
Most psychologists have at least a vague understanding of the scientific method. Somewhere they probably heard about Popper and the idea that empirical data can be used to test theories. As all theories are false, these tests should at some point lead to an empirical outcome that is inconsistent with a theory. This outcome is not a failure. It is an expected outcome of good science. It also does not mean that the theory was bad. Rather it was a temporary theory that is now modified or replaced by a better theory. And so, science makes progress….
However, psychologists do not use the scientific method popperly. Null-hypothesis significance testing adds some confusion here. After all, psychologists publish over 90% successful rejections of the nil-hypothesis. Doesn’t that show they are good Popperians? The answer is no because the nil-hypothesis is not predicted by a theory. The nil-hypothesis is only useful to reject it to claim that there is a predicted relationship between two variables. Thus, psychology journals are filled with over 90% reports of findings that confirm theoretical predictions. While this may look like a major success, it actually shows a major problems. Psychologists never publish results that disconfirm a theoretical prediction. As a result, there is never a need to develop better theories. Thus, a root evil that prevents psychology from being a real science is verificationism.
The need to provide evidence for, rather than against, a theory led to the use of questionable research practices. Questionable research practices are used to report results that confirm theoretical predictions. For example, researchers may simply not report results of studies that did not reject the nil-hypothesis. Other practices can help to produce significant results by inflating the risk of a false positive result. The use of QRPs explains why psychology journals have been publishing over 90% results that confirm theoretical predictions for 60 years (Sterling, 1959). Only recently, it has become more acceptable to report studies that failed to support a theoretical prediction and question the validity of a theory. However, these studies are still a small minority. Thus, psychological science suffers from confirmation bias.
Structural Equation Modelling
Multivariate, correlational studies are different from univariate experiments. In a univariate experiment, a result is either significant or not. Thus, only tempering with the evidence can produce confirmation bias. In multivariate statistics, data are analyzed with complex statistical tools that provide researchers with flexibility in their data analysis. Thus, it is not necessary to alter the data to produce confirmatory results. Sometimes it is sufficient to analyze the data in a way that confirm a theoretical prediction without showing that alternative models fit the data equally well or better.
It is also easier to combat confirmation bias in multivariate research by fitting alternative models to the same data. Model comparison also avoids the problem of significance testing, where non-significant results are considered inconclusive, while significant results are used to confirm and cement a theory. In SEM, statistical inferences work the other way around. A model with good fit (non-significant chi-square or acceptable fit) is a possible model that can explain the data, while a model with significant deviation from the data is rejected. The reason is that the significance test (or model fit) is used to test an actual theoretical model rather than the nil-hypothesis. This forces researchers to specify an actual set of predictions and subject them to an empirical test. Thus, SEM is ideally suited to test theories popperly.
Confirmation Bias in SEM Research
Although SEM is ideally suited to test competing theories against each other, psychology journals are not used to model comparisons and tend to publish SEM research in the same flawed confirmatory way as other research is conducted and reported. For example, an article in Psychological Science this year published an investigation of the structure of personality and the hypothesis that several personality traits are linked to a bio-marker (Wright et al., 2019).
Their preferred model assumes that the Big Five traits neuroticism, agreeableness, and conscientiousness are not independent, but systematically linked by a higher-order triat called alpha or stability (Digman, 1997; DeYoung, 2007). In their model, the stability factor is linked to a marker of the serotonin (5-HT) prolactin response. This model implies that all three traits are related to the biomarker as there are indirect paths from all three traits to the biomarker that are “mediated” by the stability factor (for technical reasons the path goes from stabilty to the biomarker, but theoretically, we would expect the relationship to go the other way from a neurological mechanism to behaviour).
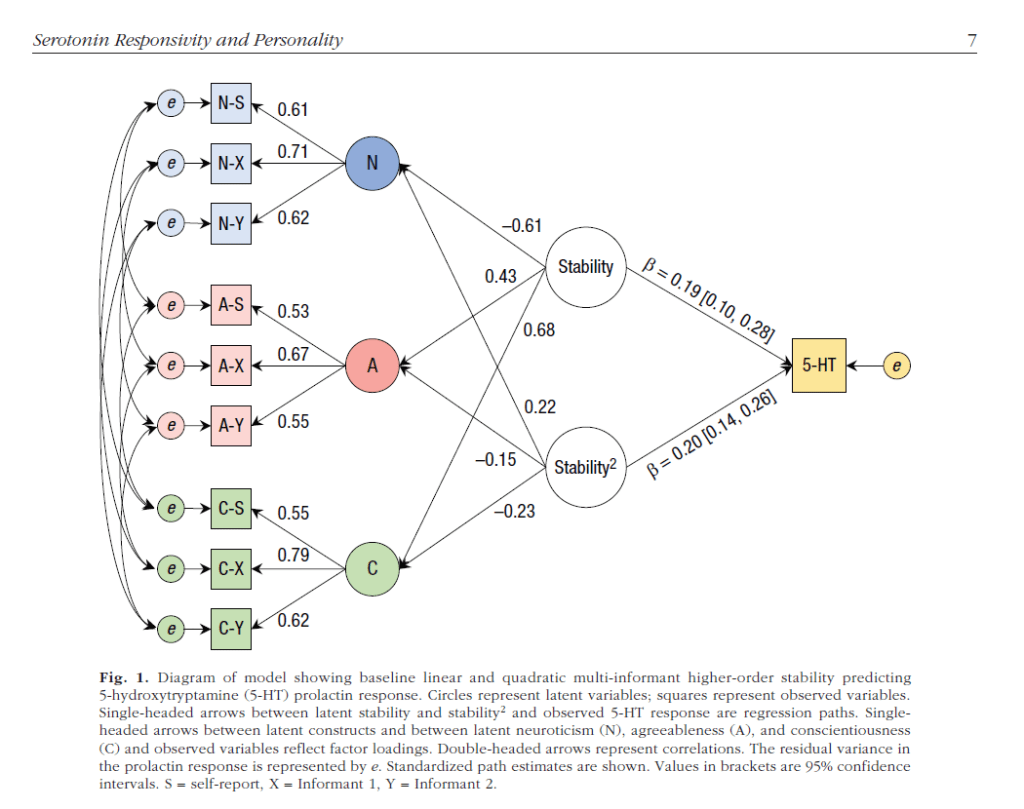
Thanks to the new world of open science, the authors shared actual MPLUS outputs of their models on OSF ( https://osf.io/h5nbu/ ). All the outputs also included the covariance matrix among the predictor variables, which made it possible to fit alternative models to the data.
Alternative Models
Another source of confirmation bias in psychology is that literature reviews fail to mention evidence that contradicts the theory that authors try to confirm. This is pervasive and by no means a specific criticism of the authors. Contrary to the claims in the article, the existence of a meta-trait of stability is actually controversial. Digman (1997) reported some SEM results that were false and could not be reproduced (cf. Anusic et al., 2009). Moreover, alpha could not be identified when the Big Five were modelled as latent factors (Anusic et al., 2009). This led me to propose that meta-traits may be an artifact of using impure Big Five scales as indicators of the Big Five. For example, if some agreeableness items have negative secondary loadings on neuroticism, the agreeableness scale is contaminated with valid variance in neuroticism. Thus, we would observe a negative correlation between neuroticism and agreeableness even across raters (e.g., self-ratings of neuroticism and informant ratings of agreeableness). Here I fitted a model with secondary loadings and independent Big Five factors to the data. I also examined the prediction that the biomarker is related to all three Big Five traits. The alternative model had acceptable fit, CFI = .976, RMSEA = .056.
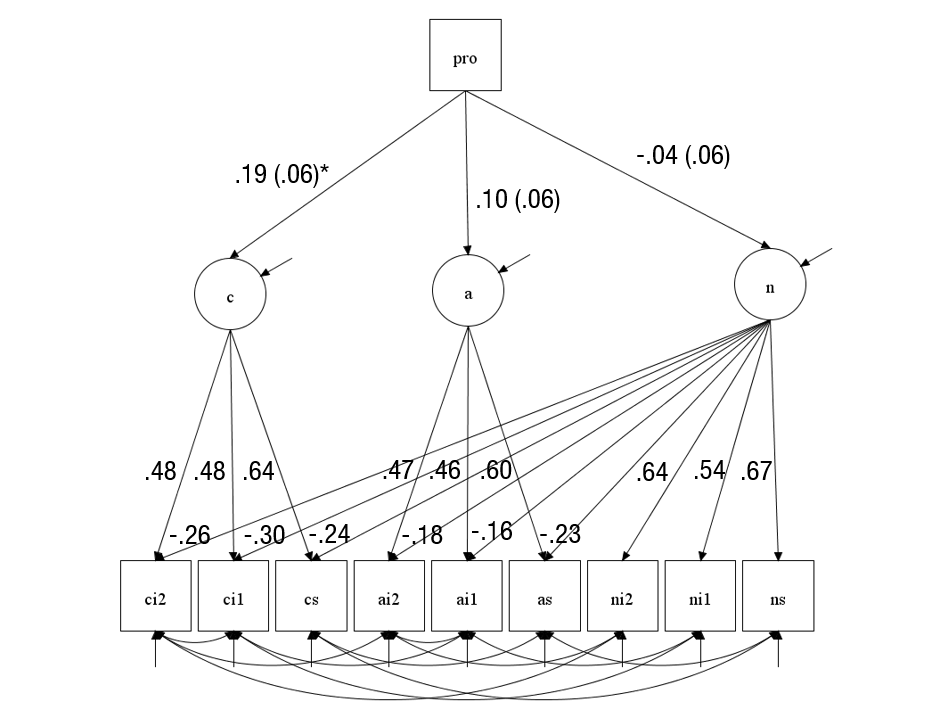
The main finding of this model is that the biomarker shows only a significant relationship with conscientiousness, while the relationship with agreeableness trended in the right direction, but was not significant (p = .089) and the relationship for neuroticism was even weaker (p = .474). Aside from the question about significance, we also have to take effect sizes into account. Given the parameter estimates, the bimarker would produce very small correlations among the Big Five traits (e.g., r(A,C) = .19 * .10 = .019. Thus, even if these relationships were significant, they would not provide compelling evidence that a source of shared variance among the three traits has been identified.
The next model shows that the authors’s model ignored the stronger relationship between conscientiousness and the biomarker. When this relationship is added to the model, there is no significant relationship between the stability factor and the biomarker.

Thus, the main original finding of this study was that a serotonin related bio-marker was significantly related to conscientiousness, but not significantly related to neuroticism. This finding is inconsistent with theories that link neuroticism to serotonin, and evidence that serotonin reuptake inhibitors reduce neuroticism (at least in depressed patients). However, such results are difficult to publish because a single study with a non-significant results does not provide sufficient evidence to falsify a theory. However, fitting data to a theory only leads to confirmation bias.
The good news is that the authors were able to publish the results of an impressive study and that their data are openly available and can provide credible information for meta-analytic evaluations of structural models of personality, while the results of this study alone are inconclusive and compatible with many different theories of personality.
One way to take more advantage of these data would be to share the covariance matrix of items to model personality structure with a proper measurement model of the Big Five traits and to avoid the problem of contaminated scale scores, which is the best practice for the use of structural equation models. These models provide no evidence for Digman’s meta-traits (Schimmack, 2019a, Schimmack, 2019b).
In conclusion, the main point of this post is that (a) SEM can be used to test and falsify models, (b) SEM can be used to realize that data are consistent with multiple models and that better data are needed to find the better model, (c) studies of Big Five factors require a measurement model with Big Five factors and cannot rely on messy scale scores as indicators of the Big Five, and (d) personality psychologists need better training in the use of SEM.
1 thought on “Confirmation Bias is Everywhere: Serotonin and the Meta-Trait of Stability”