In this series of blog posts, I am reexamining Carter et al.’s (2019) simulation studies that tested various statistical tools to conduct a meta-analysis. The reexamination has three purposes. First, it examines the performance of methods that can detect biases to do so. Second, I examine the ability of methods that estimate heterogeneity to provide good estimates of heterogeneity. Third, I examine the ability of different methods to estimate the average effect size for three different sets of effect sizes, namely (a) the effect size of all studies, including effects in the opposite direction than expected, (b) all positive effect sizes, and (c) all positive and significant effect sizes.
The reason to estimate effect sizes for different sets of studies is that meta-analyses can have different purposes. If all studies are direct replications of each other, we would not want to exclude studies that show negative effects. For example, we want to know that a drug has negative effects in a specific population. However, many meta-analyses in psychology rely on conceptual replications with different interventions and dependent variables. Moreover, many studies are selected to show significant results. In these meta-analyses, the purpose is to find subsets of studies that show the predicted effect with notable effect sizes. In this context, it is not relevant whether researchers tried many other manipulations that did not work. The aim is to find the one’s that did work and studies with significant results are the most likely ones to have real effects. Selection of significance, however, can lead to overestimation of effect sizes and underestimation of heterogeneity. Thus, methods that correct for bias are likely to outperform methods that do not in this setting.
I focus on the selection model implemented in the weightr package in R because it is the only tool that tests for the presence of bias and estimates heterogeneity. I examine the ability of these tests to detect bias when it is present and to provide good estimates of heterogeneity when heterogeneity is present. I also use the model result to compute estimates of the average effect size for all three sets of studies (all, only positive, only positive & significant).
The second method is PET-PEESE because it is widely used. PET-PEESE does not provide conclusive evidence of bias, but a positive relationship between effect sizes and sampling error suggests that bias is present. It does not provide an estimate of heterogeneity. It is also not clear which set of studies are the target of this method. Presumably, it is the average effect size of all studies, but if very few negative results are available, the estimate overestimates this average. I examine whether it produces a more reasonable estimate of the average of the positive results.
P-uniform is included because it is similar to the widely used p-curve method,but has an r-package and produces slightly superior estimates. I am using the LN1MINP method that is less prone to inflated estimates when heterogeneity is present. P-uniform assumes selection bias and does not test for it. It also does not test heterogeneity. Importantly, p-uniform uses only significant results and estimates the average effect size of the set of studies with positive and significant results. It does not provide estimates for the set of only positive results (including non-significant ones) or the set of all studies, including negative results.
Finally, I am using these simulations to examine the performance of z-curve.2.0. Using exactly the simulations that Carter et al. (2019) used prevents me from simulation hacking; that is, testing situations that show favorable results for my own method. I am testing the performance of z-curve to estimate average power of studies with positive and significant results and the average power of all positive studies. I then use these power estimates to estimate the average effect size for these two sets of studies. I also examine the presence of publication bias and p-hacking with z-curve.
In a simulation without bias (Simulation #296) and with high selection bias and p-hacking (Simulation #424) performed well when it properly modeled selection bias and p-hacking. Here I present a simulation that assumes only p-hacking without selection bias (simulation #328). This scenario is interesting because all studies that were conducted are available for the meta-analysis. P-hacking will only inflate effect size estimates for some studies to produce statistical significance. The question is how p-hacking influences effect sizes estimates of models that assume selection bias and correct for selection bias, when selection bias is not present.
Simulation 328
I focus on a sample size of k = 100 studies to examine the properties of confidence intervals with a large, but not unreasonable set of studies. Simulation 328 has the same mean and standard deviation of the true population effect sizes in simulations #296 and #424, namely a small mean effect size of d = .2 and large heterogeneity, tau = 4. The curve in Figure 1 shows the distribution of true population effect sizes. 95% of these effect sizes are in the range from -.6 and 1.
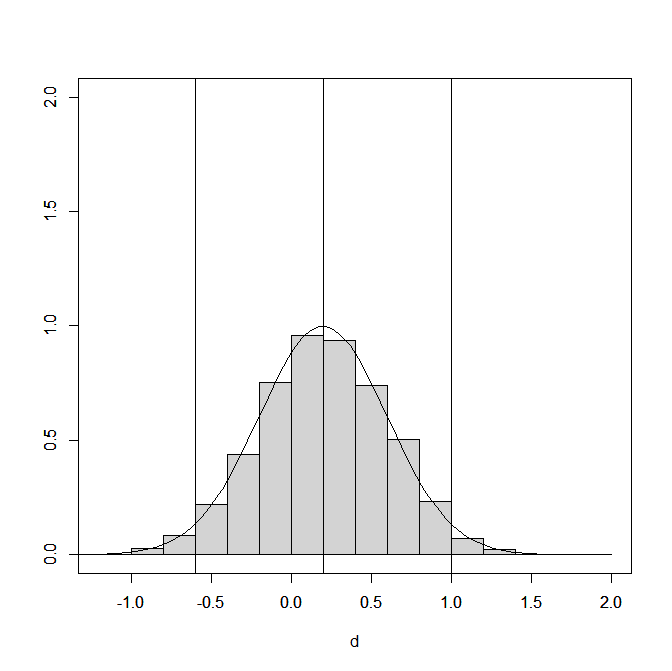
The histogram in Figure 1 shows the distribution of population effect sizes in the studies that are “published,” that is, studies that are available for the meta-analysis. It simply shows that p-hacking does not change the population of studies that are available for meta-analysis. The distribution of the true population effect sizes is not influenced by p-hacking.
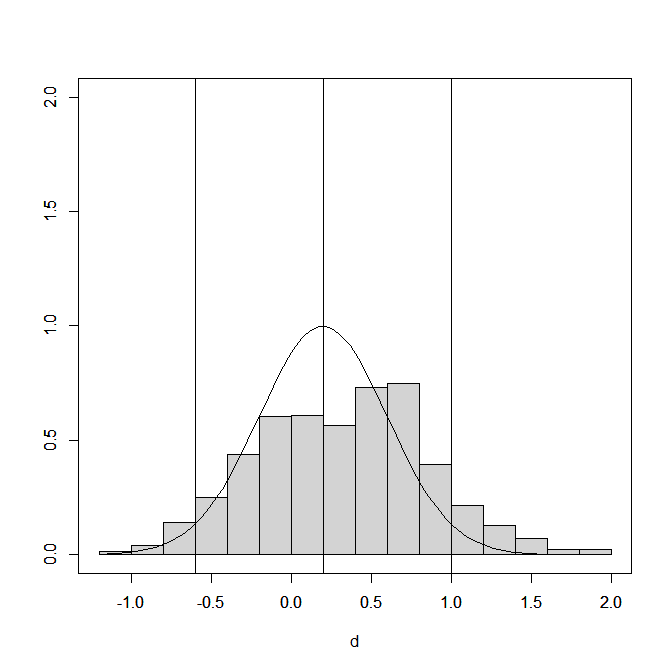
Figure 2 shows the distribution of the effect size estimates (extreme values below d = 1.2 and above d = 2 are excluded). The key finding here is that p-hacking moves some observed effect size estimates to the right. Thus, a naive meta-analysis would overestimate the average effect size.
P-hacking however, is a broad term for many practices and it can vary in terms of the amount of bias that is introduced. it is therefore important to examine the amount of p-hacking that is simulated in Carter et al.’s (2019) simulation with “high” p-hacking. The effect of “high” p-hacking on naive meta-analyses is relatively mild.
For the set of all studies, the weighted average effect size estimate is d = .20, not even inflated at all. The reason is that large samples are more likely to produce significant results without p-hacking and are weighted more heavily in the estimation of the true average.
The true average for only positive results is d = .38. The weighted average estimate is d = .44. This is a small bias with little practical consequences.
For the subset of positive and significant results the true average is d = .47. The weighted average estimate is d = .53. Once more, the bias is small.
Thus, Carter et al.’s (2019) simulation of p-hacking in the “high” condition is relatively mild p-hacking. Intense p-hacking would produce 100% significant results without a real effect.
Figure 3 shows the z-curve plot when the effect sizes and sampling errors are converted into z-scores. The distribution of z-scores shows that there are too many just significant results. A binomial test of the frequency of z-scores between 2 and 2.6 (roughly p = .05 to .01, two-sided) shows excessive just significance (EJS) p < .0001. However, these results do not tell us whether the excess is due to publication bias or p-hacking.

To distinguish between the two sources of bias, I fitted the model to the “really” significant results (z > 2.6). This makes it possible to use the EJS test to reveal p-hacking. If the amount of just significant results is not consistent with the model of really significant results, it suggests that p-hacking was used.

The results in Figure 4 show statistically significant excessive just significance, p < .0001, but the model predicts the distribution of just significant z-scores rather well. The difference between observed (54%) and expected (45%) just significant results is small. Thus, the model falsely assumes that selection bias accounts for the high percentage of just significant results. This has important implications for the estimates of power. The average power of the significant results (p < .05, two-sided) is called the Expected Replication Rate and is estimated to be ERR = 43%. This is slightly lower than the true value of 48%. The reason is that p-hacking produces a downward bias and the model does not fully correct for p-hacking.
The effect on the estimate of average power for all positive results, including non-significant ones, is even bigger. This estimate is called the expected discovery rate. The estimate is only 16%, but the true value is 40%. Thus, p-hacking can severely bias the estimate of the EDR when the model assumes selection bias rather than p-hacking contributes to the excess of just significant results.
In actual datasets with fewer studies, it is even more difficult to distinguish between publication bias and p-hacking. So, what can meta-analysts do when there is uncertainty about the cause of excessive just-significant results? First, they can use figures like Figure 3 to examine whether the pattern looks like some non-significant results were moved up to produce an excess of just significant results. In Figure 3, this seems plausible, and we know that this is how the data were created. However, the model in Figure 3 is still influenced by the excessive just significant results and overestimates power. Thus, some correction would be needed. A second option is to fit the normal selection model. This will lead to an underestimation of power, but that can be considered a desirable bias that punishes p-hacking.
Figure 5 shows that the normal selection model underestimates the true power after selection for significance by 10 percentage points (38% versus 48%). This is also not much lower than the estimate with the model that takes p-hacking into account (Figure 4, 43%). Thus, for situations with relatively mild p-hacking like this one, the normal selection model may be acceptable, especially when there is no conclusive evidence that p-hacking was used.

The bias for effect size estimates is also small. The estimate based on the typical selection model for the average effect size of positive and significant results is d = 43, whereas the true parameter is .48. Thus, I used the normal selection model to estimate power and effect sizes for this simulation condition.
To conclude this discussion of p-hacking, it is important to understand the p-hacking simulation in Carter et al.’s (2019) simulation #328. While the condition is the highest level of p-hacking in their design, the amount of p-hacking is mild. First, studies with positive results have an average power of 40% to produce a significant result without p-hacking. Second, about one-quarter of non-significant positive results remain non-significant. Third, many negative results are also available. In contrast, intense p-hacking would produce mostly significant results with less than 33% power (Simonsohn et al. 2014). Thus, additional simulations of p-hacking with more extreme levels of p-hacking are needed to evaluate all methods under those conditions.
Model Specifications
The specification of the z-curve model was explained and justified above.
The specification of the selection model is easier because it can take selection bias and p-hacking into account in a single model. I used the same approach that I used for simulation #424 that simulated selection bias and p-hacking. I modeled selection bias with the standard approach; that is, a step at .025 (one-tailed) to distinguish positive and significant results from all other results. In addition, I added a step at .005 (one-tailed). This models p-hacking by allowing an excess of p-values between .05 and .01 (two-tailed). The selection weight for this range of p-values is used as a test of p-hacking. In addition, the model had steps at .5 to distinguish positive and negative effects, and .975 to distinguish negative non-significant and negative significant results. The selection weight for positive non-significant results is used as a test of selection bias, but we already saw that p-hacking alone can reduce the amount of non-significant results because these p-hacking moves these p-values into the range of just significant results. Thus, it is difficult to detect selection bias when evidence of p-hacking is present.
The key advantage of the selection model is that it does not rely on significance testing to specify models with or without bias. It will adjust the estimates of the average and standard deviation of the effect sizes based on the estimated amount of bias. The following simulation examines how well this adjustment works when only 100 studies are available to fit the model. .
P-uniform and PET-PEESE do not require thinking and were used as usual.
Selection Model (weightr)
Carter et al. (2019) observe conversion issues with the selection model in some conditions. In my simulation the model produced useable estimates 100% of the time. The test of selection bias showed an average weight for non-significant positive results of .50, but with a wide confidence interval, average CI ranging from -.07 to 1.06. Only 58% of the confidence intervals excluded a value of 1. More important is the test of p-hacking. The average weight for just significant results was high, suggesting p-hacking, w = 3.14. However, the average confidence interval was wide, ranging from .55 to 5.74, and only 11% of the confidence intervals excluded a value of 1. Thus, mild p-hacking is difficult to detect.
The low power to detect p-hacking also led to an underestimation of the average effect size, d = .13, 95%CI = -.13 to .39, but 88% of confidence intervals included the true value of d = .20. The bias is small. The estimate of heterogeneity was close to the true value, tau = .39, average CI = .24 to .49 and 88% of CI included the true value of tau = .40. As a result, the estimate of the subset of results with positive effect size estimates had only a small bias, d = .33, average CI = .05 to .57, and 91% of confidence intervals included the true value of d = .38. Finally, the estimated average for positive and significant results was d = .53, average CI = .23 to .75, and 95% of confidence intervals included the true value of d = .47.
In short, while the selection model was not able to detect p-hacking, it provided good estimates of average effect sizes and heterogeneity in Carter et al.’s (2019) simulation of p-hacking. This finding diverges from Carter et al.’s results that suggested the selection model severely underestimates effect sizes when p-hacking is present. The reason for the discrepancy is that Carter et al. used the default implementation of the selection model that distinguishes only non-significant and significant results. The present results show that a specification that takes p-hacking and the sign of effects into account leads to superior estimates. Thus, Carter et al.’s (2019) concerns about selection models can be addressed with a better specification of the selection model and are not a problem of selection models in general.
It is important that these results were obtained with Carter et al.’s (2019) simulation of p-hacking. Thus, the good results of the selection model cannot be attributed to simulation hacking; that is, I picked a simulation condition that favored a preferred model. Furthermore, my preferred model is z-curve. The good performance of the selection model is just an empirical observation that can be reproduced easily by using the proper specification of the selection model with steps at .005, .025, .050, .500, and .975.
The good performance of the selection model can be explained by Carter et al.’s (2019) simulation of population effect sizes with a normal distribution. This simulation matches the assumptions of the selection model. An interesting question is how the selection model performs with other distributions of effect sizes, but this goes beyond the reexamination of Carter et al.’s (2019) simulation studies.
PET-PEESE
PET regresses effect sizes on the sampling error. The average estimate was d = .04, average 95%CI = -.12 to .21, and only 45% of the confidence intervals included the true parameter, d = .20. Thus, PET often fails to reject the false null-hypothesis. This is a problem because PET does not provide information about heterogeneity. Thus, the non-significant PET result can easily be misinterpreted as evidence that the null hypothesis is true in all studies, which is clearly not the case in this simulation that has high heterogeneity and the set of studies with positive estimates has an average effect size of d = .38.
PEESE regresses the effect sizes on the sampling variance (i.e., the squared sampling error). The average effect size estimate is d = .10, average 95%CI = -.01 to .21, and only 53% of the confidence intervals include the true average for all studies. PEESE is better than PET, but the problem here is that a non-significant estimate for PET is used to favor PET over PEESE estimates.
In short, PET-PEESE is clearly inferior to the selection model in this simulation condition. It was also inferior or not better in the simulation without bias or with p-hacking and selection bias. Whether PET-PEESE ever outperforms the selection model has to be examined in other settings.
P-Uniform
The p-uniform estimate is d = .31, average 95%CI = .12 to .42. It is often stated that p-uniform overestimates effect sizes in the presence of heterogeneity. However, this claim is based on the comparison of p-uniform estimates to the true average for all studies, d = .2. This is not a plausible comparison because p-uniform estimates are based on the subset of significant results and the method estimates the average effect size of this subset. The true average for positive and significant results is d = .38. Thus, p-hacking introduces a small bias. The results are nearly as good as the estimate for positive and significant results with the selection model. Thus, there is no evidence that high heterogeneity inflates p-uniform estimates in this simulation. Rather, p-uniform tends to underestimate the average effect size when p-hacking is used.
P-uniform also tests for the presence of bias, but the test detected bias in only 2% of the studies. The main limitation of p-uniform is that it does not provide tests of heterogeneity. As the selection model estimates average power of positive and significant results as well as p-uniform, and it detects bias better than the p-uniform method, the selection model is superior.
Z-Curve
In a model that assumed no bias, z-curve predicted on average 36% just significant results. On average 54% just significant results were observed, The binomial significance test showed evidence of bias was significant 84% of the time. This shows higher power to detect bias. However, the model that tests specifically for p-hacking found only 25% significant results The reason is that the z-curve prediction of just significant results based on the “really” significant results was close to the observed frequency (49% vs. 54%). Without evidence of p-hacking, the normal selection model was applied to all significant z-scores (z > 1.96).
The average power was estimated at 38%, average 95%CI = 20% to 58%. As the confidence interval is wide, 81% of confidence intervals included the true value of 46%, despite a 10 percentage-point bias. These results show that p-hacking leads to an underestimation of power when just significant results are attributed to selection rather than p-hacking.
The bias is more pronounced for the estimated average power of positive results. Here the average estimate is 16%, average 95%CI = .05 to .43, and none of the confidence intervals included the true value of 40%. This shows that p-hacking can dramatically attenuate estimates of the average power of positive tests. How to deal with this bias will be the topic of future blog posts.
Although the average power of positive and significant results was underestimated, the estimate of the average effect size for this set of results was slightly overestimated, d = .41, average 95%CI = .26 to .55 and 90% of the CI included the true value, d = .38. While this is the best estimate of the average effect size for this set of studies, it is unlikely that this is a robust finding.
The effect size estimate for the set of positive results was underestimated, d = .22, 95% = .00 to .44, and only 66% of confidence intervals included the correct value.
In conclusion, z-curve can provide a powerful test of bias that is more powerful than the test of bias with the selection model. Z-curve also provides useable estimates of average power and effect sizes for the positive and significant results, but the estimates for the set of positive results are severely biased by p-hacking.
Conclusion
The main conclusion from this simulation study is that a properly specified selection model that models p-hacking with overrepresentation of just significant results outperforms other models. This adds to the finding that the selection model performs as well or better than other models without bias or with a mix of selection bias and p-hacking. Z-curve adds information about the presence of bias, either selection or p-hacking, and power estimation for the set of studies with significant results. The other methods have yet to show that they can outperform the selection model in some realistic conditions.
The present results from a reexamination of Carter et al.’s (2019) simulation study are important because the undermine Carter et al.’s (2019) main conclusion that no model works best in all situations. So far, the improved selection model does work well and does not show the strong underestimation of effect sizes that Carter et al. found in this condition with the default selection model (3PSM).
The good performance of the selection model may be due to the modeling of effect sizes with a normal distribution. This helps the selection model because it assumes a normal distribution. It is therefore necessary to expand Carter et al.’s (2019) simulation studies, and model other distributions of population effect sizes. Maybe other methods perform better in those scenarios.
Another observation in this reexamination was that Carter et al.’s high p-hacking condition actually modeled mild p-hacking. It is therefore necessary to examine simulations of more extreme forms of p-hacking.
1 thought on “Carter et al. (2019): Simulation #328”