needed to publish. In social psychology it is also necessary to present a package of significant results across multiple studies, which is nearly impossible without the use of QRPs (Schimmack, 2012). To examine this hypothesis, I correlated the EDR with researchers’ H-Index (as of 2/1/2021). The correlation was small, r(N = 222) = .10, 95%CI = -.03 to .23, and not significant, t(220) = 1.44, p = .15. This finding is only seemingly inconsistent with Janke et al.’s (2019) finding that self-reported QRPs were significantly correlated with self-reported ambition, r(217) = .20, p = .014. Both correlations are small and positive, suggesting that achievement motivated researchers may be slightly more likely to use QRPs. However, the evidence is by no means conclusive and the actual relationship is weak. Thus, there is no evidence to support that highly productive researchers with impressive H-indices achieved their success by using QRPs more than other researchers. Rather, they became successful in a field where QRPs are the norm. If the norms were different, they would have become successful following these other norms.
Impact
A common saying in science is that “extraordinary claims require extraordinary evidence.” Thus, we might expect stronger evidence for claims of time-reversed feelings (Bem, 2011) than for evidence that individuals from different cultures regulate their emotions differently (Matsumoto et al., 2008). However, psychologists have relied on statistical significance with alpha = .05 as a simple rule to claim discoveries. This is a problem because statistical significance is meaningless when results are selected for significance and replication failures with non-significant results remain unpublished (Sterling, 1959). Thus, psychologists have trusted an invalid criterion that does not distinguish between true and false discoveries. It is , however, possible that social psychologists used other information (e.g, gossip about replication failures at conferences) to focus on credible results and to ignore incredible ones. To examine this question, I correlated authors’ EDR with the number of citations in 2019. I used citation counts for 2019 because citation counts for 2020 are not yet final (the results will be updated with the 2020 counts). Using 2019 increases the chances of finding a significant relationship because replication failures over the past decade could have produced changes in citation rates.
The correlation between EDR and number of citations was statistically significant, r(N = 222) = .16, 95%CI = .03 to .28, t(220) = 2.39, p = .018. However, the lower limit of the 95% confidence interval is close to zero. Thus, it is possible that the real relationship is too small to matter. Moreover, the non-parametric correlation with Kendell’s tau was not significant, tau = .085, z = 1.88, p = .06. Thus, at present there is insufficient evidence to suggest that citation counts take the credibility of significant results into account. At present, p-values less than .05 are treated as equally credible no matter how they were produced.
Conclusion
There is general agreement that questionable research practices have been used to produce an unreal success rate of 90% or more in psychology journals (Sterling, 1959). However, there is less agreement about the amount of QRPs that are being used and the implications for the credibility of significant results in psychology journals (John et al., 2012; Fiedler & Schwarz, 2016). The problem is that self-reports may be biased because researchers are unable or unwilling to report the use of QRPs (Nisbett & Wilson, 1977). Thus, it is necessary to examine this question with alternative methods. The present study used a statistical method to compare the observed discovery rate with a statistically estimated discovery rate based on the distribution of significant p-values. The results showed that on average social psychologists have made extensive use of QRPs to inflate an expected discovery rate of around 35% to an observed discovery rate of 70%. Moreover, the estimated discovery rate of 35%is likely to be an inflated estimate of the discovery rate for focal hypothesis tests because the present analysis is based on focal and non-focal tests. This would explain why the actual success rate in replication studies is even lower thna the estimated discovery rate of 35% (Open Science Collaboration, 2015).
The main novel contribution of this study was to examine individual differences in the use of QRPs. While the ODR was fairly consistent across articles, the EDR varied considerably across researchers. However, this variation showed only very small relationships with a researchers’ cohort (first year of publication). This finding suggests that the use of QRPs varies more across research fields and other factors than over time. Additional analysis should explore predictors of the variation across researchers.
Another finding was that citations of authors’ work do not take credibility of p-values into account. Citations are influenced by popularity of topics and other factors and do not take the strength of evidence into account. One reason for this might be that social psychologists often publish multiple internal replications within a single article. This gives the illusion that results are robust and credible because it is very unlikely to replicate type-I errors. However, Bem’s (2011) article with 9 internal replications of time-reversed feelings showed that QRPs are also used to produce consistent results within a single article (Francis, 2012; Schimmack, 2012). Thus, number of significant results within an article or across articles is also an invalid criterion to evaluate the robustness of results.
In conclusion, social psychologists have conducted studies with low statistical power since the beginning of empirical social psychology. The main reason for this is the preference for between-subject designs that have low statistical power with small sample sizes of N = 40 participants and small to moderate effect sizes. Despite repeated warnings about the problems of selection for significance (Sterling, 1959) and the problems of small sample sizes (Cohen, 1961; Sedelmeier & Gigerenzer, 1989; Tversky & Kahneman, 1971), the practices have not changed since Festinger conducted his seminal study on dissonance with n = 20 per group. Over the past decades, social psychology journals have reported thousands of statistically significant results that are used in review articles, meta-analyses, textbooks, and popular books as evidence to support claims about human behavior. The problem is that it is unclear which of these significant results are true positives and which are false positives, especially if false positives are not just strictly nil-results, but also results with tiny effect sizes that have no practical significance. Without other reliable information, even social psychologists do not know which of their colleagues results are credible or not. Over the past decade, the inability to distinguish credible and incredible information has produced heated debates and a lack of confidence in published results. The present study shows that the general research practices of a researcher provide valuable information about credibility. For example, a p-value of .01 by a researcher with an EDR of 70 is more credible than a p-value of .01 by a researcher with an EDR of 15. Thus, rather than stereotyping social psychologists based on the low replication rate in the Open Science Collaboration project, social psychologists should be evaluated based on their own research practices.
References
Cairo, A. H., Green, J. D., Forsyth, D. R., Behler, A. M. C., & Raldiris, T. L. (2020). Gray (Literature) Matters: Evidence of Selective Hypothesis Reporting in Social Psychological Research. Personality and Social Psychology Bulletin, 46(9), 1344–1362. https://doi.org/10.1177/0146167220903896
Janke, S., Daumiller, M., & Rudert, S. C. (2019). Dark pathways to achievement in science: Researchers’ achievement goals predict engagement in questionable research practices.
Social Psychological and Personality Science, 10(6), 783–791. https://doi.org/10.1177/1948550618790227
1 thought on “The Prevalence of Questionable Research Practices in Social Psychology”