Psychological science has a replication crisis. Many textbook findings, especially in social psychology, failed to replicate over the past years. The reason for these surprising replication failures is that psychologists have used questionable research practices to produce results that confirm theories rather than using statistical methods to test theories and to let theories fail if the evidence does not support them. However, falsification of theories is a sign of scientific progress and it is time to subject psychological theories to real tests.
In personality psychology, the biggest theory is Big Five theory. In short, Big Five theory postulates that variation in personality across individuals can be described with five broad personality dimensions: neuroticism, extraversion, openness, agreeableness, and conscientiousness. Textbooks also claim that the Big Five are fairly universal and can be demonstrated in different countries and with different languages.
One limitation of these studies is that they often use vague criteria to claim that the Big Five have been found or that personality traits are universal. Psychometricians have developed rigorous statistical methods to test these claims, but these methods are rarely used by personality psychologists to test Big Five theory. Some personality psychologists even claimed that these methods should not be used to test Big Five theory because they fail to support the Big Five (McCrae et al., 1996). I have argued that it is time to test Big Five theory with rigorous methods and to let the data decide whether the Big Five exist or not. Other personality psychologists have also started to subject Big Five theory to more rigorous tests (Soto & John, 2017).
Big Five Theory
Big Five theory does not postulate that there are only five dimensions of personality. Rather, it starts with the observation that many important personality traits have been identified and labeled in everyday life. There are hundreds of words that describe individual differences such as helpful, organized, friendly, anxious, curious, or thoughtful. Big Five theory postulates that these personality traits are systematically related to each other. That is, organized individuals are also more likely to be thoughtful and anxious individuals are also more likely to be irritable and sad. Big Five theory explains these correlations among personality traits with five independent factors; that is some broad personality trait that causes covariations among more specific traits that are often called facets. For example, a general disposition to experience more intense unpleasant feelings may produce correlations among the disposition to experience more anxiety, anger, and sadness.
The main prediction of Big Five theory is that the pattern of correlations among personality traits should be similar across different samples and measurement instruments, and that factor analysis produces the same pattern of correlations.
Testing Big Five Theory
A proper psychometric test of Big Five theory requires a measurement model of the facets. If facets are not measured properly, it is impossible to examine the pattern of correlations among the facets. Thus, a proper test of Big Five theory requires fitting a hierarchical model to personality ratings. The first level of the hierarchy specifies a fairly large number of facets that are supposed to be related to one or more Big Five dimensions. The second level of the hierarchy specifies the Big Five factors so that it is possible to examine the relationships (factor loadings) of the facets on the Big Five factors. At present, very few studies have tried to test Big Five theory with hierarchical models. Soto and John (2017) tested Big Five theory with three facets for each Big Five domain and found reasonably good fit for their hierarchical models (see Figure for their model).

Although Soto and Johns’s (2017) article is a step in the right direction, it does not provide a thorough test of Big Five theory for several reasons. First, the model allows facets to correlate freely rather than testing the prediction that these correlations are produced by a Big Five factor. Second, models with only three indicators have zero degrees of freedom and produce perfect fit to the data. Thus, more than three facets are needed to test the prediction that Big Five factors account for the pattern of correlations among facets. Third, the model was fitted separately for each Big Five domain. Thus, there is no information about the relationship of facets to other Big Five factors. For example, the anger facet of neuroticism tends to show negative loadings on agreeableness. Whether such relationships are consistent across datasets is also important to examine.
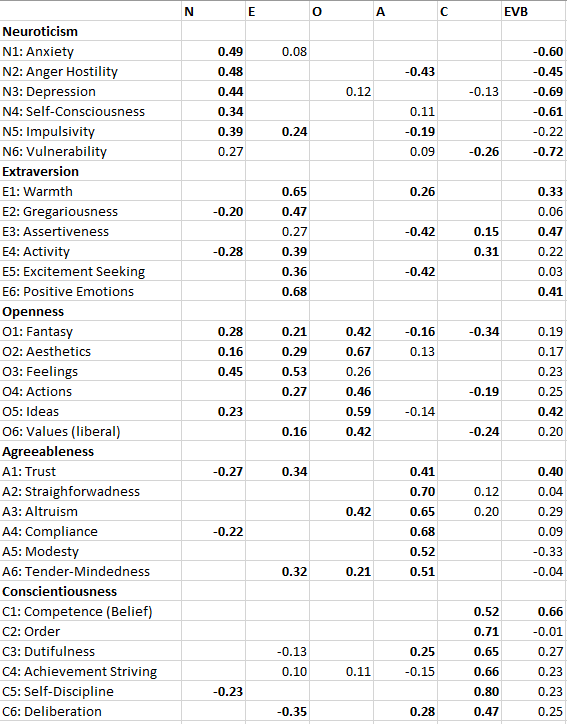
In a recent blog post, I presented I tried to fit a Big Five model to the 30 facets of the NEO-PI-R (Schimmack, 2019a). Table 1 shows the factor loadings of the 30 facets on the Big Five factors.
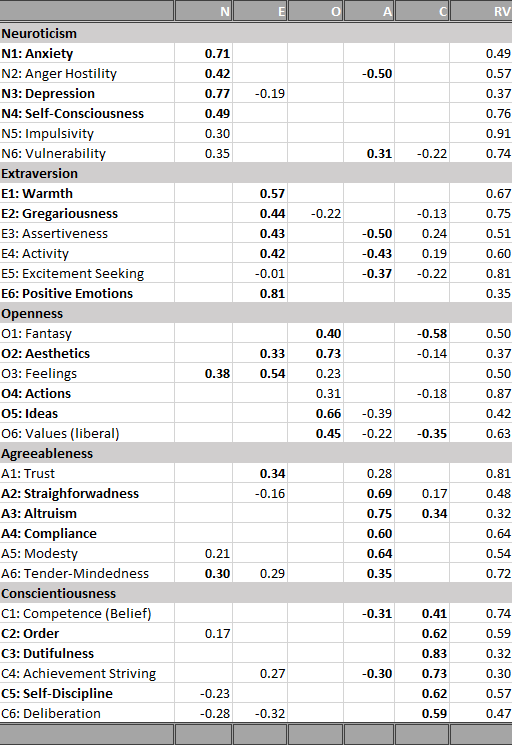
The results were broadly consistent with the theoretical Big Five structure. However, some facets did not show the predicted pattern. For example, excitement seeking did not load on extraversion. Other facets had rather weak loadings. For example, the loading of Impulsivity on neuroticism implies that less than 10% of the variance in impulsivity is explained by neuroticism. These results do not falsify Big Five theory by any means. However, they provide the basis for further theory development and refinement of personality theory. However, before any revisions of Big Five theory are made, it is important to examine the replicability of the factor structure in hierarchical measurement models.
Replication Study
Data
From 2010 to 2012 I posted a personality questionnaire with 303 items on the web. Visitors were provided with feedback about their personality on the Big Five dimensions and the 30 facets. In addition to the items that were used to provide feedback, the questionnaire contained several additional items that might help to improve measurement of facets. Furthermore, the questionnaire included some items about life-satisfaction because I have an interest in the relationship between personality traits and life-satisfaction. The questionnaire also included four questions about desirable attributes, namely attractiveness, intelligence, fitness, and broad knowledge. These questions have been used before to demonstrate evaluative biases in personality ratings (Anusic et al., 2009).
The covariance matrix for all 303 items is posted on OSF (web303.N808.cov.dat).
Models
Simple correlations and factor analysis were used to identify three indicators of the 30 NEO-facets. Good indicators should show moderate and similar correlations to each other. During this stage it became apparent that the item-set failed to capture the self-consciousness facet of neuroticism and the dutifulness facet of conscientiousness. Thus, these two facets could not be included in the model.
I first fitted a model that allowed the 28 facets to be correlated freely. This model evaluates the measurement of the 28 facets and provides information about the pattern of correlations among facets that Big Five theory aims to explain. This model showed very high correlations between the neuoroticism-facet anger and the agreeableness-facet compliance (r = .8), the warmth and gregariousness facets of extraversion (r = 1) , and the anxiety and vulnerability facets of neuroticism (r = .8). These correlations raise concerns about the discriminant validity of these facets and create problems in fitting a hierarchical model to the data. Thus, I dropped the vulnerability, gregariousness, and compliance items and facets from the model. Thus, the final model had 83 items, 26 facets, and factors for life-satisfaction and for desirable attributes.
The model fit for the model with correlated factors was accepted considering the RMSEA fit index, but below standard criteria for the CFI. However, examination of the modification indices showed that only freeing weak secondary loadings would further improve model fit. Thus, the model was considered adequate and model fit of this model served as a comparison standard for the hierarchical model, CFI = .867, RMSEA = .037.
The hierarchical model specified the Big Five as independent factors. In addition, it included an acquiescence factor and an evaluative bias factor. The evaluative bias factor was allowed to correlate with the desirable attribute factor (cf. Anusic et al., 2009). Life-satisfaction was regressed on the facets, but only significant facets were retained in the final model. Model fit of this model was comparable to model fit of the baseline model, CFI = .861, RMSEA = .040.
The complete syntax and results can be found on OSF (https://osf.io/23k8v/).
Results
Measurement Model
The first set of tables shows the item loadings on the primary factor, the evaluative bias factor, the acquiescence factor, and secondary loadings. Facet names are based on the NEO-PI-R.
Primary loadings of neuroticism items on their facets are generally high and secondary loadings are small (Table 1). Thus, the four neuroticism facets were clearly identified.
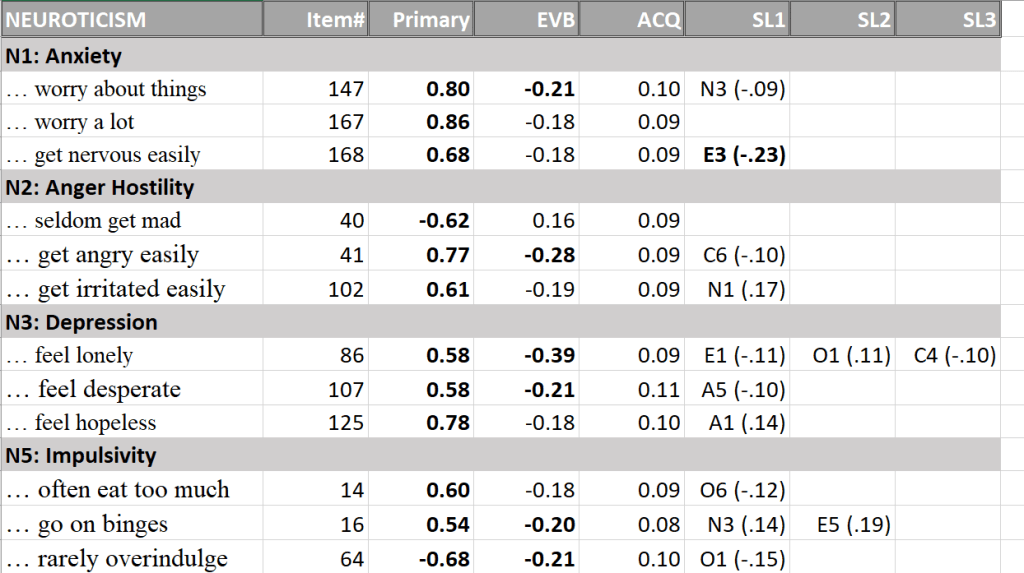
The measurement model for the extraversion facets also showed high primary loadings (Table 2).
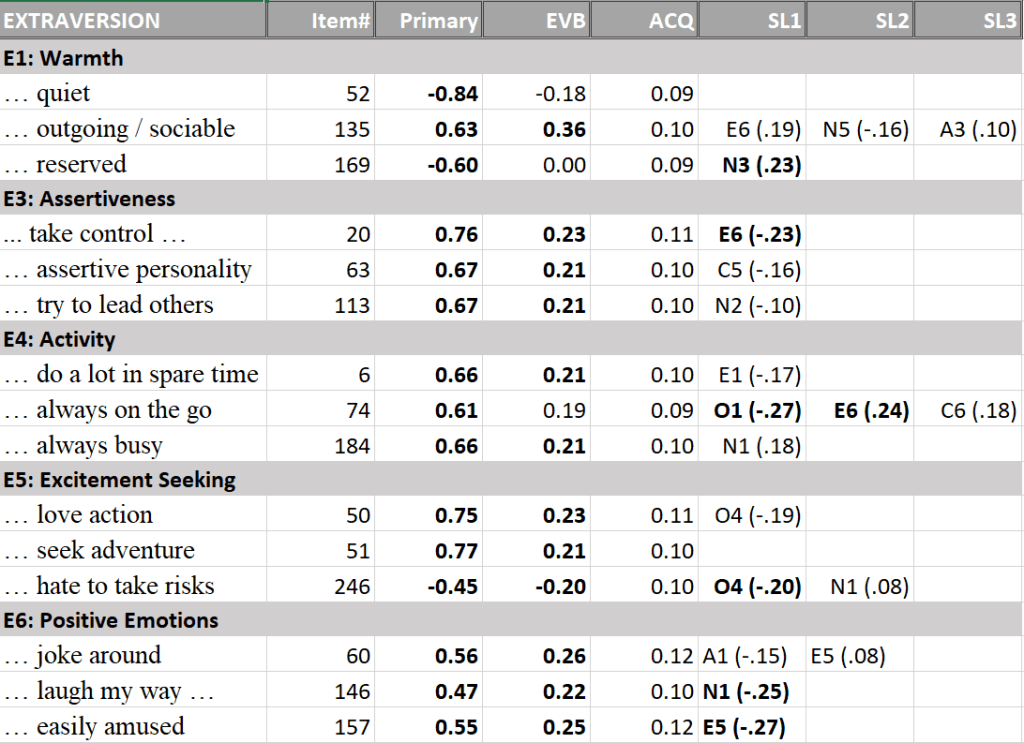
For openness, one item of the values facet had a low loading, but the other two items clearly identified the facet (Table 3).

All primary loadings for the four agreeableness facets were above .4 and the facets were clearly identified (Table 4).

Finally, the conscientiousness facets were also clearly identified (Table 5).
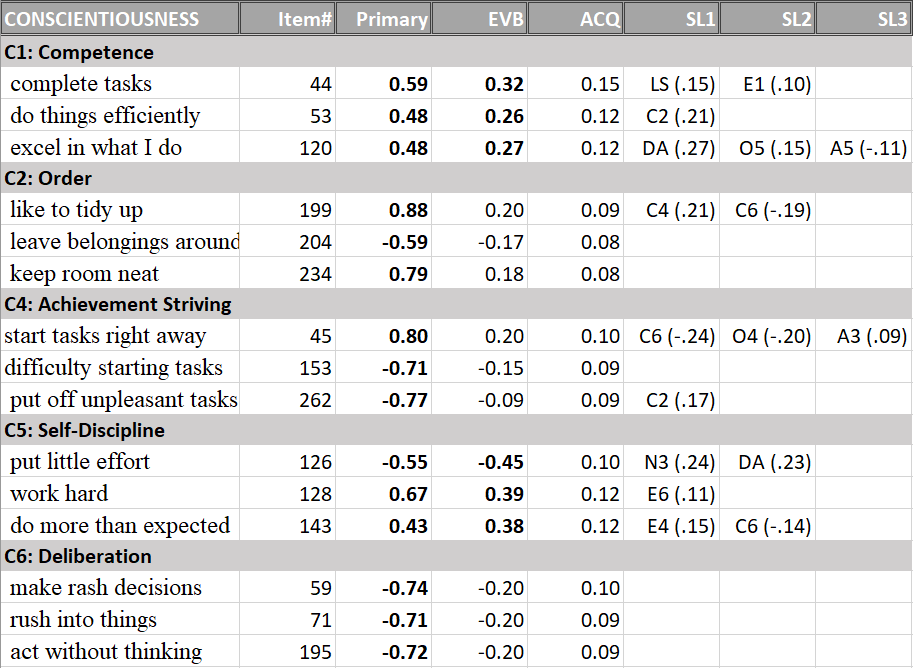
In conclusion, the measurement model for the 24 facets showed that all facets were measured well and that the item content matches the facet labels. Thus, the basic requirement for examining the structural relationships among facets have been met.
Structural Model
The most important result are the loadings of the 24 facets on the Big Five factors. These results are shown in Table 6. To ease interpretation, primary loadings greater than .4 and secondary loadings greater than .2 are printed in bold. Results that are consistent with the previous study of the NEO-PI-R are highlighted with a gray background.
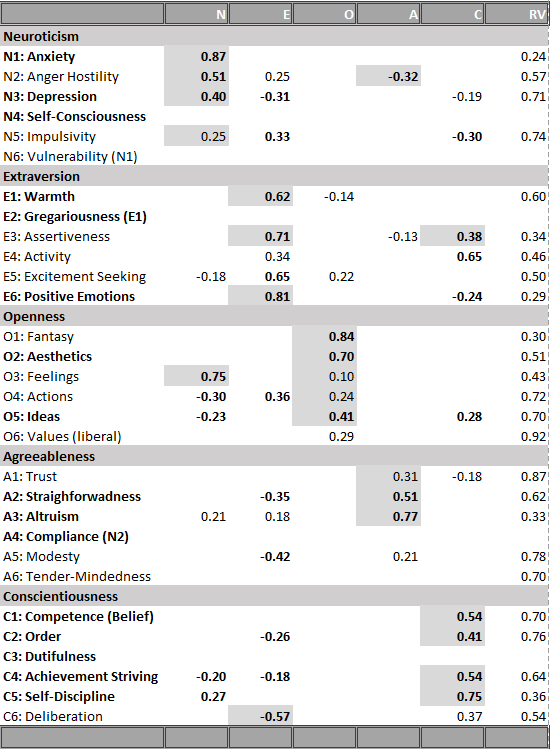
15 of the 24 primary loadings are above .4 and replicate results with the NEO-PI-R. This finding provides support for the Big Five model.
There are also four consistent loadings below .4, namely for the impulsivity facet of neuroticism, the openness facets feelings and actions, and the agreeableness facet of trust. This finding suggests that the model needs to be revised. Either there are measurement problems or openness is not related to emotions and actions. Problems with agreeableness have led to the creation of an alternative model with six factors (Ashton & Lee) that distinguishes two aspects of agreeableness.
There are eight facets with inconsistent loading patterns. Activity loaded with .34 on extraversion. More problematic was the high secondary loading on conscientiousness, suggesting that activity level is not clearly related to a single Big Five trait. The results for excitement seeking were particularly different. Excitement seeking did not load at all on extraversion in the NEO-PI-R model, but the loading in this sample was high.
The loading for values on openness was .45 for the NEO-PI-R and .29 in this sample. Thus, the results are more consistent than the use of the arbitrary .4 value suggests. Values are related to openness, but the relationship is weak and openness explains no more than 20% of the variance in holding liberal versus conservative values.
For agreeableness, compliance was represented by the anger facet of neuroticism, which did not load above .4 on agreeableness although the loading came close (-.32). Thus, the results do not require a revision of the model based on the present data. The biggest problem was that the modesty facet did not load highly on the agreeableness facet (.21). More research is needed to examine the relationship between modesty and agreeableness.
Results for conscientiousness were fairly consistent with theory and the loading of the deliberation facet on conscientiousness was just shy of the arbitrary .4 criterion (.37). Thus, no revision to the model is needed at this point.
The consistent results provide some robust markers of the Big Five, that is facets with high primary and low secondary loadings. Neuroticism is most clearly related to high anxiety and high vulnerability (sensitivity to stress), which could not be distinguished in the present dataset. However, other negative emotions like anger and depression are also consistently related to neuroticism. This suggests that neuroticism is a general disposition to experience more unpleasant emotions. Based on structural models of affective experiences, this dimension is related to Negative Activation and tense arousal.
Extraversion is consistently related to warmth and gregariousness, which could not be separated in the present dataset as well as assertiveness and positive emotions. One interpretation of this finding is that extraversion reflects positive activation or energetic arousal, which is a distinct affective system that has been linked to approach motivation. Structural analyses of affect also show that tense arousal and energetic arousal are two separate dimensions. The inconsistent results for action may reflect the fact that activity levels can also be influenced by more effortful forms of engagement that are related to conscientiousness. Extraverted activity might be more intrinsically motivated by positive emotions, whereas conscientious activity is more driven by extrinsic motivation.
The core facets of openness are fantasy/imagination, artistic interests, and intellectual engagement. The common feature of these facets is that attention is directed. The mind is traveling rather than being focused on the immediate situation. A better way to capture openness to feelings might be to distinguish feelings that arise from actual events versus emotions that are elicited by imagined events or art.
The core features of agreeableness are straighforwardness, altruism, and tender-mindedness, which could not be separated from altruism in this dataset. The common feature is a concern about the well-being of others versus a focus on the self. Trust may not load highly on agreeableness because the focus of trust is individuals own well-being. Trusting others may be beneficial for the self if others are trustworthy or harmful if they are not. However, it is not necessary to trust somebody in need to help them unless helping is risky.
The core feature of conscientiousness is self-discipline. Order and achievement striving (which is not the best label for this facet) also imply that conscientious people can stay focused on things that need to be done and are not easily distracted. Conscientious people are more likely to follow a set of rules.
There are only a few consistent secondary loadings. This suggest that many secondary loadings may be artifacts of item-selection or participant selection. The few consistent secondary loadings make theoretical sense. Anger loads negatively on agreeableness and this facet is probably best considered a blend of high neuroticism and low agreeableness.
Assertiveness shows a positive loading on conscientiousness. The reason is that conscientious people may have a strong motivation to follow their internal norms (a moral compass) and that they are wiling to assert these norms if necessary.
The openness to feelings facet has a strong “secondary” loading on neuroticism, suggesting that this facet does not measure what it was intended to measure. It just seems to be another measure of strong feelings without specifying the valence.
Finally, deliberation is negatively related to extraversion. This finding is consistent with the speculation that extraversion is related to approach motivation. Extraverts are more likely to give in to temptations, whereas conscientious individuals are more likely to resist temptations. In this context, the results for impulsivity are also noteworthy. At least in this dataset, implusive behaviors that were mostly related to eating were more strongly related to extraversion than to neuroticism. If neuroticism is strongly related to anxiety and avoidance behavior, it is not clear why neurotic individuals would be more impulsive. However, if extraversion reflects approach motivation, it makes more sense that extraverts are more likely to indulge.
Of course, these interpretations of the results are mere speculations. In fact, it is not even clear that the Big Five account for the correlations among facets. Some researchers have proposed that facets may directly influence each other. While this is possible, such models will have to explain the consistent pattern of correlations among facets. The present results are at least consistent with the idea that five broader dispositions explain some of these correlations.
Neuroticism is a broad disposition to experience a range of unpleasant emotions, not just anxiety.
Extraversion is a broad disposition to be actively and positively engaged.
Openness is a broad disposition to focus on internal processes (thoughts and feelings) rather than on external events and doing things.
Agreeableness is a broad disposition to be concerned with the well-being of others as opposed to being only concerned with oneself.
Conscientiousness is a broad disposition to be guided by norms and rules as opposed to being guided by momentary events or impulses.
While these broad dispositions account for some of the variance in specific personality traits, facets, facets add additional information that is not captured by the Big Five. The last column in Table 1 shows the residual (i.e., unexplained) variances in the facets. While the amount of unepxlained variance varies considerable across facets, the average is high (57%) and this estimate is consistent with the estimate in the NEO-PI-R (58%). Thus, the Big Five provide only a very broad and unclear impression of individuals’ personality.
Residual Correlations among Facets
Traditional factor analysis does not allow for correlations among the residual variances of indicators. CFA models that do not include these correlations have poor fit. I was only able to produce reasonable fit to the NEO-PI-R data by including correlated residuals in the model. This was also the case for this dataset. Table 7 shows the residual correlations. For the ease of interpretation, residual correlations that were consistent across models are highlighted in green.
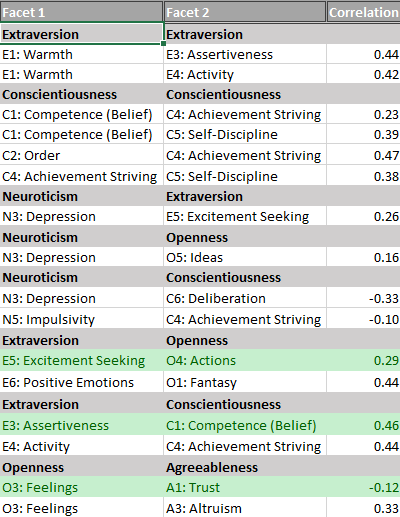
As can be seen, most of the residual correlations were inconsistent across datasets. This shows that the structure of facet correlations is not stable across these two datasets. This complicates the search for a structural model of personality because it will be necessary to uncover moderators of these inconsistencies.
Life Satisfaction
While dozens of articles have correlated Big Five measures with life-satisfaction scales, few studies have examined how facets are related to life-satisfaction (Schimmack, Oishi, Furr & Funder, 2004). The most consistent finding has been that the depression facet explains unique variance above and beyond neuroticism. This was also the case in this dataset. Depression was by far the strongest predictor of life-satisfaction (-.56). The only additional significant predictor that was added to the model was the competence facet (.22). Contrary to previous studies, the cheerfulness facet did not predict unique variance in life-satisfaction judgments. More research at the facet level and with other specific personality traits below the Big Five is needed. However, the present results confirm that facets contain unique information that contributes to the prediction of outcome variables. This is not surprising given the large amount of unexplained variance in facets.
Desirable Attributes
Table 8 shows the loadings of the four desirable attributes on the DA factor. Loadings are similar to those in Anusic et al. (2009). As objective correlations among these characteristics are close to zero, the shared variance can be interpreted as an evaluative bias. Items did not load on the evaluative bias factor to examine the relationship with the evaluative bias factor at the factor level.

Unexpectedly, the DA factor correlated only modestly with the evaluative bias factor for the facet-items, r = .38. This correlation is notably weaker than the correlation reported by Anusic et al. (2009), r = .76. This raises some questions about the nature of the evaluative bias variance. It is unfortunate that we do not know more about this persistent variance in personality ratings, one-hundred years after Thorndike (1920) first reported it.
Conclusion
In an attempt to replicate a hierarchical model of personality, I was only partially successful to cross-validate the original model. On the positive side, 15 out of 24 distinct facets had loadings on the predicted Big Five factor. This supports the Big Five as a broad model of personality. However, I also replicated some results that question the relationship between some facets and Big Five factors. For example, impulsiveness does not seem to be a facet of neuroticism and openness to actions may not be a facet of openness. Moreover, there were many inconsistent results that suggest the structure of personality is not as robust as one might expect. More research is needed to identify moderators of facet correlations. For example, in student samples anxiety may be a positive predictor of achievement striving, whereas it may be unrelated or negatively related to achievement striving in middle or old age.
Past research with exploratory methods has also ignored that the Big Five do not explain all of the correlations among facets. However, these correlations also seem to vary across samples.
All of these results do not make for neat and sexy JPSP article that proposes a simple model of personality structure, but the present results do suggest that one should not trust such simple models because personality structure is much more complex and unstable than these models suggest.
I can only repeat that personality research will only make progress by using proper methods that can actually test and falsify structural models. Falsification of simple and false models is the impetus for theory development. Thus, for the sake of progress, I declare that the Big Five model that has been underpinning personality research for 40 needs to be revised. Most importantly, progress can only be made if personality measures do not already assume that the Big Five are valid. Measures like the BFI-2 (Soto & John) or the NEO-PI-R have the advantage that they capture a wide range of personality differences at the facet level. Surely there are more than 15, 24, or 30 facets. So more research about personality at the facet level is required. Personality research might also benefit from a systematic model that integrates the diverse range of personality measures that have been developed for specific research questions from attachment styles to machiavellianism. All of this research would benefit from the use of structural equation modeling because SEM can fit a diverse range of models and provides information of model fit.