With 4,366 citations in WebOfScience, Taylor and Brown’s article “ILLUSIONS AND WELL-BEING: A SOCIAL PSYCHOLOGICAL PERSPECTIVE ON MENTAL-HEALTH” is one of the most cited articles in social psychology.
The key premises of the article is that human information processing is faulty and that mistakes are not random. Rather human information processing is systematically biased.
Taylor and Brown (1988) quote Fiske and Taylor’s (1984) book about social cognitions to support this assumption. “Instead of a naïve scientist entering the environment in search of the truth, we find the rather unflattering picture of a charlatan trying to make the data come out in a manner most advantageous to his or her already-held theories” (p. 88).
30 years later, a different picture emerges. First, evidence has accumulated that human information processing is not as faulty as social psychologists assumed in the early 1980s. For example, personality psychologists have shown that self-ratings of personality have some validity (Funder, 1995). Second, it has also become apparent that social psychologists have acted like charlatans in their research articles, when they used questionable research practices to make unfounded claims about human behavior. For example, Bem (2011) used these methods to show that extrasensory perception is real. This turned out to be a false claim based on shoddy use of the scientific method.
Of course, a literature with thousands of citations also has produced a mountain of new evidence. This might suggest that Taylor and Brown’s claims have been subjected to rigorous tests. However, this is actually not the case. Most studies that examined the benefits of positive illusions relied on self-ratings of well-being, mental-health, or adjustment to demonstrate that positive illusions are beneficial. The problem is evident. When self-ratings are used to measure the predictor and the criterion, shared method variance alone is sufficient to produce a positive correlation. The vast majority of self-enhancement studies relied on this flawed method to examine the benefits of positive illusions (see meta-analysis by Dufner, Gebauer, & Sedikides, 2019).
However, there are a few attempts to demonstrate that positive illusions about the self predict well-being measures is measured by informant ratings to reduce the influence of shared method variance. The most prominent example is Taylor et al. (2003) article ” Portrait of the self-enhancer: Well adjusted and well liked or maladjusted and friendless.”
[Sadly, this was published in the Personality section of JPSP]

The abstract gives the impression that the results clearly favored Taylor’s positive illusions model. However, a closer inspection of reality shows that the abstract is itself illusory and disconnected from reality.
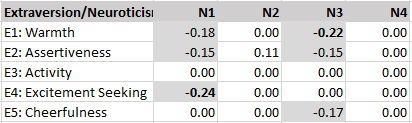
First, the study had a small sample size (N = 92). Second, only about half of these participants . Informant ratings were obtained from a single friend, but only 55 participants identified a friend who provided informant ratings. Even in 2003, it was common to use larger samples and more informants to measure well-being (e.g., Schimmack, & Diener, 2003). Moreover, friends are not as good as family members to report on well-being (Schneider & Schimmack, 2009). It only attests to Taylor’s social power that such a crappy, underpowered study was published in JPSP.
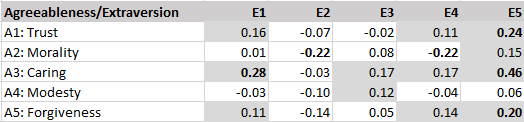
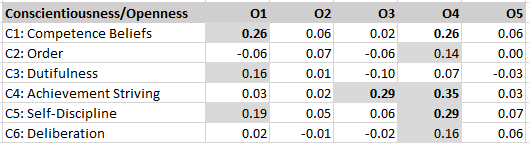
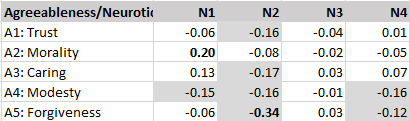
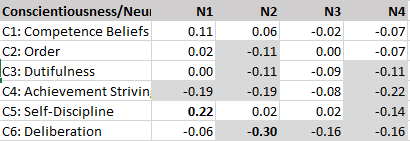
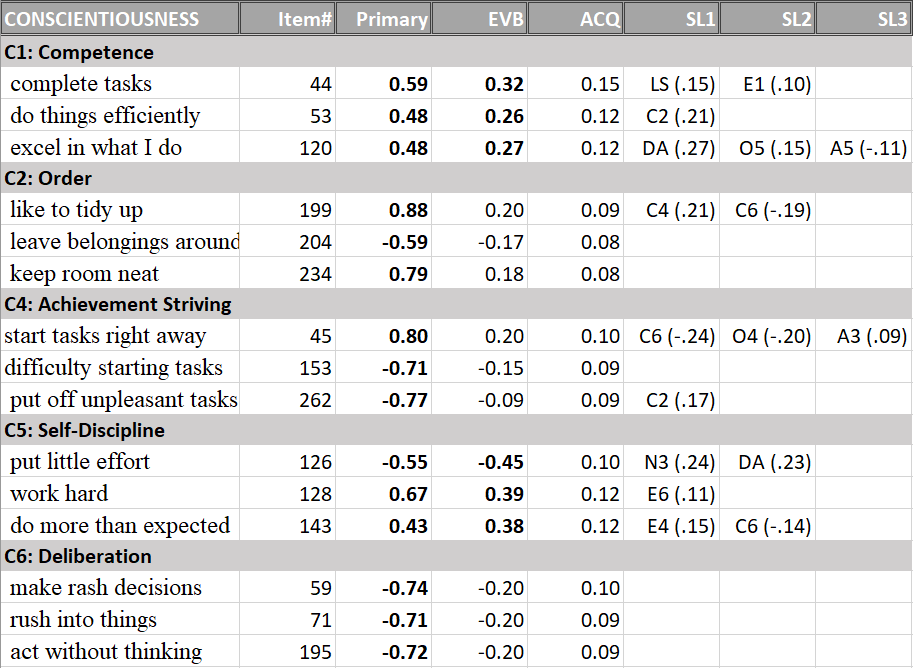
The results showed no significant correlations between various measures of positive illusions (self-enhancement) and peer-ratings of mental health (last row).
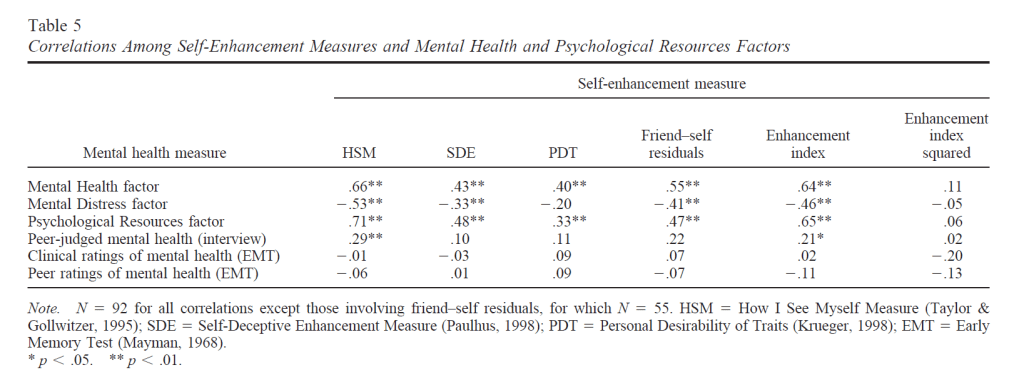
Thus, the study provided no evidence for the claim in the abstract that positive illusions about the self predict well-being or mental health without the confound of shared method variance.
Meta-Analysis
Dufner, Gebauer, Sedikides, and Denissen (2019) conducted a meta-analysis of the literature. The abstract gives the impression that there is a clear positive effect of positive illusions on well-being.

Not surprisingly, studies that used self-ratings of adjustment/well-being/mental health showed positive association. The more interesting question is how self-enhancement measures are related to non-self-report measures of well-being. Table 3 shows that the meta-analysis identified 22 studies with an informant-rating of well-being and that these studies showed a small positive relationship, r = .12.

I was surprised that the authors found 22 studies because my own literature research uncovered fewer studies. So, I took a closer look at the 22 studies included in the meta-analysis (see APPENDIX).
Many of the studies relied on measures of social desirable responding (Marlow-Crowne Social Desirability Scale, Balanced -Inventory-of-Desirable Responding) as a measure of positive illusions. The problem with these studies is that social desirability scales also contain a notable portion of real personality variance. Thus, these studies do not conclusively demonstrate that illusions are related to informant ratings of adjustment. Paulhus’s studies are problematic because adjustment ratings were based on first-impressions in a zero-acquaintance relationship, and the results changed over time. Self-enhancers were perceived as better adjusted in the beginning, but as less adjusted later on. The problem here is that well-being ratings in this context have low validity. Finally, most studies were underpowered given the estimated population effect size of r = .12. The only reasonably powered study by Church et al. with 900 participants produced a correlation of r = .17 with an unweighted measure and r = .08 with a weighted measure. Overall, this evidence does not provide clear evidence that positive illusions about the self have positive effects. They actually show that any beneficial effects would be small.
New Evidence
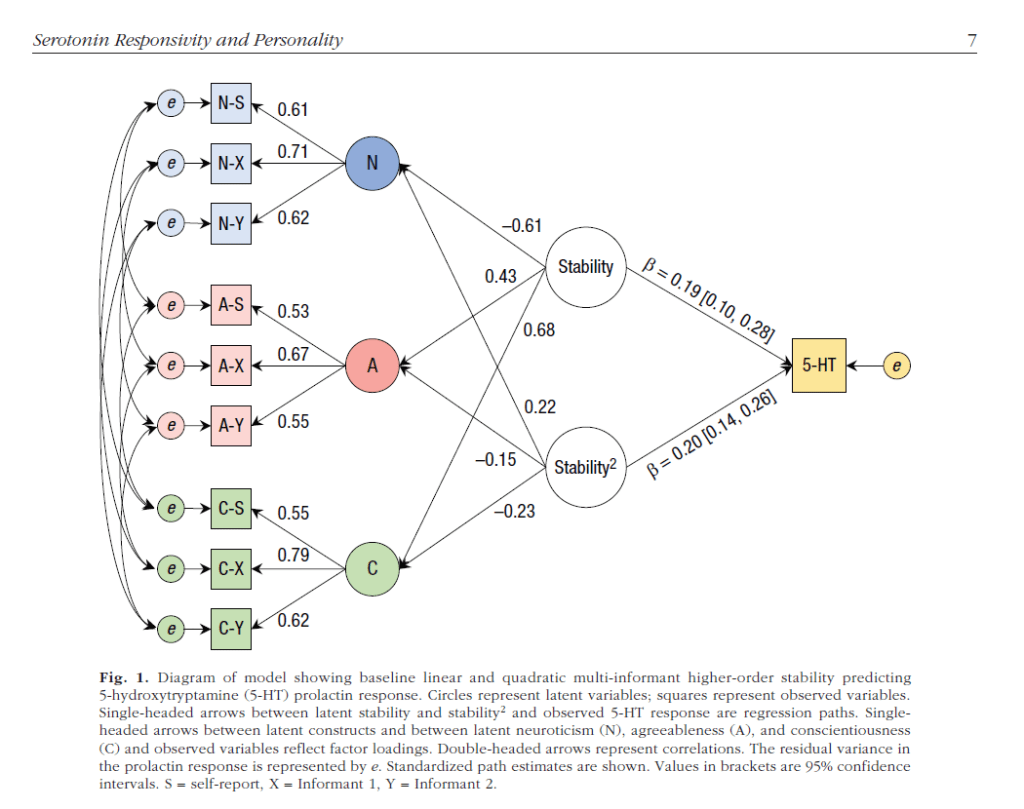
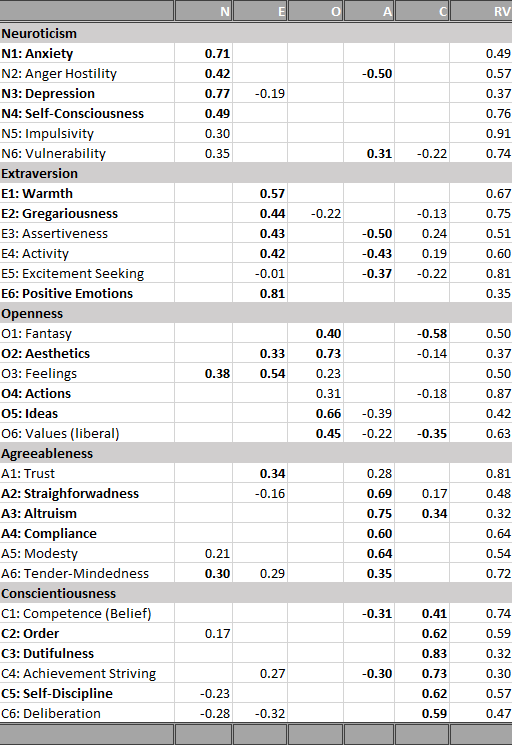
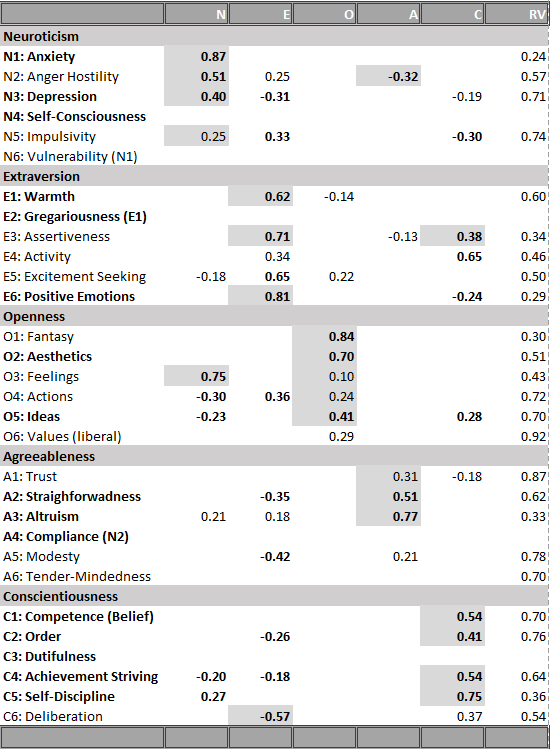
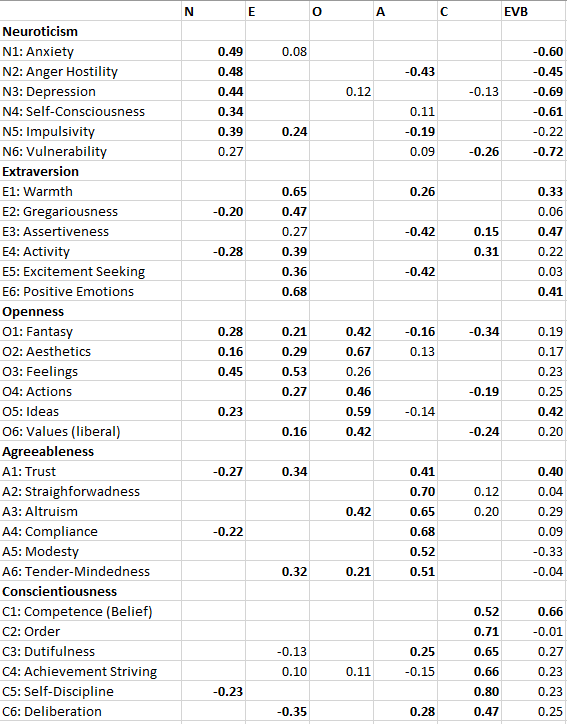
In a forthcoming JRP article, Hyunji Kim and I present the most comprehensive test of Taylor’s positive illusion hypothesis (Schimmack & Kim, 2019). We collected data from 458 triads (students with both biological parents living together). We estimated separate models for students, mothers, and fathers as targets. In each model, targets self-ratings of the Big Five personality ratings were modelled with the halo-alpha-beta model, where the halo factor represents positive illusions about the self (Anusic et al., 2009). The halo factor was then allowed to predict the shared variance in well-being ratings by all three raters, and well-being ratings were based on three indicators (global life-satisfaction, average domain satisfaction, and hedonic balance, cf. Zou, Schimmack, & Gere, 2013).
The structural equation model is shown in Figure 1. The complete data, MPLUS syntax and output files and a preprint of the article are available on OSF ( https://osf.io/6z34w/).
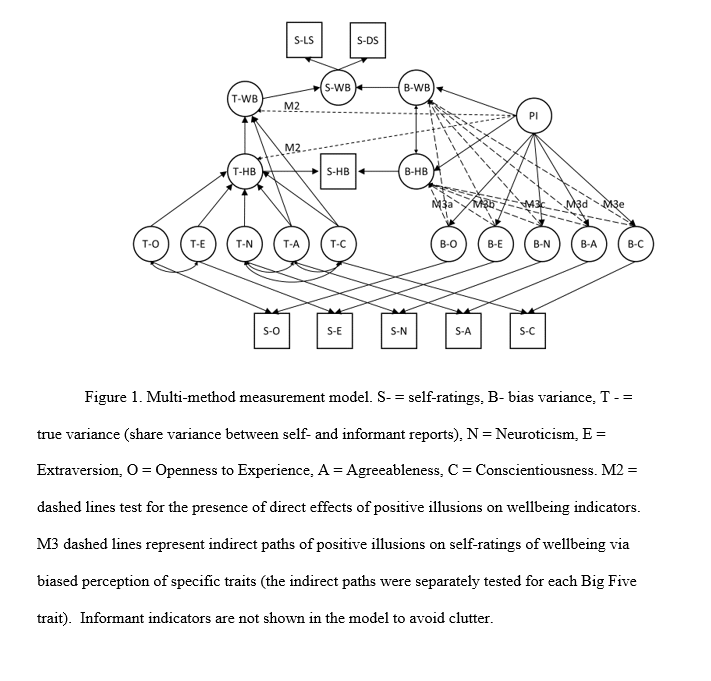
The key findings are reported in Table 6. There were no significant relationships between self-rated halo bias and the shared variance among ratings of well-being across the three raters. Although this finding does not prove that positive illusions are not beneficial, the results suggest that it is rather difficult to demonstrate these benefits even in reasonably powered studies to detect moderate effect sizes.

The study did replicate much stronger relationships with self-ratings of well-being. However, this finding begs the question whether positive illusions are beneficial only in ways that are not visible to close others or whether these relationships simply reflect shared method variance.
Conclusion
Over 30 years ago, Taylor and Brown made the controversial proposal that humans benefit from distorted perceptions of reality. Only this year, a meta-analysis claimed that there is strong evidence to support this claim. I argue that the evidence in support of the illusion model is itself illusory because it rests on studies that relate self-ratings to self-ratings. Given the pervasive influence of rating biases on self-ratings, shared method variance alone is sufficient to explain positive correlations in these studies (Campbell & Fiske, 1959). Only a few studies have attempted to address this problem by using informant ratings of well-being as an outcome measure. These studies tend to find weak relationships that are often not significant. Thus, there is currently no scientific evidence to support Taylor and Brown’s social psychological perspective on mental health. Rather, the literature on positive illusions provides further evidence that social and personality psychologists have been unable to subject the positive illusions hypothesis to a rigorous test. To make progress in the study of well-being it is important to move beyond the use of self-ratings to reduce the influence of method variance that can produce spurious correlations among self-report measures.
APPENDIX
| Article# | Title | Study | Informants | N | SR | IR | |||
| 1 | Do Chinese Self-Enhance or Self-Efface? It’s a Matter of Domain | 1 | Table 4 | helpfulness | neuroticism | 130 | 0.48 | 0.01 | |
| 2 | How self-enhancers adapt well to loss: the mediational role of loneliness and social functioning | 1 | BIDR-SD | SR symptoms (reversed) / IR mental health | 57 | 0.24 | 0.34 | ||
| 3 | Portrait of the self- enhancer:Well- adjusted and well- liked or maladjusted and friendless? | 1 | |||||||
| 4 | Social Desirability Scales: More Substance Than Style | 1 | Table 2 | MCSD | depression (reversed) | 215 | 0.49 | 0.31 | |
| 5 | Substance and bias in social desirability responding. | 1 | 2 Friends | Table 2 | SDE | neuroticism (reversed) | 67 | 0.39 | 0.26 |
| 6 | Interpersonal and intrapsychic adaptiveness of trait self-enhancement: A mixed blessing | 1a | Zero-Aquaintance | Table 2 Time 1 | Trait SE | Adjustment | 124 | NA | 0.36 |
| 6 | Interpersonal and intrapsychic adaptiveness of trait self-enhancement: A mixed blessing | 1b | Zero-Aquaintance | Table 2 Time 2 | Trait SE | Adjustment | 124 | NA | -0.11 |
| 6 | Interpersonal and intrapsychic adaptiveness of trait self-enhancement: A mixed blessing | 2 | Zero-Aquaintance | Table 4 Time 1 | Trait SE | Adjustment | 89 | NA | 0.35 |
| 6 | Interpersonal and intrapsychic adaptiveness of trait self-enhancement: A mixed blessing | 2 | Zero-Aquaintance | Table 4 Time 1 | Trait SE | Adjustment | 89 | NA | -0.22 |
| 7 | A test of the construct validity of the Five-Factor Narcissism Inventory | 1 | 1 Peer | Table 1 | FFNI Vulnerability | Neuroticism | 287 | 0.5 | 0.33 |
| 8 | Moderators of the adaptiveness of self-enhancement: Operationalization, motivational domain, adjustment facet, and evaluator | 1 | 3 Peers/Family Members | Self-Residuals | Adjustment | 123 | 0.22 | -0.2 | |
| 9 | Grandiose and Vulnerable Narcissism: A Nomological Network Analysis | 1 | NA | NA | |||||
| 10 | Socially desirable responding in personality assessment: Still more substance than style | 1a | 1 Roommate | Table 1 | MCSD | neuroticism (reversed) | 128 | 0.41 | 0.06 |
| 10 | Socially desirable responding in personality assessment: Still more substance than style | 1b | Parents | Table 1 | MCSD | neuroticism (reversed) | 128 | 0.41 | 0.09 |
| 11 | Two faces of human happiness: Explicit and implicit life-satisfaction | 1a | 1 Peer | Table 1 | BIDR-SD | PANAS | 159 | 0.45 | 0.17 |
| 11 | Two faces of human happiness: Explicit and implicit life-satisfaction | 1b | 1 Peer | Table 1 | BIDR-SD | LS | 159 | 0.36 | -0.03 |
| 12 | Socially desirable responding in personality assessment: Not necessarily faking and not necessarily substance | 1 | 1 roommate | Table 2 | BIDR-SD | neuroticism (reversed) | 602 | 0.26 | 0.02 |
| 13 | Depression and the chronic pain experience | 1 | none | MCSD | NA | NA | |||
| 14 | Trait self-enhancement as a buffer against potentially traumatic events: A prospective study | 1 | Friends | Table 5 | BIDR-SD | mental health | 32 | NA | -0.01 |
| 15 | Big Tales and Cool Heads: Academic Exaggeration Is Related to Cardiac Vagal Reactivity | 1 | 62 | NA | NA | ||||
| 16 | Are Actual and Perceived Intellectual Self-enhancers Evaluated Differently bySocial Perceivers? | 1 | 1 Friend | Table 1 / above diagonal | SE intelligence | neuroticism (reversed) | 337 | 0.17 | 0.15 |
| 16 | Are Actual and Perceived Intellectual Self-enhancers Evaluated Differently bySocial Perceivers? | 3 | Zero-Aquaintance | Table 1 / below diagonal | SE intelligence | neuroticism (reversed) | 183 | 0.19 | 0.38 |
| 17 | Response artifacts in the measurement of subjective well-being | 1 | 7 friends / family | Table 1 | MCSD | LS | 108 | 0.3 | 0.36 |
| 18 | A Four-Culture Study of Self-Enhancement and Adjustment Using the | 1a | 6 friends/ family | Table 6 SRM unweighted | SRM | LS | 900 | 0.53 | 0.17 |
| 18 | A Four-Culture Study of Self-Enhancement and Adjustment Using the | 1b | 6 friends/ family | Table 6 SRM weighted | SRM | LS | 900 | 0.49 | 0.08 |
| 19 | You Probably Think This Paper’s About You: Narcissists’ Perceptions of Their Personality and Reputation | 1 | NA | NA | |||||
| 20 | What Does the Narcissistic Personality Inventory Really Measure? | 4 | Roommates | NPI-Grandiose | College Adjustment | 200 | 0.48 | 0.27 | |
| 21 | Self-enhancement as a buffer against extreme adversity: Civil war in Bosnia and traumatic loss in the United States | 1 | Mental Health Experts | Self-Peer Dis | adjustment difficulties (reversed) | 78 | 0.47 | 0.27 | |
| 21 | Self-enhancement as a buffer against extreme adversity: Civil war in Bosnia and traumatic loss in the United States | 2 | Mental Health Experts | Table 2 25 months | BIDR-SD | self distress / MHE PTSD | 74 | 0.3 | 0.35 |
| 22 | Self-enhancement among high-exposure survivors of the September 11th terrorist attack: Resilience or social maladjustment | 1 | Friend/Family | BIDR-SD | self depression 18 months / mental health | 45 | 0.29 | 0.33 | |
| 23 | Decomposing a Sense of Superiority: The Differential Social Impact of Self-Regard and Regard for Others | 1 | Zero-Aquaintance | SRM | neuroticism (reversed) | 235 | NA | 0.02 | |
| 24 | Personality, Emotionality, and Risk Prediction | 1 | 94 | NA | NA | ||||
| 24 | Personality, Emotionality, and Risk Prediction | 2 | 119 | NA | NA | ||||
| 25 | Social desirability scales as moderator and suppressor variables | 1 | MCSD | 300 | NA | NA |