
In 1998 Baumeister and colleagues introduced a laboratory experiment to study will-power. Participants are assigned to one of two conditions. In one condition, participants have to exert will-power to work on an effortful task. The other condition is a control condition with a task that does not require will-power. After the manipulation all participants have to perform a second task that requires will-power. The main hypothesis is that participants who already used will-power on the first task will perform more poorly on the second task than participants in the control condition.
In 2010, a meta-analysis examined the results of studies that had used this paradigm (Hagger Wood, & Chatzisarantis, 2010). The meta-analysis uncovered 198 studies with a total of 10,782 participants. The overall effect size in the meta-analysis suggested strong support for the hypothesis with an average effect size of d = .62.
However, the authors of the meta-analysis did not examine the contribution of publication bias to the reported results. Carter and McCullough (2013) compared the percentage of significant results to average observed power. This test showed clear evidence that studies with significant results and inflated effect sizes were overrepresented in the meta-analysis. Carter and McCullough (2014) used meta-regression to examine bias (Stanley and Doucouliagos, 2013). This approach relies on the fact that several sources of reporting bias and publication bias produce a correlation between sampling error and effect size. When effect sizes are regressed on sampling error, the intercept provides an estimate of the unbiased effect size; that is the effect size when sampling error in the population when sampling error is zero. Stanley and Doucouliagos (2013) use two regression methods. One method uses sampling error as a predictor (PET). The other method uses the sampling error squared as a predictor (PEESE). Carter and McCullough (2013) used both methods. PET showed bias and there was no evidence for the key hypothesis. PEESE also showed evidence of bias, but suggested that the effect is present.
There are several problems with the regression-based approach as a way to correct for biases (Replication-Index, December 17, 2014). One problem is that other factors can produce a correlation between sampling error and effect sizes. In this specific case, it is possible that effect sizes vary across experimental paradigms. Hagger and Chatzisarantis (2014) use these problems to caution readers that it is premature to disregard an entire literature on ego-depletion. The R-Index can provide some additional information about the empirical foundation of ego-depletion theory.
The analyses here focus on the handgrip paradigm because this paradigm has high power to detect moderate to strong effects because these studies measured handgrip strengths before and after the manipulation of will-power. Based on published studies, it is possible to estimate the retest correlation of handgrip performance (r ~ .8). Below are some a priori power analysis with common sample sizes and Cohen’s effect sizes of small, moderate, and large effect sizes.
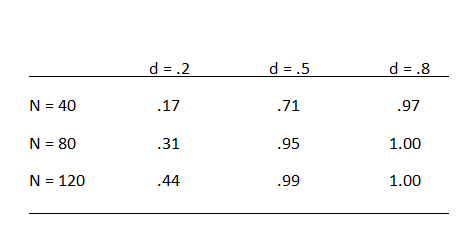
The power analysis shows that the pre-post design is very powerful to detect moderate to large effect sizes. Even with a sample size of just 40 participants (20 per condition), power is 71%. If reporting bias and publication bias exclude 30% non-significant results from the evidence, observed power is inflated to 82%. The comparison of success rate (100%) and observed power (82%) leads to an estimated inflation rate of 18%) and an R-Index is 64% (82% – 18%). Thus a moderate effect size in studies with 40 or more participants is expected to produce an R-Index greater than 64%.
However, with typical sample sizes of less than 120 participants, the expected rate of significant results is less than 50%. With N = 80 and true power of 31%, the reporting of only significant results would boost the observed power to 64%. The inflation rate would be 30% and the R-Index would be 39%. In this case, the R-Index overestimates true power by 9%. Thus, an R-Index less than 50% suggests that the true effect size is small or that the null-hypothesis is true (importantly, the null-hypothesis refers to the effect in the handgrip-paradigm, not to the validity of the broader theory that it becomes more difficult to sustain effort over time).
R-Analysis
The meta-analysis included 18 effect sizes based on handgrip studies. Two unpublished studies (Ns = 24, 37) were not included in this analysis. Seeley & Gardner (2003)’s study was excluded because it failed to use a pre-post design, which could explain the non-significant result. The meta-analysis reported two effect sizes for this study. Thus, 4 effects were excluded and the analysis below is based on the remaining 14 studies.
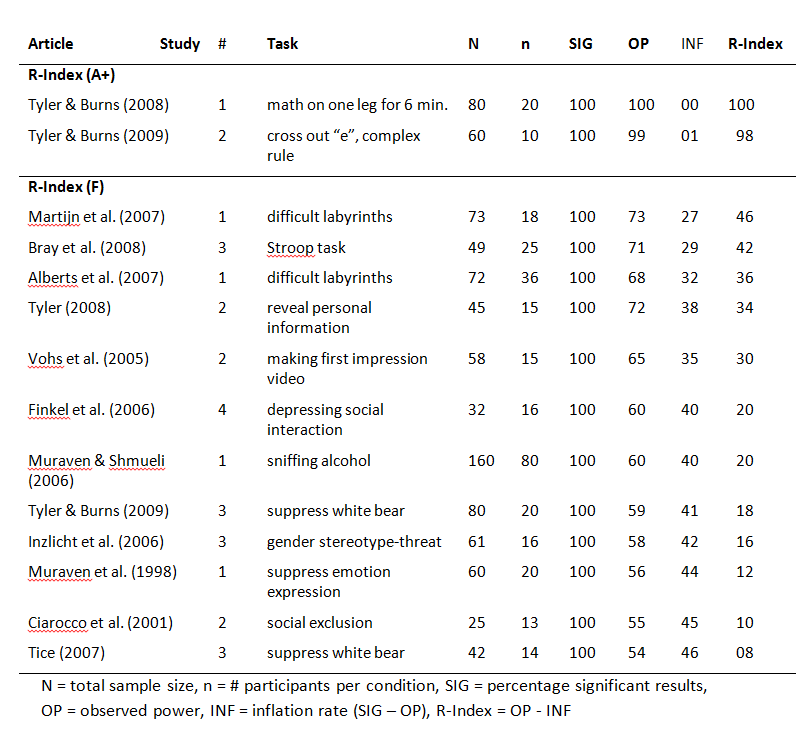
All articles presented significant effects of will-power manipulations on handgrip performance. Bray et al. (2008) reported three tests; one was deemed not significant (p = .10), one marginally significant (.06), and one was significant at p = .05 (p = .01). The results from the lowest p-value were used. As a result, the success rate was 100%.
Median observed power was 63%. The inflation rate is 37% and the R-Index is 26%. An R-Index of 22% is consistent with a scenario in which the null-hypothesis is true and all reported findings are type-I errors. Thus, the R-Index supports Carter and McCullough’s (2014) conclusion that the existing evidence does not provide empirical support for the hypothesis that will-power manipulations lower performance on a measure of will-power.
The R-Index can also be used to examine whether a subset of studies provides some evidence for the will-power hypothesis, but that this evidence is masked by the noise generated by underpowered studies with small samples. Only 7 studies had samples with more than 50 participants. The R-Index for these studies remained low (20%). Only two studies had samples with 80 or more participants. The R-Index for these studies increased to 40%, which is still insufficient to estimate an unbiased effect size.
One reason for the weak results is that several studies used weak manipulations of will-power (e.g., sniffing alcohol vs. sniffing water in the control condition). The R-Index of individual studies shows two studies with strong results (R-Index > 80). One study used a physical manipulation (standing one leg). This manipulation may lower handgrip performance, but this effect may not reflect an influence on will-power. The other study used a mentally taxing (and boring) task that is not physically taxing as well, namely crossing out “e”s. This task seems promising for a replication study.
Power analysis with an effect size of d = .2 suggests that a serious empirical test of the will-power hypothesis requires a sample size of N = 300 (150 per cell) to have 80% power in a pre-post study of will-power.
Conclusion
The R-Index of 14 will-power studies with the powerful pre-post handgrip paradigm confirms Carter and McCullough’s (2014) conclusion that a meta-analysis of will-power studies (Hagger Wood, & Chatzisarantis, 2010) provided an inflated estimate of the true effect size and that the existing studies provide no empirical support for the effect of will-power manipulations on a second effortful task. The existing studies have insufficient statistical power to distinguish a true null-effect from a small effect (d = .2). Power analysis suggest that future studies should focus on strong manipulations of will-power and use sample sizes of N = 300 participants.
Limitation
This analysis examined only a small set of studies in the meta-analysis that used handgrip performance as dependent variable. Other studies may show different results, but these studies often used a simple between-subject design with small samples. This paradigm has low power to detect even moderate effect sizes. It is therefore likely that the R-Index will also confirm Carter and McCullough’s (2014) conclusion.