
Abstract
It has been suggested that social psychologists have a unique opportunity to learn from their mistakes and to improve scientific practices (Bloom, 2016). So far, the editors and the editorial board responsible for PSPB have failed to seize this opportunity. The collective activities of social psychologists that leads to the publication of statistical results in this journal have changed rather little in response to concerns that most of the published results in social psychology are not replicable.
Introduction
There is a replication crisis in social psychology (see Schimmack, 2020, for a review). This crisis is sometimes unfairly generalized to all disciplines in psychology, while some areas do not have a replication crisis (Open Science Collaboration, 2015; Schimmack, 2020). The crisis is also sometimes presented as an opportunity.
“A public discussion about how scientists make mistakes and how they can work to correct them will help advance scientific understanding more generally. Psychology can lead the way here.” (Paul Boom, 2016. The Atlantic).
However, the response to the replication crisis by social psychologists has been mixed (Schimmack, 2020). Especially, older social psychologists have mostly denied that there is a crisis. In contrast, younger social psychologists have created a new organization to improve (social) psychology. It is unclear whether the comments by older psychologists reflect their behaviors. On the other hand, it is possible that they continue to conduct research as before. On the other hand, it is possible that older social psychologists are mainly trying to preserve a positive image, while they are quietly changing their behaviors.
This blog post sheds some light on this question by examining the replicability of results published in the journal Personality and Social Psychology Bulletin (PSPB). The editors during the decade of replication failures were Shinobu Kitayama, Duane T. Wegener & Lee Fabrigar, and Christian S. Crandall.
One year before the replication crisis, Kitayama (2010) was optimistic about the quality of research in PSPB. “Now everyone in our field would agree that PSPB is one of our very best journals.” He also described 2010 as an exciting time, not knowing how exciting the next decade would be. I could not find an editorial by Wegener and Fabrigar. Their views on the replication crisis are reflected in their article “Conceptualizing and evaluating the replication of research results” (Fabrigar & Wegener, 2016).
“Another theme that readers might draw from our discussion is that concerns about a “replication crisis” in psychology are exaggerated. In a number of respects, one might conclude that much of what we have said is reassuring for the field.” (p. 12).
Cris Crandall is well-known as an outspoken defender of the status quo on social media. This view is echoed in his editorial (Crandall, Leach, Robinson, & West, 2018).
“PSPB has always been a place for newer, creative ideas, and we will continue to seek papers that showcase creativity, progress, and innovation. We will continue the practice of seeking the highest quality” (p. 287).
However, the authors also express their intention to make some improvements.
“We encourage people to be transparent in the analysis and reporting of a priori power, consistent with the goals of transparency and clarity in reporting all statistical analyses.”
Despite this statement, PSPB did not implement open-science badges that reward researchers for sharing data or pre-registering studies. I asked Chris Crandall why he did not adopt badges for PSPB, but he declined to answer.
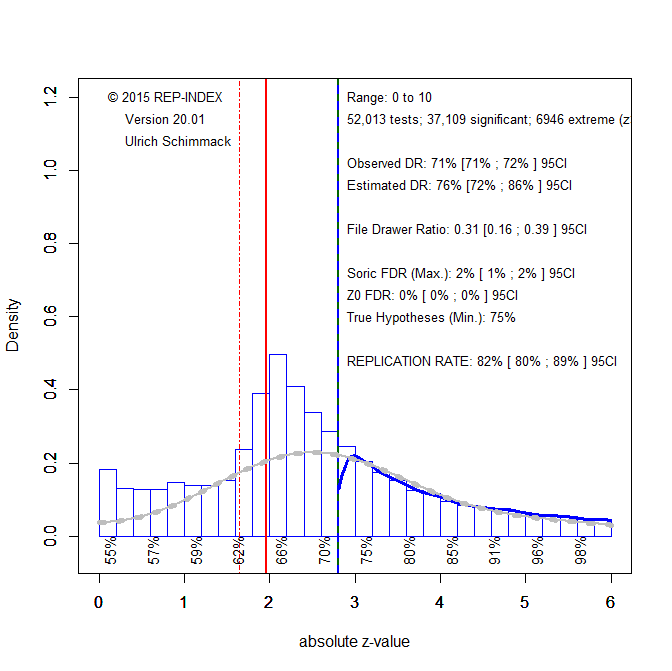
It is therefore an empirical question how much the credibility of results published in PSPB has improved in response to the replication crisis. This blog post examines this question by conducting a z-curve analysis of PSPB (Brunner & Schimmack, 2019; Bartos & Schimmack, 2020). Articles published from 2000 to 2019 were downloaded and test statistics (F-values, t-values) were automatically extracted. Figure 1 shows a z-curve plot of the 50,013 test statistics that were converted into two-sided p-values and then converted into absolute z-scores.

Visual inspection of Figure 1 shows that researchers used questionable research practices. This is indicated by the cliff around a value of z = 1.96 that corresponds to a p-value of .05 (two-tailed). As can be seen, there are a lot fewer results just below 1.96 that are not significant than results just above 1.96 that are just-significant. Moreover, results between 1.65 and 1.96 are often reported as marginally significant support for a hypothesis. Thus, only values below 1.65 reflect results that are presented as truly non-significant results.
Z-Curve quantifies the use of QRPs by comparing the expected discovery rate to the observed discovery rate. The observed discovery rate is the percentage of reported results that are significant. The expected discovery rate is the percentage of significant results that are expected given the distribution of significant results. The grey curve shows the expected distribution. The observed discovery rate of 71%, 95%CI = 71%-72%, is much higher than the expected discovery rate of 34%, 95%CI = 22% to 41%. The confidence intervals are clearly not overlapping, indicating that this is not just a chance finding. Thus, questionable practices were used to inflate the percentage of reported significant results. For example, a simple QRP is to simply not report results from studies that failed to produce significant results. Although this may seem dishonest and unethical, it is a widely used practice.
Z-curve also provides an estimate of the expected replication rate (ERR). The ERR is the percentage of significant results that is expected if studies with significant results were replicated exactly, including the same sample size. The estimate is 64%, which is not a terribly low ERR. However, there are two caveats. First, the estimate is an average and replicability is lower for just significant results as indicated by the estimates of 31% for z-scores between 2 and 2.5. This means that just-significant results are unlikely to replicate. Moreover, it has been pointed out that studies in social psychology are more difficult to replicate. Thus, exact replications are impossible. Using data from actual replications, Bartos and Schimmack (2020) found that the expected discovery rate is a better predictor of success rates in actual replication studies, which is about 25% (Open Science Collaboration, 2015). For PSPB, the EDR estimate of 34% is closer to the actual success rate than the ERR of 64%.
Given the questionable nature of just-significant results, it is possible to exclude these values from the z-curve model. I typically use 2.4 as a criterion but given the extent of questionable practices, I chose a value of 2.8, which corresponds to a p-value of .005. Figure 2 shows the results. Questionable research practices are now reflected in the high proportion of just-significant results that exceeds the proportion predicted by z-curve (grey curve). The replication rate increases to 82%, and the EDR increases to 76%. Thus, readers of PSPB may use p = .005 to evaluate statistical significance because these results are more credible than just significant results that were obtained with questionable practices.
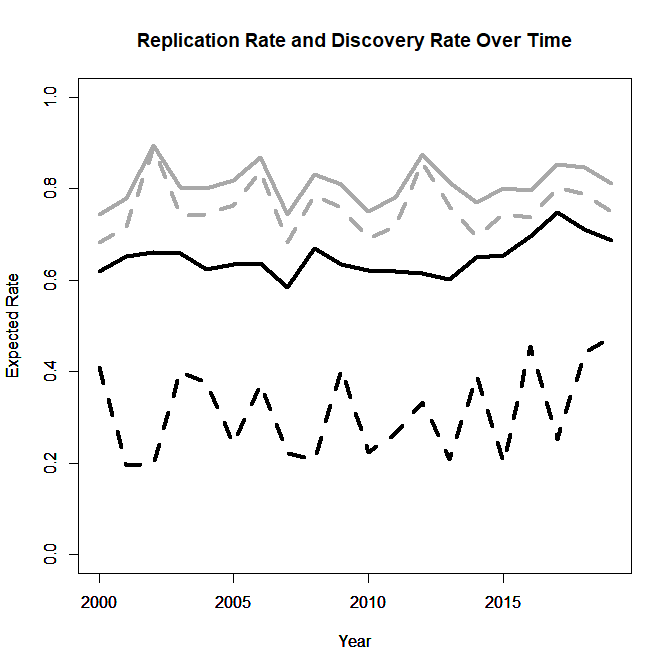
Figure 3 examines time trends for ERR (black) and EDR (grey) computed for all significant results (solid) and for selected z-scores greater than 2.8 (dotted). The time trend for the ERR with all significant results is significant, t(19) = 2.35, p = .03, but all other time trends are not significant. In terms of effect sizes the ERR with all significant results increased from 63% in 2000-2014, to 71% in 2015-2019. The EDR for all significant results also increased from 29% to 41%. Thus, it is possible that slight improvements did occur, although there is too much uncertainty in the estimates to be sure. Although the positive trend in the last couple of years is encouraging, the results do not show a notable response to the replication crisis in social psychology. The absence of a strong response is particularly troublesome if success rates of actual replication studies are better predicted by the EDR than the ERR.
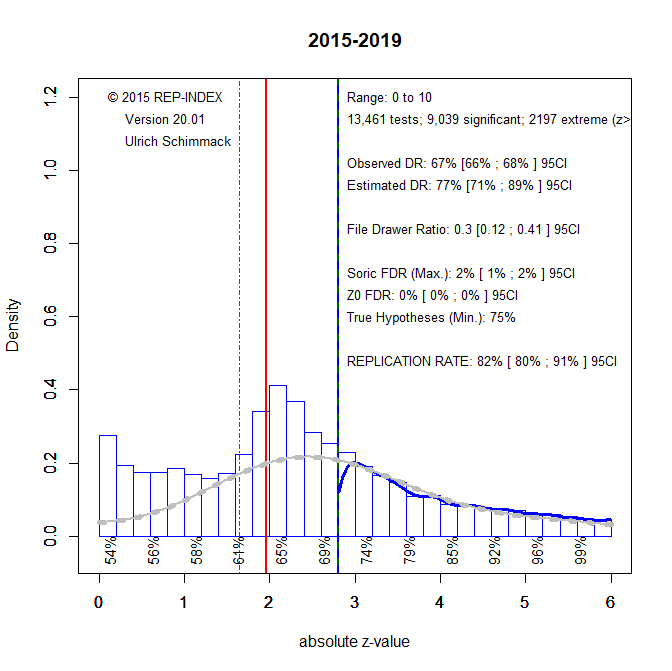
The next figures make different assumptions about the use of questionable research practices in the more recent years form 2015-2019. Figure 4 shows the model that assumes researchers simply report significant results and tend to not report non-significant results.

The large discrepancy between the EDR and ODR suggests that questionable research practices continue to be used by social psychologists who publish in PSPB. Figure 5 excludes questionable results that are just significant. This figure implies that researchers are using QRPs that inflate effect sizes to produce significant results. As these practices tend to produce weak evidence, they produce an unexplained pile of just-significant results.
The last figure fits z-curve to all results, including non-significant ones. Without questionable practices the model should fit well across the entire range of z-values.

The results suggest that questionable research practices are used to turn promising results (z > 1 & z < 2) into just-significant results (z > 2 & z < 2.4) because there are too few promising results and too many just-significant results.
The results also suggest that non-significant results are mostly false negatives (i.e., there is an effect, but the result is not significant). The estimated maximum false discovery rate is only 3%, and the estimate of the minimum number of true hypotheses that are being tested is 62%. Thus, there is no evidence that most significant results in PSPB are false positives or that replication failures can be attributed to testing riskier hypotheses than cognitive psychologists. The results are rather consistent with criticisms that have been raised decades ago that social psychologists mostly test true hypotheses with low statistical power (Cohen, 1962). Thus, neither significant results nor non-significant results provide much empirical evidence that can be used to evaluate theories. To advance social psychology, social psychologists need to test riskier predictions (e.g., make predictions about ranges of effect sizes) and they need to do so with high power so that prediction failures can falsify theoretical predictions and spurn theory development. Social psychology will make no progress if it continues to focus on rejecting nil-hypotheses that manipulations have absolutely no effect that are a priori implausible.
Given the present results, it seems unlikely that PSPB will make the necessary changes to increase the credibility and importance of social psychology; at least until a new editor is appointed. Readers are advised to be skeptical about just significant p-values and focus on p-values less than .005 (heuristic: ~ t > 2.8, F > 8).
Conclusion
In conclusion, it has been suggested that social psychologists have a unique opportunity to learn from their mistakes and to improve scientific practices (Bloom, 2016). So far, the editors and the editorial board responsible for PSPB have failed to seize this opportunity. The collective activities of social psychologists that leads to the publication of statistical results in this journal have changed rather little in response to concerns that most of the published results in social psychology are not replicable.